
機器學習開發(fā)的靈藥:Docker容器
來源:機器之心
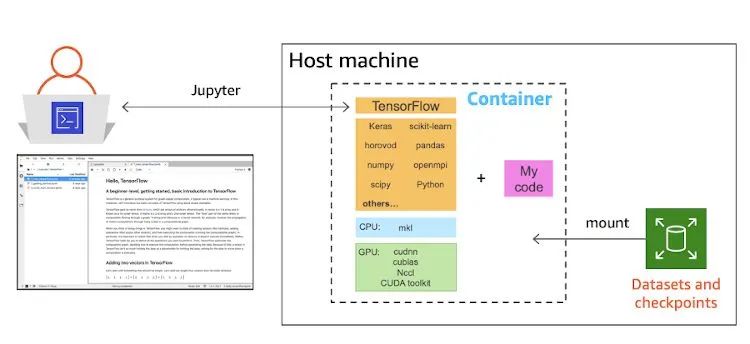
大多數(shù)人都喜歡在筆記本電腦上做原型開發(fā)。當想與人協(xié)作時,通常會將代碼推送到 GitHub 并邀請協(xié)作者。當想運行實驗并需要更多的計算能力時,會在云中租用 CPU 和 GPU 實例,將代碼和依賴項復(fù)制到實例中,然后運行實驗。如果您對這個過程很熟悉,那么您可能會奇怪:為什么一定要用 Docker 容器呢?
運營團隊中優(yōu)秀的 IT 專家們可以確保您的代碼持續(xù)可靠地運行,并能夠根據(jù)客戶需求進行擴展。那么對于運營團隊而言,容器不就成了一種罕見的工具嗎?您能夠高枕無憂,無需擔心部署問題,是因為有一群基礎(chǔ)設(shè)施專家負責在 Kubernetes 上部署并管理您的應(yīng)用程序嗎?
在本文中,AWS會嘗試說明為什么您應(yīng)該考慮使用 Docker 容器進行機器學習開發(fā)。在本文的前半部分,將討論在使用復(fù)雜的開源機器學習軟件時遇到的主要難題,以及采用容器將如何緩和這些問題。然后,將介紹如何設(shè)置基于 Docker 容器的開發(fā)環(huán)境,并演示如何使用該環(huán)境來協(xié)作和擴展集群上的工作負載。
機器學習開發(fā)環(huán)境:基本需求
首先了解一下機器學習開發(fā)環(huán)境所需的四個基本要素:
計算:訓練模型離不開高性能 CPU 和 GPU;
存儲:用于存儲大型訓練數(shù)據(jù)集和您在訓練過程中生成的元數(shù)據(jù);
框架和庫:提供用于訓練的 API 和執(zhí)行環(huán)境;
源代碼控制:用于協(xié)作、備份和自動化。
作為機器學習研究人員、開發(fā)人員或數(shù)據(jù)科學家,您可以在單個 Amazon Elastic Compute Cloud (Amazon EC2)?實例或家庭工作站上搭建滿足這四種要素的環(huán)境。
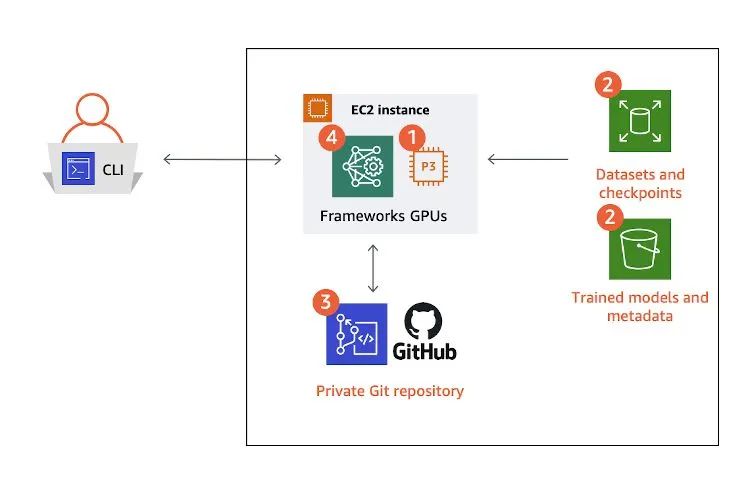
那么,此設(shè)置有什么問題嗎?
其實也談不上有問題。因為幾十年來,大多數(shù)開發(fā)設(shè)置都是如此:既沒有集群,也沒有共享文件系統(tǒng)。
除了高性能計算 (HPC) 項目的一小群研究人員能夠?qū)㈤_發(fā)的代碼放在超級計算機上運行之外,絕大多數(shù)人都只能依靠自己專用的計算機進行開發(fā)。
事實證明,與傳統(tǒng)軟件開發(fā)相比,機器學習與 HPC 具有更多的共同點。與 HPC 工作負載一樣,若在大型集群上運行機器學習工作負載,執(zhí)行速度更快,實驗速度也更快。要利用集群進行機器學習訓練,您需要確保自己的開發(fā)環(huán)境可移植,并且訓練在集群上可重復(fù)。
為什么需要可移植的訓練環(huán)境?
在機器學習開發(fā)流程中的某個階段,您會遇到以下兩個難題:
您正在進行實驗,但您的訓練腳本發(fā)生了太多次的更改導致無法運行,并且只用一臺計算機無法滿足需求。
您在具有大型數(shù)據(jù)集的大型模型上進行訓練,但僅在一臺計算機上運行使您無法在合理的時間內(nèi)獲得結(jié)果。
這兩個原因往往會讓您希望在集群上運行機器學習訓練。這也是科學家選擇使用超級計算機(例如 Summit 超級計算機)進行科學實驗的原因。要解決第一個難題,您可以在計算機集群上獨立且異步地運行每個模型。要解決第二個難題,您可以將單個模型分布在集群上以實現(xiàn)更快的訓練。
這兩種解決方案都要求您能夠在集群上以一致的方式成功復(fù)現(xiàn)開發(fā)訓練設(shè)置。這一要求很有挑戰(zhàn)性,因為集群上運行的操作系統(tǒng)和內(nèi)核版本、GPU、驅(qū)動程序和運行時以及軟件依賴項可能與您的開發(fā)計算機有所不同。
您需要可移植的機器學習環(huán)境的另一個原因是便于協(xié)作開發(fā)。通過版本控制與協(xié)作者共享訓練腳本很容易。但在不共享整個執(zhí)行環(huán)境(包括代碼、依賴項和配置)的情況下保證可重復(fù)性卻很難。這些內(nèi)容將在下一節(jié)中介紹。
機器學習、開源和專用硬件
機器學習開發(fā)環(huán)境面臨的挑戰(zhàn)是,它們依賴于復(fù)雜且不斷發(fā)展的開源機器學習框架和工具包以及同樣復(fù)雜且不斷發(fā)展的硬件生態(tài)系統(tǒng)。雖然這兩者都是我們需要的積極特質(zhì),但它們卻在短期內(nèi)構(gòu)成了挑戰(zhàn)。
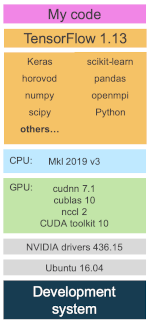
在進行機器學習訓練時,您有多少次問過自己以下這些問題:
我的代碼是否利用了 CPU 和 GPU 上的所有可用資源?
我是否使用了正確的硬件庫 和硬件庫版本?
當運行環(huán)境大同小異時,為什么我的訓練代碼在自己的計算機上可以正常工作,而在同事的計算機上就會崩潰?
我今天更新了驅(qū)動程序,現(xiàn)在訓練變慢/出錯了。這是為什么?
如果您檢查自己的機器學習軟件堆棧,會發(fā)現(xiàn)自己的大部分時間都花在了紫紅色框(即圖中的我的代碼)上。這部分包括您的訓練腳本、實用程序和幫助例程、協(xié)作者的代碼、社區(qū)貢獻等。如果這還不夠復(fù)雜,您還會注意到您的依賴項包括:
迅速演進的機器學習框架 API;
機器學習框架依賴項,其中有很多是獨立的項目;
CPU 專用庫,用于加速數(shù)學例程;
GPU 專用庫,用于加速數(shù)學例程和 GPU 間通信例程;以及
需要與用于編譯上述 GPU 庫的 GPU 編譯器協(xié)調(diào)一致的 GPU 驅(qū)動程序。
由于開源機器學習軟件堆棧的高度復(fù)雜性,在您將代碼移至協(xié)作者的計算機或集群環(huán)境時,會引入多個故障點。在下圖中,請注意,即使您控制對訓練代碼和機器學習框架的更改,也可能無法顧及到較低級別的更改,從而導致實驗失敗。
最終,白白浪費了您的寶貴時間。
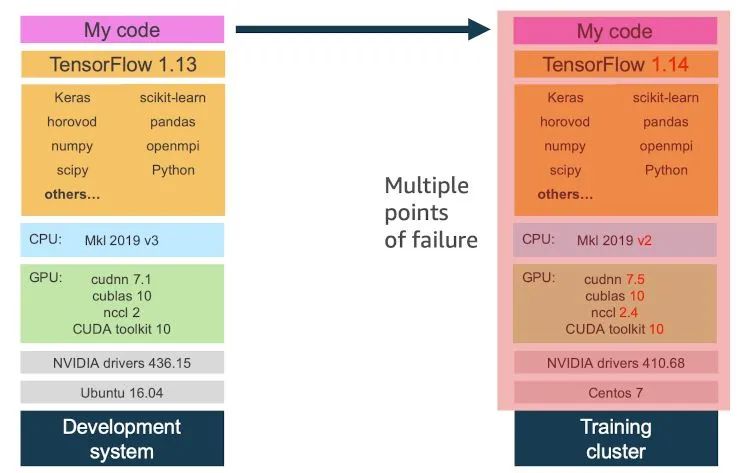
為什么不使用虛擬 Python 環(huán)境?
您可能會認為,conda 和 virtualenv 之類的虛擬環(huán)境方法可以解決這些問題。沒錯,但是它們只能解決部分問題。有些非 Python 依賴項不由這些解決方案管理。由于典型機器學習堆棧十分復(fù)雜,因此很大一部分框架依賴項(例如硬件庫)都在虛擬環(huán)境范圍之外。
使用容器進行機器學習開發(fā)
機器學習軟件是具有多個項目和參與者的零散生態(tài)系統(tǒng)的一部分。這可能是件好事,因為每個人都可以從自己的參與中獲益,并且開發(fā)人員始終擁有充分的選擇。不利方面是要應(yīng)對一些問題,例如一致性、可移植性和依賴項管理。這就是容器技術(shù)的用武之地。在本文中,我不想討論容器的常規(guī)優(yōu)勢,而想講講講機器學習如何從容器中獲益。
容器不僅可以完全封裝您的訓練代碼,還能封裝整個依賴項堆棧甚至硬件庫。您會得到一個一致且可移植的機器學習開發(fā)環(huán)境。通過容器,在集群上開展協(xié)作和進行擴展都會變得更加簡單。如果您在容器環(huán)境中開發(fā)代碼和運行訓練,不僅可以方便地共享您的訓練腳本,還能共享您的整個開發(fā)環(huán)境,只需將您的容器映像推送到容器注冊表中,并讓協(xié)作者或集群管理服務(wù)提取容器映像并運行,即可重現(xiàn)您的結(jié)果。
