
模型部署翻車記:PyTorch轉(zhuǎn)onnx踩坑實錄
在深度學(xué)習(xí)模型部署時,從pytorch轉(zhuǎn)換onnx的過程中,踩了一些坑。本文總結(jié)了這些踩坑記錄,希望可以幫助其他人。
首先,簡單說明一下pytorch轉(zhuǎn)onnx的意義。在pytorch訓(xùn)練出一個深度學(xué)習(xí)模型后,需要在TensorRT或者openvino部署,這時需要先把Pytorch模型轉(zhuǎn)換到onnx模型之后再做其它轉(zhuǎn)換。因此,在使用pytorch訓(xùn)練深度學(xué)習(xí)模型完成后,在TensorRT或者openvino或者opencv和onnxruntime部署時,pytorch模型轉(zhuǎn)onnx這一步是必不可少的。接下來通過幾個實例程序,介紹pytorch轉(zhuǎn)換onnx的過程中遇到的坑。
1. opencv里的深度學(xué)習(xí)模塊不支持3維池化層
起初,我在微信公眾號里看到一篇文章《使用Python和YOLO檢測車牌》。文中展示的檢測結(jié)果如下,其實這種檢測結(jié)果并不是一個優(yōu)良的結(jié)果,可以看到檢測框里的車牌是傾斜的,如果要識別車牌里的文字,那么傾斜的車牌會嚴(yán)重影響車牌識別結(jié)果的。

對于車牌識別這種場景,在做車牌檢測時,一種優(yōu)良的檢測結(jié)果應(yīng)該是這樣的,如下圖所示。

