
高并發(fā)場(chǎng)景下 disk io 引發(fā)的高時(shí)延問(wèn)題
該系統(tǒng)屬于長(zhǎng)連接消息推送業(yè)務(wù),某節(jié)假日推送消息的流量突增幾倍,瞬時(shí)出現(xiàn)比平日多出幾倍的消息量等待下推。
事后,發(fā)現(xiàn)生產(chǎn)消息的業(yè)務(wù)服務(wù)端因?yàn)槟?bug,把大量消息堆積在內(nèi)存里,在一段時(shí)間后,突發(fā)性的發(fā)送大量消息到推送系統(tǒng)。但由于流量保護(hù)器的上限較高,當(dāng)前未觸發(fā)熔斷和限流,所以消息依然在流轉(zhuǎn)。
消息系統(tǒng)不能簡(jiǎn)單地進(jìn)行削峰填谷式的排隊(duì)處理,因?yàn)楹苋菀自斐上⒌暮臅r(shí)長(zhǎng)尾,所以在不觸發(fā)流量保護(hù)器的前提下,需要進(jìn)行的并發(fā)并行地去流轉(zhuǎn)消息。
下圖是我司長(zhǎng)連接消息推送系統(tǒng)的簡(jiǎn)單架構(gòu)圖,問(wèn)題出在下游的消息生產(chǎn)方業(yè)務(wù)端。
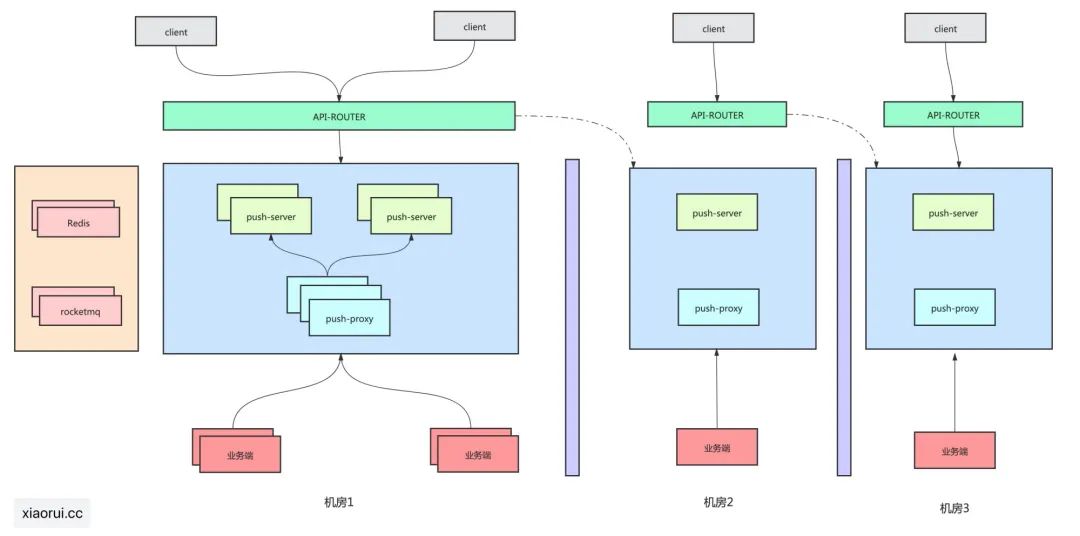
其實(shí)更重要的原因是前些日子公司做成本優(yōu)化,把一個(gè)可用區(qū)里的一波機(jī)器從物理機(jī)遷移到阿里云內(nèi),機(jī)器的配置也做了閹割。突然想起曹春暉大佬的一句話:
沒(méi)錢做優(yōu)化,有錢加機(jī)器。
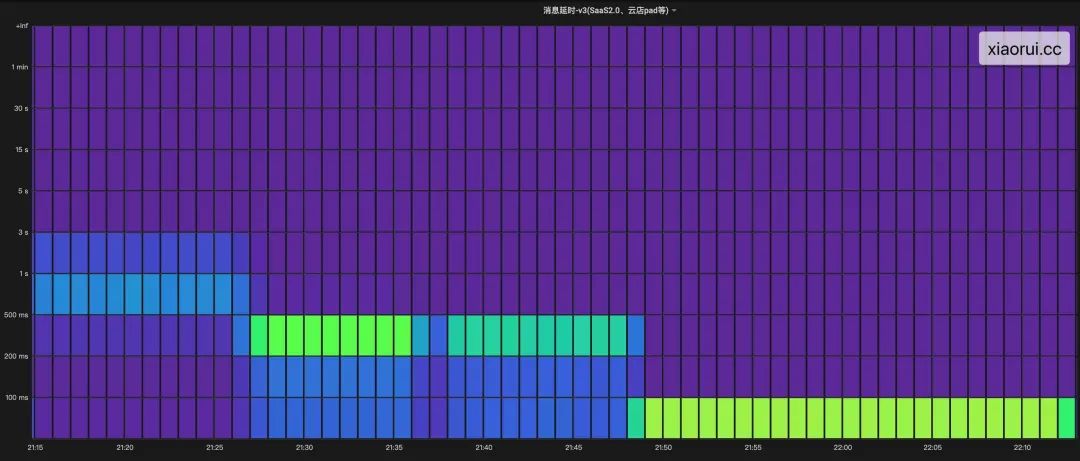
這樣兩個(gè)問(wèn)題加起來(lái),導(dǎo)致消息時(shí)延從 100ms 干到 3s 左右,通過(guò)監(jiān)控看到高時(shí)延問(wèn)題持續(xù) 10 來(lái)分鐘。
分析問(wèn)題
造成消息推送的時(shí)延飆高,通常來(lái)說(shuō)有幾種情況,要么 cpu 負(fù)載高?要么 redis 時(shí)延高?要么消費(fèi)rocketmq 慢?或者哪個(gè)關(guān)鍵函數(shù)處理慢 ?
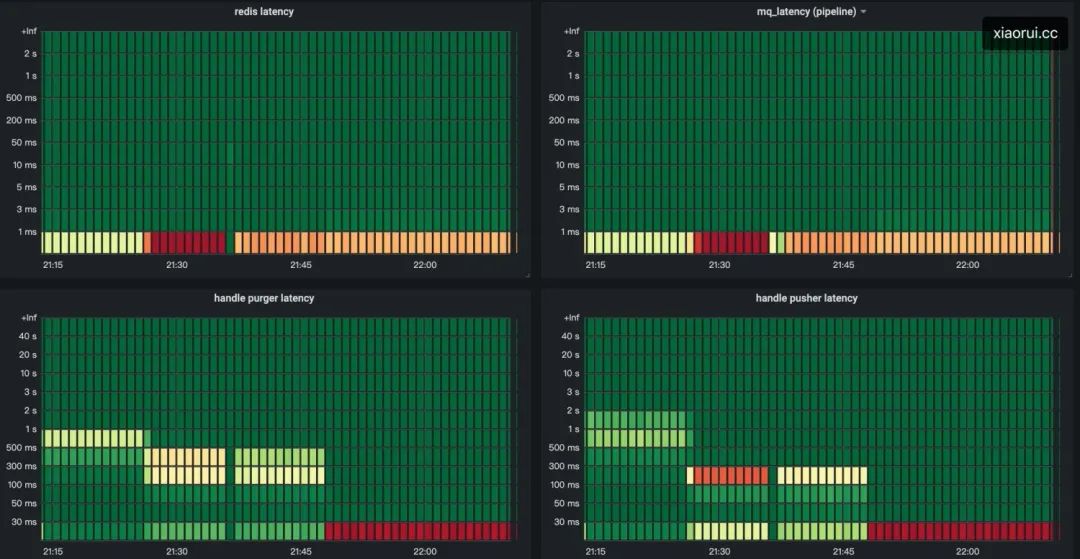
通過(guò)監(jiān)控圖表得知,load 正常,且網(wǎng)絡(luò) io 方面都不慢,但兩個(gè)關(guān)鍵函數(shù)都發(fā)生了處理延遲的現(xiàn)象,這兩個(gè)函數(shù)內(nèi)除處理 redis 和 mq 的網(wǎng)絡(luò) io 操作外,基本是純業(yè)務(wù)組合的邏輯,講道理不會(huì)慢成這個(gè)德行。
詢問(wèn)基礎(chǔ)運(yùn)維的同學(xué)得知,當(dāng)時(shí)該幾個(gè)主機(jī)出現(xiàn)了磁盤(pán) iops 劇烈抖動(dòng), iowait 也隨之飆高。
但問(wèn)題來(lái)了,大家都知道通常來(lái)說(shuō) Linux 下的讀寫(xiě)都有使用 buffer io,寫(xiě)數(shù)據(jù)是先寫(xiě)到 page buffer 里,然后由內(nèi)核的 kworker/flush 線程將 dirty pages 刷入磁盤(pán),但當(dāng)臟寫(xiě)率超過(guò)閾值 dirty_ratio 時(shí),業(yè)務(wù)中的 write 會(huì)被堵塞住,被動(dòng)觸發(fā)進(jìn)行同步刷盤(pán)。
推送系統(tǒng)的日志已經(jīng)是 INFO 級(jí)別了,雖然日志經(jīng)過(guò)特殊編碼,空間看似很小,但消息的流程依舊復(fù)雜,不能不記錄,每次扯皮的時(shí)候都依賴這些鏈路日志來(lái)甩鍋。
阿里云主機(jī)普通云盤(pán)的 io 性能差強(qiáng)人意,以前在物理機(jī)部署時(shí),真沒(méi)出現(xiàn)這問(wèn)題。??
解決思路
通過(guò)監(jiān)控的趨勢(shì)可分析出,隨著消息的突增造成的抖動(dòng),我們只需要解決抖動(dòng)就好了。上面有說(shuō),雖然是 buffer io 寫(xiě)日志,但隨著大量臟數(shù)據(jù)的產(chǎn)生,來(lái)不及刷盤(pán)還是會(huì)阻塞 write 調(diào)用的。
解決方法很簡(jiǎn)單,異步寫(xiě)不就行了!!!
-
實(shí)例化一個(gè) ringbuffer 結(jié)構(gòu),該 ringbuffer 的本質(zhì)就是一個(gè)環(huán)形的 []byte數(shù)組,可使用 Lock Free 提高讀寫(xiě)性能; -
為了避免 OOM, 需要限定最大的字節(jié)數(shù);為了調(diào)和空間利用率及性能,支持?jǐn)U縮容;縮容不要太頻繁,可設(shè)定一個(gè)空閑時(shí)間; -
抽象 log 的寫(xiě)接口,把待寫(xiě)入的數(shù)據(jù)塞入到ringbuffer里; -
啟動(dòng)一個(gè)協(xié)程去消費(fèi) ringbuffer 的數(shù)據(jù),寫(xiě)入到日志文件里; -
當(dāng) ringbuffer 為空時(shí),進(jìn)行休眠百個(gè)毫秒; -
當(dāng) ringbuffer 滿了時(shí),直接覆蓋寫(xiě)入。
這個(gè)靠譜么?我以前做分布式行情推送系統(tǒng)也是異步寫(xiě)日志,據(jù)我所知,像 WhatsApp、騰訊 QQ 和廣發(fā)證券也是異步寫(xiě)日志。對(duì)于低延遲的服務(wù)來(lái)說(shuō),disk io 造成的時(shí)延也是很恐怖的。
覆蓋日志,被覆蓋的日志呢?異步寫(xiě)日志,那 Crash 了呢?首先線上我們會(huì)預(yù)設(shè)最大 ringbuffer 為 200MB,200MB 足夠支撐長(zhǎng)時(shí)間的日志的緩沖。如果緩沖區(qū)滿了,說(shuō)明這期間并發(fā)量著實(shí)太大,覆蓋就覆蓋了,畢竟系統(tǒng)穩(wěn)定性和保留日志,你要哪個(gè)?