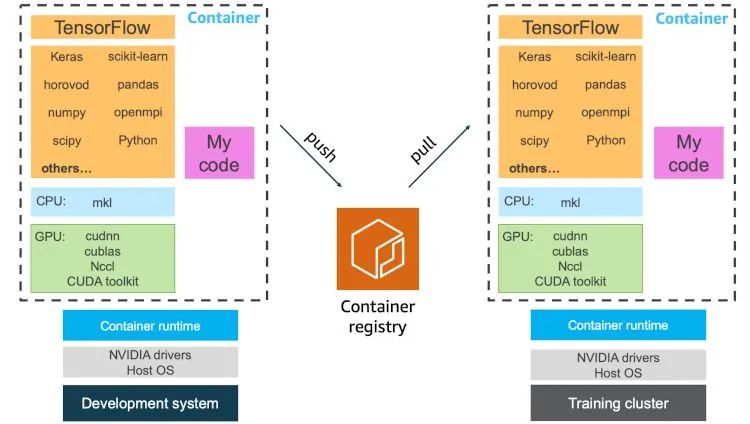
應(yīng)將/不應(yīng)將哪些內(nèi)容包含在您的機器學習開發(fā)容器中
這個問題沒有正確答案,您的團隊如何運營由您來決定,但是關(guān)于可以包含哪些內(nèi)容,有以下幾個方案:
只包含機器學習框架和依賴項:這是最簡潔的方法。每位協(xié)作者都可以獲得相同執(zhí)行環(huán)境的相同副本。他們可以在運行時將自己的訓練腳本克隆到容器中,也可以掛載包含訓練代碼的卷。
機器學習框架、依賴項和訓練代碼:當擴展集群上的工作負載時,首選此方法。您可以獲得一個可在集群上擴展的可執(zhí)行的機器學習軟件單元。根據(jù)您對訓練代碼的組織方式,您可以允許腳本執(zhí)行多種訓練變體,以運行超參數(shù)搜索實驗。
共享您的開發(fā)容器也非常輕松。您可以按以下方式進行共享:
容器映像:這是最簡單的方法。這種方法允許每位協(xié)作者或集群管理服務(wù)(例如 Kubernetes)提取容器映像,對映像進行實例化,然后直接執(zhí)行訓練。
Dockerfile:這是一種輕量型方法。Dockerfile 中包含關(guān)于創(chuàng)建容器映像時需要下載、構(gòu)建和編譯哪些依賴項的說明。可以在您編寫訓練代碼時對 Dockerfile 進行版本控制。您可以使用持續(xù)集成服務(wù)(例如 AWS CodeBuild),自動完成從 Dockerfile 創(chuàng)建容器映像的過程。
Docker 中心提供了廣泛使用的開源機器學習框架或庫的容器映像,這些映像通常由框架維護人員提供。您可以在他們的存儲庫中找到 TensorFlow、PyTorch 和 MXNet 等。在決定從哪里下載以及下載哪種類型的容器映像時,要十分謹慎。
大部分上游存儲庫都會將其容器構(gòu)建為在任何位置均可使用,這意味著這些容器需要與大部分 CPU 和 GPU 架構(gòu)兼容。如果您確切知曉將在怎樣的系統(tǒng)上運行容器,最好選擇已經(jīng)針對您的系統(tǒng)配置進行優(yōu)化的合格容器映像。
使用 Jupyter 和 Docker 容器設(shè)置您的機器學習開發(fā)環(huán)境
AWS 使用常用的開源深度學習框架來托管可用于計算優(yōu)化型 CPU 和 GPU 實例的 AWS Deep Learning Containers。接下來,我將說明如何使用容器通過幾個步驟設(shè)置開發(fā)環(huán)境。在此示例中,我假設(shè)您使用的是 Amazon EC2 實例。

第 1 步:啟動您的開發(fā)實例。
C5、P3 或 G4 系列實例都適合用于機器學習工作負載。后兩者每個實例最多可提供多達八個 NVIDIA GPU。有關(guān)如何啟動實例的簡要指南,請閱讀 Amazon EC2 入門文檔(https://amazonaws-china.com/cn/ec2/getting-started/)。
選擇 Amazon 系統(tǒng)映像 (AMI) 時,請選擇最新的 Deep Learning AMI,該 AMI 中包含所有最新的深度學習框架、Docker 運行時以及 NVIDIA 驅(qū)動程序和庫。盡管使用安裝在 AMI 本地的深度學習框架看似方便,但使用深度學習容器會讓您距離可移植性更強的環(huán)境更近一步。
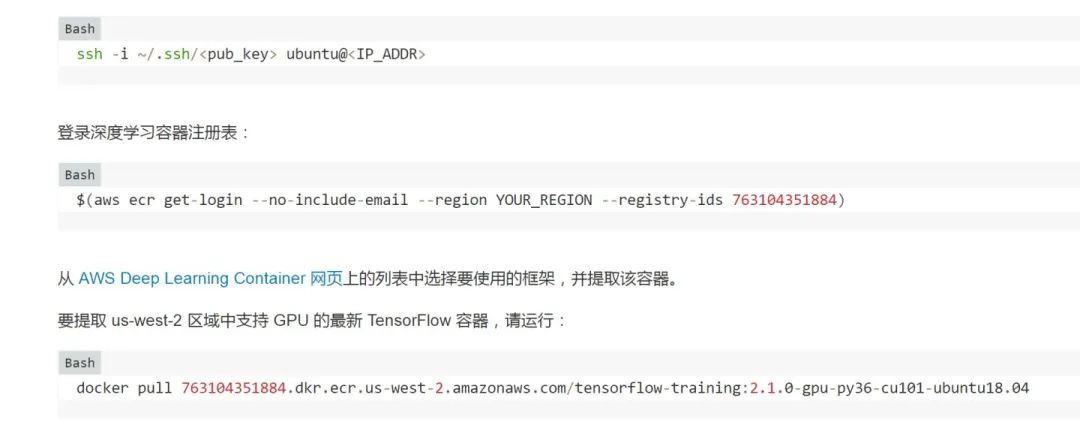
第 2 步:通過 SSH 連接到實例并下載深度學習容器。
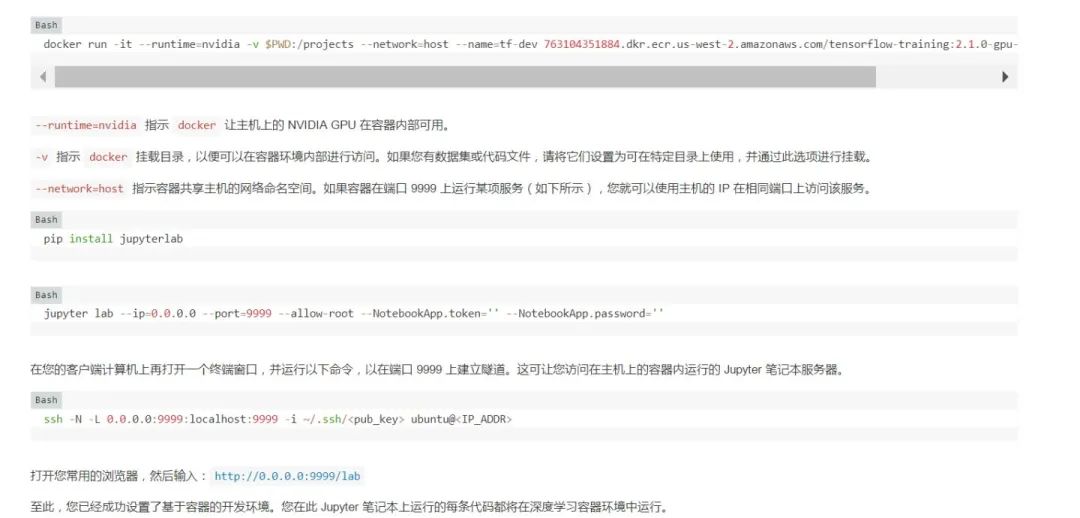
第 3 步:實例化容器并設(shè)置 Jupyter。
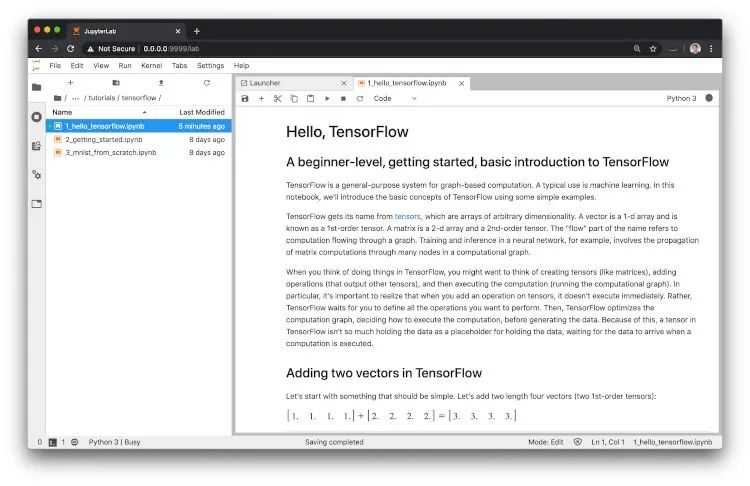
第 4 步:使用基于容器的開發(fā)環(huán)境。
容器原本是無狀態(tài)的執(zhí)行環(huán)境,因此請將您的工作保存在調(diào)用 docker run 時使用 -v 標志指定的掛載目錄中。要退出容器,請停止 Jupyter 服務(wù)器并在終端上鍵入 exit。要重新啟動已停止的容器,請運行:
docker?start?tf-dev按照第 3 步中的說明設(shè)置隧道,即可繼續(xù)進行開發(fā)。
現(xiàn)在,假設(shè)您要對基本容器進行更改,例如,按照第 3 步所示,將 Jupyter 安裝到容器中。最簡單的方法是跟蹤所有自定義安裝并在 Dockerfile 中進行捕獲。這使您可以重新創(chuàng)建容器映像,并從頭進行更改。這還可用于記錄更改,并且可與剩余代碼一起進行版本控制。
在對開發(fā)過程造成最小干擾的情況下執(zhí)行此操作的更快方法是,通過運行以下命令將這些更改提交到新的容器映像中:
sudo?docker?commit?tf-dev?my-tf-dev:latest注意:容器純粹主義者會認為這不是保存更改的建議方法,應(yīng)將這些更改記錄在 Dockerfile 中。這是一個很好的建議,也是通過編寫 Dockerfile 跟蹤您的自定義設(shè)置的好做法。如果您不這樣做,則會面臨以下風險:隨著時間流逝,您將失去對更改的跟蹤,并將依賴于一個“工作”映像,就像依賴于無法訪問源代碼的已編譯二進制文件一樣。
如果您想與協(xié)作者共享新容器,請將其推送到容器注冊表,例如 Docker Hub 或 Amazon Elastic Container Registry (Amazon ECR)。要將其推送到 Amazon ECR,請先創(chuàng)建一個注冊表,登錄,然后推送您的容器:
aws?ecr?create-repository?--repository-name?my-tf-dev$(aws?ecr?get-login?--no-include-email?--region?) docker?tag?my-tf-dev:latest?.dkr.ecr. .amazonaws.com/my-tf-dev:latest docker?push?.dkr.ecr. .amazonaws.com/my-tf-dev:latest
現(xiàn)在,您可以與協(xié)作者共享此容器映像,并且您的代碼應(yīng)該能像在計算機上一樣工作。這種方法的額外好處是您現(xiàn)在可以使用同一容器在集群上運行大規(guī)模工作負載。我們來了解一下如何做到這一點。
機器學習訓練容器并在集群上擴展它們
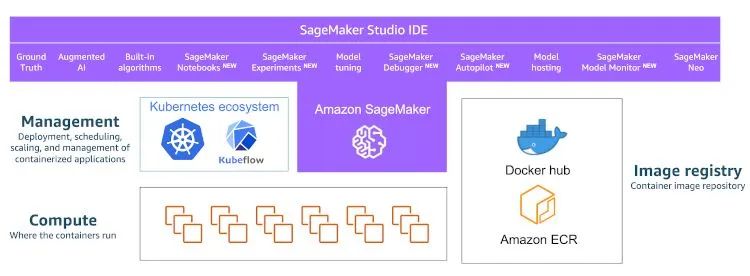
大多數(shù)集群管理解決方案(例如 Kubernetes 或 Amazon ECS)都會在集群上調(diào)度和運行容器。另外,您也可以使用完全托管的服務(wù),例如 Amazon SageMaker,在其中您可以根據(jù)需要配置實例,并在作業(yè)完成時自動將其銷毀。此外,該服務(wù)還提供用于數(shù)據(jù)標簽的完全托管的服務(wù)套件、托管的 Jupyter 筆記本開發(fā)環(huán)境、托管的訓練集群、超參數(shù)優(yōu)化、托管模型托管服務(wù)以及將所有這些結(jié)合在一起的 IDE。
要利用這些解決方案并在集群上運行機器學習訓練,您必須構(gòu)建一個容器并將其推送到注冊表。
如果您如上所述采用基于容器的機器學習開發(fā),那么您盡可放心,您開發(fā)時所用的容器環(huán)境將按計劃在集群上大規(guī)模運行,而不會出現(xiàn)框架版本問題和依賴項問題。
要在 2 個節(jié)點上使用 Kubernetes 和 KubeFlow 運行分布式訓練作業(yè),您需要在 YAML 中編寫一個如下所示的配置文件:
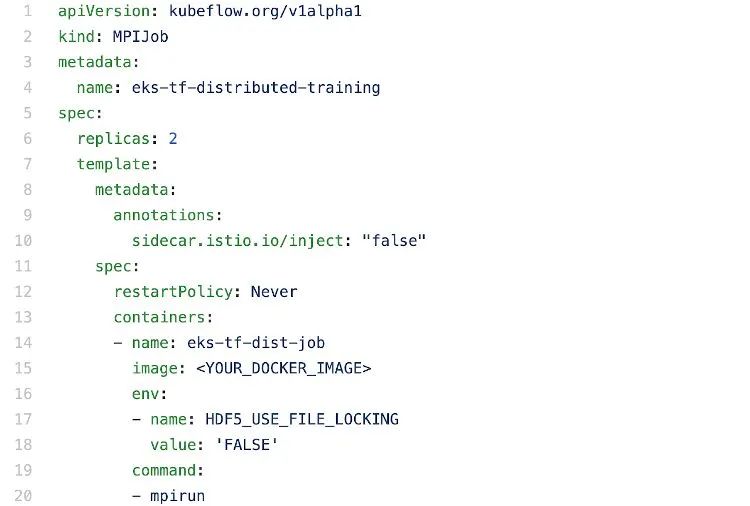
使用 TensorFlow 和 Horovod API 進行分布式訓練的 Kubernetes 配置文件的摘錄,可在 Github 上找到。請注意,屏幕截圖未顯示完整文件。
在映像部分下,您將使用訓練腳本指定 docker 圖像。在命令下,您將指定訓練所需的命令。由于這是一項分布式訓練作業(yè),因此您將使用 mpirun 命令運行 MPI 作業(yè)。
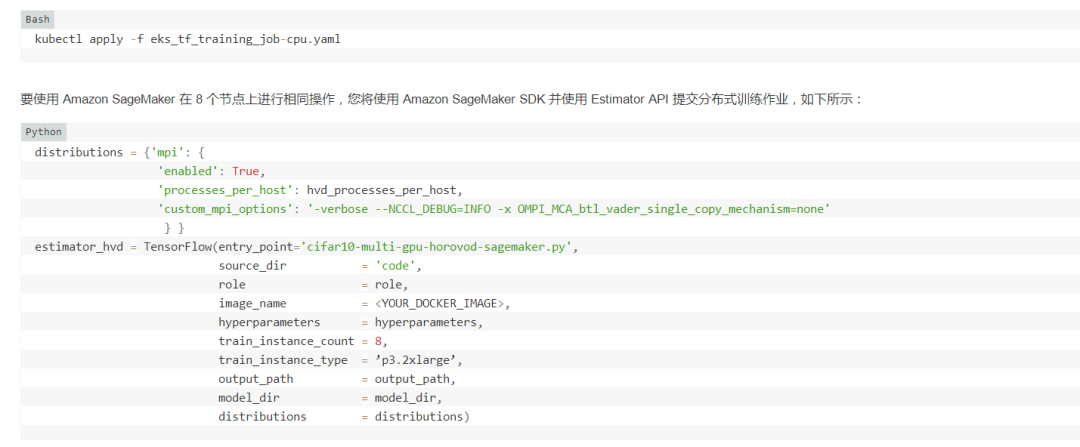
您可以按以下步驟將此作業(yè)提交到 Kubernetes 集群(假設(shè)集群已設(shè)置并正在運行,并且您已安裝 KubeFlow):
多疑善思,但不要驚慌失措
機器學習社區(qū)發(fā)展迅猛。新的研究成果在發(fā)布后的數(shù)周或數(shù)月之內(nèi)就會在開源框架中的 API 中實施。由于軟件迅速演進,及時更新并保持產(chǎn)品的質(zhì)量、一致性和可靠性頗具挑戰(zhàn)。因此,請保持多疑善思,但不要驚慌失措,因為您不是單人作戰(zhàn),并且社區(qū)中有許多最佳實踐可用來確保您從最新信息中受益。
轉(zhuǎn)向容器化機器學習開發(fā)是應(yīng)對這些挑戰(zhàn)的一種途徑,希望在本文中我已經(jīng)解釋清楚了這一點。
現(xiàn)在,創(chuàng)建AWS賬戶即可體驗免費產(chǎn)品服務(wù),包括以下內(nèi)容:

Python大數(shù)據(jù)分析
data creates?value
掃碼關(guān)注我們