
Hive|如何避免數(shù)據(jù)傾斜

1. hive中桶的概述
對(duì)于每一個(gè)表(table)或者分區(qū), Hive可以進(jìn)一步組織成桶,也就是說桶是更為細(xì)粒度的數(shù)據(jù)范圍劃分。Hive也是 針對(duì)某一列進(jìn)行桶的組織。Hive采用對(duì)列值哈希,然后除以桶的個(gè)數(shù)求余的方式?jīng)Q定該條記錄存放在哪個(gè)桶當(dāng)中。
把表(或者分區(qū))組織成桶(Bucket)有兩個(gè)理由:
(1)獲得更高的查詢處理效率。
桶為表加上了額外的結(jié)構(gòu),Hive 在處理有些查詢時(shí)能利用這個(gè)結(jié)構(gòu)。具體而言,連接兩個(gè)在(包含連接列的)相同列上劃分了桶的表,可以使用 Map 端連接 (Map-side join)高效的實(shí)現(xiàn)。比如JOIN操作。對(duì)于JOIN操作兩個(gè)表有一個(gè)相同的列,如果對(duì)這兩個(gè)表都進(jìn)行了桶操作。那么將保存相同列值的桶進(jìn)行JOIN操作就可以,可以大大較少JOIN的數(shù)據(jù)量。
(2)使取樣(sampling)更高效。
在處理大規(guī)模數(shù)據(jù)集時(shí),在開發(fā)和修改查詢的階段,如果能在數(shù)據(jù)集的一小部分?jǐn)?shù)據(jù)上試運(yùn)行查詢,會(huì)帶來很多方便。
創(chuàng)建帶桶的 table
create?table?bucketed_user(id?int,name?string)?clustered?by?(id)?sorted?by(name)?into?4?buckets?row?format?delimited?fields?terminated?by?'\t'?stored?as?textfile;?
首先,我們來看如何告訴Hive—個(gè)表應(yīng)該被劃分成桶。我們使用CLUSTERED BY 子句來指定劃分桶所用的列和要?jiǎng)澐值耐暗膫€(gè)數(shù):
CREATE?TABLE?bucketed_user?(id?INT)?name?STRING)?
CLUSTERED?BY?(id)?INTO?4?BUCKETS;?
在這里,我們使用用戶ID來確定如何劃分桶(Hive使用對(duì)值進(jìn)行哈希并將結(jié)果除 以桶的個(gè)數(shù)取余數(shù)。這樣,任何一桶里都會(huì)有一個(gè)隨機(jī)的用戶集合(PS:其實(shí)也能說是隨機(jī),不是嗎?)。
對(duì)于map端連接的情況,兩個(gè)表以相同方式劃分桶。處理左邊表內(nèi)某個(gè)桶的 mapper知道右邊表內(nèi)相匹配的行在對(duì)應(yīng)的桶內(nèi)。因此,mapper只需要獲取那個(gè)桶 (這只是右邊表內(nèi)存儲(chǔ)數(shù)據(jù)的一小部分)即可進(jìn)行連接。這一優(yōu)化方法并不一定要求 兩個(gè)表必須桶的個(gè)數(shù)相同,兩個(gè)表的桶個(gè)數(shù)是倍數(shù)關(guān)系也可以。用HiveQL對(duì)兩個(gè)劃分了桶的表進(jìn)行連接,可參見“map連接”部分(P400)。
桶中的數(shù)據(jù)可以根據(jù)一個(gè)或多個(gè)列另外進(jìn)行排序。由于這樣對(duì)每個(gè)桶的連接變成了高效的歸并排序(merge-sort), 因此可以進(jìn)一步提升map端連接的效率。以下語法聲明一個(gè)表使其使用排序桶:
CREATE?TABLE?bucketed_users?(id?INT,?name?STRING)?
CLUSTERED?BY?(id)?SORTED?BY?(id?ASC)?INTO?4?BUCKETS;?
