
中文多模態(tài)CLIP,它終于有開源了
大家好,我是DASOU。
前段時間發(fā)現(xiàn)在Github上有位同學(xué)開源了中文的CLIP,包括權(quán)重和微調(diào)代碼。但是可惜的是,這個倉庫后續(xù)被關(guān)閉了,很奇怪~~

所以這個倉庫就不能用了。
當(dāng)時是分享到朋友圈了,所以看到就是賺到:
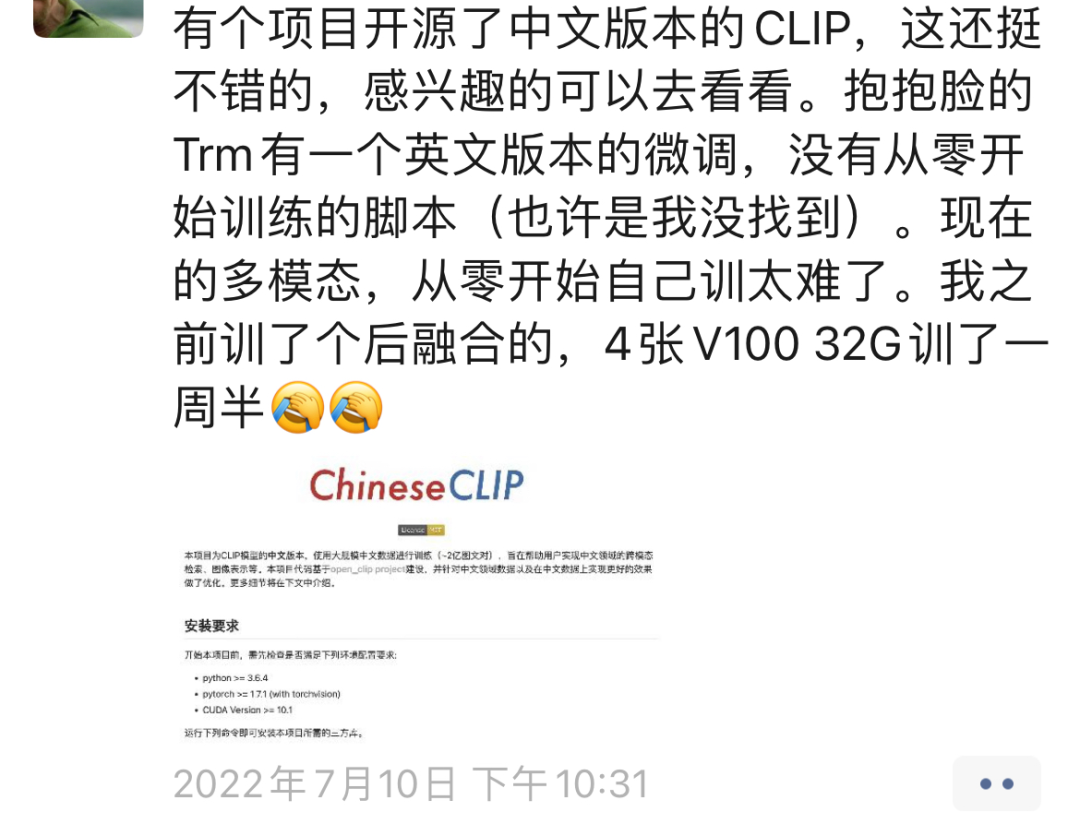
不過后來有朋友書說看到了另一個同學(xué)開源了同樣的項目,我fork了一下,大家可以去我Github看下,應(yīng)該也能用~~
然后,這兩天在知乎看到又有位同學(xué)開源了CLIP的中文權(quán)重,比較方便的一點是在hugging face可以直接調(diào)用使用。
hugging face是有預(yù)留CLIPModel的接口的,所以開源的權(quán)重可以直接被使用。
我看作者的描述,「在預(yù)訓(xùn)練的時候,對于image encoder,直接加載openAI的權(quán)重,而且是凍住,并沒有參與訓(xùn)練。對于text encoder, 則是加載中文robert預(yù)訓(xùn)練模型作為初始化權(quán)重進(jìn)行訓(xùn)練。所以放出來的開源模型只有text encoder,image encoder直接用openAI的權(quán)重即可」
emm......好吧。
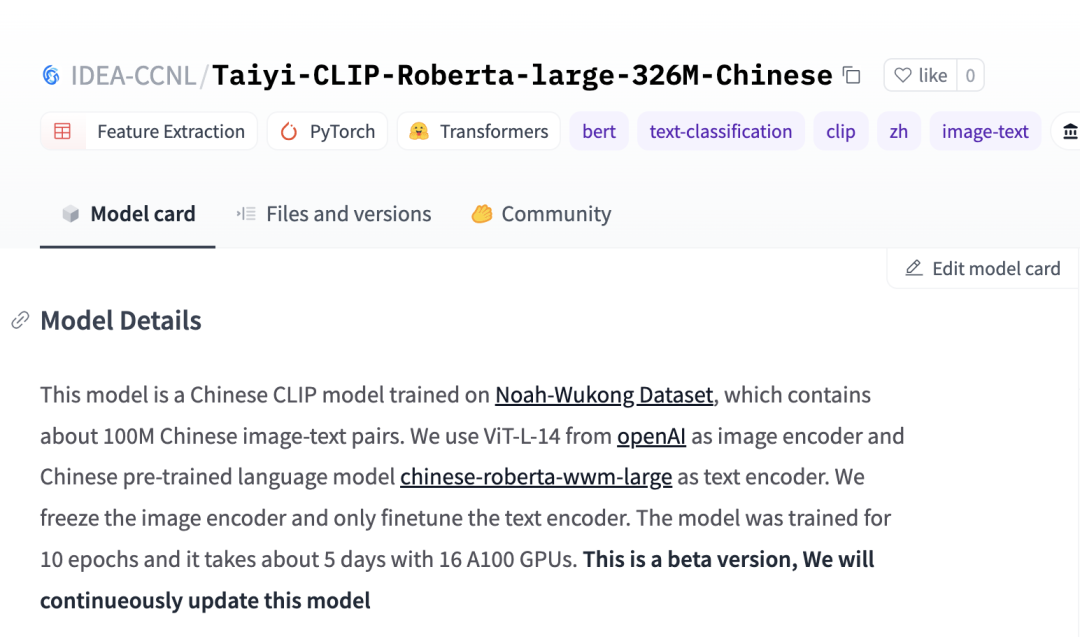
模式是基于wukong數(shù)據(jù)集訓(xùn)練的,這個數(shù)據(jù)集在剛出來的時候,我也公眾號分享了一下,看這里 這個數(shù)據(jù)集,絕了。
總的來說,有大規(guī)模的多模態(tài)中文模型開源出來總歸是好的。因為對于一些同學(xué)來說,從零訓(xùn)練一個多模態(tài)模型,實在是太耗資源了,也是一個小門檻。
我之前用訓(xùn)練一個后融合的多模態(tài)模,4張V100/32G顯存,訓(xùn)練了快2周,還沒訓(xùn)練好~~
辛苦求個三連
權(quán)重地址:https://huggingface.co/IDEA-CCNL/Taiyi-CLIP-Roberta-large-326M-Chinese
如果想第一時間看到一些比較好的技術(shù)/論文的分享,可以加我微信圍觀朋友圈~~