
【NLP】什么是模型的記憶力!
作者 | 太子長(zhǎng)琴
整理 | NewBeeNLP
語言模型能夠記住一些訓(xùn)練數(shù)據(jù),如果經(jīng)過合適地提示引導(dǎo),可能會(huì)生成記住的數(shù)據(jù)。這肯定不太合適,因?yàn)榭赡軙?huì)侵犯隱私、降低效用(重復(fù)的容易記住的詞往往質(zhì)量比較低),并且有失公平(有些文本被記住而有些沒有)。
在我們今天要分享來自Google的Paper:Quantifying Memorization Across Neural Language Models[1]中,描述了三個(gè)對(duì)數(shù)線性關(guān)系,量化了 LM 生成記憶數(shù)據(jù)的程度。如果增大:(1)模型的容量,(2)樣本的重復(fù)次數(shù),(3)提示文的 Token 數(shù)量,記憶會(huì)顯著增加。總的來說,LM 的記憶比之前認(rèn)識(shí)到的更普遍,并隨著模型不斷增大可能變得更糟。
一句話概述:更大的模型更可能學(xué)到重復(fù)數(shù)據(jù)的特性,去重是緩解模型記憶危害的不錯(cuò)策略。
其實(shí),關(guān)于模型的記憶一直以來都是有被人們認(rèn)識(shí)到的,尤其當(dāng)我們?cè)谧鑫谋旧蓵r(shí),總是特別擔(dān)心模型會(huì)說出什么「驚人」的話語。亞馬遜的音響案例僅僅是一方面,還有可能會(huì)生成政治敏感、歧視、暴力、色情等多種不當(dāng)言論,這還是被動(dòng)的方面。模型也可能被懷有不良意圖的人「誘導(dǎo)」而生成一些能被他們利用到的言論和信息。
目前對(duì) LM 這方面的評(píng)估還比較淺,對(duì)不同大小的模型和數(shù)據(jù)集能帶來多少記憶的變化的理解還不夠深入。之前的很多研究主要聚焦在模型或數(shù)據(jù)集固定的情況,或比較狹窄的變化上。也有衡量現(xiàn)有模型記憶的,但更多關(guān)注如何避免問題并確保模型輸出的新穎性,而不是研究最大限度地記憶來研究模型風(fēng)險(xiǎn)。
本文從三個(gè)能顯著影響記憶的屬性進(jìn)行研究:
模型規(guī)模:大模型比小模型能多記住 2-5 倍的數(shù)據(jù)。 數(shù)據(jù)重復(fù):樣本重復(fù)次數(shù)越多越容易被提取。 上下文:圍繞的上下文越長(zhǎng)越容易被提取。
方法
記憶的定義
如果存在一個(gè)長(zhǎng)度為 k 的文本 p,通過模型 f + greedy decoding,可以生成文本 s,而 p+s 包含在訓(xùn)練數(shù)據(jù)中,則稱 s 是可提取的。選擇此定義的原因是更加可執(zhí)行。其他定義包括:差異隱私或反事實(shí)記憶的下限(需要大量模型評(píng)估隱私,對(duì)大模型不合適);計(jì)算曝光(每個(gè)序列需要數(shù)千個(gè)生成,為精心設(shè)計(jì)訓(xùn)練樣本設(shè)計(jì),大規(guī)模實(shí)驗(yàn)不可行);k-eidetic 記憶,對(duì)非提示的記憶是個(gè)有用的定義,但對(duì)使用訓(xùn)練數(shù)據(jù)進(jìn)行提示的情況不太有用。
評(píng)估數(shù)據(jù)的選擇
首先不可能是所有訓(xùn)練數(shù)據(jù)了,本文選擇了 50000 句,當(dāng)然也不能隨機(jī)選,否則不可能包含到要評(píng)估的方向。本文構(gòu)造了一個(gè)重復(fù)歸一化的子集,對(duì)每個(gè)序列長(zhǎng)度 L(50,100,150,……,500)和整數(shù) n,選擇 1000 個(gè)序列,在訓(xùn)練數(shù)據(jù)中包含了 2^{n/4} - 2^{n+1}/4 次。這個(gè)操作直到某個(gè) n 時(shí),訓(xùn)練數(shù)據(jù)中按此標(biāo)準(zhǔn)沒法得到 1000 句時(shí)停止。這有助于評(píng)估樣本重復(fù)這個(gè)因子。對(duì) 50-500 之間的每個(gè)序列長(zhǎng)度,都分別收集了大約 50000 個(gè)重復(fù)不同次數(shù)的樣本,總共大概 50 萬個(gè)序列。比如,對(duì) L=50,從 n=7 時(shí),重復(fù)次數(shù) 3-4 次,選擇 1000 個(gè),然后增加 n,直到訓(xùn)練數(shù)據(jù)中找不到 1000 個(gè)時(shí)停止,一共大概有 50000 個(gè)。
對(duì)每個(gè)長(zhǎng)度 L,使用前 L-50 個(gè) Token 進(jìn)行提示,預(yù)測(cè) 50 個(gè) Token 看看是不是和原文完全匹配。50 個(gè) Token 對(duì)應(yīng) 127 個(gè)字符或 25 個(gè)單詞,遠(yuǎn)超過典型英語句子的長(zhǎng)度。通過對(duì)所有長(zhǎng)度 L(而不是重復(fù)次數(shù))求平均值來計(jì)算序列可提取的平均概率。
