
學(xué)習(xí)用Pandas處理分類數(shù)據(jù)!
↑↑↑關(guān)注后"星標(biāo)"Datawhale
每日干貨 &?每月組隊(duì)學(xué)習(xí),不錯(cuò)過(guò)
?Datawhale干貨?作者:耿遠(yuǎn)昊,Datawhale成員,華東師范大學(xué)
分類數(shù)據(jù)(categorical data)是按照現(xiàn)象的某種屬性對(duì)其進(jìn)行分類或分組而得到的反映事物類型的數(shù)據(jù),又稱定類數(shù)據(jù)。直白來(lái)說(shuō),就是取值為有限的,或者說(shuō)是固定數(shù)量的可能值。例如:性別、血型等。
今天,我們來(lái)學(xué)習(xí)下,Pandas如何處理分類數(shù)據(jù)。主要圍繞以下幾個(gè)方面展開(kāi):

本文目錄
????1.?Category的創(chuàng)建及其性質(zhì)
????????1.1.?分類變量的創(chuàng)建
??????? 1.2. 分類變量的結(jié)構(gòu)
? ? ? ? 1.3.?類別的修改
????2. 分類變量的排序
????????2.1. 序的建立
????????2.2.?排序
????3. 分類變量的比較操作
????????3.1. 與標(biāo)量或等長(zhǎng)序列的比較
????????3.2. 與另一分類變量的比較
????4.?問(wèn)題及練習(xí)
????????4.1. 問(wèn)題
????????4.2. 練習(xí)首先,讀入數(shù)據(jù):
import pandas as pdimport numpy as npdf = pd.read_csv('data/table.csv')df.head()
一、category的創(chuàng)建及其性質(zhì)
1.1.?分類變量的創(chuàng)建
(a)用Series創(chuàng)建
pd.Series(["a", "b", "c", "a"], dtype="category")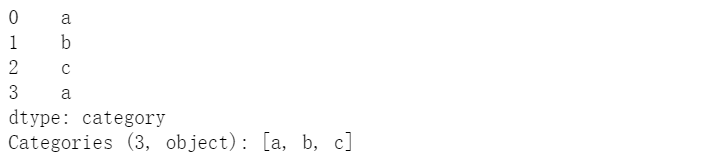
(b)對(duì)DataFrame指定類型創(chuàng)建
temp_df = pd.DataFrame({'A':pd.Series(["a", "b", "c", "a"], dtype="category"),'B':list('abcd')})temp_df.dtypes

(c)利用內(nèi)置Categorical類型創(chuàng)建
cat = pd.Categorical(["a", "b", "c", "a"], categories=['a','b','c'])pd.Series(cat)
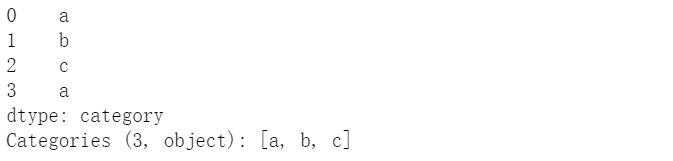
(d)利用cut函數(shù)創(chuàng)建,默認(rèn)使用區(qū)間類型為標(biāo)簽
pd.cut(np.random.randint(0,60,5), [0,10,30,60])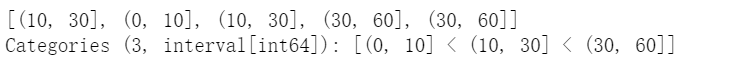
可指定字符為標(biāo)簽
pd.cut(np.random.randint(0,60,5), [0,10,30,60], right=False, labels=['0-10','10-30','30-60'])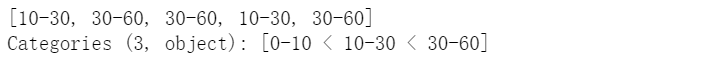
1.2. 分類變量的結(jié)構(gòu)
一個(gè)分類變量包括三個(gè)部分,元素值(values)、分類類別(categories)、是否有序(order)。從上面可以看出,使用cut函數(shù)創(chuàng)建的分類變量默認(rèn)為有序分類變量。下面介紹如何獲取或修改這些屬性。
(a)describe方法
該方法描述了一個(gè)分類序列的情況,包括非缺失值個(gè)數(shù)、元素值類別數(shù)(不是分類類別數(shù))、最多次出現(xiàn)的元素及其頻數(shù)。
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))s.describe()

(b)categories和ordered屬性,查看分類類別和是否排序
s.cat.categoriesIndex(['a', 'b', 'c', 'd'], dtype='object')
s.cat.orderedFalse1.3. 類別的修改
(a)利用set_categories修改,修改分類,但本身值不會(huì)變化
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))s.cat.set_categories(['new_a','c'])

(b)利用rename_categories修改,需要注意的是該方法會(huì)把值和分類同時(shí)修改
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))s.cat.rename_categories(['new_%s'%i for i in s.cat.categories])

利用字典修改值
s.cat.rename_categories({'a':'new_a','b':'new_b'})
(c)利用add_categories添加
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))s.cat.add_categories(['e'])

(d)利用remove_categories移除
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))s.cat.remove_categories(['d'])

(e)刪除元素值未出現(xiàn)的分類類型
s = pd.Series(pd.Categorical(["a", "b", "c", "a",np.nan], categories=['a','b','c','d']))s.cat.remove_unused_categories()

二、分類變量的排序
前面提到,分類數(shù)據(jù)類型被分為有序和無(wú)序,這非常好理解,例如分?jǐn)?shù)區(qū)間的高低是有序變量,考試科目的類別一般看做無(wú)序變量
2.1.?序的建立
(a)一般來(lái)說(shuō)會(huì)將一個(gè)序列轉(zhuǎn)為有序變量,可以利用as_ordered方法
s = pd.Series(["a", "d", "c", "a"]).astype('category').cat.as_ordered()s

退化為無(wú)序變量,只需要使用as_unordereds.cat.as_unordered()
(b)利用set_categories方法中的order參數(shù)
pd.Series(["a", "d", "c", "a"]).astype('category').cat.set_categories(['a','c','d'],ordered=True)
(c)利用reorder_categories方法,這個(gè)方法的特點(diǎn)在于,新設(shè)置的分類必須與原分類為同一集合
s = pd.Series(["a", "d", "c", "a"]).astype('category')s.cat.reorder_categories(['a','c','d'],ordered=True)

#s.cat.reorder_categories(['a','c'],ordered=True) #報(bào)錯(cuò)#s.cat.reorder_categories(['a','c','d','e'],ordered=True) #報(bào)錯(cuò)
2.2. 排序
先前在第1章介紹的值排序和索引排序都是適用的
s = pd.Series(np.random.choice(['perfect','good','fair','bad','awful'],50)).astype('category')s.cat.set_categories(['perfect','good','fair','bad','awful'][::-1],ordered=True).head()

s.sort_values(ascending=False).head()
df_sort = pd.DataFrame({'cat':s.values,'value':np.random.randn(50)}).set_index('cat')df_sort.head()

df_sort.sort_index().head()
3.1. 與標(biāo)量或等長(zhǎng)序列的比較
(a)標(biāo)量比較
s = pd.Series(["a", "d", "c", "a"]).astype('category')s == 'a'

(b)等長(zhǎng)序列比較
s == list('abcd')
3.2.?與另一分類變量的比較
(a)等式判別(包含等號(hào)和不等號(hào)),兩個(gè)分類變量的等式判別需要滿足分類完全相同。
s = pd.Series(["a", "d", "c", "a"]).astype('category')s == s

s != s
s_new = s.cat.set_categories(['a','d','e'])#s == s_new #報(bào)錯(cuò)
(b)不等式判別(包含>=,<=,<,>),兩個(gè)分類變量的不等式判別需要滿足兩個(gè)條件:① 分類完全相同 ② 排序完全相同
s = pd.Series(["a", "d", "c", "a"]).astype('category')#s >= s #報(bào)錯(cuò)
s = pd.Series(["a", "d", "c", "a"]).astype('category').cat.reorder_categories(['a','c','d'],ordered=True)s >= s

四、問(wèn)題與練習(xí)
4.1. 問(wèn)題【問(wèn)題一】 如何使用union_categoricals方法?它的作用是什么?
- 如果要組合不一定具有相同類別的類別,union_categoricals函數(shù)將組合類似列表的類別。新類別將是合并的類別的并集。如下所示:
from pandas.api.types import union_categoricalsa = pd.Categorical(['b','c'])b = pd.Categorical(['a','b'])union_categoricals([a,b])

默認(rèn)情況下,生成的類別將按照在數(shù)據(jù)中顯示的順序排列。如果要對(duì)類別進(jìn)行排序,可使用sort_categories=True參數(shù)。
union_categoricals也適用于組合相同類別和順序信息的兩個(gè)分類。
union_categoricals可以在合并分類時(shí)重新編碼類別的整數(shù)代碼。
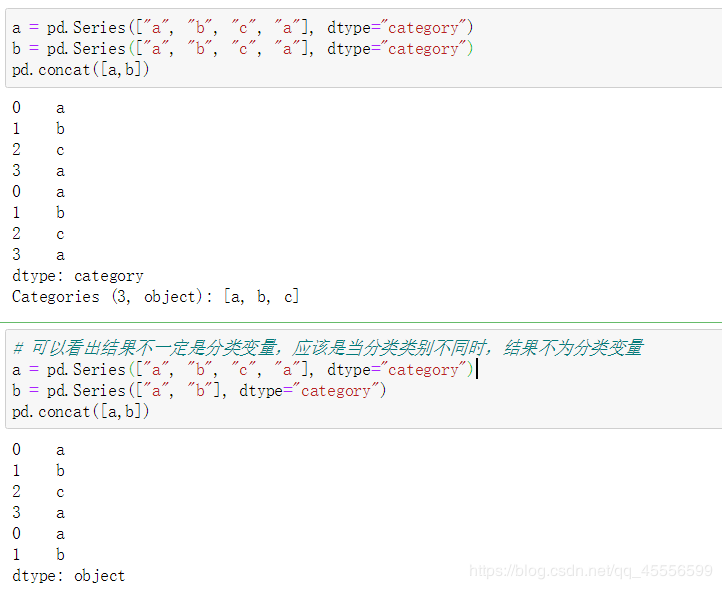
【問(wèn)題二】 利用concat方法將兩個(gè)序列縱向拼接,它的結(jié)果一定是分類變量嗎?什么情況下不是?
【問(wèn)題三】 當(dāng)使用groupby方法或者value_counts方法時(shí),分類變量的統(tǒng)計(jì)結(jié)果和普通變量有什么區(qū)別?
分類變量的groupby方法/value_counts方法,統(tǒng)計(jì)對(duì)象是類別。
- 普通變量groupby方法/value_counts方法,統(tǒng)計(jì)對(duì)象是唯一值(不包含NA)。
【問(wèn)題四】 下面的代碼說(shuō)明了Series創(chuàng)建分類變量的什么“缺陷”?如何避免?(提示:使用Series中的copy參數(shù))
cat = pd.Categorical([1, 2, 3, 10], categories=[1, 2, 3, 4, 10])s = pd.Series(cat, name="cat")cat
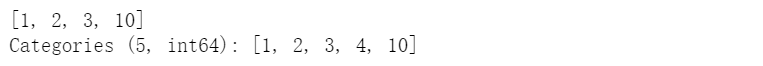
s.iloc[0:2] = 10cat
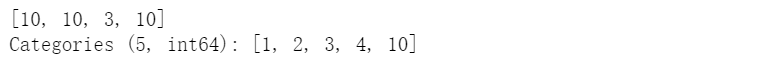
4.2. 練習(xí)
【練習(xí)一】 現(xiàn)繼續(xù)使用第四章中的地震數(shù)據(jù)集,請(qǐng)解決以下問(wèn)題:
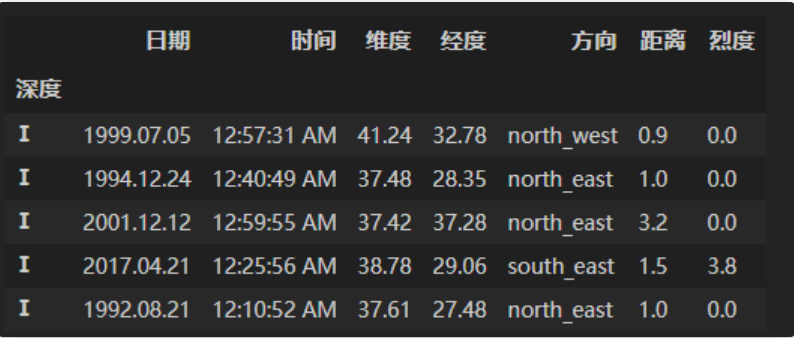
(a)現(xiàn)在將深度分為七個(gè)等級(jí):[0,5,10,15,20,30,50,np.inf],請(qǐng)以深度等級(jí)Ⅰ,Ⅱ,Ⅲ,Ⅳ,Ⅴ,Ⅵ,Ⅶ為索引并按照由淺到深的順序進(jìn)行排序。
- 使用cut方法對(duì)列表中的深度劃分,并將該列作為索引值。然后按索引排序即可。
df = pd.read_csv('data/Earthquake.csv')df_result = df.copy()df_result['深度'] = pd.cut(df['深度'],[0,5,10,15,20,30,50,np.inf], right=False, labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ','Ⅴ','Ⅵ','Ⅶ'])df_result = df_result.set_index('深度').sort_index()df_result.head()
(b)在(a)的基礎(chǔ)上,將烈度分為4個(gè)等級(jí):[0,3,4,5,np.inf],依次對(duì)南部地區(qū)的深度和烈度等級(jí)建立多級(jí)索引排序。
跟(a)很相似,cut方法對(duì)深度,烈度進(jìn)行切分,把index設(shè)為[‘深度’,‘烈度’],然后進(jìn)行索引排序即可。
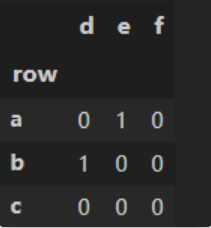
【練習(xí)二】 對(duì)于分類變量而言,調(diào)用第4章中的變形函數(shù)會(huì)出現(xiàn)一個(gè)BUG(目前的版本下還未修復(fù)):例如對(duì)于crosstab函數(shù),按照官方文檔的說(shuō)法,即使沒(méi)有出現(xiàn)的變量也會(huì)在變形后的匯總結(jié)果中出現(xiàn),但事實(shí)上并不是這樣,比如下面的例子就缺少了原本應(yīng)該出現(xiàn)的行'c'和列'f'。基于這一問(wèn)題,請(qǐng)嘗試設(shè)計(jì)my_crosstab函數(shù),在功能上能夠返回正確的結(jié)果。df['烈度'] = pd.cut(df['烈度'],[0,3,4,5,np.inf], right=False, labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ'])df['深度'] = pd.cut(df['深度'],[0,5,10,15,20,30,50,np.inf], right=False, labels=['Ⅰ','Ⅱ','Ⅲ','Ⅳ','Ⅴ','Ⅵ','Ⅶ'])df_ds = df.set_index(['深度','烈度'])df_ds.sort_index()
因?yàn)镃ategories中肯定包含出現(xiàn)的變量。所以將第一個(gè)參數(shù)作為index,第二個(gè)參數(shù)作為columns,建立一個(gè)DataFrame,然后把出現(xiàn)的變量組合起來(lái),對(duì)應(yīng)位置填入1即可。
foo = pd.Categorical(['b','a'], categories=['a', 'b', 'c'])bar = pd.Categorical(['d', 'e'], categories=['d', 'e', 'f'])import numpydef my_crosstab(a, b):s1 = pd.Series(list(foo.categories), name='row')s2 = list(bar.categories)df = pd.DataFrame(np.zeros((len(s1), len(s2)),int),index=s1, columns=s2)index_1 = list(foo)index_2 = list(bar)for loc in zip(index_1, index_2):df.loc[loc] = 1return dfmy_crosstab(foo, bar)
本文電子版 后臺(tái)回復(fù) 分類數(shù)據(jù) 獲取
“竟然學(xué)習(xí)完了,給自己點(diǎn)個(gè)贊↓