我們?nèi)绾伪WC表中的數(shù)據(jù)都劃分成桶了呢?把在Hive外生成的數(shù)據(jù)加載到劃分成 桶的表中,當(dāng)然是可以的。其實(shí)讓Hive來劃分桶更容易。這一操作通常針對(duì)已有的表。
Hive并不檢查數(shù)據(jù)文件中的桶是否和表定義中的桶一致(無論是對(duì)于桶 的數(shù)量或用于劃分桶的列)。如果兩者不匹配,在査詢時(shí)可能會(huì)碰到錯(cuò) 誤或未定義的結(jié)果。因此,建議讓Hive來進(jìn)行劃分桶的操作。
2.hive中join優(yōu)化
mapside join
方法一:
select?/*+?MAPJOIN(time_dim)?*/?count(*)?from
store_sales?join?time_dim?on?(ss_sold_time_sk?=?t_time_sk)
方法二:這個(gè)可以由hive自動(dòng)進(jìn)行map端join
set?hive.auto.convert.join=true;
select?count(*)?from
store_sales?join?time_dim?on?(ss_sold_time_sk?=?t_time_sk)
執(zhí)行下面這段代碼將會(huì)產(chǎn)生兩個(gè)map-only方法:
select?/*+?MAPJOIN(time_dim,?date_dim)?*/?count(*)?from
store_sales
join?time_dim?on?(ss_sold_time_sk?=?t_time_sk)?
join?date_dim?on?(ss_sold_date_sk?=?d_date_sk)
where?t_hour?=?8?and?d_year?=?2002
設(shè)置下面兩個(gè)屬性hive將會(huì)進(jìn)行自動(dòng)執(zhí)行上述過程,第一個(gè)屬性默認(rèn)為true,第二個(gè)屬性是設(shè)置map端join適合讀取內(nèi)存文件的大小。
set?hive.auto.convert.join.noconditionaltask?=?true;
set?hive.auto.convert.join.noconditionaltask.size?=?10000000;
Sort-Merge-Bucket (SMB) joins可以被轉(zhuǎn)化為SMB map joins。
我們只需要設(shè)置一下幾個(gè)參數(shù)即可:
set?hive.auto.convert.sortmerge.join=true;
set?hive.optimize.bucketmapjoin?=?true;
set?hive.optimize.bucketmapjoin.sortedmerge?=?true;
已設(shè)置大表選擇的策略
使用下面屬性:
set?hive.auto.convert.sortmerge.join.bigtable.selection.policy=?org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ;
幾種策略設(shè)置
org.apache.hadoop.hive.ql.optimizer.AvgPartitionSizeBasedBigTableSelectorForAutoSMJ?(default)
org.apache.hadoop.hive.ql.optimizer.LeftmostBigTableSelectorForAutoSMJ
org.apache.hadoop.hive.ql.optimizer.TableSizeBasedBigTableSelectorForAutoSMJ
詳細(xì)請(qǐng)參考一下連接:hive中進(jìn)行連接方案詳解(https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins)
3,數(shù)據(jù)傾斜
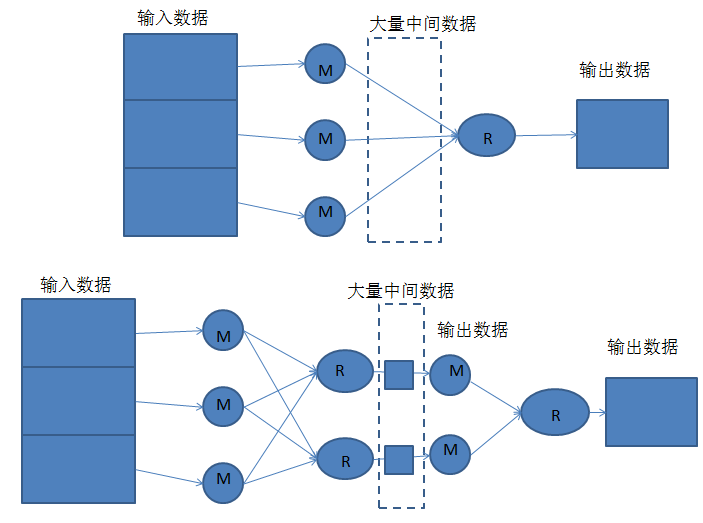
Hive的執(zhí)行是分階段的,map處理數(shù)據(jù)量的差異取決于上一個(gè)stage的reduce輸出,所以如何將數(shù)據(jù)均勻的分配到各個(gè)reduce中,就是解決數(shù)據(jù)傾斜的根本所在。
操作
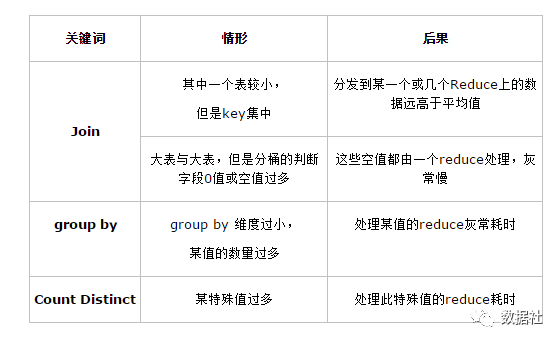
原因
1,數(shù)據(jù)在節(jié)點(diǎn)上分布不均
2,key分布不均(key中存在個(gè)別值數(shù)據(jù)量比較大,比如NULL,那么join時(shí)就會(huì)容易發(fā)生數(shù)據(jù)傾斜)
3,count(disctinct key),在數(shù)據(jù)兩比較大的時(shí)候容易發(fā)生數(shù)據(jù)傾斜,因?yàn)閏ount(distinct)是按照group by字段進(jìn)行分組的
4,group by的使用容易造成數(shù)據(jù)傾斜
5,業(yè)務(wù)數(shù)據(jù)本身的特性
6,建表時(shí)考慮不周
7,某些SQL語句本身就有數(shù)據(jù)傾斜
表現(xiàn)
任務(wù)進(jìn)度長(zhǎng)時(shí)間維持在99%左右,查看任務(wù)監(jiān)控頁面發(fā)現(xiàn)只有少量reduce任務(wù)未完成。因?yàn)槠涮幚淼臄?shù)據(jù)量和其他reduce差異過大。單一reduce的記錄數(shù)與平均記錄數(shù)差異過大,通常可能達(dá)到3倍甚至更多。最長(zhǎng)時(shí)長(zhǎng)遠(yuǎn)大于平均時(shí)長(zhǎng)。
4,數(shù)據(jù)傾斜的解決方案
參數(shù)調(diào)節(jié)
set?hive.map.aggr=true;
Map?端部分聚合,相當(dāng)于Combiner
set?hive.groupby.skewindata=true;
有數(shù)據(jù)傾斜的時(shí)候進(jìn)行負(fù)載均衡,當(dāng)選項(xiàng)設(shè)定為 true,生成的查詢計(jì)劃會(huì)有兩個(gè) MR Job。第一個(gè) MR Job 中,Map 的輸出結(jié)果集合會(huì)隨機(jī)分布到 Reduce 中,每個(gè) Reduce 做部分聚合操作,并輸出結(jié)果,這樣處理的結(jié)果是相同的 Group By Key 有可能被分發(fā)到不同的 Reduce 中,從而達(dá)到負(fù)載均衡的目的;第二個(gè) MR Job 再根據(jù)預(yù)處理的數(shù)據(jù)結(jié)果按照 Group By Key 分布到 Reduce 中(這個(gè)過程可以保證相同的 Group By Key 被分布到同一個(gè) Reduce 中),最后完成最終的聚合操作。
SQL語句調(diào)節(jié):
如何Join 關(guān)于驅(qū)動(dòng)表的選取,選用join key分布最均勻的表作為驅(qū)動(dòng)表 做好列裁剪和filter操作,以達(dá)到兩表做join的時(shí)候,數(shù)據(jù)量相對(duì)變小的效果。 大小表Join 使用map join讓小的維度表(1000條以下的記錄條數(shù)) 先進(jìn)內(nèi)存。在map端完成reduce. 大表Join大表 把空值的key變成一個(gè)字符串加上隨機(jī)數(shù),把傾斜的數(shù)據(jù)分到不同的reduce上,由于null值關(guān)聯(lián)不上,處理后并不影響最終結(jié)果。 count distinct大量相同特殊值 容易傾斜,當(dāng)xx字段存在大量的某個(gè)值時(shí),NULL或者空的記錄 解決思路 將特定的值,進(jìn)行特定的處理。比如是null,過濾掉,where case 特定方式轉(zhuǎn)換特定的值,使得這些值不一樣,同時(shí)這些值不影響分析。 group by維度過小:Group by在Map端進(jìn)行部分?jǐn)?shù)據(jù)合并
