
高逼格的 SQL 寫法:行行比較!!

來源:cnblogs.com/youzhibing/p/15101096.html
環(huán)境準備
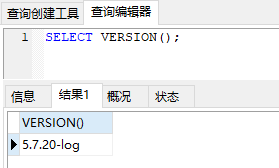
數據庫版本:MySQL 5.7.20-log
建表 SQL
DROP?TABLE?IF?EXISTS?`t_ware_sale_statistics`;
CREATE?TABLE?`t_ware_sale_statistics`?(
??`id`?bigint(20)?NOT?NULL?AUTO_INCREMENT?COMMENT?'主鍵id',
??`business_id`?bigint(20)?NOT?NULL?COMMENT?'業(yè)務機構編碼',
??`ware_inside_code`?bigint(20)?NOT?NULL?COMMENT?'商品自編碼',
??`weight_sale_cnt_day`?double(16,4)?DEFAULT?NULL?COMMENT?'平均日銷量',
??`last_thirty_days_sales`?double(16,4)?DEFAULT?NULL?COMMENT?'最近30天銷量',
??`last_sixty_days_sales`?double(16,4)?DEFAULT?NULL?COMMENT?'最近60天銷量',
??`last_ninety_days_sales`?double(16,4)?DEFAULT?NULL?COMMENT?'最近90天銷量',
??`same_period_sale_qty_thirty`?double(16,4)?DEFAULT?NULL?COMMENT?'去年同期30天銷量',
??`same_period_sale_qty_sixty`?double(16,4)?DEFAULT?NULL?COMMENT?'去年同期60天銷量',
??`same_period_sale_qty_ninety`?double(16,4)?DEFAULT?NULL?COMMENT?'去年同期90天銷量',
??`create_user`?bigint(20)?DEFAULT?NULL?COMMENT?'創(chuàng)建人',
??`create_time`?datetime?NOT?NULL?DEFAULT?CURRENT_TIMESTAMP?COMMENT?'創(chuàng)建時間',
??`modify_user`?bigint(20)?DEFAULT?NULL?COMMENT?'最終修改人',
??`modify_time`?datetime?NOT?NULL?DEFAULT?CURRENT_TIMESTAMP?ON?UPDATE?CURRENT_TIMESTAMP?COMMENT?'最終修改時間',
??`is_delete`?tinyint(2)?DEFAULT?'2'?COMMENT?'是否刪除,1:是,2:否',
??PRIMARY?KEY?(`id`)?USING?BTREE,
??KEY?`idx_business_ware`?(`business_id`,`ware_inside_code`)?USING?BTREE
)?ENGINE=InnoDB?DEFAULT?CHARSET=utf8mb4?ROW_FORMAT=DYNAMIC?COMMENT='商品銷售統(tǒng)計';
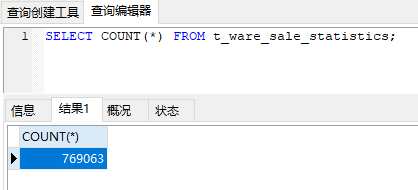
初始化數據
準備了 769063 條數據
需求背景
業(yè)務機構下銷售商品,同個業(yè)務機構可以銷售不同的商品,同個商品可以在不同的業(yè)務機構銷售,也就說:業(yè)務機構與商品是多對多的關系
假設現在有 n 個機構,每個機構下有幾個商品,如何查詢出這幾個門店下各自商品的銷售情況?
具體點,類似如下
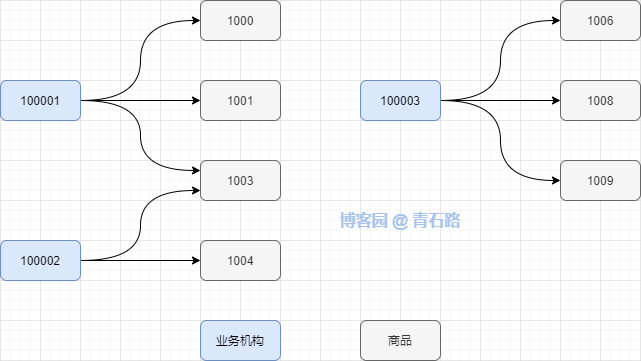
如何查出 100001 下商品 1000、1001、1003 、 100002 下商品 1003、1004 、 100003 下商品 1006、1008、1009 的銷售情況
相當于是雙層列表(業(yè)務機構列表中套商品列表)的查詢;業(yè)務機構列表和商品列表都不是固定的,而是動態(tài)的
那么問題就是:如何查詢多個業(yè)務機構下,某些商品的銷售情況
問題經我一描述,可能更模糊了,大家明白意思了就好!
循環(huán)查詢
這個很容易想到,在代碼層面循環(huán)業(yè)務機構列表,每個業(yè)務機構查一次數據庫,偽代碼如下:

具體的 SQL 類似如下

SQL 能走索引

實現簡單,也好理解,SQL 也能走索引,一切看起來似乎很完美,然而現實是:部門開發(fā)規(guī)范約束,不能循環(huán)查數據庫,哦豁,這種方式只能放棄,另尋其他方式了
OR 拼接
通過 MyBatis 的 動態(tài) SQL 功能,進行 SQL 拼接,類似如下

具體的 SQL 類似如下
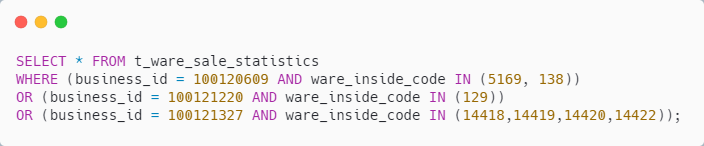
SQL 也能走索引

實現簡單,也好理解,SQL 也能走索引,而且只查詢一次數據庫,貌似可行
唯一可惜的是:有點費 OR,如果業(yè)務機構比較多,那 SQL 會比較長
作為候選人之一吧,我們接著往下看
混查過濾
同樣是利用 Mybatis 的 動態(tài) SQL ,將 business_id 列表拼在一起、 ware_inside_code 拼在一起,類似如下

具體的 SQL 類似如下

SQL 也能走索引

實現簡單,也好理解,SQL 也能走索引,而且只查詢一次數據庫,似乎可行
但是:查出來的結果集大于等于我們想要的結果集,你品,你細品!
所以還需要對查出來的結果集進行一次過濾,過濾出我們想要的結果集
姑且也作為候選人之一吧,我們繼續(xù)往下看
行行比較
SQL-92 中加入了行與行比較的功能,這樣一來,比較謂詞 = 、< 、> 和 IN 謂詞的參數就不再只是標量值了,還可以是值列表了
當然,還是得用到 Mybatis 的 動態(tài) SQL ,類似如下

具體的 SQL 類似如下

SQL 同樣能走索引

只是:有點不好理解,因為我們平時這么用的少,所以這種寫法看起來很陌生
另外,行行比較是 SQL 規(guī)范,不是某個關系型數據庫的規(guī)范,也就說關系型數據庫都應該支持這種寫法總結
1、最后選擇了 行行比較 這種方式來實現了需求
別問我為什么,問就是逼格高!
2、某一個需求的實現往往有很多種方式,我們需要結合業(yè)務以及各種約束綜合考慮,選擇最合適的那個
3、行行比較是 SQL-92 中引入的,SQL-92 是 1992 年制定的規(guī)范
行行比較不是新特性,而是很早就存在的基礎功能!
參考
《SQL進階教程》
神奇的 SQL 之 MySQL 執(zhí)行計劃 → EXPLAIN,讓我們了解 SQL 的執(zhí)行過程!
神奇的 SQL 之性能優(yōu)化 → 讓 SQL 飛起來
神奇的 SQL 之擦肩而過 → 真的用到索引了嗎
精彩推薦: