
一整套Java線上故障排查技巧,愛了!
線上故障主要會(huì)包括 CPU、磁盤、內(nèi)存以及網(wǎng)絡(luò)問題,而大多數(shù)故障可能會(huì)包含不止一個(gè)層面的問題,所以進(jìn)行排查時(shí)候盡量四個(gè)方面依次排查一遍。
同時(shí)例如 jstack、jmap 等工具也是不囿于一個(gè)方面的問題的,基本上出問題就是 df、free、top 三連,然后依次 jstack、jmap 伺候,具體問題具體分析即可。
CPU
一般來講我們首先會(huì)排查 CPU 方面的問題。CPU 異常往往還是比較好定位的。原因包括業(yè)務(wù)邏輯問題(死循環(huán))、頻繁 GC 以及上下文切換過多。
而最常見的往往是業(yè)務(wù)邏輯(或者框架邏輯)導(dǎo)致的,可以使用 jstack 來分析對(duì)應(yīng)的堆棧情況。
①使用 jstack 分析 CPU 問題
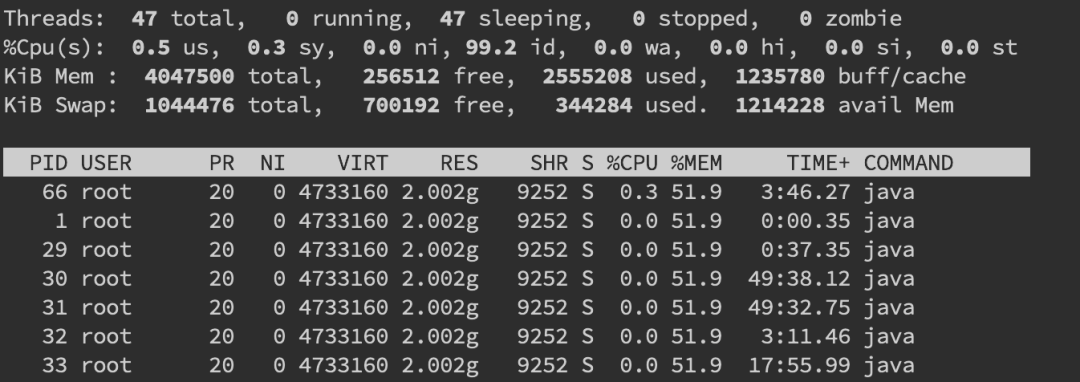
我們先用 ps 命令找到對(duì)應(yīng)進(jìn)程的 pid(如果你有好幾個(gè)目標(biāo)進(jìn)程,可以先用 top 看一下哪個(gè)占用比較高)。
接著用top -H -p pid來找到 CPU 使用率比較高的一些線程:

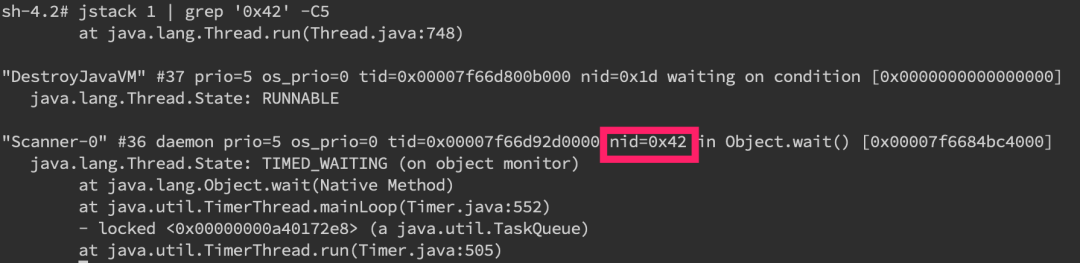
可以看到我們已經(jīng)找到了 nid 為 0x42 的堆棧信息,接著只要仔細(xì)分析一番即可。
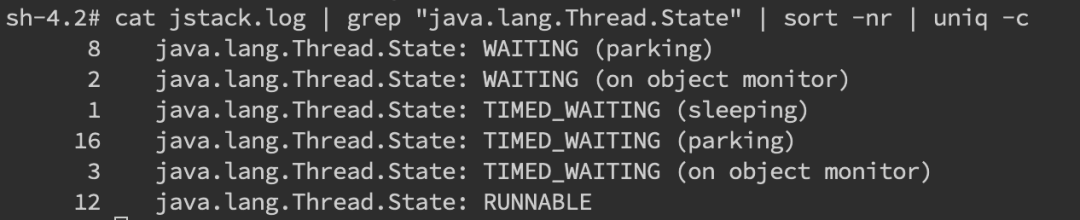
當(dāng)然更常見的是我們對(duì)整個(gè) jstack 文件進(jìn)行分析,通常我們會(huì)比較關(guān)注 WAITING 和 TIMED_WAITING 的部分,BLOCKED 就不用說了。
②頻繁 GC
當(dāng)然我們還是會(huì)使用 jstack 來分析問題,但有時(shí)候我們可以先確定下 GC 是不是太頻繁。
使用 jstat -gc pid 1000 命令來對(duì) GC 分代變化情況進(jìn)行觀察,1000 表示采樣間隔(ms),S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU 分別代表兩個(gè) Survivor 區(qū)、Eden 區(qū)、老年代、元數(shù)據(jù)區(qū)的容量和使用量。
YGC/YGT、FGC/FGCT、GCT 則代表 YoungGc、FullGc 的耗時(shí)和次數(shù)以及總耗時(shí)。

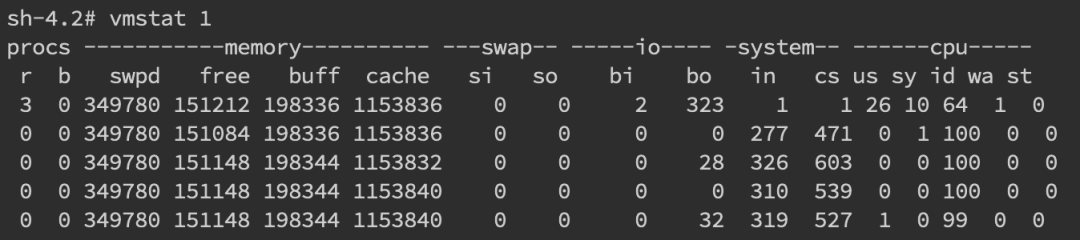
③上下文切換
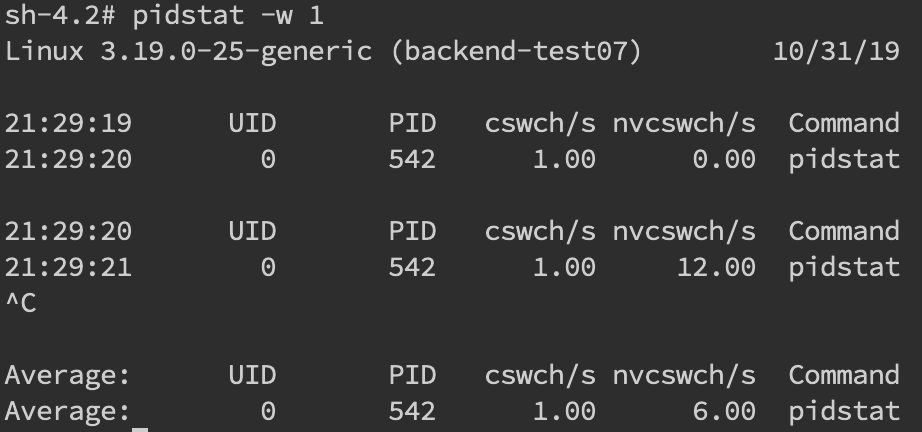
磁盤

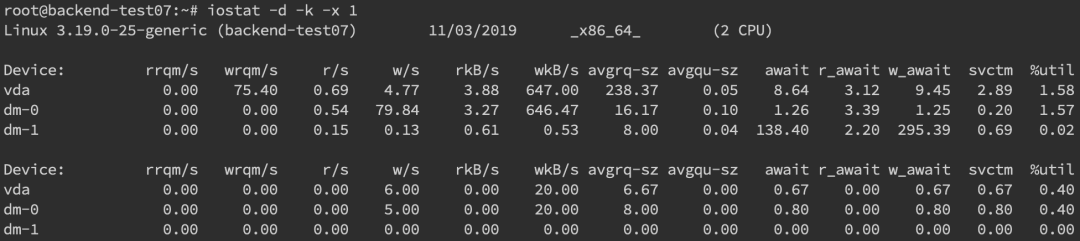
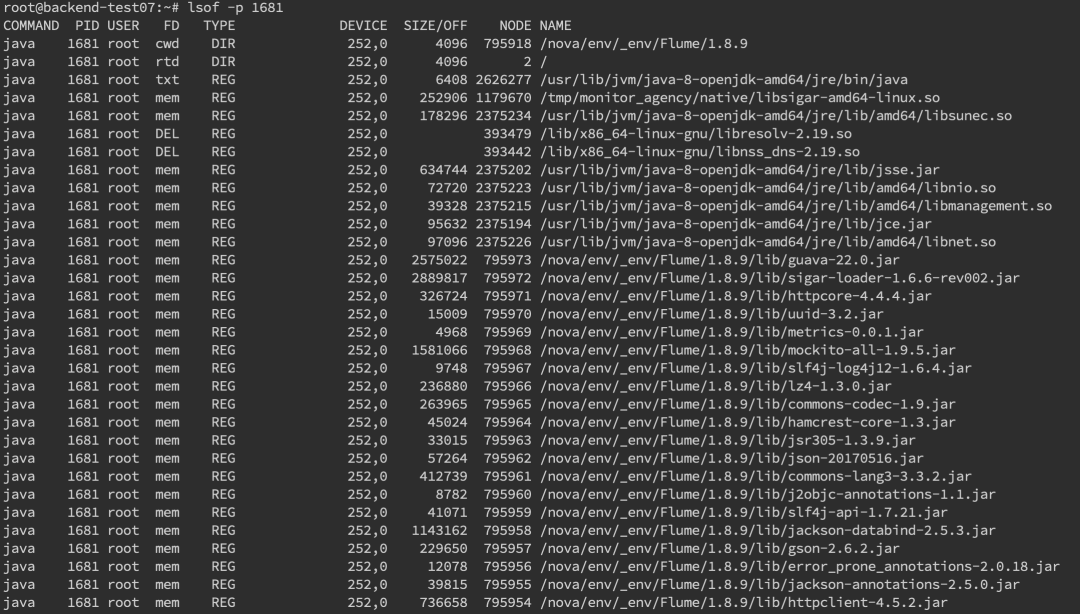
最后一列 %util 可以看到每塊磁盤寫入的程度,而 rrqpm/s 以及 wrqm/s 分別表示讀寫速度,一般就能幫助定位到具體哪塊磁盤出現(xiàn)問題了。
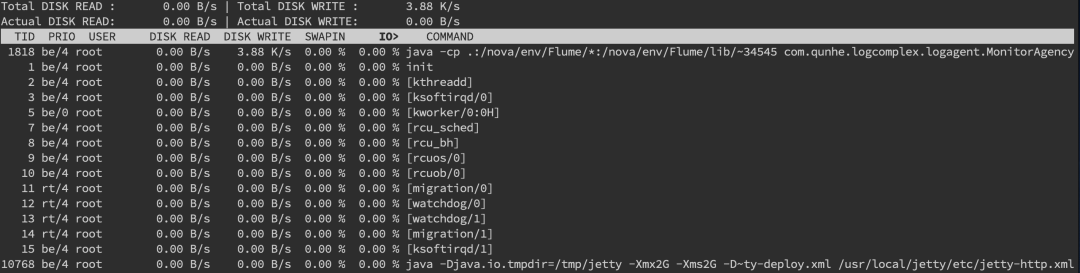

