
【Python】推薦20個(gè)好用到爆的Pandas函數(shù)方法
pandas函數(shù),大家可能平時(shí)看到的不多,但是使用起來(lái)倒是非常的方便,也能夠幫助我們數(shù)據(jù)分析人員大幅度地提高工作效率,同時(shí)也希望大家看完之后能夠有所收獲items()方法iterrows()方法insert()方法assign()方法eval()方法pop()方法truncate()方法count()方法add_prefix()方法/add_suffix()方法clip()方法filter()方法first()方法isin()方法df.plot.area()方法df.plot.bar()方法df.plot.box()方法df.plot.pie()方法
items()方法
items()方法可以用來(lái)遍歷數(shù)據(jù)集當(dāng)中的每一列,同時(shí)返回列名以及每一列當(dāng)中的內(nèi)容,通過(guò)以元組的形式,示例如下df?=?pd.DataFrame({'species':?['bear',?'bear',?'marsupial'],
??????????????????'population':?[1864,?22000,?80000]},
??????????????????index=['panda',?'polar',?'koala'])
df
output
?????????species??population
panda???????bear????????1864
polar???????bear???????22000
koala??marsupial???????80000
然后我們使用items()方法
for?label,?content?in?df.items():
????print(f'label:?{label}')
????print(f'content:?{content}',?sep='\n')
????print("="?*?50)
output
label:?species
content:?panda?????????bear
polar?????????bear
koala????marsupial
Name:?species,?dtype:?object
==================================================
label:?population
content:?panda?????1864
polar????22000
koala????80000
Name:?population,?dtype:?int64
==================================================
相繼的打印出了‘species’和‘population’這兩列的列名和相應(yīng)的內(nèi)容
iterrows()方法
iterrows()方法而言,其功能則是遍歷數(shù)據(jù)集當(dāng)中的每一行,返回每一行的索引以及帶有列名的每一行的內(nèi)容,示例如下for?label,?content?in?df.iterrows():
????print(f'label:?{label}')
????print(f'content:?{content}',?sep='\n')
????print("="?*?50)
output
label:?panda
content:?species???????bear
population????1864
Name:?panda,?dtype:?object
==================================================
label:?polar
content:?species????????bear
population????22000
Name:?polar,?dtype:?object
==================================================
label:?koala
content:?species???????marsupial
population????????80000
Name:?koala,?dtype:?object
==================================================
insert()方法
insert()方法主要是用于在數(shù)據(jù)集當(dāng)中的特定位置處插入數(shù)據(jù),示例如下
df.insert(1,?"size",?[2000,?3000,?4000])
output
?????????species??size??population
panda???????bear??2000????????1864
polar???????bear??3000???????22000
koala??marsupial??4000???????80000
可見(jiàn)在DataFrame數(shù)據(jù)集當(dāng)中,列的索引也是從0開(kāi)始的
assign()方法
assign()方法可以用來(lái)在數(shù)據(jù)集當(dāng)中添加新的列,示例如下
df.assign(size_1=lambda?x:?x.population?*?9?/?5?+?32)
output
