
給127.0.0.1發(fā)了個包,我發(fā)現(xiàn)了···
大家好,我是飛哥!
我們拆解完了 Linux 網(wǎng)絡包的接收過程,也搞定了網(wǎng)絡包的發(fā)送過程。內(nèi)核收發(fā)網(wǎng)絡包整體流程就算是摸清楚了。
正在飛哥對這兩篇文章洋洋得意的時候,收到了一位讀者的發(fā)來的提問:“飛哥, 127.0.0.1 本機網(wǎng)絡 IO 是咋通信的”。額,,這題好像之前確實沒講到。。
現(xiàn)在本機網(wǎng)絡 IO 應用非常廣。在 php 中 一般 Nginx 和 php-fpm 是通過 127.0.0.1 來進行通信的。在微服務中,由于 side car 模式的應用,本機網(wǎng)絡請求更是越來越多。所以,我想如果能深度理解這個問題在實踐中將非常的有意義,在此感謝@文武 的提出。
今天咱們就把 127.0.0.1 的網(wǎng)絡 IO 問題搞搞清楚!為了方便討論,我把這個問題拆分成兩問:
127.0.0.1 本機網(wǎng)絡 IO 需要經(jīng)過網(wǎng)卡嗎? 和外網(wǎng)網(wǎng)絡通信相比,在內(nèi)核收發(fā)流程上有啥差別?
鋪墊完畢,拆解正式開始!!
一、跨機網(wǎng)路通信過程
在開始講述本機通信過程之前,我們還是先回顧一下跨機網(wǎng)絡通信。
1.1 跨機數(shù)據(jù)發(fā)送
從 send 系統(tǒng)調(diào)用開始,直到網(wǎng)卡把數(shù)據(jù)發(fā)送出去,整體流程如下:
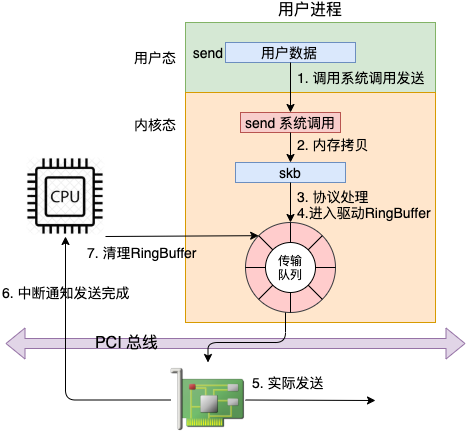
在這幅圖中,我們看到用戶數(shù)據(jù)被拷貝到內(nèi)核態(tài),然后經(jīng)過協(xié)議棧處理后進入到了 RingBuffer 中。隨后網(wǎng)卡驅動真正將數(shù)據(jù)發(fā)送了出去。當發(fā)送完成的時候,是通過硬中斷來通知 CPU,然后清理 RingBuffer。
不過上面這幅圖并沒有很好地把內(nèi)核組件和源碼展示出來,我們再從代碼的視角看一遍。
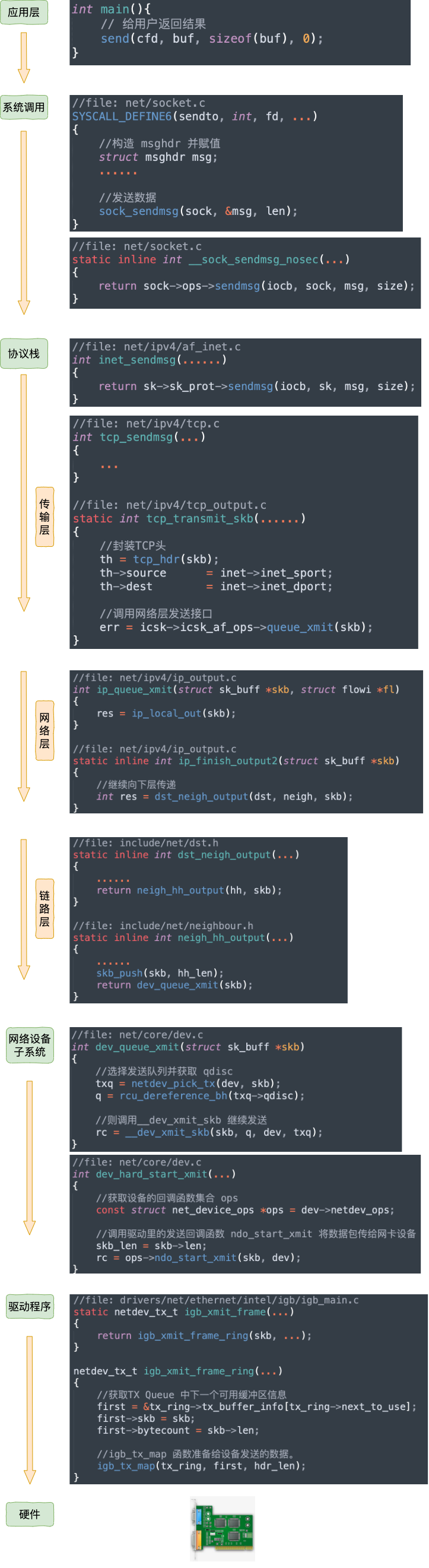
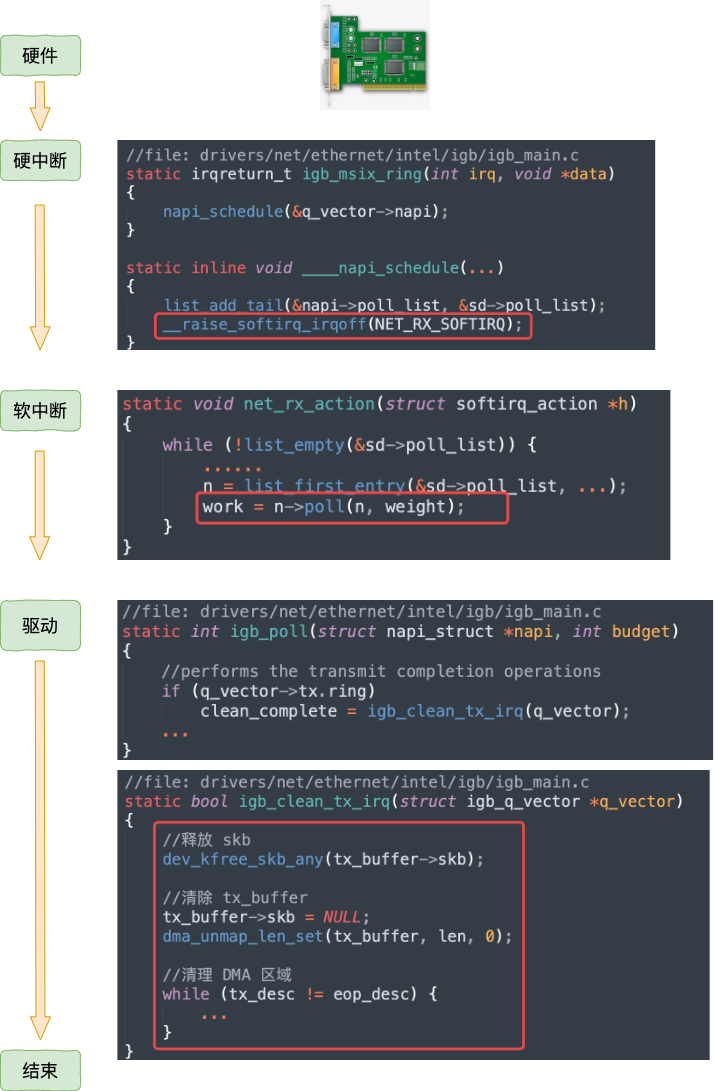
等網(wǎng)絡發(fā)送完畢之后。網(wǎng)卡在發(fā)送完畢的時候,會給 CPU 發(fā)送一個硬中斷來通知 CPU。收到這個硬中斷后會釋放 RingBuffer 中使用的內(nèi)存。
1.2 跨機數(shù)據(jù)接收
當數(shù)據(jù)包到達另外一臺機器的時候,Linux 數(shù)據(jù)包的接收過程開始了。
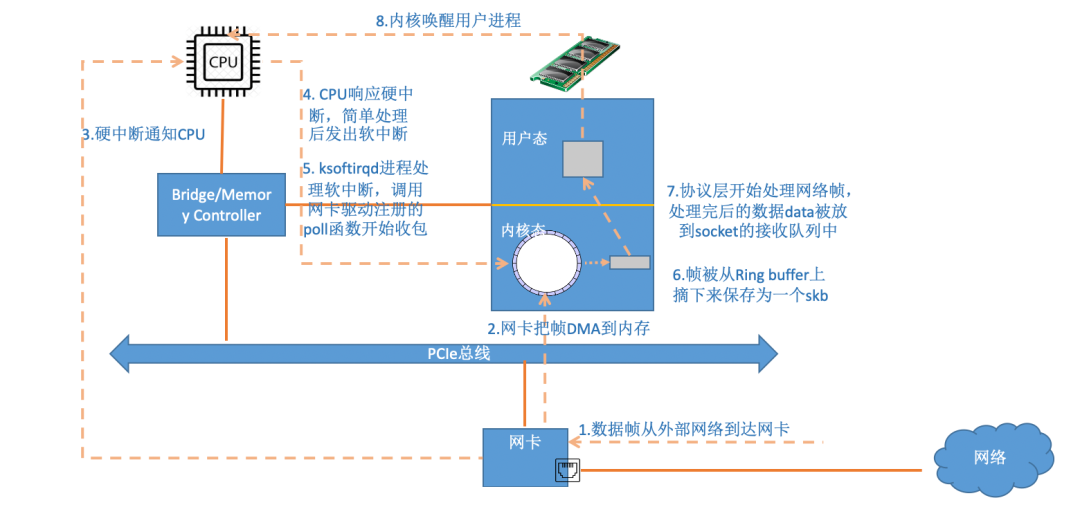
當網(wǎng)卡收到數(shù)據(jù)以后,CPU發(fā)起一個中斷,以通知 CPU 有數(shù)據(jù)到達。當CPU收到中斷請求后,會去調(diào)用網(wǎng)絡驅動注冊的中斷處理函數(shù),觸發(fā)軟中斷。ksoftirqd 檢測到有軟中斷請求到達,開始輪詢收包,收到后交由各級協(xié)議棧處理。當協(xié)議棧處理完并把數(shù)據(jù)放到接收隊列的之后,喚醒用戶進程(假設是阻塞方式)。
我們再同樣從內(nèi)核組件和源碼視角看一遍。
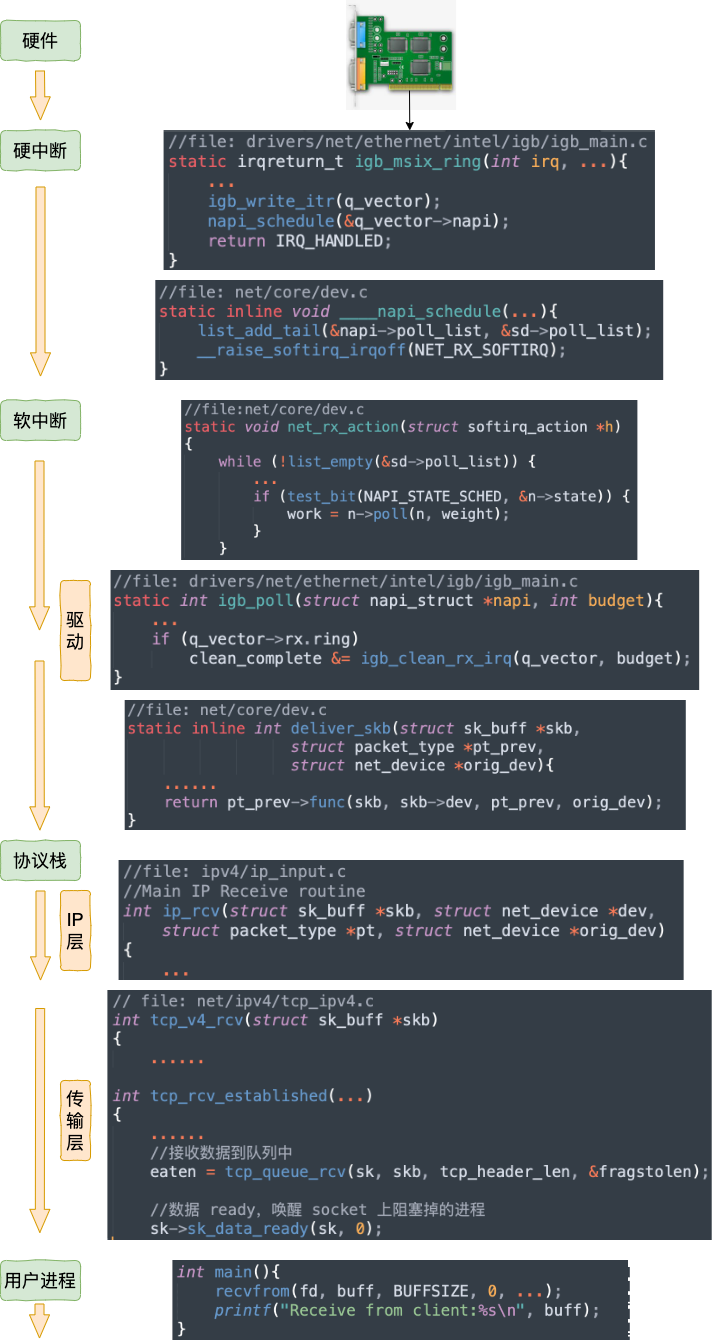
1.3 跨機網(wǎng)絡通信匯總
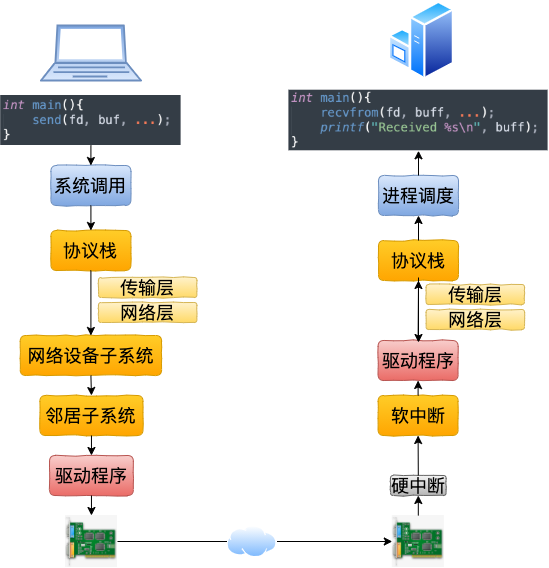
二、本機發(fā)送過程
在第一節(jié)中,我們看到了跨機時整個網(wǎng)絡發(fā)送過程(嫌第一節(jié)流程圖不過癮,想繼續(xù)看源碼了解細節(jié)的同學可以參考 拆解 Linux 網(wǎng)絡包發(fā)送過程) 。
在本機網(wǎng)絡 IO 的過程中,流程會有一些差別。為了突出重點,將不再介紹整體流程,而是只介紹和跨機邏輯不同的地方。有差異的地方總共有兩個,分別是路由和驅動程序。
2.1 網(wǎng)絡層路由
發(fā)送數(shù)據(jù)會進入?yún)f(xié)議棧到網(wǎng)絡層的時候,網(wǎng)絡層入口函數(shù)是 ip_queue_xmit。在網(wǎng)絡層里會進行路由選擇,路由選擇完畢后,再設置一些 IP 頭、進行一些 netfilter 的過濾后,將包交給鄰居子系統(tǒng)。
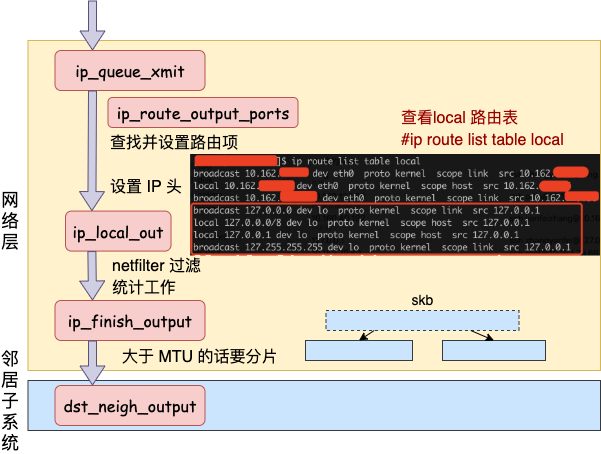
對于本機網(wǎng)絡 IO 來說,特殊之處在于在 local 路由表中就能找到路由項,對應的設備都將使用 loopback 網(wǎng)卡,也就是我們常見的 lo。
我們來詳細看看路由網(wǎng)絡層里這段路由相關工作過程。從網(wǎng)絡層入口函數(shù) ip_queue_xmit 看起。
//file:?net/ipv4/ip_output.c
int?ip_queue_xmit(struct?sk_buff?*skb,?struct?flowi?*fl)
{
?//檢查?socket?中是否有緩存的路由表
?rt?=?(struct?rtable?*)__sk_dst_check(sk,?0);
?if?(rt?==?NULL)?{
??//沒有緩存則展開查找
??//則查找路由項,?并緩存到?socket?中
??rt?=?ip_route_output_ports(...);
??sk_setup_caps(sk,?&rt->dst);
?}
查找路由項的函數(shù)是 ip_route_output_ports,它又依次調(diào)用到 ip_route_output_flow、__ip_route_output_key、fib_lookup。調(diào)用過程省略掉,直接看 fib_lookup 的關鍵代碼。
//file:include/net/ip_fib.h
static?inline?int?fib_lookup(struct?net?*net,?const?struct?flowi4?*flp,