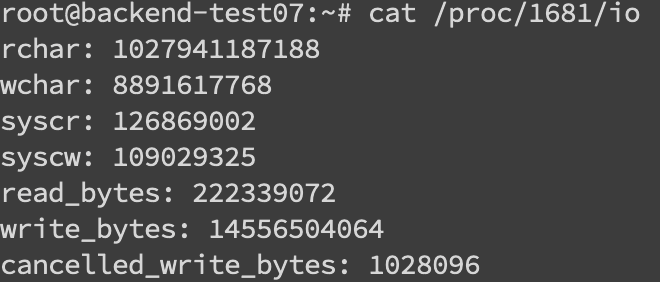
內(nèi)存
內(nèi)存問題排查起來相對(duì)比 CPU 麻煩一些,場(chǎng)景也比較多。主要包括 OOM、GC 問題和堆外內(nèi)存。

堆內(nèi)內(nèi)存
內(nèi)存問題大多還都是堆內(nèi)內(nèi)存問題。表象上主要分為 OOM 和 Stack Overflow。
①OOM
JMV 中的內(nèi)存不足,OOM 大致可以分為以下幾種:
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
這個(gè)意思是沒有足夠的內(nèi)存空間給線程分配 Java 棧,基本上還是線程池代碼寫的有問題,比如說忘記 shutdown,所以說應(yīng)該首先從代碼層面來尋找問題,使用 jstack 或者 jmap。
如果一切都正常,JVM 方面可以通過指定 Xss 來減少單個(gè) thread stack 的大小。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
這個(gè)意思是堆的內(nèi)存占用已經(jīng)達(dá)到 -Xmx 設(shè)置的最大值,應(yīng)該是最常見的的 OOM 錯(cuò)誤了。
解決思路仍然是先應(yīng)該在代碼中找,懷疑存在內(nèi)存泄漏,通過 jstack 和 jmap 去定位問題。如果說一切都正常,才需要通過調(diào)整 Xmx 的值來擴(kuò)大內(nèi)存。
Caused by: java.lang.OutOfMemoryError: Meta space
這個(gè)意思是元數(shù)據(jù)區(qū)的內(nèi)存占用已經(jīng)達(dá)到 XX:MaxMetaspaceSize 設(shè)置的最大值,排查思路和上面的一致,參數(shù)方面可以通過 XX:MaxPermSize 來進(jìn)行調(diào)整(這里就不說 1.8 以前的永久代了)。
②Stack Overflow
棧內(nèi)存溢出,這個(gè)大家見到也比較多。
Exception in thread "main" java.lang.StackOverflowError
表示線程棧需要的內(nèi)存大于 Xss 值,同樣也是先進(jìn)行排查,參數(shù)方面通過Xss來調(diào)整,但調(diào)整的太大可能又會(huì)引起 OOM。
③使用 JMAP 定位代碼內(nèi)存泄漏

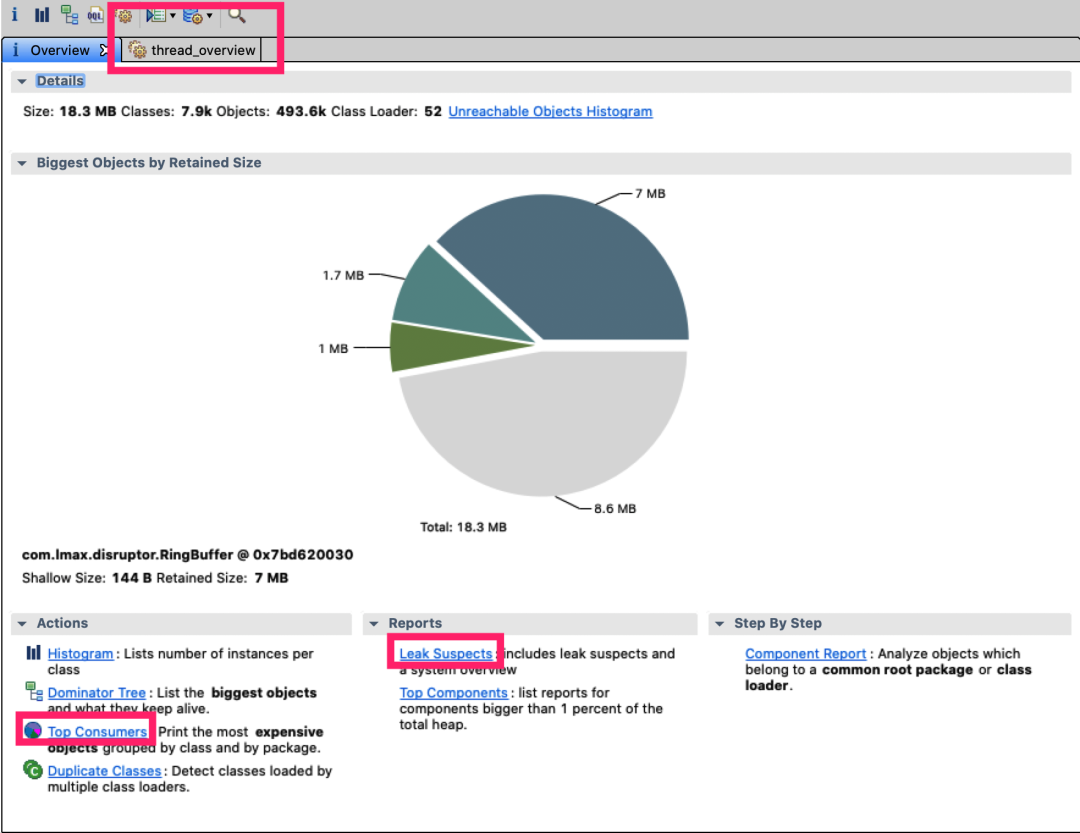
通過 mat(Eclipse Memory Analysis Tools)導(dǎo)入 dump 文件進(jìn)行分析,內(nèi)存泄漏問題一般我們直接選 Leak Suspects 即可,mat 給出了內(nèi)存泄漏的建議。
另外也可以選擇 Top Consumers 來查看最大對(duì)象報(bào)告。和線程相關(guān)的問題可以選擇 thread overview 進(jìn)行分析。
日常開發(fā)中,代碼產(chǎn)生內(nèi)存泄漏是比較常見的事,并且比較隱蔽,需要開發(fā)者更加關(guān)注細(xì)節(jié)。
比如說每次請(qǐng)求都 new 對(duì)象,導(dǎo)致大量重復(fù)創(chuàng)建對(duì)象;進(jìn)行文件流操作但未正確關(guān)閉;手動(dòng)不當(dāng)觸發(fā) GC;ByteBuffer 緩存分配不合理等都會(huì)造成代碼 OOM。
另一方面,我們可以在啟動(dòng)參數(shù)中指定 -XX:+HeapDumpOnOutOfMemoryError 來保存 OOM 時(shí)的 dump 文件。
④GC 問題和線程
GC 問題除了影響 CPU 也會(huì)影響內(nèi)存,排查思路也是一致的。一般先使用 jstat 來查看分代變化情況,比如 youngGC 或者 FullGC 次數(shù)是不是太多呀;EU、OU 等指標(biāo)增長(zhǎng)是不是異常呀等。
線程的話太多而且不被及時(shí) GC 也會(huì)引發(fā) OOM,大部分就是之前說的 unable to create new native thread。


