
Spark性能優(yōu)化指南——高級(jí)篇
繼基礎(chǔ)篇講解了每個(gè)Spark開(kāi)發(fā)人員都必須熟知的開(kāi)發(fā)調(diào)優(yōu)與資源調(diào)優(yōu)之后,本文作為《Spark性能優(yōu)化指南》的高級(jí)篇,將深入分析數(shù)據(jù)傾斜調(diào)優(yōu)與shuffle調(diào)優(yōu),以解決更加棘手的性能問(wèn)題。
調(diào)優(yōu)概述
有的時(shí)候,我們可能會(huì)遇到大數(shù)據(jù)計(jì)算中一個(gè)最棘手的問(wèn)題——數(shù)據(jù)傾斜,此時(shí)Spark作業(yè)的性能會(huì)比期望差很多。數(shù)據(jù)傾斜調(diào)優(yōu),就是使用各種技術(shù)方案解決不同類型的數(shù)據(jù)傾斜問(wèn)題,以保證Spark作業(yè)的性能。
數(shù)據(jù)傾斜發(fā)生時(shí)的現(xiàn)象
絕大多數(shù)task執(zhí)行得都非常快,但個(gè)別task執(zhí)行極慢。比如,總共有1000個(gè)task,997個(gè)task都在1分鐘之內(nèi)執(zhí)行完了,但是剩余兩三個(gè)task卻要一兩個(gè)小時(shí)。這種情況很常見(jiàn)。
原本能夠正常執(zhí)行的Spark作業(yè),某天突然報(bào)出OOM(內(nèi)存溢出)異常,觀察異常棧,是我們寫的業(yè)務(wù)代碼造成的。這種情況比較少見(jiàn)。
數(shù)據(jù)傾斜發(fā)生的原理
數(shù)據(jù)傾斜的原理很簡(jiǎn)單:在進(jìn)行shuffle的時(shí)候,必須將各個(gè)節(jié)點(diǎn)上相同的key拉取到某個(gè)節(jié)點(diǎn)上的一個(gè)task來(lái)進(jìn)行處理,比如按照key進(jìn)行聚合或join等操作。此時(shí)如果某個(gè)key對(duì)應(yīng)的數(shù)據(jù)量特別大的話,就會(huì)發(fā)生數(shù)據(jù)傾斜。比如大部分key對(duì)應(yīng)10條數(shù)據(jù),但是個(gè)別key卻對(duì)應(yīng)了100萬(wàn)條數(shù)據(jù),那么大部分task可能就只會(huì)分配到10條數(shù)據(jù),然后1秒鐘就運(yùn)行完了;但是個(gè)別task可能分配到了100萬(wàn)數(shù)據(jù),要運(yùn)行一兩個(gè)小時(shí)。因此,整個(gè)Spark作業(yè)的運(yùn)行進(jìn)度是由運(yùn)行時(shí)間最長(zhǎng)的那個(gè)task決定的。
因此出現(xiàn)數(shù)據(jù)傾斜的時(shí)候,Spark作業(yè)看起來(lái)會(huì)運(yùn)行得非常緩慢,甚至可能因?yàn)槟硞€(gè)task處理的數(shù)據(jù)量過(guò)大導(dǎo)致內(nèi)存溢出。
下圖就是一個(gè)很清晰的例子:hello這個(gè)key,在三個(gè)節(jié)點(diǎn)上對(duì)應(yīng)了總共7條數(shù)據(jù),這些數(shù)據(jù)都會(huì)被拉取到同一個(gè)task中進(jìn)行處理;而world和you這兩個(gè)key分別才對(duì)應(yīng)1條數(shù)據(jù),所以另外兩個(gè)task只要分別處理1條數(shù)據(jù)即可。此時(shí)第一個(gè)task的運(yùn)行時(shí)間可能是另外兩個(gè)task的7倍,而整個(gè)stage的運(yùn)行速度也由運(yùn)行最慢的那個(gè)task所決定。
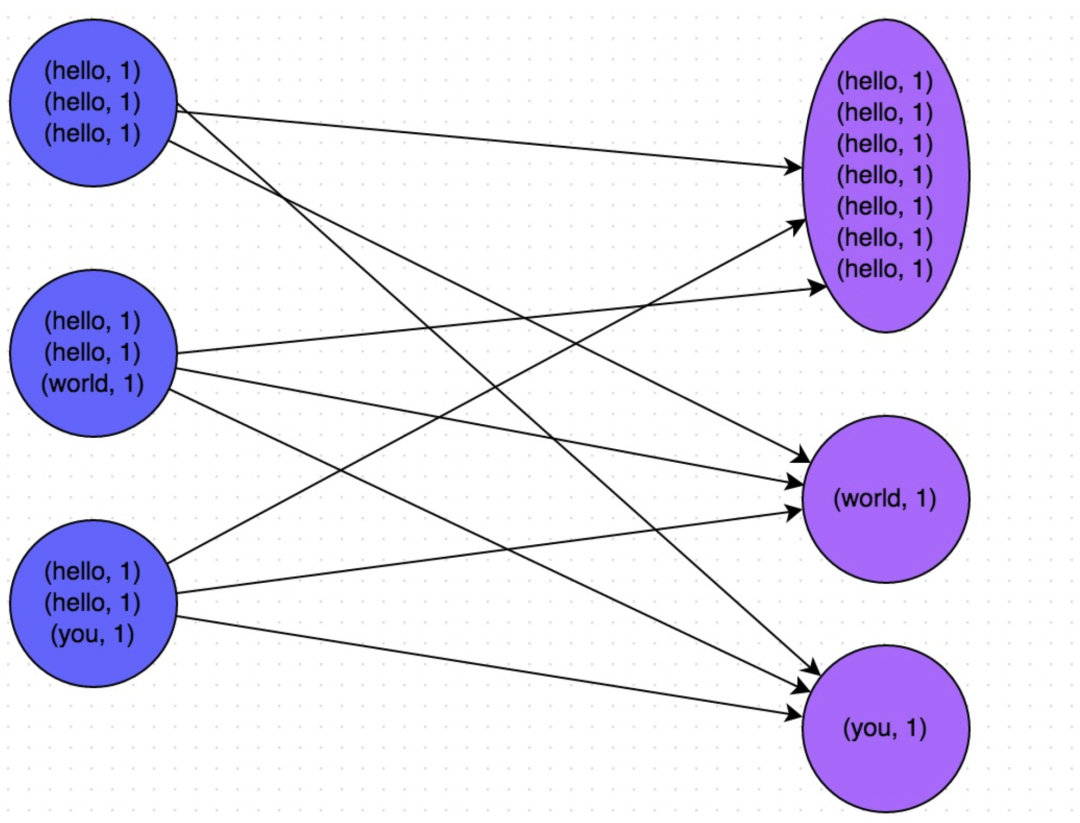
如何定位導(dǎo)致數(shù)據(jù)傾斜的代碼
數(shù)據(jù)傾斜只會(huì)發(fā)生在shuffle過(guò)程中。這里給大家羅列一些常用的并且可能會(huì)觸發(fā)shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。出現(xiàn)數(shù)據(jù)傾斜時(shí),可能就是你的代碼中使用了這些算子中的某一個(gè)所導(dǎo)致的。
某個(gè)task執(zhí)行特別慢的情況
首先要看的,就是數(shù)據(jù)傾斜發(fā)生在第幾個(gè)stage中。
如果是用yarn-client模式提交,那么本地是直接可以看到log的,可以在log中找到當(dāng)前運(yùn)行到了第幾個(gè)stage;如果是用yarn-cluster模式提交,則可以通過(guò)Spark Web UI來(lái)查看當(dāng)前運(yùn)行到了第幾個(gè)stage。此外,無(wú)論是使用yarn-client模式還是yarn-cluster模式,我們都可以在Spark Web UI上深入看一下當(dāng)前這個(gè)stage各個(gè)task分配的數(shù)據(jù)量,從而進(jìn)一步確定是不是task分配的數(shù)據(jù)不均勻?qū)е铝藬?shù)據(jù)傾斜。
比如下圖中,倒數(shù)第三列顯示了每個(gè)task的運(yùn)行時(shí)間。明顯可以看到,有的task運(yùn)行特別快,只需要幾秒鐘就可以運(yùn)行完;而有的task運(yùn)行特別慢,需要幾分鐘才能運(yùn)行完,此時(shí)單從運(yùn)行時(shí)間上看就已經(jīng)能夠確定發(fā)生數(shù)據(jù)傾斜了。此外,倒數(shù)第一列顯示了每個(gè)task處理的數(shù)據(jù)量,明顯可以看到,運(yùn)行時(shí)間特別短的task只需要處理幾百KB的數(shù)據(jù)即可,而運(yùn)行時(shí)間特別長(zhǎng)的task需要處理幾千KB的數(shù)據(jù),處理的數(shù)據(jù)量差了10倍。此時(shí)更加能夠確定是發(fā)生了數(shù)據(jù)傾斜。
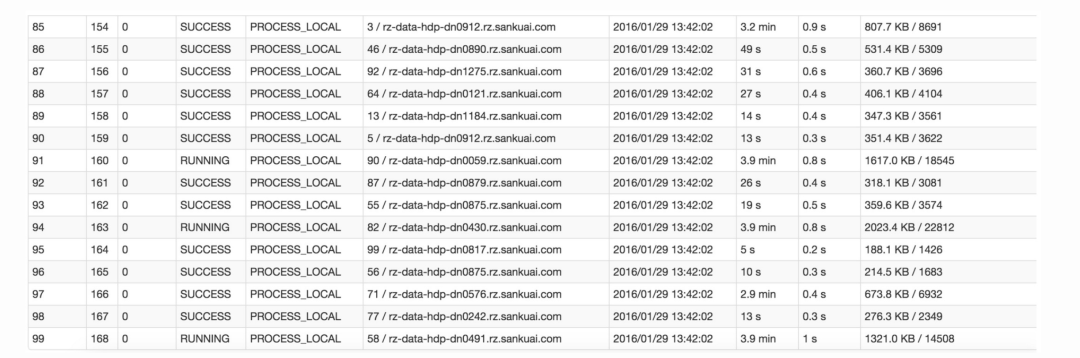
知道數(shù)據(jù)傾斜發(fā)生在哪一個(gè)stage之后,接著我們就需要根據(jù)stage劃分原理,推算出來(lái)發(fā)生傾斜的那個(gè)stage對(duì)應(yīng)代碼中的哪一部分,這部分代碼中肯定會(huì)有一個(gè)shuffle類算子。精準(zhǔn)推算stage與代碼的對(duì)應(yīng)關(guān)系,需要對(duì)Spark的源碼有深入的理解,這里我們可以介紹一個(gè)相對(duì)簡(jiǎn)單實(shí)用的推算方法:只要看到Spark代碼中出現(xiàn)了一個(gè)shuffle類算子或者是Spark SQL的SQL語(yǔ)句中出現(xiàn)了會(huì)導(dǎo)致shuffle的語(yǔ)句(比如group by語(yǔ)句),那么就可以判定,以那個(gè)地方為界限劃分出了前后兩個(gè)stage。
這里我們就以Spark最基礎(chǔ)的入門程序——單詞計(jì)數(shù)來(lái)舉例,如何用最簡(jiǎn)單的方法大致推算出一個(gè)stage對(duì)應(yīng)的代碼。如下示例,在整個(gè)代碼中,只有一個(gè)reduceByKey是會(huì)發(fā)生shuffle的算子,因此就可以認(rèn)為,以這個(gè)算子為界限,會(huì)劃分出前后兩個(gè)stage。* stage0,主要是執(zhí)行從textFile到map操作,以及執(zhí)行shuffle write操作。shuffle write操作,我們可以簡(jiǎn)單理解為對(duì)pairs RDD中的數(shù)據(jù)進(jìn)行分區(qū)操作,每個(gè)task處理的數(shù)據(jù)中,相同的key會(huì)寫入同一個(gè)磁盤文件內(nèi)。* stage1,主要是執(zhí)行從reduceByKey到collect操作,stage1的各個(gè)task一開(kāi)始運(yùn)行,就會(huì)首先執(zhí)行shuffle read操作。執(zhí)行shuffle read操作的task,會(huì)從stage0的各個(gè)task所在節(jié)點(diǎn)拉取屬于自己處理的那些key,然后對(duì)同一個(gè)key進(jìn)行全局性的聚合或join等操作,在這里就是對(duì)key的value值進(jìn)行累加。stage1在執(zhí)行完reduceByKey算子之后,就計(jì)算出了最終的wordCounts RDD,然后會(huì)執(zhí)行collect算子,將所有數(shù)據(jù)拉取到Driver上,供我們遍歷和打印輸出。
val conf = new SparkConf()
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://...")
