
圖解 Redis 五種數(shù)據(jù)結(jié)構(gòu)底層實(shí)現(xiàn)
以下文章來(lái)源于武培軒,回復(fù)資源獲取資料
Redis 是一個(gè)基于內(nèi)存中的數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)系統(tǒng),可以用作數(shù)據(jù)庫(kù)、緩存和消息中間件。Redis 支持五種常見(jiàn)對(duì)象類(lèi)型:字符串(String)、哈希(Hash)、列表(List)、集合(Set)以及有序集合(Zset),我們?cè)谌粘9ぷ髦幸矔?huì)經(jīng)常使用它們。知其然,更要知其所以然,本文將會(huì)帶你讀懂這五種常見(jiàn)對(duì)象類(lèi)型的底層數(shù)據(jù)結(jié)構(gòu)。
本文主要內(nèi)容參考自《Redis設(shè)計(jì)與實(shí)現(xiàn)》
1. 對(duì)象類(lèi)型和編碼
Redis 使用對(duì)象來(lái)存儲(chǔ)鍵和值的,在Redis中,每個(gè)對(duì)象都由 redisObject 結(jié)構(gòu)表示。redisObject 結(jié)構(gòu)主要包含三個(gè)屬性:type、encoding 和 ptr。
typedefstructredisObject{ // 類(lèi)型unsignedtype: 4;// 編碼unsignedencoding: 4; // 底層數(shù)據(jù)結(jié)構(gòu)的指針void*ptr; } robj;
其中 type 屬性記錄了對(duì)象的類(lèi)型。對(duì)于 Redis 來(lái)說(shuō),鍵對(duì)象總是字符串類(lèi)型,值對(duì)象可以是任意支持的類(lèi)型。因此,當(dāng)我們說(shuō) Redis 鍵采用哪種對(duì)象類(lèi)型的時(shí)候,指的是對(duì)應(yīng)的值采用哪種對(duì)象類(lèi)型。
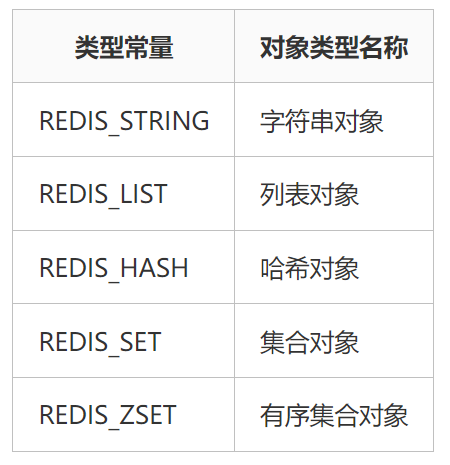
*ptr 屬性指向了對(duì)象的底層數(shù)據(jù)結(jié)構(gòu),而這些數(shù)據(jù)結(jié)構(gòu)由 encoding 屬性決定。

之所以由 encoding 屬性來(lái)決定對(duì)象的底層數(shù)據(jù)結(jié)構(gòu),是為了實(shí)現(xiàn)同一對(duì)象類(lèi)型,支持不同的底層實(shí)現(xiàn)。這樣就能在不同場(chǎng)景下,使用不同的底層數(shù)據(jù)結(jié)構(gòu),進(jìn)而極大提升Redis的靈活性和效率。
底層數(shù)據(jù)結(jié)構(gòu)后面會(huì)詳細(xì)講解,這里簡(jiǎn)單看一下即可。
2. 字符串對(duì)象
字符串是我們?nèi)粘9ぷ髦杏玫米疃嗟膶?duì)象類(lèi)型,它對(duì)應(yīng)的編碼可以是 int、raw 和 embstr。字符串對(duì)象相關(guān)命令可參考:Redis命令-Strings。
如果一個(gè)字符串對(duì)象保存的是不超過(guò) long 類(lèi)型的整數(shù)值,此時(shí)編碼類(lèi)型即為 int,其底層數(shù)據(jù)結(jié)構(gòu)直接就是 long 類(lèi)型。例如執(zhí)行 set number 10086,就會(huì)創(chuàng)建 int 編碼的字符串對(duì)象作為 number 鍵的值。
如果字符串對(duì)象保存的是一個(gè)長(zhǎng)度大于 39 字節(jié)的字符串,此時(shí)編碼類(lèi)型即為 raw,其底層數(shù)據(jù)結(jié)構(gòu)是簡(jiǎn)單動(dòng)態(tài)字符串(SDS);如果長(zhǎng)度小于等于 39 個(gè)字節(jié),編碼類(lèi)型則為 embstr,底層數(shù)據(jù)結(jié)構(gòu)就是 embstr 編碼 SDS。下面,我們?cè)敿?xì)理解下什么是簡(jiǎn)單動(dòng)態(tài)字符串。
2.1 簡(jiǎn)單動(dòng)態(tài)字符串SDS 定義
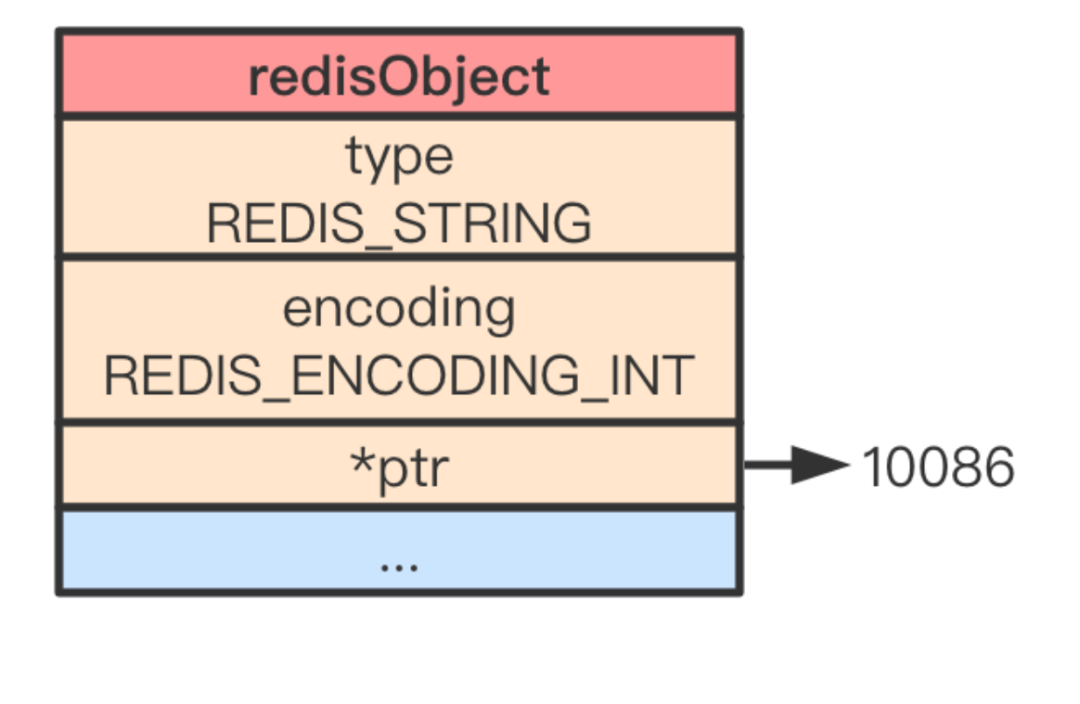
在 Redis 中,使用 sdshdr 數(shù)據(jù)結(jié)構(gòu)表示 SDS:
structsdshdr{ // 字符串長(zhǎng)度intlen; // buf數(shù)組中未使用的字節(jié)數(shù)intfree; // 字節(jié)數(shù)組,用于保存字符串charbuf[]; };
SDS 遵循了 C 字符串以空字符結(jié)尾的慣例,保存空字符的 1 字節(jié)不會(huì)計(jì)算在 len 屬性里面。例如,Redis 這個(gè)字符串在 SDS 里面的數(shù)據(jù)可能是如下形式:
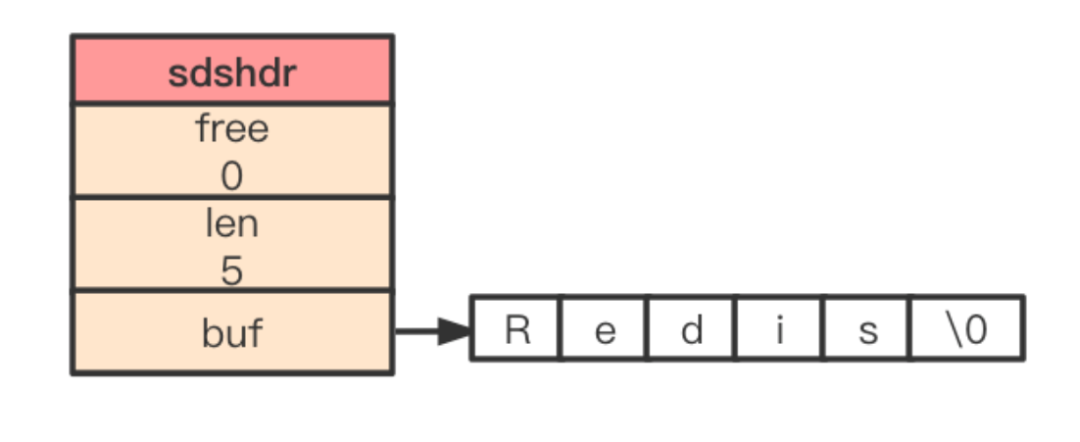
SDS 與 C 字符串的區(qū)別
C 語(yǔ)言使用長(zhǎng)度為 N+1 的字符數(shù)組來(lái)表示長(zhǎng)度為N的字符串,并且字符串的最后一個(gè)元素是空字符 0。Redis 采用 SDS 相對(duì)于 C 字符串有如下幾個(gè)優(yōu)勢(shì):
常數(shù)復(fù)雜度獲取字符串長(zhǎng)度;
杜絕緩沖區(qū)溢出;
減少修改字符串時(shí)帶來(lái)的內(nèi)存重分配次數(shù);
二進(jìn)制安全。
常數(shù)復(fù)雜度獲取字符串長(zhǎng)度
因?yàn)?C 字符串并不記錄自身的長(zhǎng)度信息,所以為了獲取字符串的長(zhǎng)度,必須遍歷整個(gè)字符串,時(shí)間復(fù)雜度是 O(N)。而 SDS 使用 len 屬性記錄了字符串的長(zhǎng)度,因此獲取 SDS字符串長(zhǎng)度的時(shí)間復(fù)雜度是 O(1)。
杜絕緩沖區(qū)溢出
C 字符串不記錄自身長(zhǎng)度帶來(lái)的另一個(gè)問(wèn)題是, 很容易造成緩存區(qū)溢出。比如使用字符串拼接函數(shù)(stract)的時(shí)候,很容易覆蓋掉字符數(shù)組原有的數(shù)據(jù)。
與 C 字符串不同,SDS 的空間分配策略完全杜絕了發(fā)生緩存區(qū)溢出的可能性。當(dāng) SDS 進(jìn)行字符串?dāng)U充時(shí),首先會(huì)檢查當(dāng)前的字節(jié)數(shù)組的長(zhǎng)度是否足夠。如果不夠的話(huà),會(huì)先進(jìn)行自動(dòng)擴(kuò)容,然后再進(jìn)行字符串操作。
減少修改字符串時(shí)帶來(lái)的內(nèi)存重分配次數(shù)
因?yàn)?C 字符串的長(zhǎng)度和底層數(shù)據(jù)是緊密關(guān)聯(lián)的,所以每次增長(zhǎng)或者縮短一個(gè)字符串,程序都要對(duì)這個(gè)數(shù)組進(jìn)行一次內(nèi)存重分配:
如果是增長(zhǎng)字符串操作,需要先通過(guò)內(nèi)存重分配來(lái)擴(kuò)展底層數(shù)組空間大小,不這么做就導(dǎo)致緩存區(qū)溢出;
如果是縮短字符串操作,需要先通過(guò)內(nèi)存重分配來(lái)來(lái)回收不再使用的空間,不這么做就導(dǎo)致內(nèi)存泄漏。
因?yàn)閮?nèi)存重分配涉及復(fù)雜的算法,并且可能需要執(zhí)行系統(tǒng)調(diào)用,所以通常是個(gè)比較耗時(shí)的操作。對(duì)于 Redis 來(lái)說(shuō),字符串修改是一個(gè)十分頻繁的操作。如果每次都像 C 字符串那樣進(jìn)行內(nèi)存重分配,對(duì)性能影響太大了,顯然是無(wú)法接受的。
SDS 通過(guò)空閑空間解除了字符串長(zhǎng)度和底層數(shù)據(jù)之間的關(guān)聯(lián)。在 SDS 中,數(shù)組中可以包含未使用的字節(jié),這些字節(jié)數(shù)量由 free 屬性記錄。 通過(guò)空閑空間,SDS 實(shí)現(xiàn)了空間預(yù)分配和惰性空間釋放兩種優(yōu)化策略。
1. 空間預(yù)分配
空間預(yù)分配是用于優(yōu)化 SDS 字符串增長(zhǎng)操作的,簡(jiǎn)單來(lái)說(shuō)就是當(dāng)字節(jié)數(shù)組空間不足觸發(fā)重分配的時(shí)候,總是會(huì)預(yù)留一部分空閑空間。這樣的話(huà),就能減少連續(xù)執(zhí)行字符串增長(zhǎng)操作時(shí)的內(nèi)存重分配次數(shù)。
有兩種預(yù)分配的策略:
len 小于 1MB 時(shí):每次重分配時(shí)會(huì)多分配同樣大小的空閑空間;
len 大于等于 1MB 時(shí):每次重分配時(shí)會(huì)多分配 1MB 大小的空閑空間。
2. 惰性空間釋放
惰性空間釋放是用于優(yōu)化 SDS 字符串縮短操作的。簡(jiǎn)單來(lái)說(shuō)就是當(dāng)字符串縮短時(shí),并不立即使用內(nèi)存重分配來(lái)回收多出來(lái)的字節(jié),而是用 free 屬性記錄,等待將來(lái)使用。SDS 也提供直接釋放未使用空間的 API,在需要的時(shí)候,也能真正的釋放掉多余的空間。
二進(jìn)制安全
C 字符串中的字符必須符合某種編碼,并且除了字符串末尾之外,其它位置不允許出現(xiàn)空字符。這些限制使得 C 字符串只能保存文本數(shù)據(jù)。
但是對(duì)于 Redis 來(lái)說(shuō),不僅僅需要保存文本,還要支持保存二進(jìn)制數(shù)據(jù)。為了實(shí)現(xiàn)這一目標(biāo),SDS 的 API 全部做到了二進(jìn)制安全(binary-safe)。
2.2 raw 和 embstr 編碼的 SDS 區(qū)別
我們?cè)谇懊嬷v過(guò),長(zhǎng)度大于 39 字節(jié)的字符串,編碼類(lèi)型為 raw,底層數(shù)據(jù)結(jié)構(gòu)是簡(jiǎn)單動(dòng)態(tài)字符串(SDS)。這個(gè)很好理解,比如當(dāng)我們執(zhí)行 set story "Long, long, long ago there lived a king ..."(長(zhǎng)度大于39)之后,Redis 就會(huì)創(chuàng)建一個(gè) raw 編碼的 String 對(duì)象。
數(shù)據(jù)結(jié)構(gòu)如下:

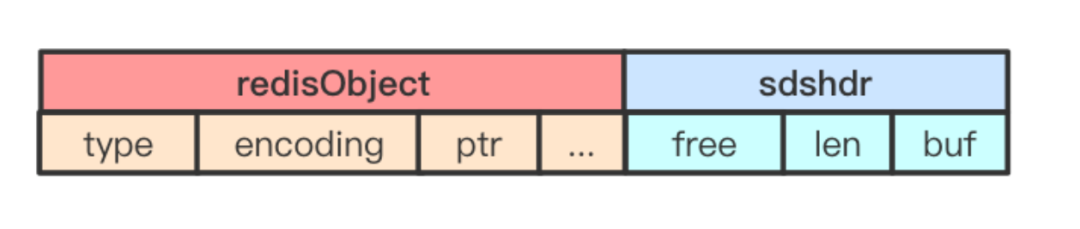
長(zhǎng)度小于等于 39 個(gè)字節(jié)的字符串,編碼類(lèi)型為 embstr,底層數(shù)據(jù)結(jié)構(gòu)則是 embstr 編碼 SDS。embstr 編碼是專(zhuān)門(mén)用來(lái)保存短字符串的,它和 raw 編碼最大的不同在于:raw 編碼會(huì)調(diào)用兩次內(nèi)存分配分別創(chuàng)建 redisObject 結(jié)構(gòu)和 sdshdr 結(jié)構(gòu);而 embstr 編碼則是只調(diào)用一次內(nèi)存分配,在一塊連續(xù)的空間上同時(shí)包含 redisObject 結(jié)構(gòu)和 sdshdr 結(jié)構(gòu)。
2.3 編碼轉(zhuǎn)換
int 編碼和 embstr 編碼的字符串對(duì)象在條件滿(mǎn)足的情況下會(huì)自動(dòng)轉(zhuǎn)換為 raw 編碼的字符串對(duì)象。
對(duì)于 int 編碼來(lái)說(shuō),當(dāng)我們修改這個(gè)字符串為不再是整數(shù)值的時(shí)候,此時(shí)字符串對(duì)象的編碼就會(huì)從 int 變?yōu)?raw。
對(duì)于 embstr 編碼來(lái)說(shuō),只要我們修改了字符串的值,此時(shí)字符串對(duì)象的編碼就會(huì)從 embstr 變?yōu)?raw。
embstr 編碼的字符串對(duì)象可以認(rèn)為是只讀的,因?yàn)?Redis 為其編寫(xiě)任何修改程序。當(dāng)我們要修改 embstr 編碼字符串時(shí),都是先將轉(zhuǎn)換為 raw 編碼,然后再進(jìn)行修改。
3. 列表對(duì)象
列表對(duì)象的編碼可以是 linkedlist 或者 ziplist,對(duì)應(yīng)的底層數(shù)據(jù)結(jié)構(gòu)是鏈表和壓縮列表。列表對(duì)象相關(guān)命令可參考:Redis 命令-List。
默認(rèn)情況下,當(dāng)列表對(duì)象保存的所有字符串元素的長(zhǎng)度都小于 64 字節(jié),且元素個(gè)數(shù)小于 512 個(gè)時(shí),列表對(duì)象采用的是 ziplist 編碼,否則使用 linkedlist 編碼。
可以通過(guò)配置文件修改該上限值。
3.1 鏈表
鏈表是一種非常常見(jiàn)的數(shù)據(jù)結(jié)構(gòu),提供了高效的節(jié)點(diǎn)重排能力以及順序性的節(jié)點(diǎn)訪(fǎng)問(wèn)方式。在 Redis 中,每個(gè)鏈表節(jié)點(diǎn)使用 listNode 結(jié)構(gòu)表示:
