
聊聊 Kafka Consumer 那點(diǎn)事
? ? ??
? ? ?在上一篇中我們?cè)敿?xì)聊了關(guān)于 Kafka Producer 內(nèi)部的底層原理設(shè)計(jì)思想和細(xì)節(jié), 本篇我們主要來(lái)聊聊?Kafka Consumer?即消費(fèi)者的內(nèi)部底層原理設(shè)計(jì)思想。
Consumer之總體概述
? ? ? 在 Kafka 中, 我們把消費(fèi)消息的一方稱為 Consumer?即?消費(fèi)者, 它是 Kafka 的核心組件之一。它的主要功能是將 Producer 生產(chǎn)的消息進(jìn)行消費(fèi)處理,完成消費(fèi)任務(wù)。那么這些 Producer 產(chǎn)生的消息是怎么被 Consumer 消費(fèi)的呢?又是基于何種消費(fèi)方式進(jìn)行消費(fèi),分區(qū)分配策略都有哪些,消費(fèi)者組以及重平衡機(jī)制是如何處理的,偏移量如何提交和存儲(chǔ),消費(fèi)進(jìn)度如何監(jiān)控, 如何保證消費(fèi)處理完成?接下來(lái)會(huì)逐一講解說(shuō)明。
Consumer之消費(fèi)方式詳解
? ? ? ?我們知道消息隊(duì)列一般有兩種實(shí)現(xiàn)方式,(1)Push(推模式) (2)Pull(拉模式),那么 Kafka Consumer 究竟采用哪種方式進(jìn)行消費(fèi)的呢?其實(shí)?Kafka?Consumer 采用的是主動(dòng)拉取 Broker 數(shù)據(jù)進(jìn)行消費(fèi)的即 Pull 模式。這兩種方式各有優(yōu)劣,我們來(lái)分析一下:
? ? ? ?1)、為什么不采用Push模式?如果是選擇 Push 模式最大缺點(diǎn)就是 Broker 不清楚 Consumer 的消費(fèi)速度,且推送速率是 Broker 進(jìn)行控制的, 這樣很容易造成消息堆積,如果 Consumer 中執(zhí)行的任務(wù)操作是比較耗時(shí)的,那么 Consumer 就會(huì)處理的很慢, 嚴(yán)重情況可能會(huì)導(dǎo)致系統(tǒng) Crash。
? ? ??? 2)、為什么采用Pull模式?如果選擇 Pull 模式,這時(shí) Consumer 可以根據(jù)自己的情況和狀態(tài)來(lái)拉取數(shù)據(jù), 也可以進(jìn)行延遲處理。但是 Pull 模式也有不足,Kafka 又是如何解決這一問(wèn)題?如果 Kafka Broker 沒(méi)有消息,這時(shí)每次 Consumer 拉取的都是空數(shù)據(jù),?可能會(huì)一直循環(huán)返回空數(shù)據(jù)。?針對(duì)這個(gè)問(wèn)題,Consumer 在每次調(diào)用 Poll() 消費(fèi)數(shù)據(jù)的時(shí)候,順帶一個(gè) timeout 參數(shù),當(dāng)返回空數(shù)據(jù)的時(shí)候,會(huì)在?Long?Polling?中進(jìn)行阻塞,等待 timeout 再去消費(fèi),直到數(shù)據(jù)到達(dá)。??
Consumer之初始化
? ? ? ??聊完 Consumer 消費(fèi)方式和優(yōu)缺點(diǎn)以及 Kafka 針對(duì)缺點(diǎn)又是如何權(quán)衡解決的,接下來(lái)我們來(lái)聊聊 Consumer初始化都做了什么?
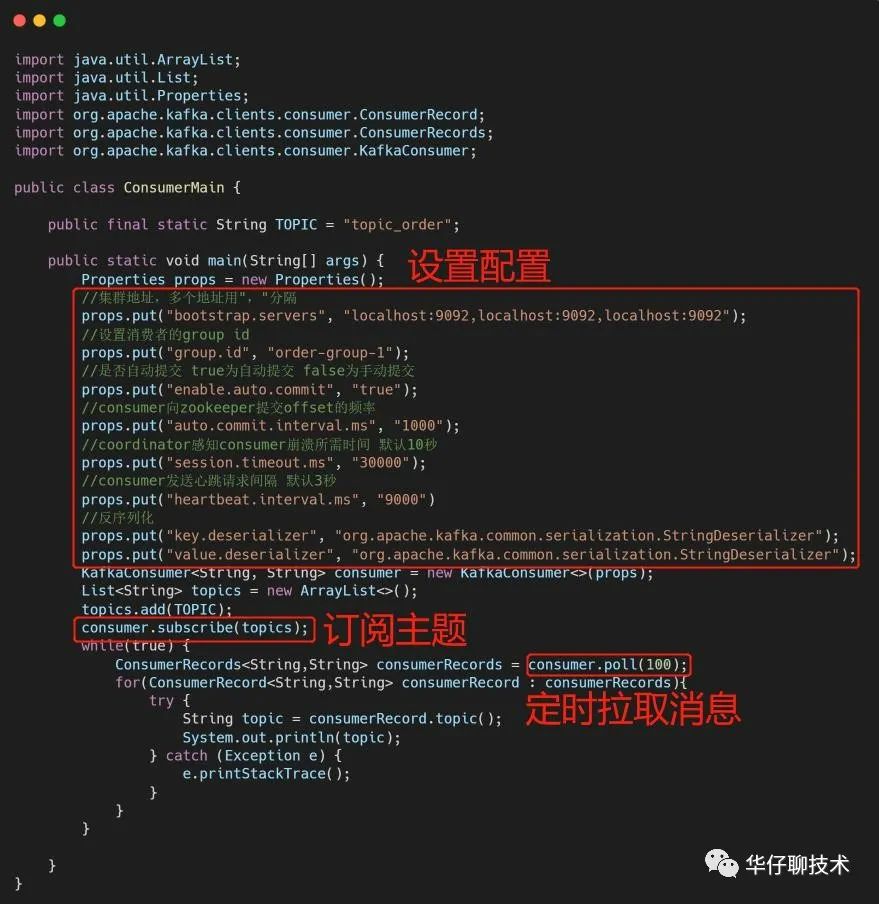
? ? ???Kafka consumer 初始化代碼:
?
? ? ? 從代碼可以看出初始化 Consumer 有4步:
構(gòu)造 Propertity 對(duì)象,進(jìn)行 Consumer 相關(guān)的配置;
創(chuàng)建 KafkaConsumer 的對(duì)象 Consumer;
訂閱相應(yīng)的 Topic 列表;
調(diào)用 Consumer 的 poll() 方法拉取訂閱的消息