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.collect().foreach(println(_))
通過(guò)對(duì)單詞計(jì)數(shù)程序的分析,希望能夠讓大家了解最基本的stage劃分的原理,以及stage劃分后shuffle操作是如何在兩個(gè)stage的邊界處執(zhí)行的。然后我們就知道如何快速定位出發(fā)生數(shù)據(jù)傾斜的stage對(duì)應(yīng)代碼的哪一個(gè)部分了。比如我們?cè)赟park Web UI或者本地log中發(fā)現(xiàn),stage1的某幾個(gè)task執(zhí)行得特別慢,判定stage1出現(xiàn)了數(shù)據(jù)傾斜,那么就可以回到代碼中定位出stage1主要包括了reduceByKey這個(gè)shuffle類算子,此時(shí)基本就可以確定是由educeByKey算子導(dǎo)致的數(shù)據(jù)傾斜問(wèn)題。比如某個(gè)單詞出現(xiàn)了100萬(wàn)次,其他單詞才出現(xiàn)10次,那么stage1的某個(gè)task就要處理100萬(wàn)數(shù)據(jù),整個(gè)stage的速度就會(huì)被這個(gè)task拖慢。
某個(gè)task莫名其妙內(nèi)存溢出的情況
這種情況下去定位出問(wèn)題的代碼就比較容易了。我們建議直接看yarn-client模式下本地log的異常棧,或者是通過(guò)YARN查看yarn-cluster模式下的log中的異常棧。一般來(lái)說(shuō),通過(guò)異常棧信息就可以定位到你的代碼中哪一行發(fā)生了內(nèi)存溢出。然后在那行代碼附近找找,一般也會(huì)有shuffle類算子,此時(shí)很可能就是這個(gè)算子導(dǎo)致了數(shù)據(jù)傾斜。
但是大家要注意的是,不能單純靠偶然的內(nèi)存溢出就判定發(fā)生了數(shù)據(jù)傾斜。因?yàn)樽约壕帉懙拇a的bug,以及偶然出現(xiàn)的數(shù)據(jù)異常,也可能會(huì)導(dǎo)致內(nèi)存溢出。因此還是要按照上面所講的方法,通過(guò)Spark Web UI查看報(bào)錯(cuò)的那個(gè)stage的各個(gè)task的運(yùn)行時(shí)間以及分配的數(shù)據(jù)量,才能確定是否是由于數(shù)據(jù)傾斜才導(dǎo)致了這次內(nèi)存溢出。
查看導(dǎo)致數(shù)據(jù)傾斜的key的數(shù)據(jù)分布情況
知道了數(shù)據(jù)傾斜發(fā)生在哪里之后,通常需要分析一下那個(gè)執(zhí)行了shuffle操作并且導(dǎo)致了數(shù)據(jù)傾斜的RDD/Hive表,查看一下其中key的分布情況。這主要是為之后選擇哪一種技術(shù)方案提供依據(jù)。針對(duì)不同的key分布與不同的shuffle算子組合起來(lái)的各種情況,可能需要選擇不同的技術(shù)方案來(lái)解決。
此時(shí)根據(jù)你執(zhí)行操作的情況不同,可以有很多種查看key分布的方式:
如果是Spark SQL中的group by、join語(yǔ)句導(dǎo)致的數(shù)據(jù)傾斜,那么就查詢一下SQL中使用的表的key分布情況。 如果是對(duì)Spark RDD執(zhí)行shuffle算子導(dǎo)致的數(shù)據(jù)傾斜,那么可以在Spark作業(yè)中加入查看key分布的代碼,比如RDD.countByKey()。然后對(duì)統(tǒng)計(jì)出來(lái)的各個(gè)key出現(xiàn)的次數(shù),collect/take到客戶端打印一下,就可以看到key的分布情況。
舉例來(lái)說(shuō),對(duì)于上面所說(shuō)的單詞計(jì)數(shù)程序,如果確定了是stage1的reduceByKey算子導(dǎo)致了數(shù)據(jù)傾斜,那么就應(yīng)該看看進(jìn)行reduceByKey操作的RDD中的key分布情況,在這個(gè)例子中指的就是pairs RDD。如下示例,我們可以先對(duì)pairs采樣10%的樣本數(shù)據(jù),然后使用countByKey算子統(tǒng)計(jì)出每個(gè)key出現(xiàn)的次數(shù),最后在客戶端遍歷和打印樣本數(shù)據(jù)中各個(gè)key的出現(xiàn)次數(shù)。
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))
數(shù)據(jù)傾斜的解決方案
解決方案一:使用Hive ETL預(yù)處理數(shù)據(jù)
方案適用場(chǎng)景:導(dǎo)致數(shù)據(jù)傾斜的是Hive表。如果該Hive表中的數(shù)據(jù)本身很不均勻(比如某個(gè)key對(duì)應(yīng)了100萬(wàn)數(shù)據(jù),其他key才對(duì)應(yīng)了10條數(shù)據(jù)),而且業(yè)務(wù)場(chǎng)景需要頻繁使用Spark對(duì)Hive表執(zhí)行某個(gè)分析操作,那么比較適合使用這種技術(shù)方案。
方案實(shí)現(xiàn)思路:此時(shí)可以評(píng)估一下,是否可以通過(guò)Hive來(lái)進(jìn)行數(shù)據(jù)預(yù)處理(即通過(guò)Hive ETL預(yù)先對(duì)數(shù)據(jù)按照key進(jìn)行聚合,或者是預(yù)先和其他表進(jìn)行join),然后在Spark作業(yè)中針對(duì)的數(shù)據(jù)源就不是原來(lái)的Hive表了,而是預(yù)處理后的Hive表。此時(shí)由于數(shù)據(jù)已經(jīng)預(yù)先進(jìn)行過(guò)聚合或join操作了,那么在Spark作業(yè)中也就不需要使用原先的shuffle類算子執(zhí)行這類操作了。
方案實(shí)現(xiàn)原理:這種方案從根源上解決了數(shù)據(jù)傾斜,因?yàn)閺氐妆苊饬嗽赟park中執(zhí)行shuffle類算子,那么肯定就不會(huì)有數(shù)據(jù)傾斜的問(wèn)題了。但是這里也要提醒一下大家,這種方式屬于治標(biāo)不治本。因?yàn)楫吘箶?shù)據(jù)本身就存在分布不均勻的問(wèn)題,所以Hive ETL中進(jìn)行g(shù)roup by或者join等shuffle操作時(shí),還是會(huì)出現(xiàn)數(shù)據(jù)傾斜,導(dǎo)致Hive ETL的速度很慢。我們只是把數(shù)據(jù)傾斜的發(fā)生提前到了Hive ETL中,避免Spark程序發(fā)生數(shù)據(jù)傾斜而已。
方案優(yōu)點(diǎn):實(shí)現(xiàn)起來(lái)簡(jiǎn)單便捷,效果還非常好,完全規(guī)避掉了數(shù)據(jù)傾斜,Spark作業(yè)的性能會(huì)大幅度提升。
方案缺點(diǎn):治標(biāo)不治本,Hive ETL中還是會(huì)發(fā)生數(shù)據(jù)傾斜。
方案實(shí)踐經(jīng)驗(yàn):在一些Java系統(tǒng)與Spark結(jié)合使用的項(xiàng)目中,會(huì)出現(xiàn)Java代碼頻繁調(diào)用Spark作業(yè)的場(chǎng)景,而且對(duì)Spark作業(yè)的執(zhí)行性能要求很高,就比較適合使用這種方案。將數(shù)據(jù)傾斜提前到上游的Hive ETL,每天僅執(zhí)行一次,只有那一次是比較慢的,而之后每次Java調(diào)用Spark作業(yè)時(shí),執(zhí)行速度都會(huì)很快,能夠提供更好的用戶體驗(yàn)。
項(xiàng)目實(shí)踐經(jīng)驗(yàn):在美團(tuán)·點(diǎn)評(píng)的交互式用戶行為分析系統(tǒng)中使用了這種方案,該系統(tǒng)主要是允許用戶通過(guò)Java Web系統(tǒng)提交數(shù)據(jù)分析統(tǒng)計(jì)任務(wù),后端通過(guò)Java提交Spark作業(yè)進(jìn)行數(shù)據(jù)分析統(tǒng)計(jì)。要求Spark作業(yè)速度必須要快,盡量在10分鐘以內(nèi),否則速度太慢,用戶體驗(yàn)會(huì)很差。所以我們將有些Spark作業(yè)的shuffle操作提前到了Hive ETL中,從而讓Spark直接使用預(yù)處理的Hive中間表,盡可能地減少Spark的shuffle操作,大幅度提升了性能,將部分作業(yè)的性能提升了6倍以上。
解決方案二:過(guò)濾少數(shù)導(dǎo)致傾斜的key
方案適用場(chǎng)景:如果發(fā)現(xiàn)導(dǎo)致傾斜的key就少數(shù)幾個(gè),而且對(duì)計(jì)算本身的影響并不大的話,那么很適合使用這種方案。比如99%的key就對(duì)應(yīng)10條數(shù)據(jù),但是只有一個(gè)key對(duì)應(yīng)了100萬(wàn)數(shù)據(jù),從而導(dǎo)致了數(shù)據(jù)傾斜。