set?hive.map.aggr?;?-->?是否在Map端進(jìn)行數(shù)據(jù)聚合,默認(rèn)設(shè)置為true;
set?hive.groupby.mapaggr.checkinterval ;?-->?在Map端進(jìn)行聚合操作的條目數(shù)。
進(jìn)行負(fù)載均衡負(fù)載均衡
set?hive.groupby.skewindata?;
默認(rèn)值是false,需要設(shè)置成true?;
當(dāng)設(shè)置為true時(shí),會(huì)變成兩個(gè)MapReduce?;
第一個(gè)MR JOb中,map的輸出結(jié)果會(huì)隨機(jī)分布到Reduce中,每個(gè)Reduce做部分聚合操作,并輸出結(jié)果,這樣出來的結(jié)果相同的Group By Key有可能被分發(fā)到不同的Reduce中,從而達(dá)到輔助均衡目的。
第二個(gè)MR JOb,會(huì)根據(jù)預(yù)處理數(shù)據(jù)結(jié)果按照key分布到Reduce中,最終完成聚合操作。
5,典型的業(yè)務(wù)場(chǎng)景
空值產(chǎn)生的數(shù)據(jù)傾斜
場(chǎng)景:如日志中,常會(huì)有信息丟失的問題,比如日志中的 user_id,如果取其中的 user_id 和 用戶表中的user_id 關(guān)聯(lián),會(huì)碰到數(shù)據(jù)傾斜的問題。
解決方法1:user_id為空的不參與關(guān)聯(lián)
select?*?from?log?a
??join?users?b
??on?a.user_id?is?not?null
??and?a.user_id?=?b.user_id
union?all
select?*?from?log?a
??where?a.user_id?is?null;
解決方法2 :賦與空值分新的key值
select?*
??from?log?a
??left?outer?join?users?b
??on?case?when?a.user_id?is?null?then?concat(‘hive’,rand()?)?else?a.user_id?end?=?b.user_id;
結(jié)論:方法2比方法1效率更好,不但io少了,而且作業(yè)數(shù)也少了。解決方法1中 log讀取兩次,jobs是2。解決方法2 job數(shù)是1 。這個(gè)優(yōu)化適合無效 id (比如 -99 , ’’, null 等) 產(chǎn)生的傾斜問題。把空值的 key 變成一個(gè)字符串加上隨機(jī)數(shù),就能把傾斜的數(shù)據(jù)分到不同的reduce上 ,解決數(shù)據(jù)傾斜問題。
不同數(shù)據(jù)類型關(guān)聯(lián)產(chǎn)生數(shù)據(jù)傾斜
場(chǎng)景:用戶表中user_id字段為int,log表中user_id字段既有string類型也有int類型。當(dāng)按照user_id進(jìn)行兩個(gè)表的Join操作時(shí),默認(rèn)的Hash操作會(huì)按int型的id來進(jìn)行分配,這樣會(huì)導(dǎo)致所有string類型id的記錄都分配到一個(gè)Reducer中。
解決方法:把數(shù)字類型轉(zhuǎn)換成字符串類型
select?*?from?users?a
??left?outer?join?logs?b
