語音識別技術(shù)概述
Author:louwill
From:深度學習筆記
概述
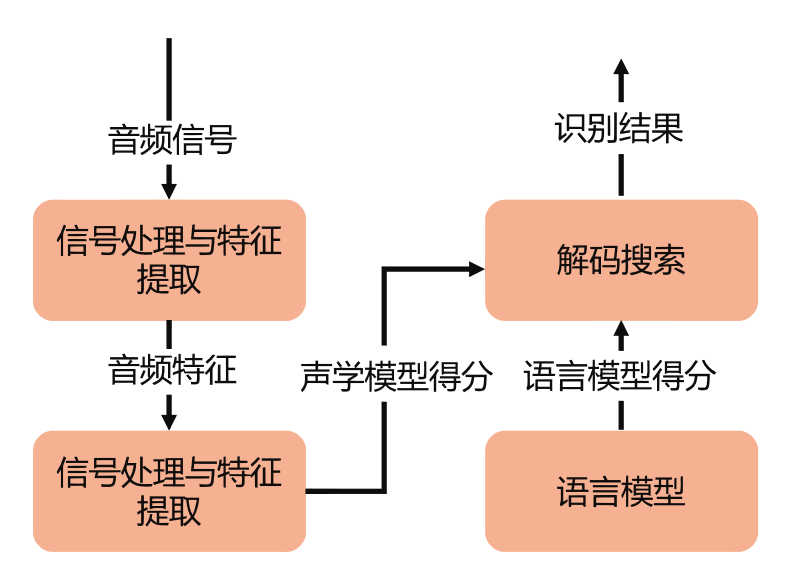

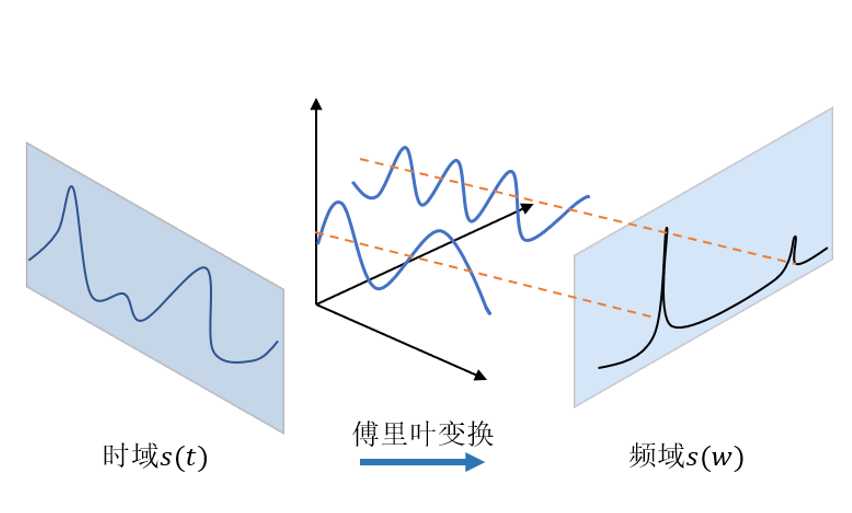
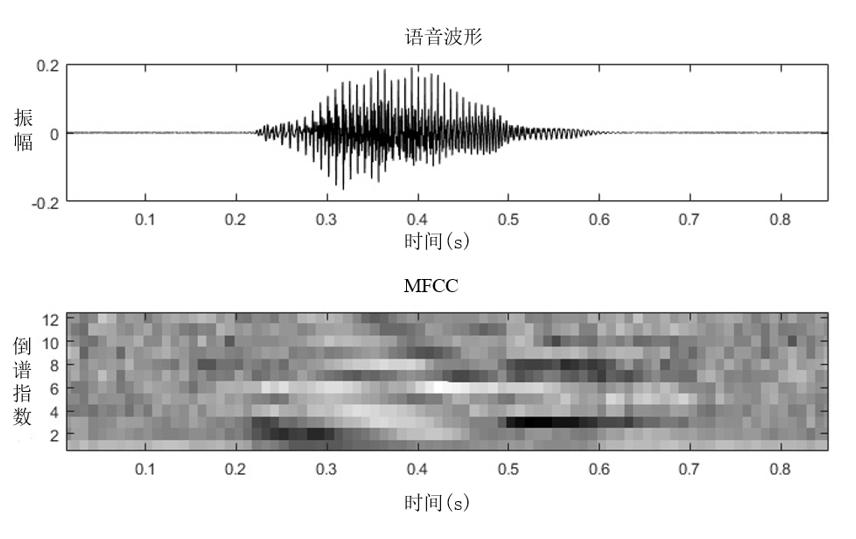
信號處理與特征提取
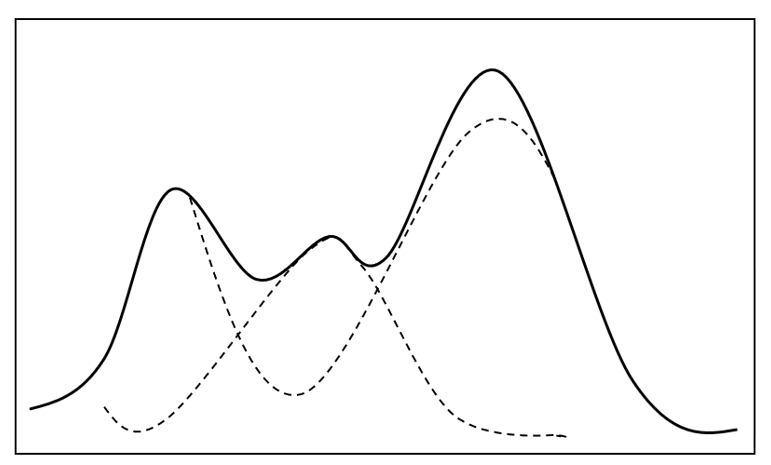
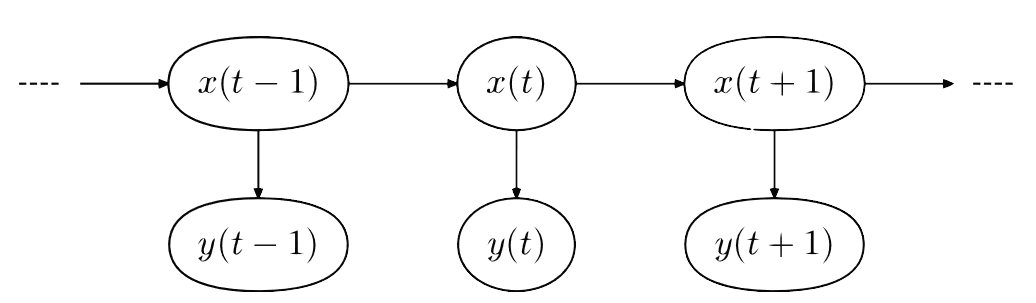
傳統(tǒng)聲學模型
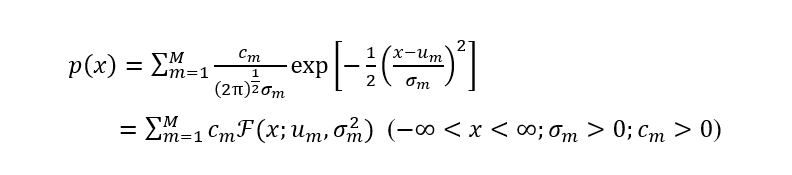
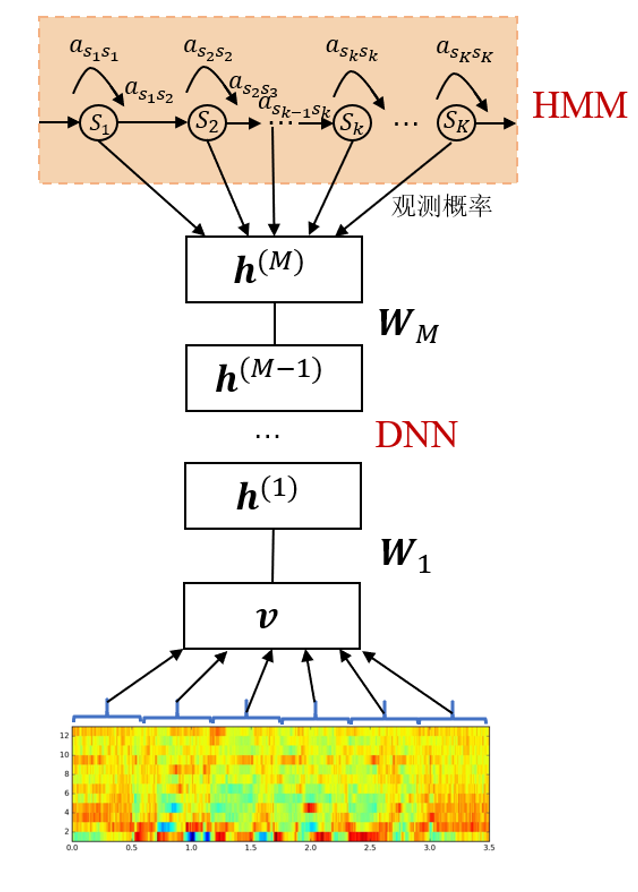
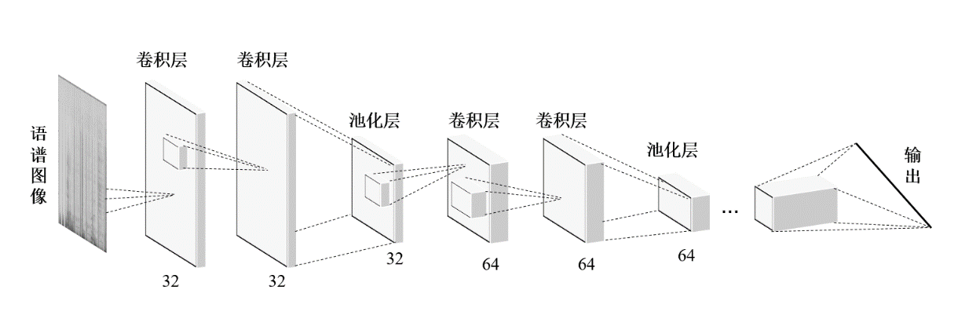
基于深度學習的聲學模型
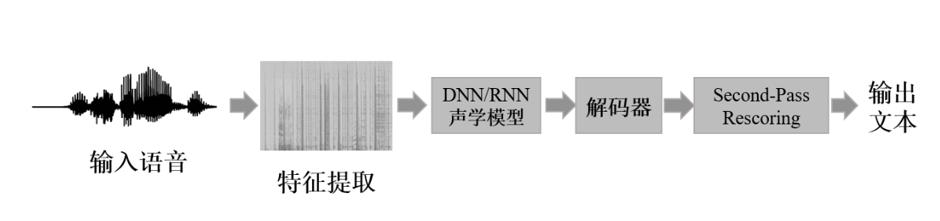
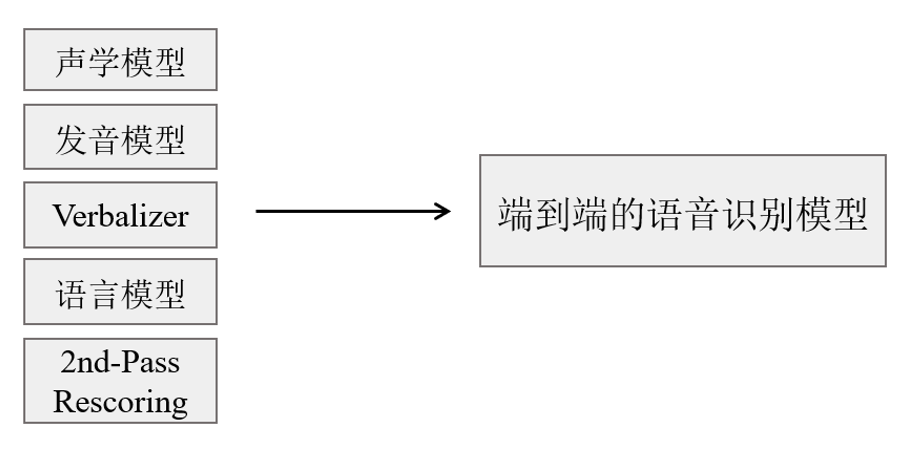
端到端的語音識別系統(tǒng)簡介
往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf

喜歡您就點個在看!
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APPAuthor:louwill
From:深度學習筆記
往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf
<b id="afajh"><abbr id="afajh"></abbr></b>