
你真的會(huì)使用數(shù)據(jù)庫(kù)的索引嗎?
? ? ? ? ? ? ? ? ? ?
摘要:使用索引也很簡(jiǎn)單,然而, 會(huì)使用索引是一回事, 而深入理解索引原理又能恰到好處使用索引又是另一回事。
本文分享自華為云社區(qū)《索引到底能提升多少查詢(xún)效率?何時(shí)該使用索引?一文快速搞懂?dāng)?shù)據(jù)庫(kù)索引及合理使用它》,作者:曲鳥(niǎo)。
一、前言
無(wú)論是面試、還是日常工作中,或多或少都會(huì)使用或者聽(tīng)到別人談?wù)撍饕@個(gè)技術(shù)。
然而很大一部份程序員對(duì)索引的了解僅限于到“加索引能使查詢(xún)變快”這個(gè)概念為止。
使用索引也很簡(jiǎn)單,然而, 會(huì)使用索引是一回事, 而深入理解索引原理又能恰到好處使用索引又是另一回事。
這已經(jīng)是兩個(gè)相差甚遠(yuǎn)的技術(shù)層級(jí)了。
二、千萬(wàn)級(jí)數(shù)據(jù)表索引和無(wú)索引查詢(xún)效率對(duì)比
現(xiàn)在有一個(gè)學(xué)生表student,有1000萬(wàn)條數(shù)據(jù)
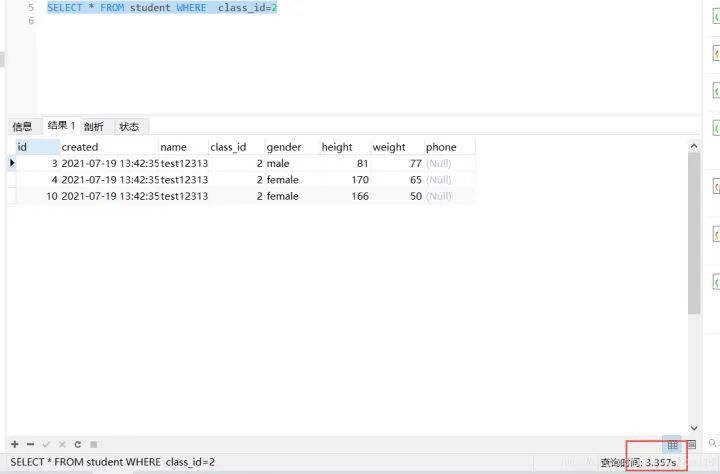
未加索引,查詢(xún)class_id=2的學(xué)生信息的耗時(shí):SELECT * FROM student WHERE class_id=2 花費(fèi)了3.357秒
加上索引,查詢(xún)class_id=2的學(xué)生信息的耗時(shí):SELECT * FROM student WHERE class_id=2 花費(fèi)了0.017秒
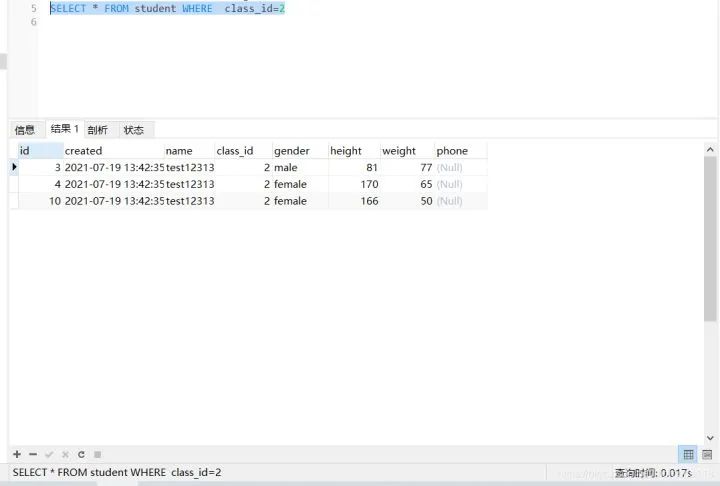
1000萬(wàn)條數(shù)據(jù)下,兩個(gè)查詢(xún)的性能差了近200倍!!
這個(gè)差距是特別大的!難怪需要加索引!!!
三、什么是索引
網(wǎng)上很多講解索引的文章對(duì)索引的描述是這樣的:
索引就像書(shū)的目錄, 通過(guò)書(shū)的目錄就可以準(zhǔn)確的定位到書(shū)籍的具體的內(nèi)容。
這句話概述的非常正確!
但說(shuō)了跟沒(méi)說(shuō)一樣,懂的人自然懂!不懂的人感覺(jué)懂了,但還是一臉蒙的狀態(tài)!