typedefstructlistNode{// 前置節(jié)點(diǎn)structlistNode* prev; // 后置節(jié)點(diǎn)structlistNode* next; // 節(jié)點(diǎn)值void*value; }listNode
- 多個(gè) listNode 通過(guò) prev 和 next 指針組成雙端鏈表,如下圖所示:

為了操作起來(lái)比較方便,Redis 使用了 list 結(jié)構(gòu)持有鏈表。
typedefstructlist{ // 表頭節(jié)點(diǎn)listNode *head; // 表尾節(jié)點(diǎn)listNode *tail; // 鏈表包含的節(jié)點(diǎn)數(shù)量unsignedlonglen; // 節(jié)點(diǎn)復(fù)制函數(shù)void*(*dup)( void*ptr); // 節(jié)點(diǎn)釋放函數(shù)void(* free)( void*ptr); // 節(jié)點(diǎn)對(duì)比函數(shù)int(*match)( void*ptr, void*key); } list;
list 結(jié)構(gòu)為鏈表提供了表頭指針 head、表尾指針 tail,以及鏈表長(zhǎng)度計(jì)數(shù)器 len,而 dup、free 和 match 成員則是實(shí)現(xiàn)多態(tài)鏈表所需類(lèi)型的特定函數(shù)。
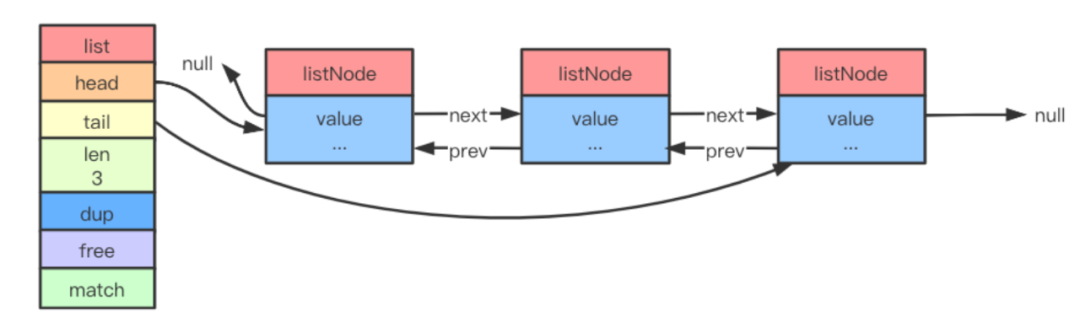
Redis 鏈表實(shí)現(xiàn)的特征總結(jié)如下:
雙端 :鏈表節(jié)點(diǎn)帶有 prev 和 next 指針,獲取某個(gè)節(jié)點(diǎn)的前置節(jié)點(diǎn)和后置節(jié)點(diǎn)的復(fù)雜度都是 O(n) ;
無(wú)環(huán) :表頭節(jié)點(diǎn)的 prev 指針和表尾節(jié)點(diǎn)的 next 指針都指向 NULL,對(duì)鏈表的訪(fǎng)問(wèn)以 NULL 為終點(diǎn);
帶表頭指針和表尾指針 :通過(guò) list 結(jié)構(gòu)的 head 指針和 tail 指針,程序獲取鏈表的表頭節(jié)點(diǎn)和表尾節(jié)點(diǎn)的復(fù)雜度為 O(1) ;
帶鏈表長(zhǎng)度計(jì)數(shù)器 :程序使用 list 結(jié)構(gòu)的 len 屬性來(lái)對(duì) list 持有的節(jié)點(diǎn)進(jìn)行計(jì)數(shù),程序獲取鏈表中節(jié)點(diǎn)數(shù)量的復(fù)雜度為 O(1) ;
多態(tài) :鏈表節(jié)點(diǎn)使用 void* 指針來(lái)保存節(jié)點(diǎn)值,可以保存各種不同類(lèi)型的值。
3.2 壓縮列表
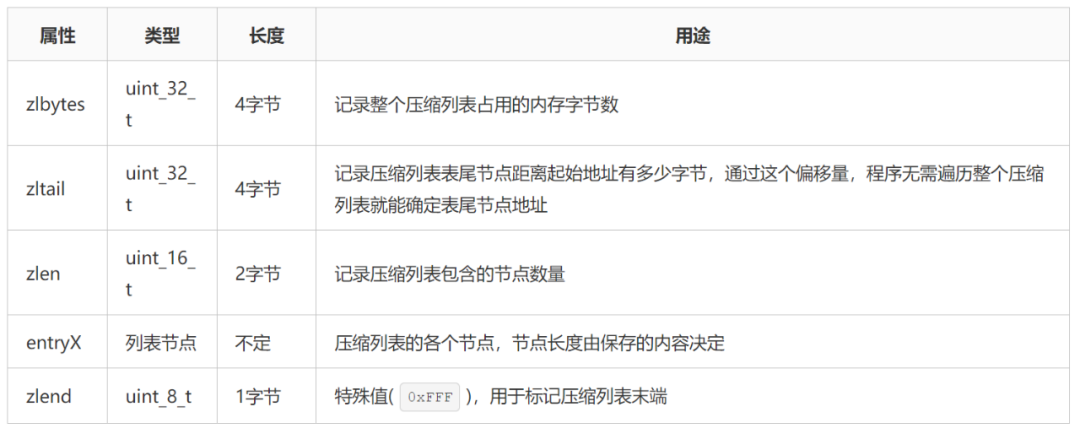
壓縮列表(ziplist)是列表鍵和哈希鍵的底層實(shí)現(xiàn)之一。壓縮列表主要目的是為了節(jié)約內(nèi)存,是由一系列特殊編碼的連續(xù)內(nèi)存塊組成的順序型數(shù)據(jù)結(jié)構(gòu)。一個(gè)壓縮列表可以包含任意多個(gè)節(jié)點(diǎn),每個(gè)節(jié)點(diǎn)可以保存一個(gè)字節(jié)數(shù)組或者一個(gè)整數(shù)值。

如上圖所示,壓縮列表記錄了各組成部分的類(lèi)型、長(zhǎng)度以及用途。
4. 哈希對(duì)象
哈希對(duì)象的編碼可以是 ziplist 或者 hashtable。
4.1 hash-ziplist
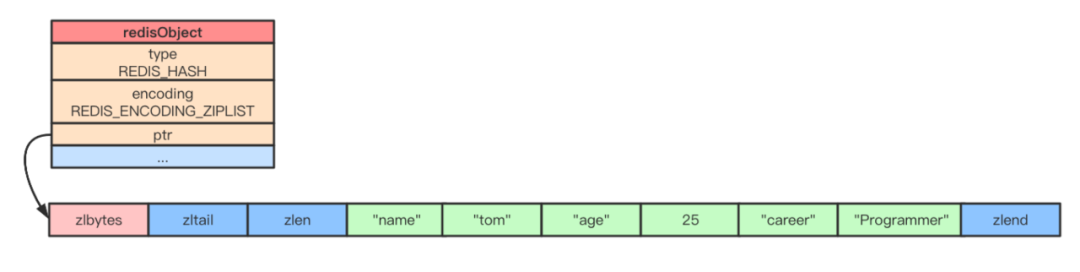
ziplist 底層使用的是壓縮列表實(shí)現(xiàn),上文已經(jīng)詳細(xì)介紹了壓縮列表的實(shí)現(xiàn)原理。每當(dāng)有新的鍵值對(duì)要加入哈希對(duì)象時(shí),先把保存了鍵的節(jié)點(diǎn)推入壓縮列表表尾,然后再將保存了值的節(jié)點(diǎn)推入壓縮列表表尾。比如,我們執(zhí)行如下三條 HSET 命令:
HSETprofile name "tom" HSET profile age 25 HSET profile career "Programmer"如果此時(shí)使用 ziplist 編碼,那么該 Hash 對(duì)象在內(nèi)存中的結(jié)構(gòu)如下:
3.2 hash-hashtable
hashtable 編碼的哈希對(duì)象使用字典作為底層實(shí)現(xiàn)。字典是一種用于保存鍵值對(duì)的數(shù)據(jù)結(jié)構(gòu),Redis 的字典使用哈希表作為底層實(shí)現(xiàn),一個(gè)哈希表里面可以有多個(gè)哈希表節(jié)點(diǎn),每個(gè)哈希表節(jié)點(diǎn)保存的就是一個(gè)鍵值對(duì)。
3.3 哈希表
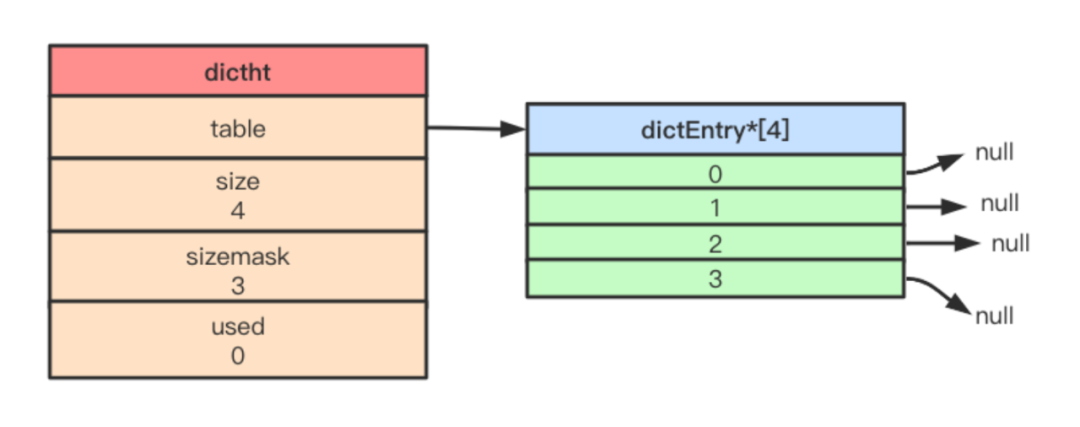
Redis 使用的哈希表由 dictht 結(jié)構(gòu)定義:
typedefstructdictht{ // 哈希表數(shù)組 dictEntry **table;// 哈希表大小unsignedlongsize;// 哈希表大小掩碼,用于計(jì)算索引值// 總是等于 size-1unsignedlongsizemask;// 該哈希表已有節(jié)點(diǎn)數(shù)量unsignedlongused; } dictht
table 屬性是一個(gè)數(shù)組,數(shù)組中的每個(gè)元素都是一個(gè)指向 dictEntry 結(jié)構(gòu)的指針,每個(gè) dictEntry 結(jié)構(gòu)保存著一個(gè)鍵值對(duì)。
size 屬性記錄了哈希表的大小,即 table 數(shù)組的大小。used 屬性記錄了哈希表目前已有節(jié)點(diǎn)數(shù)量。sizemask 總是等于 size-1,這個(gè)值主要用于數(shù)組索引。
比如下圖展示了一個(gè)大小為 4 的空哈希表。
哈希表節(jié)點(diǎn)
哈希表節(jié)點(diǎn)使用 dictEntry 結(jié)構(gòu)表示,每個(gè) dictEntry 結(jié)構(gòu)都保存著一個(gè)鍵值對(duì):
typedefstructdictEntry{ // 鍵void*key;// 值union{ void*val; unit64_tu64; nit64_ts64; } v;// 指向下一個(gè)哈希表節(jié)點(diǎn),形成鏈表structdictEntry* next; } dictEntry;
key 屬性保存著鍵值對(duì)中的鍵,而 v 屬性則保存了鍵值對(duì)中的值。值可以是一個(gè)指針,一個(gè) uint64_t 整數(shù)或者是 int64_t 整數(shù)。next 屬性指向了另一個(gè) dictEntry 節(jié)點(diǎn),在數(shù)組桶位相同的情況下,將多個(gè) dictEntry 節(jié)點(diǎn)串聯(lián)成一個(gè)鏈表,以此來(lái)解決鍵沖突問(wèn)題(鏈地址法)。
3.4 字典
Redis 字典由 dict 結(jié)構(gòu)表示:
typedefstructdict{ // 類(lèi)型特定函數(shù)dictType *type;// 私有數(shù)據(jù)void*privdata;// 哈希表dictht ht[ 2];//rehash索引// 當(dāng)rehash不在進(jìn)行時(shí),值為-1intrehashidx; }
ht 是大小為 2,且每個(gè)元素都指向 dictht 哈希表。一般情況下,字典只會(huì)使用 ht[0] 哈希表,ht[1] 哈希表只會(huì)在對(duì) ht[0] 哈希表進(jìn)行 rehash 時(shí)使用。rehashidx 記錄了 rehash 的進(jìn)度,如果目前沒(méi)有進(jìn)行 rehash,值為 -1。
rehash
為了使 hash 表的負(fù)載因子 (ht[0]).used/ht[0]).size) 維持在一個(gè)合理范圍,當(dāng)哈希表保存的元素過(guò)多或者過(guò)少時(shí),程序需要對(duì) hash 表進(jìn)行相應(yīng)的擴(kuò)展和收縮。
rehash(重新散列)操作就是用來(lái)完成 hash 表的擴(kuò)展和收縮的。
rehash 的步驟如下:
1. 為 ht [1] 哈希表分配空間;
如果是 擴(kuò)展操作 ,那么 ht[1] 的大小為第一個(gè)大于 ht[0].used*2的2n。比如ht[0].used=5,那么此時(shí) ht[1] 的大小就為 16(大于 10 的第一個(gè) 2n 的值是 16);
如果是 收縮操作 ,那么 ht[1] 的大小為第一個(gè)大于 ht[0].used 的 2n。比如ht[0].used=5,那么此時(shí) ht[1] 的大小就為 8(大于 5 的第一個(gè) 2n 的值是 8)。
2. 將保存在 ht[0] 中的所有鍵值對(duì) rehash 到 ht[1] 中;
3. 遷移完成之后,釋放掉 ht[0],并將現(xiàn)在的 ht[1] 設(shè)置為 ht[0],在 ht[1] 新創(chuàng)建一個(gè)空白哈希表,為下一次 rehash 做準(zhǔn)備。
哈希表的擴(kuò)展和收縮時(shí)機(jī)
當(dāng)服務(wù)器沒(méi)有執(zhí)行 BGSAVE 或者 BGREWRITEAOF 命令時(shí),負(fù)載因子大于等于 1 觸發(fā)哈希表的擴(kuò)展操作;
當(dāng)服務(wù)器在執(zhí)行 BGSAVE 或者 BGREWRITEAOF 命令,負(fù)載因子大于等于 5 觸發(fā)哈希表的擴(kuò)展操作;
當(dāng)哈希表負(fù)載因子小于 0.1,觸發(fā)哈希表的收縮操作。
漸進(jìn)式 rehash
前面講過(guò),擴(kuò)展或者收縮需要將 ht[0] 里面的元素全部 rehash 到 ht[1] 中,如果 ht[0] 元素很多,顯然一次性 rehash 成本會(huì)很大,從影響到 Redis 性能。
為了解決上述問(wèn)題,Redis 使用了漸進(jìn)式 rehash 技術(shù),具體來(lái)說(shuō)就是分多次,漸進(jìn)式地將 ht[0] 里面的元素慢慢地 rehash 到 ht[1] 中。
下面是漸進(jìn)式 rehash 的詳細(xì)步驟:
為 ht[1] 分配空間;
在字典中維持一個(gè)索引計(jì)數(shù)器變量 rehashidx,并將它的值設(shè)置為 0,表示 rehash 正式開(kāi)始;
在 rehash 進(jìn)行期間,每次對(duì)字典執(zhí)行添加、刪除、查找或者更新時(shí),除了會(huì)執(zhí)行相應(yīng)的操作之外,還會(huì)順帶將 ht[0] 在 rehashidx 索引位上的所有鍵值對(duì) rehash 到 ht[1] 中,rehash 完成之后,rehashidx 值加 1;
隨著字典操作的不斷進(jìn)行,最終會(huì)在啊某個(gè)時(shí)刻遷移完成,此時(shí)將 rehashidx 值置為 -1,表示 rehash 結(jié)束。
漸進(jìn)式 rehash 一次遷移一個(gè)桶上所有的數(shù)據(jù)。設(shè)計(jì)上采用 分而治之的思想, 將原本集中式的操作分散到每個(gè)添加、刪除、查找和更新操作上,從而避免集中式 rehash 帶來(lái)的龐大計(jì)算。
因?yàn)樵跐u進(jìn)式 rehash 時(shí),字典會(huì)同時(shí)使用 ht[0] 和 ht[1] 兩張表,所以此時(shí)對(duì)字典的刪除、查找和更新操作都可能會(huì)在兩個(gè)哈希表進(jìn)行。比如,如果要查找某個(gè)鍵時(shí),先在 ht[0] 中查找,如果沒(méi)找到,則繼續(xù)到 ht[1] 中查找。
hash 對(duì)象中的 hashtable
HSETprofile name "tom"HSET profile age 25HSET profile career "Programmer"還是上述三條命令,保存數(shù)據(jù)到 Redis 的哈希對(duì)象中,如果采用 hashtable 編碼保存的話(huà),那么該 Hash 對(duì)象在內(nèi)存中的結(jié)構(gòu)如下:
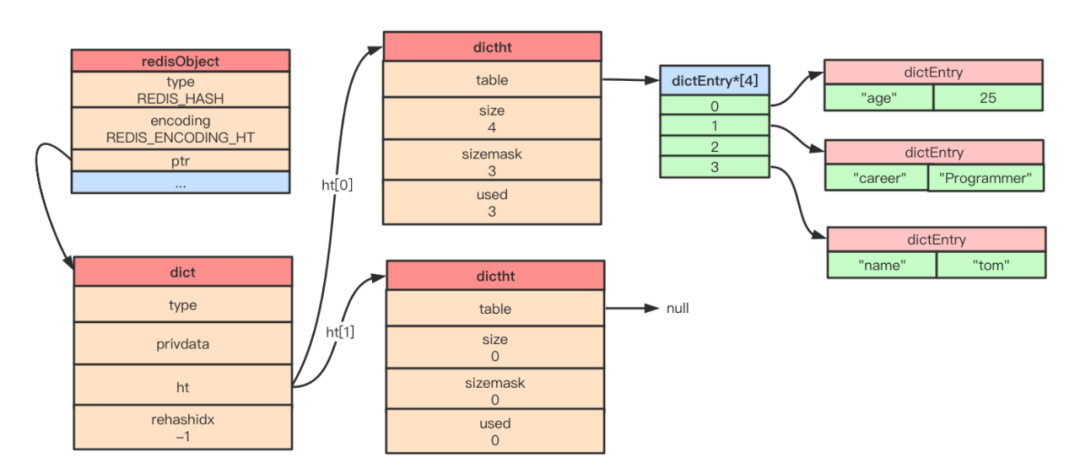
當(dāng)哈希對(duì)象保存的所有鍵值對(duì)的鍵和值的字符串長(zhǎng)度都小于 64 個(gè)字節(jié),并且數(shù)量小于 512 個(gè)時(shí),使用 ziplist 編碼,否則使用 hashtable 編碼。
可以通過(guò)配置文件修改該上限值。
4. 集合對(duì)象
集合對(duì)象的編碼可以是 intset 或者 hashtable。當(dāng)集合對(duì)象保存的元素都是整數(shù),并且個(gè)數(shù)不超過(guò) 512 個(gè)時(shí),使用 intset 編碼,否則使用 hashtable 編碼。
4.1 set-intset
intset 編碼的集合對(duì)象底層使用整數(shù)集合實(shí)現(xiàn)。
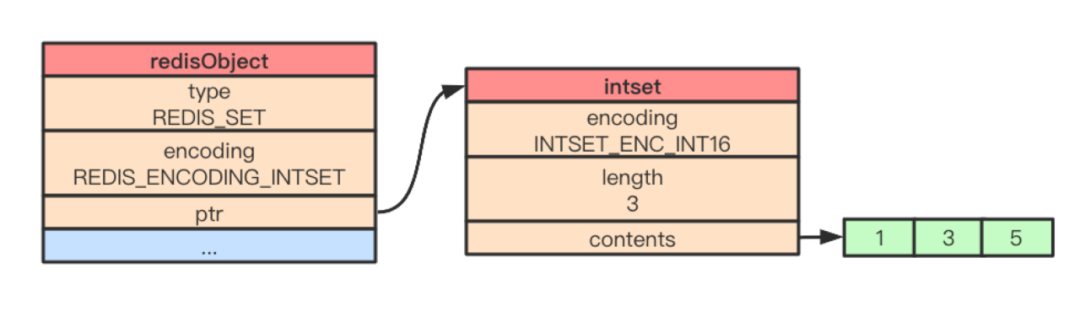
整數(shù)集合(intset)是 Redis 用于保存整數(shù)值的集合抽象數(shù)據(jù)結(jié)構(gòu),它可以保存類(lèi)型為 int16_t、int32_t 或者 int64_t 的整數(shù)值,并且保證集合中的數(shù)據(jù)不會(huì)重復(fù)。Redis 使用 intset 結(jié)構(gòu)表示一個(gè)整數(shù)集合。
typedefstructintset{// 編碼方式uint32_tencoding;// 集合包含的元素?cái)?shù)量uint32_tlength;// 保存元素的數(shù)組int8_tcontents[];} intset;
contents 數(shù)組是整數(shù)集合的底層實(shí)現(xiàn):整數(shù)集合的每個(gè)元素都是 contents 數(shù)組的一個(gè)數(shù)組項(xiàng),各個(gè)項(xiàng)在數(shù)組中按值大小從小到大有序排列,并且數(shù)組中不包含重復(fù)項(xiàng)。
雖然 contents 屬性聲明為 int8_t 類(lèi)型的數(shù)組,但實(shí)際上,contents 數(shù)組不保存任何 int8_t 類(lèi)型的值,數(shù)組中真正保存的值類(lèi)型取決于 encoding。
如果 encoding 屬性值為 INTSET_ENC_INT16,那么 contents 數(shù)組就是 int16_t 類(lèi)型的數(shù)組,以此類(lèi)推。
當(dāng)新插入元素的類(lèi)型比整數(shù)集合現(xiàn)有類(lèi)型元素的類(lèi)型大時(shí),整數(shù)集合必須先升級(jí),然后才能將新元素添加進(jìn)來(lái)。這個(gè)過(guò)程分以下三步進(jìn)行:
根據(jù)新元素類(lèi)型,擴(kuò)展整數(shù)集合底層數(shù)組空間大小;
將底層數(shù)組現(xiàn)有所有元素都轉(zhuǎn)換為與新元素相同的類(lèi)型,并且維持底層數(shù)組的有序性;
將新元素添加到底層數(shù)組里面。
還有一點(diǎn)需要注意的是, 整數(shù)集合不支持降級(jí)。一旦對(duì)數(shù)組進(jìn)行了升級(jí),編碼就會(huì)一直保持升級(jí)后的狀態(tài)。
舉個(gè)例子,當(dāng)執(zhí)行 SADD numbers 1 3 5 向集合對(duì)象插入數(shù)據(jù)時(shí),該集合對(duì)象在內(nèi)存的結(jié)構(gòu)如下:
4.2 set-hashtable
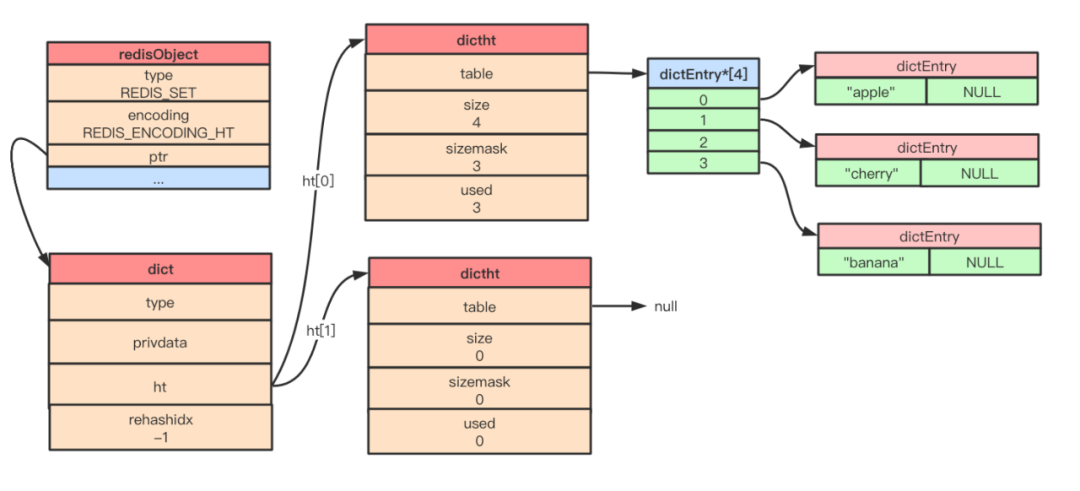
hashtable 編碼的集合對(duì)象使用字典作為底層實(shí)現(xiàn)。字典的每個(gè)鍵都是一個(gè)字符串對(duì)象,每個(gè)字符串對(duì)象對(duì)應(yīng)一個(gè)集合元素,字典的值都是 NULL。
當(dāng)我們執(zhí)行 SADD fruits "apple" "banana" "cherry" 向集合對(duì)象插入數(shù)據(jù)時(shí),該集合對(duì)象在內(nèi)存的結(jié)構(gòu)如下:
5. 有序集合對(duì)象
有序集合的編碼可以是 ziplist 或者 skiplist。當(dāng)有序集合保存的元素個(gè)數(shù)小于 128 個(gè),且所有元素成員長(zhǎng)度都小于 64 字節(jié)時(shí),使用 ziplist 編碼,否則使用 skiplist 編碼。
5.1 zset-ziplist
ziplist 編碼的有序集合使用壓縮列表作為底層實(shí)現(xiàn)。每個(gè)集合元素使用兩個(gè)緊挨著一起的兩個(gè)壓縮列表節(jié)點(diǎn)表示,第一個(gè)節(jié)點(diǎn)保存元素的成員(member),第二個(gè)節(jié)點(diǎn)保存元素的分值(score)。
