
基于深度學(xué)習(xí)的圖標(biāo)型驗(yàn)證碼識(shí)別系統(tǒng)

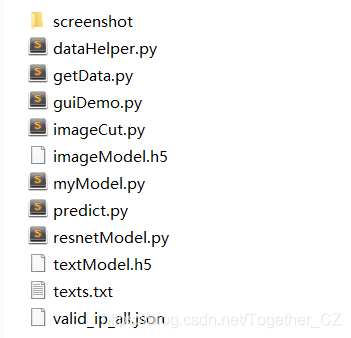
| 文件名稱 | 文件說明 |
|---|---|
| screenshot/ | 軟件截圖目錄 |
| getData.py | 圖像驗(yàn)證碼數(shù)據(jù)采集模塊 |
| imageCut.py | 圖像驗(yàn)證碼數(shù)據(jù)切分處理模塊 |
| dataHelper.py | 模型數(shù)據(jù)加載預(yù)處理模塊 |
| myModel.py | 模型訓(xùn)練模塊 |
| resnetModel.py | Resnet模塊 |
| predict.py | 離線模塊預(yù)測(cè)識(shí)別模塊 |
| guiDemo.py | 界面可視化模塊 |
| texts.txt | 文本標(biāo)簽集合 |
| valid_ip_all.json | IP代理池?cái)?shù)據(jù),避免爬蟲被封禁 |
| imageModel.h5 | 訓(xùn)練好的圖像識(shí)別模型文件 |
| textModel.h5 | 訓(xùn)練好的文本識(shí)別模塊文件 |
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能: 網(wǎng)絡(luò)驗(yàn)證碼數(shù)據(jù)采集模塊
'''
def buildProxy():
'''
構(gòu)建代理信息
'''
header_list=generateRandomUA(num=500)
header={'User-Agent':random.choice(header_list)}
ip_proxy=random.choice(ip_list)
one_type,one_ip,one_port=ip_proxy[0],ip_proxy[1],ip_proxy[2]
proxy={one_type:one_type+'://'+one_ip+':'+one_port}
return header,proxy
def getPageHtml(url,header,proxy,num_retries=3):
'''
多代理形式、超時(shí)重試機(jī)制,獲取數(shù)據(jù)
'''
try:
response=requests.get(url,headers=header,proxies=proxy,timeout=5)
return response
except Exception as e:
time.sleep(random.randint(3,8))
while num_retries:
num_retries-=1
print('Left tring number is: ', num_retries)
return getPageHtml(url,header,proxy,num_retries)
def getVCPics(img_url,start,end,saveDir):
'''
下載驗(yàn)證碼數(shù)據(jù)
'''
if not os.path.exists(saveDir):
os.makedirs(saveDir)
for i in range(start,end):
print("Downloading",i+1,"......")
header,proxy=buildProxy()
try:
img=getPageHtml(img_url,header,proxy,num_retries=3)
pic_name=saveDir+str(i+1)+'.jpg'
file_pic=open(pic_name,'ab')
file_pic.write(img.content)
file_pic.close()
time.sleep(random.randint(0.1,1))
except:
pass
if __name__ == '__main__':
print('captchaDataCollection!!!')
url="要爬取的驗(yàn)證碼鏈接"
#驗(yàn)證碼數(shù)據(jù)采集
getVCPics(url,0,500,'originalData/play/')



def singleCut(img_path,row,col,cutDir):
'''
單張驗(yàn)證碼圖像數(shù)據(jù)切割處理
'''
img=Image.open(img_path)
print('image_shape: ', img.size)
name=img_path.split('/')[-1].strip().split('.')[0].strip()
if not os.path.exists(cutDir):
os.makedirs(cutDir)
w,h=img.size
if row<=h and col<=w:
print('Original image info: %sx%s, %s, %s' % (w,h,img.format,img.mode))
rowheight=h//row
colwidth=w//col
for r in range(row):
for c in range(col):
box=(c*colwidth,r*rowheight,(c+1)*colwidth,(r+1)*rowheight)
if not os.path.exists(cutDir+name+'/'):
os.makedirs(cutDir+name+'/')
num=len(os.listdir(cutDir+name+'/'))
img.crop(box).save(cutDir+name+'/'+str(num)+'.png')
print('Total: ',num)
else:
print('Wrong Parameters!!!')