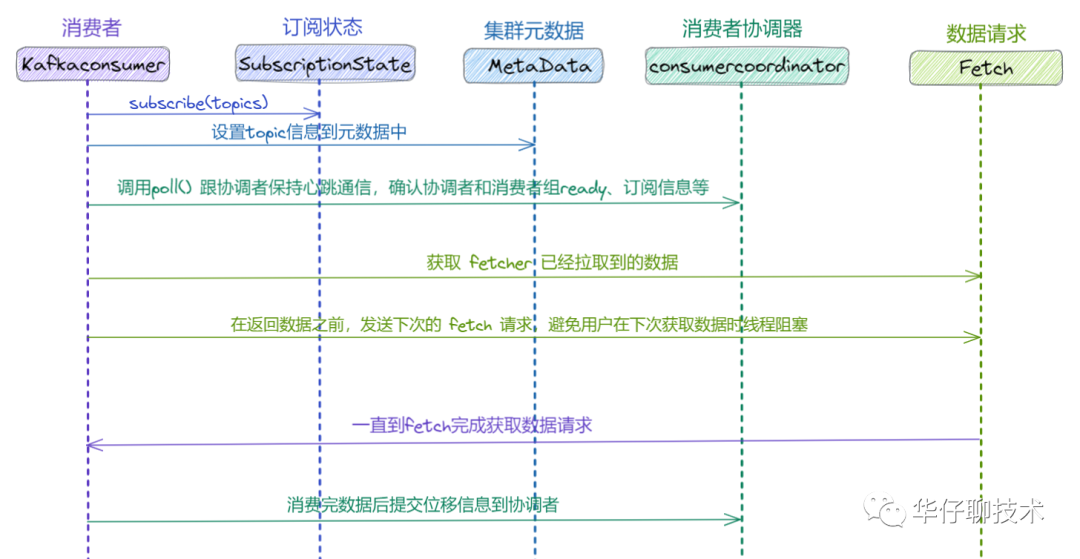
? ? ? ? Kafka consumer 消費(fèi)流程圖如下:
Consumer之消費(fèi)者組機(jī)制
1
Consumer Group機(jī)制
? ? ? ?聊完 Consumer 的初始化流程,接下來(lái)我們來(lái)聊聊 Consumer 消費(fèi)者組機(jī)制,為什么 Kafka 要設(shè)計(jì) Consumer Group, 只有 Consumer 不可以嗎??我們知道 Kafka 是一款高吞吐量,低延遲,高并發(fā),? 高可擴(kuò)展性的消息隊(duì)列產(chǎn)品, 那么如果某個(gè) Topic?擁有數(shù)百萬(wàn)到數(shù)千萬(wàn)的數(shù)據(jù)量, 僅僅依靠 Consumer?進(jìn)程消費(fèi), 消費(fèi)速度可想而知,?所以需要一個(gè)擴(kuò)展性較好的機(jī)制來(lái)保障消費(fèi)進(jìn)度, 這個(gè)時(shí)候 Consumer Group 應(yīng)運(yùn)而生,?Consumer Group 是 Kafka 提供的可擴(kuò)展且具有容錯(cuò)性的消費(fèi)者機(jī)制。
Kafka Consumer Group?特點(diǎn)如下:
每個(gè)?Consumer Group?有一個(gè)或者多個(gè) Consumer
每個(gè)?Consumer Group 擁有一個(gè)公共且唯一的 Group ID
Consumer Group 在消費(fèi) Topic 的時(shí)候,Topic 的每個(gè) Partition 只能分配給組內(nèi)的某個(gè) Consumer,只要被任何 Consumer 消費(fèi)一次,?那么這條數(shù)據(jù)就可以認(rèn)為被當(dāng)前 Consumer Group 消費(fèi)成功
2
Partition 分配策略機(jī)制
? ? ? ??我們知道一個(gè) Consumer Group 中有多個(gè) Consumer,一個(gè) Topic 也有多個(gè) Partition,所以必然會(huì)涉及到 Partition 的分配問(wèn)題: 確定哪個(gè) Partition 由哪個(gè) Consumer 來(lái)消費(fèi)的問(wèn)題。
? ? ?Kafka 客戶端提供了3 種分區(qū)分配策略:RangeAssignor、RoundRobinAssignor 和 StickyAssignor,前兩種分配方案相對(duì)簡(jiǎn)單一些StickyAssignor 分配方案相對(duì)復(fù)雜一些。

? ?RangeAssignor 是 Kafka 默認(rèn)的分區(qū)分配算法,它是按照 Topic 的維度進(jìn)行分配的,對(duì)于每個(gè) Topic,首先對(duì) Partition 按照分區(qū)ID進(jìn)行排序,然后對(duì)訂閱這個(gè) Topic 的 Consumer Group?的 Consumer 再進(jìn)行排序,之后盡量均衡的按照范圍區(qū)段將分區(qū)分配給 Consumer。此時(shí)可能會(huì)造成先分配分區(qū)的 Consumer 進(jìn)程的任務(wù)過(guò)重(分區(qū)數(shù)無(wú)法被消費(fèi)者數(shù)量整除)。
? ?分區(qū)分配場(chǎng)景分析如下圖所示(同一個(gè)消費(fèi)者組下的多個(gè) consumer):
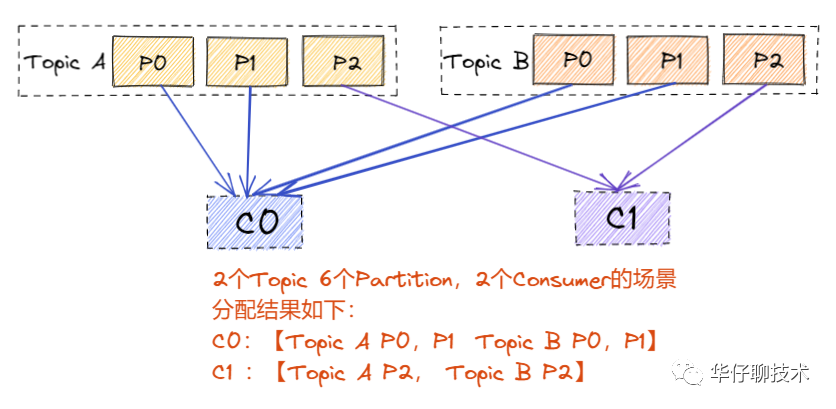
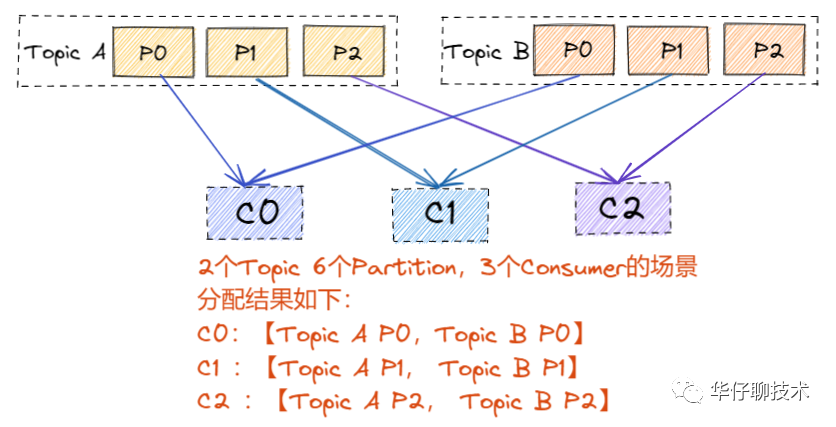
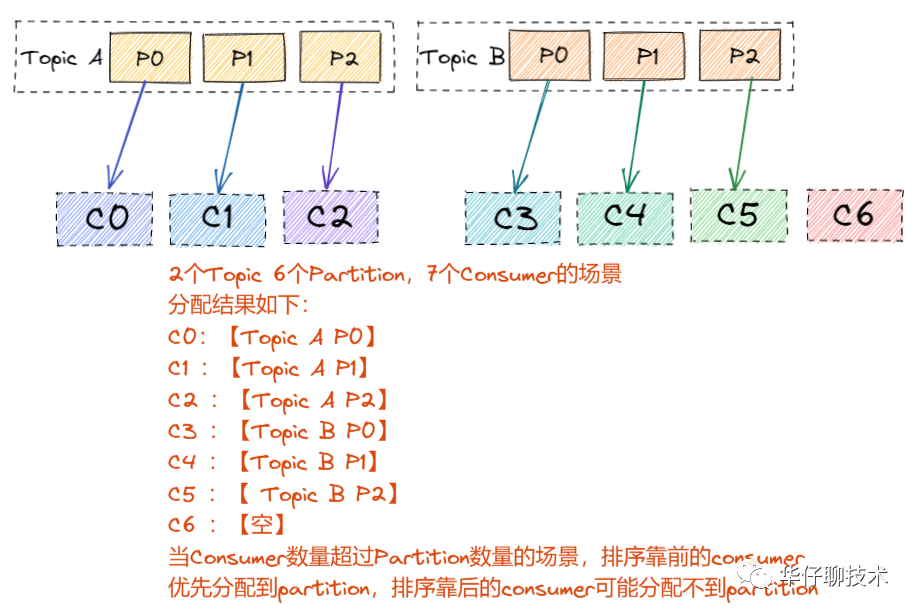
? ? ? ? ? 結(jié)論:這種分配方式明顯的問(wèn)題就是隨著消費(fèi)者訂閱的Topic的數(shù)量的增加,不均衡的問(wèn)題會(huì)越來(lái)越嚴(yán)重。
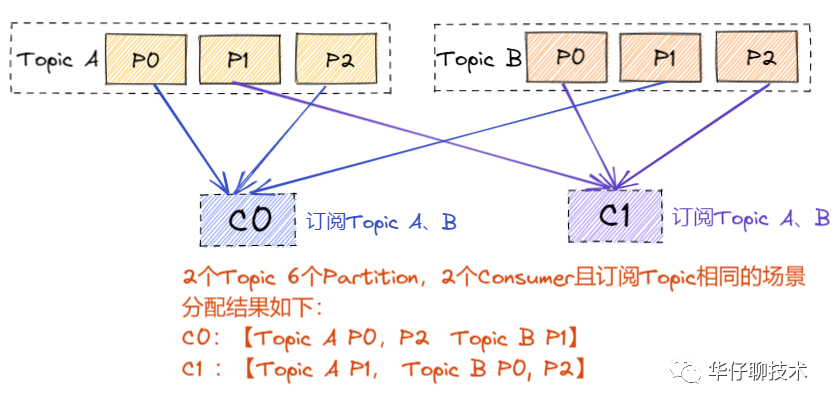
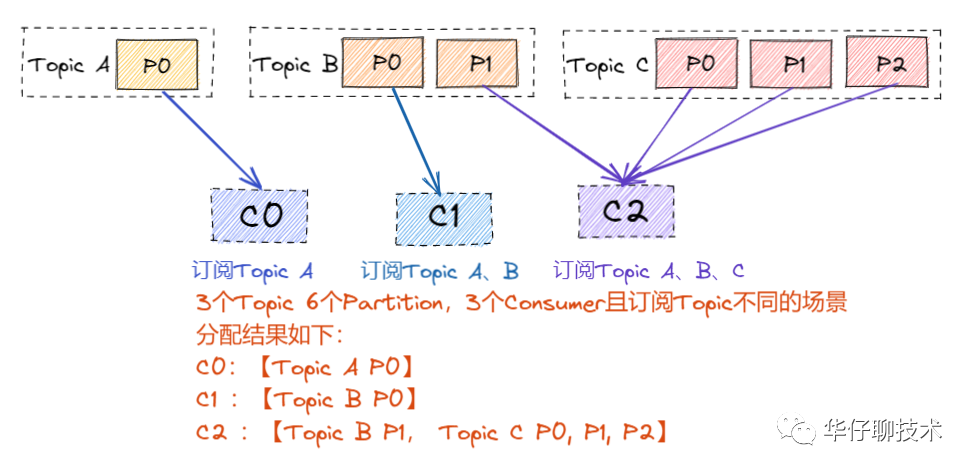
? ?RoundRobinAssignor 的分區(qū)分配策略是將?Consumer Group 內(nèi)訂閱的所有 Topic 的 Partition 及所有 Consumer 進(jìn)行排序后按照順序盡量均衡的一個(gè)一個(gè)進(jìn)行分配。如果 Consumer Group 內(nèi),每個(gè) Consumer 訂閱都訂閱了相同的Topic,那么分配結(jié)果是均衡的。如果訂閱 Topic 是不同的,那么分配結(jié)果是不保證“盡量均衡”的,因?yàn)槟承?Consumer 可能不參與一些 Topic 的分配。
? ?分區(qū)分配場(chǎng)景分析如下圖所示:
? ? 1) 當(dāng)組內(nèi)每個(gè) Consumer 訂閱的 Topic 是相同情況:
? ?2) 當(dāng)組內(nèi)每個(gè)訂閱的 Topic 是不同情況,這樣就可能會(huì)造成分區(qū)訂閱的傾斜:
? ? ?StickyAssignor 分區(qū)分配算法是 Kafka Java 客戶端提供的分配策略中最復(fù)雜的一種,可以通過(guò) partition.assignment.strategy 參數(shù)去設(shè)置,從 0.11 版本開(kāi)始引入,目的就是在執(zhí)行新分配時(shí),盡量在上一次分配結(jié)果上少做調(diào)整,其主要實(shí)現(xiàn)了以下2個(gè)目標(biāo):
? ? 1)、Topic Partition 的分配要盡量均衡。
? ?2)、當(dāng) Rebalance(重分配,后面會(huì)詳細(xì)分析)?發(fā)生時(shí),盡量與上一次分配結(jié)果保持一致。
? ? 注意:當(dāng)兩個(gè)目標(biāo)發(fā)生沖突的時(shí)候,優(yōu)先保證第一個(gè)目標(biāo),這樣可以使分配更加均勻,其中第一個(gè)目標(biāo)是3種分配策略都盡量去嘗試完成的, 而第二個(gè)目標(biāo)才是該算法的精髓所在。
? ? ? 下面我們舉例來(lái)聊聊?RoundRobinAssignor 跟?StickyAssignor的區(qū)別。
? ? ? ?分區(qū)分配場(chǎng)景分析如下圖所示:
? ? ? ?1)組內(nèi)每個(gè) Consumer 訂閱的 Topic 是相同情況,RoundRobinAssignor 跟StickyAssignor?分配一致:
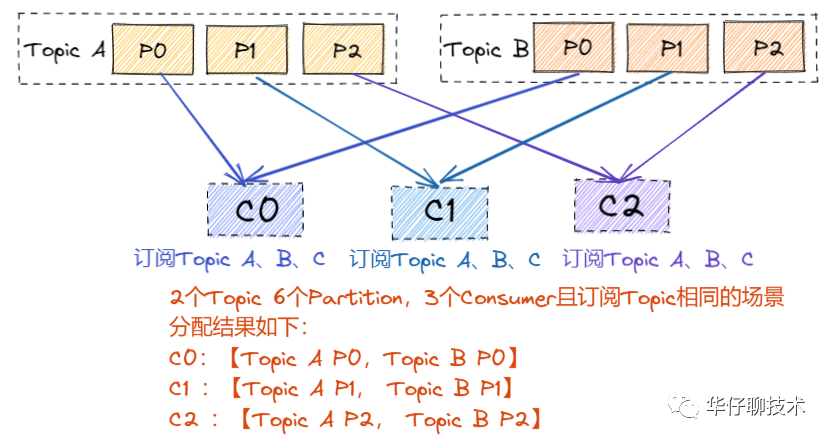
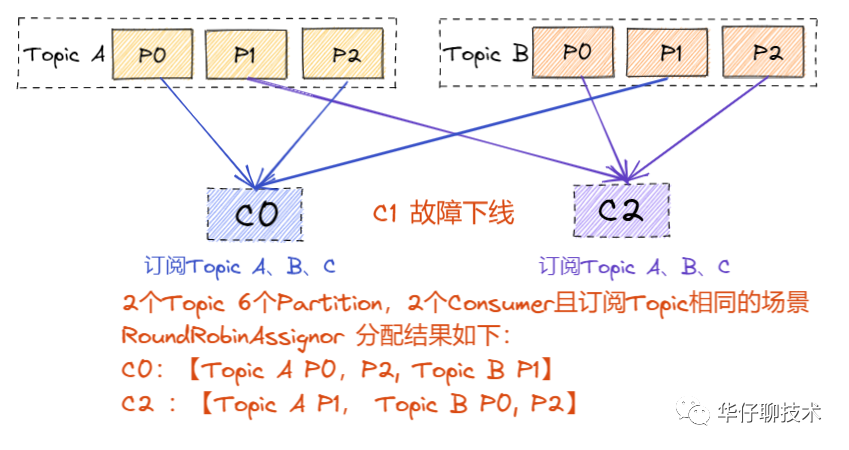
? ? ? ? 當(dāng)上述情況發(fā)生 Rebalance 情況后,可能分配會(huì)不太一樣,假如這時(shí)候C1發(fā)生故障下線:
? ? ? ??RoundRobinAssignor:
? ? ? ??而StickyAssignor:
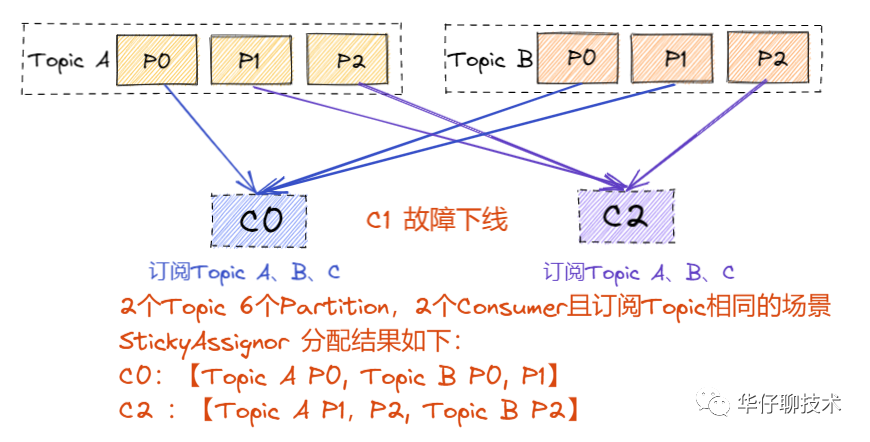
? ? ? ??結(jié)論: 從上面 Rebalance 后的結(jié)果可以看出,雖然兩種分配策略最后都是均勻分配的,但是 RoundRoubinAssignor 完全是重新分配了一遍,而 StickyAssignor 則是在原先的基礎(chǔ)上達(dá)到了均勻的狀態(tài)。
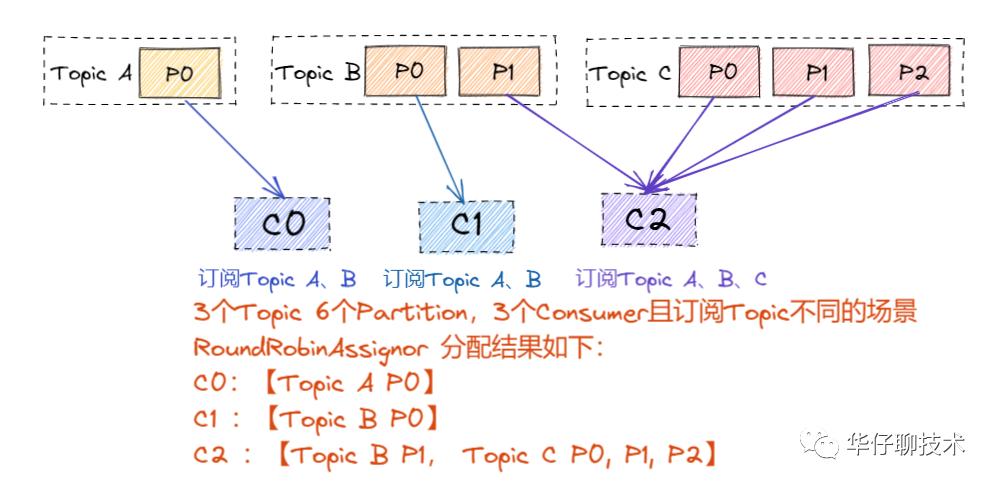
? ? ??2) 當(dāng)組內(nèi)每個(gè)?Consumer?訂閱的 Topic 是不同情況:
? ? ? ?RoundRobinAssignor:
? ? ? ? StickyAssignor:
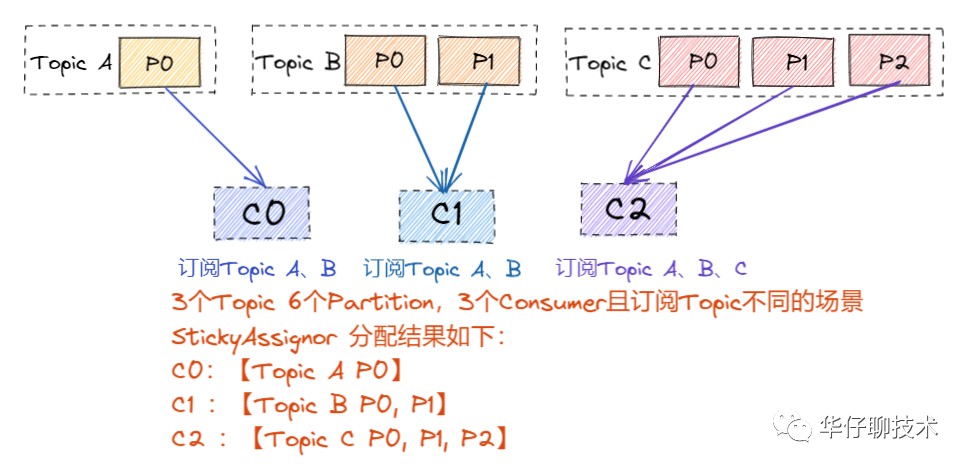
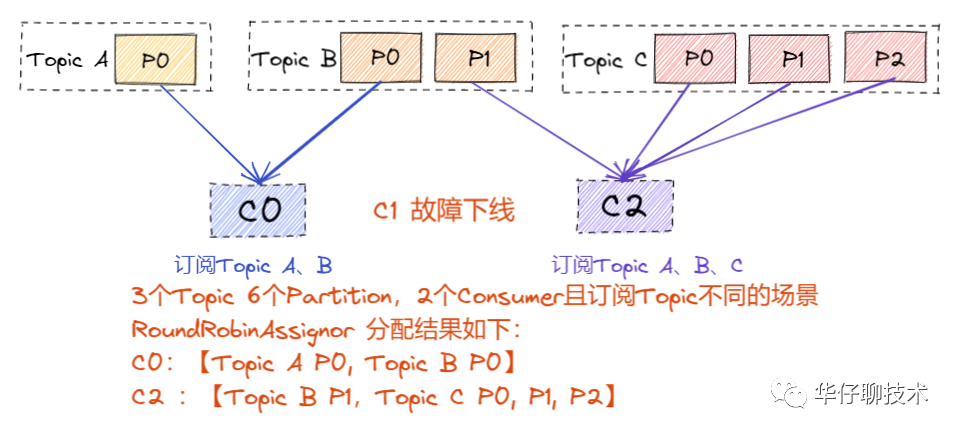
