
Spark/Flink/CarbonData技術(shù)實(shí)踐最佳案例解析
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




當(dāng)前無論是傳統(tǒng)企業(yè)還是互聯(lián)網(wǎng)公司對(duì)大數(shù)據(jù)實(shí)時(shí)分析和處理的要求越來越高,數(shù)據(jù)越實(shí)時(shí)價(jià)值越大,面向毫秒~ 秒級(jí)的實(shí)時(shí)大數(shù)據(jù)計(jì)算場(chǎng)景,Spark 和 Flink 各有所長(zhǎng)。CarbonData 是一種高性能大數(shù)據(jù)存儲(chǔ)方案,已在 20+ 企業(yè)生產(chǎn)環(huán)境上部署應(yīng)用,其中最大的單一集群數(shù)據(jù)規(guī)模達(dá)到幾萬億。
Spark Structured Streaming 特性介紹
作為 Spark Structured Streaming 最核心的開發(fā)人員、Databricks 工程師,Tathagata Das(以下簡(jiǎn)稱“TD”)在開場(chǎng)演講中介紹了 Structured Streaming 的基本概念,及其在存儲(chǔ)、自動(dòng)流化、容錯(cuò)、性能等方面的特性,在事件時(shí)間的處理機(jī)制,最后帶來了一些實(shí)際應(yīng)用場(chǎng)景。
首先,TD 對(duì)流處理所面對(duì)的問題和概念做了清晰的講解。TD 提到,因?yàn)榱魈幚砭哂腥缦嘛@著的復(fù)雜性特征,所以很難建立非常健壯的處理過程:
一是數(shù)據(jù)有各種不同格式(Jason、Avro、二進(jìn)制)、臟數(shù)據(jù)、不及時(shí)且無序;
二是復(fù)雜的加載過程,基于事件時(shí)間的過程需要支持交互查詢,和機(jī)器學(xué)習(xí)組合使用;
三是不同的存儲(chǔ)系統(tǒng)和格式(SQL、NoSQL、Parquet 等),要考慮如何容錯(cuò)。
因?yàn)榭梢赃\(yùn)行在 Spark SQL 引擎上,Spark Structured Streaming 天然擁有較好的性能、良好的擴(kuò)展性及容錯(cuò)性等 Spark 優(yōu)勢(shì)。除此之外,它還具備豐富、統(tǒng)一、高層次的 API,因此便于處理復(fù)雜的數(shù)據(jù)和工作流。再加上,無論是 Spark 自身,還是其集成的多個(gè)存儲(chǔ)系統(tǒng),都有豐富的生態(tài)圈。這些優(yōu)勢(shì)也讓 Spark Structured Streaming 得到更多的發(fā)展和使用。
流的定義是一種無限表(unbounded table),把數(shù)據(jù)流中的新數(shù)據(jù)追加在這張無限表中,而它的查詢過程可以拆解為幾個(gè)步驟,例如可以從 Kafka 讀取 JSON 數(shù)據(jù),解析 JSON 數(shù)據(jù),存入結(jié)構(gòu)化 Parquet 表中,并確保端到端的容錯(cuò)機(jī)制。其中的特性包括:
支持多種消息隊(duì)列,比如 Files/Kafka/Kinesis 等。
可以用 join(), union() 連接多個(gè)不同類型的數(shù)據(jù)源。
返回一個(gè) DataFrame,它具有一個(gè)無限表的結(jié)構(gòu)。
你可以按需選擇 SQL(BI 分析)、DataFrame(數(shù)據(jù)科學(xué)家分析)、DataSet(數(shù)據(jù)引擎),它們有幾乎一樣的語義和性能。
把 Kafka 的 JSON 結(jié)構(gòu)的記錄轉(zhuǎn)換成 String,生成嵌套列,利用了很多優(yōu)化過的處理函數(shù)來完成這個(gè)動(dòng)作,例如 from_json(),也允許各種自定義函數(shù)協(xié)助處理,例如 Lambdas, flatMap。
在 Sink 步驟中可以寫入外部存儲(chǔ)系統(tǒng),例如 Parquet。在 Kafka sink 中,支持 foreach 來對(duì)輸出數(shù)據(jù)做任何處理,支持事務(wù)和 exactly-once 方式。
支持固定時(shí)間間隔的微批次處理,具備微批次處理的高性能性,支持低延遲的連續(xù)處理(Spark 2.3),支持檢查點(diǎn)機(jī)制(check point)。
秒級(jí)處理來自 Kafka 的結(jié)構(gòu)化源數(shù)據(jù),可以充分為查詢做好準(zhǔn)備。
Spark SQL 把批次查詢轉(zhuǎn)化為一系列增量執(zhí)行計(jì)劃,從而可以分批次地操作數(shù)據(jù)。
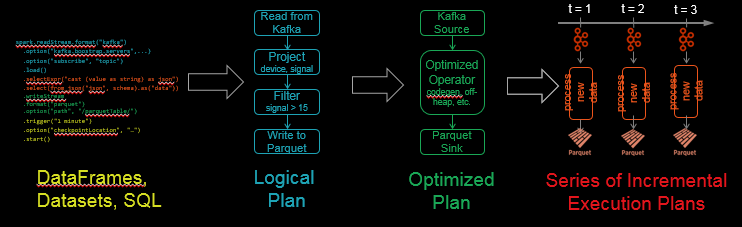
在容錯(cuò)機(jī)制上,Structured Streaming 采取檢查點(diǎn)機(jī)制,把進(jìn)度 offset 寫入 stable 的存儲(chǔ)中,用 JSON 的方式保存支持向下兼容,允許從任何錯(cuò)誤點(diǎn)(例如自動(dòng)增加一個(gè)過濾來處理中斷的數(shù)據(jù))進(jìn)行恢復(fù)。這樣確保了端到端數(shù)據(jù)的 exactly-once。
在性能上,Structured Streaming 重用了 Spark SQL 優(yōu)化器和 Tungsten 引擎,而且成本降低了 3 倍!
Structured Streaming 隔離處理邏輯采用的是可配置化的方式(比如定制 JSON 的輸入數(shù)據(jù)格式),執(zhí)行方式是批處理還是流查詢很容易識(shí)別。同時(shí) TD 還比較了批處理、微批次 - 流處理、持續(xù)流處理三種模式的延遲性、吞吐性和資源分配情況。
在時(shí)間窗口的支持上,Structured Streaming 支持基于事件時(shí)間(event-time)的聚合,這樣更容易了解每隔一段時(shí)間發(fā)生的事情。同時(shí)也支持各種用戶定義聚合函數(shù)(User Defined Aggregate Function,UDAF)。另外,Structured Streaming 可通過不同觸發(fā)器間分布式存儲(chǔ)的狀態(tài)來進(jìn)行聚合,狀態(tài)被存儲(chǔ)在內(nèi)存中,歸檔采用 HDFS 的 Write Ahead Log (WAL)機(jī)制。當(dāng)然,Structured Streaming 還可自動(dòng)處理過時(shí)的數(shù)據(jù),更新舊的保存狀態(tài)。因?yàn)闅v史狀態(tài)記錄可能無限增長(zhǎng),這會(huì)帶來一些性能問題,為了限制狀態(tài)記錄的大小,Spark 使用水印(watermarking)來刪除不再更新的舊的聚合數(shù)據(jù)。允許支持自定義狀態(tài)函數(shù),比如事件或處理時(shí)間的超時(shí),同時(shí)支持Scala 和Java。
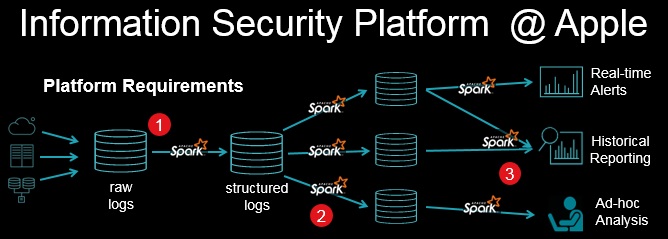
TD 在演講中也具體舉例了流處理的應(yīng)用情況。在蘋果的信息安全平臺(tái)中,每秒將產(chǎn)生有百萬級(jí)事件,Structured Streaming 可以用來做缺陷檢測(cè),下圖是該平臺(tái)架構(gòu):
CarbonData 原理、應(yīng)用和新規(guī)劃
華為大數(shù)據(jù)架構(gòu)師蔡強(qiáng)在以 CarbonData 為主題的演講中主要介紹了企業(yè)對(duì)數(shù)據(jù)應(yīng)用的挑戰(zhàn)、存儲(chǔ)產(chǎn)品的選型決策,并深入講解了 CarbonData 的原理及應(yīng)用,以及對(duì)未來的規(guī)劃等。
企業(yè)中包含多種數(shù)據(jù)應(yīng)用,從商業(yè)智能、批處理到機(jī)器學(xué)習(xí),數(shù)據(jù)增長(zhǎng)快速、數(shù)據(jù)結(jié)構(gòu)復(fù)雜的特征越來越明顯。在應(yīng)用集成上,需要也越來越多,包括支持 SQL 的標(biāo)準(zhǔn)語法、JDBC 和 ODBC 接口、靈活的動(dòng)態(tài)查詢、OLAP 分析等。
針對(duì)當(dāng)前大數(shù)據(jù)領(lǐng)域分析場(chǎng)景需求各異而導(dǎo)致的存儲(chǔ)冗余問題,CarbonData 提供了一種新的融合數(shù)據(jù)存儲(chǔ)方案,以一份數(shù)據(jù)同時(shí)支持支持快速過濾查找和各種大數(shù)據(jù)離線分析和實(shí)時(shí)分析,并通過多級(jí)索引、字典編碼、預(yù)聚合、動(dòng)態(tài) Partition、實(shí)時(shí)數(shù)據(jù)查詢等特性提升了 IO 掃描和計(jì)算性能,實(shí)現(xiàn)萬億數(shù)據(jù)分析秒級(jí)響應(yīng)。蔡強(qiáng)在演講中對(duì) CarbonData 的設(shè)計(jì)思路做了詳細(xì)講解。
在數(shù)據(jù)統(tǒng)一存儲(chǔ)上:通過數(shù)據(jù)共享減少孤島和冗余,支持多種業(yè)務(wù)場(chǎng)景以產(chǎn)生更大價(jià)值。
大集群:區(qū)別于以往的單機(jī)系統(tǒng),用戶希望新的大數(shù)據(jù)存儲(chǔ)方案能應(yīng)對(duì)日益增多的數(shù)據(jù),隨時(shí)可以通過增加資源的方式橫向擴(kuò)展,無限擴(kuò)容。
易集成:提供標(biāo)準(zhǔn)接口,新的大數(shù)據(jù)方案與企業(yè)已采購的工具和 IT 系統(tǒng)要能無縫集成,支撐老業(yè)務(wù)快速遷移。另外要與大數(shù)據(jù)生態(tài)中的各種軟件能無縫集成。
高性能:計(jì)算與存儲(chǔ)分離,支持從 GB 到 PB 大規(guī)模數(shù)據(jù),十萬億數(shù)據(jù)秒級(jí)響應(yīng)。
開放生態(tài):與大數(shù)據(jù)生態(tài)無縫集成,充分利用云存儲(chǔ)和 Hadoop 集群的優(yōu)勢(shì)。
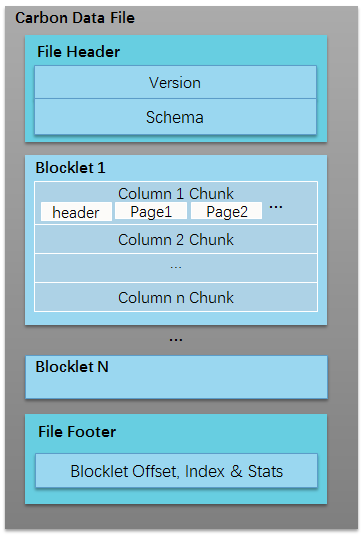
數(shù)據(jù)布局如下圖,CarbonData 用一個(gè) HDFS 文件構(gòu)成一個(gè) Block,包含若干 Blocklet 作為文件內(nèi)的列存數(shù)據(jù)塊,F(xiàn)ile Header/Fille Footer 提供元數(shù)據(jù)信息,內(nèi)置 Blocklet 索引以及 Blocklet 級(jí)和 Page 級(jí)的統(tǒng)計(jì)信息,壓縮編碼采用 RLE、自適應(yīng)編碼、Snappy/Zstd 壓縮,數(shù)據(jù)類型支持所有基礎(chǔ)和復(fù)雜類型:
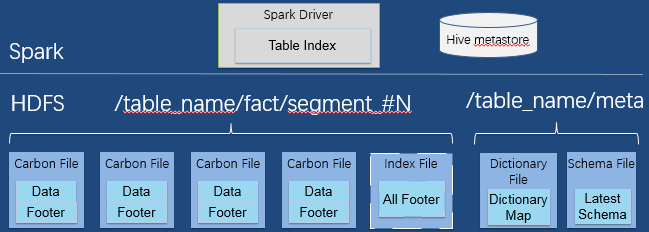
Spark Driver 將集中式的索引存在內(nèi)存中,根據(jù)索引快速過濾數(shù)據(jù),Hive metastore 存儲(chǔ)表的元數(shù)據(jù) (表的信息等)。
一次 Load/Insert 對(duì)應(yīng)生成一個(gè) Segment, 一個(gè) Segment 包含多個(gè) Shard, 一個(gè) Shard 就是一臺(tái)機(jī)器上導(dǎo)入的多個(gè)數(shù)據(jù)文件和一個(gè)索引文件組成。每個(gè) Segment 包含數(shù)據(jù)和元數(shù)據(jù)(CarbonData File 和 Index 文件),不同的 Segment 可以有不同的文件格式,支持更多其他格式(CSV, Parquet),采用增量的數(shù)據(jù)管理方式,處理比分區(qū)管理的速度快很多。
查詢時(shí)會(huì)將 filter 和 projection 下推到 DataMap(數(shù)據(jù)地圖)。它的執(zhí)行模型如下:
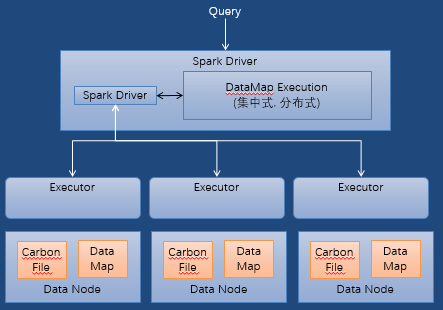
主要包括 Index DataMap 和 MV DataMap 兩種不同 DataMap,三級(jí) Index 索引架構(gòu)減少了 Spark Task 數(shù)和磁盤 IO,MV 可以進(jìn)行預(yù)匯聚和 join 的操作,用數(shù)據(jù)入庫時(shí)間換取查詢時(shí)間。
DataMap 根據(jù)實(shí)際數(shù)據(jù)量大小選擇集中式或者分布式存儲(chǔ),以避免大內(nèi)存問題。
DataMap 支持內(nèi)存或磁盤的存儲(chǔ)方式。
最后,蔡強(qiáng)也分析了 CarbonData 的具體使用和未來計(jì)劃。
在使用上,CarbonData 提供了非常豐富的功能特性,用戶可權(quán)衡入庫時(shí)間、索引粒度和查詢性能,增量入庫等方面來靈活設(shè)置。表操作與 SparkSQL 深度集成,支持高檢測(cè)功能的可配置 Table Properties。語法和 API 保持 SparkSQL 一致,支持并發(fā)導(dǎo)入、更新、合并和查詢。DataMap類似一張視圖表,可用于加速 Carbon 表查詢,通過 datamap_provider 支持 Bloomfilter、Pre-aggregate、MV 三種類型的地圖。流式入庫與 Structured Streaming集成,實(shí)現(xiàn)準(zhǔn)實(shí)時(shí)分析。支持同時(shí)查詢實(shí)時(shí)數(shù)據(jù)和歷史數(shù)據(jù),支持預(yù)聚合并自動(dòng)刷新,聚合查詢會(huì)先檢查聚合操作,從而取得數(shù)據(jù)返回客戶端。準(zhǔn)實(shí)時(shí)查詢,提供了 Stream SQL 標(biāo)準(zhǔn)接口,建立臨時(shí)的 Source 表和 Sink 表。支持類似 Structured Streaming(結(jié)構(gòu)化流)的邏輯語句和調(diào)度作業(yè)。
CarbonData 從 2016 年進(jìn)入孵化器到 2017 年畢業(yè),一共發(fā)布了 10 多個(gè)穩(wěn)定的版本,今年 9 月份將會(huì)迎來 1.5.0 版的發(fā)布。1.5.0 將支持 Spark File Format,增強(qiáng)對(duì) S3 上數(shù)據(jù)的支持,支持 Spark2.3 和 Hadoop3.1 以及復(fù)雜類型的支持。而 1.5.1 主要會(huì)對(duì) MV 支持增量的加載,增強(qiáng)對(duì) DataMap 的選擇,以及增強(qiáng)了對(duì) Presto 的支持。
Flink 在美團(tuán)的實(shí)踐與應(yīng)用
美團(tuán)點(diǎn)評(píng)數(shù)據(jù)平臺(tái)的高級(jí)工程師孫夢(mèng)瑤介紹了美團(tuán)的實(shí)時(shí)平臺(tái)架構(gòu)及當(dāng)前痛點(diǎn),帶來了美團(tuán)如何在 Flink 上的實(shí)踐以及如何打造實(shí)時(shí)數(shù)據(jù)平臺(tái),最后介紹了實(shí)時(shí)指標(biāo)聚合系統(tǒng)和機(jī)器學(xué)習(xí)平臺(tái)是如何利用 Flink 進(jìn)行賦能。
孫夢(mèng)瑤首先介紹了美團(tuán)目前實(shí)時(shí)計(jì)算平臺(tái)的架構(gòu):
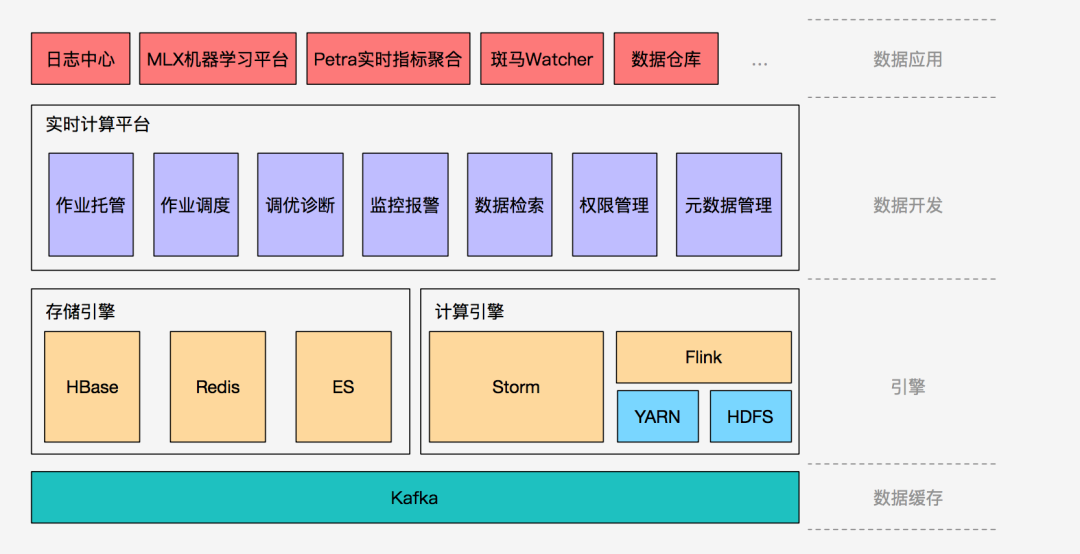
首先,在數(shù)據(jù)緩存層,Kafka 作為最大的數(shù)據(jù)中轉(zhuǎn)層(所有日志類的數(shù)據(jù)),支撐了美團(tuán)線上的大量業(yè)務(wù),包括離線拉取,以及部分實(shí)時(shí)處理業(yè)務(wù)等。其次,引擎層由計(jì)算引擎和存儲(chǔ)引擎來支撐,計(jì)算引擎由 Storm 和 Flink 混合使用,存儲(chǔ)引擎則提供實(shí)時(shí)存儲(chǔ)功能。接著,平臺(tái)層為數(shù)據(jù)開發(fā)提供支持,為美團(tuán)的日志中心、機(jī)器學(xué)習(xí)中心、實(shí)時(shí)指標(biāo)聚合平臺(tái)提供支撐。架構(gòu)最頂層的數(shù)據(jù)應(yīng)用層?就是由實(shí)時(shí)計(jì)算平臺(tái)支撐的業(yè)務(wù)。
目前,美團(tuán)實(shí)時(shí)計(jì)算平臺(tái)的作業(yè)量已達(dá)到近萬,集群的節(jié)點(diǎn)的規(guī)模達(dá)到千級(jí)別,天級(jí)消息量已經(jīng)達(dá)到了萬億級(jí),高峰期的秒級(jí)消息量則高達(dá)千萬條。但是,隨著業(yè)務(wù)的快速擴(kuò)增,美團(tuán)點(diǎn)評(píng)在實(shí)時(shí)計(jì)算層面仍面臨著一系列的痛點(diǎn)及問題:
一是實(shí)時(shí)計(jì)算精確性問題:由于 Storm 的 At-Least-Once 特性導(dǎo)致數(shù)據(jù)重復(fù),而滿足 Exactly-Once 的 Trident 無法保證某些業(yè)務(wù)的毫秒級(jí)延遲要求。
二是流處理中的狀態(tài)管理問題:基于 Storm 的流處理的狀態(tài)如果管理不好,會(huì)引起故障難以恢復(fù)的尷尬狀況。
三是實(shí)時(shí)計(jì)算表義能力的局限性:基于對(duì)實(shí)時(shí)計(jì)算場(chǎng)景的業(yè)務(wù)需求,發(fā)現(xiàn)之前的系統(tǒng)在表義能力方面有一定的限制。
四是開發(fā)調(diào)試成本高:不同生態(tài)的手工代碼開發(fā),導(dǎo)致后續(xù)開發(fā)、調(diào)試、維護(hù)成本的增加。
在這樣的的背景下,美團(tuán)點(diǎn)評(píng)基礎(chǔ)數(shù)據(jù)團(tuán)隊(duì)也開始引入 Flink 并探索相對(duì)應(yīng)的創(chuàng)新實(shí)踐之路。Flink 在美團(tuán)點(diǎn)評(píng)的實(shí)踐主要包括三大維度:一是穩(wěn)定性實(shí)踐,二是 Flink 的平臺(tái)化,三是生態(tài)建設(shè):
穩(wěn)定性實(shí)踐層面,美團(tuán)點(diǎn)評(píng)首先按不同的業(yè)務(wù)(取決于不同的高峰期、運(yùn)維時(shí)間、可靠性、延遲要求、應(yīng)用場(chǎng)景等)進(jìn)行對(duì)應(yīng)的資源隔離,隔離策略是通過 YARN 在物理節(jié)點(diǎn)上打標(biāo)簽和隔離離線 DataNode 與實(shí)時(shí)計(jì)算節(jié)點(diǎn)。
其次,再實(shí)施基于 CPU、基于內(nèi)存的智能調(diào)度,目前方案是從 CPU 和內(nèi)存兩個(gè)方面進(jìn)行調(diào)度優(yōu)化。還包括對(duì) Flink 的 JobManager 部署 HA(High Availability),保證節(jié)點(diǎn)的高可用性。針對(duì)網(wǎng)絡(luò)連接故障,采用自動(dòng)拉起的方式,通過 checkpoint 恢復(fù)失敗的作業(yè)。
此外,針對(duì) Flink 對(duì) Kafka 08 的讀寫超時(shí),美團(tuán)點(diǎn)評(píng)會(huì)根據(jù)用戶的指定次數(shù)對(duì)異常進(jìn)行重試,這種方式在解決大規(guī)模集群的節(jié)點(diǎn)故障問題時(shí)可以做更好的平衡。在容災(zāi)方面,其采用了多機(jī)房和各種熱備提升系統(tǒng)的抗故障能力,即使斷電斷網(wǎng)也能進(jìn)行保證作業(yè)繼續(xù)進(jìn)行數(shù)據(jù)處理。
Flink 平臺(tái)化層面,通過內(nèi)部的作業(yè)管理的實(shí)時(shí)計(jì)算平臺(tái),其團(tuán)隊(duì)可以看到總覽的作業(yè)狀態(tài),以及資源運(yùn)行和占用情況。針對(duì)實(shí)時(shí)作業(yè)中可能出現(xiàn)的狀態(tài),比如延遲、失敗,提供監(jiān)控報(bào)警并能便捷地進(jìn)行消息預(yù)訂(電話,郵件,短信等方式)。針對(duì)顯著的性能差別,也提供了調(diào)優(yōu)診斷的手段進(jìn)行自助查詢、對(duì)比、診斷。
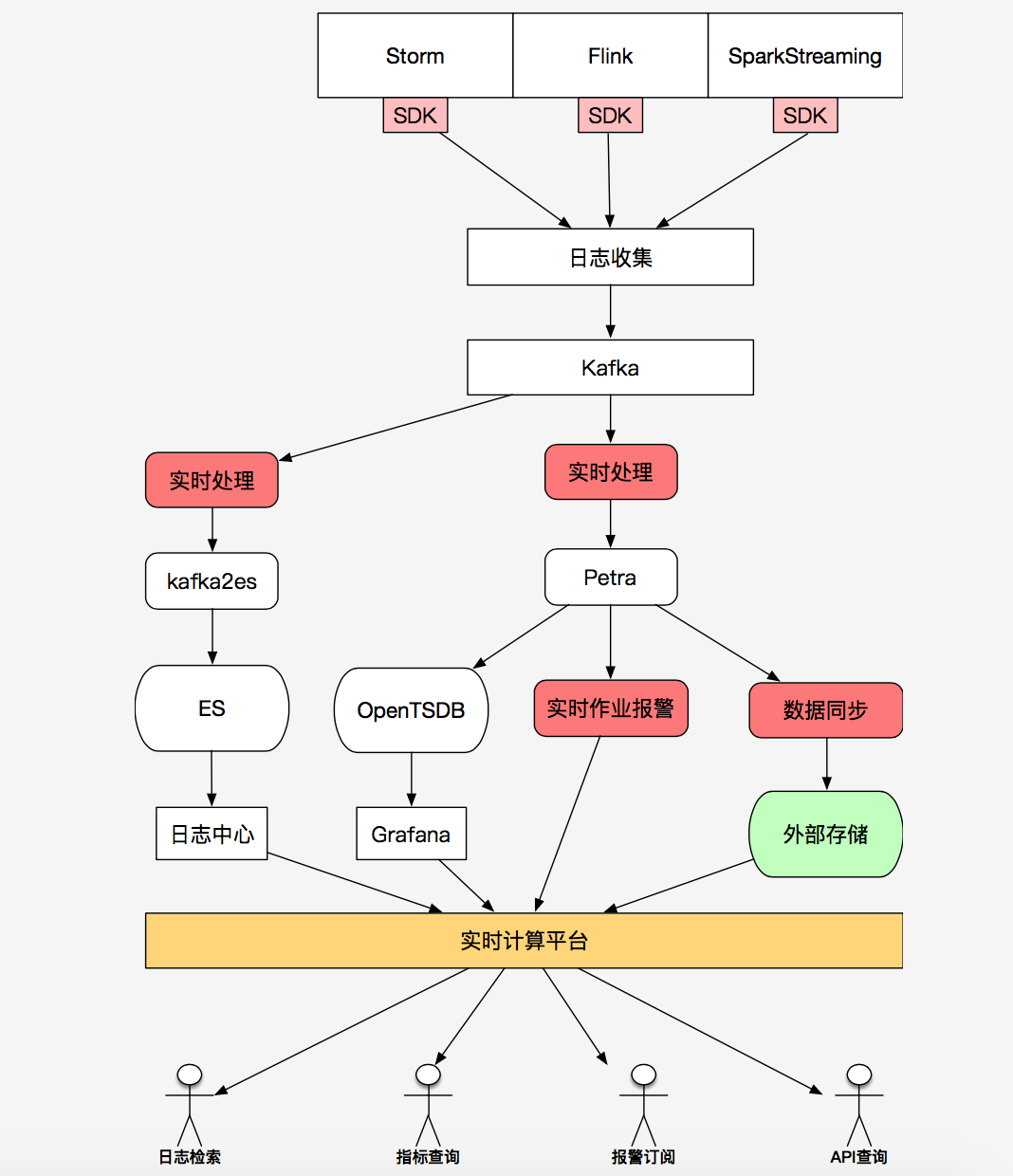
接下來,孫夢(mèng)瑤還主要講解了 Flink 在美團(tuán)的應(yīng)用,其中主要包括兩點(diǎn):一是在Petra 實(shí)時(shí)指標(biāo)聚合系統(tǒng)的應(yīng)用,二是用于 MLX 機(jī)器學(xué)習(xí)平臺(tái)的構(gòu)建。
Petra 實(shí)時(shí)指標(biāo)聚合系統(tǒng)主要完成對(duì)美團(tuán)業(yè)務(wù)系統(tǒng)指標(biāo)的聚合和展示。它對(duì)應(yīng)的場(chǎng)景是整合多個(gè)上游系統(tǒng)的業(yè)務(wù)維度和指標(biāo),確保低延遲、同步時(shí)效性及可配置。因此美團(tuán)點(diǎn)評(píng)團(tuán)隊(duì)充分利用了 Flink 基于事件時(shí)間和聚合的良好支持、Flink 在精確率(checkpoint 機(jī)制)和低延遲上的特性,以及熱點(diǎn) key 散列解決了維度計(jì)算中的數(shù)據(jù)傾斜問題。
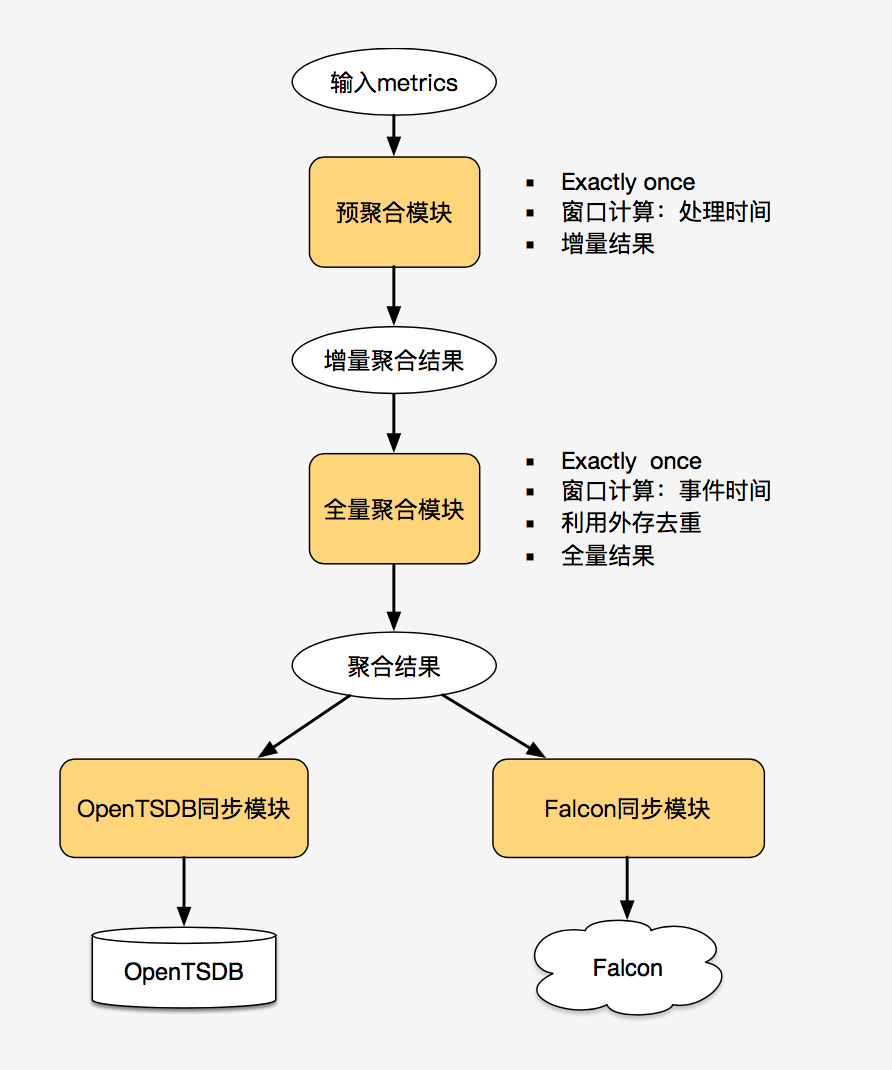
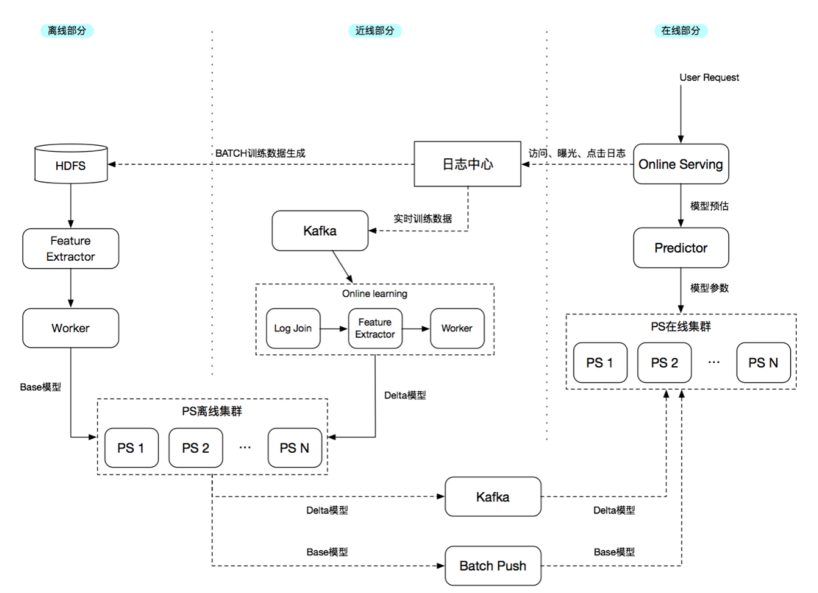
MLX 機(jī)器學(xué)習(xí)平臺(tái)主要通過特征數(shù)據(jù)的提取和模型的訓(xùn)練,支持美團(tuán)點(diǎn)評(píng)的搜索和推薦以及其他業(yè)務(wù)的應(yīng)用。它需要滿足提供離線模式——通過批處理抽取離線特征數(shù)據(jù),同時(shí)也提供近線模式——通過 Flink 抽取實(shí)時(shí)日志系統(tǒng)中的特征數(shù)據(jù)。接著訓(xùn)練綜合了離線和近線數(shù)據(jù)的特征數(shù)據(jù)集群,提取特征并進(jìn)行模型訓(xùn)練,最終產(chǎn)生有意義的特征。目前,它能支持現(xiàn)有離線場(chǎng)景下的特征提取體系,通過 Flink 支持增量在線日志交易類數(shù)據(jù),有了離線和在線數(shù)據(jù)就能較好的支持模型訓(xùn)練、特征提取、在線預(yù)估、實(shí)時(shí)預(yù)測(cè)等。
未來,美團(tuán)點(diǎn)評(píng)還將從三方面優(yōu)化 Flink 相關(guān)實(shí)踐:
狀態(tài)的統(tǒng)一方面:對(duì)狀態(tài)進(jìn)行統(tǒng)一的管理以及大狀態(tài)性能優(yōu)化。
SQL 開發(fā)效率的提升:基于 Flink 在語義上的優(yōu)勢(shì)解決配置、查詢方面的問題,在性能、開發(fā)、維護(hù)方面做進(jìn)一步優(yōu)化。
新應(yīng)用場(chǎng)景的探索:除流處理外,進(jìn)一步整合業(yè)務(wù)場(chǎng)景下離線和在線數(shù)據(jù),通過統(tǒng)一的 API 為業(yè)務(wù)提供更多的服務(wù)。
Flink 和 Spark 流框架對(duì)比 + 華為流計(jì)算技術(shù)演進(jìn)
華為云技術(shù)專家時(shí)金魁作為最后一位演講嘉賓,系統(tǒng)性地梳理、比較了 Flink/Spark 的流框架,同時(shí)介紹了華為流計(jì)算技術(shù)演進(jìn)過程,并詳解了華為 CloudStream 的服務(wù)能力及應(yīng)用。
時(shí)金魁一開始即列舉了最常用的流計(jì)算框架 Storm、Nifi、Spark 和 Flink 等。提供了下面常見開源流計(jì)算框架以便大家了解這個(gè)生態(tài)圈的最新情況。

其中,華為云 CloudStream 同時(shí)支持 Flink 和 Spark(Streaming 和 Structured Streaming)。時(shí)金魁提到,華為流計(jì)算團(tuán)隊(duì)在研發(fā)過程中發(fā)現(xiàn),Spark Streaming 能力有限,無法完全滿足實(shí)時(shí)流計(jì)算場(chǎng)景,而華為自研多年的流框架生態(tài)不足,Storm 日薄西山,所以華為在 2016 年轉(zhuǎn)向 Flink 為主 Spark 為輔的組合。今年 Spark Structured 能力越來越豐富,與 Flink 之間的 gap 正快速縮小,也是幸事。
時(shí)金魁認(rèn)為,流計(jì)算就是實(shí)時(shí)處理當(dāng)下正在發(fā)生的流數(shù)據(jù),逐條進(jìn)行大數(shù)據(jù)分析或算法運(yùn)算。它具備以下幾個(gè)特征:
數(shù)據(jù)先后順序不確定導(dǎo)致的亂序問題。
內(nèi)存計(jì)算。
流速不定(數(shù)據(jù)大小不能預(yù)測(cè)),數(shù)據(jù)傾斜(分布不均勻),導(dǎo)致計(jì)算資源分配不均,能力受限。
Long running 永遠(yuǎn)不結(jié)束。
基于消息事件的逐條處理。
提供可靠的快照。
從新技術(shù)、用戶耐心、大數(shù)據(jù)增長(zhǎng)幾個(gè)方面,時(shí)金魁介紹了實(shí)時(shí)流計(jì)算最大限度挖掘數(shù)據(jù)的價(jià)值,是商業(yè)驅(qū)動(dòng)和市場(chǎng)價(jià)值的一種體現(xiàn)。實(shí)時(shí)流計(jì)算具有豐富的使用場(chǎng)景,如實(shí)時(shí)商品的廣告推薦、金融風(fēng)控、交通物流、車聯(lián)網(wǎng)、智慧城市等等。只要需要對(duì)實(shí)時(shí)的大數(shù)據(jù)推薦或者實(shí)時(shí)大數(shù)據(jù)分析,都能找到流計(jì)算的應(yīng)用價(jià)值。
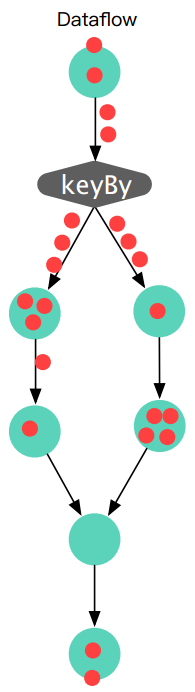
時(shí)金魁在演講中重點(diǎn)講解了數(shù)據(jù)流模型,即它是一個(gè)實(shí)時(shí)往下流的過程。在 Flink 中,客觀的理解就是一個(gè)無限的數(shù)據(jù)流,提供分配和合并,并提供觸發(fā)器和增量處理機(jī)制。如下圖所示:
時(shí)金魁介紹說,對(duì)華為而言,Spark,F(xiàn)link 以及 CloudStream,這三部分構(gòu)成了 LOGO 中的“三條杠”,華為實(shí)時(shí)流計(jì)算服務(wù)俗稱“華為云三道杠”,為客戶主要提供云計(jì)算的服務(wù)。
通過對(duì) Flink 的內(nèi)核分析以及運(yùn)行分析,他解釋了如何實(shí)現(xiàn)一個(gè)完整的數(shù)據(jù)流處理過程:
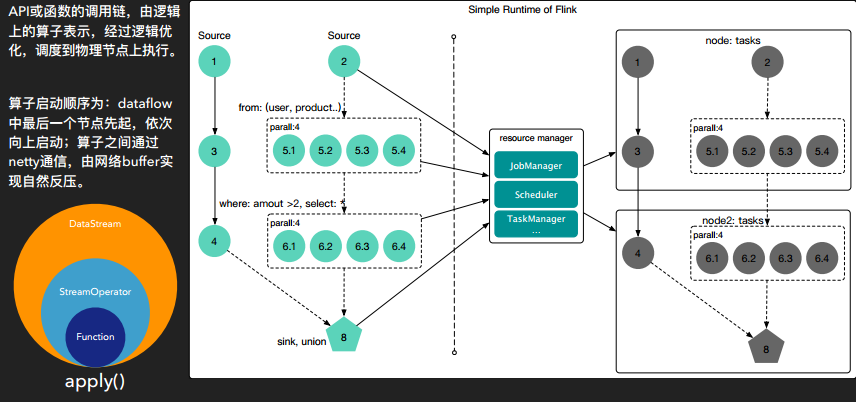
解析:邏輯關(guān)系解析,生成 StreamTransformation
分析:構(gòu)建 StreamGraph,DAG,為生成執(zhí)行計(jì)劃準(zhǔn)備
生成:構(gòu)建 ExecutionGraph,為運(yùn)行做準(zhǔn)備