#截取文字
box=(120,3,177,22) #(左上角坐標(biāo),右下角坐標(biāo))
res=img.crop(box)
res.save('text.jpg')
res.show()
#截取主體圖像數(shù)據(jù)
box=(0,33,293,190) #(左上角坐標(biāo),右下角坐標(biāo))
res=img.crop(box)
res.save('image.jpg')
res.show()



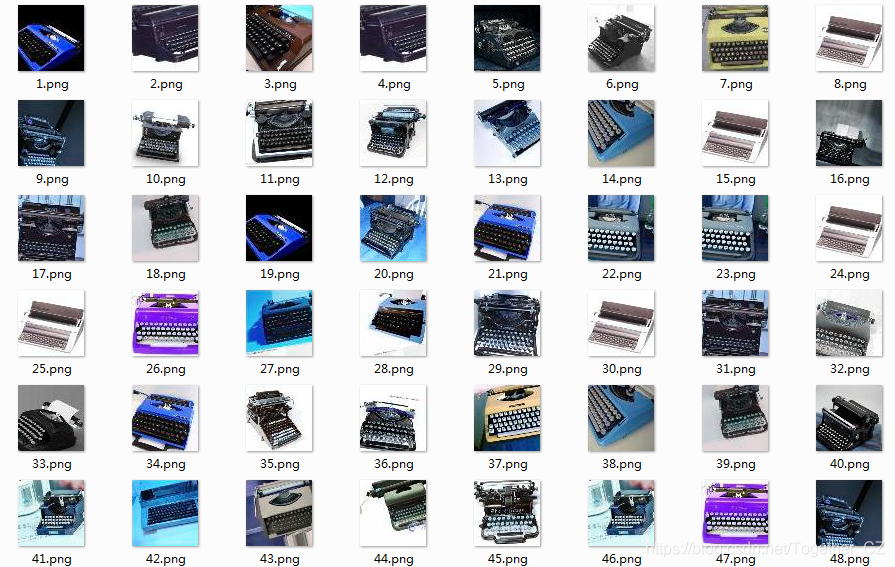
打字機(jī)
調(diào)色板
跑步機(jī)
毛線
老虎
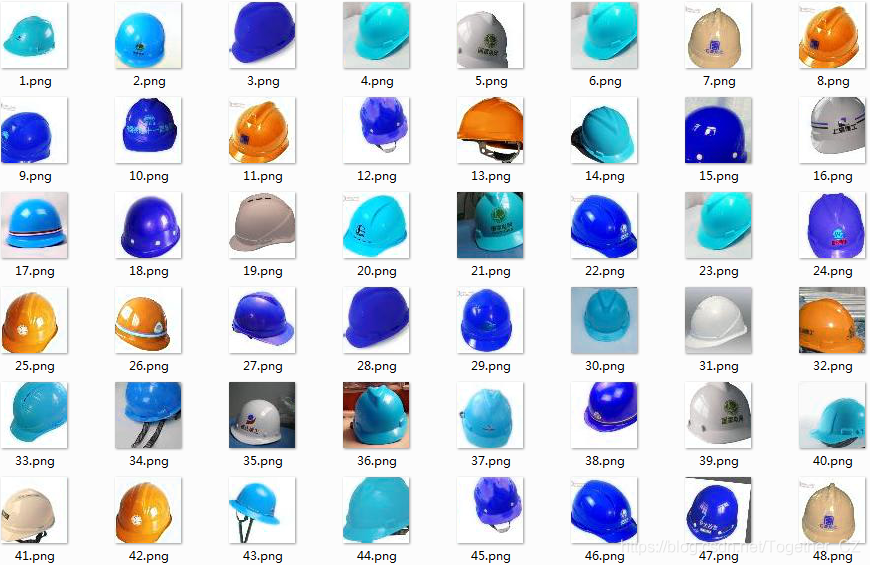
安全帽
沙包
盤子
本子
藥片
雙面膠
龍舟
紅酒
拖把
卷尺
海苔
紅豆
黑板
熱水袋
燭臺(tái)
鐘表
路燈
沙拉
海報(bào)
公交卡
櫻桃
創(chuàng)可貼
牌坊
蒼蠅拍
高壓鍋
電線
網(wǎng)球拍
海鷗
風(fēng)鈴
訂書機(jī)
冰箱
話梅
排風(fēng)機(jī)
鍋鏟
綠豆
航母
電子秤
紅棗
金字塔
鞭炮
菠蘿
開瓶器
電飯煲
儀表盤
棉棒
籃球
獅子
螞蟻
蠟燭
茶盅
印章
茶幾
啤酒
檔案袋
掛鐘
刺繡
鈴鐺
護(hù)腕
手掌印
錦旗
文具盒
辣椒醬
耳塞
中國(guó)結(jié)
蜥蜴
剪紙
漏斗
鑼
蒸籠
珊瑚
雨靴
薯?xiàng)l
蜜蜂
日歷
口哨
def resnetModel(num_classes,deep=18,h=16,w=10,way=1):
'''
resnet 模型
'''
if deep==18:
model=ResnetBuilder.build_resnet_18((way, h, w), num_classes)
elif deep==34:
model=ResnetBuilder.build_resnet_34((way, h, w), num_classes)
elif deep==50:
model=ResnetBuilder.build_resnet_50((way, h, w), num_classes)
model.compile(optimizer='sgd',loss='categorical_crossentropy',metrics=['accuracy'])
print(model.summary())
return model
def vggModel(num_classes,epochs,x_train,h=16,w=10,way=1):
'''
VGG-16模型
'''
print('x_train.shape: ',x_train.shape)
input_shape=(h,w,way)
model=Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=input_shape,padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform')) #512
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(1024,activation='relu')) #4096
model.add(Dropout(0.5))
model.add(Dense(1024,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
print(model.summary())
return model
def selfModel(num_classes,epochs,x_train,h=16,w=10,way=1):
'''