壓縮列表內(nèi)的集合元素按照分值從小到大排列。如果我們執(zhí)行 ZADD price 8.5 apple 5.0 banana 6.0 cherry 命令向有序集合插入元素,該有序集合在內(nèi)存中的結(jié)構(gòu)如下:

5.2 zset-skiplist
skiplist 編碼的有序集合對(duì)象使用 zset 結(jié)構(gòu)作為底層實(shí)現(xiàn),一個(gè) zset 結(jié)構(gòu)同時(shí)包含一個(gè)字典和一個(gè)跳躍表。
typedefstructzset{ zskiplist *zs1;dict *dict;}繼續(xù)介紹之前,我們先了解一下什么是跳躍表。
跳躍表
跳躍表(skiplist)是一種有序的數(shù)據(jù)結(jié)構(gòu),它通過(guò)在每個(gè)節(jié)點(diǎn)中維持多個(gè)指向其他節(jié)點(diǎn)的指針,從而達(dá)到快速訪(fǎng)問(wèn)節(jié)點(diǎn)的目的。
Redis 的跳躍表由 zskiplistNode 和 zskiplist 兩個(gè)結(jié)構(gòu)定義。zskiplistNode 結(jié)構(gòu)表示跳躍表節(jié)點(diǎn),zskiplist 保存跳躍表節(jié)點(diǎn)相關(guān)信息,比如節(jié)點(diǎn)的數(shù)量,以及指向表頭和表尾節(jié)點(diǎn)的指針等。
跳躍表節(jié)點(diǎn) zskiplistNode
跳躍表節(jié)點(diǎn) zskiplistNode 結(jié)構(gòu)定義如下:
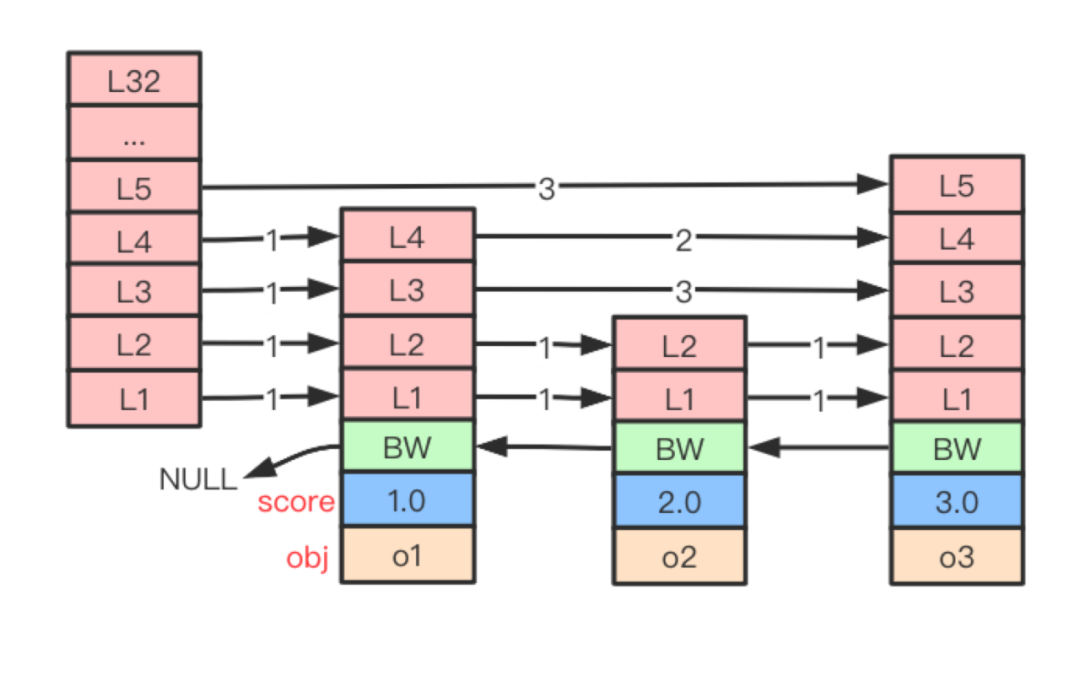
typedefstructzskiplistNode{// 后退指針structzskiplistNode* backward;// 分值doublescore;// 成員對(duì)象robj *obj;// 層structzskiplistLevel{// 前進(jìn)指針structzskiplistNode* forward;// 跨度unsignedintspan;}level[];} zskiplistNode;
下圖是一個(gè)層高為 5,包含 4 個(gè)跳躍表節(jié)點(diǎn)(1 個(gè)表頭節(jié)點(diǎn)和 3 個(gè)數(shù)據(jù)節(jié)點(diǎn))組成的跳躍表:
有序集合對(duì)象的 skiplist 實(shí)現(xiàn)
前面講過(guò),skiplist 編碼的有序集合對(duì)象使用 zset 結(jié)構(gòu)作為底層實(shí)現(xiàn)。一個(gè) zset 結(jié)構(gòu)同時(shí)包含一個(gè)字典和一個(gè)跳躍表。
typedefstructzset{ zskiplist *zs1;dict *dict;}zset 結(jié)構(gòu)中的 zs1 跳躍表按分值從小到大保存了所有集合元素,每個(gè)跳躍表節(jié)點(diǎn)都保存了一個(gè)集合元素。
通過(guò)跳躍表,可以對(duì)有序集合進(jìn)行基于 score 的快速范圍查找。zset 結(jié)構(gòu)中的 dict 字典為有序集合創(chuàng)建了從成員到分值的映射,字典的鍵保存了成員,字典的值保存了分值。通過(guò)字典,可以用 O(1) 復(fù)雜度查找給定成員的分值。
假如還是執(zhí)行 ZADD price 8.5 apple 5.0 banana 6.0 cherry 命令向 zset 保存數(shù)據(jù),如果采用 skiplist 編碼方式的話(huà),該有序集合在內(nèi)存中的結(jié)構(gòu)如下:

6. 總結(jié)
總的來(lái)說(shuō),Redis 底層數(shù)據(jù)結(jié)構(gòu)主要包括簡(jiǎn)單動(dòng)態(tài)字符串(SDS)、鏈表、字典、跳躍表、整數(shù)集合和壓縮列表六種類(lèi)型。并且基于這些基礎(chǔ)數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)了字符串對(duì)象、列表對(duì)象、哈希對(duì)象、集合對(duì)象以及有序集合對(duì)象五種常見(jiàn)的對(duì)象類(lèi)型。每一種對(duì)象類(lèi)型都至少采用了 2 種數(shù)據(jù)編碼,不同的編碼使用的底層數(shù)據(jù)結(jié)構(gòu)也不同。