方案實(shí)現(xiàn)思路:如果我們判斷那少數(shù)幾個(gè)數(shù)據(jù)量特別多的key,對(duì)作業(yè)的執(zhí)行和計(jì)算結(jié)果不是特別重要的話,那么干脆就直接過(guò)濾掉那少數(shù)幾個(gè)key。比如,在Spark SQL中可以使用where子句過(guò)濾掉這些key或者在Spark Core中對(duì)RDD執(zhí)行filter算子過(guò)濾掉這些key。如果需要每次作業(yè)執(zhí)行時(shí),動(dòng)態(tài)判定哪些key的數(shù)據(jù)量最多然后再進(jìn)行過(guò)濾,那么可以使用sample算子對(duì)RDD進(jìn)行采樣,然后計(jì)算出每個(gè)key的數(shù)量,取數(shù)據(jù)量最多的key過(guò)濾掉即可。
方案實(shí)現(xiàn)原理:將導(dǎo)致數(shù)據(jù)傾斜的key給過(guò)濾掉之后,這些key就不會(huì)參與計(jì)算了,自然不可能產(chǎn)生數(shù)據(jù)傾斜。
方案優(yōu)點(diǎn):實(shí)現(xiàn)簡(jiǎn)單,而且效果也很好,可以完全規(guī)避掉數(shù)據(jù)傾斜。
方案缺點(diǎn):適用場(chǎng)景不多,大多數(shù)情況下,導(dǎo)致傾斜的key還是很多的,并不是只有少數(shù)幾個(gè)。
方案實(shí)踐經(jīng)驗(yàn):在項(xiàng)目中我們也采用過(guò)這種方案解決數(shù)據(jù)傾斜。有一次發(fā)現(xiàn)某一天Spark作業(yè)在運(yùn)行的時(shí)候突然OOM了,追查之后發(fā)現(xiàn),是Hive表中的某一個(gè)key在那天數(shù)據(jù)異常,導(dǎo)致數(shù)據(jù)量暴增。因此就采取每次執(zhí)行前先進(jìn)行采樣,計(jì)算出樣本中數(shù)據(jù)量最大的幾個(gè)key之后,直接在程序中將那些key給過(guò)濾掉。
解決方案三:提高shuffle操作的并行度
方案適用場(chǎng)景:如果我們必須要對(duì)數(shù)據(jù)傾斜迎難而上,那么建議優(yōu)先使用這種方案,因?yàn)檫@是處理數(shù)據(jù)傾斜最簡(jiǎn)單的一種方案。
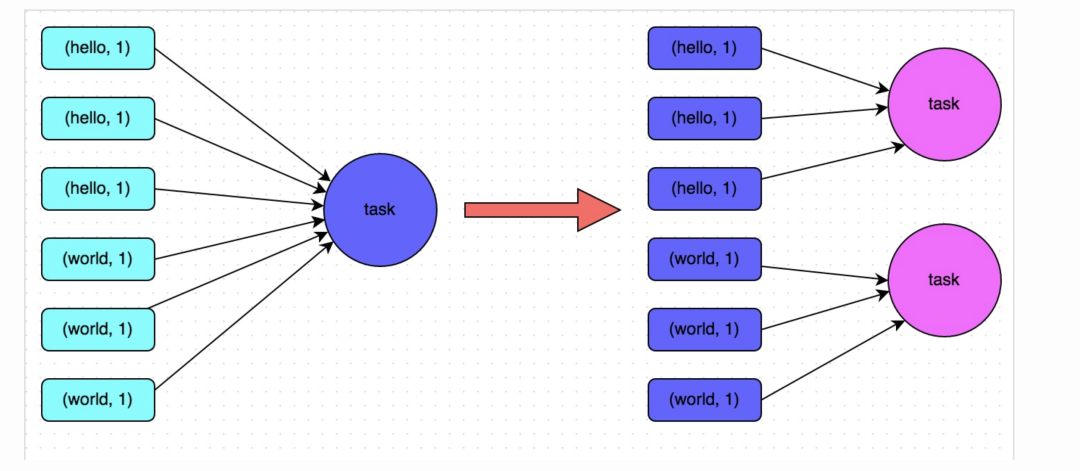
方案實(shí)現(xiàn)思路:在對(duì)RDD執(zhí)行shuffle算子時(shí),給shuffle算子傳入一個(gè)參數(shù),比如reduceByKey(1000),該參數(shù)就設(shè)置了這個(gè)shuffle算子執(zhí)行時(shí)shuffle read task的數(shù)量。對(duì)于Spark SQL中的shuffle類語(yǔ)句,比如group by、join等,需要設(shè)置一個(gè)參數(shù),即spark.sql.shuffle.partitions,該參數(shù)代表了shuffle read task的并行度,該值默認(rèn)是200,對(duì)于很多場(chǎng)景來(lái)說(shuō)都有點(diǎn)過(guò)小。
方案實(shí)現(xiàn)原理:增加shuffle read task的數(shù)量,可以讓原本分配給一個(gè)task的多個(gè)key分配給多個(gè)task,從而讓每個(gè)task處理比原來(lái)更少的數(shù)據(jù)。舉例來(lái)說(shuō),如果原本有5個(gè)key,每個(gè)key對(duì)應(yīng)10條數(shù)據(jù),這5個(gè)key都是分配給一個(gè)task的,那么這個(gè)task就要處理50條數(shù)據(jù)。而增加了shuffle read task以后,每個(gè)task就分配到一個(gè)key,即每個(gè)task就處理10條數(shù)據(jù),那么自然每個(gè)task的執(zhí)行時(shí)間都會(huì)變短了。具體原理如下圖所示。
方案優(yōu)點(diǎn):實(shí)現(xiàn)起來(lái)比較簡(jiǎn)單,可以有效緩解和減輕數(shù)據(jù)傾斜的影響。
方案缺點(diǎn):只是緩解了數(shù)據(jù)傾斜而已,沒(méi)有徹底根除問(wèn)題,根據(jù)實(shí)踐經(jīng)驗(yàn)來(lái)看,其效果有限。
方案實(shí)踐經(jīng)驗(yàn):該方案通常無(wú)法徹底解決數(shù)據(jù)傾斜,因?yàn)槿绻霈F(xiàn)一些極端情況,比如某個(gè)key對(duì)應(yīng)的數(shù)據(jù)量有100萬(wàn),那么無(wú)論你的task數(shù)量增加到多少,這個(gè)對(duì)應(yīng)著100萬(wàn)數(shù)據(jù)的key肯定還是會(huì)分配到一個(gè)task中去處理,因此注定還是會(huì)發(fā)生數(shù)據(jù)傾斜的。所以這種方案只能說(shuō)是在發(fā)現(xiàn)數(shù)據(jù)傾斜時(shí)嘗試使用的第一種手段,嘗試去用嘴簡(jiǎn)單的方法緩解數(shù)據(jù)傾斜而已,或者是和其他方案結(jié)合起來(lái)使用。
解決方案四:兩階段聚合(局部聚合+全局聚合)
方案適用場(chǎng)景:對(duì)RDD執(zhí)行reduceByKey等聚合類shuffle算子或者在Spark SQL中使用group by語(yǔ)句進(jìn)行分組聚合時(shí),比較適用這種方案。
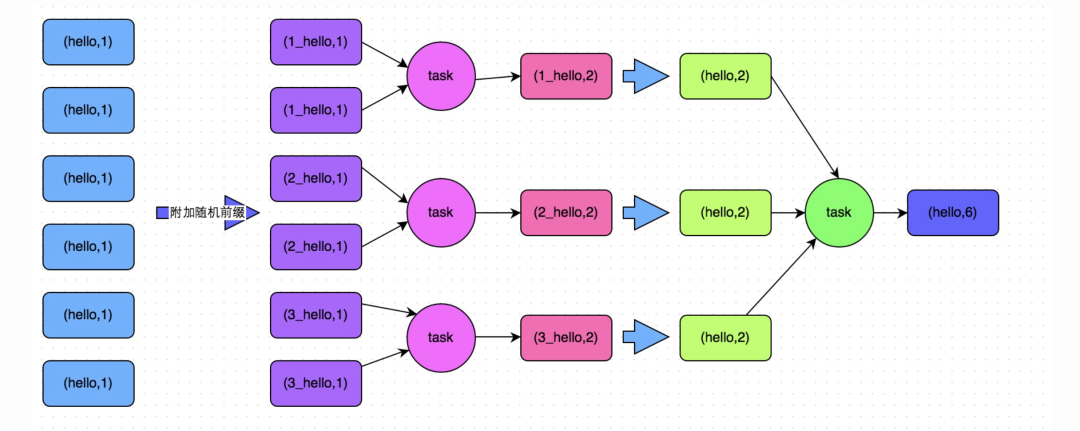
方案實(shí)現(xiàn)思路:這個(gè)方案的核心實(shí)現(xiàn)思路就是進(jìn)行兩階段聚合。第一次是局部聚合,先給每個(gè)key都打上一個(gè)隨機(jī)數(shù),比如10以內(nèi)的隨機(jī)數(shù),此時(shí)原先一樣的key就變成不一樣的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就會(huì)變成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接著對(duì)打上隨機(jī)數(shù)后的數(shù)據(jù),執(zhí)行reduceByKey等聚合操作,進(jìn)行局部聚合,那么局部聚合結(jié)果,就會(huì)變成了(1_hello, 2) (2_hello, 2)。然后將各個(gè)key的前綴給去掉,就會(huì)變成(hello,2)(hello,2),再次進(jìn)行全局聚合操作,就可以得到最終結(jié)果了,比如(hello, 4)。
方案實(shí)現(xiàn)原理:將原本相同的key通過(guò)附加隨機(jī)前綴的方式,變成多個(gè)不同的key,就可以讓原本被一個(gè)task處理的數(shù)據(jù)分散到多個(gè)task上去做局部聚合,進(jìn)而解決單個(gè)task處理數(shù)據(jù)量過(guò)多的問(wèn)題。接著去除掉隨機(jī)前綴,再次進(jìn)行全局聚合,就可以得到最終的結(jié)果。具體原理見(jiàn)下圖。
方案優(yōu)點(diǎn):對(duì)于聚合類的shuffle操作導(dǎo)致的數(shù)據(jù)傾斜,效果是非常不錯(cuò)的。通常都可以解決掉數(shù)據(jù)傾斜,或者至少是大幅度緩解數(shù)據(jù)傾斜,將Spark作業(yè)的性能提升數(shù)倍以上。
方案缺點(diǎn):僅僅適用于聚合類的shuffle操作,適用范圍相對(duì)較窄。如果是join類的shuffle操作,還得用其他的解決方案。
// 第一步,給RDD中的每個(gè)key都打上一個(gè)隨機(jī)前綴。
JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(
new PairFunction<Tuple2<Long,Long>, String, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(10);
return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
}
});
// 第二步,對(duì)打上隨機(jī)前綴的key進(jìn)行局部聚合。
JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
// 第三步,去除RDD中每個(gè)key的隨機(jī)前綴。
JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(
new PairFunction<Tuple2<String,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
throws Exception {
long originalKey = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Long>(originalKey, tuple._2);
}
});
// 第四步,對(duì)去除了隨機(jī)前綴的RDD進(jìn)行全局聚合。
JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
解決方案五:將reduce join轉(zhuǎn)為map join
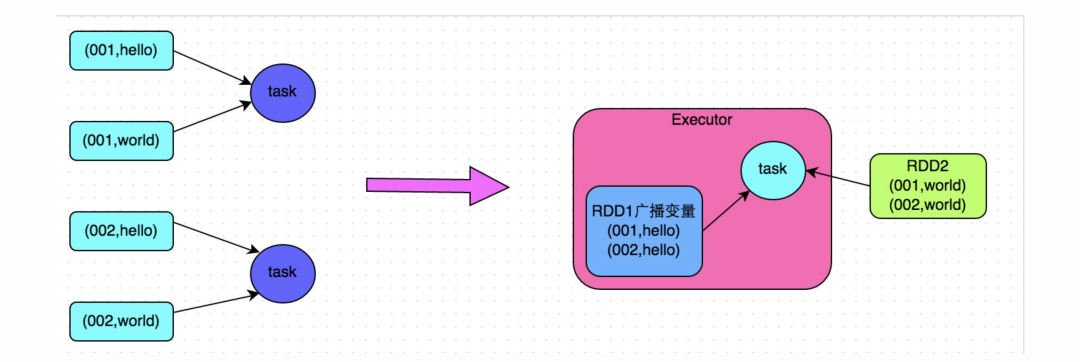
方案適用場(chǎng)景:在對(duì)RDD使用join類操作,或者是在Spark SQL中使用join語(yǔ)句時(shí),而且join操作中的一個(gè)RDD或表的數(shù)據(jù)量比較小(比如幾百M(fèi)或者一兩G),比較適用此方案。
方案實(shí)現(xiàn)思路:不使用join算子進(jìn)行連接操作,而使用Broadcast變量與map類算子實(shí)現(xiàn)join操作,進(jìn)而完全規(guī)避掉shuffle類的操作,徹底避免數(shù)據(jù)傾斜的發(fā)生和出現(xiàn)。將較小RDD中的數(shù)據(jù)直接通過(guò)collect算子拉取到Driver端的內(nèi)存中來(lái),然后對(duì)其創(chuàng)建一個(gè)Broadcast變量;接著對(duì)另外一個(gè)RDD執(zhí)行map類算子,在算子函數(shù)內(nèi),從Broadcast變量中獲取較小RDD的全量數(shù)據(jù),與當(dāng)前RDD的每一條數(shù)據(jù)按照連接key進(jìn)行比對(duì),如果連接key相同的話,那么就將兩個(gè)RDD的數(shù)據(jù)用你需要的方式連接起來(lái)。
方案實(shí)現(xiàn)原理:普通的join是會(huì)走shuffle過(guò)程的,而一旦shuffle,就相當(dāng)于會(huì)將相同key的數(shù)據(jù)拉取到一個(gè)shuffle read task中再進(jìn)行join,此時(shí)就是reduce join。但是如果一個(gè)RDD是比較小的,則可以采用廣播小RDD全量數(shù)據(jù)+map算子來(lái)實(shí)現(xiàn)與join同樣的效果,也就是map join,此時(shí)就不會(huì)發(fā)生shuffle操作,也就不會(huì)發(fā)生數(shù)據(jù)傾斜。具體原理如下圖所示。
方案優(yōu)點(diǎn):對(duì)join操作導(dǎo)致的數(shù)據(jù)傾斜,效果非常好,因?yàn)楦揪筒粫?huì)發(fā)生shuffle,也就根本不會(huì)發(fā)生數(shù)據(jù)傾斜。
方案缺點(diǎn):適用場(chǎng)景較少,因?yàn)檫@個(gè)方案只適用于一個(gè)大表和一個(gè)小表的情況。畢竟我們需要將小表進(jìn)行廣播,此時(shí)會(huì)比較消耗內(nèi)存資源,driver和每個(gè)Executor內(nèi)存中都會(huì)駐留一份小RDD的全量數(shù)據(jù)。如果我們廣播出去的RDD數(shù)據(jù)比較大,比如10G以上,那么就可能發(fā)生內(nèi)存溢出了。因此并不適合兩個(gè)都是大表的情況。
// 首先將數(shù)據(jù)量比較小的RDD的數(shù)據(jù),collect到Driver中來(lái)。
List<Tuple2<Long, Row>> rdd1Data = rdd1.collect()
// 然后使用Spark的廣播功能,將小RDD的數(shù)據(jù)轉(zhuǎn)換成廣播變量,這樣每個(gè)Executor就只有一份RDD的數(shù)據(jù)。
// 可以盡可能節(jié)省內(nèi)存空間,并且減少網(wǎng)絡(luò)傳輸性能開(kāi)銷。
final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data);
// 對(duì)另外一個(gè)RDD執(zhí)行map類操作,而不再是join類操作。
JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple)
throws Exception {
// 在算子函數(shù)中,通過(guò)廣播變量,獲取到本地Executor中的rdd1數(shù)據(jù)。
List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value();
// 可以將rdd1的數(shù)據(jù)轉(zhuǎn)換為一個(gè)Map,便于后面進(jìn)行join操作。
Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>();
for(Tuple2<Long, Row> data : rdd1Data) {
rdd1DataMap.put(data._1, data._2);
}
// 獲取當(dāng)前RDD數(shù)據(jù)的key以及value。
String key = tuple._1;
String value = tuple._2;
// 從rdd1數(shù)據(jù)Map中,根據(jù)key獲取到可以join到的數(shù)據(jù)。
Row rdd1Value = rdd1DataMap.get(key);
return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value));
}
});
// 這里得提示一下。
// 上面的做法,僅僅適用于rdd1中的key沒(méi)有重復(fù),全部是唯一的場(chǎng)景。
// 如果rdd1中有多個(gè)相同的key,那么就得用flatMap類的操作,在進(jìn)行join的時(shí)候不能用map,而是得遍歷rdd1所有數(shù)據(jù)進(jìn)行join。
// rdd2中每條數(shù)據(jù)都可能會(huì)返回多條join后的數(shù)據(jù)。
解決方案六:采樣傾斜key并分拆join操作
方案適用場(chǎng)景:兩個(gè)RDD/Hive表進(jìn)行join的時(shí)候,如果數(shù)據(jù)量都比較大,無(wú)法采用“解決方案五”,那么此時(shí)可以看一下兩個(gè)RDD/Hive表中的key分布情況。如果出現(xiàn)數(shù)據(jù)傾斜,是因?yàn)槠渲心骋粋€(gè)RDD/Hive表中的少數(shù)幾個(gè)key的數(shù)據(jù)量過(guò)大,而另一個(gè)RDD/Hive表中的所有key都分布比較均勻,那么采用這個(gè)解決方案是比較合適的。
方案實(shí)現(xiàn)思路:
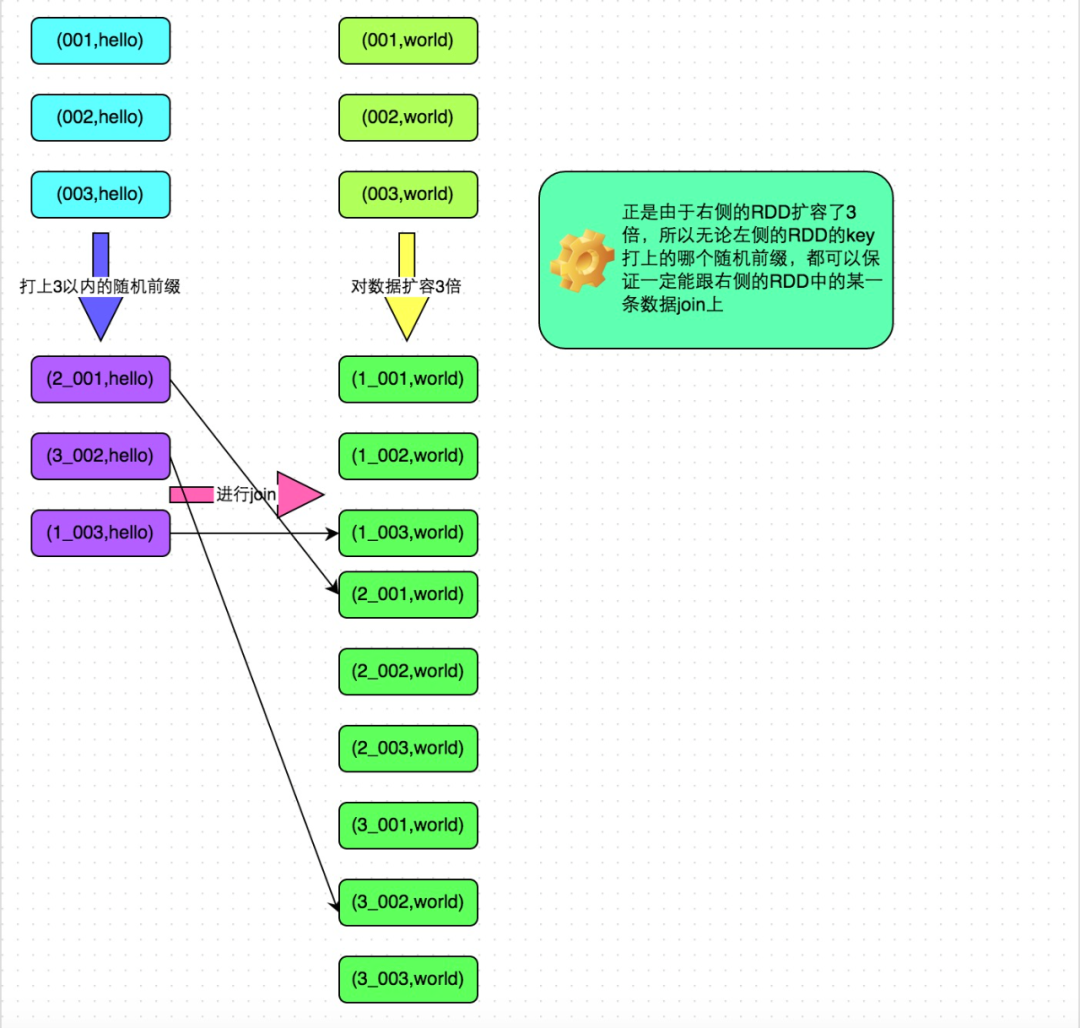
對(duì)包含少數(shù)幾個(gè)數(shù)據(jù)量過(guò)大的key的那個(gè)RDD,通過(guò)sample算子采樣出一份樣本來(lái),然后統(tǒng)計(jì)一下每個(gè)key的數(shù)量,計(jì)算出來(lái)數(shù)據(jù)量最大的是哪幾個(gè)key。 然后將這幾個(gè)key對(duì)應(yīng)的數(shù)據(jù)從原來(lái)的RDD中拆分出來(lái),形成一個(gè)單獨(dú)的RDD,并給每個(gè)key都打上n以內(nèi)的隨機(jī)數(shù)作為前綴,而不會(huì)導(dǎo)致傾斜的大部分key形成另外一個(gè)RDD。 接著將需要join的另一個(gè)RDD,也過(guò)濾出來(lái)那幾個(gè)傾斜key對(duì)應(yīng)的數(shù)據(jù)并形成一個(gè)單獨(dú)的RDD,將每條數(shù)據(jù)膨脹成n條數(shù)據(jù),這n條數(shù)據(jù)都按順序附加一個(gè)0~n的前綴,不會(huì)導(dǎo)致傾斜的大部分key也形成另外一個(gè)RDD。 再將附加了隨機(jī)前綴的獨(dú)立RDD與另一個(gè)膨脹n倍的獨(dú)立RDD進(jìn)行join,此時(shí)就可以將原先相同的key打散成n份,分散到多個(gè)task中去進(jìn)行join了。 而另外兩個(gè)普通的RDD就照常join即可。 最后將兩次join的結(jié)果使用union算子合并起來(lái)即可,就是最終的join結(jié)果。
方案實(shí)現(xiàn)原理:對(duì)于join導(dǎo)致的數(shù)據(jù)傾斜,如果只是某幾個(gè)key導(dǎo)致了傾斜,可以將少數(shù)幾個(gè)key分拆成獨(dú)立RDD,并附加隨機(jī)前綴打散成n份去進(jìn)行join,此時(shí)這幾個(gè)key對(duì)應(yīng)的數(shù)據(jù)就不會(huì)集中在少數(shù)幾個(gè)task上,而是分散到多個(gè)task進(jìn)行join了。具體原理見(jiàn)下圖。
方案優(yōu)點(diǎn):對(duì)于join導(dǎo)致的數(shù)據(jù)傾斜,如果只是某幾個(gè)key導(dǎo)致了傾斜,采用該方式可以用最有效的方式打散key進(jìn)行join。而且只需要針對(duì)少數(shù)傾斜key對(duì)應(yīng)的數(shù)據(jù)進(jìn)行擴(kuò)容n倍,不需要對(duì)全量數(shù)據(jù)進(jìn)行擴(kuò)容。避免了占用過(guò)多內(nèi)存。
方案缺點(diǎn):如果導(dǎo)致傾斜的key特別多的話,比如成千上萬(wàn)個(gè)key都導(dǎo)致數(shù)據(jù)傾斜,那么這種方式也不適合。
// 首先將數(shù)據(jù)量比較小的RDD的數(shù)據(jù),collect到Driver中來(lái)。
List<Tuple2<Long, Row>> rdd1Data = rdd1.collect()
// 然后使用Spark的廣播功能,將小RDD的數(shù)據(jù)轉(zhuǎn)換成廣播變量,這樣每個(gè)Executor就只有一份RDD的數(shù)據(jù)。
// 可以盡可能節(jié)省內(nèi)存空間,并且減少網(wǎng)絡(luò)傳輸性能開(kāi)銷。
final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data);
// 對(duì)另外一個(gè)RDD執(zhí)行map類操作,而不再是join類操作。
JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple)