執(zhí)行:申請(qǐng)資源,執(zhí)行計(jì)劃(算子)
最后生成數(shù)據(jù)流(DataStream)
下圖是 Flink 的技術(shù)棧圖,包括了一個(gè)完整的數(shù)據(jù)流框架:
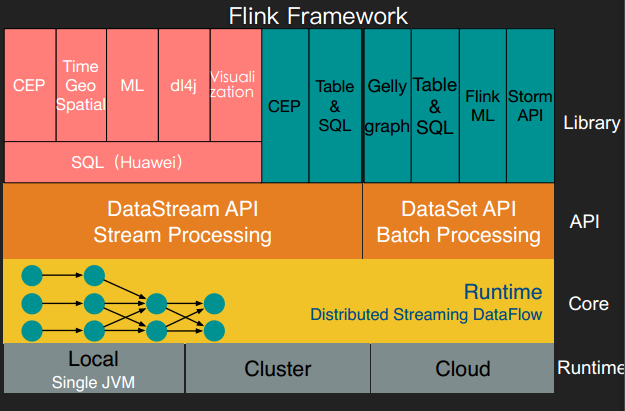
此外,時(shí)金魁還對(duì) Flink 和 Spark 做了詳細(xì)的對(duì)比。Flink的優(yōu)勢(shì)包括具備成熟的數(shù)據(jù)流模型,能提供大量易用的 API 供使用,在 SQL、Table、CEP、ML、Graph 方面都提供完善的功能。對(duì)比之下,Spark擁有活躍的社區(qū)和完善的生態(tài),Structured Streaming 能提供統(tǒng)一標(biāo)準(zhǔn),保證低延遲。
而華為根據(jù) Flink 與 Spark 框架各自的特點(diǎn),摒棄其劣勢(shì),設(shè)計(jì)開發(fā)出一款全新的實(shí)時(shí)流計(jì)算服務(wù) Cloud Stream Service(簡(jiǎn)稱 CS)。CS 采用 Apache Flink 的 Dataflow 模型,實(shí)現(xiàn)完全的實(shí)時(shí)計(jì)算,同時(shí)采用在線 SQL 編輯平臺(tái)編寫的 Stream SQL,自定義數(shù)據(jù)流入、數(shù)據(jù)處理、數(shù)據(jù)流出,并完全兼容 Spark 和 Flink 的 API。
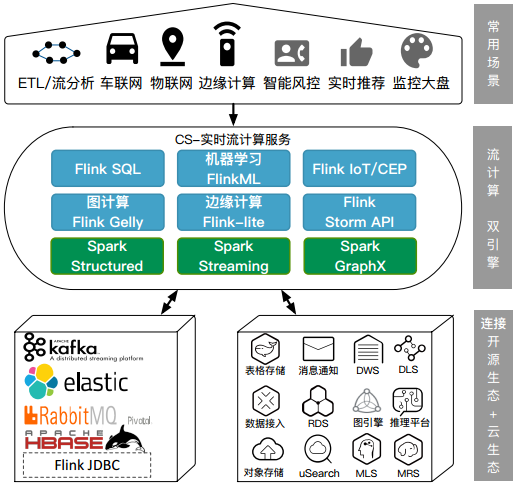
總結(jié)來說,Cloud Stream 具有易用、按需計(jì)費(fèi)、開箱即用、低延時(shí)(毫秒)高吞吐(百萬消息每秒)、完整生態(tài)、完全可靠等幾大優(yōu)勢(shì)。
例如,在易用性維度,Cloud Stream 利用可視化的 StreamSQL 編輯器,因此可以方便地定義 SQL,可在線調(diào)試和監(jiān)控作業(yè)。
在安全性維度,華為實(shí)時(shí)流計(jì)算團(tuán)隊(duì)在行業(yè)首創(chuàng)了全托管的 serverless 獨(dú)享集群模式。第一,它采用物理隔離,使得用戶在作業(yè)運(yùn)行時(shí)和資源上無共享,多用戶之間無交叉;二是在業(yè)務(wù)上實(shí)現(xiàn)隔離,使得連接、數(shù)據(jù)和計(jì)算相互獨(dú)立無干擾;三是沙箱在共享資源池中很難完全防語言、應(yīng)用、OS 等方面的共計(jì),而且對(duì) Spark 和 Flink 有一定的侵入性。
在線機(jī)器學(xué)習(xí)方面,CloudStream 通過了流式隨機(jī)森林算法應(yīng)用于實(shí)時(shí)故障檢測(cè);通過特征工程應(yīng)用于實(shí)時(shí)推薦;通過在線機(jī)器學(xué)習(xí)應(yīng)用于智慧城市;通過地理分析函數(shù)應(yīng)用于卡車運(yùn)輸位置檢測(cè)。
最后,時(shí)金魁也分享了 CloudStream 支持對(duì)接用戶自己搭建的 Kafka、Hadoop、Elastic Search、RabbitMQ 等開源產(chǎn)品集群;同時(shí)已支持連通華為云上的其他服務(wù),如消息通知服務(wù)、云搜索服務(wù)、智能邊緣平臺(tái)等十幾個(gè)服務(wù),從而為用戶提供一站式、生態(tài)豐富、功能強(qiáng)大的實(shí)時(shí)流計(jì)算平臺(tái)。


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??