Zero Shot | 一文了解零樣本學習
點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達


來源|知乎? 作者|恒大大
01

02
03

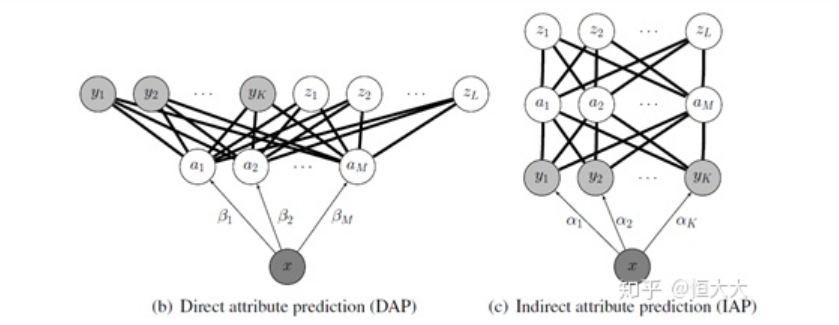
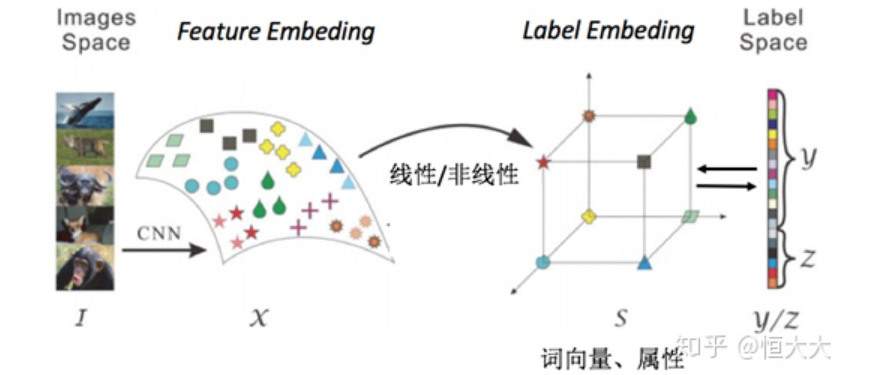
04
05
06
07
推薦閱讀
關于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質量文章,喜歡總結知識,歡迎關注[程序員大白],大家一起學習進步!
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APP點擊上方“程序員大白”,選擇“星標”公眾號
重磅干貨,第一時間送達
來源|知乎? 作者|恒大大
01
02
03
04
05
06
07
推薦閱讀
關于程序員大白
程序員大白是一群哈工大,東北大學,西湖大學和上海交通大學的碩士博士運營維護的號,大家樂于分享高質量文章,喜歡總結知識,歡迎關注[程序員大白],大家一起學習進步!
<b id="afajh"><abbr id="afajh"></abbr></b>