?????????species??population????size_1
panda???????bear????????1864????3387.2
polar???????bear???????22000???39632.0
koala??marsupial???????80000??144032.0
lambda匿名函數(shù),在數(shù)據(jù)集當(dāng)中添加一個(gè)新的列,命名為‘size_1’,當(dāng)然我們也可以通過(guò)assign()方法來(lái)創(chuàng)建不止一個(gè)列df.assign(size_1?=?lambda?x:?x.population?*?9?/?5?+?32,
??????????size_2?=?lambda?x:?x.population?*?8?/?5?+?10)
output
?????????species??population????size_1????size_2
panda???????bear????????1864????3387.2????2992.4
polar???????bear???????22000???39632.0???35210.0
koala??marsupial???????80000??144032.0??128010.0
eval()方法
eval()方法主要是用來(lái)執(zhí)行用字符串來(lái)表示的運(yùn)算過(guò)程的,例如
df.eval("size_3?=?size_1?+?size_2")
output
?????????species??population????size_1????size_2????size_3
panda???????bear????????1864????3387.2????2992.4????6379.6
polar???????bear???????22000???39632.0???35210.0???74842.0
koala??marsupial???????80000??144032.0??128010.0??272042.0
當(dāng)然我們也可以同時(shí)對(duì)執(zhí)行多個(gè)運(yùn)算過(guò)程
df?=?df.eval('''
size_3?=?size_1?+?size_2
size_4?=?size_1?-?size_2
''')
output
?????????species??population????size_1????size_2????size_3???size_4
panda???????bear????????1864????3387.2????2992.4????6379.6????394.8
polar???????bear???????22000???39632.0???35210.0???74842.0???4422.0
koala??marsupial???????80000??144032.0??128010.0??272042.0??16022.0
pop()方法
pop()方法主要是用來(lái)刪除掉數(shù)據(jù)集中特定的某一列數(shù)據(jù)
df.pop("size_3")
output
panda??????6379.6
polar?????74842.0
koala????272042.0
Name:?size_3,?dtype:?float64
而原先的數(shù)據(jù)集當(dāng)中就沒(méi)有這個(gè)‘size_3’這一例的數(shù)據(jù)了
truncate()方法
truncate()方法主要是根據(jù)行索引來(lái)篩選指定行的數(shù)據(jù)的,示例如下
df?=?pd.DataFrame({'A':?['a',?'b',?'c',?'d',?'e'],
???????????????????'B':?['f',?'g',?'h',?'i',?'j'],
???????????????????'C':?['k',?'l',?'m',?'n',?'o']},
??????????????????index=[1,?2,?3,?4,?5])
output
???A??B??C
1??a??f??k
2??b??g??l
3??c??h??m
4??d??i??n
5??e??j??o
我們使用truncate()方法來(lái)做一下嘗試
df.truncate(before=2,?after=4)
output
???A??B??C
2??b??g??l
3??c??h??m
4??d??i??n
before和after存在于truncate()方法中,目的就是把行索引2之前和行索引4之后的數(shù)據(jù)排除在外,篩選出剩余的數(shù)據(jù)count()方法
count()方法主要是用來(lái)計(jì)算某一列當(dāng)中非空值的個(gè)數(shù),示例如下
df?=?pd.DataFrame({"Name":?["John",?"Myla",?"Lewis",?"John",?"John"],
???????????????????"Age":?[24.,?np.nan,?25,?33,?26],
???????????????????"Single":?[True,?True,?np.nan,?True,?False]})
output
????Name???Age?Single
