
特征選擇的通俗講解!

來源:Datawhale 本文約5000字,建議閱讀8分鐘 本文我們將通俗介紹如何使用 python 減少 kaggle Mushroom Classification 數(shù)據(jù)集中的特性數(shù)量。
簡介
據(jù)《福布斯》報道,每天大約會有 250 萬字節(jié)的數(shù)據(jù)被產(chǎn)生。然后,可以使用數(shù)據(jù)科學和機器學習技術對這些數(shù)據(jù)進行分析,以便提供分析和作出預測。盡管在大多數(shù)情況下,在開始任何統(tǒng)計分析之前,需要先對最初收集的數(shù)據(jù)進行預處理。有許多不同的原因?qū)е滦枰M行預處理分析,例如:
收集的數(shù)據(jù)格式不對(如 SQL 數(shù)據(jù)庫、JSON、CSV 等)
缺失值和異常值
標準化
減少數(shù)據(jù)集中存在的固有噪聲(部分存儲數(shù)據(jù)可能已損壞)
數(shù)據(jù)集中的某些功能可能無法收集任何信息以供分析
減少統(tǒng)計分析期間要使用的特征的數(shù)量可能會帶來一些好處,例如:
提高精度
降低過擬合風險
加快訓練速度
改進數(shù)據(jù)可視化
增加我們模型的可解釋性
事實上,統(tǒng)計上證明,當執(zhí)行機器學習任務時,存在針對每個特定任務應該使用的最佳數(shù)量的特征(圖 1)。如果添加的特征比必要的特征多,那么我們的模型性能將下降(因為添加了噪聲)。真正的挑戰(zhàn)是找出哪些特征是最佳的使用特征(這實際上取決于我們提供的數(shù)據(jù)量和我們正在努力實現(xiàn)的任務的復雜性)。這就是特征選擇技術能夠幫到我們的地方!
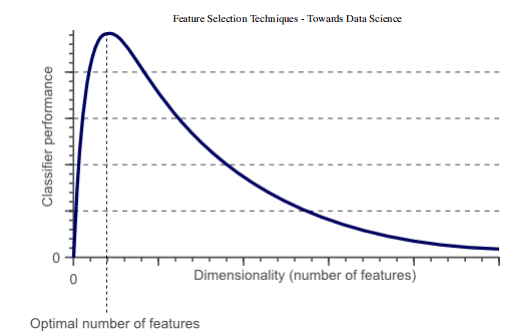
圖 1:分類器性能和維度之間的關系
特征選擇
有許多不同的方法可用于特征選擇。其中最重要的是:
1.過濾方法=過濾我們的數(shù)據(jù)集,只取包含所有相關特征的子集(例如,使用 Pearson 相關的相關矩陣)。
2.遵循過濾方法的相同目標,但使用機器學習模型作為其評估標準(例如,向前/向后/雙向/遞歸特征消除)。我們將一些特征輸入機器學習模型,評估它們的性能,然后決定是否添加或刪除特征以提高精度。因此,這種方法可以比濾波更精確,但計算成本更高。
3.嵌入方法。與過濾方法一樣,嵌入方法也使用機器學習模型。這兩種方法的區(qū)別在于,嵌入的方法檢查 ML 模型的不同訓練迭代,然后根據(jù)每個特征對 ML 模型訓練的貢獻程度對每個特征的重要性進行排序。
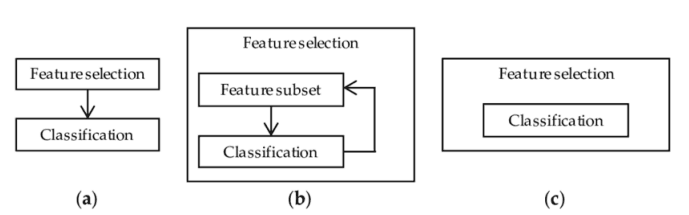
圖 2:過濾器、包裝器和嵌入式方法表示 [3]
實踐
在本文中,我將使用 Mushroom Classification 數(shù)據(jù)集,通過查看給定的特征來嘗試預測蘑菇是否有毒。在這樣做的同時,我們將嘗試不同的特征消除技術,看看它們會如何影響訓練時間和模型整體的精度。
數(shù)據(jù)下載:
https://github.com/ffzs/dataset/blob/master/mushrooms.csv
首先,我們需要導入所有必需的庫。

我們將在本例中使用的數(shù)據(jù)集如下圖所示。

