
Stream流暢編程:優(yōu)雅而高效的代碼創(chuàng)作
你知道的越多,不知道的就越多,業(yè)余的像一棵小草!
你來,我們一起精進(jìn)!你不來,我和你的競爭對(duì)手一起精進(jìn)!
編輯:業(yè)余草
來源:juejin.cn/post/7254960898686910520
推薦:https://t.zsxq.com/11yPfGLPK
自律才能自由
流式編程的概念和作用
Java 流(Stream)是一連串的元素序列,可以進(jìn)行各種操作以實(shí)現(xiàn)數(shù)據(jù)的轉(zhuǎn)換和處理。流式編程的概念基于函數(shù)式編程的思想,旨在簡化代碼,提高可讀性和可維護(hù)性。
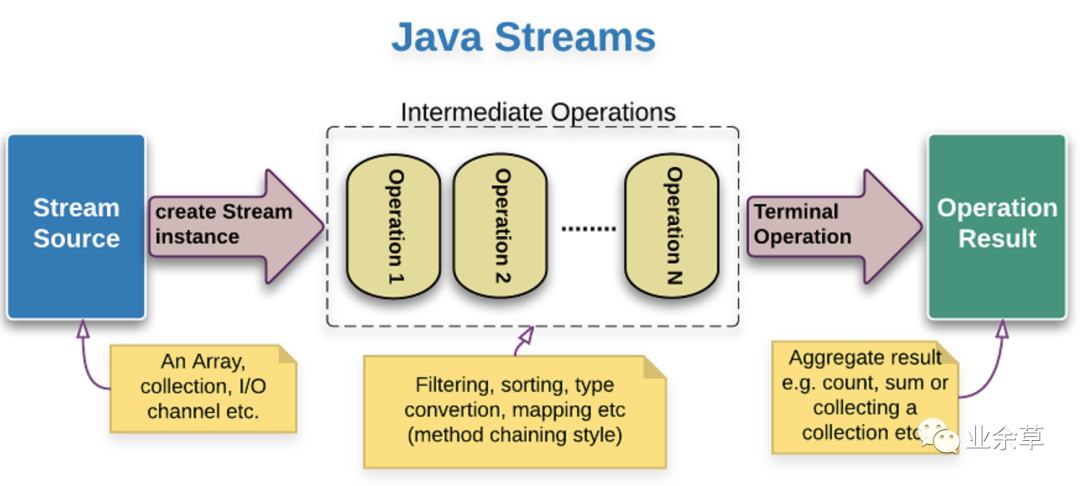
Java Stream 的主要作用有以下幾個(gè)方面:
-
簡化集合操作:使用傳統(tǒng)的 for 循環(huán)或迭代器來處理集合數(shù)據(jù)可能會(huì)導(dǎo)致冗長而復(fù)雜的代碼。而使用流式編程,能夠用更直觀、更簡潔的方式對(duì)集合進(jìn)行過濾、映射、排序、聚合等操作,使代碼變得更加清晰易懂。
-
延遲計(jì)算:流式操作允許你在處理數(shù)據(jù)之前定義一系列的操作步驟,但只在需要結(jié)果時(shí)才會(huì)實(shí)際執(zhí)行。這種延遲計(jì)算的特性意味著可以根據(jù)需要?jiǎng)討B(tài)調(diào)整數(shù)據(jù)處理的操作流程,提升效率。
-
并行處理:Java Stream 提供了并行流的支持,可以將數(shù)據(jù)分成多個(gè)塊進(jìn)行并行處理,從而充分利用多核處理器的性能優(yōu)勢,提高代碼的執(zhí)行速度。
-
函數(shù)式編程風(fēng)格:流式編程鼓勵(lì)使用函數(shù)式編程的思想,通過傳遞函數(shù)作為參數(shù)或使用 Lambda 表達(dá)式來實(shí)現(xiàn)代碼的簡化和靈活性。這種函數(shù)式的編程模式有助于減少副作用,并使代碼更易測試和調(diào)試。
為什么使用流式編程可以提高代碼可讀性和簡潔性
-
聲明式編程風(fēng)格:流式編程采用了一種聲明式的編程風(fēng)格,你只需描述你想要對(duì)數(shù)據(jù)執(zhí)行的操作,而不需要顯式地編寫迭代和控制流語句。這使得代碼更加直觀和易于理解,因?yàn)槟憧梢愿鼘W⒌乇磉_(dá)你的意圖,而無需關(guān)注如何實(shí)現(xiàn)。
-
鏈?zhǔn)秸{(diào)用:流式編程使用方法鏈?zhǔn)秸{(diào)用的方式,將多個(gè)操作鏈接在一起。每個(gè)方法都返回一個(gè)新的流對(duì)象,這樣你可以像“流水線”一樣在代碼中順序地寫下各種操作,使代碼邏輯清晰明了。這種鏈?zhǔn)秸{(diào)用的方式使得代碼看起來更加流暢,減少了中間變量和臨時(shí)集合的使用。
-
操作的組合:流式編程提供了一系列的操作方法,如過濾、映射、排序、聚合等,這些方法可以按照需要進(jìn)行組合使用。你可以根據(jù)具體的業(yè)務(wù)需求將這些操作串聯(lián)起來,形成一個(gè)復(fù)雜的處理流程,而不需要編寫大量的循環(huán)和條件語句。這種組合操作的方式使得代碼更加模塊化和可維護(hù)。
-
減少中間狀態(tài):傳統(tǒng)的迭代方式通常需要引入中間變量來保存中間結(jié)果,這樣會(huì)增加代碼的復(fù)雜度和維護(hù)成本。而流式編程將多個(gè)操作鏈接在一起,通過流對(duì)象本身來傳遞數(shù)據(jù),避免了中間狀態(tài)的引入。這種方式使得代碼更加簡潔,減少了臨時(shí)變量的使用。
-
減少循環(huán)和條件:流式編程可以替代傳統(tǒng)的循環(huán)和條件語句的使用。例如,可以使用 filter() 方法進(jìn)行元素的篩選,使用 map() 方法進(jìn)行元素的轉(zhuǎn)換,使用 reduce() 方法進(jìn)行聚合操作等。這些方法可以用一行代碼完成相應(yīng)的操作,避免了繁瑣的循環(huán)和條件邏輯,使得代碼更加簡潔明了。
Stream 基礎(chǔ)知識(shí)
什么是 Stream
Stream(流)是 Java 8 引入的一個(gè)新的抽象概念,它代表著一種處理數(shù)據(jù)的序列。簡單來說,Stream 是一系列元素的集合,這些元素可以是集合、數(shù)組、I/O 資源或者其他數(shù)據(jù)源。
Stream API 提供了豐富的操作方法,可以對(duì) Stream 中的元素進(jìn)行各種轉(zhuǎn)換、過濾、映射、聚合等操作,從而實(shí)現(xiàn)對(duì)數(shù)據(jù)的處理和操作。Stream API 的設(shè)計(jì)目標(biāo)是提供一種高效、可擴(kuò)展和易于使用的方式來處理大量的數(shù)據(jù)。
Stream 具有以下幾個(gè)關(guān)鍵特點(diǎn):
-
數(shù)據(jù)源:Stream 可以基于不同類型的數(shù)據(jù)源創(chuàng)建,如集合、數(shù)組、I/O 資源等。你可以通過調(diào)用集合或數(shù)組的 stream() 方法來創(chuàng)建一個(gè)流。
-
數(shù)據(jù)處理:Stream 提供了豐富的操作方法,可以對(duì)流中的元素進(jìn)行處理。這些操作可以按需求組合起來,形成一個(gè)流水線式的操作流程。常見的操作包括過濾(filter)、映射(map)、排序(sorted)、聚合(reduce)等。
-
惰性求值:Stream 的操作是惰性求值的,也就是說在定義操作流程時(shí),不會(huì)立即執(zhí)行實(shí)際計(jì)算。只有當(dāng)終止操作(如收集結(jié)果或遍歷元素)被調(diào)用時(shí),才會(huì)觸發(fā)實(shí)際的計(jì)算過程。
-
不可變性:Stream 是不可變的,它不會(huì)修改原始數(shù)據(jù)源,也不會(huì)產(chǎn)生中間狀態(tài)或副作用。每個(gè)操作都會(huì)返回一個(gè)新的流對(duì)象,以保證數(shù)據(jù)的不可變性。
-
并行處理:Stream 支持并行處理,可以通過 parallel() 方法將流轉(zhuǎn)換為并行流,利用多核處理器的優(yōu)勢來提高處理速度。在某些情況下,使用并行流可以極大地提高程序的性能。
通過使用 Stream,我們可以使用簡潔、函數(shù)式的方式處理數(shù)據(jù)。相比傳統(tǒng)的循環(huán)和條件語句,Stream 提供了更高層次的抽象,使代碼更具可讀性、簡潔性和可維護(hù)性。它是一種強(qiáng)大的工具,可以幫助我們更有效地處理和操作集合數(shù)據(jù)。
Stream 的特性和優(yōu)勢
-
簡化的編程模型:Stream 提供了一種更簡潔、更聲明式的編程模型,使代碼更易于理解和維護(hù)。通過使用 Stream API,我們可以用更少的代碼實(shí)現(xiàn)復(fù)雜的數(shù)據(jù)操作,將關(guān)注點(diǎn)從如何實(shí)現(xiàn)轉(zhuǎn)移到了更關(guān)注我們想要做什么。
-
函數(shù)式編程風(fēng)格:Stream 是基于函數(shù)式編程思想設(shè)計(jì)的,它鼓勵(lì)使用不可變的數(shù)據(jù)和純函數(shù)的方式進(jìn)行操作。這種風(fēng)格避免了副作用,使代碼更加模塊化、可測試和可維護(hù)。此外,Stream 還支持 Lambda 表達(dá)式,使得代碼更加簡潔和靈活。
-
惰性求值:Stream 的操作是惰性求值的,也就是說在定義操作流程時(shí)并不會(huì)立即執(zhí)行計(jì)算。只有當(dāng)終止操作被調(diào)用時(shí),才會(huì)觸發(fā)實(shí)際的計(jì)算過程。這種特性可以避免對(duì)整個(gè)數(shù)據(jù)集進(jìn)行不必要的計(jì)算,提高了效率。
-
并行處理能力:Stream 支持并行處理,在某些情況下可以通過 parallel() 方法將流轉(zhuǎn)換為并行流,利用多核處理器的優(yōu)勢來提高處理速度。并行流能夠自動(dòng)將數(shù)據(jù)劃分為多個(gè)子任務(wù),并在多個(gè)線程上同時(shí)執(zhí)行,提高了處理大量數(shù)據(jù)的效率。
-
優(yōu)化的性能:Stream API 內(nèi)部使用了優(yōu)化技術(shù),如延遲執(zhí)行、短路操作等,以提高計(jì)算性能。Stream 操作是通過內(nèi)部迭代器實(shí)現(xiàn)的,可以更好地利用硬件資源,并適應(yīng)數(shù)據(jù)規(guī)模的變化。
-
支持豐富的操作方法:Stream API 提供了許多豐富的操作方法,如過濾、映射、排序、聚合等。這些方法可以按需求組合起來形成一個(gè)操作流程。在組合多個(gè)操作時(shí),Stream 提供了鏈?zhǔn)秸{(diào)用的方式,使代碼更加簡潔和可讀性更強(qiáng)。
-
可以操作各種數(shù)據(jù)源:Stream 不僅可以操作集合類數(shù)據(jù),還可以操作其他數(shù)據(jù)源,如數(shù)組、I/O 資源甚至無限序列。這使得我們可以使用相同的編程模型來處理各種類型的數(shù)據(jù)。
如何創(chuàng)建 Stream 對(duì)象
-
從集合創(chuàng)建:我們可以通過調(diào)用集合的 stream()方法來創(chuàng)建一個(gè) Stream 對(duì)象。例如:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> stream = numbers.stream();
-
從數(shù)組創(chuàng)建:Java 8 引入了 Arrays類的stream()方法,我們可以使用它來創(chuàng)建一個(gè) Stream 對(duì)象。例如:
String[] names = {"Alice", "Bob", "Carol"};
Stream<String> stream = Arrays.stream(names);
-
通過 Stream.of() 創(chuàng)建:我們可以使用 Stream.of()方法直接將一組元素轉(zhuǎn)換為 Stream 對(duì)象。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
-
通過 Stream.builder() 創(chuàng)建:如果我們不確定要添加多少個(gè)元素到 Stream 中,可以使用 Stream.builder()創(chuàng)建一個(gè) Stream.Builder 對(duì)象,并使用其add()方法來逐個(gè)添加元素,最后調(diào)用build()方法生成 Stream 對(duì)象。例如:
Stream.Builder<String> builder = Stream.builder();
builder.add("Apple");
builder.add("Banana");
builder.add("Cherry");
Stream<String> stream = builder.build();
-
從 I/O 資源創(chuàng)建:Java 8 引入了一些新的 I/O 類(如 BufferedReader、Files等),它們提供了很多方法來讀取文件、網(wǎng)絡(luò)流等數(shù)據(jù)。這些方法通常返回一個(gè) Stream 對(duì)象,可以直接使用。例如:
Path path = Paths.get("data.txt");
try (Stream<String> stream = Files.lines(path)) {
// 使用 stream 處理數(shù)據(jù)
} catch (IOException e) {
e.printStackTrace();
}
-
通過生成器創(chuàng)建:除了從現(xiàn)有的數(shù)據(jù)源創(chuàng)建 Stream,我們還可以使用生成器來生成元素。Java 8 中提供了 Stream.generate()方法和Stream.iterate()方法來創(chuàng)建無限 Stream。例如:
Stream<Integer> stream = Stream.generate(() -> 0); // 創(chuàng)建一個(gè)無限流,每個(gè)元素都是 0
Stream<Integer> stream = Stream.iterate(0, n -> n + 1); // 創(chuàng)建一個(gè)無限流,從 0 開始遞增
需要注意的是,Stream 對(duì)象是一種一次性使用的對(duì)象,它只能被消費(fèi)一次。一旦對(duì) Stream 執(zhí)行了終止操作(如收集結(jié)果、遍歷元素),Stream 就會(huì)被關(guān)閉,后續(xù)無法再使用。因此,在使用 Stream 時(shí),需要根據(jù)需要重新創(chuàng)建新的 Stream 對(duì)象。
常用的 Stream 操作方法
-
過濾(Filter): filter()方法接受一個(gè) Predicate 函數(shù)作為參數(shù),用于過濾 Stream 中的元素。只有滿足 Predicate 條件的元素會(huì)被保留下來。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> filteredStream = stream.filter(n -> n % 2 == 0); // 過濾出偶數(shù)
-
映射(Map): map()方法接受一個(gè) Function 函數(shù)作為參數(shù),用于對(duì) Stream 中的元素進(jìn)行映射轉(zhuǎn)換。對(duì)每個(gè)元素應(yīng)用函數(shù)后的結(jié)果會(huì)構(gòu)成一個(gè)新的 Stream。例如:
Stream<String> stream = Stream.of("apple", "banana", "cherry");
Stream<Integer> mappedStream = stream.map(s -> s.length()); // 映射為單詞長度
-
扁平映射(FlatMap): flatMap()方法類似于map()方法,不同之處在于它可以將每個(gè)元素映射為一個(gè)流,并將所有流連接成一個(gè)流。這主要用于解決嵌套集合的情況。例如:
List<List<Integer>> nestedList = Arrays.asList(
Arrays.asList(1, 2),
Arrays.asList(3, 4),
Arrays.asList(5, 6)
);
Stream<Integer> flattenedStream = nestedList.stream().flatMap(List::stream); // 扁平化為一個(gè)流
-
截?cái)啵↙imit): limit()方法可以限制 Stream 的大小,只保留前 n 個(gè)元素。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> limitedStream = stream.limit(3); // 只保留前 3 個(gè)元素