在輸出車牌檢測框的同時輸出檢測到的車牌的4個角點。有了這4個角點之后,對車牌做透視變換,這時的車牌就是水平放置的,最后做車牌識別,這樣就做成了一個車牌識別系統(tǒng),在這個系統(tǒng)里包含車牌檢測,車牌矯正,車牌識別三個模塊。車牌檢測模塊使用retinaface,原始的retinaface是做人臉檢測的,它能輸出人臉檢測矩形框和人臉5個關(guān)鍵點。考慮到車牌只有4個點,于是修改retinaface的網(wǎng)絡(luò)結(jié)構(gòu)使其輸出4個關(guān)鍵點,然后在車牌數(shù)據(jù)集訓(xùn)練,訓(xùn)練完成后,以一幅圖片上做目標(biāo)檢測的結(jié)果如上圖所示。車牌矯正模塊使用了傳統(tǒng)圖像處理方法,關(guān)鍵函數(shù)是opencv里的getPerspectiveTransform和warpPerspective。車牌識別模塊使用Intel公司提出的LPRNet。
整套程序是基于pytorch框架運行的,我把這套程序發(fā)布在github上,地址是 https://github.com/hpc203/license-plate-detect-recoginition-pytorch
接下來我就嘗試把pytorch模型轉(zhuǎn)換到onnx文件,然后使用opencv做車牌檢測與識別。然而在轉(zhuǎn)換完成onnx文件后,使用opencv讀取onnx文件遇到了一些坑,我在網(wǎng)上搜索,也沒有找到解決辦法。
轉(zhuǎn)換過程分兩步,首先是轉(zhuǎn)換車牌檢測retinaface到onnx文件,這一步倒是很順利,轉(zhuǎn)換沒有出錯,并且使用opencv讀取onnx文件做前向推理的輸出結(jié)果也是正確的。第二步轉(zhuǎn)換車牌識別LPRNet到onnx文件,由于Pytorch自帶torch.onnx.export轉(zhuǎn)換得到的ONNX,因此轉(zhuǎn)換的代碼很簡單,在生成onnx文件后,opencv讀取onnx文件出現(xiàn)了模型其妙的錯誤。程序運行的結(jié)果截圖如下
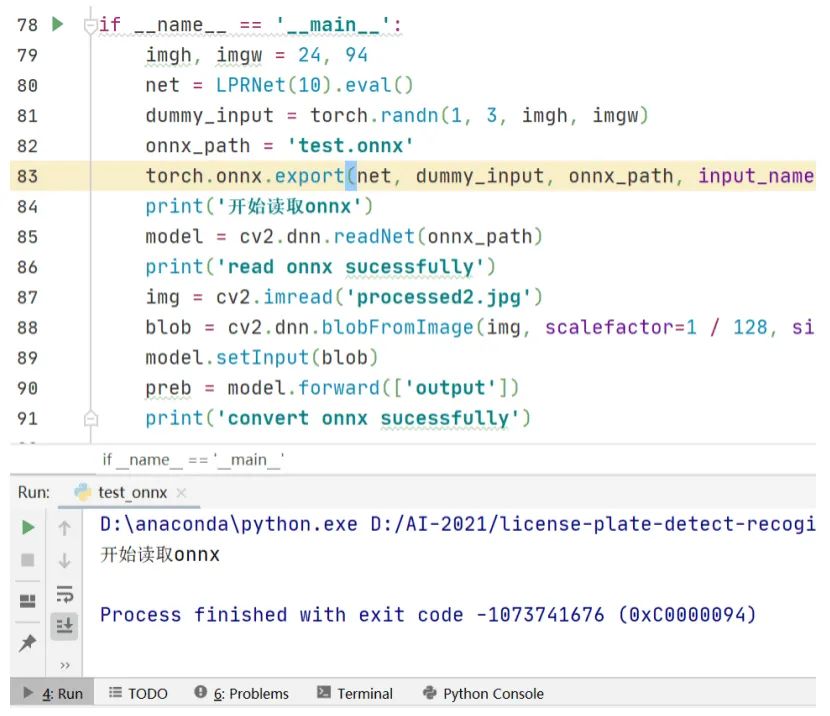
從打印結(jié)果看,torch.onnx.export生成onnx文件時沒有問題的,但是在cv2.dnn.readNet這一步出現(xiàn)異常導(dǎo)致程序中斷,并且打印出的異常信息是一連串的數(shù)字,去百度搜索也么找到解決辦法。觀察LPRNet的網(wǎng)絡(luò)結(jié)構(gòu),發(fā)現(xiàn)在LPRNet里定義了3維池化層,代碼截圖如下

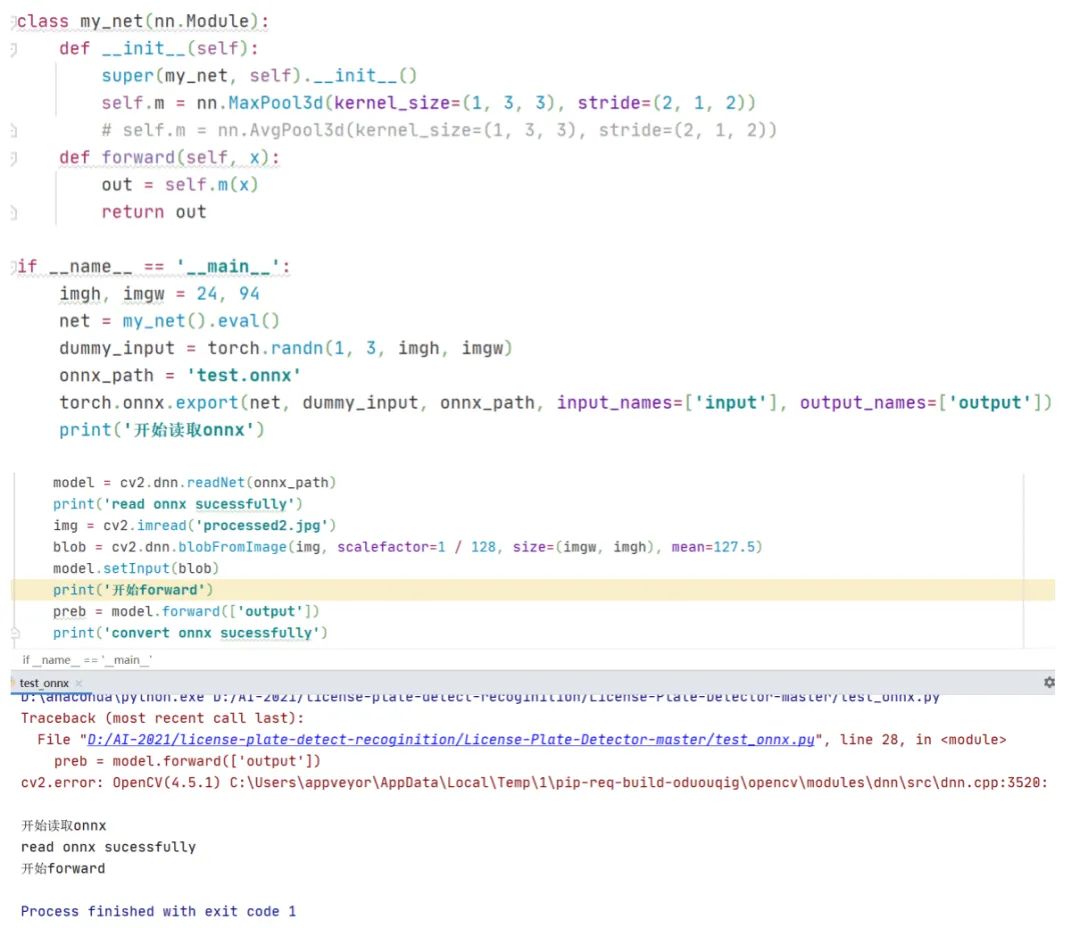
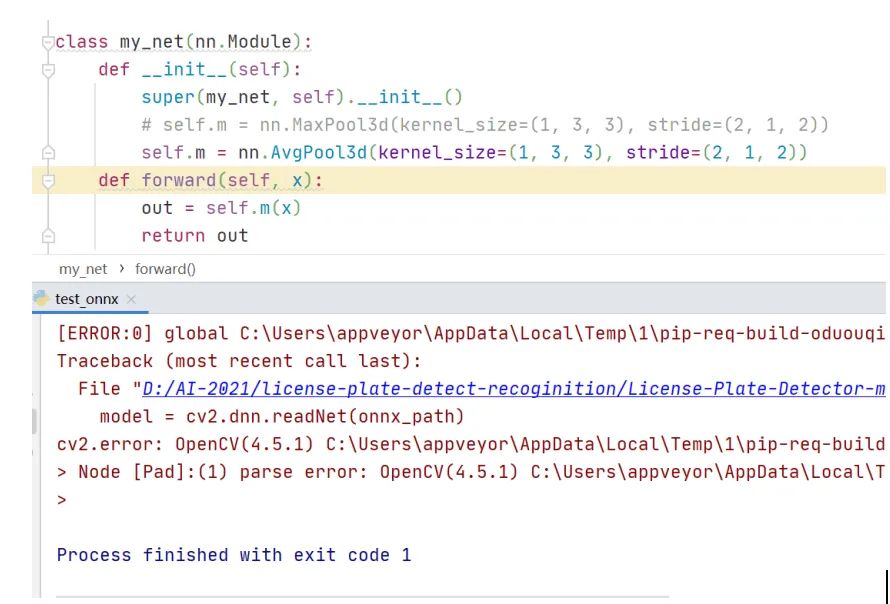
可以看到依然出錯,這說明opencv的深度學(xué)習(xí)模塊里不支持3維池化。不過,對比3維池化和2維池化的前向計算原理可以發(fā)現(xiàn),3維池化其實等價于2個2維池化。程序?qū)嵗缦?/p>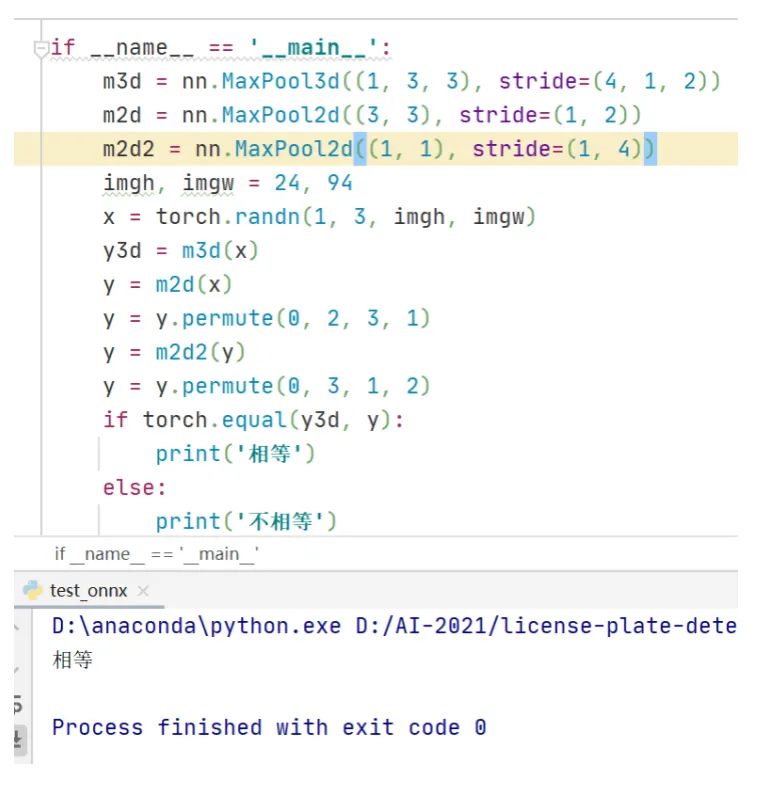
程序最后最后運行結(jié)果打印信息是相等。從這里就可以看出opencv里的深度學(xué)習(xí)模塊并不支持3維池化的前向計算,這期待后續(xù)新版本的opencv里能添加3維池化的計算。這時在LPRNet網(wǎng)絡(luò)結(jié)構(gòu)定義文件里修改3維池化層,重新生成onnx文件,opencv讀取onnx文件執(zhí)行前向計算后依然出錯,運行結(jié)果如下。
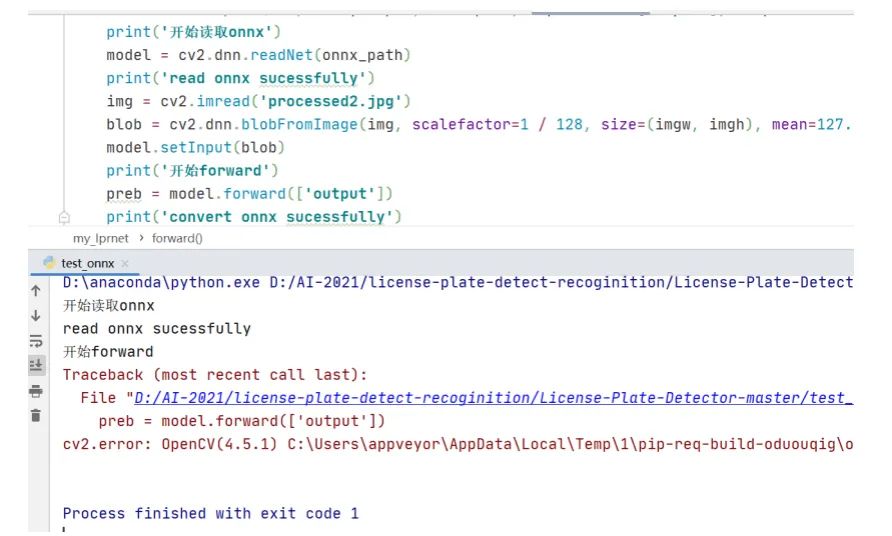
于是繼續(xù)觀察LPRNet的網(wǎng)絡(luò)結(jié)構(gòu),在forward函數(shù)里看到有求平均值的操作,代碼截圖如下所示
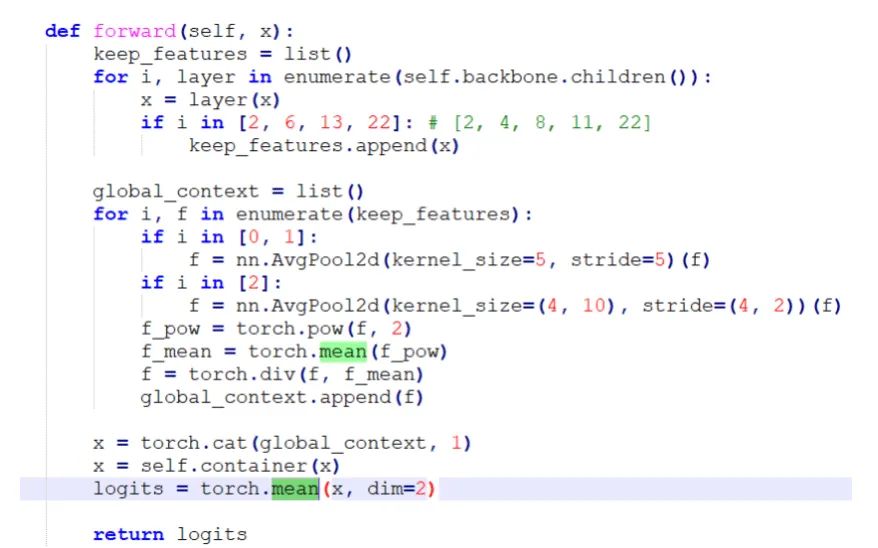
注意到第一個torch.mean函數(shù)里沒有聲明在哪個維度求平均值,這說明它是對一個4維四維張量的整體求平均值,這時候從一個4維空間搜索成一個點,也就是一個標(biāo)量數(shù)值。但是在pytorch里,對一個張量求平均值后依然是一個張量,只不過它的維度shape是空的,示例代碼如下。這時如果想要訪問平均值,需要加上.item(),這個是需要注意的一個pytorch知識點。
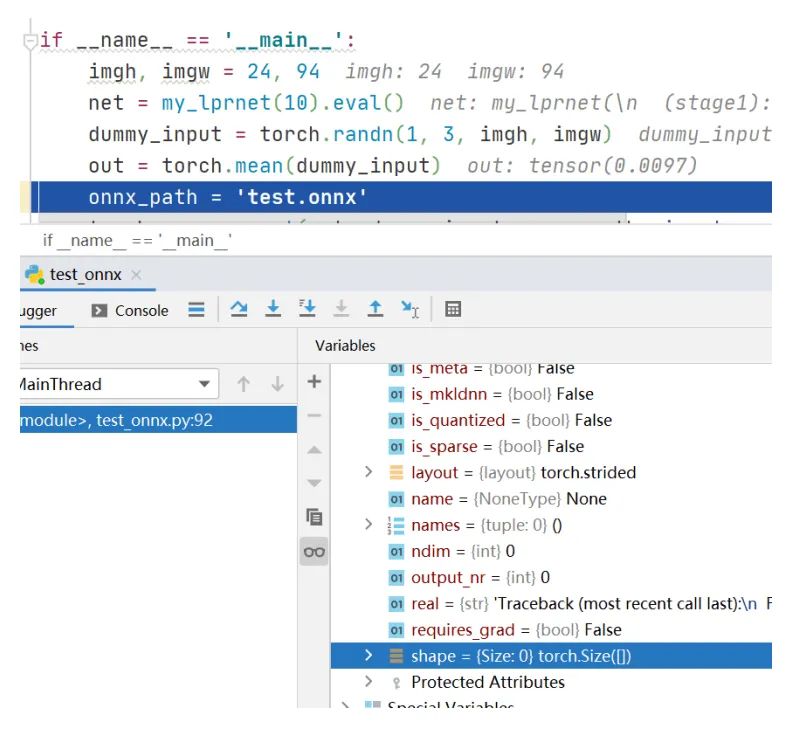
在修改這個代碼bug后重新生成onnx文件,使用opencv讀取onnx文件做前向計算就不再出現(xiàn)異常錯誤了。
通過以上幾個程序?qū)嶒灒梢钥偨Y(jié)出opencv讀取onnx文件做深度學(xué)習(xí)前向計算的2個坑:
(1) .opencv里的深度學(xué)習(xí)模塊不支持3維池化計算,解決辦法是修改原始網(wǎng)絡(luò)結(jié)構(gòu),把3維池化轉(zhuǎn)換成兩個2維池化,重新生成onnx文件
(2) .當(dāng)神經(jīng)網(wǎng)絡(luò)里有torch.mean和torch.sum這種把4維張量收縮到一個數(shù)值的運算時,opencv執(zhí)行forward會出錯,這時的解決辦法是修改原始網(wǎng)絡(luò)結(jié)構(gòu),在torch.mean的后面加上.item()
在解決這些坑之后,編寫了一套使用opencv做車牌檢測與識別的程序,包含C++和python兩個版本的代碼。使用opencv的dnn模塊做前向計算,后處理模塊是自己使用C++和Python獨立編寫的。
代碼已發(fā)布在github上,地址是:https://github.com/hpc203/license-plate-detect-recoginition-opencv
2. opencv與onnxruntime的差異
起初在github上看到一個使用DBNet檢測條形碼的程序,不過它是基于pytorch框架做的。于是我編寫一套程序把pytorch模型轉(zhuǎn)換到onnx文件,使用opencv讀取onnx文件做前向計算。編寫完程序后在運行時沒有出錯,但是最后輸出的結(jié)果跟調(diào)用pytorch 的輸出結(jié)果不一致,并且從可視化結(jié)果看,沒有檢測出圖片中的條形碼。這時在看到網(wǎng)上有很多使用onnxruntime部署onnx模型的文章,于是決定使用onnxruntime部署,編寫完程序后運行,選取幾張快遞單圖片測試,結(jié)果如下圖所示DBNet檢測到的4個點,圖中綠色的點,紅色的線是把4個連接起來的直線。


并且我還編寫了一個函數(shù)比較opencv和onnxruntime的輸出結(jié)果,程序代碼和運行結(jié)果如下,可以看到在相同輸入,讀取同一個onnx文件的前提下,opencv和onnxruntime的輸出結(jié)果竟然不相同。

ONNXRuntime是微軟推出的一款推理框架,用戶可以非常便利的用其運行一個onnx模型。從這個實驗,可以看出相比于opencv庫,onnxruntime庫對onnx模型支持的更好。
我把這套使用DBNet檢測條形碼的程序發(fā)布在github上,地址是:https://github.com/hpc203/dbnet-barcode
3. onnxruntime支持3維池化和3維卷積
在第1節(jié)講到opencv不支持3維池化,那么onnxruntime是否支持呢?接著編寫了一個程序探索onnxruntime對3維池化的支持情況,代碼和運行結(jié)果如下,可以看到程序報錯了。
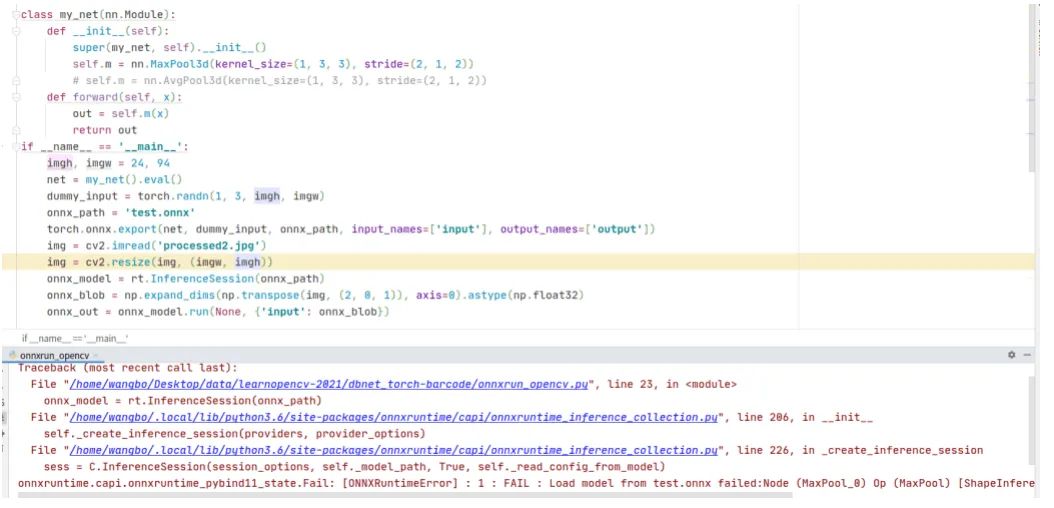
查看nn.MaxPool3d的說明文檔,截圖如下,可以看到它的輸入和輸出是5維張量,于是修改上面的代碼,把輸入調(diào)整到5維張量。

代碼和運行結(jié)果如下,可以看到這時候onnxruntime庫能正常讀取onnx文件,并且它的輸出結(jié)果跟pytorch的輸出結(jié)果相等。
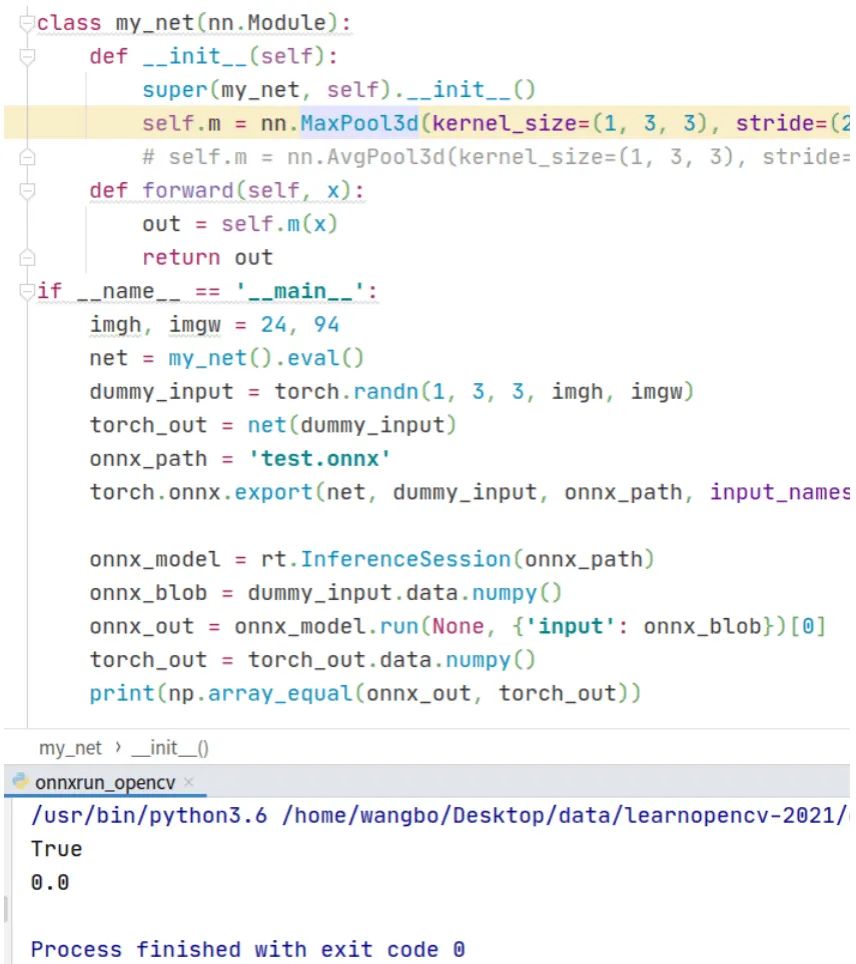
繼續(xù)實驗,把三維池化改作三維卷積,代碼和運行結(jié)果如下,可以看到平均差異在小數(shù)點后11位,可以忽略不計。
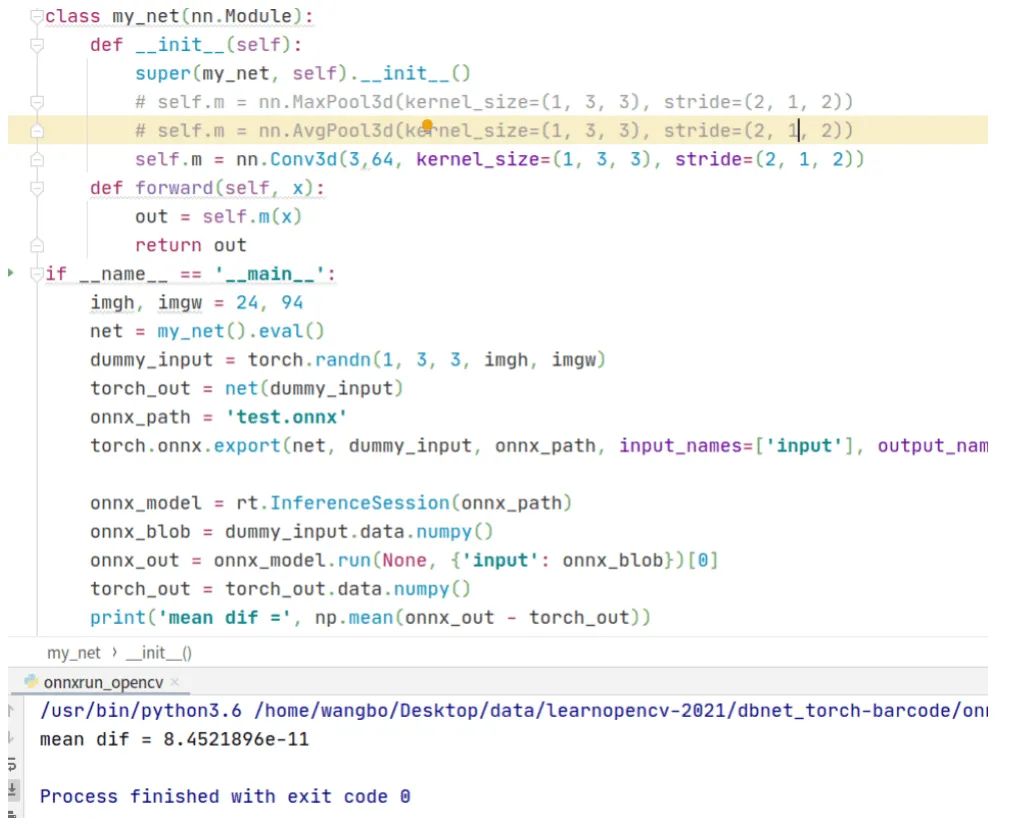
在第1節(jié)講到過opencv不支持3維池化,那時候的輸入張量是4維的,如果把輸入張量改成5維的,那么opencv是否就能進行3維池化計算呢?為此,編寫代碼,驗證這個想法。代碼和運行結(jié)果如下,可以看到在cv2.dnn.blobFromImage這行代碼出錯了。
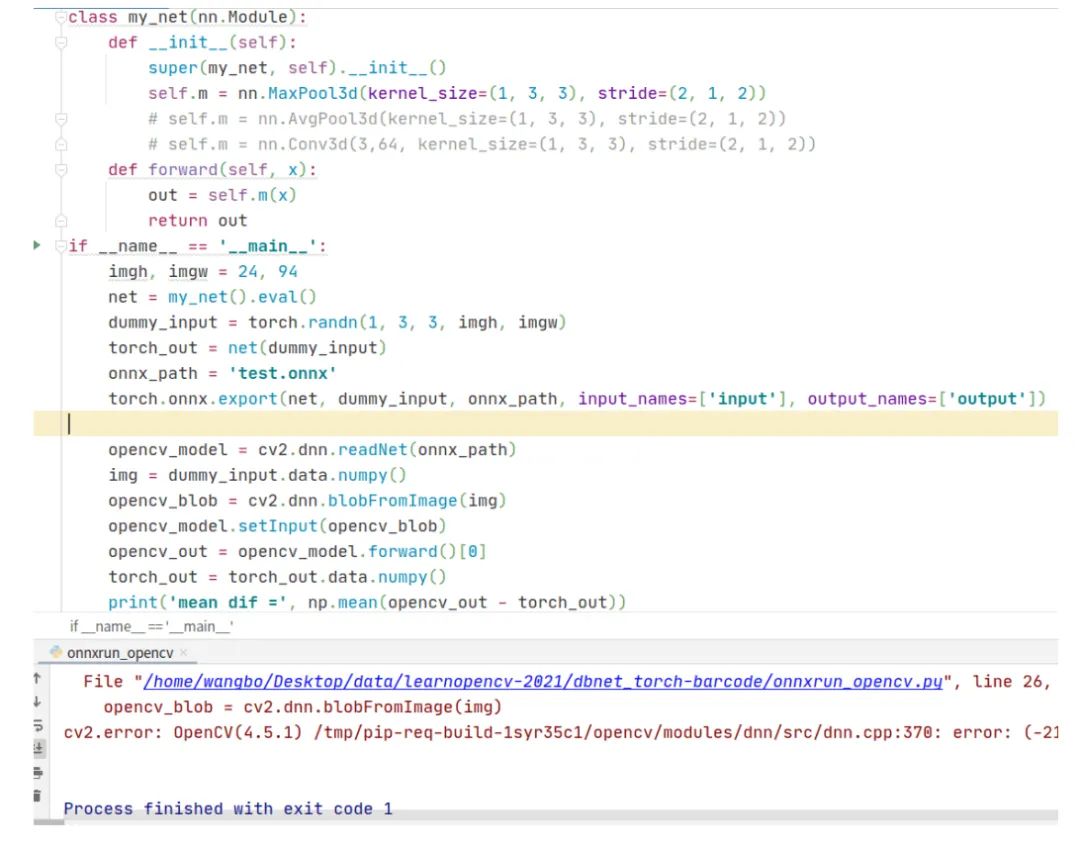
查看cv2.dnn.blobFromImage這個函數(shù)的說明文檔,截圖如下,可以看到它的輸入image是4維的,這說明它不支持5維的輸入。
經(jīng)過這一系列的程序?qū)嶒炚撟C,可以看出onnxruntime庫對onnx模型支持的更好。如果深度學(xué)習(xí)模型有3維池化或3維卷積層,那么在轉(zhuǎn)換到onnx文件后,使用onnxruntime部署深度學(xué)習(xí)是一個不錯的選擇。
4. onnx動態(tài)分辨率輸入
不過我在做pytorch導(dǎo)出onnx文件時,還發(fā)現(xiàn)了一個問題。在torch.export函數(shù)里有一個輸入?yún)?shù)dynamic_axes,它表示動態(tài)的軸,即可變的維度。假如一個神經(jīng)網(wǎng)絡(luò)輸入是動態(tài)分辨率的,那么需要定義dynamic_axes = {'input': {2: 'height', 3: 'width'}, 'output': {2: 'height', 3: 'width'}},接下來我編寫一個程序來驗證,代碼和運行結(jié)果的截圖如下
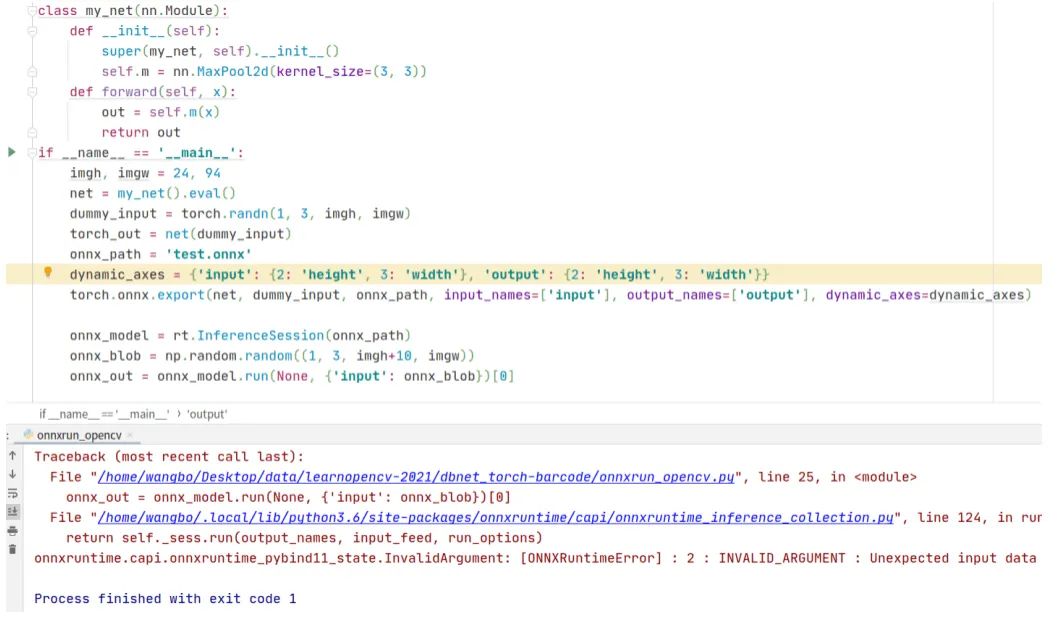
可以看到,在生成onnx文件后,使用onnxruntime庫讀取,對輸入blob的高增加10個像素單位,在run這一步出錯了。使用opencv讀取onnx文件,代碼和運行結(jié)果的截圖如下,可以看到依然出錯了。
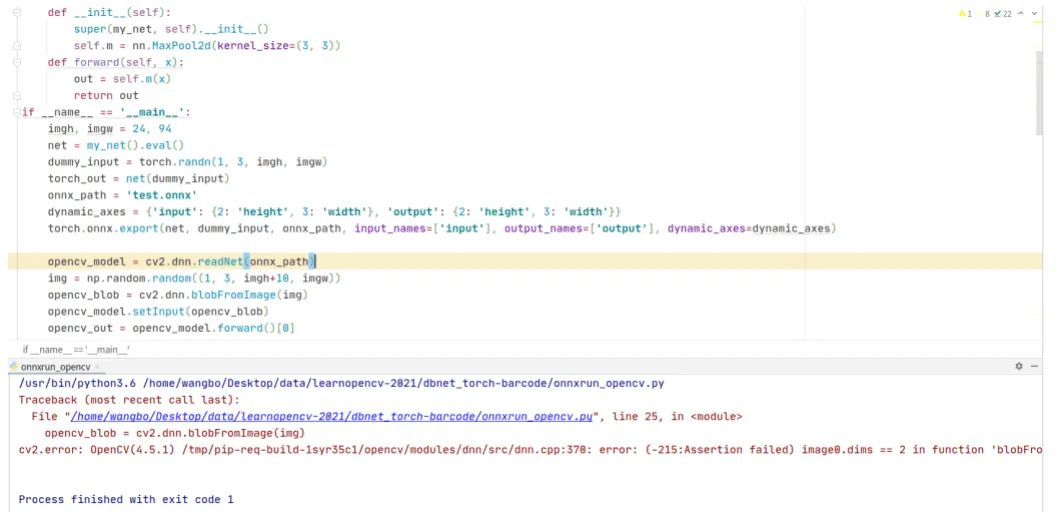
通過這個程序?qū)嶒灒屓藨岩蓆orch.export函數(shù)的輸入?yún)?shù)dynamic_axes是否真的支持動態(tài)分辨率輸入的。
以上這些程序?qū)嶒炇俏以诰帉懰惴☉?yīng)用程序時記錄下的一些bug和解決方案的,希望能幫助到深度學(xué)習(xí)算法開發(fā)應(yīng)用人員少走彎路。
此外,DBNet的官方代碼里提供了轉(zhuǎn)換到onnx模型文件,于是我依然編寫了一套使用opencv部署DBNet文字檢測的程序,依然是包含C++和Python兩個版本的代碼。官方代碼的模型是在ICDAR場景文本檢測數(shù)據(jù)集上訓(xùn)練的,考慮到車牌里也含有文字,我把文章開頭展示的汽車圖片作為輸入,程序檢測結(jié)果如下,可以看到依然能檢測到車牌的4個角點,只是不夠準(zhǔn)確。如果想要獲得準(zhǔn)確的角點定位,可以在車牌數(shù)據(jù)集上訓(xùn)練DBNet。
我把使用opencv部署DBNet文字檢測的程序發(fā)布在github上,程序依然是包含c++和python兩種版本的實現(xiàn),地址是:https://github.com/hpc203/dbnet-opencv-cpp-python