實(shí)驗(yàn)
主要研究 GPT-Neo,在 Pile 數(shù)據(jù)集(各種來源的 825G 語料)上訓(xùn)練的。模型有四種尺寸:125M,1.3B,2.7B 和 6B。
實(shí)驗(yàn)結(jié)果如下圖所示: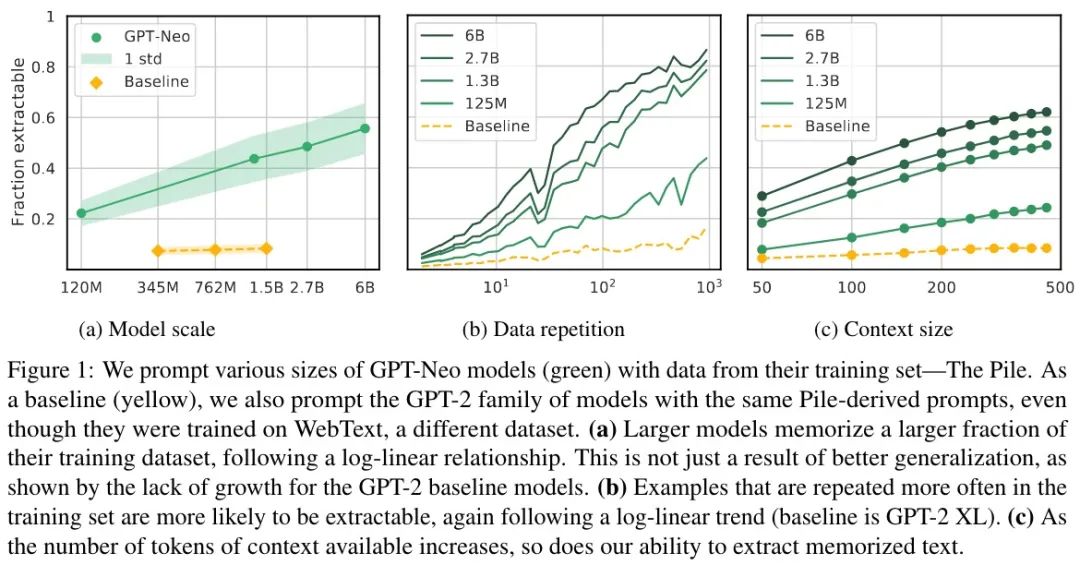
更大模型記住更多
如圖 a 所示,相比 Baseline 的 GPT-2 能完成 6% 的評(píng)估樣本,GPT-Neo 相似大小(1.3B)達(dá)到了 40%,GPT-2 記住的大多是無意義的序列(數(shù)字、重復(fù)的幾個(gè) Token 或標(biāo)點(diǎn))。因此,得出的結(jié)論是: 較大模型具有較高比例的提取率,這是因?yàn)樗鼈冇涀×藬?shù)據(jù),而不僅僅是因?yàn)榇竽P屯ǔ8鼫?zhǔn)確。
重復(fù)文本記住更多
如圖 b 所示,重復(fù)的文本越多被記住的概率越大。而且還可以發(fā)現(xiàn), 即使只有很少的重復(fù)記憶也會(huì)發(fā)生 ,因此去重并不能完美的防止泄露。
更長(zhǎng)的提示記住更多
如圖 c 所示,隨著提示長(zhǎng)度的增加,記憶也有顯著的增加。作者稱其為「可發(fā)現(xiàn)現(xiàn)象」:一些記憶只有在特定條件下才會(huì)變得明顯,例如當(dāng)模型被提示具有足夠長(zhǎng)的上下文時(shí)。一方面看這是好的,因?yàn)橐恍┯洃涬y以被發(fā)現(xiàn);另一方面看,也會(huì)損害我們?cè)跈C(jī)器學(xué)習(xí)模型審計(jì)隱私的能力。
以下是備用實(shí)驗(yàn)設(shè)置,結(jié)果如下圖所示:
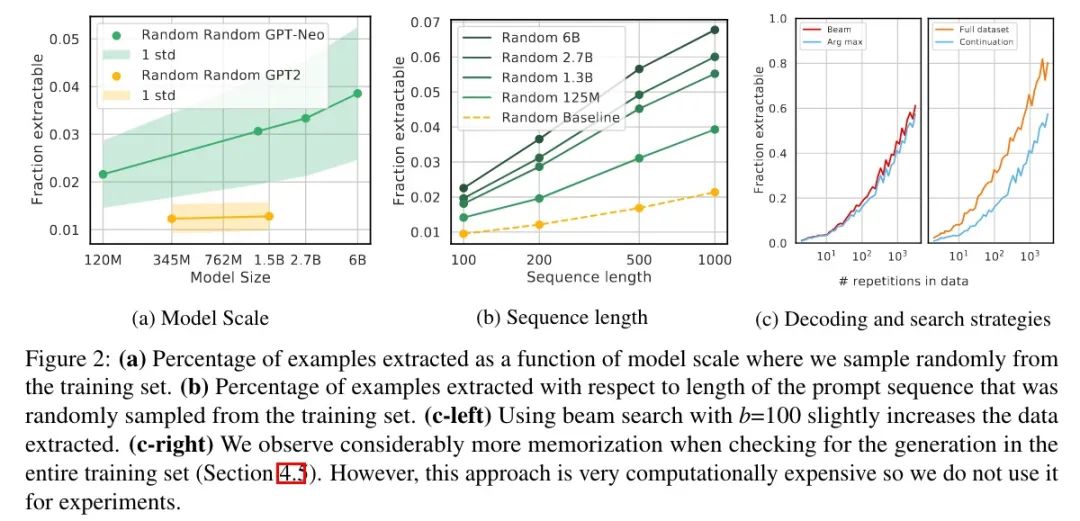
隨機(jī)采樣
為 100 200 500 1000 的長(zhǎng)度各隨機(jī)選擇了 10 萬,結(jié)果如圖 a 和 b 所示,記憶的絕對(duì)概率遠(yuǎn)低于之前實(shí)驗(yàn)的結(jié)果,不過整體的趨勢(shì)是一樣的。另外,長(zhǎng)序列相比短序列更容易預(yù)測(cè)正確(圖 b Baseline,GPT2-XL,1.5B)。
解碼策略
如圖 c(左)所示,beam search(b=100)只是輕微增加了記憶,而且兩者在 45% 的時(shí)間內(nèi)產(chǎn)生了相同的輸出。
其他定義
就是本來是和原始那條數(shù)據(jù)對(duì)比,現(xiàn)在是在整個(gè)語料上看有沒有一樣的。這其實(shí)是放寬了記憶,因?yàn)橛行┚渥忧熬Y一樣,但后面不一樣。按之前那種做法,如果后綴正好生成了另外一句的,那就不算記住了;但現(xiàn)在的定義也算記住了。
結(jié)果如圖 c(右)所示,稍微用腦子想一下都知道結(jié)果肯定是增加了,而且隨著重復(fù)次數(shù)的增加,差異更加明顯。
定性分析
普遍的記憶序列都是非常規(guī)文本,如代碼片段或高度重復(fù)的文本(如開源許可)。另外,增加模型大小會(huì)導(dǎo)致大量非重疊的記憶序列,盡管每個(gè)模型都有一些彼此不同享的記憶量。如下圖所示:
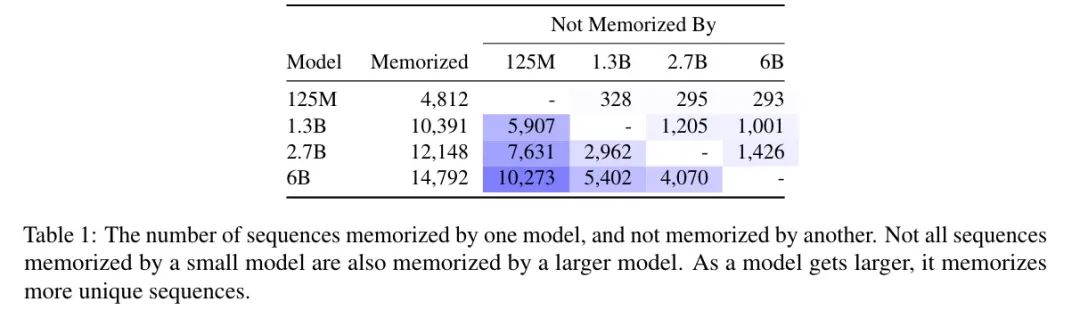
同時(shí),還發(fā)現(xiàn)雖然較小模型的生成和訓(xùn)練數(shù)據(jù)不匹配,但通常主題相關(guān)且局部一致,但它們只是語法上合理,語義上不正確。
復(fù)制研究
接下來,進(jìn)一步將上面的分析復(fù)制到在不同數(shù)據(jù)集(重復(fù)的 C4)和具有不同訓(xùn)練目標(biāo)上訓(xùn)練的不同語言模型家族(T5)上。
實(shí)驗(yàn)結(jié)果如下圖所示:
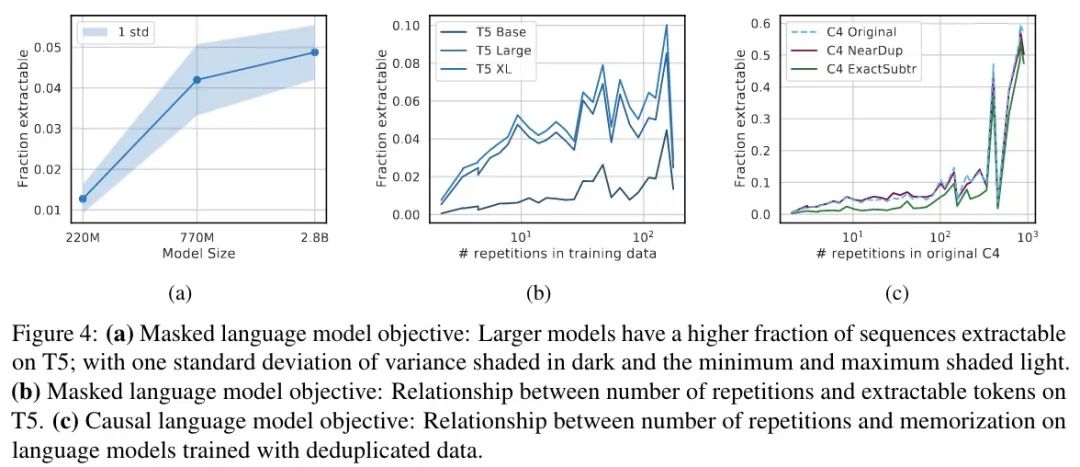
T5 MLM
首先需要重新定義一下什么是記憶,由于是 MLM,這里就定義為可以完美地完成填空(15% 的空),簡(jiǎn)單起見每句只檢查一組。結(jié)果如上圖 a 所示,結(jié)果與圖 1 類似,隨著參數(shù)的增加,記憶增加。雖然趨勢(shì)一致,但與同等大小的因果模型相比,MLM 的記憶要少一個(gè)數(shù)量級(jí)。
接下來是重復(fù)樣本的情況,如上圖 b 所示,結(jié)果開始變得不那么明朗,趨勢(shì)并不明顯,出現(xiàn)大約 140 次的序列更可能被記住。進(jìn)一步定性分析發(fā)現(xiàn),138-158 重復(fù)組中包含的大多數(shù)重復(fù)樣本大多是空格 Token,這就比其他重復(fù)次數(shù)的序列更容易預(yù)測(cè)。
在重復(fù)數(shù)據(jù)上訓(xùn)練的 LM
共三組結(jié)果,分別是:C4,刪除近似重復(fù)的文檔后的 C4,刪除長(zhǎng)度為 50 Token 的重復(fù)后的 C4。結(jié)果如上圖 c 所示,去重后記住的要更少,但只有在重復(fù) 100 次以下時(shí)有效,重復(fù)超過 100 次后就沒用了,可能意味著重復(fù)數(shù)據(jù)刪除并未徹底(重復(fù)的不同但有效的定義)。
說實(shí)話,這個(gè)解釋真的很牽強(qiáng)啊……
結(jié)論
對(duì)于研究文本生成的從業(yè)者來說,本文證明,雖然當(dāng)前 LM 確實(shí)準(zhǔn)確模擬了訓(xùn)練數(shù)據(jù)的分布,但并不一定意味著它們將對(duì)所需的基礎(chǔ)數(shù)據(jù)分布進(jìn)行建模。特別當(dāng)訓(xùn)練數(shù)據(jù)分布偏斜(比如有很多重復(fù)樣本)時(shí),更大的模型更可能會(huì)學(xué)習(xí)到意外的數(shù)據(jù)集特性。因此,仔細(xì)分析用于訓(xùn)練更大模型的數(shù)據(jù)集變得更加重要,因?yàn)楦竽P涂赡鼙刃∧P陀涀「嗉?xì)節(jié)。
對(duì)于研究隱私的從業(yè)者來說,本文的研究表明,當(dāng)前大型語言模型可能會(huì)記住其訓(xùn)練數(shù)據(jù)的很大一部分,記憶與模型大小呈對(duì)數(shù)線性關(guān)系。同時(shí),這種記憶常常不容易被發(fā)現(xiàn),并且對(duì)于實(shí)際提取這些數(shù)據(jù)的攻擊,必須開發(fā)定性的新攻擊策略。幸運(yùn)的是,僅出現(xiàn)一次的訓(xùn)練數(shù)據(jù)似乎很少被記住,因此去重可能是緩解模型記憶危害的一項(xiàng)實(shí)用技術(shù)。
本文參考資料
Quantifying Memorization Across Neural Language Models: https://arxiv.org/abs/2202.07646
往期精彩回顧
適合初學(xué)者入門人工智能的路線及資料下載 (圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載 機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印 《統(tǒng)計(jì)學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯 機(jī)器學(xué)習(xí)交流qq群955171419,加入微信群請(qǐng)掃碼