
再見,Excel數(shù)據(jù)透視表;你好,pd.pivot_table
導(dǎo)讀
Excel作為Office常用辦公軟件之一,其在一名數(shù)據(jù)分析師的工作日常中也占有一定地位,比如個(gè)人就常常傾向于依賴Excel完成簡(jiǎn)單的數(shù)據(jù)處理和可視化作圖,其中數(shù)據(jù)處理部分則主要是運(yùn)用內(nèi)置函數(shù)+數(shù)據(jù)透視表兩大部分。
Excel數(shù)據(jù)透視表雖好,但在pandas面前它也有其不香的一面!

選擇Excel菜單欄中插入數(shù)據(jù)透視表選項(xiàng)卡
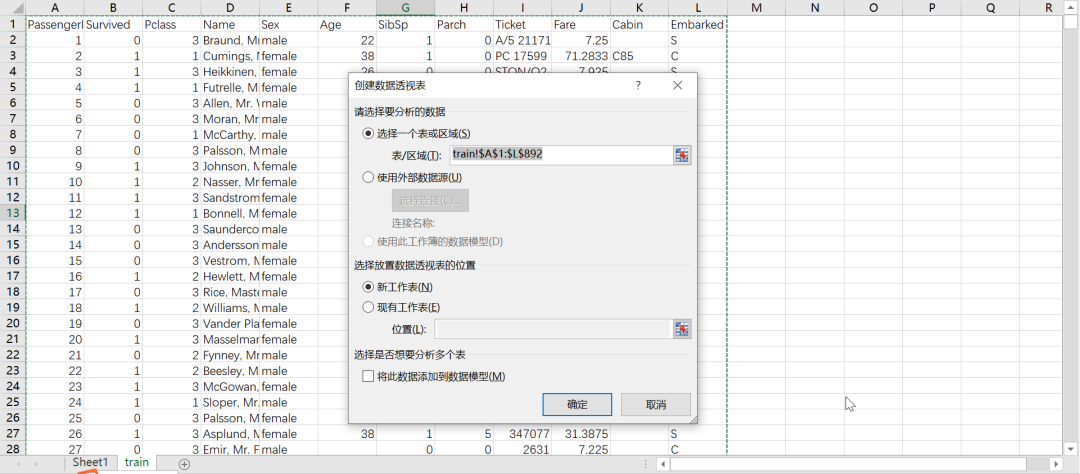
分別拖動(dòng)目標(biāo)字段到相應(yīng)行列位置,設(shè)置統(tǒng)計(jì)函數(shù)為求和
得到統(tǒng)計(jì)好的數(shù)據(jù)透視表結(jié)果
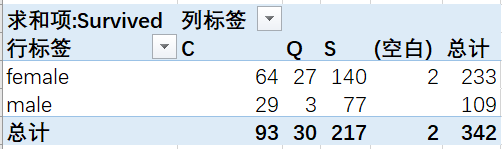
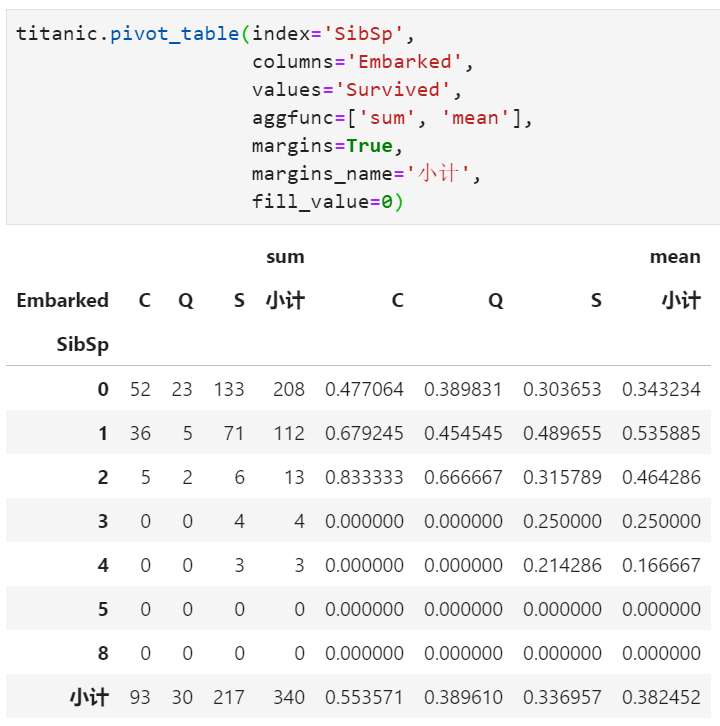
至此,我們可以發(fā)現(xiàn)數(shù)據(jù)透視表中實(shí)際存在4個(gè)重要的設(shè)置項(xiàng):
行字段
列字段
統(tǒng)計(jì)字段
統(tǒng)計(jì)方式(聚合函數(shù))
值得指出的是,以上4個(gè)要素每一個(gè)都可以不唯一,例如可以拖動(dòng)多個(gè)字段到行/列字段中形成二級(jí)索引,也可完成對(duì)不同字段的統(tǒng)計(jì),以及拖動(dòng)相同字段設(shè)置不同統(tǒng)計(jì)方法實(shí)現(xiàn)多種聚合。
values?: 待聚合的列名
index?:?用于放入透視表結(jié)果中的行索引列名
columns?:?用于放入透視表結(jié)果中列索引列名
aggfunc :?聚合統(tǒng)計(jì)函數(shù),可以是單個(gè)函數(shù),也可以是函數(shù)列表,還可以是字典格式,默認(rèn)聚合函數(shù)為均值。當(dāng)該參數(shù)傳入字典格式時(shí),key為列名,value為聚合函數(shù)值,此時(shí)values參數(shù)無(wú)效
fill_value : 缺失值填充值,默認(rèn)為None,即不對(duì)缺失值做任何處理。注意這里的缺失值是指透視后結(jié)果中可能存在的缺失值,而非透視前的原表中缺失值
margins?: 指定是否加入?yún)R總列,布爾值,默認(rèn)為False,體現(xiàn)為Excel透視表中的行小計(jì)和列小計(jì)
margins_name?:?匯總列的列名,與上一個(gè)參數(shù)配套使用,默認(rèn)為'All',當(dāng)margins為False時(shí),該參數(shù)無(wú)作用
dropna :?是否丟棄匯總結(jié)果中全為NaN的行或列,默認(rèn)為True。例如,行有3個(gè)取值,列有3個(gè)取值,經(jīng)過(guò)透視表重組后理論上最多有3×3=9個(gè)結(jié)果,但實(shí)際可能只有3×2=6個(gè)非空值,其中全為空的一列默認(rèn)舍棄
observed : 適用于分類變量,一般無(wú)需關(guān)注。
其中前4個(gè)參數(shù)是核心參數(shù)。
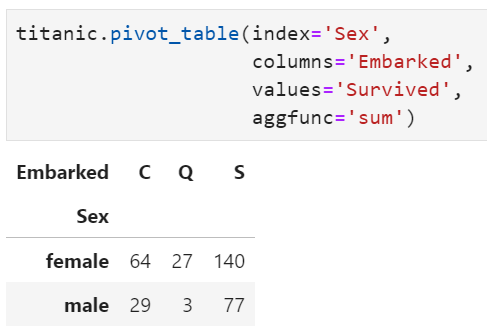
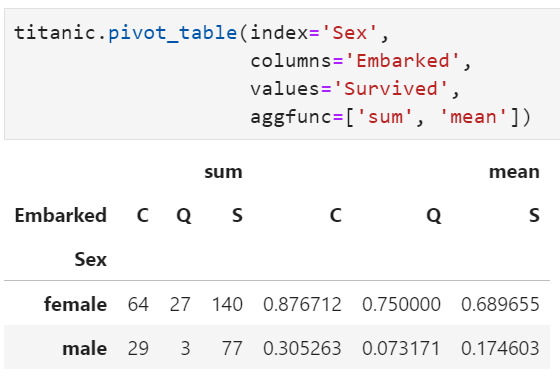
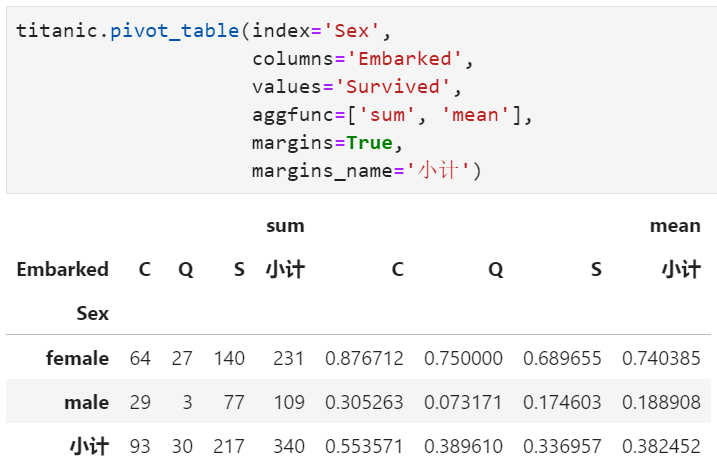
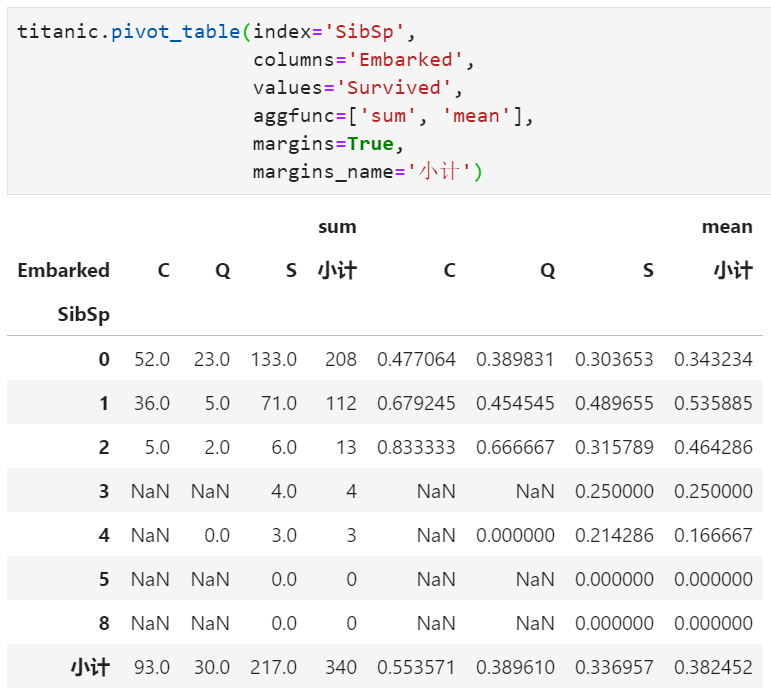
實(shí)際上,上述效果就相當(dāng)于執(zhí)行完pivot_table的基礎(chǔ)上再加一個(gè)fillna()函數(shù)即可。
pivot僅適用于數(shù)據(jù)變形,即由長(zhǎng)表變?yōu)閷挶恚喈?dāng)于對(duì)數(shù)據(jù)進(jìn)行了重組;而pivot_table除了數(shù)據(jù)重組外,還有一個(gè)額外的效果,即數(shù)據(jù)聚合,即若重組后對(duì)應(yīng)的行標(biāo)簽和列標(biāo)簽下取值不唯一,此時(shí)按指定方法進(jìn)行聚合;換言之,pivot能干的事情,pivot_table都能干,反之則不然。
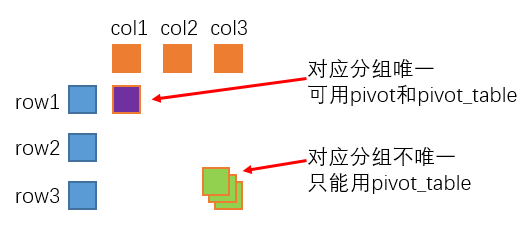
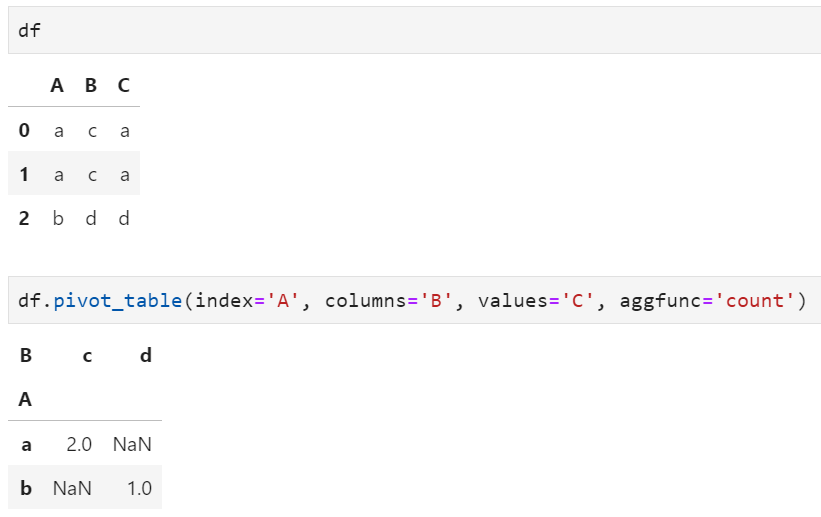
pivot由于僅涉及行列重組和變形,所以一般更適用于分類變量;而pivot_table在重組的基礎(chǔ)上還增加了聚合統(tǒng)計(jì)的過(guò)程,所以一般更適用于數(shù)值型變量,但對(duì)于支持分類變量統(tǒng)計(jì)的聚合函數(shù)(例如count),則pivot_table也可適用。
相關(guān)閱讀: