
Hudi 番外 | Apache Hudi:CDC的黃金搭檔
1. 介紹
Apache Hudi是一個(gè)開(kāi)源的數(shù)據(jù)湖框架,旨在簡(jiǎn)化增量數(shù)據(jù)處理和數(shù)據(jù)管道開(kāi)發(fā)。借助Hudi可以在Amazon S3、Aliyun OSS數(shù)據(jù)湖中進(jìn)行記錄級(jí)別管理插入/更新/刪除。AWS EMR集群已支持Hudi組件,并且可以與AWS Glue Data Catalog無(wú)縫集成。此特性可使得直接在Athena或Redshift Spectrum查詢(xún)Hudi數(shù)據(jù)集。
對(duì)于企業(yè)使用AWS云的一種常見(jiàn)數(shù)據(jù)流如圖1所示,即將數(shù)據(jù)實(shí)時(shí)復(fù)制到S3。
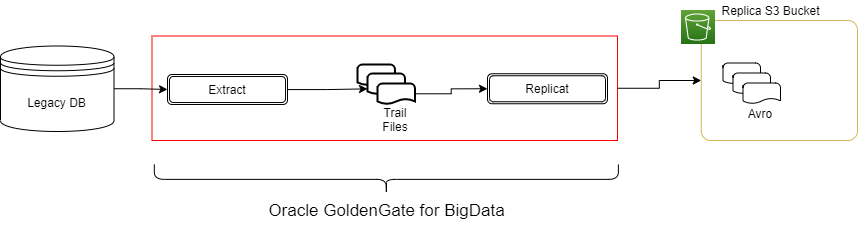
本篇文章將介紹如何使用Oracle GoldenGate來(lái)捕獲變更事件并利用Hudi格式寫(xiě)入S3數(shù)據(jù)湖。
Oracle GG可以使用多個(gè)處理程序和格式輸出,請(qǐng)查看此處[1]獲取更多信息。
本篇文章中不關(guān)心處理程序,我們假設(shè)使用Avro Operation格式,這種格式較為冗長(zhǎng),但有著廣泛應(yīng)用,因?yàn)槠淦胶饬藬?shù)據(jù)完整性和性能。如圖2所示,此格式包含每個(gè)記錄的before和after版本。

即使完整且易于生成,此格式也不適合用Athena或Spectrum進(jìn)行分析,從使用角度也無(wú)法替代源數(shù)據(jù)。此外你可能需要對(duì)歷史數(shù)據(jù)進(jìn)行分區(qū)處理以便快速檢索。
本文我們將介紹如何利用Apache Hudi框架做到這一點(diǎn),以構(gòu)建易于分析的目標(biāo)數(shù)據(jù)集。
2. 系統(tǒng)架構(gòu)
我們不詳細(xì)介紹如何將avro格式文件放入Replica S3桶中,整個(gè)數(shù)據(jù)體系結(jié)構(gòu)如下所示
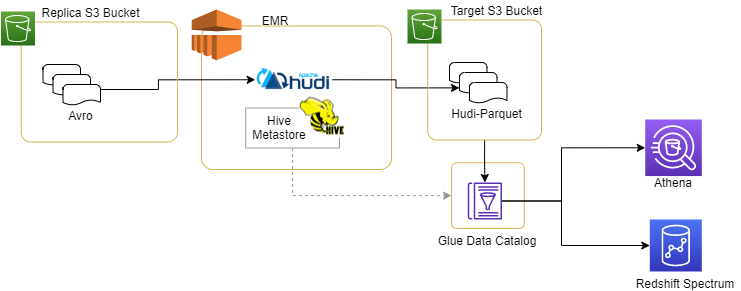
Hudi代碼運(yùn)行在EMR集群中,從Replica S3桶中讀取avro數(shù)據(jù),并將目標(biāo)數(shù)據(jù)集存儲(chǔ)到Target S3桶中。
EMR軟件配置如下
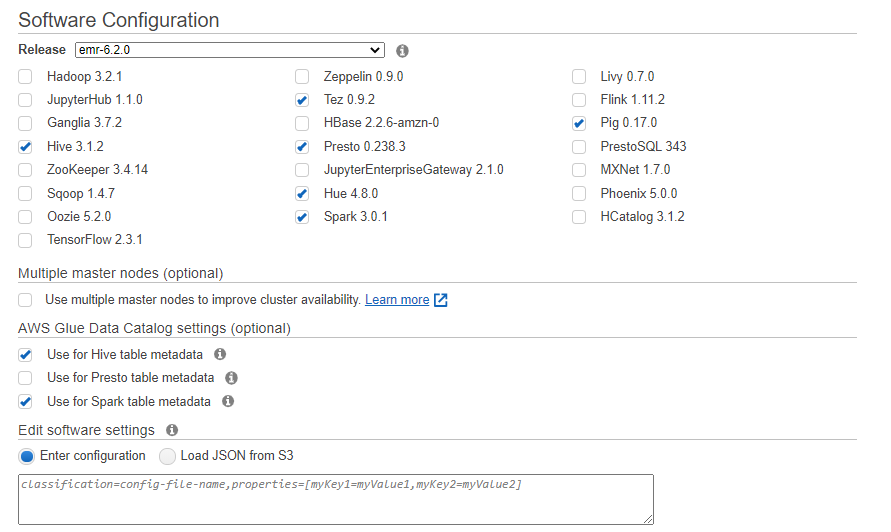
硬件配置如下
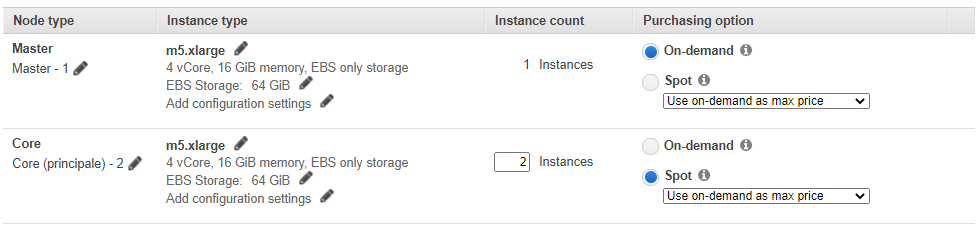
由于插入/更新始終保留最后一條記錄,因此Hudi作業(yè)非常具有彈性, 因此可以利用Spot Instance(搶占式實(shí)例)大大降低成本。
除此之外,還需要設(shè)置
?源bucket(如 my-s3-sourceBucket)?目標(biāo)bucket (如 my-s4-targetBucket)?Glue數(shù)據(jù)庫(kù)(如 sales-db)
配置完后需要確保EMR集群有讀寫(xiě)權(quán)限。
如果你需要一些樣例數(shù)據(jù),可以點(diǎn)擊此處[2]獲取。當(dāng)設(shè)置好桶后,啟動(dòng)EMR集群并將這些樣例數(shù)據(jù)導(dǎo)入Replica桶。
3. 關(guān)于分區(qū)的注意事項(xiàng)
為構(gòu)建按時(shí)間劃分的數(shù)據(jù)集,必須確定不可變的日期類(lèi)型字段。參照示例數(shù)據(jù)集(銷(xiāo)售訂單),我們假設(shè)訂單日期永遠(yuǎn)不會(huì)改變,因此我們將DAT_ORDER字段作為寫(xiě)入Hudi數(shù)據(jù)集的分區(qū)字段。
分區(qū)方式是YYYY/MM/DD,通過(guò)該方式,所有數(shù)據(jù)將被組織在嵌套的子文件夾中。Hudi框架將提供此分區(qū)信息,并將一個(gè)特定字段添加到關(guān)聯(lián)的Hive/Glue表中。當(dāng)查詢(xún)時(shí),該字段上的過(guò)濾條件將轉(zhuǎn)換為超高效的分區(qū)修剪掃描條件。
實(shí)際上這是我們必須對(duì)數(shù)據(jù)集做的唯一強(qiáng)假設(shè),所有其他信息都在avro文件中(字段名稱(chēng),字段類(lèi)型,PK等)。
除此元數(shù)據(jù)外,GoldenGate通常還會(huì)添加一些其他信息,例如表名稱(chēng),操作時(shí)間戳,操作類(lèi)型(插入/更新/刪除)和自定義標(biāo)記。你可以利用這些字段來(lái)構(gòu)造通用邏輯并構(gòu)建靈活的遷移平臺(tái)。
4. 步驟
啟動(dòng)spark-shell
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" --jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar啟動(dòng)后可以運(yùn)行如下代碼:
val ggDeltaFiles = "s3://" + sourceBucket + "/" + sourceSubFolder + "/" + sourceSystem + "/" + inputTableName + "/";val rootDataframe:DataFrame = spark.read.format("avro").load(ggDeltaFiles);// extract PK fields name from first lineval pkFields: Seq[String] = rootDataframe.select("primary_keys").limit(1).collect()(0).getSeq(0);// take into account the "after." fields onlyval columnsPre:Array[String] = rootDataframe.select("after.