
基于Seq2Seq模型自動生成春聯(lián)

向AI轉(zhuǎn)型的程序員都關(guān)注了這個號??????
機器學(xué)習(xí)AI算法工程?? 公眾號:datayx
一、【數(shù)據(jù)集構(gòu)造】
詩詞歌句屬于自然語言一部分,對于計算機來說自然需要對數(shù)據(jù)進行數(shù)字化處理。其中步驟主要分成分詞、編碼、數(shù)據(jù)集輸入輸出構(gòu)造。
1、分詞方面
傳統(tǒng)自然語言處理在分詞方面使用“詞”為劃分粒度,以此來增加字間的關(guān)系,常見的編碼包,比如jieba分詞等。在數(shù)據(jù)集構(gòu)造的時候,本文想到詩詞與現(xiàn)代語言相比,更加凝練 ,一字可以有多義,比如“備”字,可以有“準(zhǔn)備”、“具備”、”周全“這些意思,因此在詩詞文本上采用了”字“為粒度的方式進行劃分。而且這種方式,在代碼上也好實現(xiàn)一些。
2、編碼方面
分布式編碼起源于Harris的分布假說,它認(rèn)為某個單詞的含義可以由上下文進行聯(lián)合表示,認(rèn)為相似的詞會出現(xiàn)于相同語境(上下文)。本文出于詩詞中存在一定的語義關(guān)系,前后聯(lián)系的考慮,為了保留字間關(guān)聯(lián),本文使用了分布式編碼的方式,使用Word2Vec的方式構(gòu)建字向量,對漢字進行數(shù)字化。
3、數(shù)據(jù)輸入輸出安排
輸入輸出數(shù)據(jù)集分成四個部分,與后面模型結(jié)構(gòu)相關(guān):Encoder_inputs、Encoder_outputs、Decoder_inputs和Decoder_outputs,我們先來了解數(shù)據(jù),后面模型部分會進行詳細介紹劃分原因。
第一、二部分Encoder部分
是為了訓(xùn)練一個上聯(lián)生成模型Encoder,需要構(gòu)造數(shù)據(jù)的輸入encoder_inputs和encoder_outputs。為了增強句間的字的語序特征,本文提出使用”1:N”的方式,根據(jù)時序?qū)υ娋溥M行拆分,構(gòu)造長度相同的數(shù)據(jù)集詩句。具體表現(xiàn)為下圖1。
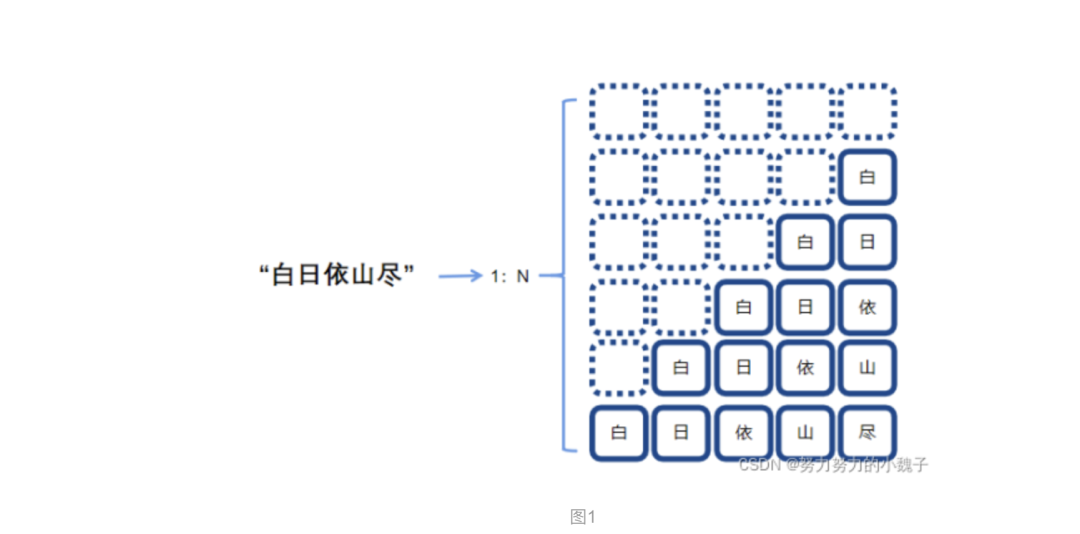
?按照時序不同時刻輸入的內(nèi)容不同,字間相互錯落一個時間間隔,一行將作為一個輸入,對應(yīng)下一個字為其輸出,這樣就仿真人們作詩的過程,一字一字生成詩句。使用“X”來表示空格,最后一個完整句對應(yīng)輸出為“END”表示結(jié)束。這樣,一個N字詩句就將生成(n+1)*n的句子,大大增加了數(shù)據(jù)集大小,同時也強調(diào)了字在句子中的時序特征。比如輸入為:“XXXX白”,輸出對應(yīng)“日”;下一個輸入就是“XXX白日”,對應(yīng)輸出為“依”;如此構(gòu)造出多個輸入輸出。
第三、四部分?jǐn)?shù)據(jù)輸出Decoder
是為了訓(xùn)練一個能根據(jù)上聯(lián)encoder部分,而對應(yīng)產(chǎn)生下聯(lián)的模型。下聯(lián)模型需要輸入和上聯(lián)模型思想不同,這時候我們輸入是下聯(lián)對應(yīng)每一個字的前一個單字和上聯(lián)的輸出,將二者聯(lián)合起來構(gòu)建一個輸入向量;而對應(yīng)輸出應(yīng)該是真正對應(yīng)位置的單字;所以輸入部分也需要錯落一個時間間隔。這樣說比較抽象,我們舉例來說明,如下圖2所示。
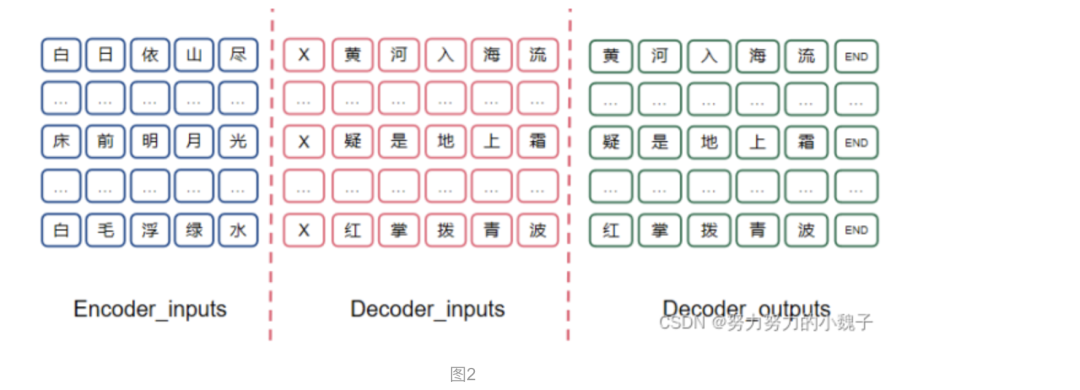
?可以看到,上聯(lián)encoder在Decoder模型的輸入為“白日依山盡”,同時在Decoder模型中輸入包括錯落一個時間(或者說字)的單字,如“X”,對應(yīng)輸出應(yīng)該是“黃”。其中“X”在這里表示句子的開始,“END”表示結(jié)束。
? ? ? ?這樣做的目的是為了仿照人們吟詩作對的思考過程,需要考慮上聯(lián)的關(guān)系,同時也要考慮前一個字對后一個字生成的影響,其中可能包括平仄關(guān)系(這里沒有強調(diào),只是個猜想)。
二、【模型搭建】
? ? ? ? ?在構(gòu)建模型的時候,本文主要思量到的是數(shù)據(jù)的關(guān)系。首先需求上,我們研究的是自然語言,具有時序特點;其次,我們的自然語言處理方面需要聯(lián)系到前后的關(guān)系;最后,要考慮人們吟詩作對的過程的模仿。
? ? ? ? 根據(jù)這些思想,本文參考了大量自然語言處理方面的應(yīng)用資料,比如:模型翻譯、英文小說自動生成等方面(本來應(yīng)該貼上鏈接的,現(xiàn)在一回頭找不到資料了,感謝各位大大……跪謝……),想到將翻譯模型移植至古詩文生成模型中,框架是Seq2Seq模型,主要模型被我分成兩個部分:連字成句模型 和 連句成對模型。模型的整體架構(gòu)如下圖3所示。
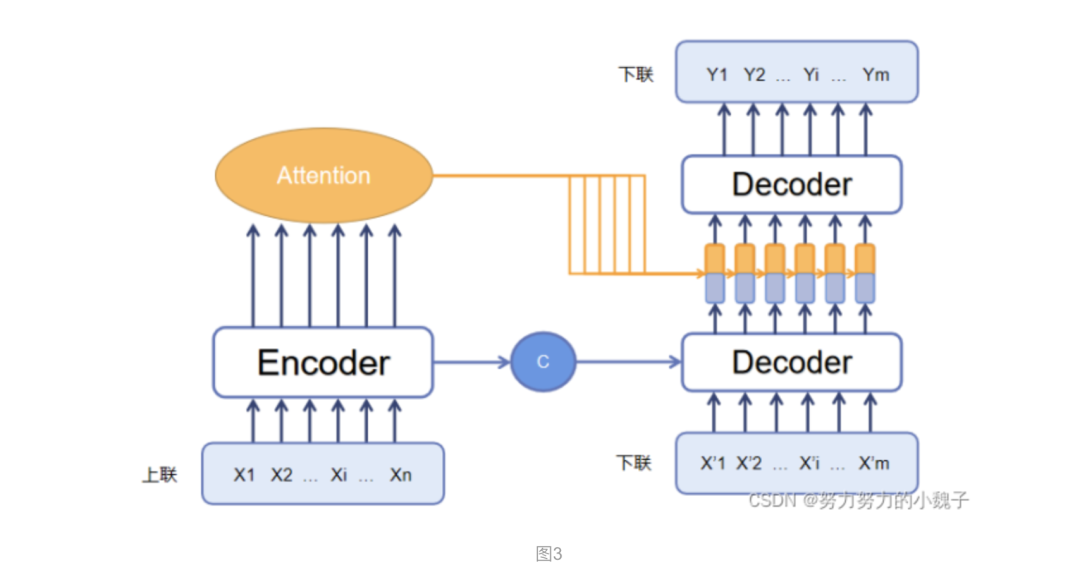
1、連字成句模型
? ? ? 這個部分屬于Seq2Seq中Encoder部分,主要用于“首聯(lián)”的生成。顧名思義,功能是用戶輸入一個單字,對應(yīng)模型能夠訓(xùn)練生成一整句最優(yōu)句子。
? ? ?詩詞屬于自然語言處理的一部分,具有前后的聯(lián)系關(guān)系,所以選用時序關(guān)系的模型最好,常見有RNN。由于RNN在處理長序列句子中存在“梯度爆炸”和“梯度消失”的問題,所以本文選用的是LSTM模型,屬于RNN的一種升級模式。同時,又由于一個LSTM只能保證一個單向語義聯(lián)系,所以為了保留前后的關(guān)系,本文選用了雙向的LSTM,也做BiLSTM。模型如下圖4所示。
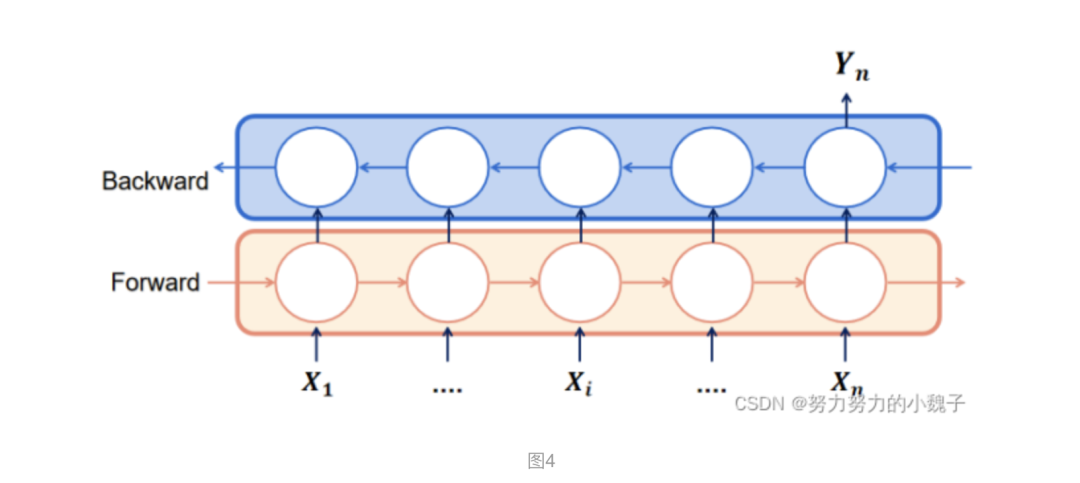
舉例說明,聯(lián)系上部分?jǐn)?shù)據(jù)構(gòu)造方面,輸入的X1、X2……Xn是1:N的時序拆解內(nèi)容,輸出的Yn為對應(yīng)時序下的單字輸出。比如,輸入”XXXX白“,對應(yīng)輸出Yn為”日”。
2、連句成對模型
? ? ? 連句成對模型功能是生成下聯(lián),屬于Seq2Seq中Decoder部分。與上聯(lián)模型不同的是,我們這時候輸出是一整個句子(也就是把LSTM模型中每個時序的輸出都輸出)。模型結(jié)構(gòu)如下圖5所示。
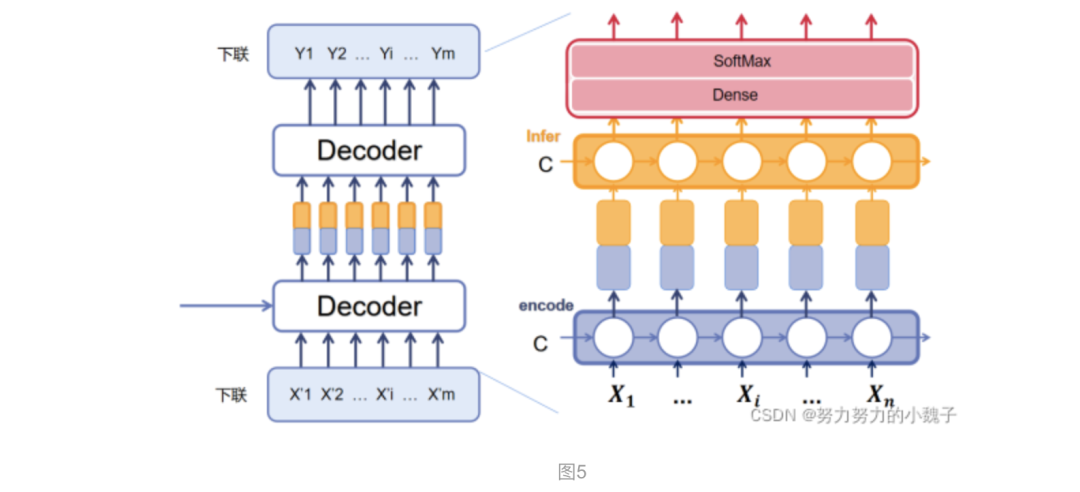
首先介紹的是圖中Decoder的下面部分,本文把它稱為是Decoder_encoder,也就是對下聯(lián)的輸入進行編碼的意思。
? ? ? ? 本文參考人們吟詩作對的方式,認(rèn)為下聯(lián)的每個字的選擇生成,和當(dāng)前字前面的句子以及上聯(lián)信息相關(guān)。所以Decoder_encoder部分我們選用了LSTM,生成前序向量;之后為了聯(lián)系上聯(lián),我們想到上聯(lián)中每個字實際應(yīng)該側(cè)重點各有不同,所以引入了Attention模型,將上聯(lián)生成的句子進行Attention權(quán)值重分配,使得上聯(lián)對下聯(lián)每個字的影響權(quán)值各不相同。
? ? ? ? 比如“白日依山盡”為了生成”黃“字,顯然”白“字的權(quán)值更應(yīng)該大一些。前序序列的編碼向量和Attention下的上聯(lián)向量,本文將其進行縱向連接,也就是圖上顯示那樣。兩種顏色的拼接,將作為Decoder第二部分的輸入。
? ? ? ?其次是attention計算結(jié)構(gòu),如圖6所示。
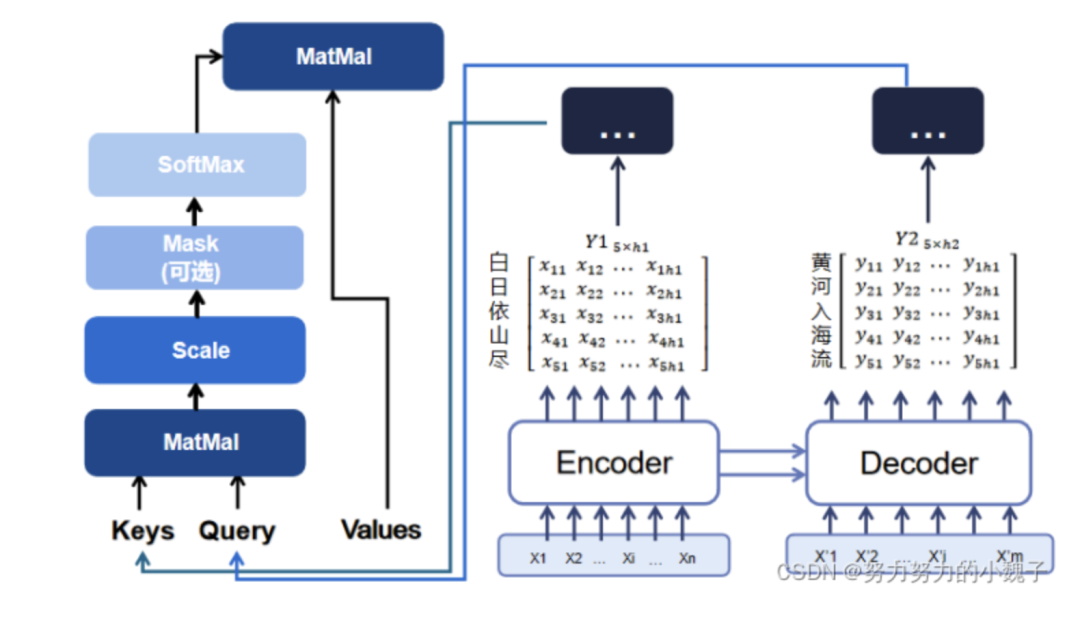
以“白日依山盡,黃河入海流”為例。
? ? ?本文設(shè)Encoder的輸出維度為h1,設(shè)Decoder編碼encode層的輸出維度為h2,Attention后的輸出維度為out。
? ? ?因此,Encoder對“白日依山盡”進行編碼獲得大小為[5,h1]的隱藏層輸出Y1,此時Y1。Decoder對“黃河入海流”進行編碼獲得大小為[5, h2]的隱藏層輸出Y2。
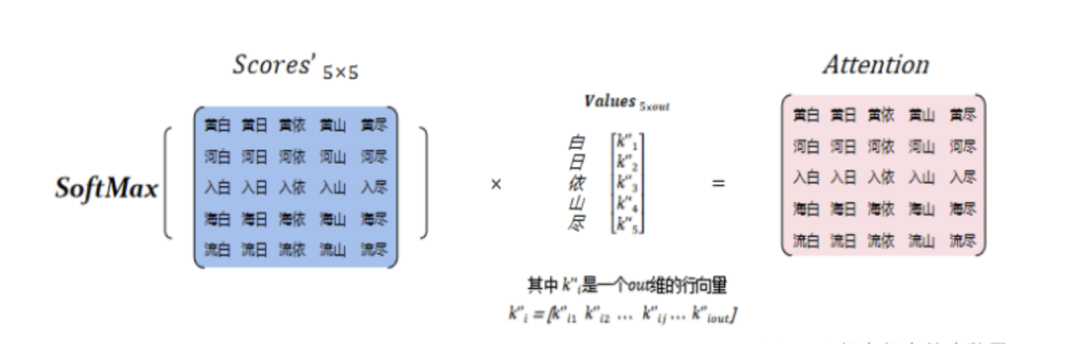
? ? ? 之后,我們需要隨機生成權(quán)重矩陣Wq、(大小為[h2, out])、Wk、Wv(大小為[h1, out]),將Wq和Y2相乘生成大小為[5,out]的Query值;同理,Wk和Wv與Y1相乘生成大小為[5, out]的Keys和Values值,如圖7所示。
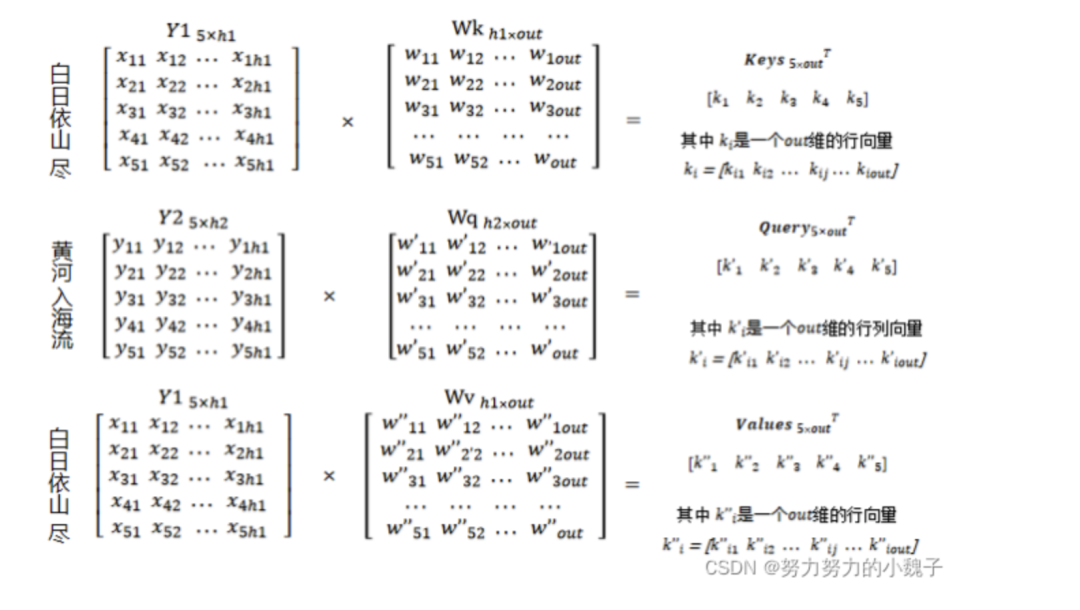
? ?然后,對Keys矩陣進行轉(zhuǎn)置變成[out, 5],通過點積方式計算出Query與Keys中各個key的得分Scores,矩陣得到大小為[5, 5],如圖8所示。
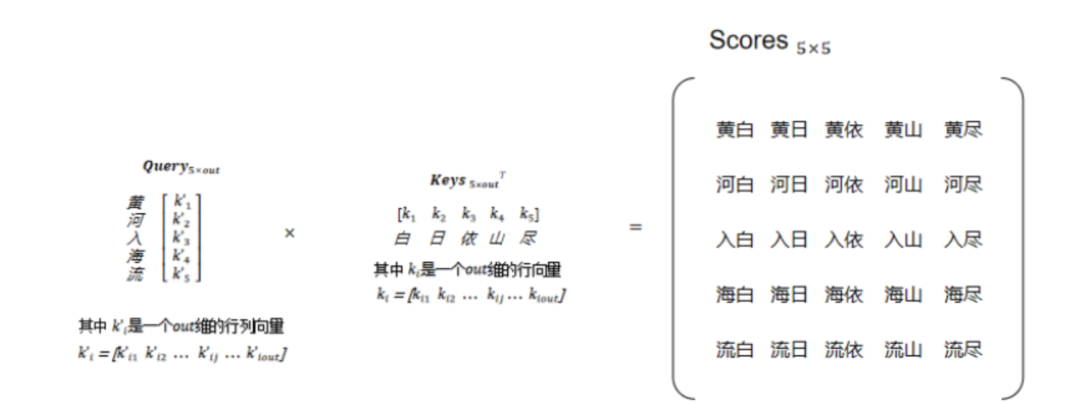
為了防止產(chǎn)生過大的方差,因此需要對得分矩陣Scores進行縮放,除以維度的平方得到Scores’,大小為[5, 5]。將縮放后的Scores通過SoftMax函數(shù)進行概率轉(zhuǎn)換,得到最終Query與Keys中每個Key的權(quán)重Probs。
? ? ? ? 最后,將Probs與Values進行點乘,獲得大小為[5, out]的Attention值,如圖9所示。
最后介紹的是圖中Decoder的第二部分,本文稱之為Decoder_infer,用于生成最后的句子。
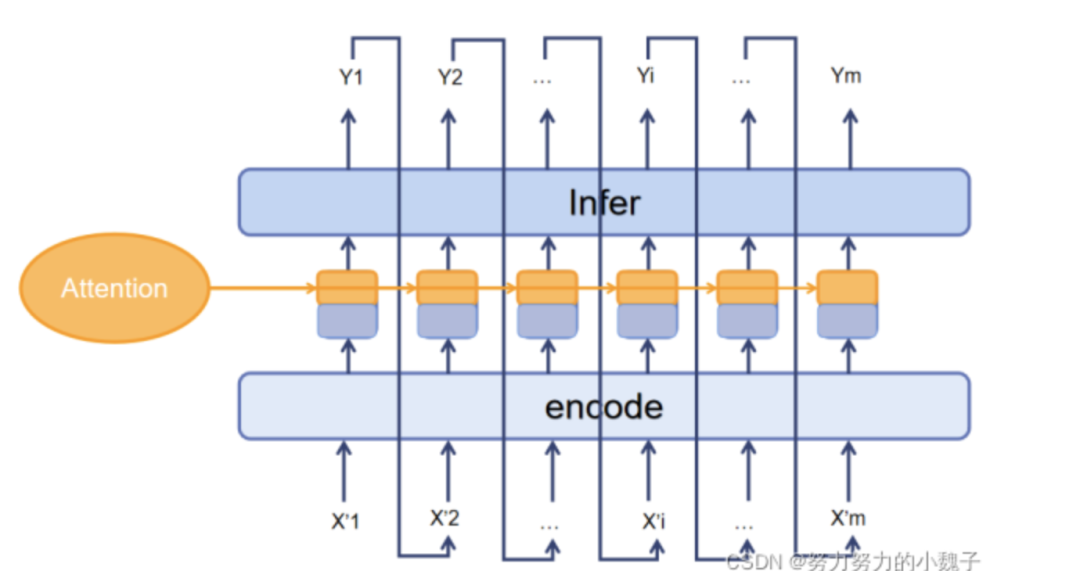
? ? ? ? Decoder_infer和一個SoftMax層相連,是為了讓模型在我們的漢字字典里選出最有可能的生成字結(jié)果。前面的監(jiān)督學(xué)習(xí)和Attention結(jié)果相結(jié)合已經(jīng)生成了對應(yīng)的組合輸入向量,這時候我們就可以使用LSTM,將模型的每個神經(jīng)元的輸出打開,結(jié)合SoftMax生成最佳生成字,從而生成完整下聯(lián)。值得注意的是,這一部分的模型在訓(xùn)練完成后,下聯(lián)需要以一個鏈?zhǔn)降姆绞竭M行使用。如下圖10所示。
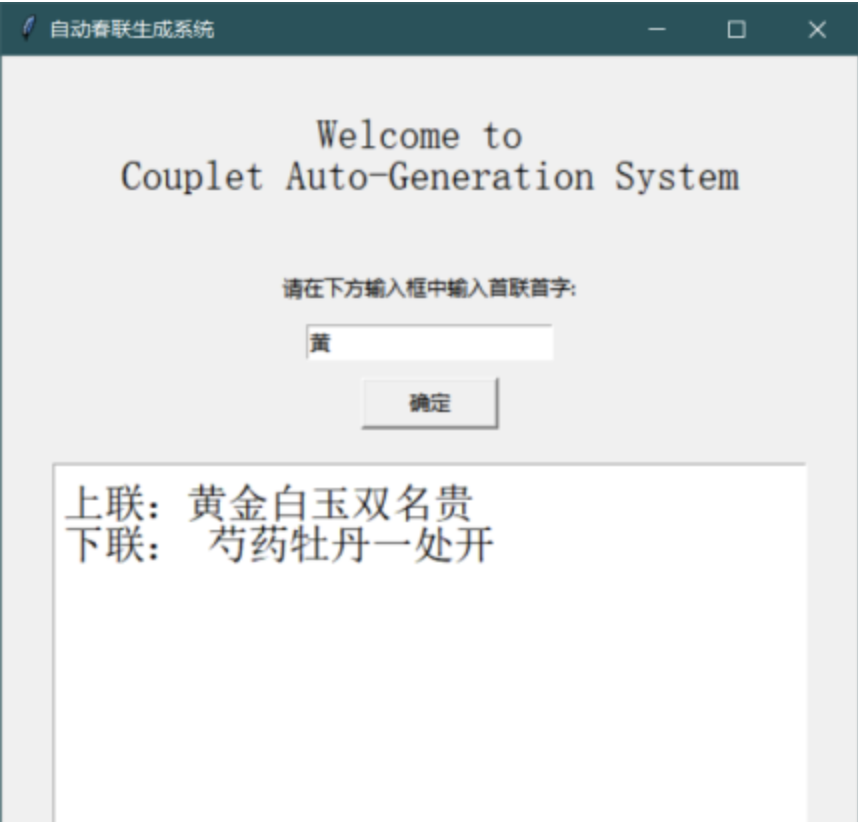
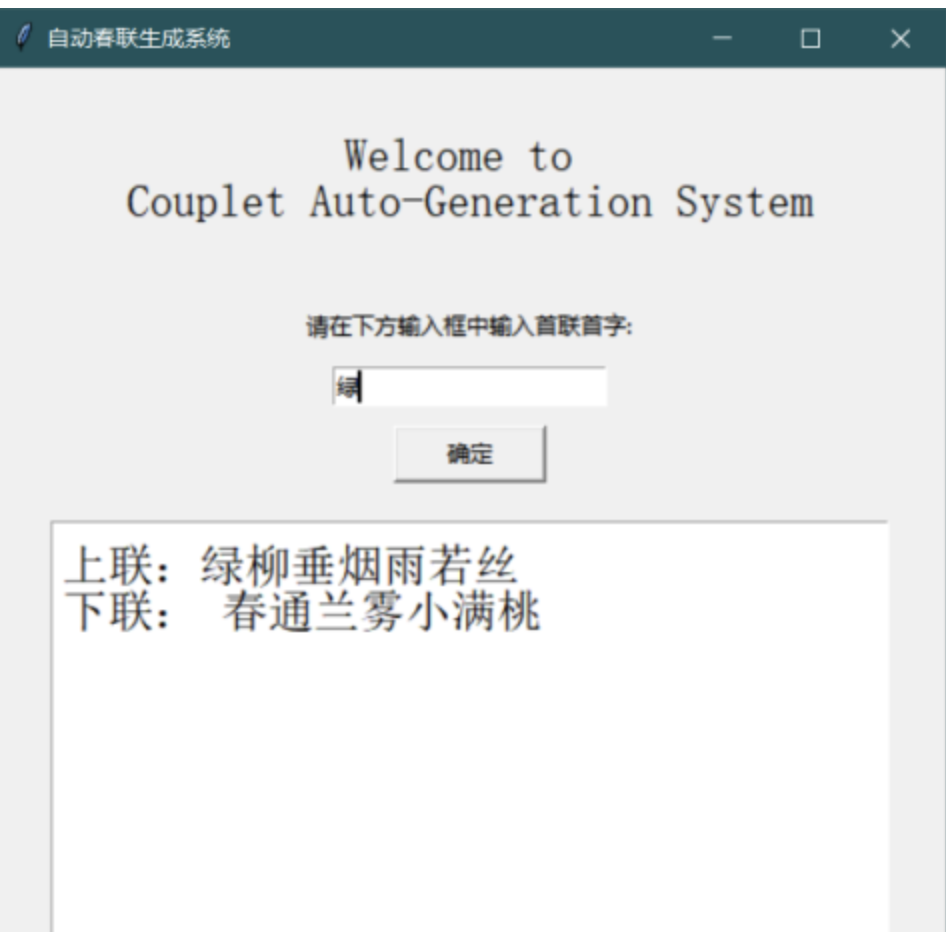
本文使用python keras框架下編程。實驗數(shù)據(jù)來源于一位名叫馮重樸_梨味齋散葉的博主的新浪博客,選用數(shù)據(jù)集中長度大小為7的對聯(lián)作為本實驗數(shù)據(jù)。下面將展示實驗?zāi)P秃蛯嶒灲Y(jié)果。
相關(guān)代碼,70萬條對聯(lián)數(shù)據(jù)集
獲取方式:
關(guān)注微信公眾號 datayx ?然后回復(fù)?對聯(lián)?即可獲取。
對聯(lián)體驗鏈接
https://ai.binwang.me/couplet/


機器學(xué)習(xí)算法AI大數(shù)據(jù)技術(shù)
?搜索公眾號添加:?datanlp
長按圖片,識別二維碼
閱讀過本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實戰(zhàn)
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測
《基于深度學(xué)習(xí)的自然語言處理》中/英PDF
【全套視頻課】最全的目標(biāo)檢測算法系列講解,通俗易懂!
《美團機器學(xué)習(xí)實踐》_美團算法團隊.pdf
《深度學(xué)習(xí)入門:基于Python的理論與實現(xiàn)》高清中文PDF+源碼
《深度學(xué)習(xí):基于Keras的Python實踐》PDF和代碼
python就業(yè)班學(xué)習(xí)視頻,從入門到實戰(zhàn)項目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個項目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實踐詳解》完整版PDF+附書代碼
《深度學(xué)習(xí)之pytorch》pdf+附書源碼
PyTorch深度學(xué)習(xí)快速實戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評分8.1,《機器學(xué)習(xí)實戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識圖譜項目實戰(zhàn)視頻(全23課)
李沐大神開源《動手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
FashionAI服裝屬性標(biāo)簽圖像識別Top1-5方案分享
重要開源!CNN-RNN-CTC 實現(xiàn)手寫漢字識別
同樣是機器學(xué)習(xí)算法工程師,你的面試為什么過不了?
前海征信大數(shù)據(jù)算法:風(fēng)險概率預(yù)測
【Keras】完整實現(xiàn)‘交通標(biāo)志’分類、‘票據(jù)’分類兩個項目,讓你掌握深度學(xué)習(xí)圖像分類
VGG16遷移學(xué)習(xí),實現(xiàn)醫(yī)學(xué)圖像識別分類工程項目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競賽華人第1名團隊-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機器學(xué)習(xí)、數(shù)據(jù)分析、python
?搜索公眾號添加:?datayx??