堆外內(nèi)存
如果碰到堆外內(nèi)存溢出,那可真是太不幸了。首先堆外內(nèi)存溢出表現(xiàn)就是物理常駐內(nèi)存增長(zhǎng)快,報(bào)錯(cuò)的話視使用方式都不確定。
如果由于使用 Netty 導(dǎo)致的,那錯(cuò)誤日志里可能會(huì)出現(xiàn) OutOfDirectMemoryError 錯(cuò)誤,如果直接是 DirectByteBuffer,那會(huì)報(bào) OutOfMemoryError: Direct buffer memory。
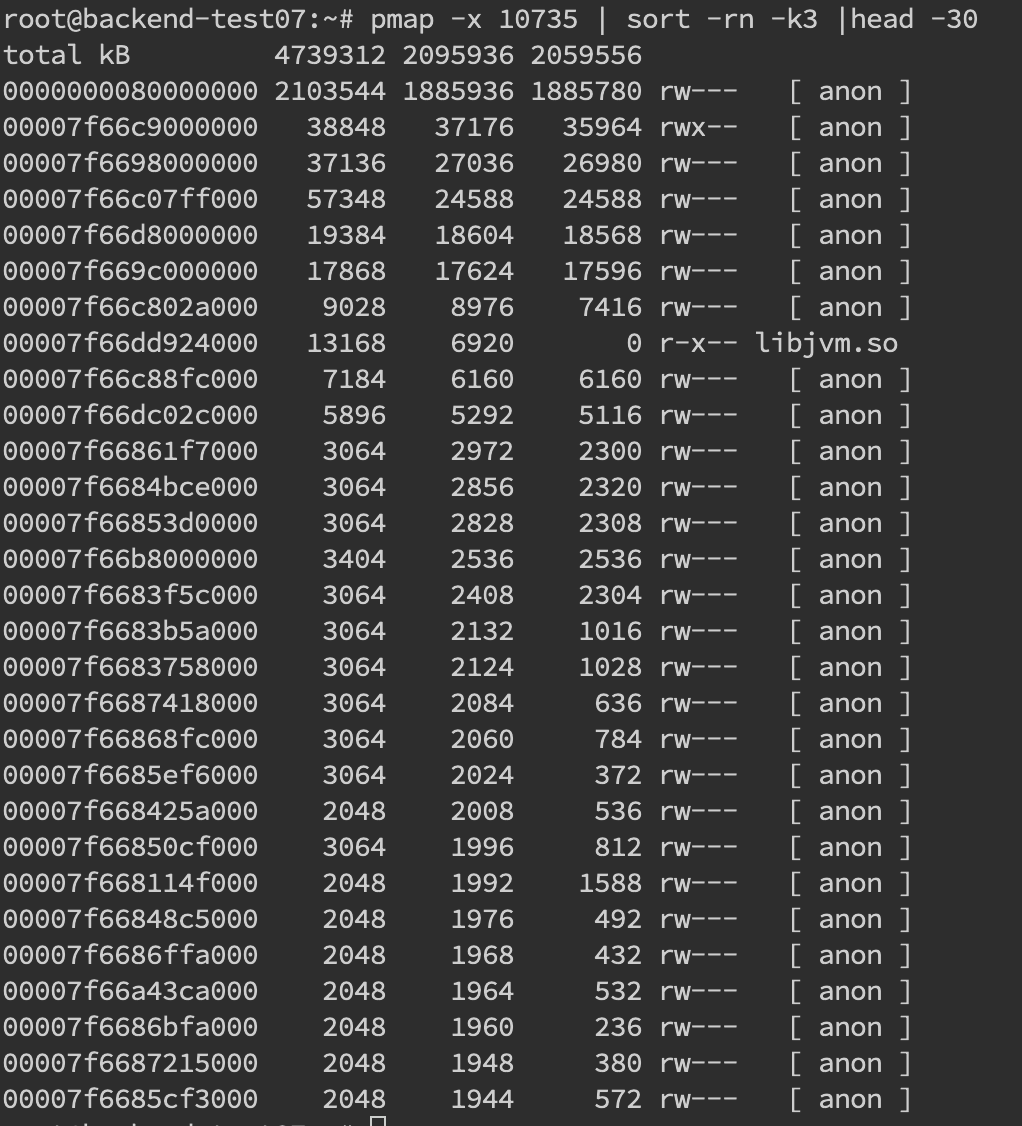
堆外內(nèi)存溢出往往是和 NIO 的使用相關(guān),一般我們先通過 pmap 來查看下進(jìn)程占用的內(nèi)存情況 pmap -x pid | sort -rn -k3 | head -30,這段意思是查看對(duì)應(yīng) pid 倒序前 30 大的內(nèi)存段。

獲取 dump 文件后可用 heaxdump 進(jìn)行查看 hexdump -C filename | less,不過大多數(shù)看到的都是二進(jìn)制亂碼。
NMT 是 Java7U40 引入的 HotSpot 新特性,配合 jcmd 命令我們就可以看到具體內(nèi)存組成了。
需要在啟動(dòng)參數(shù)中加入 -XX:NativeMemoryTracking=summary 或者 -XX:NativeMemoryTracking=detail,會(huì)有略微性能損耗。