? ? ? 當(dāng)上述情況發(fā)生 Rebalance 情況后,可能分配會(huì)不太一樣,假如這時(shí)候C1發(fā)生故障下線:
? ? ??RoundRobinAssignor:
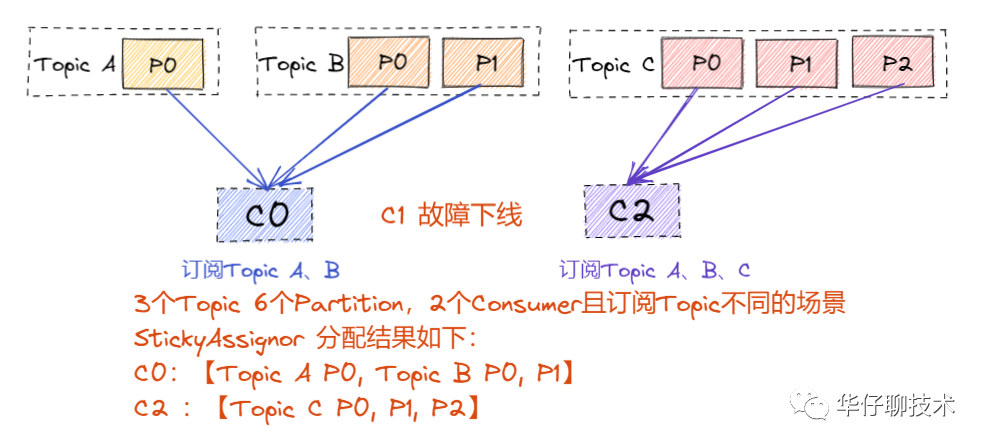
? ? ? StickyAssignor:
? ? ??
? ? ?從上面結(jié)果可以看出,RoundRoubin 的分配策略在 Rebalance (重分配)之后造成了嚴(yán)重的分配傾斜。因此在生產(chǎn)環(huán)境上如果想要減少重分配帶來(lái)的開(kāi)銷,可以選用 StickyAssignor 的分區(qū)分配策略。? ??
??
Consumer之消費(fèi)者組重分配機(jī)制
? ? ? ?上面聊完消費(fèi)者組以及分區(qū)分配策略后,我們來(lái)聊聊 Consumer Group 中 Rebalance (重分配)?機(jī)制,對(duì)于 Consumer Group 來(lái)說(shuō),可能隨時(shí)都會(huì)有 Consumer 加入或退出,那么 Consumer 列表的變化必定會(huì)引起 Partition 的重新分配。我們將這個(gè)分配過(guò)程叫做?Consumer Rebalance,但是這個(gè)分配過(guò)程需要借助 Broker 端的 Coordinator 協(xié)調(diào)者組件,在 Coordinator 的幫助下完成整個(gè)消費(fèi)者組的分區(qū)重分配,也是通過(guò)監(jiān)聽(tīng)ZooKeeper 的?/admin/reassign_partitions 節(jié)點(diǎn)觸發(fā)的。
1
Rebalance 觸發(fā)與通知
??Rebalance 的觸發(fā)條件有三種:
當(dāng) Consumer Group 組成員數(shù)量發(fā)生變化(主動(dòng)加入或者主動(dòng)離組,故障下線等)
當(dāng)訂閱主題數(shù)量發(fā)生變化
當(dāng)訂閱主題的分區(qū)數(shù)發(fā)生變化
? Rebalance 如何通知其他 consumer 進(jìn)程?
? ? ?Rebalance 的通知機(jī)制就是靠 Consumer 端的心跳線程,它會(huì)定期發(fā)送心跳請(qǐng)求到 Broker 端的 Coordinator,當(dāng)協(xié)調(diào)者決定開(kāi)啟 Rebalance 后,它會(huì)將“REBALANCE_IN_PROGRESS”封裝
進(jìn)心跳請(qǐng)求的響應(yīng)中發(fā)送給 Consumer ,當(dāng) Consumer 發(fā)現(xiàn)心跳響應(yīng)中包含了“REBALANCE_IN_PROGRESS”,就知道 Rebalance 開(kāi)始了。
2
協(xié)議 (protocol) 說(shuō)明
? ? ? ? ?其實(shí) Rebalance 本質(zhì)上也是一組協(xié)議。Consumer Group 與 Coordinator 共同使用它來(lái)完成 Consumer Group 的 Rebalance。下面我看看這5種協(xié)議都是什么,完成了什么功能:?
Heartbeat請(qǐng)求:Consumer 需要定期給 Coordinator 發(fā)送心跳來(lái)證明自己還活著。
LeaveGroup請(qǐng)求:主動(dòng)告訴 Coordinator 要離開(kāi) Consumer Group
SyncGroup請(qǐng)求:Group Leader Consumer 把分配方案告訴組內(nèi)所有成員
JoinGroup請(qǐng)求:成員請(qǐng)求加入組
DescribeGroup請(qǐng)求:顯示組的所有信息,包括成員信息,協(xié)議名稱,分配方案,訂閱信息等。通常該請(qǐng)求是給管理員使用。
Coordinator 在 Rebalance 的時(shí)候主要用到了前面4種請(qǐng)求
3
Consumer Group 狀態(tài)機(jī)
? ? ? ? ? ?? ??
? ? ? ?Rebalance?一旦發(fā)生,必定會(huì)涉及到 Consumer Group?的狀態(tài)流轉(zhuǎn),此時(shí) Kafka 為我們?cè)O(shè)計(jì)了一套完整的狀態(tài)機(jī)機(jī)制,來(lái)幫助 Broker Coordinator?完成整個(gè)重平衡流程。了解整個(gè)狀態(tài)流轉(zhuǎn)過(guò)程可以幫助我們深入理解 Consumer Group 的設(shè)計(jì)原理。
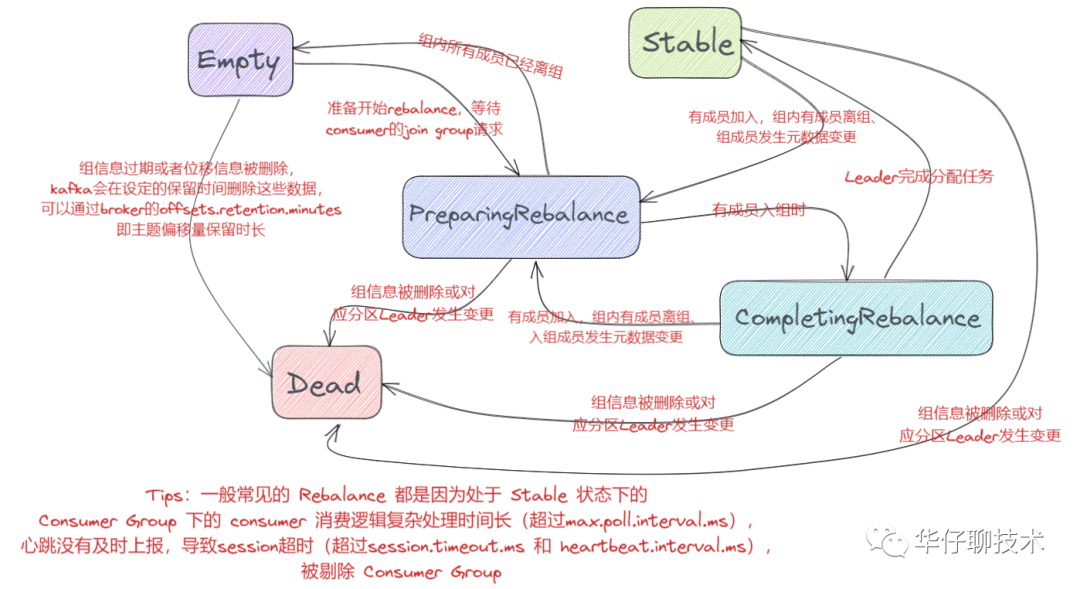
? ? ? 5種狀態(tài),定義分別如下:
? ? ?Empty 狀態(tài)表示當(dāng)前組內(nèi)無(wú)成員,?但是可能存在 Consumer Group 已提交的位移數(shù)據(jù),且未過(guò)期,這種狀態(tài)只能響應(yīng) JoinGroup 請(qǐng)求。
? ??Dead 狀態(tài)表示組內(nèi)已經(jīng)沒(méi)有任何成員的狀態(tài),組內(nèi)的元數(shù)據(jù)已經(jīng)被 Broker Coordinator 移除,這種狀態(tài)響應(yīng)各種請(qǐng)求都是一個(gè)Response:UNKNOWN_MEMBER_ID。
? ? ?PreparingRebalance 狀態(tài)表示準(zhǔn)備開(kāi)始新的 Rebalance, 等待組內(nèi)所有成員重新加入組內(nèi)。
? ? ?CompletingRebalance 狀態(tài)表示組內(nèi)成員都已經(jīng)加入成功,正在等待分配方案,舊版本中叫“AwaitingSync”。
? ? ?Stable 狀態(tài)表示 Rebalance 已經(jīng)完成,?組內(nèi) Consumer 可以開(kāi)始消費(fèi)了。
? ? ?5種狀態(tài)流轉(zhuǎn)圖如下:
4
Rebalance?流程分析
? ? ? ?接下來(lái)我們看看 Rebalance 的流程,通過(guò)上面5種狀態(tài)可以看出,Rebalance 主要分為兩個(gè)步驟:加入組(對(duì)應(yīng)JoinGroup請(qǐng)求)和等待 Leader Consumer 分配方案(SyncGroup?請(qǐng)求)。
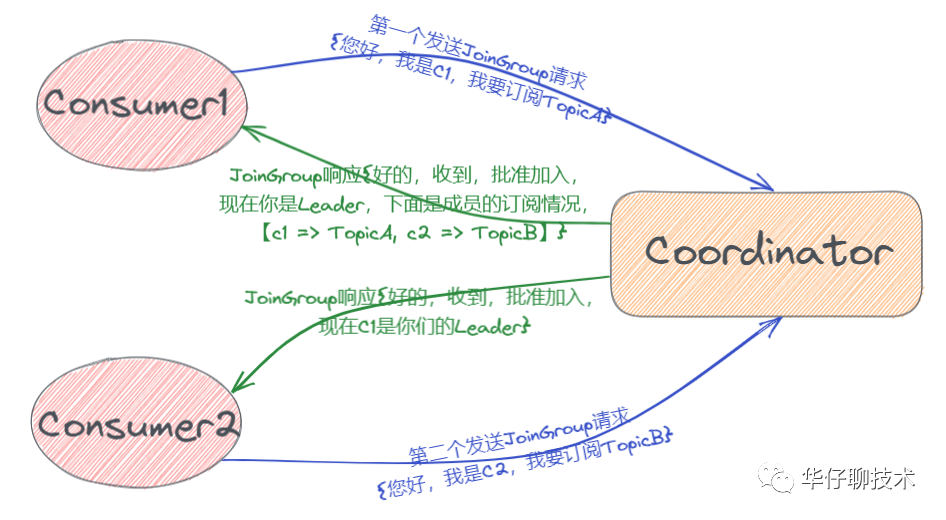
? ? ? 1)、JoinGroup?請(qǐng)求: 組內(nèi)所有成員向?Coordinator?發(fā)送 JoinGroup 請(qǐng)求,請(qǐng)求加入組,順帶會(huì)上報(bào)自己訂閱的 Topic,這樣?Coordinator?就能收集到所有成員的?JoinGroup 請(qǐng)求和訂閱 Topic 信息,Coordinator?就會(huì)從這些成員中選擇一個(gè)擔(dān)任這個(gè)Consumer Group 的 Leader(一般情況下,第一個(gè)發(fā)送請(qǐng)求的 Consumer 會(huì)成為 Leader),這里說(shuō)的Leader 是指具體的某一個(gè) consumer,它的任務(wù)就是收集所有成員的訂閱 Topic 信息,然后制定具體的消費(fèi)分區(qū)分配方案。待選出 Leader 后,Coordinator?會(huì)把 Consumer Group 的訂閱 Topic 信息封裝進(jìn) JoinGroup 請(qǐng)求的 Response 中,然后發(fā)給 Leader ,然后由 Leader 統(tǒng)一做出分配方案后,進(jìn)入到下一步,如下圖:
? ? ?
? ? ? ?2)、SyncGroup 請(qǐng)求:??Leader 開(kāi)始分配消費(fèi)方案,即哪個(gè) Consumer 負(fù)責(zé)消費(fèi)哪些 Topic 的哪些 Partition。一旦完成分配,Leader 會(huì)將這個(gè)分配方案封裝進(jìn) SyncGroup 請(qǐng)求中發(fā)給 Coordinator ,其他成員也會(huì)發(fā) SyncGroup 請(qǐng)求,只是內(nèi)容為空,待 Coordinator 接收到分配方案之后會(huì)把方案封裝進(jìn) SyncGroup 的 Response 中發(fā)給組內(nèi)各成員, 這樣各自就知道應(yīng)該消費(fèi)哪些 Partition 了,如下圖:
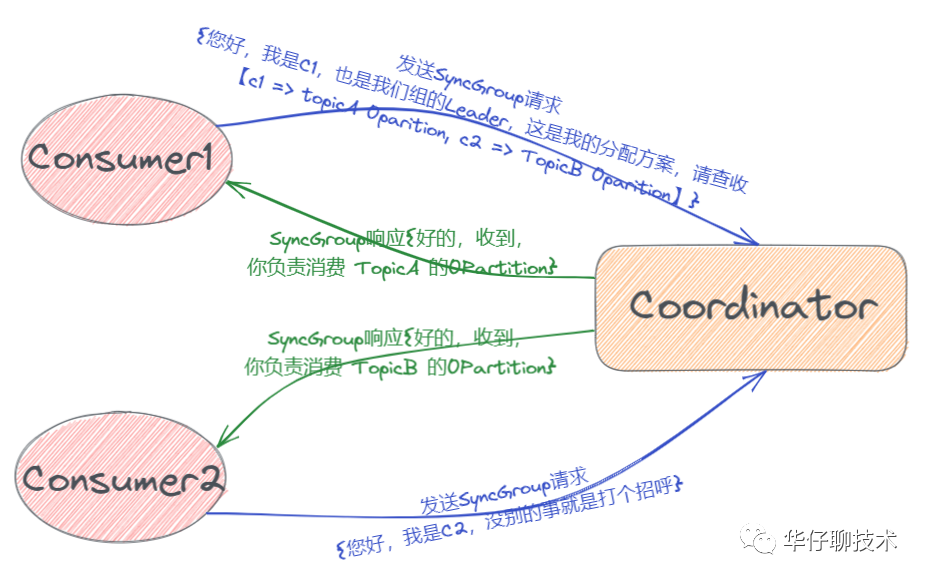
5
Rebalance 場(chǎng)景分析
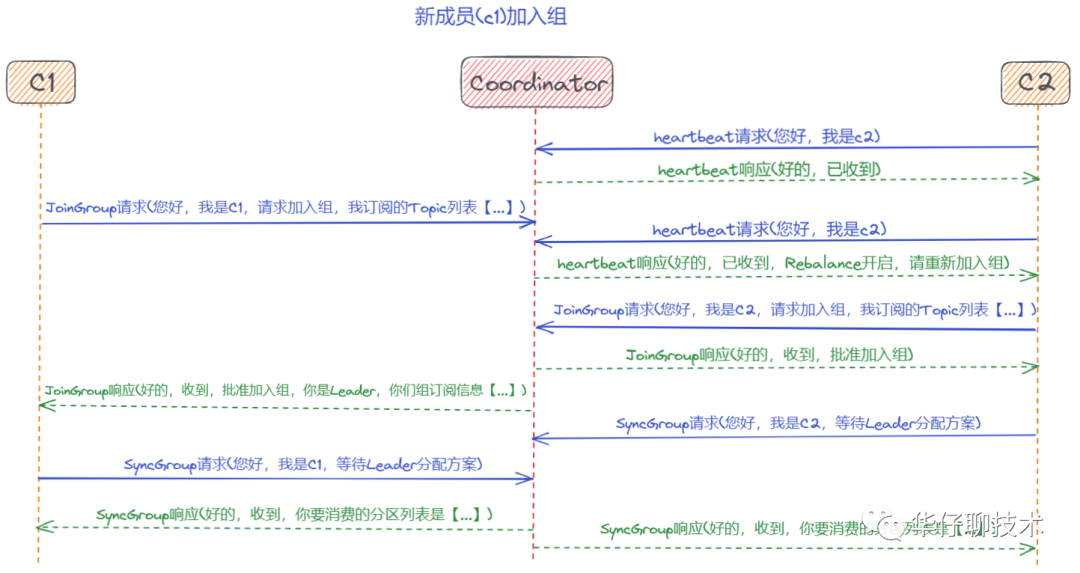
? ? ? 剛剛詳細(xì)的聊了關(guān)于 Rebalance 的狀態(tài)流轉(zhuǎn)與流程分析,接下來(lái)我們通過(guò)時(shí)序圖來(lái)重點(diǎn)分析幾個(gè)場(chǎng)景來(lái)加深對(duì) Rebalance 的理解。
? ? ? ?場(chǎng)景一:新成員(c1)加入組
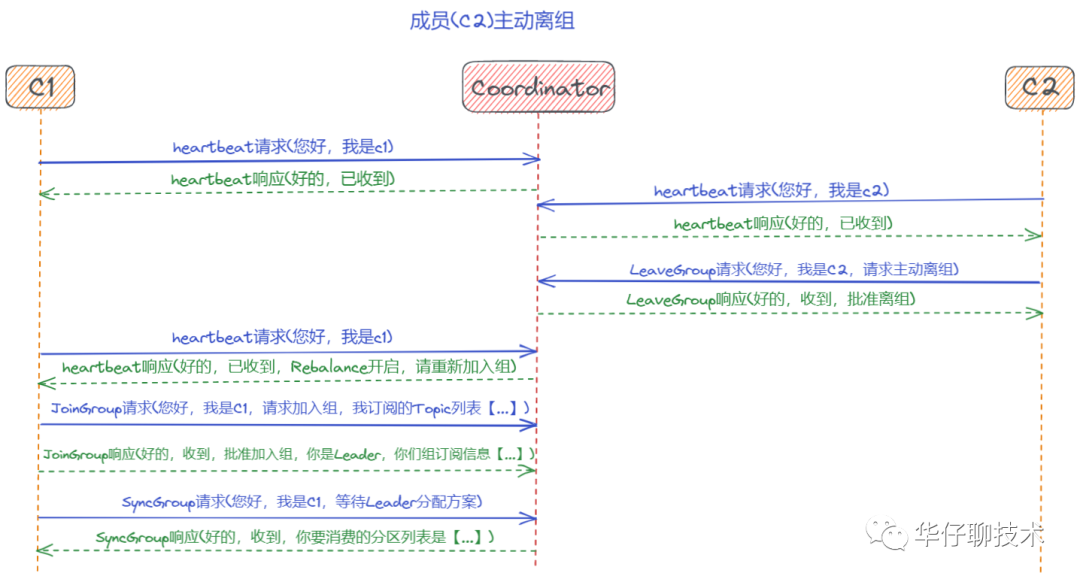
? ? ? ? 場(chǎng)景二:成員(c2)主動(dòng)離組
? ? ? ? 場(chǎng)景三:成員(c2)超時(shí)被踢出組
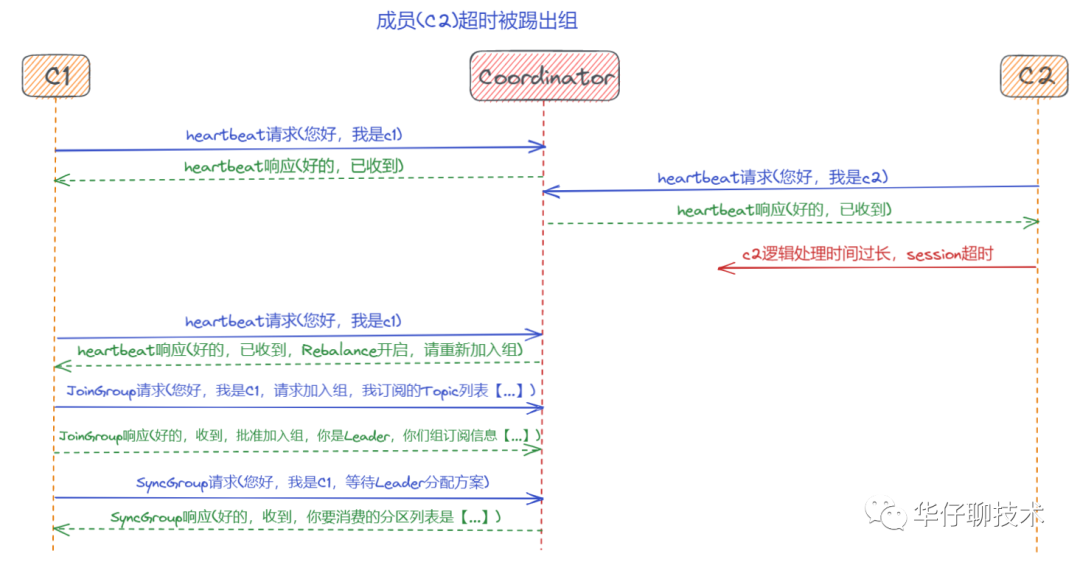
? ? ? ? 場(chǎng)景四:成員(c2)提交位移數(shù)據(jù)
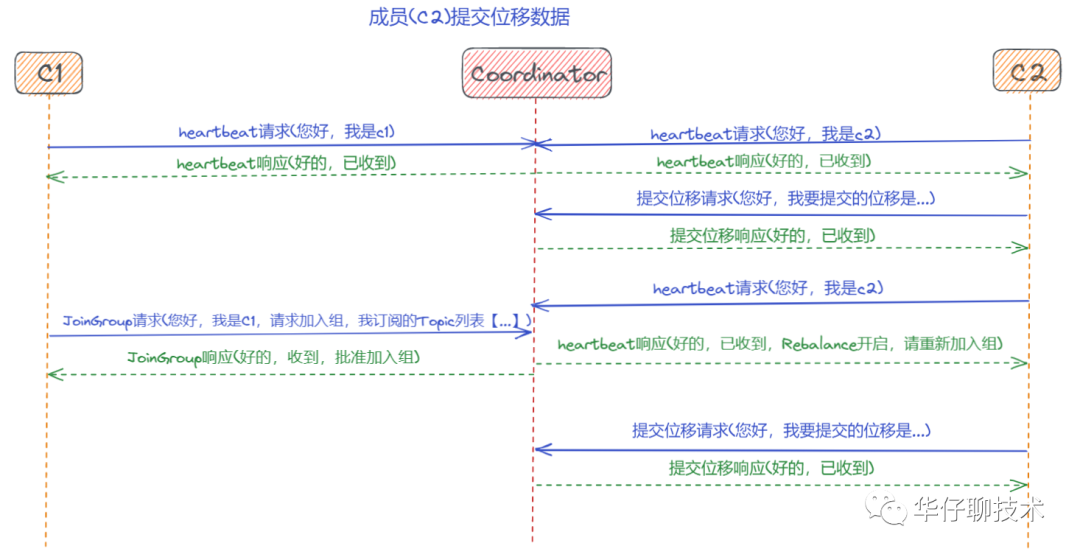
?
Consumer之位移提交機(jī)制
1
位移提交 Offset 概念理解
? ? ? ?上面聊完消費(fèi)者組 Rebalance 機(jī)制后,我們來(lái)聊聊 Consumer 的位移提交機(jī)制,在聊位移提交之前,我們回顧一下 位移 和 消費(fèi)者位移 之間的區(qū)別。通常所說(shuō)的位移是指 Topic Partition 在 Broker 端的存儲(chǔ)偏移量,而消費(fèi)者位移則是指某個(gè) Consumer Group 在不同 Topic Partition 上面的消費(fèi)偏移量(也可以理解為消費(fèi)進(jìn)度),它記錄了 Consumer 要消費(fèi)的下一條消息的位移。
? ? ? ?Consumer 需要向 Kafka 上報(bào)自己的位移數(shù)據(jù)信息,我們將這個(gè)上報(bào)過(guò)程叫做提交位移(Committing Offsets)。它是為了保證 Consumer的消費(fèi)進(jìn)度正常,當(dāng) Consumer 發(fā)生故障重啟后, 可以直接從之前提交的 Offset 位置開(kāi)始進(jìn)行消費(fèi)而不用重頭再來(lái)一遍(Kafka 認(rèn)為小于提交的 Offset 的消息都已經(jīng)成功消費(fèi)了),Kafka 設(shè)計(jì)了這個(gè)機(jī)制來(lái)保障消費(fèi)進(jìn)度。我們知道 Consumer 可以同時(shí)去消費(fèi)多個(gè)分區(qū)的數(shù)據(jù),所以位移提交是按照分區(qū)的粒度進(jìn)行上報(bào)的,也就是說(shuō)?Consumer 需要為分配給它的每個(gè)分區(qū)提交各自的位移數(shù)據(jù)。
2
多種提交方式分析
? ? ? ?Kafka Consumer 提供了多種提交方式,從用戶角度來(lái)說(shuō):位移提交可以分為自動(dòng)提交和手動(dòng)提交,但從 Consumer 的角度來(lái)說(shuō),位移提交可以分為同步提交和異步提交, 接下來(lái)我們就來(lái)聊聊自動(dòng)提交和手動(dòng)提交方式:
? ? ??自動(dòng)提交是指?Kafka Consumer 在后臺(tái)默默地幫我們提交位移,用戶不需要關(guān)心這個(gè)事情。啟用自動(dòng)提交位移,在 初始化 KafkaConsumer 的時(shí)候,通過(guò)設(shè)置參數(shù) enable.auto.commit = true?(默認(rèn)為true),開(kāi)啟之后還需要另外一個(gè)參數(shù)進(jìn)行配合即?auto.commit.interval.ms,這個(gè)參數(shù)表示 Kafka Consumer 每隔 X 秒自動(dòng)提交一次位移,這個(gè)值默認(rèn)是5秒。
? ? ? 自動(dòng)提交看起來(lái)是挺美好的,?那么自動(dòng)提交會(huì)不會(huì)出現(xiàn)消費(fèi)數(shù)據(jù)丟失的情況呢?在設(shè)置了?enable.auto.commit?=?true?的時(shí)候,Kafka 會(huì)保證在開(kāi)始調(diào)用 Poll()?方法時(shí),提交上一批消息的位移,再處理下一批消息, 因此它能保證不出現(xiàn)消費(fèi)丟失的情況。但自動(dòng)提交位移也有設(shè)計(jì)缺陷,那就是它可能會(huì)出現(xiàn)重復(fù)消費(fèi)。就是在自動(dòng)提交間隔之間發(fā)生 Rebalance 的時(shí)候,此時(shí) Offset 還未提交,待 Rebalance 完成后, 所有 Consumer 需要將發(fā)生 Rebalance 前的消息進(jìn)行重新消費(fèi)一次。
? ? ??與自動(dòng)提交相對(duì)應(yīng)的就是手動(dòng)提交了。開(kāi)啟手動(dòng)提交位移的方法就是在初始化KafkaConsumer 的時(shí)候設(shè)置參數(shù) enable.auto.commit =?false,但是只設(shè)置為?false 還不行,它只是告訴 Kafka Consumer 不用自動(dòng)提交位移了,你還需要在處理完消息之后調(diào)用相應(yīng)的? Consumer API 手動(dòng)進(jìn)行提交位移,對(duì)于手動(dòng)提交位移,又分為同步提交和異步提交。
?? 1)、同步提交API:
? ? ? ? ?KafkaConsumer#commitSync(),該方法會(huì)提交由 KafkaConsumer#poll() 方法返回的最新位移值,它是一個(gè)同步操作,會(huì)一直阻塞等待直到位移被成功提交才返回,如果提交的過(guò)程中出現(xiàn)異常,該方法會(huì)將異常拋出。這里我們知道在調(diào)用?commitSync()?方法的時(shí)機(jī)是在處理完 Poll() 方法返回所有消息之后進(jìn)行提交,如果過(guò)早的提交了位移就會(huì)出現(xiàn)消費(fèi)數(shù)據(jù)丟失的情況。
? ?2)、異步提交API:
? ? ? ? KafkaConsumer#commitAsync(),該方法是異步方式進(jìn)行提交的,調(diào)用 commitAsync() 之后,它會(huì)立即返回,并不會(huì)阻塞,因此不會(huì)影響 Consumer 的 TPS。另外 Kafka 針對(duì)它提供了callback,方便我們來(lái)實(shí)現(xiàn)提交之后的邏輯,比如記錄日志或異常處理等等。由于它是一個(gè)異步操作, 假如出現(xiàn)問(wèn)題是不會(huì)進(jìn)行重試的,這時(shí)候重試位移值可能已不是最新值,所以重試無(wú)意義。
? ?3)、混合提交模式:
? ? ? ? 從上面分析可以得出 commitSync 和 commitAsync 都有自己的缺陷,我們需要將 commitSync 和 commitAsync 組合使用才能到達(dá)最理想的效果,既不影響 Consumer TPS,又能利用 commitSync 的自動(dòng)重試功能來(lái)避免一些瞬時(shí)錯(cuò)誤(網(wǎng)絡(luò)抖動(dòng),GC,Rebalance 問(wèn)題),在生產(chǎn)環(huán)境中建議大家使用混合提交模式來(lái)提高 Consumer的健壯性。
Consumer之__consumer_offsets存儲(chǔ)
1
__consumer_offsets 揭秘
? ? ? ?
? ? ? 上面聊完 Consumer 位移提交,我們知道 Consumer 消費(fèi)完數(shù)據(jù)后需要進(jìn)行位移提交, 那么提交的位移數(shù)據(jù)究竟存儲(chǔ)在哪里, 又是以何種方式進(jìn)行存儲(chǔ)的,接下來(lái)我們就看看新舊版本 Kafka 對(duì)于 Offset 存儲(chǔ)方式。
? ? ? ? 我們知道 Kafka?舊版本(0.8版本之前)是重度依賴 Zookeeper 來(lái)實(shí)現(xiàn)各種各樣的協(xié)調(diào)管理,當(dāng)然舊版本的 Consumer Group 是把位移保存在 ZooKeeper 中,減少 Broker 端狀態(tài)存儲(chǔ)開(kāi)銷,鑒于?Zookeeper 的存儲(chǔ)架構(gòu)設(shè)計(jì)來(lái)說(shuō), 它不適合頻繁寫更新,而 Consumer Group 的位移提交又是高頻寫操作,這樣會(huì)拖慢?ZooKeeper?集群的性能,?于是在新版 Kafka 中,?社區(qū)重新設(shè)計(jì)了?Consumer Group 的位移管理方式,采用了將位移保存在 Kafka 內(nèi)部(這是因?yàn)?Kafka Topic 天然支持高頻寫且持久化),這就是所謂大名鼎鼎的__consumer_offsets。
? ? ? __consumer_offsets:用來(lái)保存 Kafka Consumer 提交的位移信息,另外它是由 Kafka 自動(dòng)創(chuàng)建的,和普通的 Topic 相同,它的消息格式也是 Kafka 自己定義的,我們無(wú)法進(jìn)行修改。這里我們很好奇它的消息格式究竟是怎么樣的,讓我們來(lái)一起分析并揭開(kāi)它的神秘面紗吧。
?? ? ??
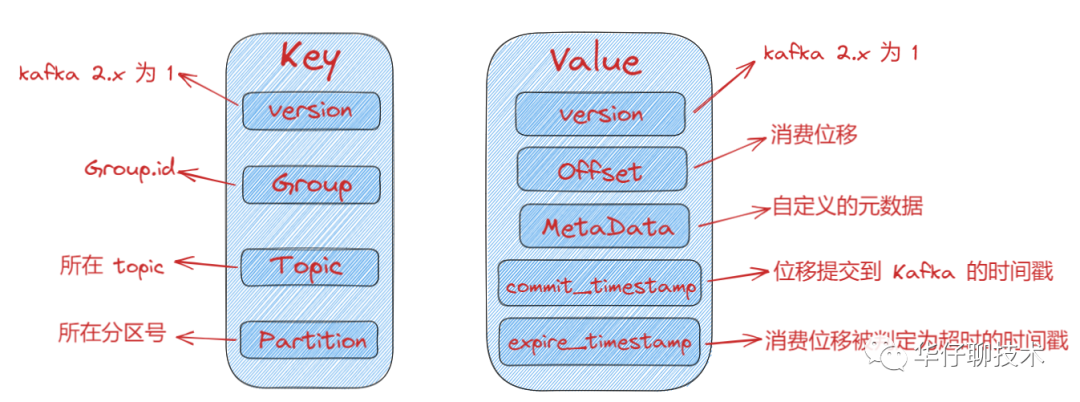
__consumer_offsets?消息格式分析揭秘:
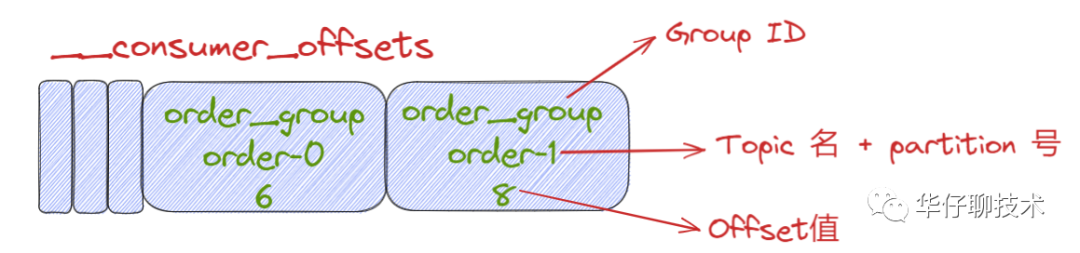
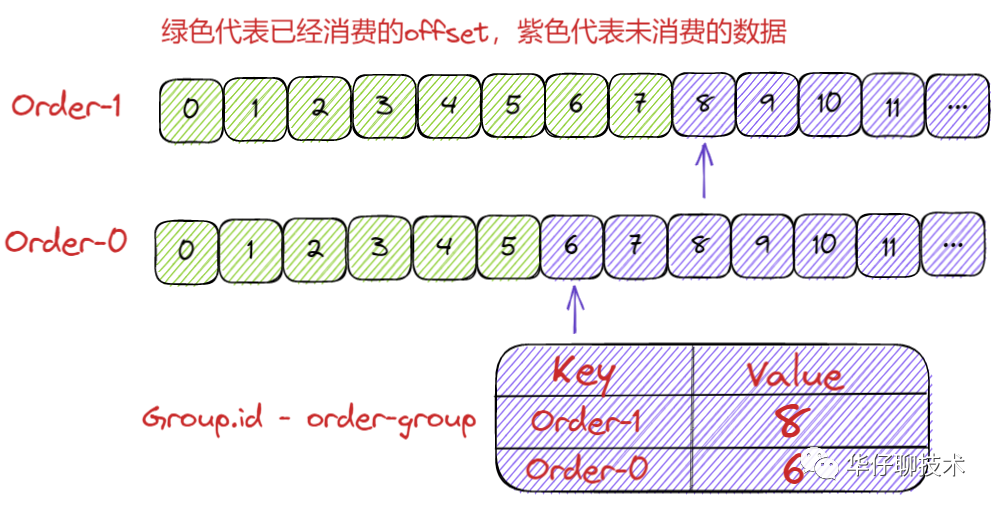
所謂的消息格式我們可以簡(jiǎn)單理解為是一個(gè) KV 對(duì)。Key 和 Value 分別表示消息的鍵值和消息體。
那么 Key 存什么呢?既然是存儲(chǔ) Consumer 的位移信息,在 Kafka 中,Consumer 數(shù)量會(huì)很多,那么必須有字段來(lái)標(biāo)識(shí)這個(gè)位移數(shù)據(jù)是屬于哪個(gè) Consumer的,怎么來(lái)標(biāo)識(shí) Consumer 字段呢?前面在講解 Consumer Group 的時(shí)候我們知道它共享一個(gè)公共且唯一的Group ID,那么只保存它就可以了嗎?我們知道 Consumer 提交位移是在分區(qū)的維度進(jìn)行的,很顯然,key中還應(yīng)該保存 Consumer 要提交位移的分區(qū)。
總結(jié):位移主題的 Key 中應(yīng)該保存 3 部分內(nèi)容:
value 可以簡(jiǎn)單認(rèn)為存儲(chǔ)的是offset值,當(dāng)然底層還存儲(chǔ)其他一些元數(shù)據(jù),幫助 Kafka 來(lái)完成一些其他操作,比如刪除過(guò)期位移數(shù)據(jù)等。
__consumer_offsets 消息格式示意圖:
? ???
2
__consumer_offsets創(chuàng)建過(guò)程
??
? ? ? ?聊完消息格式后, 我們來(lái)聊聊? __consumer_offsets 是怎么被創(chuàng)建出來(lái)的呢??當(dāng) Kafka 集群中的第一個(gè) Consumer 啟動(dòng)時(shí),Kafka 會(huì)自動(dòng)創(chuàng)建__consumer_offsets。前面說(shuō)過(guò),它就是普通的 Topic, 它也有對(duì)應(yīng)的分區(qū)數(shù),如果由 Kafka 自動(dòng)創(chuàng)建的,那么分區(qū)數(shù)又是怎么設(shè)置的呢?這個(gè)依賴?Broker 端參數(shù) offsets.topic.num.partitions?(默認(rèn)值是50),因此 Kafka 會(huì)自動(dòng)創(chuàng)建一個(gè)有?50?個(gè)分區(qū)的__consumer_offsets?。這就是我們?cè)?Kafka 日志路徑下看到有很多 __consumer_offsets-xxx 這樣的目錄的原因。既然有分區(qū)數(shù),必然就會(huì)有對(duì)應(yīng)的副本數(shù),這個(gè)是依賴?Broker 端另一個(gè)參數(shù) offsets.topic.replication.factor(默認(rèn)值為3)。總結(jié)一下,如果__consumer_offsets?由?Kafka 自動(dòng)創(chuàng)建的,那么該 Topic 的分區(qū)數(shù)是 50,副本數(shù)是 3,而具體 Group 的消費(fèi)情況要存儲(chǔ)到哪個(gè) Partition ,根據(jù)abs(GroupId.hashCode()) % NumPartitions 來(lái)計(jì)算的,這樣就可以保證 Consumer Offset?信息與 Consumer Group 對(duì)應(yīng)的 Coordinator 處于同一個(gè) Broker 節(jié)點(diǎn)上。
3
查看__consumer_offsets數(shù)據(jù)
? ? ??Kafka?默認(rèn)提供了腳本供用戶查看 Consumer 信息, 具體的查看方式如下:
//1.查看 kafka 消費(fèi)者組列表:./bin/kafka-consumer-groups.sh --bootstrap-server:9092 --list //2.查看 kafka 中某一個(gè)消費(fèi)者組(test-group-1)的消費(fèi)情況:./bin/kafka-consumer-groups.sh --bootstrap-server:9092 --group test-group-1 --describe //3.計(jì)算 group.id 對(duì)應(yīng)的 partition 的公式為:abs(GroupId.hashCode()) % NumPartitions //其中GroupId:test-group-1 NumPartitions:50//3.找到 group.id 對(duì)應(yīng)的 partition 后,就可以指定分區(qū)消費(fèi)了//kafka 0.11以后./bin/kafka-console-consumer.sh --bootstrap-server message-1:9092 --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --partition xx//kafka 0.11以前./bin/kafka-console-consumer.sh --bootstrap-server message-1:9092 --topic __consumer_offsets --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" --partition xx//4.獲取指定consumer group的位移信息//kafka 0.11以后kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition xx --broker-list:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" //kafka 0.11以前kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition xx --broker-list:9092 --formatter "kafka.coordinator.GroupMetadataManager\$OffsetsMessageFormatter" //5.腳本執(zhí)行后輸出的元數(shù)據(jù)信息//格式:[消費(fèi)者組 : 消費(fèi)的topic : 消費(fèi)的分區(qū)] :: [offset位移], [offset提交時(shí)間], [元數(shù)據(jù)過(guò)期時(shí)間][order-group-1,topic-order,0]::[OffsetMetadata[36672,NO_METADATA],CommitTime?1633694193000,ExpirationTime?1633866993000]
??
Consumer之消費(fèi)進(jìn)度監(jiān)控
? ? ? 上面聊完 Consumer的各個(gè)實(shí)現(xiàn)細(xì)節(jié),我們來(lái)聊聊對(duì)于 Consumer 來(lái)說(shuō),最重要的事情即消費(fèi)進(jìn)度的監(jiān)控, 或者說(shuō)監(jiān)控其滯后程度(Consumer 當(dāng)前落后于 Producer 的程度),這里有個(gè)專業(yè)名詞叫 Consumer Lag。舉例說(shuō)明: Kafka Producer 向某 Topic 成功生產(chǎn)了 1000 萬(wàn)條消息,這時(shí) Consumer 當(dāng)前消費(fèi)了 900 萬(wàn)條消息,那么可以認(rèn)為 Consumer 滯后了 100 萬(wàn)條消息,即 Lag 等于 100 萬(wàn)。
? ? ??對(duì) Consumer 來(lái)說(shuō),Lag 應(yīng)該算是最重要的監(jiān)控指標(biāo)了。它直接反映了一個(gè) Consumer 的運(yùn)行情況。Lag 值越小表示該 Consumer 能夠及時(shí)的消費(fèi) Producer 生產(chǎn)出來(lái)的消息,滯后程度很小;如果該值有增大的趨勢(shì)說(shuō)明可能會(huì)有堆積,嚴(yán)重會(huì)拖慢下游的處理速度。
? ? ?對(duì)于這么重要的指標(biāo),我們?cè)撛趺幢O(jiān)控它呢?主要有 以下幾 種方法:
使用?Kafka 自帶的命令行工具 kafka-consumer-groups 腳本
使用 Kafka Java Consumer API 編程
使用 Kafka 自帶的 JMX 監(jiān)控指標(biāo)
如果是云產(chǎn)品的話, 可以直接使用云產(chǎn)品自帶的監(jiān)控功能
? ?
Consumer之總結(jié)
? ? ? ?至此已經(jīng)跟大家全面深入的剖析了 Kafka Consumer 內(nèi)部底層原理設(shè)計(jì)的方方面面, kafka 原理相關(guān)篇章到此告一段落, 后續(xù)會(huì)針對(duì) Kafka 細(xì)節(jié)技術(shù)點(diǎn)進(jìn)行專題和源碼分析,?大家敬請(qǐng)期待...
堅(jiān)持總結(jié),?持續(xù)輸出高質(zhì)量文章??關(guān)注我:?華仔聊技術(shù)
往期推薦

覺(jué)得不錯(cuò), 點(diǎn)個(gè)再看哦