圖 3:Mushroom Classification 數(shù)據(jù)集
在將這些數(shù)據(jù)輸入機器學習模型之前,我決定對所有分類變量進行 one hot 編碼,將數(shù)據(jù)分為特征(x)和標簽(y),最后在訓練集和測試集中進行。
X = df.drop(['class'], axis = 1)Y = df['class']X = pd.get_dummies(X, prefix_sep='_')Y = LabelEncoder().fit_transform(Y)X2 = StandardScaler().fit_transform(X)X_Train, X_Test, Y_Train, Y_Test = train_test_split(X2, Y, test_size = 0.30, random_state = 101)特征重要性
基于集合的決策樹模型(如隨機森林)可以用來對不同特征的重要性進行排序。了解我們的模型最重要的特征對于理解我們的模型如何做出預測(使其更易于解釋)是至關重要的。同時,我們可以去掉那些對我們的模型沒有任何好處的特征。
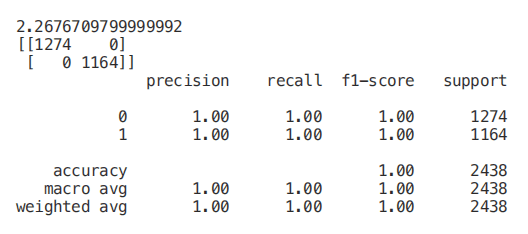
start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train,Y_Train)print(time.process_time() - start)predictionforest = trainedforest.predict(X_Test)print(confusion_matrix(Y_Test,predictionforest))print(classification_report(Y_Test,predictionforest))
如下圖所示,使用所有特征訓練一個隨機森林分類器,在大約 2.2 秒的訓練時間內(nèi)獲得 100% 的準確率。在下面的每個示例中,每個模型的訓練時間都將打印在每個片段的第一行,供你參考。
一旦我們的隨機森林分類器得到訓練,我們就可以創(chuàng)建一個特征重要性圖,看看哪些特征對我們的模型預測來說是最重要的(圖 4)。在本例中,下面只顯示了前 7 個特性。
figure(num=None, figsize=(20, 22), dpi=80, facecolor='w', edgecolor='k')
feat_importances = pd.Series(trainedforest.feature_importances_, index= X.columns)feat_importances.nlargest(7).plot(kind='barh')
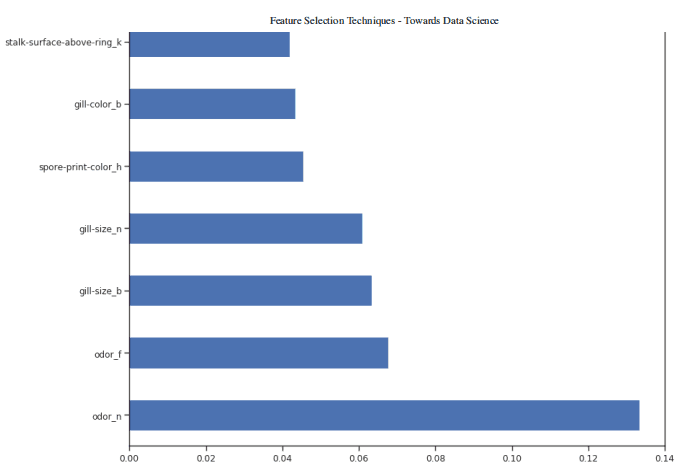
圖 4:特征重要性圖
現(xiàn)在我們知道了哪些特征被我們的隨機森林認為是最重要的,我們可以嘗試使用前 3 個來訓練我們的模型。
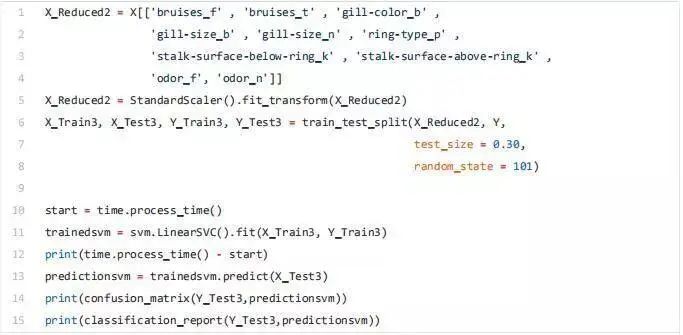
X_Reduced = X[['odor_n','odor_f', 'gill-size_n','gill-size_b']]X_Reduced = StandardScaler().fit_transform(X_Reduced)X_Train2, X_Test2, Y_Train2, Y_Test2 = train_test_split(X_Reduced, Y, test_size = 0.30, random_state = 101)start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train2,Y_Train2)print(time.process_time() - start)predictionforest = trainedforest.predict(X_Test2)print(confusion_matrix(Y_Test2,predictionforest))print(classification_report(Y_Test2,predictionforest))
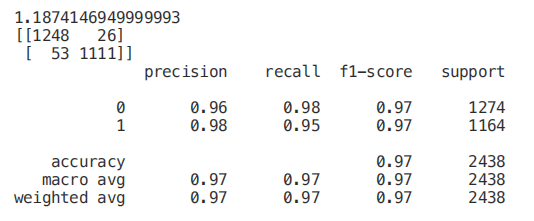
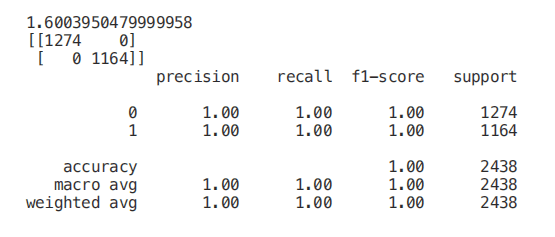
start = time.process_time()trainedtree = tree.DecisionTreeClassifier().fit(X_Train, Y_Train)print(time.process_time() - start)predictionstree = trainedtree.predict(X_Test)print(confusion_matrix(Y_Test,predictionstree))print(classification_report(Y_Test,predictionstree))
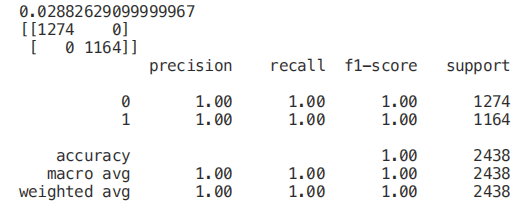
import graphvizfrom sklearn.tree import DecisionTreeClassifier, export_graphviz
data = export_graphviz(trainedtree,out_file=None,feature_names= X.columns, class_names=['edible', 'poisonous'], filled=True, rounded=True, max_depth=2, special_characters=True)graph = graphviz.Source(data)graph
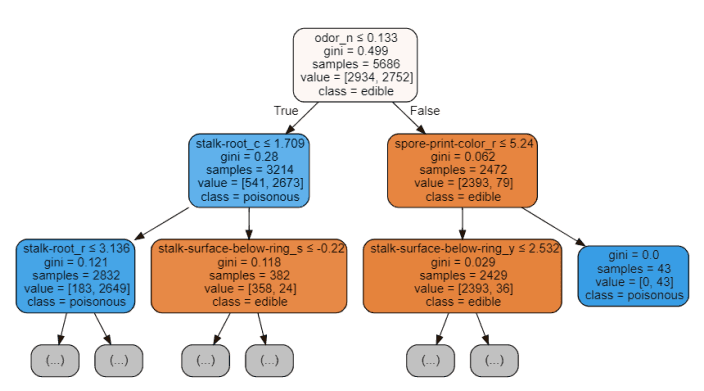
圖 5:決策樹可視化
遞歸特征消除(RFE)
遞歸特征消除(RFE)將機器學習模型的實例和要使用的最終期望特征數(shù)作為輸入。然后,它遞歸地減少要使用的特征的數(shù)量,采用的方法是使用機器學習模型精度作為度量對它們進行排序。
創(chuàng)建一個 for 循環(huán),其中輸入特征的數(shù)量是我們的變量,這樣就可以通過跟蹤在每個循環(huán)迭代中注冊的精度,找出我們的模型所需的最佳特征數(shù)量。使用 RFE 支持方法,我們可以找出被評估為最重要的特征的名稱(rfe.support 返回一個布爾列表,其中 true 表示一個特征被視為重要,false 表示一個特征不重要)。
from sklearn.feature_selection import RFEmodel = RandomForestClassifier(n_estimators=700)rfe = RFE(model, 4)start = time.process_time()RFE_X_Train = rfe.fit_transform(X_Train,Y_Train)RFE_X_Test = rfe.transform(X_Test)rfe = rfe.fit(RFE_X_Train,Y_Train)print(time.process_time() - start)print("Overall Accuracy using RFE: ", rfe.score(RFE_X_Test,Y_Test))
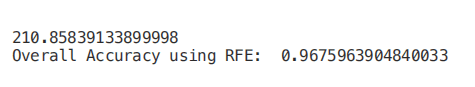
SelecFromModel
selectfrommodel 是另一種 scikit 學習方法,可用于特征選擇。此方法可用于具有 coef 或 feature 重要性屬性的所有不同類型的 scikit 學習模型(擬合后)。與 rfe 相比,selectfrommodel 是一個不太可靠的解決方案。實際上,selectfrommodel 只是根據(jù)計算出的閾值(不涉及優(yōu)化迭代過程)刪除不太重要的特性。
為了測試 selectfrommodel 的有效性,我決定在這個例子中使用一個 ExtraTreesClassifier。
ExtratreesClassifier(極端隨機樹)是基于樹的集成分類器,與隨機森林方法相比,它可以產(chǎn)生更少的方差(因此減少了過擬合的風險)。隨機森林和極隨機樹的主要區(qū)別在于極隨機樹中節(jié)點的采樣不需要替換。
from sklearn.ensemble import ExtraTreesClassifierfrom sklearn.feature_selection import SelectFromModelmodel = ExtraTreesClassifier()start = time.process_time()model = model.fit(X_Train,Y_Train)model = SelectFromModel(model, prefit=True)print(time.process_time() - start)Selected_X = model.transform(X_Train)start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(Selected_X, Y_Train)print(time.process_time() - start)Selected_X_Test = model.transform(X_Test)predictionforest = trainedforest.predict(Selected_X_Test)print(confusion_matrix(Y_Test,predictionforest))print(classification_report(Y_Test,predictionforest))
-
如果兩個特征之間的相關性為 0,則意味著更改這兩個特征中的任何一個都不會影響另一個。 -
