
我發(fā)現(xiàn)了pandas的黃金搭檔!
?本文示例代碼及文件已上傳至我的
?Github倉庫https://github.com/CNFeffery/DataScienceStudyNotes
1 簡介
pandas發(fā)展了如此多年,所包含的功能已經(jīng)覆蓋了大部分數(shù)據(jù)清洗、分析場景,但仍然有著相當一部分的應(yīng)用場景pandas中尚存空白亦或是現(xiàn)階段的操作方式不夠簡潔方便。
今天我要給大家介紹的Python庫pyjanitor就內(nèi)置了諸多功能方法,可以在兼容pandas中數(shù)據(jù)框等數(shù)據(jù)結(jié)構(gòu)的同時為pandas補充更多功能。它是對R中著名的數(shù)據(jù)清洗包janitor的移植,就如同它的名字那樣,幫助我們完成數(shù)據(jù)處理的清潔工作:

2 pyjanitor中的常用功能
對于使用conda的朋友,推薦使用下列命令完成pyjanitor的安裝,其中使用到上海交大的conda-forge鏡像:
conda?install?pyjanitor?-c?https://mirrors.sjtug.sjtu.edu.cn/anaconda/cloud/conda-forge?-y
完成安裝后import janitor即可進行導(dǎo)入,接著我們就可以直接在pandas的代碼邏輯中穿插pyjanitor的各種API接口。
pyjanitor中的很多功能實際上跟pandas中的一些功能存在重疊,作為一位pandas老手,這部分功能費老師我還是傾向于使用pandas完成,因此下面我只給大家介紹一些pyjanitor中頗具特色的功能:
2.1 利用also()方法穿插執(zhí)行任意函數(shù)
熟悉pandas鏈式寫法的朋友應(yīng)該知道這種寫法對于處理數(shù)據(jù)和理清步驟有多高效,pyjanitor中的also()方法允許我們在鏈式過程中隨意插入執(zhí)行任意函數(shù),接受上一步狀態(tài)的數(shù)據(jù)框運算結(jié)果,且不影響對下一步處理邏輯的數(shù)據(jù)輸入,我非常喜歡這個功能,下面是一個簡單的例子:
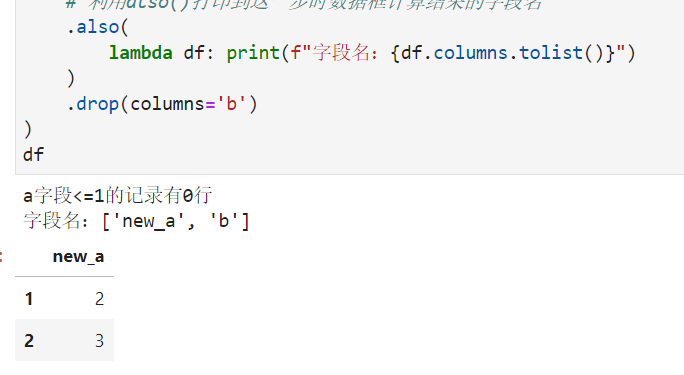
df?=?(
????#?構(gòu)造示例數(shù)據(jù)框
????pd.DataFrame({"a":?[1,?2,?3],?"b":?list("abc")})
????.query("a?>?1")
????#?利用also()插入lambda函數(shù)接受上一步的輸入對象
????.also(lambda?df:?print(f"a字段<=1的記錄有{df.query('a?<=?1').shape[0]}行"))
????.rename(columns={'a':?'new_a'})
????#?利用also()實現(xiàn)中間計算結(jié)果的導(dǎo)出
????.also(lambda?df:?df.to_csv("temp.csv",?index=False))
????#?利用also()打印到這一步時數(shù)據(jù)框計算結(jié)果的字段名
????.also(
????????lambda?df:?print(f"字段名:{df.columns.tolist()}")
????)