其實(shí)想要理解索引原理,必須清楚一種數(shù)據(jù)結(jié)構(gòu):
平衡樹(shù)」(非二叉),也就是b tree或者 b+ tree
當(dāng)然, 有的數(shù)據(jù)庫(kù)也使用哈希桶作用索引的數(shù)據(jù)結(jié)構(gòu) , 然而, 主流的RDBMS都是把平衡樹(shù)當(dāng)做數(shù)據(jù)表默認(rèn)的索引數(shù)據(jù)結(jié)構(gòu)的。
我們平時(shí)建表的時(shí)候都會(huì)為表加上主鍵, 在某些關(guān)系數(shù)據(jù)庫(kù)中, 如果建表時(shí)不指定主鍵,數(shù)據(jù)庫(kù)會(huì)拒絕建表的語(yǔ)句執(zhí)行。
事實(shí)上, 一個(gè)加了主鍵的表,并不能被稱(chēng)之為“表”。一個(gè)沒(méi)加主鍵的表,它的數(shù)據(jù)無(wú)序的放置在磁盤(pán)存儲(chǔ)器上,一行一行的排列的很整齊。如果給表上了主鍵,那么表在磁盤(pán)上的存儲(chǔ)結(jié)構(gòu)就由整齊排列的結(jié)構(gòu)轉(zhuǎn)變成了樹(shù)狀結(jié)構(gòu),也就是上面說(shuō)的“平衡樹(shù)”結(jié)構(gòu),換句話說(shuō),就是整個(gè)表就變成了一個(gè)索引。
沒(méi)錯(cuò), 再說(shuō)一遍, 整個(gè)表變成了一個(gè)索引!
也就是所謂的“聚集索引”。這就是為什么一個(gè)表只能有一個(gè)主鍵, 一個(gè)表只能有一個(gè)“聚集索引”,因?yàn)橹麈I的作用就是把“表”的數(shù)據(jù)格式轉(zhuǎn)換成“樹(shù)(索引)”的格式。
未加索引時(shí),之前執(zhí)行的查詢(xún)sql會(huì)讓數(shù)據(jù)庫(kù)系統(tǒng)逐行的遍歷整張表,對(duì)于每一行都要檢查其class_id字段是否等于“2”。因?yàn)槲覀円檎宜衏lass_id為“2”的員工,所以當(dāng)我們發(fā)現(xiàn)了一條class_id是“2”的記錄后,并不能停止繼續(xù)查找,因?yàn)榭赡苓€有class_id等于“2”的其他記錄。
這就意味著,對(duì)于表中的千萬(wàn)條記錄,數(shù)據(jù)庫(kù)每一條都要檢查。這就是所謂的“全表掃描”( full table scan)
而加上索引的最大作用就是加快查詢(xún)速度,它能從根本上減少需要掃表的記錄/行的數(shù)量。
四、Mysql中的索引
在MySQL中, 索引有兩種分類(lèi)方式:邏輯分類(lèi)和物理分類(lèi)。
按照邏輯分類(lèi),索引可分為:
主鍵索引:一張表只能有一個(gè)主鍵索引,不允許重復(fù)、不允許為 NULL;
唯一索引:數(shù)據(jù)列不允許重復(fù),允許為 NULL 值,一張表可有多個(gè)唯一索引,但是一個(gè)唯一索引只能包含一列,比如身份證號(hào)碼、卡號(hào)等都可以作為唯一索引;
普通索引:一張表可以創(chuàng)建多個(gè)普通索引,一個(gè)普通索引可以包含多個(gè)字段,允許數(shù)據(jù)重復(fù),允許 NULL 值插入;
全文索引:讓搜索關(guān)鍵詞更高效的一種索引。
按照物理分類(lèi),索引可分為:
聚集索引:一般是表中的主鍵索引,如果表中沒(méi)有顯示指定主鍵,則會(huì)選擇表中的第一個(gè)不允許為 NULL 的唯一索引,如果還是沒(méi)有的話,就采用 Innodb 存儲(chǔ)引擎為每行數(shù)據(jù)內(nèi)置的 6 字節(jié) ROWID 作為聚集索引。每張表只有一個(gè)聚集索引,因?yàn)榫奂饕逆I值的邏輯順序決定了表中相應(yīng)行的物理順序。聚集索引在精確查找和范圍查找方面有良好的性能表現(xiàn)(相比于普通索引和全表掃描),聚集索引就顯得彌足珍貴,聚集索引選擇還是要慎重的(一般不會(huì)讓沒(méi)有語(yǔ)義的自增 id 充當(dāng)聚集索引);
非聚集索引:該索引中索引的邏輯順序與磁盤(pán)上行的物理存儲(chǔ)順序不同(非主鍵的那一列),一個(gè)表中可以擁有多個(gè)非聚集索引。
在目前用的最多的mysql的InnoDB存儲(chǔ)引擎中,是使用B+Tree索引方法來(lái)進(jìn)行索引建立的。
