
使用 jvm-profiler 分析 spark 內(nèi)存使用
背景
在生產(chǎn)環(huán)境中,為了提高任務(wù)提交的響應(yīng)速度,我們研發(fā)了類似 Spark Jobserver 的服務(wù),各種類型的 spark 任務(wù)復(fù)用已經(jīng)啟動的 Spark Application,避免了 sparkContext 初始化冷啟動的過程。
可復(fù)用Spark服務(wù)的內(nèi)存是固定的,因此又開放了用戶自定義 Executor 內(nèi)存的權(quán)限,用戶為了避免自己的任務(wù)因內(nèi)存不足而失敗,往往會把內(nèi)存設(shè)置的很大,從而帶來了內(nèi)存濫用的問題。
jvm-profiler
一般來說監(jiān)控 spark 內(nèi)存有2種方式
通過 Spark ListenerBus 獲取 Executor 內(nèi)部的內(nèi)存使用情況 ,現(xiàn)在能獲取的相關(guān)信息還比較少,在 https://github.com/apache/spark/pull/21221 合進(jìn)來后就能采集到executor 內(nèi)存各個邏輯分區(qū)的使用情況。
通過 Spark Metrics 將 JVM 信息發(fā)送到指定的 sink,用戶也可以自定義 Sink 比如發(fā)送到 kafka/Redis。
Uber 最近開源了 jvm-profiler,采集分布式JVM應(yīng)用信息,可以用于 debug CPU/mem/io 或者方法調(diào)用的時間等。比如調(diào)整Spark JVM 內(nèi)存大小,監(jiān)控 HDFS Namenode RPC 延時,分析數(shù)據(jù)血緣關(guān)系。
應(yīng)用于 Spark 比較簡單
每5S采集一次JVM信息,發(fā)送到 kafka profiler_CpuAndMemory topic
hdfs dfs -put jvm-profiler-0.0.9.jar hdfs://hdfs_url/lib/jvm-profiler-0.0.9.jar--conf spark.jars=hdfs://hdfs_url/lib/jvm-profiler-0.0.9.jar--conf spark.executor.extraJavaOptions=-javaagent:jvm-profiler-0.0.9.jar=reporter=com.uber.profiling.reporters.KafkaOutputReporter,metricInterval=5000,brokerList=brokerhost:9092,topicPrefix=profiler_
消費后存入HDFS用于分析。
分析
hive 表結(jié)構(gòu)

對用戶自定義內(nèi)存的任務(wù)進(jìn)行分析
用戶自定義內(nèi)存調(diào)度任務(wù),75%的任務(wù)內(nèi)存使用率低于80%,可以進(jìn)行優(yōu)化。
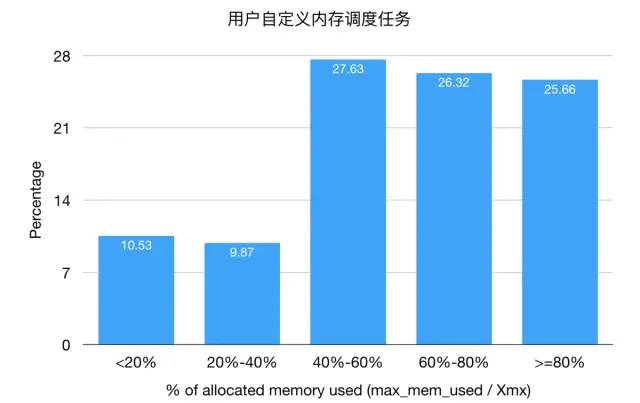
用戶自定義內(nèi)存調(diào)度任務(wù)
用戶自定義內(nèi)存開發(fā)任務(wù),45%的任務(wù)內(nèi)存使用率低于20%,用戶存在不良使用習(xí)慣。
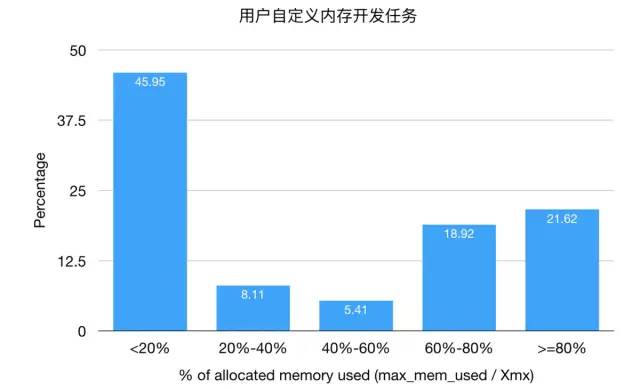
用戶自定義內(nèi)存開發(fā)任務(wù)
總結(jié)
通過采集 jvm 的最大使用值和設(shè)定值,可以解決下述問題。
內(nèi)存濫用
監(jiān)控應(yīng)用內(nèi)存使用趨勢,防止數(shù)據(jù)增長導(dǎo)致內(nèi)存不足
Spark Executor 默認(rèn)內(nèi)存設(shè)置不合理
根據(jù)應(yīng)用的使用預(yù)計內(nèi)存減少情況
executor 默認(rèn)內(nèi)存減少10%,平均每個任務(wù)能釋放 60G 內(nèi)存
自定義內(nèi)存調(diào)度任務(wù)利用率提高到 70%,平均每個任務(wù)能釋放 450G 內(nèi)存
自定義內(nèi)存開發(fā)任務(wù)利用率提高到 70%,平均每個任務(wù)能釋放 550G 內(nèi)存
參考
JVM Profiler: An Open Source Tool for Tracing Distributed JVM Applications at Scale
https://www.jianshu.com/p/09e2ccacfc26