????.drop(columns='b')
)
df
2.2 利用case_when()方法實現(xiàn)多條件分支
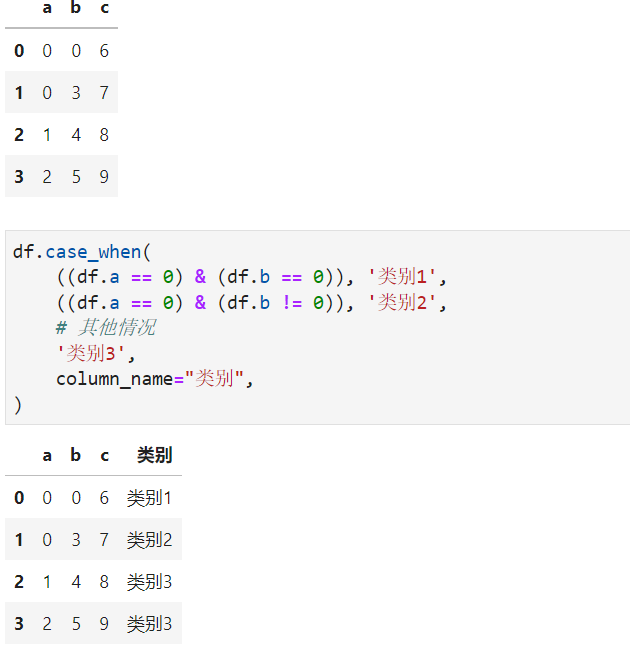
pyjanitor中的case_when()方法可以幫助我們針對數(shù)據(jù)框?qū)崿F(xiàn)類似SQL中的的多條件分支運算,注意,因為是多條件分支,所以包含最后的“其他”條件在內(nèi),需要至少定義3條分支規(guī)則,參考下面的例子:
df?=?pd.DataFrame(
????{
????????"a":?[0,?0,?1,?2],
????????"b":?[0,?3,?4,?5],
????????"c":?[6,?7,?8,?9],
????}
)
df.case_when(
????((df.a?==?0)?&?(df.b?==?0)),?'類別1',
????((df.a?==?0)?&?(df.b?!=?0)),?'類別2',
????#?其他情況
????'類別3',
????column_name="類別",
)
2.3 利用conditional_join()實現(xiàn)條件連接
pyjanitor中的conditional_join()非常地好用,它彌補了pandas一直以來都未完善的“條件連接”功能,即我們對兩張表進行「連接」的條件,不只pandas中的merge()、join()之類的方法所實現(xiàn)的,左表與右表的指定字段之間相等這樣簡單的條件判斷,而是可高度自定義的條件判斷。
conditional_join()在作為方法使用時,其第一個參數(shù)應(yīng)傳入連接中的「右表」數(shù)據(jù)框,緊接著的是若干個格式為(左表字段, 右表字段, 判斷條件)這樣的三元組來定義單條或多條條件判斷的「且」組合,之后再用于定義連接方式how參數(shù)。
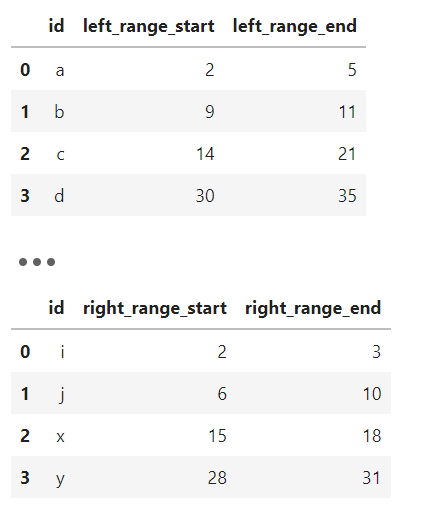
下面是一個示例,這里我們實現(xiàn)生信中常見的一種數(shù)據(jù)分析操作,左表和右表各自定義了一些區(qū)間段,我們利用條件連接來為左表找到右表中完全被其包住的區(qū)間:
#?定義示例左表
df_left?=?pd.DataFrame({
????'id':?list('abcd'),
????'left_range_start':?[2,?9,?14,?30],
????'left_range_end':?[5,?11,?21,?35]
})
#?定義示例右表
df_right?=?pd.DataFrame({
????'id':?list('ijxy'),
????'right_range_start':?[2,?6,?15,?28],
????'right_range_end':?[3,?10,?18,?31]
})
進行條件連接:
(
????df_left
????.conditional_join(
????????df_right,
????????#?滿足left_range_start?<=?right_range_start
????????('left_range_start',?'right_range_start',?'<='),
????????#?且滿足left_range_end?>=?right_range_end
????????('left_range_end',?'right_range_end',?'>=')
????)
)
連接結(jié)果如下:

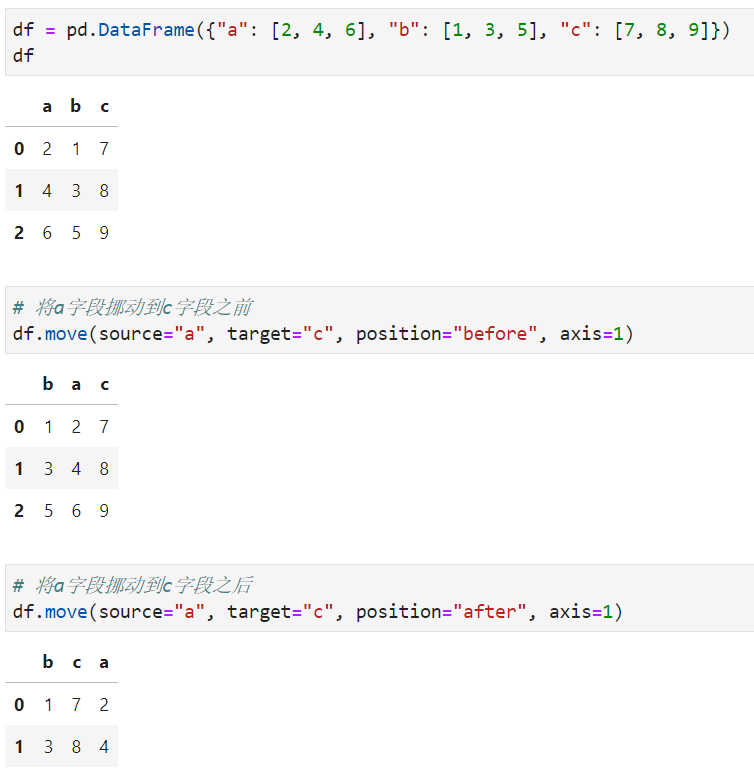
2.4 利用move()方法快捷完成字段位置調(diào)整
pyjanitor中的move()方法用于快捷調(diào)整某行或某列數(shù)據(jù)的位置,通過source參數(shù)指定需要移動的數(shù)據(jù)行index或列的字段名,target參數(shù)用于指定移動的目標位置數(shù)據(jù)行index或列的字段名,position用于設(shè)置移動方式('before'表示移動到目標之前一個位置,after表示后一個位置),axis用于設(shè)定移動方式(0表示行移動,1表示列移動)。
以最常用的列移動為例:
而除了上述這些頗具特色的功能外,pyjanitor中還針對生信、化學(xué)、金融、機器學(xué)習、數(shù)學(xué)等領(lǐng)域內(nèi)置了一些特別的功能,感興趣的朋友可以前往其官網(wǎng)https://pyjanitor-devs.github.io/pyjanitor/進一步了解相關(guān)內(nèi)容。
以上就是本文的全部內(nèi)容,歡迎在評論區(qū)與我進行討論~
END
推薦閱讀
牛逼!Python常用數(shù)據(jù)類型的基本操作(長文系列第①篇)
牛逼!Python的判斷、循環(huán)和各種表達式(長文系列第②篇)