B+樹(shù)索引是B+樹(shù)在數(shù)據(jù)庫(kù)中的一種實(shí)現(xiàn),是最常見(jiàn)也是數(shù)據(jù)庫(kù)中使用最為頻繁的一種索引。
B+樹(shù)中的B代表平衡(balance),而不是二叉(binary),因?yàn)锽+樹(shù)是從最早的平衡二叉樹(shù)演化而來(lái)的。先了解二叉查找樹(shù)、平衡二叉樹(shù)(AVLTree)和平衡多路查找樹(shù)(B-Tree),B+樹(shù)即由這些樹(shù)逐步優(yōu)化而來(lái)。
具體的講解可參考:https://www.cnblogs.com/wuzhenzhao/p/10341114.html 該博客。
五、索引的優(yōu)缺點(diǎn)
優(yōu)點(diǎn):
1、索引能夠提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫(kù)的IO成本。
2、通過(guò)創(chuàng)建唯一性索引,可以保證數(shù)據(jù)庫(kù)表中每一行數(shù)據(jù)的唯一性,創(chuàng)建唯一索引
3、在使用分組和排序子句進(jìn)行數(shù)據(jù)檢索時(shí),同樣可以顯著減少查詢(xún)中分組和排序的時(shí)間
4、加速兩個(gè)表之間的連接,一般是在外鍵上創(chuàng)建索引
缺點(diǎn):
1、創(chuàng)建索引和維護(hù)索引要耗費(fèi)時(shí)間,這種時(shí)間隨著數(shù)據(jù)量的增加而增加
2、索引需要占物理空間,除了數(shù)據(jù)表占數(shù)據(jù)空間之外,每一個(gè)索引還要占一定的物理空間,如果要建立聚簇索引,那么需要的空間就會(huì)更大
3、當(dāng)對(duì)表中的數(shù)據(jù)進(jìn)行增加、刪除和修改的時(shí)候,索引也要?jiǎng)討B(tài)的維護(hù),降低了數(shù)據(jù)的維護(hù)速度
六、索引何時(shí)應(yīng)該使用
需創(chuàng)建索引的情況:
1.主鍵,自動(dòng)建立唯一索引
2.頻繁作為查詢(xún)的條件的字段
3.查詢(xún)中與其他表關(guān)聯(lián)的字段存在外鍵關(guān)系
4.查詢(xún)中排序的字段,排序字段若通過(guò)索引去訪問(wèn)將大大提高排序的速度
5.查詢(xún)中統(tǒng)計(jì)或者分組字段
避免創(chuàng)建索引的情況:
1.數(shù)據(jù)唯一性差的字段不要使用索引
比如性別,只有兩種可能數(shù)據(jù)。意味著索引的二叉樹(shù)級(jí)別少,多是平級(jí)。這樣的二叉樹(shù)查找無(wú)異于全表掃描。
2.頻繁更新的字段不要使用索引
比如登錄次數(shù),頻繁變化導(dǎo)致索引也頻繁變化,增大數(shù)據(jù)庫(kù)工作量,降低效率。
3.字段不在where語(yǔ)句出現(xiàn)時(shí)不要添加索引
只有在where語(yǔ)句出現(xiàn),mysql才會(huì)去使用索引
4.數(shù)據(jù)量少的表不要使用索引
使用了改善也不大
七、哪些sql能命中索引
1.前導(dǎo)模糊查詢(xún)不能使用索引, 如name like ‘%濤’
2、Union、in、or可以命中索引,建議使用in。
3、負(fù)條件查詢(xún)不能使用索引,可以?xún)?yōu)化為in查詢(xún),其中負(fù)條件有!=、<>、not in、not exists、not like等
4、聯(lián)合索引最左前綴原則,又叫最左側(cè)查詢(xún),如果在(a,b,c)三個(gè)字段上建立聯(lián)合索引,那么它能夠加快a|(a,b)|(a,b,c)三組的查詢(xún)速度。
5、建立聯(lián)合查詢(xún)時(shí),區(qū)分度最高的字段在最左邊
6、如果建立了(a,b)聯(lián)合索引,就不必再單獨(dú)建立a索引。同理,如果建立了(a,b,c)索引就不必再建立a,(a,b)索引
7、存在非等號(hào)和等號(hào)混合判斷條件時(shí),在建索引時(shí),要把等號(hào)條件的列前置
8、范圍列可以用到索引,但是范圍列后面的列無(wú)法用到索引。
索引最多用于一個(gè)范圍列,如果查詢(xún)條件中有兩個(gè)范圍列則無(wú)法全用到索引。范圍條件有:<、<=、>、>=、between等。