????????struct?fib_result?*res)
{
?struct?fib_table?*table;
?table?=?fib_get_table(net,?RT_TABLE_LOCAL);
?if?(!fib_table_lookup(table,?flp,?res,?FIB_LOOKUP_NOREF))
??return?0;
?table?=?fib_get_table(net,?RT_TABLE_MAIN);
?if?(!fib_table_lookup(table,?flp,?res,?FIB_LOOKUP_NOREF))
??return?0;
?return?-ENETUNREACH;
}
在 fib_lookup 將會對 local 和 main 兩個路由表展開查詢,并且是先查 local 后查詢 main。我們在 Linux 上使用命令名可以查看到這兩個路由表, 這里只看 local 路由表(因為本機網(wǎng)絡 IO 查詢到這個表就終止了)。
#ip?route?list?table?local
local?10.143.x.y?dev?eth0?proto?kernel?scope?host?src?10.143.x.y
local?127.0.0.1?dev?lo?proto?kernel?scope?host?src?127.0.0.1
從上述結果可以看出,對于目的是 127.0.0.1 的路由在 local 路由表中就能夠找到了。fib_lookup 工作完成,返回__ip_route_output_key 繼續(xù)。
//file:?net/ipv4/route.c
struct?rtable?*__ip_route_output_key(struct?net?*net,?struct?flowi4?*fl4)
{
?if?(fib_lookup(net,?fl4,?&res))?{
?}
?if?(res.type?==?RTN_LOCAL)?{
??dev_out?=?net->loopback_dev;
??...
?}
?rth?=?__mkroute_output(&res,?fl4,?orig_oif,?dev_out,?flags);
?return?rth;
}
對于是本機的網(wǎng)絡請求,設備將全部都使用 net->loopback_dev,也就是 lo 虛擬網(wǎng)卡。
接下來的網(wǎng)絡層仍然和跨機網(wǎng)絡 IO 一樣,最終會經(jīng)過 ip_finish_output,最終進入到 鄰居子系統(tǒng)的入口函數(shù) dst_neigh_output 中。
本機網(wǎng)絡 IO 需要進行 IP 分片嗎?因為和正常的網(wǎng)絡層處理過程一樣會經(jīng)過 ip_finish_output 函數(shù)。在這個函數(shù)中,如果 skb 大于 MTU 的話,仍然會進行分片。只不過 lo 的 MTU 比 Ethernet 要大很多。通過 ifconfig 命令就可以查到,普通網(wǎng)卡一般為 1500,而 lo 虛擬接口能有 65535。
在鄰居子系統(tǒng)函數(shù)中經(jīng)過處理,進入到網(wǎng)絡設備子系統(tǒng)(入口函數(shù)是 dev_queue_xmit)。
2.2 網(wǎng)絡設備子系統(tǒng)
網(wǎng)絡設備子系統(tǒng)的入口函數(shù)是 dev_queue_xmit。簡單回憶下之前講述跨機發(fā)送過程的時候,對于真的有隊列的物理設備,在該函數(shù)中進行了一系列復雜的排隊等處理以后,才調(diào)用 dev_hard_start_xmit,從這個函數(shù) 再進入驅動程序來發(fā)送。在這個過程中,甚至還有可能會觸發(fā)軟中斷來進行發(fā)送,流程如圖:
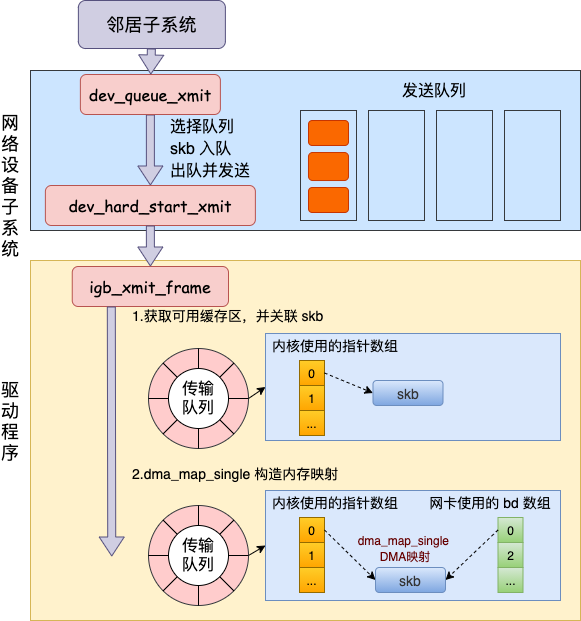
但是對于啟動狀態(tài)的回環(huán)設備來說(q->enqueue 判斷為 false),就簡單多了。沒有隊列的問題,直接進入 dev_hard_start_xmit。接著進入回環(huán)設備的“驅動”里的發(fā)送回調(diào)函數(shù) loopback_xmit,將 skb “發(fā)送”出去。
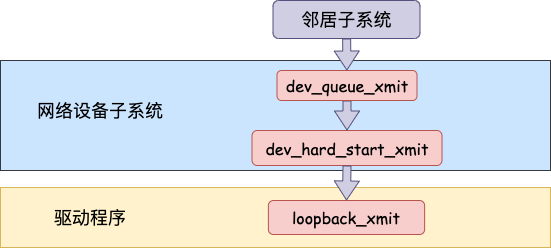
我們來看下詳細的過程,從網(wǎng)絡設備子系統(tǒng)的入口 dev_queue_xmit 看起。
//file:?net/core/dev.c
int?dev_queue_xmit(struct?sk_buff?*skb)
{
?q?=?rcu_dereference_bh(txq->qdisc);
?if?(q->enqueue)?{//回環(huán)設備這里為?false
??rc?=?__dev_xmit_skb(skb,?q,?dev,?txq);
??goto?out;
?}
?//開始回環(huán)設備處理
?if?(dev->flags?&?IFF_UP)?{
??dev_hard_start_xmit(skb,?dev,?txq,?...);
??...