-
跳過(Skip): skip()方法可以跳過 Stream 中的前 n 個(gè)元素,返回剩下的元素組成的新 Stream。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> skippedStream = stream.skip(2); // 跳過前 2 個(gè)元素
-
排序(Sorted): sorted()方法用于對(duì) Stream 中的元素進(jìn)行排序,默認(rèn)是自然順序排序。還可以提供自定義的 Comparator 參數(shù)來指定排序規(guī)則。例如:
Stream<Integer> stream = Stream.of(5, 2, 4, 1, 3);
Stream<Integer> sortedStream = stream.sorted(); // 自然順序排序
-
去重(Distinct): distinct()方法用于去除 Stream 中的重復(fù)元素,根據(jù)元素的equals()和hashCode()方法來判斷是否重復(fù)。例如:
Stream<Integer> stream = Stream.of(1, 2, 2, 3, 3, 3);
Stream<Integer> distinctStream = stream.distinct(); // 去重
-
匯總(Collect): collect()方法用于將 Stream 中的元素收集到結(jié)果容器中,如 List、Set、Map 等。可以使用預(yù)定義的 Collectors 類提供的工廠方法來創(chuàng)建收集器,也可以自定義收集器。例如:
Stream<String> stream = Stream.of("apple", "banana", "cherry");
List<String> collectedList = stream.collect(Collectors.toList()); // 收集為 List
-
歸約(Reduce): reduce()方法用于將 Stream 中的元素依次進(jìn)行二元操作,得到一個(gè)最終的結(jié)果。它接受一個(gè)初始值和一個(gè) BinaryOperator 函數(shù)作為參數(shù)。例如:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Optional<Integer> sum = stream.reduce((a, b) -> a + b); // 對(duì)所有元素求和
-
統(tǒng)計(jì)(Summary Statistics): summaryStatistics()方法可以從 Stream 中獲取一些常用的統(tǒng)計(jì)信息,如元素個(gè)數(shù)、最小值、最大值、總和和平均值。例如:
IntStream stream = IntStream.of(1, 2, 3, 4, 5);
IntSummaryStatistics stats = stream.summaryStatistics();
System.out.println("Count: " + stats.getCount());
System.out.println("Min: " + stats.getMin());
System.out.println("Max: " + stats.getMax());
System.out.println("Sum: " + stats.getSum());
System.out.println("Average: " + stats.getAverage());
以上只是 Stream API 提供的一部分常用操作方法,還有許多其他操作方法,如匹配(Match)、查找(Find)、遍歷(ForEach)等
Stream 的中間操作
過濾操作(filter)
過濾操作(filter)是 Stream API 中的一種常用操作方法,它接受一個(gè) Predicate 函數(shù)作為參數(shù),用于過濾 Stream 中的元素。只有滿足 Predicate 條件的元素會(huì)被保留下來,而不滿足條件的元素將被過濾掉。
過濾操作的語法如下:
Stream<T> filter(Predicate<? super T> predicate)
其中,T 表示 Stream 元素的類型,predicate 是一個(gè)函數(shù)式接口 Predicate 的實(shí)例,它的泛型參數(shù)和 Stream 元素類型一致。
使用過濾操作可以根據(jù)自定義的條件來篩選出符合要求的元素,從而對(duì) Stream 進(jìn)行精確的數(shù)據(jù)過濾。
下面是一個(gè)示例,演示如何使用過濾操作篩選出一個(gè)整數(shù)流中的偶數(shù):
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> filteredStream = stream.filter(n -> n % 2 == 0);
filteredStream.forEach(System.out::println); // 輸出結(jié)果: 2 4
在這個(gè)示例中,我們首先創(chuàng)建了一個(gè)包含整數(shù)的 Stream,并調(diào)用 filter() 方法傳入一個(gè) Lambda 表達(dá)式 n -> n % 2 == 0,表示要篩選出偶數(shù)。然后通過 forEach() 方法遍歷輸出結(jié)果。
需要注意的是,過濾操作返回的是一個(gè)新的 Stream 實(shí)例,原始的 Stream 不會(huì)受到改變。這也是 Stream 操作方法的一個(gè)重要特點(diǎn),它們通常返回一個(gè)新的 Stream 實(shí)例,以便進(jìn)行鏈?zhǔn)秸{(diào)用和組合多個(gè)操作步驟。
在實(shí)際應(yīng)用中,過濾操作可以與其他操作方法結(jié)合使用,如映射(map)、排序(sorted)、歸約(reduce)等,以實(shí)現(xiàn)更復(fù)雜的數(shù)據(jù)處理和轉(zhuǎn)換。而過濾操作本身的優(yōu)點(diǎn)在于,可以高效地對(duì)大型數(shù)據(jù)流進(jìn)行篩選,從而提高程序的性能和效率。
映射操作(map)
映射操作(map)是 Stream API 中的一種常用操作方法,它接受一個(gè) Function 函數(shù)作為參數(shù),用于對(duì) Stream 中的每個(gè)元素進(jìn)行映射轉(zhuǎn)換,生成一個(gè)新的 Stream。
映射操作的語法如下:
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
其中,T 表示原始 Stream 的元素類型,R 表示映射后的 Stream 的元素類型,mapper 是一個(gè)函數(shù)式接口 Function 的實(shí)例,它的泛型參數(shù)分別是原始 Stream 元素的類型和映射后的元素類型。
使用映射操作可以對(duì) Stream 中的元素逐個(gè)進(jìn)行處理或轉(zhuǎn)換,從而獲得一個(gè)新的 Stream。這個(gè)過程通常涉及對(duì)每個(gè)元素應(yīng)用傳入的函數(shù),根據(jù)函數(shù)的返回值來構(gòu)建新的元素。
下面是一個(gè)示例,演示如何使用映射操作將一個(gè)字符串流中的每個(gè)字符串轉(zhuǎn)換為其長度:
Stream<String> stream = Stream.of("apple", "banana", "cherry");
Stream<Integer> mappedStream = stream.map(s -> s.length());
mappedStream.forEach(System.out::println); // 輸出結(jié)果: 5 6 6
在這個(gè)示例中,我們首先創(chuàng)建了一個(gè)包含字符串的 Stream,并調(diào)用 map() 方法傳入一個(gè) Lambda 表達(dá)式 s -> s.length(),表示要將每個(gè)字符串轉(zhuǎn)換為其長度。然后通過 forEach() 方法遍歷輸出結(jié)果。
需要注意的是,映射操作返回的是一個(gè)新的 Stream 實(shí)例,原始的 Stream 不會(huì)受到改變。這也是 Stream 操作方法的一個(gè)重要特點(diǎn),它們通常返回一個(gè)新的 Stream 實(shí)例,以便進(jìn)行鏈?zhǔn)秸{(diào)用和組合多個(gè)操作步驟。
在實(shí)際應(yīng)用中,映射操作可以與其他操作方法結(jié)合使用,如過濾(filter)、排序(sorted)、歸約(reduce)等,以實(shí)現(xiàn)更復(fù)雜的數(shù)據(jù)處理和轉(zhuǎn)換。而映射操作本身的優(yōu)點(diǎn)在于,可以通過簡單的函數(shù)變換實(shí)現(xiàn)對(duì)原始數(shù)據(jù)的轉(zhuǎn)換,減少了繁瑣的循環(huán)操作,提高了代碼的可讀性和維護(hù)性。
需要注意的是,映射操作可能引發(fā)空指針異常(NullPointerException),因此在執(zhí)行映射操作時(shí),應(yīng)確保原始 Stream 中不包含空值,并根據(jù)具體情況進(jìn)行空值處理。
排序操作(sorted)
排序操作(sorted)是 Stream API 中的一種常用操作方法,它用于對(duì) Stream 中的元素進(jìn)行排序。排序操作可以按照自然順序或者使用自定義的比較器進(jìn)行排序。
排序操作的語法如下:
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)
第一種語法形式中,sorted() 方法會(huì)根據(jù)元素的自然順序進(jìn)行排序。如果元素實(shí)現(xiàn)了 Comparable 接口并且具備自然順序,那么可以直接調(diào)用該方法進(jìn)行排序。
第二種語法形式中,sorted(Comparator<? super T> comparator) 方法接受一個(gè)比較器(Comparator)作為參數(shù),用于指定元素的排序規(guī)則。通過自定義比較器,可以對(duì)非 Comparable 類型的對(duì)象進(jìn)行排序。
下面是一個(gè)示例,演示如何使用排序操作對(duì)一個(gè)字符串流進(jìn)行排序:
Stream<String> stream = Stream.of("banana", "apple", "cherry");
Stream<String> sortedStream = stream.sorted();
sortedStream.forEach(System.out::println); // 輸出結(jié)果: apple banana cherry
在這個(gè)示例中,我們首先創(chuàng)建了一個(gè)包含字符串的 Stream,并直接調(diào)用 sorted() 方法進(jìn)行排序。然后通過 forEach() 方法遍歷輸出結(jié)果。
需要注意的是,排序操作返回的是一個(gè)新的 Stream 實(shí)例,原始的 Stream 不會(huì)受到改變。這也是 Stream 操作方法的一個(gè)重要特點(diǎn),它們通常返回一個(gè)新的 Stream 實(shí)例,以便進(jìn)行鏈?zhǔn)秸{(diào)用和組合多個(gè)操作步驟。
在實(shí)際應(yīng)用中,排序操作可以與其他操作方法結(jié)合使用,如過濾(filter)、映射(map)、歸約(reduce)等,以實(shí)現(xiàn)更復(fù)雜的數(shù)據(jù)處理和轉(zhuǎn)換。排序操作本身的優(yōu)點(diǎn)在于,可以將數(shù)據(jù)按照特定的順序排列,便于查找、比較和分析。
需要注意的是,排序操作可能會(huì)影響程序的性能,特別是對(duì)于大型數(shù)據(jù)流或者復(fù)雜的排序規(guī)則。因此,在實(shí)際應(yīng)用中,需要根據(jù)具體情況進(jìn)行權(quán)衡和優(yōu)化,選擇合適的算法和數(shù)據(jù)結(jié)構(gòu)來提高排序的效率。
截?cái)嗖僮鳎╨imit 和 skip)
截?cái)嗖僮鳎╨imit和skip)是 Stream API 中常用的操作方法,用于在處理流的過程中對(duì)元素進(jìn)行截?cái)唷?/p>
-
limit(n):保留流中的前n個(gè)元素,返回一個(gè)包含最多n個(gè)元素的新流。如果流中元素少于n個(gè),則返回原始流。 -
skip(n):跳過流中的前n個(gè)元素,返回一個(gè)包含剩余元素的新流。如果流中元素少于n個(gè),則返回一個(gè)空流。
下面分別詳細(xì)介紹這兩個(gè)方法的使用。
limit(n) 方法示例:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> limitedStream = stream.limit(3);
limitedStream.forEach(System.out::println); // 輸出結(jié)果: 1 2 3
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 Stream,并調(diào)用 limit(3) 方法來保留前三個(gè)元素。然后使用 forEach() 方法遍歷輸出結(jié)果。
skip(n) 方法示例:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
Stream<Integer> skippedStream = stream.skip(2);
skippedStream.forEach(System.out::println); // 輸出結(jié)果: 3 4 5
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 Stream,并調(diào)用 skip(2) 方法來跳過前兩個(gè)元素。然后使用 forEach() 方法遍歷輸出結(jié)果。
需要注意的是,截?cái)嗖僮鞣祷氐氖且粋€(gè)新的 Stream 實(shí)例,原始的 Stream 不會(huì)受到改變。這也是 Stream 操作方法的一個(gè)重要特點(diǎn),它們通常返回一個(gè)新的 Stream 實(shí)例,以便進(jìn)行鏈?zhǔn)秸{(diào)用和組合多個(gè)操作步驟。
截?cái)嗖僮髟谔幚泶笮蛿?shù)據(jù)流或需要對(duì)數(shù)據(jù)進(jìn)行切分和分頁顯示的場景中非常有用。通過限制或跳過指定數(shù)量的元素,可以控制數(shù)據(jù)的大小和范圍,提高程序的性能并減少不必要的計(jì)算。
需要注意的是,在使用截?cái)嗖僮鲿r(shí)需要注意流的有界性。如果流是無界的(例如 Stream.generate()),那么使用 limit() 方法可能導(dǎo)致程序陷入無限循環(huán),而使用 skip() 方法則沒有意義。
Stream 的終端操作
forEach 和 peek