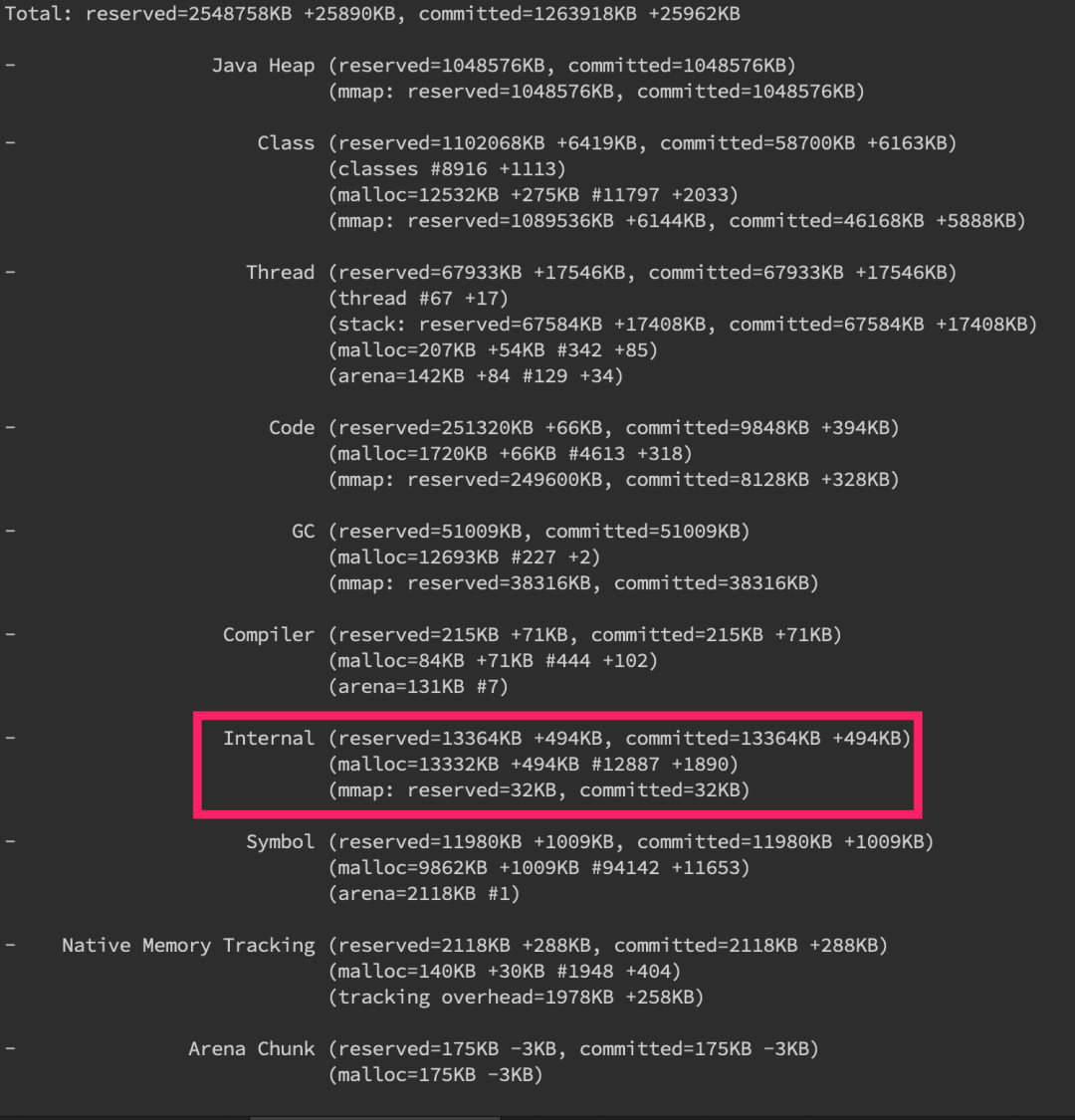
可以看到 jcmd 分析出來的內(nèi)存十分詳細(xì),包括堆內(nèi)、線程以及 GC(所以上述其他內(nèi)存異常其實(shí)都可以用 nmt 來分析),這邊堆外內(nèi)存我們重點(diǎn)關(guān)注 Internal 的內(nèi)存增長(zhǎng),如果增長(zhǎng)十分明顯的話那就是有問題了。

此外在系統(tǒng)層面,我們還可以使用 strace 命令來監(jiān)控內(nèi)存分配 strace -f -e "brk,mmap,munmap" -p pid。
這邊內(nèi)存分配信息主要包括了 pid 和內(nèi)存地址:
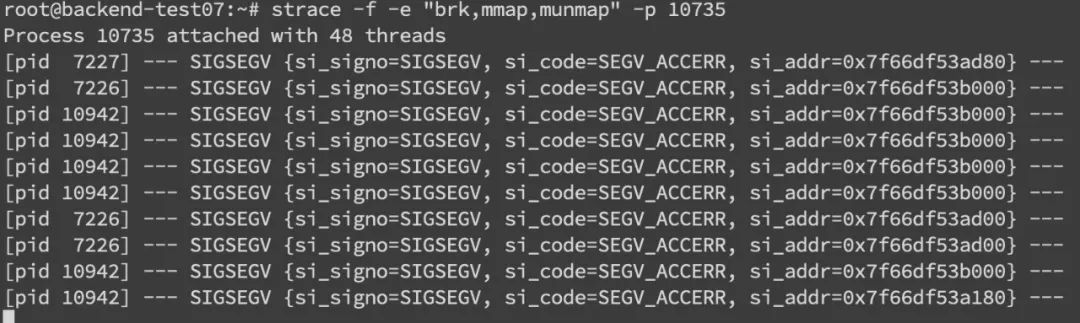
不過其實(shí)上面那些操作也很難定位到具體的問題點(diǎn),關(guān)鍵還是要看錯(cuò)誤日志棧,找到可疑的對(duì)象,搞清楚它的回收機(jī)制,然后去分析對(duì)應(yīng)的對(duì)象。
比如 DirectByteBuffer 分配內(nèi)存的話,是需要 Full GC 或者手動(dòng) system.gc 來進(jìn)行回收的(所以最好不要使用-XX:+DisableExplicitGC)。
那么其實(shí)我們可以跟蹤一下 DirectByteBuffer 對(duì)象的內(nèi)存情況,通過 jmap -histo:live pid 手動(dòng)觸發(fā) Full GC 來看看堆外內(nèi)存有沒有被回收。
如果被回收了,那么大概率是堆外內(nèi)存本身分配的太小了,通過 -XX:MaxDirectMemorySize 進(jìn)行調(diào)整。
如果沒有什么變化,那就要使用 jmap 去分析那些不能被 GC 的對(duì)象,以及和 DirectByteBuffer 之間的引用關(guān)系了。
GC 問題
堆內(nèi)內(nèi)存泄漏總是和 GC 異常相伴。不過 GC 問題不只是和內(nèi)存問題相關(guān),還有可能引起 CPU 負(fù)載、網(wǎng)絡(luò)問題等系列并發(fā)癥,只是相對(duì)來說和內(nèi)存聯(lián)系緊密些,所以我們?cè)诖藛为?dú)總結(jié)一下 GC 相關(guān)問題。
我們?cè)?CPU 章介紹了使用 jstat 來獲取當(dāng)前 GC 分代變化信息。
而更多時(shí)候,我們是通過 GC 日志來排查問題的,在啟動(dòng)參數(shù)中加上 -verbose:gc,-XX:+PrintGCDetails,-XX:+PrintGCDateStamps,-XX:+PrintGCTimeStamps 來開啟 GC 日志。
常見的 Young GC、Full GC 日志含義在此就不做贅述了。針對(duì) GC 日志,我們就能大致推斷出 youngGC 與 Full GC 是否過于頻繁或者耗時(shí)過長(zhǎng),從而對(duì)癥下藥。
我們下面將對(duì) G1 垃圾收集器來做分析,這邊也建議大家使用 G1-XX:+UseG1GC。
①youngGC 過頻繁
youngGC 頻繁一般是短周期小對(duì)象較多,先考慮是不是 Eden 區(qū)/新生代設(shè)置的太小了,看能否通過調(diào)整 -Xmn、-XX:SurvivorRatio 等參數(shù)設(shè)置來解決問題。
如果參數(shù)正常,但是 youngGC 頻率還是太高,就需要使用 Jmap 和 MAT 對(duì) dump 文件進(jìn)行進(jìn)一步排查了。
②youngGC 耗時(shí)過長(zhǎng)
耗時(shí)過長(zhǎng)問題就要看 GC 日志里耗時(shí)耗在哪一塊了。以 G1 日志為例,可以關(guān)注 Root Scanning、Object Copy、Ref Proc 等階段。
Ref Proc 耗時(shí)長(zhǎng),就要注意引用相關(guān)的對(duì)象。Root Scanning 耗時(shí)長(zhǎng),就要注意線程數(shù)、跨代引用。
Object Copy 則需要關(guān)注對(duì)象生存周期。而且耗時(shí)分析它需要橫向比較,就是和其他項(xiàng)目或者正常時(shí)間段的耗時(shí)比較。

③觸發(fā) Full GC
G1 中更多的還是 mixedGC,但 mixedGC 可以和 youngGC 思路一樣去排查。
觸發(fā) Full GC 了一般都會(huì)有問題,G1 會(huì)退化使用 Serial 收集器來完成垃圾的清理工作,暫停時(shí)長(zhǎng)達(dá)到秒級(jí)別,可以說是半跪了。
FullGC 的原因可能包括以下這些,以及參數(shù)調(diào)整方面的一些思路:
并發(fā)階段失敗:在并發(fā)標(biāo)記階段,MixGC 之前老年代就被填滿了,那么這時(shí)候 G1 就會(huì)放棄標(biāo)記周期。
這種情況,可能就需要增加堆大小,或者調(diào)整并發(fā)標(biāo)記線程數(shù) -XX:ConcGCThreads。
晉升失敗:在 GC 的時(shí)候沒有足夠的內(nèi)存供存活/晉升對(duì)象使用,所以觸發(fā)了 Full GC。
這時(shí)候可以通過 -XX:G1ReservePercent 來增加預(yù)留內(nèi)存百分比,減少 -XX:InitiatingHeapOccupancyPercent 來提前啟動(dòng)標(biāo)記,-XX:ConcGCThreads 來增加標(biāo)記線程數(shù)也是可以的。
大對(duì)象分配失敗:大對(duì)象找不到合適的 Region 空間進(jìn)行分配,就會(huì)進(jìn)行 Full GC,這種情況下可以增大內(nèi)存或者增大 -XX:G1HeapRegionSize。
程序主動(dòng)執(zhí)行 System.gc():不要隨便寫就對(duì)了。
另外,我們可以在啟動(dòng)參數(shù)中配置 -XX:HeapDumpPath=/xxx/dump.hprof 來 dump fullGC 相關(guān)的文件,并通過 jinfo 來進(jìn)行 GC 前后的 dump:
jinfo?-flag?+HeapDumpBeforeFullGC?pid?
jinfo?-flag?+HeapDumpAfterFullGC?pid
網(wǎng)絡(luò)
讀寫超時(shí):readTimeout/writeTimeout,有些框架叫做 so_timeout 或者 socketTimeout,均指的是數(shù)據(jù)讀寫超時(shí)。
注意這邊的超時(shí)大部分是指邏輯上的超時(shí)。soa 的超時(shí)指的也是讀超時(shí)。讀寫超時(shí)一般都只針對(duì)客戶端設(shè)置。
連接超時(shí):connectionTimeout,客戶端通常指與服務(wù)端建立連接的最大時(shí)間。
服務(wù)端這邊 connectionTimeout 就有些五花八門了,Jetty 中表示空閑連接清理時(shí)間,Tomcat 則表示連接維持的最大時(shí)間。
其他:包括連接獲取超時(shí) connectionAcquireTimeout 和空閑連接清理超時(shí) idleConnectionTimeout。多用于使用連接池或隊(duì)列的客戶端或服務(wù)端框架。
TCP 隊(duì)列溢出是個(gè)相對(duì)底層的錯(cuò)誤,它可能會(huì)造成超時(shí)、RST 等更表層的錯(cuò)誤。因此錯(cuò)誤也更隱蔽,所以我們單獨(dú)說一說。
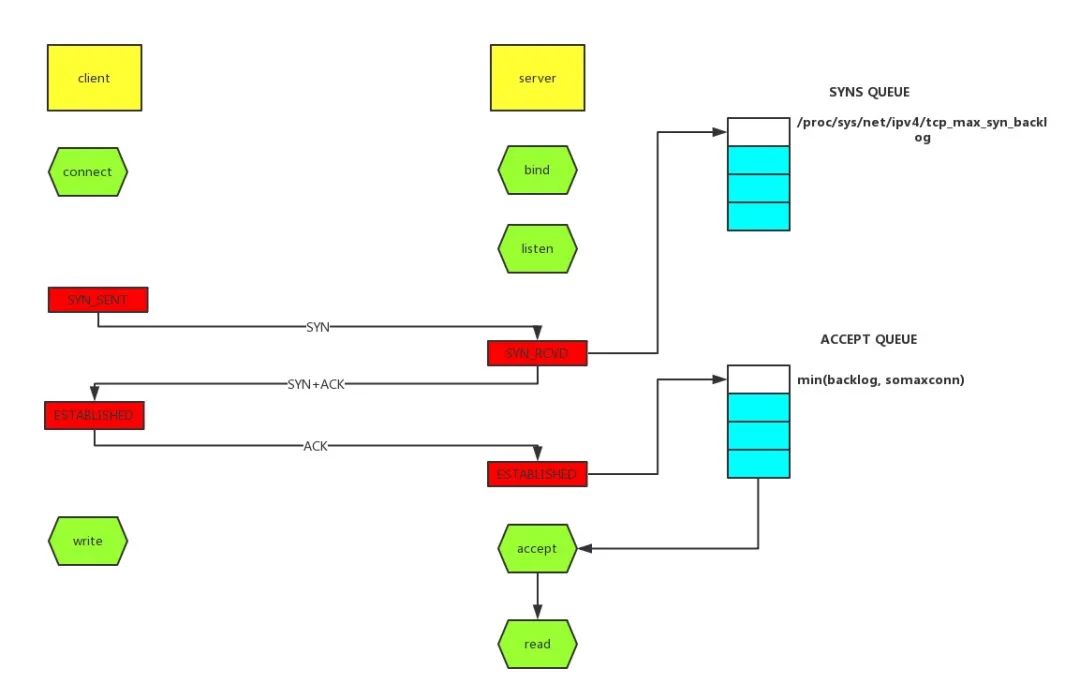
syns queue(半連接隊(duì)列)
accept queue(全連接隊(duì)列)
netstat 命令,執(zhí)行 netstat -s | egrep "listen|LISTEN":

ss 命令,執(zhí)行 ss -lnt:

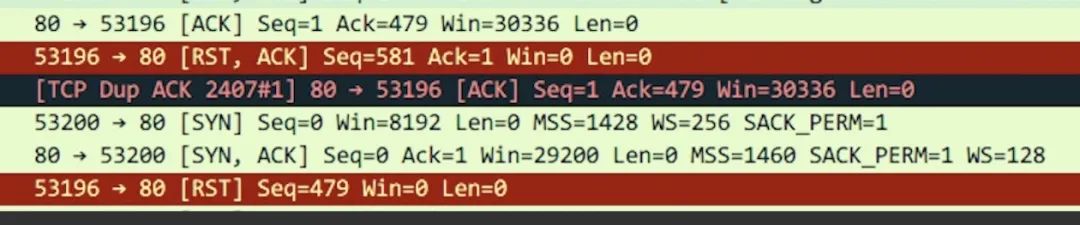
tcpdump -i en0 tcp -w xxx.cap,en0 表示監(jiān)聽的網(wǎng)卡:

接下來我們通過 wireshark 打開抓到的包,可能就能看到如下圖所示,紅色的就表示 RST 包了。
用 ss 命令會(huì)更快 ss -ant | awk '{++S[$1]} END {for(a in S) print a, S[a]}':

這種情況可以在服務(wù)端做一些內(nèi)核參數(shù)調(diào)優(yōu):
#表示開啟重用。允許將TIME-WAIT sockets重新用于新的TCP連接,默認(rèn)為0,表示關(guān)閉
net.ipv4.tcp_tw_reuse?=?1
#表示開啟TCP連接中TIME-WAIT?sockets的快速回收,默認(rèn)為0,表示關(guān)閉
net.ipv4.tcp_tw_recycle?=?1
來源:fredal.xin/java-error-check
版權(quán)申明:內(nèi)容來源網(wǎng)絡(luò),版權(quán)歸原創(chuàng)者所有。除非無法確認(rèn),我們都會(huì)標(biāo)明作者及出處,如有侵權(quán)煩請(qǐng)告知,我們會(huì)立即刪除并表示歉意。謝謝!