?}
}
在 dev_hard_start_xmit 中還是將調(diào)用設備驅動的操作函數(shù)。
//file:?net/core/dev.c
int?dev_hard_start_xmit(struct?sk_buff?*skb,?struct?net_device?*dev,
???struct?netdev_queue?*txq)
{
?//獲取設備驅動的回調(diào)函數(shù)集合?ops
?const?struct?net_device_ops?*ops?=?dev->netdev_ops;
?//調(diào)用驅動的?ndo_start_xmit?來進行發(fā)送
?rc?=?ops->ndo_start_xmit(skb,?dev);
?...
}
2.3 “驅動”程序
對于真實的 igb 網(wǎng)卡來說,它的驅動代碼都在 drivers/net/ethernet/intel/igb/igb_main.c 文件里。順著這個路子,我找到了 loopback 設備的“驅動”代碼位置:drivers/net/loopback.c。在 drivers/net/loopback.c
//file:drivers/net/loopback.c
static?const?struct?net_device_ops?loopback_ops?=?{
?.ndo_init??????=?loopback_dev_init,
?.ndo_start_xmit=?loopback_xmit,
?.ndo_get_stats64?=?loopback_get_stats64,
};
所以對 dev_hard_start_xmit 調(diào)用實際上執(zhí)行的是 loopback “驅動” 里的 loopback_xmit。為什么我把“驅動”加個引號呢,因為 loopback 是一個純軟件性質(zhì)的虛擬接口,并沒有真正意義上的驅動,它的工作流程大致如圖。
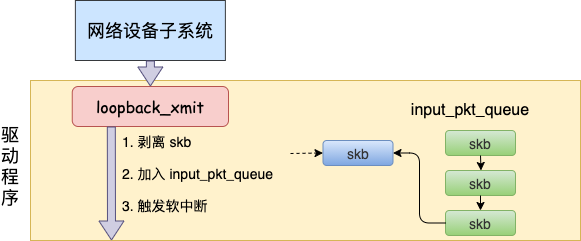
我們再來看詳細的代碼。
//file:drivers/net/loopback.c
static?netdev_tx_t?loopback_xmit(struct?sk_buff?*skb,
?????struct?net_device?*dev)
{
?//剝離掉和原?socket?的聯(lián)系
?skb_orphan(skb);
?//調(diào)用netif_rx
?if?(likely(netif_rx(skb)?==?NET_RX_SUCCESS))?{
?}
}
在 skb_orphan 中先是把 skb 上的 socket 指針去掉了(剝離了出來)。
注意,在本機網(wǎng)絡 IO 發(fā)送的過程中,傳輸層下面的 skb 就不需要釋放了,直接給接收方傳過去就行了。總算是省了一點點開銷。不過可惜傳輸層的 skb 同樣節(jié)約不了,還是得頻繁地申請和釋放。
接著調(diào)用 netif_rx,在該方法中 中最終會執(zhí)行到 enqueue_to_backlog 中(netif_rx -> netif_rx_internal -> enqueue_to_backlog)。
//file:?net/core/dev.c
static?int?enqueue_to_backlog(struct?sk_buff?*skb,?int?cpu,
?????????unsigned?int?*qtail)
{
?sd?=?&per_cpu(softnet_data,?cpu);
?...
?__skb_queue_tail(&sd->input_pkt_queue,?skb);
?...
?____napi_schedule(sd,?&sd->backlog);
在 enqueue_to_backlog 把要發(fā)送的 skb 插入 softnet_data->input_pkt_queue 隊列中并調(diào)用 ____napi_schedule 來觸發(fā)軟中斷。
//file:net/core/dev.c
static?inline?void?____napi_schedule(struct?softnet_data?*sd,
?????????struct?napi_struct?*napi)
{
?list_add_tail(&napi->poll_list,?&sd->poll_list);
?__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
只有觸發(fā)完軟中斷,發(fā)送過程就算是完成了。
三、本機接收過程
在跨機的網(wǎng)絡包的接收過程中,需要經(jīng)過硬中斷,然后才能觸發(fā)軟中斷。而在本機的網(wǎng)絡 IO 過程中,由于并不真的過網(wǎng)卡,所以網(wǎng)卡實際傳輸,硬中斷就都省去了。直接從軟中斷開始,經(jīng)過 process_backlog 后送進協(xié)議棧,大體過程如圖。
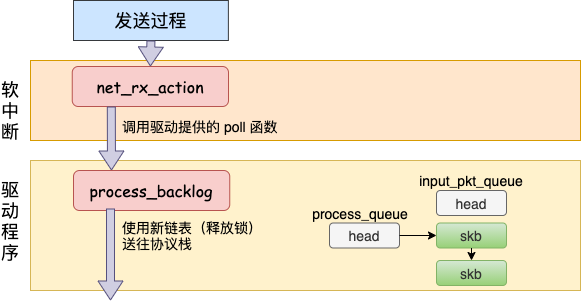
接下來我們再看更詳細一點的過程。
在軟中斷被觸發(fā)以后,會進入到 NET_RX_SOFTIRQ 對應的處理方法 net_rx_action 中(至于細節(jié)參見 圖解Linux網(wǎng)絡包接收過程 一文中的 3.2 小節(jié))。
//file:?net/core/dev.c
static?void?net_rx_action(struct?softirq_action?*h){
?while?(!list_empty(&sd->poll_list))?{
??work?=?n->poll(n,?weight);
?}
}
我們還記得對于 igb 網(wǎng)卡來說,poll 實際調(diào)用的是 igb_poll 函數(shù)。那么 loopback 網(wǎng)卡的 poll 函數(shù)是誰呢?由于poll_list 里面是 struct softnet_data 對象,我們在 net_dev_init 中找到了蛛絲馬跡。
//file:net/core/dev.c
static?int?__init?net_dev_init(void)
{
?for_each_possible_cpu(i)?{
??sd->backlog.poll?=?process_backlog;
?}
}
原來struct softnet_data 默認的 poll 在初始化的時候設置成了 process_backlog 函數(shù),來看看它都干了啥。
static?int?process_backlog(struct?napi_struct?*napi,?int?quota)
{
?while(){
??while?((skb?=?__skb_dequeue(&sd->process_queue)))?{
???__netif_receive_skb(skb);
??}
??//skb_queue_splice_tail_init()函數(shù)用于將鏈表a連接到鏈表b上,
??//形成一個新的鏈表b,并將原來a的頭變成空鏈表。
??qlen?=?skb_queue_len(&sd->input_pkt_queue);
??if?(qlen)
???skb_queue_splice_tail_init(&sd->input_pkt_queue,
?????????&sd->process_queue);
??
?}
}
這次先看對 skb_queue_splice_tail_init 的調(diào)用。源碼就不看了,直接說它的作用是把 sd->input_pkt_queue 里的 skb 鏈到 sd->process_queue 鏈表上去。

然后再看 __skb_dequeue, __skb_dequeue 是從 sd->process_queue 上取下來包來處理。這樣和前面發(fā)送過程的結尾處就對上了。發(fā)送過程是把包放到了 input_pkt_queue 隊列里,接收過程是在從這個隊列里取出 skb。
最后調(diào)用 __netif_receive_skb 將 skb(數(shù)據(jù)) 送往協(xié)議棧。在此之后的調(diào)用過程就和跨機網(wǎng)絡 IO 又一致了。
送往協(xié)議棧的調(diào)用鏈是 __netif_receive_skb => __netif_receive_skb_core => deliver_skb 后 將數(shù)據(jù)包送入到 ip_rcv 中(詳情參見圖解Linux網(wǎng)絡包接收過程 一文中的 3.3 小節(jié))。
網(wǎng)絡再往后依次是傳輸層,最后喚醒用戶進程,這里就不多展開了。
四、本機網(wǎng)絡 IO 總結
我們來總結一下本機網(wǎng)絡 IO 的內(nèi)核執(zhí)行流程。
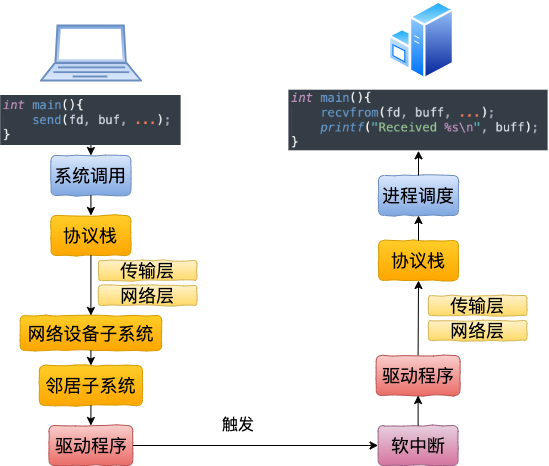
回想下跨機網(wǎng)絡 IO 的流程是
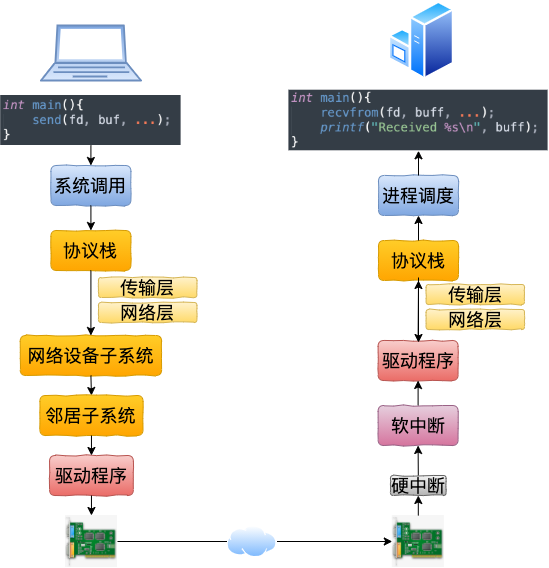
我們現(xiàn)在可以回顧下開篇的三個問題啦。
1)127.0.0.1 本機網(wǎng)絡 IO 需要經(jīng)過網(wǎng)卡嗎?
通過本文的敘述,我們確定地得出結論,不需要經(jīng)過網(wǎng)卡。即使了把網(wǎng)卡拔了本機網(wǎng)絡是否還可以正常使用的。
2)數(shù)據(jù)包在內(nèi)核中是個什么走向,和外網(wǎng)發(fā)送相比流程上有啥差別?
總的來說,本機網(wǎng)絡 IO 和跨機 IO 比較起來,確實是節(jié)約了一些開銷。發(fā)送數(shù)據(jù)不需要進 RingBuffer 的驅動隊列,直接把 skb 傳給接收協(xié)議棧(經(jīng)過軟中斷)。但是在內(nèi)核其它組件上,可是一點都沒少,系統(tǒng)調(diào)用、協(xié)議棧(傳輸層、網(wǎng)絡層等)、網(wǎng)絡設備子系統(tǒng)、鄰居子系統(tǒng)整個走了一個遍。連“驅動”程序都走了(雖然對于回環(huán)設備來說只是一個純軟件的虛擬出來的東東)。所以即使是本機網(wǎng)絡 IO,也別誤以為沒啥開銷。
最后再提一下,業(yè)界有公司基于 ebpf 來加速 istio 架構中 sidecar 代理和本地進程之間的通信。通過引入 BPF,才算是繞開了內(nèi)核協(xié)議棧的開銷,原理如下。
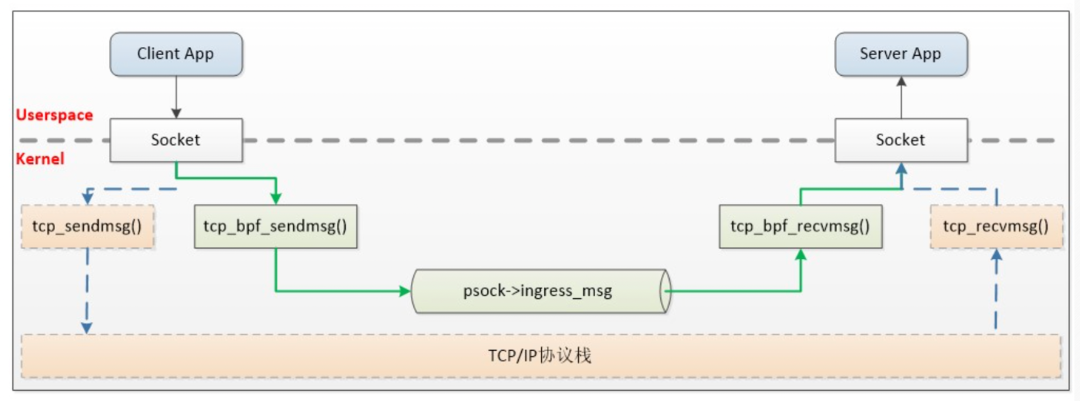
參見:https://cloud.tencent.com/developer/article/1671568