如果兩個特征之間的相關性大于 0,這意味著增加一個特征中的值也會增加另一個特征中的值(相關系數(shù)越接近 1,兩個不同特征之間的這種聯(lián)系就越強)。 -
如果兩個特征之間的相關性小于 0,這意味著增加一個特征中的值將使減少另一個特征中的值(相關性系數(shù)越接近-1,兩個不同特征之間的這種關系將越強)。
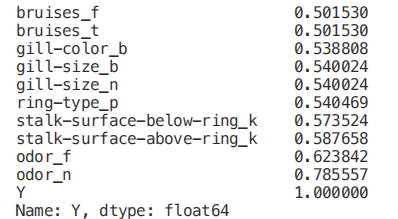
Numeric_df = pd.DataFrame(X)
Numeric_df['Y'] = Ycorr= Numeric_df.corr()corr_y = abs(corr["Y"])highest_corr = corr_y[corr_y >0.5]highest_corr.sort_values(ascending=True)
我們現(xiàn)在可以通過創(chuàng)建一個相關矩陣來更仔細地研究不同相關特征之間的關系。
figure(num=None, figsize=(12, 10), dpi=80, facecolor='w', edgecolor='k')corr2 = Numeric_df[['bruises_f' , 'bruises_t' , 'gill-color_b' , 'gill-size_b' , 'gill-size_n' , 'ring-type_p' , 'stalk-surface-below-ring_k' , 'stalk-surface-above-ring_k' , 'odor_f', 'odor_n']].corr()sns.heatmap(corr2, annot=True, fmt=".2g")
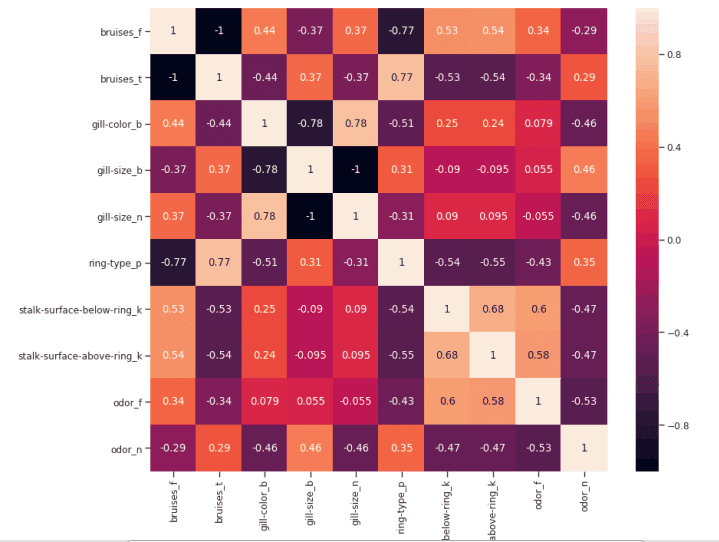
圖 6:最高相關特征的相關矩陣
在這項分析中,另一個可能要控制的方面是檢查所選變量是否彼此高度相關。如果是的話,我們就只需要保留其中一個相關的,去掉其他的。
最后,我們現(xiàn)在可以只選擇與 y 相關度最高的特征,訓練/測試一個支持向量機模型來評估該方法的結果。
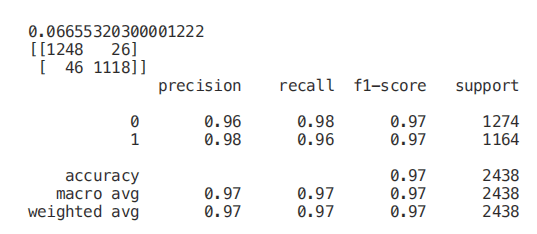
-
Classification = chi2, f_classif, mutual_info_classif -
Regression = f_regression, mutual_info_regression
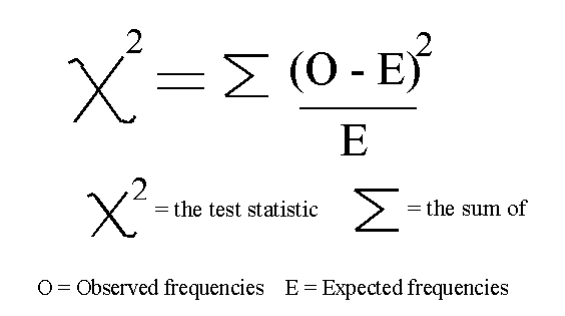
圖 7:卡方公式 [4]
卡方(chi-squared,chi2)可以將非負值作為輸入,因此,首先,我們在 0 到 1 之間的范圍內(nèi)縮放輸入數(shù)據(jù)。
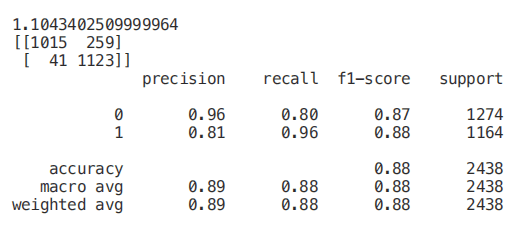
from sklearn.feature_selection import SelectKBestfrom sklearn.feature_selection import chi2min_max_scaler = preprocessing.MinMaxScaler()Scaled_X = min_max_scaler.fit_transform(X2)X_new = SelectKBest(chi2, k=2).fit_transform(Scaled_X, Y)X_Train3, X_Test3, Y_Train3, Y_Test3 = train_test_split(X_new, Y, test_size = 0.30, random_state = 101)start = time.process_time()trainedforest = RandomForestClassifier(n_estimators=700).fit(X_Train3,Y_Train3)print(time.process_time() - start)predictionforest = trainedforest.predict(X_Test3)print(confusion_matrix(Y_Test3,predictionforest))print(classification_report(Y_Test3,predictionforest))
套索回歸
當將正則化應用于機器學習模型時,我們在模型參數(shù)上加上一個懲罰,以避免我們的模型試圖太接近我們的輸入數(shù)據(jù)。通過這種方式,我們可以使我們的模型不那么復雜,并且我們可以避免過度擬合(使我們的模型不僅學習關鍵的數(shù)據(jù)特征,而且學習它的內(nèi)在噪聲)。
其中一種可能的正則化方法是套索回歸。當使用套索回歸時,如果輸入特征的系數(shù)對我們的機器學習模型訓練沒有積極的貢獻,則它們會縮小。這樣,一些特征可能會被自動丟棄,即將它們的系數(shù)指定為零。
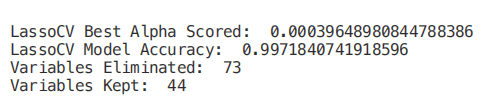
from sklearn.linear_model import LassoCVregr = LassoCV(cv=5, random_state=101)regr.fit(X_Train,Y_Train)print("LassoCV Best Alpha Scored: ", regr.alpha_)print("LassoCV Model Accuracy: ", regr.score(X_Test, Y_Test))model_coef = pd.Series(regr.coef_, index = list(X.columns[:-1]))print("Variables Eliminated: ", str(sum(model_coef == 0)))print("Variables Kept: ", str(sum(model_coef != 0)))
一旦訓練了我們的模型,我們就可以再次創(chuàng)建一個特征重要性圖來了解哪些特征被我們的模型認為是最重要的(圖 8)。這是非常有用的,尤其是在試圖理解我們的模型是如何決定做出預測的時候,因此使我們的模型更易于解釋。
figure(num=None, figsize=(12, 10), dpi=80, facecolor='w', edgecolor='k')top_coef = model_coef.sort_values()top_coef[top_coef != 0].plot(kind = "barh")plt.title("Most Important Features Identified using Lasso (!0)")
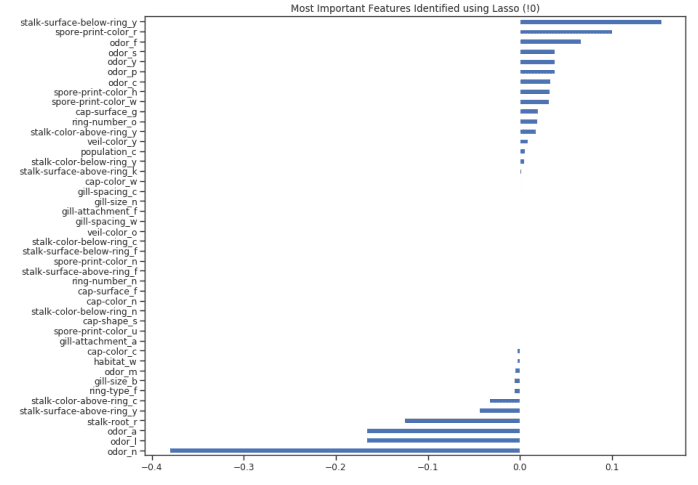
圖 8:套索特征重要性圖