自定義基礎(chǔ)模型 sparse_categorical_crossentropy
'''
print('x_train.shape: ',x_train.shape)
input_shape=(h,w,way)
model = models.Sequential([
layers.Conv2D(64, (3, 3), padding='same', activation='relu', input_shape=input_shape),
layers.MaxPooling2D(), # 19 -> 9
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(), # 9 -> 4
layers.Conv2D(64, (3, 3), padding='same', activation='relu'),
layers.MaxPooling2D(), # 4 -> 2
layers.GlobalAveragePooling2D(),
layers.Dropout(0.25),
layers.Dense(256, activation='relu'),
layers.Dense(num_classes, activation='softmax'),
])
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
print(model.summary())
return model
def main(dataDir='dataset/',nepochs=100,h=66,w=66,way=3,deep=18,flag='self',resDir='result/self/'):
'''
主函數(shù)
'''
if not os.path.exists(resDir):
os.makedirs(resDir)
X,y=dataHelper.loadDataset(dataDir=dataDir,h=h,w=w)
X=preProcess(X)
y,num_classes=oneHotEncode(y)
#數(shù)據(jù)集分割
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.30,random_state=7)
#模型定義初始化
if flag=='self':
model=selfModel(num_classes,nepochs,X_train,h=h,w=w,way=way)
elif flag=='vgg':
model=vggModel(num_classes,nepochs,X_train,h=h,w=w,way=way)
else:
model=resnetModel(num_classes,deep=deep,h=h,w=w,way=way)
# 當(dāng)標(biāo)準(zhǔn)評(píng)估停止提升時(shí),降低學(xué)習(xí)速率
reduce_lr = ReduceLROnPlateau(verbose=1)
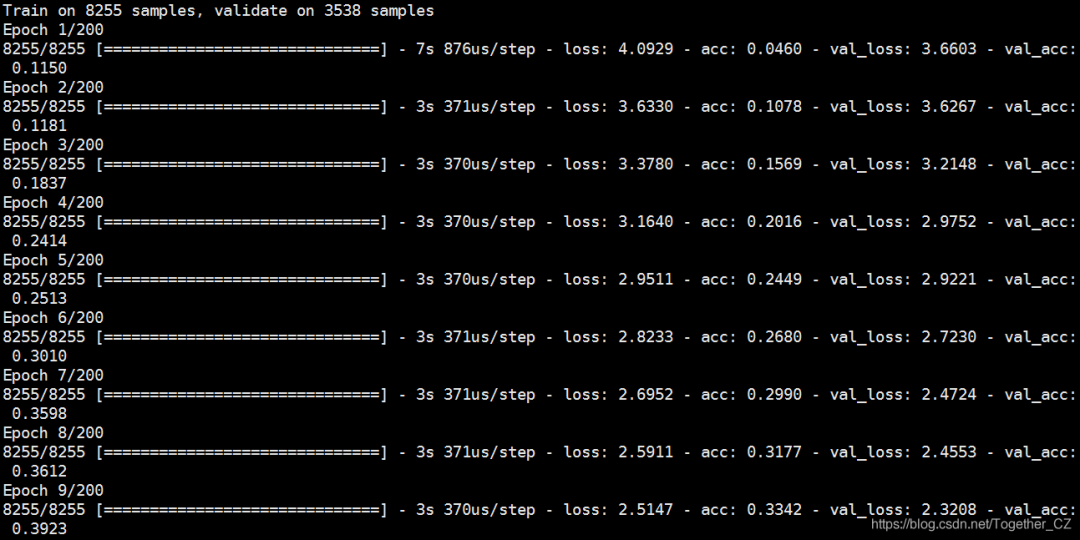
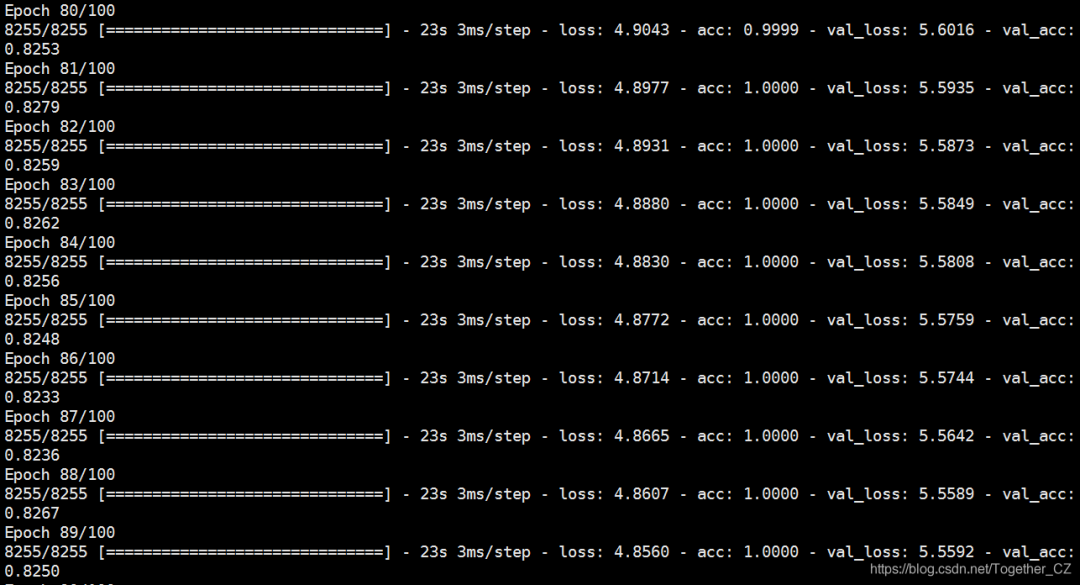
history = model.fit(X_train,y_train,epochs=nepochs,validation_data=(X_test, y_test),callbacks=[reduce_lr])
resHandle(history,resDir,model,X_test,y_test)
print('Finished.....................................................')