9、把計(jì)算放到業(yè)務(wù)層而不是數(shù)據(jù)庫(kù)層。在字段上計(jì)算不能命中索引,
10、強(qiáng)制類(lèi)型轉(zhuǎn)換會(huì)全表掃描,
如果phone字段是varcher類(lèi)型,則下面的SQL不能命中索引。Select * fromuser where phone=13800001234
11、更新十分頻繁、數(shù)據(jù)區(qū)分度不高的字段上不宜建立索引。
更新會(huì)變更B+樹(shù),更新頻繁的字段建立索引會(huì)大大降低數(shù)據(jù)庫(kù)性能。
“性別”這種區(qū)分度不太大的屬性,建立索引是沒(méi)有什么意義的,不能有效過(guò)濾數(shù)據(jù),性能與全表掃描類(lèi)似。
一般區(qū)分度在80%以上就可以建立索引。區(qū)分度可以使用count(distinct(列名))/count(*)來(lái)計(jì)算。
12、利用覆蓋索引來(lái)進(jìn)行查詢(xún)操作,避免回表。
被查詢(xún)的列,數(shù)據(jù)能從索引中取得,而不是通過(guò)定位符row-locator再到row上獲取,即“被查詢(xún)列要被所建的索引覆蓋”,這能夠加速度查詢(xún)。
13、建立索引的列不能為null,使用not null約束及默認(rèn)值
14、利用延遲關(guān)聯(lián)或者子查詢(xún)優(yōu)化超多分頁(yè)場(chǎng)景,
MySQL并不是跳過(guò)offset行,而是取offset+N行,然后放棄前offset行,返回N行,那當(dāng)offset特別大的時(shí)候,效率非常低下,要么控制返回的總數(shù),要么對(duì)超過(guò)特定閾值的頁(yè)進(jìn)行SQL改寫(xiě)。
15、業(yè)務(wù)上唯一特性的字段,即使是多個(gè)字段的組合,也必須建成唯一索引。
16、超過(guò)三個(gè)表最好不要用join,需要join的字段,數(shù)據(jù)類(lèi)型必須一致,多表關(guān)聯(lián)查詢(xún)時(shí),保證被關(guān)聯(lián)的字段需要有索引。
17、如果明確知道查詢(xún)結(jié)果只要一條,limit 1能夠提高效率,比如驗(yàn)證登錄的時(shí)候。
18、Select語(yǔ)句務(wù)必指明字段名稱(chēng)
19、如果排序字段沒(méi)有用到索引,就盡量少排序
20、盡量用union all 代替 union。Union需要將集合合并后在進(jìn)行唯一性過(guò)濾操作,這會(huì)涉及到排序,大量的cpu運(yùn)算,加大資源消耗及延遲,當(dāng)然,使用union all的前提條件是兩個(gè)結(jié)果集沒(méi)有重復(fù)數(shù)據(jù)。
八、總結(jié)
索引是非常重要的技術(shù)!
但每建立一個(gè)索引,實(shí)際上都需要在硬盤(pán)上開(kāi)辟一塊空間用于存儲(chǔ)這個(gè)索引所需要的數(shù)據(jù)結(jié)構(gòu)(雖然表述不太準(zhǔn)確但是是這個(gè)意思),因此不建議對(duì)太長(zhǎng)的字段建立索引。
而且建立的索引并不是越多越好,因?yàn)樗饕m然能夠提高查詢(xún)效率,但是會(huì)大大得影響插入、刪除和修改的效率,因?yàn)槊恳淮螖?shù)據(jù)的更新都會(huì)牽涉到對(duì)索引的修改。
綜上所述,往往在對(duì)于大量數(shù)據(jù)的插入的情況的時(shí)候,我們需要先刪除掉數(shù)據(jù)表的索引,等插入完畢后重新建立索引,這樣才能最大限度地保證數(shù)據(jù)庫(kù)的效率!
? ? ? ? ? ? ? ?
end
*版權(quán)聲明:轉(zhuǎn)載文章和圖片均來(lái)自公開(kāi)網(wǎng)絡(luò),版權(quán)歸作者本人所有,推送文章除非無(wú)法確認(rèn),我們都會(huì)注明作者和來(lái)源。如果出處有誤或侵犯到原作者權(quán)益,請(qǐng)與我們聯(lián)系刪除或授權(quán)事宜。
長(zhǎng)按識(shí)別圖中二維碼
關(guān)注獲取更多資訊
不點(diǎn)關(guān)注,我們哪來(lái)故事?

點(diǎn)個(gè)再看,你最好看