throws Exception {
// 在算子函數(shù)中,通過(guò)廣播變量,獲取到本地Executor中的rdd1數(shù)據(jù)。
List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value();
// 可以將rdd1的數(shù)據(jù)轉(zhuǎn)換為一個(gè)Map,便于后面進(jìn)行join操作。
Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>();
for(Tuple2<Long, Row> data : rdd1Data) {
rdd1DataMap.put(data._1, data._2);
}
// 獲取當(dāng)前RDD數(shù)據(jù)的key以及value。
String key = tuple._1;
String value = tuple._2;
// 從rdd1數(shù)據(jù)Map中,根據(jù)key獲取到可以join到的數(shù)據(jù)。
Row rdd1Value = rdd1DataMap.get(key);
return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value));
}
});
// 這里得提示一下。
// 上面的做法,僅僅適用于rdd1中的key沒(méi)有重復(fù),全部是唯一的場(chǎng)景。
// 如果rdd1中有多個(gè)相同的key,那么就得用flatMap類的操作,在進(jìn)行join的時(shí)候不能用map,而是得遍歷rdd1所有數(shù)據(jù)進(jìn)行join。
// rdd2中每條數(shù)據(jù)都可能會(huì)返回多條join后的數(shù)據(jù)。// 首先從包含了少數(shù)幾個(gè)導(dǎo)致數(shù)據(jù)傾斜key的rdd1中,采樣10%的樣本數(shù)據(jù)。
JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
// 對(duì)樣本數(shù)據(jù)RDD統(tǒng)計(jì)出每個(gè)key的出現(xiàn)次數(shù),并按出現(xiàn)次數(shù)降序排序。
// 對(duì)降序排序后的數(shù)據(jù),取出top 1或者top 100的數(shù)據(jù),也就是key最多的前n個(gè)數(shù)據(jù)。
// 具體取出多少個(gè)數(shù)據(jù)量最多的key,由大家自己決定,我們這里就取1個(gè)作為示范。
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// 從rdd1中分拆出導(dǎo)致數(shù)據(jù)傾斜的key,形成獨(dú)立的RDD。
JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// 從rdd1中分拆出不導(dǎo)致數(shù)據(jù)傾斜的普通key,形成獨(dú)立的RDD。
JavaPairRDD<Long, String> commonRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// rdd2,就是那個(gè)所有key的分布相對(duì)較為均勻的rdd。
// 這里將rdd2中,前面獲取到的key對(duì)應(yīng)的數(shù)據(jù),過(guò)濾出來(lái),分拆成單獨(dú)的rdd,并對(duì)rdd中的數(shù)據(jù)使用flatMap算子都擴(kuò)容100倍。
// 對(duì)擴(kuò)容的每條數(shù)據(jù),都打上0~100的前綴。
JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 將rdd1中分拆出來(lái)的導(dǎo)致傾斜的key的獨(dú)立rdd,每條數(shù)據(jù)都打上100以內(nèi)的隨機(jī)前綴。
// 然后將這個(gè)rdd1中分拆出來(lái)的獨(dú)立rdd,與上面rdd2中分拆出來(lái)的獨(dú)立rdd,進(jìn)行join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
}
});
// 將rdd1中分拆出來(lái)的包含普通key的獨(dú)立rdd,直接與rdd2進(jìn)行join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
// 將傾斜key join后的結(jié)果與普通key join后的結(jié)果,uinon起來(lái)。
// 就是最終的join結(jié)果。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);// 首先從包含了少數(shù)幾個(gè)導(dǎo)致數(shù)據(jù)傾斜key的rdd1中,采樣10%的樣本數(shù)據(jù)。
JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
// 對(duì)樣本數(shù)據(jù)RDD統(tǒng)計(jì)出每個(gè)key的出現(xiàn)次數(shù),并按出現(xiàn)次數(shù)降序排序。
// 對(duì)降序排序后的數(shù)據(jù),取出top 1或者top 100的數(shù)據(jù),也就是key最多的前n個(gè)數(shù)據(jù)。
// 具體取出多少個(gè)數(shù)據(jù)量最多的key,由大家自己決定,我們這里就取1個(gè)作為示范。
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// 從rdd1中分拆出導(dǎo)致數(shù)據(jù)傾斜的key,形成獨(dú)立的RDD。
JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// 從rdd1中分拆出不導(dǎo)致數(shù)據(jù)傾斜的普通key,形成獨(dú)立的RDD。
JavaPairRDD<Long, String> commonRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// rdd2,就是那個(gè)所有key的分布相對(duì)較為均勻的rdd。
// 這里將rdd2中,前面獲取到的key對(duì)應(yīng)的數(shù)據(jù),過(guò)濾出來(lái),分拆成單獨(dú)的rdd,并對(duì)rdd中的數(shù)據(jù)使用flatMap算子都擴(kuò)容100倍。
// 對(duì)擴(kuò)容的每條數(shù)據(jù),都打上0~100的前綴。
JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 將rdd1中分拆出來(lái)的導(dǎo)致傾斜的key的獨(dú)立rdd,每條數(shù)據(jù)都打上100以內(nèi)的隨機(jī)前綴。
// 然后將這個(gè)rdd1中分拆出來(lái)的獨(dú)立rdd,與上面rdd2中分拆出來(lái)的獨(dú)立rdd,進(jìn)行join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
}
});
// 將rdd1中分拆出來(lái)的包含普通key的獨(dú)立rdd,直接與rdd2進(jìn)行join。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
// 將傾斜key join后的結(jié)果與普通key join后的結(jié)果,uinon起來(lái)。
// 就是最終的join結(jié)果。
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);
解決方案七:使用隨機(jī)前綴和擴(kuò)容RDD進(jìn)行join
方案適用場(chǎng)景:如果在進(jìn)行join操作時(shí),RDD中有大量的key導(dǎo)致數(shù)據(jù)傾斜,那么進(jìn)行分拆key也沒(méi)什么意義,此時(shí)就只能使用最后一種方案來(lái)解決問(wèn)題了。
方案實(shí)現(xiàn)思路:
該方案的實(shí)現(xiàn)思路基本和“解決方案六”類似,首先查看RDD/Hive表中的數(shù)據(jù)分布情況,找到那個(gè)造成數(shù)據(jù)傾斜的RDD/Hive表,比如有多個(gè)key都對(duì)應(yīng)了超過(guò)1萬(wàn)條數(shù)據(jù)。 然后將該RDD的每條數(shù)據(jù)都打上一個(gè)n以內(nèi)的隨機(jī)前綴。 同時(shí)對(duì)另外一個(gè)正常的RDD進(jìn)行擴(kuò)容,將每條數(shù)據(jù)都擴(kuò)容成n條數(shù)據(jù),擴(kuò)容出來(lái)的每條數(shù)據(jù)都依次打上一個(gè)0~n的前綴。 最后將兩個(gè)處理后的RDD進(jìn)行join即可。
方案實(shí)現(xiàn)原理:將原先一樣的key通過(guò)附加隨機(jī)前綴變成不一樣的key,然后就可以將這些處理后的“不同key”分散到多個(gè)task中去處理,而不是讓一個(gè)task處理大量的相同key。該方案與“解決方案六”的不同之處就在于,上一種方案是盡量只對(duì)少數(shù)傾斜key對(duì)應(yīng)的數(shù)據(jù)進(jìn)行特殊處理,由于處理過(guò)程需要擴(kuò)容RDD,因此上一種方案擴(kuò)容RDD后對(duì)內(nèi)存的占用并不大;而這一種方案是針對(duì)有大量?jī)A斜key的情況,沒(méi)法將部分key拆分出來(lái)進(jìn)行單獨(dú)處理,因此只能對(duì)整個(gè)RDD進(jìn)行數(shù)據(jù)擴(kuò)容,對(duì)內(nèi)存資源要求很高。
方案優(yōu)點(diǎn):對(duì)join類型的數(shù)據(jù)傾斜基本都可以處理,而且效果也相對(duì)比較顯著,性能提升效果非常不錯(cuò)。
方案缺點(diǎn):該方案更多的是緩解數(shù)據(jù)傾斜,而不是徹底避免數(shù)據(jù)傾斜。而且需要對(duì)整個(gè)RDD進(jìn)行擴(kuò)容,對(duì)內(nèi)存資源要求很高。
方案實(shí)踐經(jīng)驗(yàn):曾經(jīng)開(kāi)發(fā)一個(gè)數(shù)據(jù)需求的時(shí)候,發(fā)現(xiàn)一個(gè)join導(dǎo)致了數(shù)據(jù)傾斜。優(yōu)化之前,作業(yè)的執(zhí)行時(shí)間大約是60分鐘左右;使用該方案優(yōu)化之后,執(zhí)行時(shí)間縮短到10分鐘左右,性能提升了6倍。
// 首先將其中一個(gè)key分布相對(duì)較為均勻的RDD膨脹100倍。
JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(
new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
throws Exception {
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
}
return list;
}
});
// 其次,將另一個(gè)有數(shù)據(jù)傾斜key的RDD,每條數(shù)據(jù)都打上100以內(nèi)的隨機(jī)前綴。
JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
});
// 將兩個(gè)處理后的RDD進(jìn)行join即可。
JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);
解決方案八:多種方案組合使用
在實(shí)踐中發(fā)現(xiàn),很多情況下,如果只是處理較為簡(jiǎn)單的數(shù)據(jù)傾斜場(chǎng)景,那么使用上述方案中的某一種基本就可以解決。但是如果要處理一個(gè)較為復(fù)雜的數(shù)據(jù)傾斜場(chǎng)景,那么可能需要將多種方案組合起來(lái)使用。比如說(shuō),我們針對(duì)出現(xiàn)了多個(gè)數(shù)據(jù)傾斜環(huán)節(jié)的Spark作業(yè),可以先運(yùn)用解決方案一和二,預(yù)處理一部分?jǐn)?shù)據(jù),并過(guò)濾一部分?jǐn)?shù)據(jù)來(lái)緩解;其次可以對(duì)某些shuffle操作提升并行度,優(yōu)化其性能;最后還可以針對(duì)不同的聚合或join操作,選擇一種方案來(lái)優(yōu)化其性能。大家需要對(duì)這些方案的思路和原理都透徹理解之后,在實(shí)踐中根據(jù)各種不同的情況,靈活運(yùn)用多種方案,來(lái)解決自己的數(shù)據(jù)傾斜問(wèn)題。
調(diào)優(yōu)概述
大多數(shù)Spark作業(yè)的性能主要就是消耗在了shuffle環(huán)節(jié),因?yàn)樵摥h(huán)節(jié)包含了大量的磁盤IO、序列化、網(wǎng)絡(luò)數(shù)據(jù)傳輸?shù)炔僮鳌R虼耍绻屪鳂I(yè)的性能更上一層樓,就有必要對(duì)shuffle過(guò)程進(jìn)行調(diào)優(yōu)。但是也必須提醒大家的是,影響一個(gè)Spark作業(yè)性能的因素,主要還是代碼開(kāi)發(fā)、資源參數(shù)以及數(shù)據(jù)傾斜,shuffle調(diào)優(yōu)只能在整個(gè)Spark的性能調(diào)優(yōu)中占到一小部分而已。因此大家務(wù)必把握住調(diào)優(yōu)的基本原則,千萬(wàn)不要舍本逐末。下面我們就給大家詳細(xì)講解shuffle的原理,以及相關(guān)參數(shù)的說(shuō)明,同時(shí)給出各個(gè)參數(shù)的調(diào)優(yōu)建議。
ShuffleManager發(fā)展概述
在Spark的源碼中,負(fù)責(zé)shuffle過(guò)程的執(zhí)行、計(jì)算和處理的組件主要就是ShuffleManager,也即shuffle管理器。而隨著Spark的版本的發(fā)展,ShuffleManager也在不斷迭代,變得越來(lái)越先進(jìn)。
在Spark 1.2以前,默認(rèn)的shuffle計(jì)算引擎是HashShuffleManager。該ShuffleManager而HashShuffleManager有著一個(gè)非常嚴(yán)重的弊端,就是會(huì)產(chǎn)生大量的中間磁盤文件,進(jìn)而由大量的磁盤IO操作影響了性能。
因此在Spark 1.2以后的版本中,默認(rèn)的ShuffleManager改成了SortShuffleManager。SortShuffleManager相較于HashShuffleManager來(lái)說(shuō),有了一定的改進(jìn)。主要就在于,每個(gè)Task在進(jìn)行shuffle操作時(shí),雖然也會(huì)產(chǎn)生較多的臨時(shí)磁盤文件,但是最后會(huì)將所有的臨時(shí)文件合并(merge)成一個(gè)磁盤文件,因此每個(gè)Task就只有一個(gè)磁盤文件。在下一個(gè)stage的shuffle read task拉取自己的數(shù)據(jù)時(shí),只要根據(jù)索引讀取每個(gè)磁盤文件中的部分?jǐn)?shù)據(jù)即可。
下面我們?cè)敿?xì)分析一下HashShuffleManager和SortShuffleManager的原理。
HashShuffleManager運(yùn)行原理
未經(jīng)優(yōu)化的HashShuffleManager
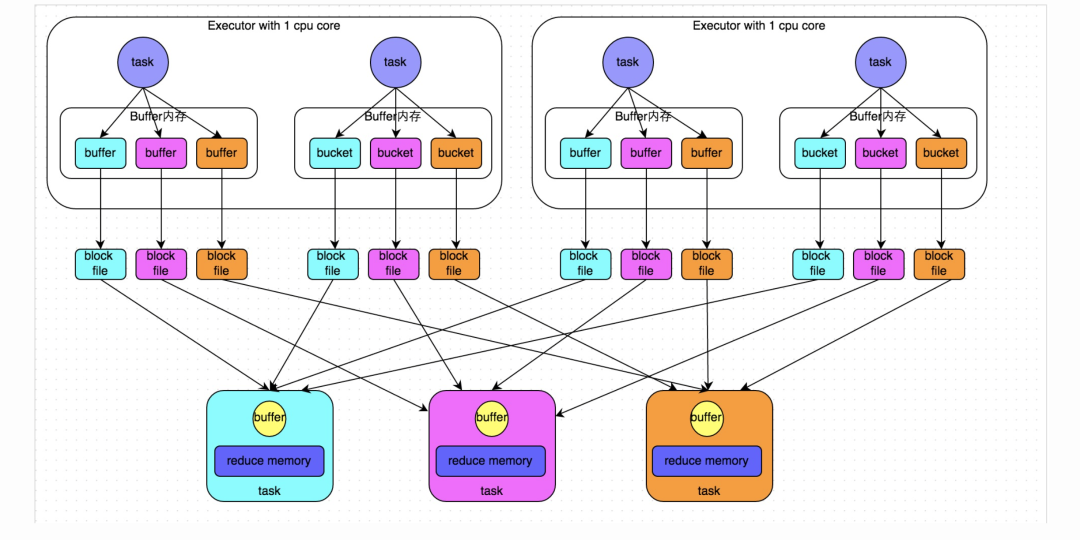
下圖說(shuō)明了未經(jīng)優(yōu)化的HashShuffleManager的原理。這里我們先明確一個(gè)假設(shè)前提:每個(gè)Executor只有1個(gè)CPU core,也就是說(shuō),無(wú)論這個(gè)Executor上分配多少個(gè)task線程,同一時(shí)間都只能執(zhí)行一個(gè)task線程。
我們先從shuffle write開(kāi)始說(shuō)起。shuffle write階段,主要就是在一個(gè)stage結(jié)束計(jì)算之后,為了下一個(gè)stage可以執(zhí)行shuffle類的算子(比如reduceByKey),而將每個(gè)task處理的數(shù)據(jù)按key進(jìn)行“分類”。所謂“分類”,就是對(duì)相同的key執(zhí)行hash算法,從而將相同key都寫入同一個(gè)磁盤文件中,而每一個(gè)磁盤文件都只屬于下游stage的一個(gè)task。在將數(shù)據(jù)寫入磁盤之前,會(huì)先將數(shù)據(jù)寫入內(nèi)存緩沖中,當(dāng)內(nèi)存緩沖填滿之后,才會(huì)溢寫到磁盤文件中去。
那么每個(gè)執(zhí)行shuffle write的task,要為下一個(gè)stage創(chuàng)建多少個(gè)磁盤文件呢?很簡(jiǎn)單,下一個(gè)stage的task有多少個(gè),當(dāng)前stage的每個(gè)task就要?jiǎng)?chuàng)建多少份磁盤文件。比如下一個(gè)stage總共有100個(gè)task,那么當(dāng)前stage的每個(gè)task都要?jiǎng)?chuàng)建100份磁盤文件。如果當(dāng)前stage有50個(gè)task,總共有10個(gè)Executor,每個(gè)Executor執(zhí)行5個(gè)Task,那么每個(gè)Executor上總共就要?jiǎng)?chuàng)建500個(gè)磁盤文件,所有Executor上會(huì)創(chuàng)建5000個(gè)磁盤文件。由此可見(jiàn),未經(jīng)優(yōu)化的shuffle write操作所產(chǎn)生的磁盤文件的數(shù)量是極其驚人的。
接著我們來(lái)說(shuō)說(shuō)shuffle read。shuffle read,通常就是一個(gè)stage剛開(kāi)始時(shí)要做的事情。此時(shí)該stage的每一個(gè)task就需要將上一個(gè)stage的計(jì)算結(jié)果中的所有相同key,從各個(gè)節(jié)點(diǎn)上通過(guò)網(wǎng)絡(luò)都拉取到自己所在的節(jié)點(diǎn)上,然后進(jìn)行key的聚合或連接等操作。由于shuffle write的過(guò)程中,task給下游stage的每個(gè)task都創(chuàng)建了一個(gè)磁盤文件,因此shuffle read的過(guò)程中,每個(gè)task只要從上游stage的所有task所在節(jié)點(diǎn)上,拉取屬于自己的那一個(gè)磁盤文件即可。
shuffle read的拉取過(guò)程是一邊拉取一邊進(jìn)行聚合的。每個(gè)shuffle read task都會(huì)有一個(gè)自己的buffer緩沖,每次都只能拉取與buffer緩沖相同大小的數(shù)據(jù),然后通過(guò)內(nèi)存中的一個(gè)Map進(jìn)行聚合等操作。聚合完一批數(shù)據(jù)后,再拉取下一批數(shù)據(jù),并放到buffer緩沖中進(jìn)行聚合操作。以此類推,直到最后將所有數(shù)據(jù)到拉取完,并得到最終的結(jié)果。
優(yōu)化后的HashShuffleManager
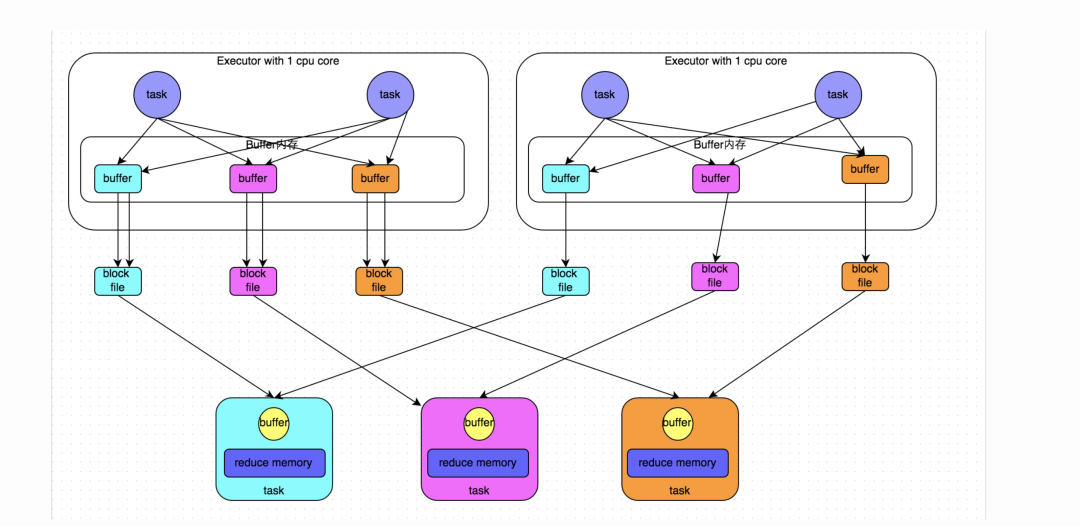
下圖說(shuō)明了優(yōu)化后的HashShuffleManager的原理。這里說(shuō)的優(yōu)化,是指我們可以設(shè)置一個(gè)參數(shù),spark.shuffle.consolidateFiles。該參數(shù)默認(rèn)值為false,將其設(shè)置為true即可開(kāi)啟優(yōu)化機(jī)制。通常來(lái)說(shuō),如果我們使用HashShuffleManager,那么都建議開(kāi)啟這個(gè)選項(xiàng)。
開(kāi)啟consolidate機(jī)制之后,在shuffle write過(guò)程中,task就不是為下游stage的每個(gè)task創(chuàng)建一個(gè)磁盤文件了。此時(shí)會(huì)出現(xiàn)shuffleFileGroup的概念,每個(gè)shuffleFileGroup會(huì)對(duì)應(yīng)一批磁盤文件,磁盤文件的數(shù)量與下游stage的task數(shù)量是相同的。一個(gè)Executor上有多少個(gè)CPU core,就可以并行執(zhí)行多少個(gè)task。而第一批并行執(zhí)行的每個(gè)task都會(huì)創(chuàng)建一個(gè)shuffleFileGroup,并將數(shù)據(jù)寫入對(duì)應(yīng)的磁盤文件內(nèi)。
當(dāng)Executor的CPU core執(zhí)行完一批task,接著執(zhí)行下一批task時(shí),下一批task就會(huì)復(fù)用之前已有的shuffleFileGroup,包括其中的磁盤文件。也就是說(shuō),此時(shí)task會(huì)將數(shù)據(jù)寫入已有的磁盤文件中,而不會(huì)寫入新的磁盤文件中。因此,consolidate機(jī)制允許不同的task復(fù)用同一批磁盤文件,這樣就可以有效將多個(gè)task的磁盤文件進(jìn)行一定程度上的合并,從而大幅度減少磁盤文件的數(shù)量,進(jìn)而提升shuffle write的性能。
假設(shè)第二個(gè)stage有100個(gè)task,第一個(gè)stage有50個(gè)task,總共還是有10個(gè)Executor,每個(gè)Executor執(zhí)行5個(gè)task。那么原本使用未經(jīng)優(yōu)化的HashShuffleManager時(shí),每個(gè)Executor會(huì)產(chǎn)生500個(gè)磁盤文件,所有Executor會(huì)產(chǎn)生5000個(gè)磁盤文件的。但是此時(shí)經(jīng)過(guò)優(yōu)化之后,每個(gè)Executor創(chuàng)建的磁盤文件的數(shù)量的計(jì)算公式為:CPU core的數(shù)量 * 下一個(gè)stage的task數(shù)量。也就是說(shuō),每個(gè)Executor此時(shí)只會(huì)創(chuàng)建100個(gè)磁盤文件,所有Executor只會(huì)創(chuàng)建1000個(gè)磁盤文件。
SortShuffleManager運(yùn)行原理
SortShuffleManager的運(yùn)行機(jī)制主要分成兩種,一種是普通運(yùn)行機(jī)制,另一種是bypass運(yùn)行機(jī)制。當(dāng)shuffle read task的數(shù)量小于等于spark.shuffle.sort.bypassMergeThreshold參數(shù)的值時(shí)(默認(rèn)為200),就會(huì)啟用bypass機(jī)制。
普通運(yùn)行機(jī)制
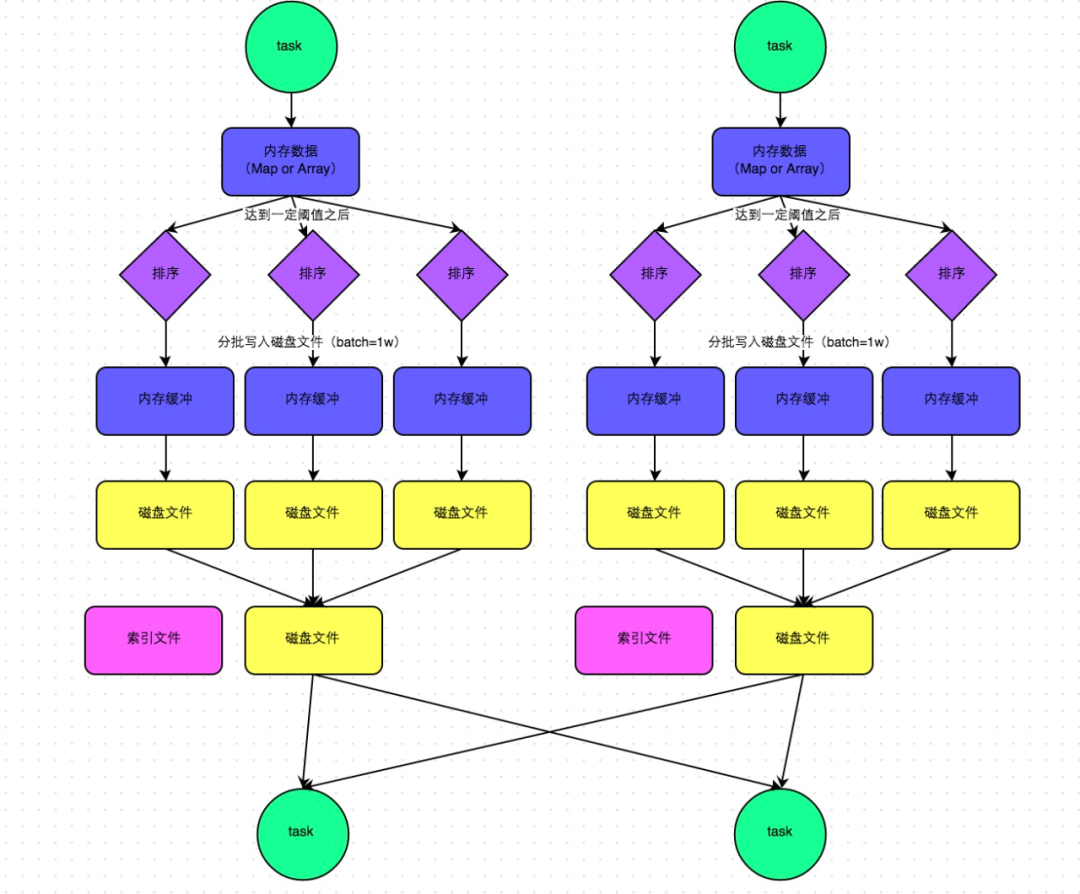
下圖說(shuō)明了普通的SortShuffleManager的原理。在該模式下,數(shù)據(jù)會(huì)先寫入一個(gè)內(nèi)存數(shù)據(jù)結(jié)構(gòu)中,此時(shí)根據(jù)不同的shuffle算子,可能選用不同的數(shù)據(jù)結(jié)構(gòu)。如果是reduceByKey這種聚合類的shuffle算子,那么會(huì)選用Map數(shù)據(jù)結(jié)構(gòu),一邊通過(guò)Map進(jìn)行聚合,一邊寫入內(nèi)存;如果是join這種普通的shuffle算子,那么會(huì)選用Array數(shù)據(jù)結(jié)構(gòu),直接寫入內(nèi)存。接著,每寫一條數(shù)據(jù)進(jìn)入內(nèi)存數(shù)據(jù)結(jié)構(gòu)之后,就會(huì)判斷一下,是否達(dá)到了某個(gè)臨界閾值。如果達(dá)到臨界閾值的話,那么就會(huì)嘗試將內(nèi)存數(shù)據(jù)結(jié)構(gòu)中的數(shù)據(jù)溢寫到磁盤,然后清空內(nèi)存數(shù)據(jù)結(jié)構(gòu)。
在溢寫到磁盤文件之前,會(huì)先根據(jù)key對(duì)內(nèi)存數(shù)據(jù)結(jié)構(gòu)中已有的數(shù)據(jù)進(jìn)行排序。排序過(guò)后,會(huì)分批將數(shù)據(jù)寫入磁盤文件。默認(rèn)的batch數(shù)量是10000條,也就是說(shuō),排序好的數(shù)據(jù),會(huì)以每批1萬(wàn)條數(shù)據(jù)的形式分批寫入磁盤文件。寫入磁盤文件是通過(guò)Java的BufferedOutputStream實(shí)現(xiàn)的。BufferedOutputStream是Java的緩沖輸出流,首先會(huì)將數(shù)據(jù)緩沖在內(nèi)存中,當(dāng)內(nèi)存緩沖滿溢之后再一次寫入磁盤文件中,這樣可以減少磁盤IO次數(shù),提升性能。
一個(gè)task將所有數(shù)據(jù)寫入內(nèi)存數(shù)據(jù)結(jié)構(gòu)的過(guò)程中,會(huì)發(fā)生多次磁盤溢寫操作,也就會(huì)產(chǎn)生多個(gè)臨時(shí)文件。最后會(huì)將之前所有的臨時(shí)磁盤文件都進(jìn)行合并,這就是merge過(guò)程,此時(shí)會(huì)將之前所有臨時(shí)磁盤文件中的數(shù)據(jù)讀取出來(lái),然后依次寫入最終的磁盤文件之中。此外,由于一個(gè)task就只對(duì)應(yīng)一個(gè)磁盤文件,也就意味著該task為下游stage的task準(zhǔn)備的數(shù)據(jù)都在這一個(gè)文件中,因此還會(huì)單獨(dú)寫一份索引文件,其中標(biāo)識(shí)了下游各個(gè)task的數(shù)據(jù)在文件中的start offset與end offset。
SortShuffleManager由于有一個(gè)磁盤文件merge的過(guò)程,因此大大減少了文件數(shù)量。比如第一個(gè)stage有50個(gè)task,總共有10個(gè)Executor,每個(gè)Executor執(zhí)行5個(gè)task,而第二個(gè)stage有100個(gè)task。由于每個(gè)task最終只有一個(gè)磁盤文件,因此此時(shí)每個(gè)Executor上只有5個(gè)磁盤文件,所有Executor只有50個(gè)磁盤文件。
bypass運(yùn)行機(jī)制
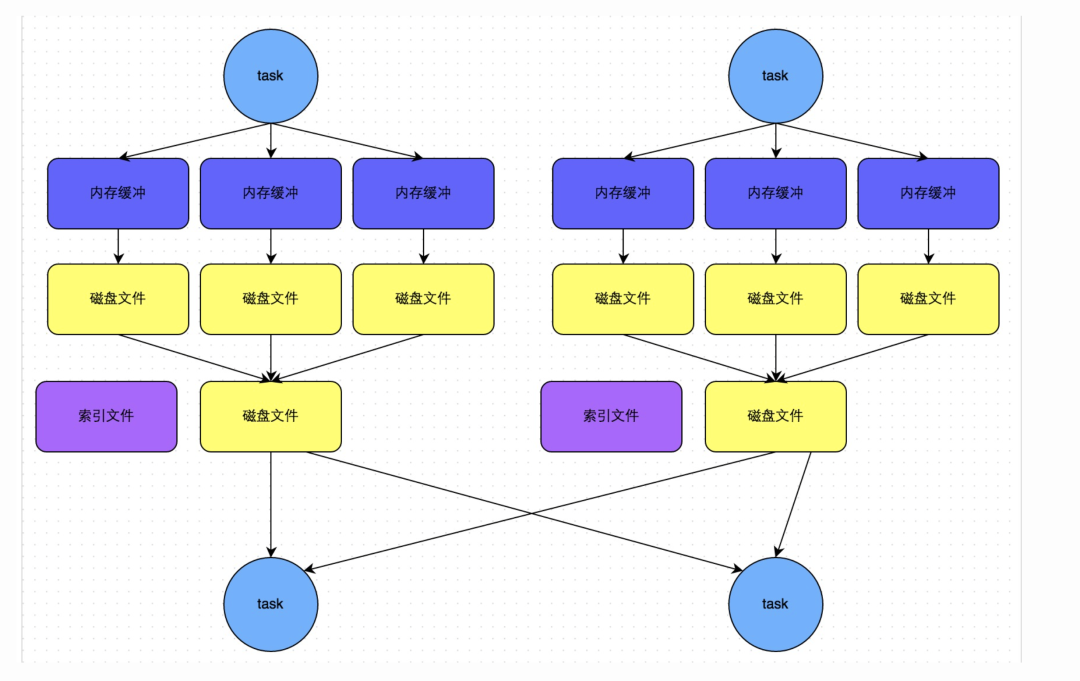
下圖說(shuō)明了bypass SortShuffleManager的原理。bypass運(yùn)行機(jī)制的觸發(fā)條件如下:
shuffle map task數(shù)量小于spark.shuffle.sort.bypassMergeThreshold參數(shù)的值。 不是聚合類的shuffle算子(比如reduceByKey)。
此時(shí)task會(huì)為每個(gè)下游task都創(chuàng)建一個(gè)臨時(shí)磁盤文件,并將數(shù)據(jù)按key進(jìn)行hash然后根據(jù)key的hash值,將key寫入對(duì)應(yīng)的磁盤文件之中。當(dāng)然,寫入磁盤文件時(shí)也是先寫入內(nèi)存緩沖,緩沖寫滿之后再溢寫到磁盤文件的。最后,同樣會(huì)將所有臨時(shí)磁盤文件都合并成一個(gè)磁盤文件,并創(chuàng)建一個(gè)單獨(dú)的索引文件。
該過(guò)程的磁盤寫機(jī)制其實(shí)跟未經(jīng)優(yōu)化的HashShuffleManager是一模一樣的,因?yàn)槎家獎(jiǎng)?chuàng)建數(shù)量驚人的磁盤文件,只是在最后會(huì)做一個(gè)磁盤文件的合并而已。因此少量的最終磁盤文件,也讓該機(jī)制相對(duì)未經(jīng)優(yōu)化的HashShuffleManager來(lái)說(shuō),shuffle read的性能會(huì)更好。
而該機(jī)制與普通SortShuffleManager運(yùn)行機(jī)制的不同在于:第一,磁盤寫機(jī)制不同;第二,不會(huì)進(jìn)行排序。也就是說(shuō),啟用該機(jī)制的最大好處在于,shuffle write過(guò)程中,不需要進(jìn)行數(shù)據(jù)的排序操作,也就節(jié)省掉了這部分的性能開(kāi)銷。
以下是Shffule過(guò)程中的一些主要參數(shù),這里詳細(xì)講解了各個(gè)參數(shù)的功能、默認(rèn)值以及基于實(shí)踐經(jīng)驗(yàn)給出的調(diào)優(yōu)建議。
spark.shuffle.file.buffer
默認(rèn)值:32k
參數(shù)說(shuō)明:該參數(shù)用于設(shè)置shuffle write task的BufferedOutputStream的buffer緩沖大小。將數(shù)據(jù)寫到磁盤文件之前,會(huì)先寫入buffer緩沖中,待緩沖寫滿之后,才會(huì)溢寫到磁盤。
調(diào)優(yōu)建議:如果作業(yè)可用的內(nèi)存資源較為充足的話,可以適當(dāng)增加這個(gè)參數(shù)的大小(比如64k),從而減少shuffle write過(guò)程中溢寫磁盤文件的次數(shù),也就可以減少磁盤IO次數(shù),進(jìn)而提升性能。在實(shí)踐中發(fā)現(xiàn),合理調(diào)節(jié)該參數(shù),性能會(huì)有1%~5%的提升。
spark.reducer.maxSizeInFlight
默認(rèn)值:48m
參數(shù)說(shuō)明:該參數(shù)用于設(shè)置shuffle read task的buffer緩沖大小,而這個(gè)buffer緩沖決定了每次能夠拉取多少數(shù)據(jù)。
調(diào)優(yōu)建議:如果作業(yè)可用的內(nèi)存資源較為充足的話,可以適當(dāng)增加這個(gè)參數(shù)的大小(比如96m),從而減少拉取數(shù)據(jù)的次數(shù),也就可以減少網(wǎng)絡(luò)傳輸?shù)拇螖?shù),進(jìn)而提升性能。在實(shí)踐中發(fā)現(xiàn),合理調(diào)節(jié)該參數(shù),性能會(huì)有1%~5%的提升。
spark.shuffle.io.maxRetries
默認(rèn)值:3
參數(shù)說(shuō)明:shuffle read task從shuffle write task所在節(jié)點(diǎn)拉取屬于自己的數(shù)據(jù)時(shí),如果因?yàn)榫W(wǎng)絡(luò)異常導(dǎo)致拉取失敗,是會(huì)自動(dòng)進(jìn)行重試的。該參數(shù)就代表了可以重試的最大次數(shù)。如果在指定次數(shù)之內(nèi)拉取還是沒(méi)有成功,就可能會(huì)導(dǎo)致作業(yè)執(zhí)行失敗。
調(diào)優(yōu)建議:對(duì)于那些包含了特別耗時(shí)的shuffle操作的作業(yè),建議增加重試最大次數(shù)(比如60次),以避免由于JVM的full gc或者網(wǎng)絡(luò)不穩(wěn)定等因素導(dǎo)致的數(shù)據(jù)拉取失敗。在實(shí)踐中發(fā)現(xiàn),對(duì)于針對(duì)超大數(shù)據(jù)量(數(shù)十億~上百億)的shuffle過(guò)程,調(diào)節(jié)該參數(shù)可以大幅度提升穩(wěn)定性。
spark.shuffle.io.retryWait
默認(rèn)值:5s
參數(shù)說(shuō)明:具體解釋同上,該參數(shù)代表了每次重試?yán)?shù)據(jù)的等待間隔,默認(rèn)是5s。
調(diào)優(yōu)建議:建議加大間隔時(shí)長(zhǎng)(比如60s),以增加shuffle操作的穩(wěn)定性。
spark.shuffle.memoryFraction
默認(rèn)值:0.2
參數(shù)說(shuō)明:該參數(shù)代表了Executor內(nèi)存中,分配給shuffle read task進(jìn)行聚合操作的內(nèi)存比例,默認(rèn)是20%。
調(diào)優(yōu)建議:在資源參數(shù)調(diào)優(yōu)中講解過(guò)這個(gè)參數(shù)。如果內(nèi)存充足,而且很少使用持久化操作,建議調(diào)高這個(gè)比例,給shuffle read的聚合操作更多內(nèi)存,以避免由于內(nèi)存不足導(dǎo)致聚合過(guò)程中頻繁讀寫磁盤。在實(shí)踐中發(fā)現(xiàn),合理調(diào)節(jié)該參數(shù)可以將性能提升10%左右。
spark.shuffle.manager
默認(rèn)值:sort
參數(shù)說(shuō)明:該參數(shù)用于設(shè)置ShuffleManager的類型。Spark 1.5以后,有三個(gè)可選項(xiàng):hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默認(rèn)選項(xiàng),但是Spark 1.2以及之后的版本默認(rèn)都是SortShuffleManager了。tungsten-sort與sort類似,但是使用了tungsten計(jì)劃中的堆外內(nèi)存管理機(jī)制,內(nèi)存使用效率更高。
調(diào)優(yōu)建議:由于SortShuffleManager默認(rèn)會(huì)對(duì)數(shù)據(jù)進(jìn)行排序,因此如果你的業(yè)務(wù)邏輯中需要該排序機(jī)制的話,則使用默認(rèn)的SortShuffleManager就可以;而如果你的業(yè)務(wù)邏輯不需要對(duì)數(shù)據(jù)進(jìn)行排序,那么建議參考后面的幾個(gè)參數(shù)調(diào)優(yōu),通過(guò)bypass機(jī)制或優(yōu)化的HashShuffleManager來(lái)避免排序操作,同時(shí)提供較好的磁盤讀寫性能。這里要注意的是,tungsten-sort要慎用,因?yàn)橹鞍l(fā)現(xiàn)了一些相應(yīng)的bug。
spark.shuffle.sort.bypassMergeThreshold
默認(rèn)值:200
參數(shù)說(shuō)明:當(dāng)ShuffleManager為SortShuffleManager時(shí),如果shuffle read task的數(shù)量小于這個(gè)閾值(默認(rèn)是200),則shuffle write過(guò)程中不會(huì)進(jìn)行排序操作,而是直接按照未經(jīng)優(yōu)化的HashShuffleManager的方式去寫數(shù)據(jù),但是最后會(huì)將每個(gè)task產(chǎn)生的所有臨時(shí)磁盤文件都合并成一個(gè)文件,并會(huì)創(chuàng)建單獨(dú)的索引文件。
調(diào)優(yōu)建議:當(dāng)你使用SortShuffleManager時(shí),如果的確不需要排序操作,那么建議將這個(gè)參數(shù)調(diào)大一些,大于shuffle read task的數(shù)量。那么此時(shí)就會(huì)自動(dòng)啟用bypass機(jī)制,map-side就不會(huì)進(jìn)行排序了,減少了排序的性能開(kāi)銷。但是這種方式下,依然會(huì)產(chǎn)生大量的磁盤文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
默認(rèn)值:false
參數(shù)說(shuō)明:如果使用HashShuffleManager,該參數(shù)有效。如果設(shè)置為true,那么就會(huì)開(kāi)啟consolidate機(jī)制,會(huì)大幅度合并shuffle write的輸出文件,對(duì)于shuffle read task數(shù)量特別多的情況下,這種方法可以極大地減少磁盤IO開(kāi)銷,提升性能。
調(diào)優(yōu)建議:如果的確不需要SortShuffleManager的排序機(jī)制,那么除了使用bypass機(jī)制,還可以嘗試將spark.shffle.manager參數(shù)手動(dòng)指定為hash,使用HashShuffleManager,同時(shí)開(kāi)啟consolidate機(jī)制。在實(shí)踐中嘗試過(guò),發(fā)現(xiàn)其性能比開(kāi)啟了bypass機(jī)制的SortShuffleManager要高出10%~30%。
本文分別講解了開(kāi)發(fā)過(guò)程中的優(yōu)化原則、運(yùn)行前的資源參數(shù)設(shè)置調(diào)優(yōu)、運(yùn)行中的數(shù)據(jù)傾斜的解決方案、為了精益求精的shuffle調(diào)優(yōu)。希望大家能夠在閱讀本文之后,記住這些性能調(diào)優(yōu)的原則以及方案,在Spark作業(yè)開(kāi)發(fā)、測(cè)試以及運(yùn)行的過(guò)程中多嘗試,只有這樣,我們才能開(kāi)發(fā)出更優(yōu)的Spark作業(yè),不斷提升其性能。
本文鏈接:https://tech.meituan.com/2016/05/12/spark-tuning-pro.html
猜你喜歡