Crash 造成異步日志丟失?針對(duì)日志做個(gè) metrics,超過(guò)一定的閾值才開(kāi)啟異步日志。但我采用的是跟廣發(fā)證券一樣的策略,不管不顧,丟了就丟了。如果正常關(guān)閉,退出前可將阻塞日志緩沖刷新完畢。如果 Crash 情況,丟了就丟了,因?yàn)?golang 的 panic 會(huì)打印到 stderr。
另外 Golang 的垃圾回收器 GC 對(duì)于 ringbuffer 這類整塊 []byte 結(jié)構(gòu)來(lái)說(shuō),掃描很是友好。Ringbuffer 開(kāi)到 1G 進(jìn)行測(cè)試,GC 的 Latency 指標(biāo)趨勢(shì)無(wú)異常。
至于異步日志的 golang 代碼,我暫時(shí)不分享給大家了,不是因?yàn)槎鄵搁T(mén),而是因?yàn)楣緝?nèi)部的 log 庫(kù)耦合了一些東西,真心懶得抽離,但異步日志的實(shí)現(xiàn)思路就是這么一回事。
結(jié)論
如有全量詳細(xì)日志的打印需求,建議分兩組 ringbuffer 緩沖區(qū),一個(gè)用作 debug 輸出,一個(gè)用作其他 level 的輸出,好處在于互不影響。還有就是做好緩沖區(qū)的監(jiān)控。
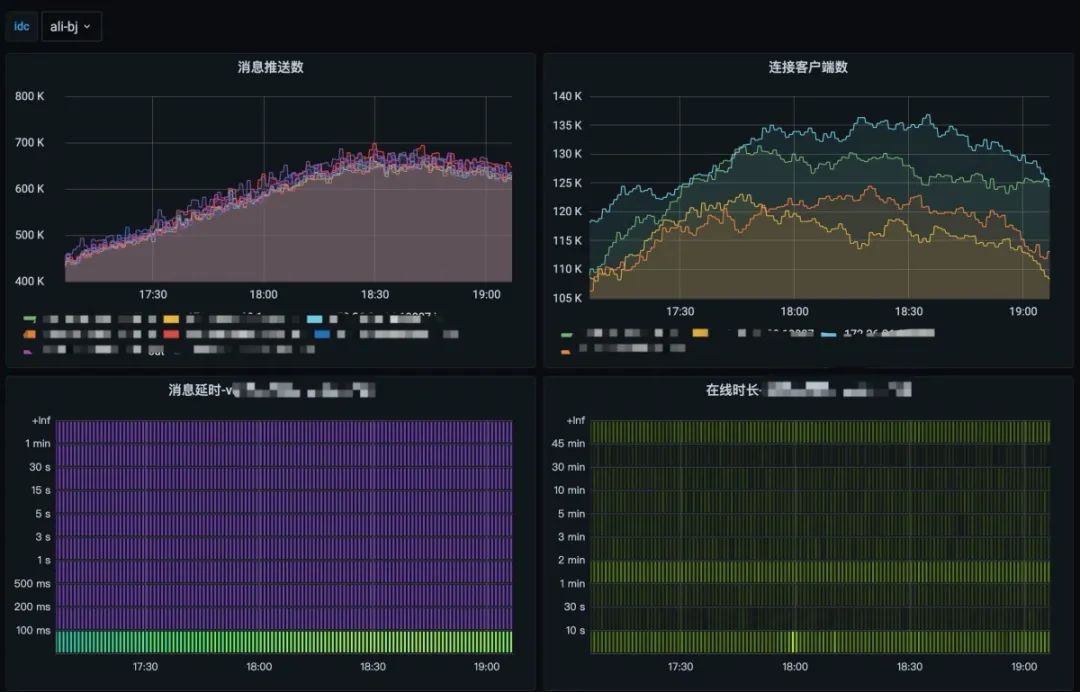
下面是我們集群中的北京阿里云可用區(qū)集群,高峰期消息的推送量不低,但消息的延遲穩(wěn)定在 100ms 以內(nèi)。
讓技術(shù)也有溫度!關(guān)注我,一起成長(zhǎng)~
資料分享,關(guān)注公眾號(hào)回復(fù)指令:
-
回復(fù)【加群】,和大佬們一起成長(zhǎng)。 -
回復(fù)【000】,下載一線大廠簡(jiǎn)歷模板。 -
回復(fù)【001】, 送你 Go 開(kāi)源電子書(shū)。