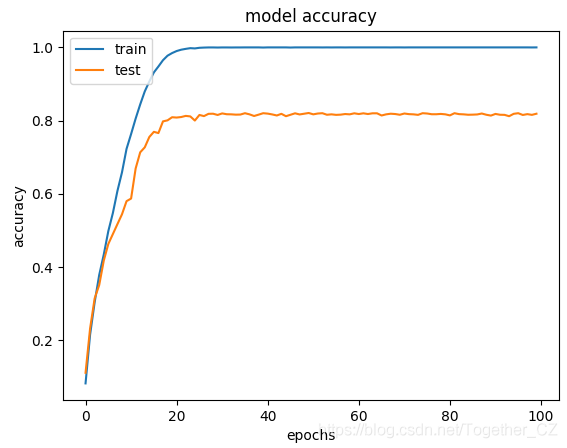
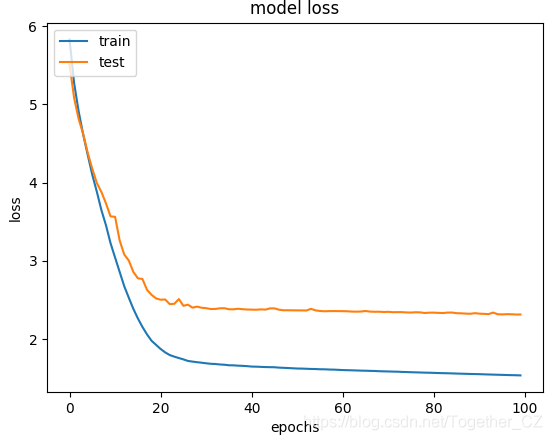
def upload_image():
'''
上傳圖像
'''
try:
file_path=filedialog.askopenfilename()
uploaded=Image.open(file_path)
uploaded.thumbnail(((top.winfo_width()/2.25),(top.winfo_height()/2.25)))
im=ImageTk.PhotoImage(uploaded)
sign_image.configure(image=im)
sign_image.image=im
label.configure(text='')
executeButton(file_path)
except:
pass
upload=Button(top,text=u"點(diǎn)擊上傳圖像",command=upload_image,padx=10,pady=5)
upload.configure(background='#63B8FF', foreground='#364156',font=('arial',20,'bold'))
upload.pack(side=BOTTOM,pady=50)
sign_image.pack(side=BOTTOM,expand=True)
label.pack(side=BOTTOM,expand=True)
heading = Label(top, text=u"12306驗(yàn)證碼識(shí)別機(jī)器人",pady=20, font=('arial',30,'bold'))
heading.configure(background='#40E0D0',foreground='#364156')
heading.pack()
top.mainloop()
使用樣例如下:


作者:沂水寒城,CSDN博客專家,個(gè)人研究方向:機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、NLP、CV
Blog: http://yishuihancheng.blog.csdn.net
贊 賞 作 者

更多閱讀
特別推薦

點(diǎn)擊下方閱讀原文加入社區(qū)會(huì)員
評(píng)論
圖片
表情