*").columns;// exclude "_isMissing" fields added by Oracle GoldenGate// The second part of the expression will safely preserve all native "**_isMissing" fieldsval columnsPost:Array[String] = columnsPre.filter { x => (!x.endsWith("_isMissing")) || (!x.endsWith("_isMissing_isMissing") && (columnsPre.filter(y => (y.equals(x + "_isMissing")) ).nonEmpty))};val columnsFinal:ArrayBuffer[String] = new ArrayBuffer[String]();columnsFinal += "op_ts";columnsFinal += "pos";// add the "after." prefixcolumnsPost.foreach(x => (columnsFinal += "after." + x));// prepare the target dataframe with the partition additional columnval preparedDataframe = rootDataframe.select("opTypeFieldName", columnsFinal.toArray:_*).withColumn("HUDI_PART_DATE", date_format(to_date(col("DAT_ORDER"), "yyyy-MM-dd"),"yyyy/MM/dd")).filter(col(opTypeFieldName).isin(admittedValues.toList: _*));// write datapreparedDataframe.write.format("org.apache.hudi").options(hudiOptions).option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, pkFields.mkString(",")).mode(SaveMode.Append).save(hudiTablePath);
上述簡(jiǎn)化了部分代碼,可以在此處[3]找到完整的代碼。
5. 結(jié)果
輸出的S3對(duì)象結(jié)果如下所示
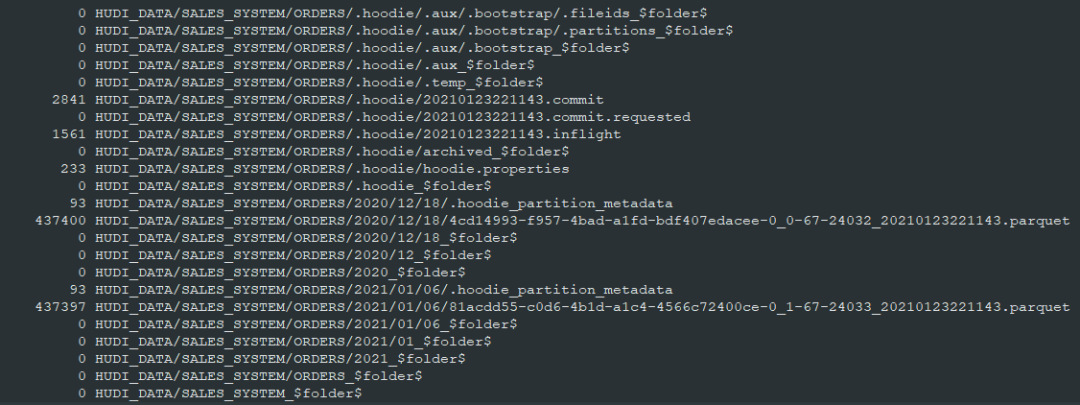
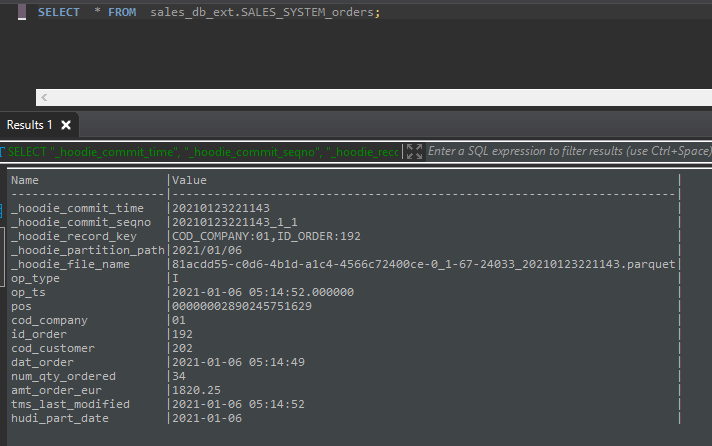
同時(shí)Glue數(shù)據(jù)目錄將使該表可用于通過(guò)外部模式在Athena或Spectrum中進(jìn)行查詢(xún)分析,外部表具有我們用于分區(qū)的hudi_part_date附加字段。
引用鏈接
[1] 此處: https://docs.oracle.com/en/middleware/goldengate/big-data/19.1/gadbd/using-pluggable-formatters.html#GUID-D77D819B-FDA2-4348-9899-711B50302F96[2] 此處: https://github.com/c-daniele/hudi-avro-op-demo/raw/master/sample_data/sample.avro[3] 此處: https://github.com/c-daniele/hudi-avro-op-demo/blob/master/hudi_main.scala