forEach和peek都是Stream API中用于遍歷流中元素的操作方法,它們?cè)谔幚砹鞯倪^程中提供了不同的功能和使用場景。
-
forEach: forEach是一個(gè)終端操作方法,它接受一個(gè)Consumer函數(shù)作為參數(shù),對(duì)流中的每個(gè)元素執(zhí)行該函數(shù)。它沒有返回值,因此無法將操作結(jié)果傳遞給后續(xù)操作。forEach會(huì)遍歷整個(gè)流,對(duì)每個(gè)元素執(zhí)行相同的操作。
示例代碼:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.stream()
.forEach(System.out::println);
這個(gè)示例中,我們創(chuàng)建了一個(gè)包含字符串的List,并通過stream()方法將其轉(zhuǎn)換為流。然后使用forEach方法遍歷輸出每個(gè)元素的值。
-
peek: peek是一個(gè)中間操作方法,它接受一個(gè)Consumer函數(shù)作為參數(shù),對(duì)流中的每個(gè)元素執(zhí)行該函數(shù)。與forEach不同的是,peek方法會(huì)返回一個(gè)新的流,該流中的元素和原始流中的元素相同。
示例代碼:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> upperCaseNames = names.stream()
.map(String::toUpperCase)
.peek(System.out::println)
.collect(Collectors.toList());
在這個(gè)示例中,我們首先將List轉(zhuǎn)換為流,并通過map方法將每個(gè)元素轉(zhuǎn)換為大寫字母。然后使用peek方法在轉(zhuǎn)換之前輸出每個(gè)元素的值。最后通過collect方法將元素收集到一個(gè)新的List中。
需要注意的是,無論是forEach還是peek,它們都是用于在流的處理過程中執(zhí)行操作。區(qū)別在于forEach是終端操作,不返回任何結(jié)果,而peek是中間操作,可以和其他操作方法進(jìn)行組合和鏈?zhǔn)秸{(diào)用。
根據(jù)使用場景和需求,選擇使用forEach或peek來遍歷流中的元素。如果只是需要遍歷輸出元素,不需要操作結(jié)果,則使用forEach。如果需要在遍歷過程中執(zhí)行一些其他操作,并將元素傳遞給后續(xù)操作,則使用peek。
聚合操作(reduce 和 collect)
reduce和collect都是Stream API中用于聚合操作的方法,它們可以將流中的元素進(jìn)行匯總、計(jì)算和收集。
-
reduce: reduce是一個(gè)終端操作方法,它接受一個(gè)BinaryOperator函數(shù)作為參數(shù),對(duì)流中的元素逐個(gè)進(jìn)行合并操作,最終得到一個(gè)結(jié)果。該方法會(huì)將流中的第一個(gè)元素作為初始值,然后將初始值與下一個(gè)元素傳遞給BinaryOperator函數(shù)進(jìn)行計(jì)算,得到的結(jié)果再與下一個(gè)元素進(jìn)行計(jì)算,以此類推,直到遍歷完所有元素。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> sum = numbers.stream()
.reduce((a, b) -> a + b);
sum.ifPresent(System.out::println); // 輸出結(jié)果: 15
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的List,并通過stream()方法將其轉(zhuǎn)換為流。然后使用reduce方法對(duì)流中的元素進(jìn)行求和操作,將每個(gè)元素依次相加,得到結(jié)果15。
-
collect: collect是一個(gè)終端操作方法,它接受一個(gè)Collector接口的實(shí)現(xiàn)作為參數(shù),對(duì)流中的元素進(jìn)行收集和匯總的操作。Collector接口定義了一系列用于聚合操作的方法,例如收集元素到List、Set、Map等容器中,或進(jìn)行字符串連接、分組、計(jì)數(shù)等操作。
示例代碼:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
String joinedNames = names.stream()
.collect(Collectors.joining(", "));
System.out.println(joinedNames); // 輸出結(jié)果: Alice, Bob, Charlie
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含字符串的List,并通過stream()方法將其轉(zhuǎn)換為流。然后使用collect方法將流中的元素連接成一個(gè)字符串,每個(gè)元素之間使用逗號(hào)和空格分隔。
需要注意的是,reduce和collect都是終端操作,它們都會(huì)觸發(fā)流的遍歷和處理。不同的是,reduce方法用于對(duì)流中的元素進(jìn)行累積計(jì)算,得到一個(gè)最終結(jié)果;而collect方法用于對(duì)流中的元素進(jìn)行收集和匯總,得到一個(gè)容器或其他自定義的結(jié)果。
在選擇使用reduce還是collect時(shí),可以根據(jù)具體需求和操作類型來決定。如果需要對(duì)流中的元素進(jìn)行某種計(jì)算和合并操作,得到一個(gè)結(jié)果,則使用reduce。如果需要將流中的元素收集到一個(gè)容器中,進(jìn)行匯總、分組、計(jì)數(shù)等操作,則使用collect。
匹配操作(allMatch、anyMatch 和 noneMatch)
在 Stream API 中,allMatch、anyMatch 和 noneMatch 是用于進(jìn)行匹配操作的方法,它們可以用來檢查流中的元素是否滿足特定的條件。
-
allMatch: allMatch 方法用于判斷流中的所有元素是否都滿足給定的條件。當(dāng)流中的所有元素都滿足條件時(shí),返回 true;如果存在一個(gè)元素不滿足條件,則返回 false。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
boolean allEven = numbers.stream()
.allMatch(n -> n % 2 == 0);
System.out.println(allEven); // 輸出結(jié)果: false
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 allMatch 方法判斷流中的元素是否都是偶數(shù)。由于列表中存在奇數(shù),所以返回 false。
-
anyMatch: anyMatch 方法用于判斷流中是否存在至少一個(gè)元素滿足給定的條件。當(dāng)流中至少有一個(gè)元素滿足條件時(shí),返回 true;如果沒有元素滿足條件,則返回 false。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
boolean hasEven = numbers.stream()
.anyMatch(n -> n % 2 == 0);
System.out.println(hasEven); // 輸出結(jié)果: true
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 anyMatch 方法判斷流中是否存在偶數(shù)。由于列表中存在偶數(shù),所以返回 true。
-
noneMatch: noneMatch 方法用于判斷流中的所有元素是否都不滿足給定的條件。當(dāng)流中沒有元素滿足條件時(shí),返回 true;如果存在一個(gè)元素滿足條件,則返回 false。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
boolean noneNegative = numbers.stream()
.noneMatch(n -> n < 0);
System.out.println(noneNegative); // 輸出結(jié)果: true
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 noneMatch 方法判斷流中的元素是否都是非負(fù)數(shù)。由于列表中的元素都是非負(fù)數(shù),所以返回 true。
需要注意的是,allMatch、anyMatch 和 noneMatch 都是終端操作,它們會(huì)遍歷流中的元素直到滿足條件或處理完所有元素。在性能上,allMatch 和 noneMatch 在第一個(gè)不匹配的元素處可以立即返回結(jié)果,而 anyMatch 在找到第一個(gè)匹配的元素時(shí)就可以返回結(jié)果。
查找操作(findFirst 和 findAny)
在 Stream API 中,findFirst 和 findAny 是用于查找操作的方法,它們可以用來從流中獲取滿足特定條件的元素。
-
findFirst: findFirst 方法用于返回流中的第一個(gè)元素。它返回一個(gè) Optional 對(duì)象,如果流為空,則返回一個(gè)空的 Optional;如果流非空,則返回流中的第一個(gè)元素的 Optional。
示例代碼:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
Optional<String> first = names.stream()
.findFirst();
first.ifPresent(System.out::println); // 輸出結(jié)果: Alice
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含字符串的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 findFirst 方法獲取流中的第一個(gè)元素,并使用 ifPresent 方法判斷 Optional 是否包含值,并進(jìn)行相應(yīng)的處理。
-
findAny: findAny 方法用于返回流中的任意一個(gè)元素。它返回一個(gè) Optional 對(duì)象,如果流為空,則返回一個(gè)空的 Optional;如果流非空,則返回流中的任意一個(gè)元素的 Optional。在順序流中,通常會(huì)返回第一個(gè)元素;而在并行流中,由于多線程的處理,可能返回不同的元素。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> any = numbers.stream()
.filter(n -> n % 2 == 0)
.findAny();
any.ifPresent(System.out::println); // 輸出結(jié)果: 2 或 4(取決于并行處理的結(jié)果)
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 filter 方法篩選出偶數(shù),再使用 findAny 方法獲取任意一個(gè)偶數(shù),最后使用 ifPresent 方法判斷 Optional 是否包含值,并進(jìn)行相應(yīng)的處理。
需要注意的是,findAny 在并行流中會(huì)更有優(yōu)勢,因?yàn)樵诙嗑€程處理時(shí),可以返回最先找到的元素,提高效率。而在順序流中,findAny 的性能與 findFirst 相當(dāng)。
統(tǒng)計(jì)操作(count、max 和 min)
在 Stream API 中,count、max 和 min 是用于統(tǒng)計(jì)操作的方法,它們可以用來獲取流中元素的數(shù)量、最大值和最小值。
-
count: count 方法用于返回流中元素的數(shù)量。它返回一個(gè) long 類型的值,表示流中的元素個(gè)數(shù)。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
long count = numbers.stream()
.count();
System.out.println(count); // 輸出結(jié)果: 5
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 count 方法獲取流中元素的數(shù)量,并將結(jié)果輸出。
-
max: max 方法用于返回流中的最大值。它返回一個(gè) Optional 對(duì)象,如果流為空,則返回一個(gè)空的 Optional;如果流非空,則返回流中的最大值的 Optional。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> max = numbers.stream()
.max(Integer::compareTo);
max.ifPresent(System.out::println); // 輸出結(jié)果: 5
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 max 方法獲取流中的最大值,并使用 ifPresent 方法判斷 Optional 是否包含值,并進(jìn)行相應(yīng)的處理。
-
min: min 方法用于返回流中的最小值。它返回一個(gè) Optional 對(duì)象,如果流為空,則返回一個(gè)空的 Optional;如果流非空,則返回流中的最小值的 Optional。
示例代碼:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> min = numbers.stream()
.min(Integer::compareTo);
min.ifPresent(System.out::println); // 輸出結(jié)果: 1
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。然后使用 min 方法獲取流中的最小值,并使用 ifPresent 方法判斷 Optional 是否包含值,并進(jìn)行相應(yīng)的處理。
這些統(tǒng)計(jì)操作方法提供了一種便捷的方式來對(duì)流中的元素進(jìn)行數(shù)量、最大值和最小值的計(jì)算。通過返回 Optional 對(duì)象,可以避免空指針異常。
并行流
什么是并行流
并行流是 Java 8 Stream API 中的一個(gè)特性。它可以將一個(gè)流的操作在多個(gè)線程上并行執(zhí)行,以提高處理大量數(shù)據(jù)時(shí)的性能。
在傳統(tǒng)的順序流中,所有的操作都是在單個(gè)線程上按照順序執(zhí)行的。而并行流則會(huì)將流的元素分成多個(gè)小塊,并在多個(gè)線程上并行處理這些小塊,最后將結(jié)果合并起來。這樣可以充分利用多核處理器的優(yōu)勢,加快數(shù)據(jù)處理的速度。
要將一個(gè)順序流轉(zhuǎn)換為并行流,只需調(diào)用流的 parallel() 方法即可。示例代碼如下所示:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.stream()
.parallel()
.forEach(System.out::println);
在這個(gè)示例中,我們創(chuàng)建了一個(gè)包含整數(shù)的 List,并通過 stream() 方法將其轉(zhuǎn)換為流。接著調(diào)用 parallel() 方法將流轉(zhuǎn)換為并行流,然后使用 forEach 方法遍歷流中的元素并輸出。
需要注意的是,并行流的使用并不總是適合所有情況。并行流的優(yōu)勢主要體現(xiàn)在數(shù)據(jù)量較大、處理時(shí)間較長的場景下。對(duì)于小規(guī)模數(shù)據(jù)和簡單的操作,順序流可能更加高效。在選擇使用并行流時(shí),需要根據(jù)具體情況進(jìn)行評(píng)估和測試,以確保獲得最佳的性能。
此外,還需要注意并行流在某些情況下可能引入線程安全的問題。如果多個(gè)線程同時(shí)訪問共享的可變狀態(tài),可能會(huì)導(dǎo)致數(shù)據(jù)競爭和不確定的結(jié)果。因此,在處理并行流時(shí),應(yīng)當(dāng)避免共享可變狀態(tài),或采用適當(dāng)?shù)耐酱胧﹣泶_保線程安全。
如何使用并行流提高性能
使用并行流可以通過利用多線程并行處理數(shù)據(jù),從而提高程序的執(zhí)行性能。下面是一些使用并行流提高性能的常見方法:
-
創(chuàng)建并行流:要?jiǎng)?chuàng)建一個(gè)并行流,只需在普通流上調(diào)用 parallel()方法。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Stream<Integer> parallelStream = numbers.parallelStream();
-
利用任務(wù)并行性:并行流會(huì)將數(shù)據(jù)分成多個(gè)小塊,并在多個(gè)線程上并行處理這些小塊。這樣可以充分利用多核處理器的優(yōu)勢。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.parallelStream()
.map(n -> compute(n)) // 在多個(gè)線程上并行處理計(jì)算
.forEach(System.out::println);
在這個(gè)示例中,使用 map 方法對(duì)流中的每個(gè)元素進(jìn)行計(jì)算。由于并行流的特性,計(jì)算操作會(huì)在多個(gè)線程上并行執(zhí)行,提高了計(jì)算的效率。
-
避免共享可變狀態(tài):在并行流中,多個(gè)線程會(huì)同時(shí)操作數(shù)據(jù)。如果共享可變狀態(tài)(如全局變量)可能導(dǎo)致數(shù)據(jù)競爭和不確定的結(jié)果。因此,避免在并行流中使用共享可變狀態(tài),或者采取適當(dāng)?shù)耐酱胧﹣泶_保線程安全。
-
使用合適的操作:一些操作在并行流中的性能表現(xiàn)更好,而另一些操作則可能導(dǎo)致性能下降。一般來說,在并行流中使用基于聚合的操作(如
reduce、collect)和無狀態(tài)轉(zhuǎn)換操作(如map、filter)的性能較好,而有狀態(tài)轉(zhuǎn)換操作(如sorted)可能會(huì)導(dǎo)致性能下降。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// good performance
int sum = numbers.parallelStream()
.reduce(0, Integer::sum);
// good performance
List<Integer> evenNumbers = numbers.parallelStream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
// potential performance degradation
List<Integer> sortedNumbers = numbers.parallelStream()
.sorted()
.collect(Collectors.toList());
在這個(gè)示例中,reduce 和 filter 的操作在并行流中具有良好的性能,而 sorted 操作可能導(dǎo)致性能下降。
除了上述方法,還應(yīng)根據(jù)具體情況進(jìn)行評(píng)估和測試,并行流是否能夠提高性能。有時(shí)候,并行流的開銷(如線程的創(chuàng)建和銷毀、數(shù)據(jù)切割和合并等)可能超過了其帶來的性能提升。因此,在選擇使用并行流時(shí),應(yīng)該根據(jù)數(shù)據(jù)量和操作復(fù)雜度等因素進(jìn)行綜合考慮,以確保獲得最佳的性能提升。
并行流的適用場景和注意事項(xiàng)
-
大規(guī)模數(shù)據(jù)集:當(dāng)需要處理大規(guī)模數(shù)據(jù)集時(shí),使用并行流可以充分利用多核處理器的優(yōu)勢,提高程序的執(zhí)行效率。并行流將數(shù)據(jù)切分成多個(gè)小塊,并在多個(gè)線程上并行處理這些小塊,從而縮短了處理時(shí)間。
-
復(fù)雜的計(jì)算操作:對(duì)于復(fù)雜的計(jì)算操作,使用并行流可以加速計(jì)算過程。由于并行流能夠?qū)⒂?jì)算操作分配到多個(gè)線程上并行執(zhí)行,因此可以有效地利用多核處理器的計(jì)算能力,提高計(jì)算的速度。
-
無狀態(tài)轉(zhuǎn)換操作:并行流在執(zhí)行無狀態(tài)轉(zhuǎn)換操作(如
map、filter)時(shí)表現(xiàn)較好。這類操作不依賴于其他元素的狀態(tài),每個(gè)元素的處理是相互獨(dú)立的,可以很容易地進(jìn)行并行處理。
并行流的注意事項(xiàng)包括:
-
線程安全問題:并行流的操作是在多個(gè)線程上并行執(zhí)行的,因此需要注意線程安全問題。如果多個(gè)線程同時(shí)訪問共享的可變狀態(tài),可能會(huì)導(dǎo)致數(shù)據(jù)競爭和不確定的結(jié)果。在處理并行流時(shí),應(yīng)避免共享可變狀態(tài),或者采用適當(dāng)?shù)耐酱胧﹣泶_保線程安全。
-
性能評(píng)估和測試:并行流的性能提升并不總是明顯的。在選擇使用并行流時(shí),應(yīng)根據(jù)具體情況進(jìn)行評(píng)估和測試,以確保獲得最佳的性能提升。有時(shí),并行流的開銷(如線程的創(chuàng)建和銷毀、數(shù)據(jù)切割和合并等)可能超過了其帶來的性能提升。
-
并發(fā)操作限制:某些操作在并行流中的性能表現(xiàn)可能較差,或者可能導(dǎo)致結(jié)果出現(xiàn)錯(cuò)誤。例如,在并行流中使用有狀態(tài)轉(zhuǎn)換操作(如
sorted)可能導(dǎo)致性能下降或結(jié)果出現(xiàn)錯(cuò)誤。在使用并行流時(shí),應(yīng)注意避免這類操作,或者在需要時(shí)采取適當(dāng)?shù)奶幚泶胧?/p> -
內(nèi)存消耗:并行流需要將數(shù)據(jù)分成多個(gè)小塊進(jìn)行并行處理,這可能導(dǎo)致額外的內(nèi)存消耗。在處理大規(guī)模數(shù)據(jù)集時(shí),應(yīng)確保系統(tǒng)有足夠的內(nèi)存來支持并行流的執(zhí)行,以避免內(nèi)存溢出等問題。
實(shí)踐應(yīng)用示例
使用 Stream 處理集合數(shù)據(jù)
-
篩選出長度大于等于5的字符串,并打印輸出:
List<String> list = Arrays.asList("apple", "banana", "orange", "grapefruit", "kiwi");
list.stream()
.filter(s -> s.length() >= 5)
.forEach(System.out::println);
輸出結(jié)果:
banana
orange
grapefruit
-
將集合中的每個(gè)字符串轉(zhuǎn)換為大寫,并收集到新的列表中:
List<String> list = Arrays.asList("apple", "banana", "orange", "grapefruit", "kiwi");
List<String> resultList = list.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
System.out.println(resultList);
輸出結(jié)果:
[APPLE, BANANA, ORANGE, GRAPEFRUIT, KIWI]
-
統(tǒng)計(jì)集合中以字母"a"開頭的字符串的數(shù)量:
List<String> list = Arrays.asList("apple", "banana", "orange", "grapefruit", "kiwi");
long count = list.stream()
.filter(s -> s.startsWith("a"))
.count();
System.out.println(count);
輸出結(jié)果:
1
-
使用并行流來提高處理速度,篩選出長度小于等于5的字符串,并打印輸出:
List<String> list = Arrays.asList("apple", "banana", "orange", "grapefruit", "kiwi");
list.parallelStream()
.filter(s -> s.length() <= 5)
.forEach(System.out::println);
輸出結(jié)果:
apple
kiwi
-
使用 Stream 對(duì)集合中的整數(shù)求和:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream()
.mapToInt(Integer::intValue)
.sum();
System.out.println(sum);
輸出結(jié)果:
15
以上示例展示了如何使用 Stream 對(duì)集合數(shù)據(jù)進(jìn)行篩選、轉(zhuǎn)換、統(tǒng)計(jì)等操作。通過鏈?zhǔn)秸{(diào)用 Stream 的中間操作和終端操作。
使用 Stream 進(jìn)行文件操作
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.stream.Stream;
public class FileStreamExample {
public static void main(String[] args) {
String fileName = "file.txt";
// 讀取文件內(nèi)容并創(chuàng)建 Stream
try (Stream<String> stream = Files.lines(Paths.get(fileName))) {
// 打印文件的每一行內(nèi)容
stream.forEach(System.out::println);
// 統(tǒng)計(jì)文件的行數(shù)
long count = stream.count();
System.out.println("總行數(shù):" + count);
// 篩選包含關(guān)鍵詞的行并打印輸出
stream.filter(line -> line.contains("keyword"))
.forEach(System.out::println);
// 將文件內(nèi)容轉(zhuǎn)換為大寫并打印輸出
stream.map(String::toUpperCase)
.forEach(System.out::println);
// 將文件內(nèi)容收集到 List 中
List<String> lines = stream.collect(Collectors.toList());
System.out.println(lines);
} catch (IOException e) {
e.printStackTrace();
}
}
}
在上面的代碼中,首先指定了要讀取的文件名 file.txt。然后使用 Files.lines() 方法讀取文件的每一行內(nèi)容,并創(chuàng)建一個(gè) Stream 對(duì)象。接下來,我們對(duì) Stream 進(jìn)行一些操作:
-
使用 forEach()方法打印文件的每一行內(nèi)容。 -
使用 count()方法統(tǒng)計(jì)文件的行數(shù)。 -
使用 filter()方法篩選出包含關(guān)鍵詞的行,并打印輸出。 -
使用 map()方法將文件內(nèi)容轉(zhuǎn)換為大寫,并打印輸出。 -
使用 collect()方法將文件內(nèi)容收集到 List 中。
請(qǐng)根據(jù)實(shí)際需求修改代碼中的文件名、操作內(nèi)容和結(jié)果處理方式。需要注意的是,在使用完 Stream 后,應(yīng)及時(shí)關(guān)閉文件資源,可以使用 try-with-resources 語句塊來自動(dòng)關(guān)閉文件。另外,請(qǐng)?zhí)幚砜赡艹霈F(xiàn)的 IOException 異常。
使用 Stream 實(shí)現(xiàn)數(shù)據(jù)轉(zhuǎn)換和篩選
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamExample {
public static void main(String[] args) {
List<String> names = Arrays.asList("Amy", "Bob", "Charlie", "David", "Eva");
// 轉(zhuǎn)換為大寫并篩選出長度大于3的名稱
List<String> result = names.stream()
.map(String::toUpperCase)
.filter(name -> name.length() > 3)
.collect(Collectors.toList());
// 打印結(jié)果
result.forEach(System.out::println);
}
}
在上述代碼中,我們首先創(chuàng)建了一個(gè)包含一些名字的列表。然后使用 Stream 對(duì)列表進(jìn)行操作:
-
使用 stream()方法將列表轉(zhuǎn)換為一個(gè) Stream。 -
使用 map()方法將每個(gè)名稱轉(zhuǎn)換為大寫。 -
使用 filter()方法篩選出長度大于3的名稱。 -
使用 collect()方法將篩選后的結(jié)果收集到一個(gè)新的列表中。
最后,我們使用 forEach() 方法打印結(jié)果列表中的每個(gè)名稱。