??on?a.usr_id?=?cast(b.user_id?as?string)
小表不小不大,怎么用 map join 解決傾斜問題
使用 map join解決小表(記錄數(shù)少)關(guān)聯(lián)大表的數(shù)據(jù)傾斜問題,這個(gè)方法使用的頻率非常高,但如果小表很大,大到map join會(huì)出現(xiàn)bug或異常,這時(shí)就需要特別的處理。以下例子:
select?*?from?log?a
??left?outer?join?users?b
??on?a.user_id?=?b.user_id;
users 表有 600w+ 的記錄,把 users 分發(fā)到所有的 map 上也是個(gè)不小的開銷,而且 map join 不支持這么大的小表。如果用普通的 join,又會(huì)碰到數(shù)據(jù)傾斜的問題。
解決方法:
select?/*+mapjoin(x)*/*?from?log?a
??left?outer?join?(
????select??/*+mapjoin(c)*/d.*
??????from?(?select?distinct?user_id?from?log?)?c
??????join?users?d
??????on?c.user_id?=?d.user_id
????)?x
??on?a.user_id?=?b.user_id;
假如,log里user_id有上百萬個(gè),這就又回到原來map join問題。所幸,每日的會(huì)員uv不會(huì)太多,有交易的會(huì)員不會(huì)太多,有點(diǎn)擊的會(huì)員不會(huì)太多,有傭金的會(huì)員不會(huì)太多等等。所以這個(gè)方法能解決很多場(chǎng)景下的數(shù)據(jù)傾斜問題。
6,數(shù)據(jù)傾斜總結(jié)
使map的輸出數(shù)據(jù)更均勻的分布到reduce中去,是我們的最終目標(biāo)。由于Hash算法的局限性,按key Hash會(huì)或多或少的造成數(shù)據(jù)傾斜。大量經(jīng)驗(yàn)表明數(shù)據(jù)傾斜的原因是人為的建表疏忽或業(yè)務(wù)邏輯可以規(guī)避的。在此給出較為通用的步驟:
1、采樣log表,哪些user_id比較傾斜,得到一個(gè)結(jié)果表tmp1。由于對(duì)計(jì)算框架來說,所有的數(shù)據(jù)過來,他都是不知道數(shù)據(jù)分布情況的,所以采樣是并不可少的。
2、數(shù)據(jù)的分布符合社會(huì)學(xué)統(tǒng)計(jì)規(guī)則,貧富不均。傾斜的key不會(huì)太多,就像一個(gè)社會(huì)的富人不多,奇特的人不多一樣。所以tmp1記錄數(shù)會(huì)很少。把tmp1和users做map join生成tmp2,把tmp2讀到distribute file cache。這是一個(gè)map過程。
3、map讀入users和log,假如記錄來自log,則檢查user_id是否在tmp2里,如果是,輸出到本地文件a,否則生成的key,value對(duì),假如記錄來自member,生成的key,value對(duì),進(jìn)入reduce階段。
4、最終把a(bǔ)文件,把Stage3 reduce階段輸出的文件合并起寫到hdfs。
如果確認(rèn)業(yè)務(wù)需要這樣傾斜的邏輯,考慮以下的優(yōu)化方案:
1、對(duì)于join,在判斷小表不大于1G的情況下,使用map join
2、對(duì)于group by或distinct,設(shè)定
hive.groupby.skewindata=true
4.中間件等
更多信息請(qǐng)關(guān)注公眾號(hào):「軟件老王」,關(guān)注不迷路,軟件老王和他的IT朋友們,分享一些他們的技術(shù)見解和生活故事。