0???John??24.0???True
1???Myla???NaN???True
2??Lewis??25.0????NaN
3???John??33.0???True
4???John??26.0??False
我們使用count()方法來(lái)計(jì)算一下數(shù)據(jù)集當(dāng)中非空值的個(gè)數(shù)
df.count()
output
Name??????5
Age???????4
Single????4
dtype:?int64
add_prefix()方法/add_suffix()方法
add_prefix()方法和add_suffix()方法分別會(huì)給列名以及行索引添加后綴和前綴,對(duì)于Series()數(shù)據(jù)集而言,前綴與后綴是添加在行索引處,而對(duì)于DataFrame()數(shù)據(jù)集而言,前綴與后綴是添加在列索引處,示例如下s?=?pd.Series([1,?2,?3,?4])
output
0??? 1
1????2
2????3
3????4
dtype:?int64
我們使用add_prefix()方法與add_suffix()方法在Series()數(shù)據(jù)集上
s.add_prefix('row_')
output
row_0????1
row_1????2
row_2????3
row_3????4
dtype:?int64
又例如
s.add_suffix('_row')
output
0_row????1
1_row????2
2_row????3
3_row????4
dtype:?int64
DataFrame()形式數(shù)據(jù)集而言,add_prefix()方法以及add_suffix()方法是將前綴與后綴添加在列索引處的df?=?pd.DataFrame({'A':?[1,?2,?3,?4],?'B':?[3,?4,?5,?6]})
output
???A??B
0??1??3
1??2??4
2??3??5
3??4??6
示例如下
df.add_prefix("column_")
output
???column_A??column_B
0?????????1?????????3
1?????????2?????????4
2?????????3?????????5
3?????????4?????????6
又例如
df.add_suffix("_column")
output
???A_column??B_column
0?????????1?????????3
1?????????2?????????4
2?????????3?????????5
3?????????4?????????6
clip()方法
clip()方法主要是通過(guò)設(shè)置閾值來(lái)改變數(shù)據(jù)集當(dāng)中的數(shù)值,當(dāng)數(shù)值超過(guò)閾值的時(shí)候,就做出相應(yīng)的調(diào)整data?=?{'col_0':?[9,?-3,?0,?-1,?5],?'col_1':?[-2,?-7,?6,?8,?-5]}
df?=?pd.DataFrame(data)
output
df.clip(lower?=?-4,?upper?=?4)
output
???col_0??col_1
0??????4?????-2
1?????-3?????-4
2??????0??????4
3?????-1??????4
4??????4?????-4
lower和upper分別代表閾值的上限與下限,數(shù)據(jù)集當(dāng)中超過(guò)上限與下限的值會(huì)被替代。filter()方法
pandas當(dāng)中的filter()方法是用來(lái)篩選出特定范圍的數(shù)據(jù)的,示例如下
df?=?pd.DataFrame(np.array(([1,?2,?3],?[4,?5,?6],?[7,?8,?9],?[10,?11,?12])),
??????????????????index=['A',?'B',?'C',?'D'],
??????????????????columns=['one',?'two',?'three'])
output
???one??two??three
A????1????2??????3
B????4????5??????6
C????7????8??????9
D???10???11?????12
我們使用filter()方法來(lái)篩選數(shù)據(jù)
df.filter(items=['one',?'three'])
output
???one??three
A????1??????3
B????4??????6
C????7??????9
D???10?????12
我們還可以使用正則表達(dá)式來(lái)篩選數(shù)據(jù)
df.filter(regex='e$',?axis=1)
output
???one??three
A????1??????3
B????4??????6
C????7??????9
D???10?????12
當(dāng)然通過(guò)參數(shù)axis來(lái)調(diào)整篩選行方向或者是列方向的數(shù)據(jù)
df.filter(like='B',?axis=0)
output
???one??two??three
B????4????5??????6
first()方法
當(dāng)數(shù)據(jù)集當(dāng)中的行索引是日期的時(shí)候,可以通過(guò)該方法來(lái)篩選前面幾行的數(shù)據(jù)
index_1?=?pd.date_range('2021-11-11',?periods=5,?freq='2D')
ts?=?pd.DataFrame({'A':?[1,?2,?3,?4,?5]},?index=index_1)
ts
output
????????????A
2021-11-11??1
2021-11-13??2
2021-11-15??3
2021-11-17??4
2021-11-19??5
我們使用first()方法來(lái)進(jìn)行一些操作,例如篩選出前面3天的數(shù)據(jù)
ts.first('3D')
output
????????????A
2021-11-11??1
2021-11-13??2
isin()方法
isin()方法主要是用來(lái)確認(rèn)數(shù)據(jù)集當(dāng)中的數(shù)值是否被包含在給定的列表當(dāng)中
df?=?pd.DataFrame(np.array(([1,?2,?3],?[4,?5,?6],?[7,?8,?9],?[10,?11,?12])),
??????????????????index=['A',?'B',?'C',?'D'],
??????????????????columns=['one',?'two',?'three'])
df.isin([3,?5,?12])
output
?????one????two??three
A??False??False???True
B??False???True??False
C??False??False??False
D??False??False???True
True,否則就返回Falsedf.plot.area()方法
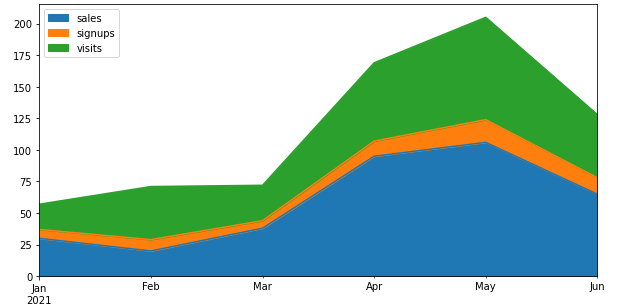
Pandas當(dāng)中通過(guò)一行代碼來(lái)繪制圖表,將所有的列都通過(guò)面積圖的方式來(lái)繪制df?=?pd.DataFrame({
????'sales':?[30,?20,?38,?95,?106,?65],
????'signups':?[7,?9,?6,?12,?18,?13],
????'visits':?[20,?42,?28,?62,?81,?50],
},?index=pd.date_range(start='2021/01/01',?end='2021/07/01',?freq='M'))
ax?=?df.plot.area(figsize?=?(10,?5))
output
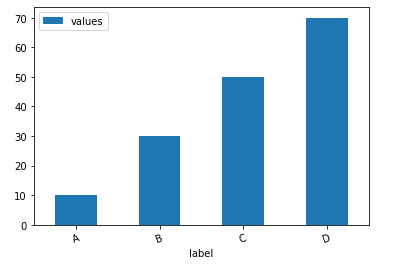
df.plot.bar()方法
下面我們看一下如何通過(guò)一行代碼來(lái)繪制柱狀圖
df?=?pd.DataFrame({'label':['A',?'B',?'C',?'D'],?'values':[10,?30,?50,?70]})
ax?=?df.plot.bar(x='label',?y='values',?rot=20)
output
當(dāng)然我們也可以根據(jù)不同的類(lèi)別來(lái)繪制柱狀圖
age?=?[0.1,?17.5,?40,?48,?52,?69,?88]
weight?=?[2,?8,?70,?1.5,?25,?12,?28]
index?=?['A',?'B',?'C',?'D',?'E',?'F',?'G']
df?=?pd.DataFrame({'age':?age,?'weight':?weight},?index=index)
ax?=?df.plot.bar(rot=0)
output
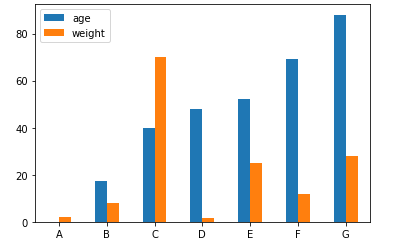
當(dāng)然我們也可以橫向來(lái)繪制圖表
ax?=?df.plot.barh(rot=0)
output
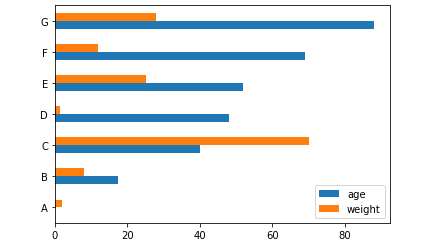
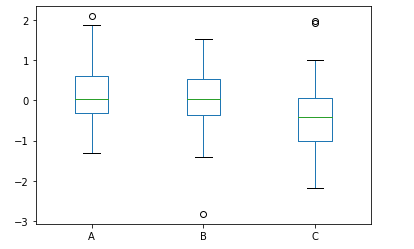
df.plot.box()方法
我們來(lái)看一下箱型圖的具體的繪制,通過(guò)pandas一行代碼來(lái)實(shí)現(xiàn)
data?=?np.random.randn(25,?3)
df?=?pd.DataFrame(data,?columns=list('ABC'))
ax?=?df.plot.box()
output
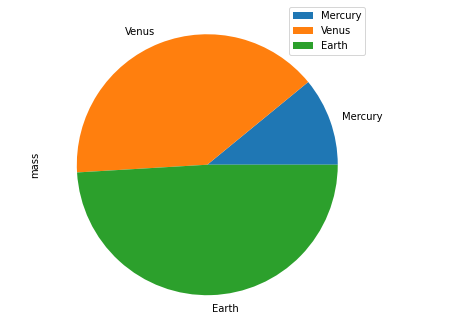
df.plot.pie()方法
接下來(lái)是餅圖的繪制
df?=?pd.DataFrame({'mass':?[1.33,?4.87?,?5.97],
???????????????????'radius':?[2439.7,?6051.8,?6378.1]},
??????????????????index=['Mercury',?'Venus',?'Earth'])
plot?=?df.plot.pie(y='mass',?figsize=(8,?8))
output
往期精彩回顧 本站qq群554839127,加入微信群請(qǐng)掃碼: