
HR-Former | 隨遲但到,HRNet+Transformer輕裝歸來(非常值得學(xué)習(xí)!!!)


本文提出了一種高分辨率Transformer(HRT),它可以通過學(xué)習(xí)高分辨率表征來完成密集的預(yù)測任務(wù),而原來的Vision Transformer學(xué)習(xí)的則是低分辨率表征,同時具有很高的內(nèi)存和計(jì)算成本。
作者在高分辨率卷積網(wǎng)絡(luò)(HRNet)中分別引入的多分辨率并行設(shè)計(jì),以及l(fā)ocal-window self-attention,在小的非重疊圖像窗口上執(zhí)行self-attention,以提高內(nèi)存和計(jì)算效率。此外,在FFN中引入了卷積操作,以在斷開的圖像窗口之間交換信息。
作者實(shí)驗(yàn)證明了HRT在人體姿態(tài)估計(jì)和語義分割任務(wù)中的有效性,HRT在COCO姿態(tài)估計(jì)上比Swin Transformer少了50%的參數(shù)和30%的FLOPs,精度比Swin Transformer高出1.3%AP。
1簡介
Vision Transformer (ViT)在ImageNet分類任務(wù)中顯示了良好的性能。后續(xù)的許多工作通過知識蒸餾、采用更深層次的體系結(jié)構(gòu)、直接引入卷積運(yùn)算、重新設(shè)計(jì)輸入圖像Tokens等來提高分類精度。此外,一些研究試圖將該Transformer擴(kuò)展到更廣泛的視覺任務(wù),如目標(biāo)檢測、語義分割、姿態(tài)估計(jì)、視頻理解等。本文主要研究密集預(yù)測任務(wù)的Transformer,包括姿態(tài)估計(jì)和語義分割。
Vision Transformer將圖像分割為大小為16×16的圖像patches序列,然后提取每個圖像patch的特征表示。因此,Vision Transformer的輸出表示失去了精確密集預(yù)測所必需的細(xì)粒度空間細(xì)節(jié)。Vision Transformer僅輸出單尺度特征表示,因此缺乏處理多尺度變化的能力。為了減少特征粒度的損失并對多尺度變化進(jìn)行建模,作者提出了高分辨率Transformer (HRT),它包含更豐富的空間信息,并為密集預(yù)測構(gòu)建多分辨率表示。
高分辨率 Transformer 采用了HRNet中的多分辨率并行設(shè)計(jì)。
首先,HRT在stem和第一階段都采用了卷積(多個研究表明卷積在早期表現(xiàn)較好); 其次,HRT在整個過程中使用并行的中分辨率和低分辨率流維護(hù)高分辨率流,以幫助提高高分辨率表示(利用不同分辨率的特征圖,HRT能夠模擬多尺度變化); 最后,HRT通過多尺度融合模塊交換多分辨率特征信息,實(shí)現(xiàn)短距離和長距離注意力的混合。
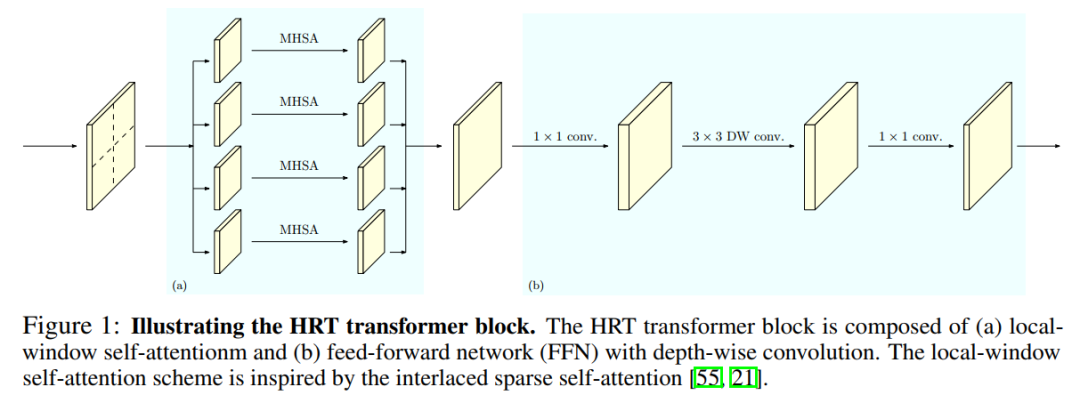
在每個分辨率下,采用局部窗口自注意力機(jī)制來降低內(nèi)存和計(jì)算復(fù)雜度。作者將表示映射劃分為一組不重疊的小圖像窗口,并在每個圖像窗口中分別執(zhí)行自注意力。這就降低了內(nèi)存和計(jì)算復(fù)雜度,從二次到線性的空間大小。
作者進(jìn)一步在局部窗口自注意力后的前饋網(wǎng)絡(luò)(FFN)中引入3×3深度卷積,以在局部窗口自注意力過程中斷開的圖像窗口之間交換信息。這有助于擴(kuò)大感受野,并對密集的預(yù)測任務(wù)至關(guān)重要。
圖1顯示了HRT Transformer Block的詳細(xì)信息。
作者進(jìn)行了圖像分類、姿態(tài)估計(jì)和語義分割任務(wù)的實(shí)驗(yàn),并在各種 Baseline 上取得了競爭性的性能。例如,與DeiT-B相比,HRT-B在ImageNet分類上獲得了+1.0%的Top-1精度,參數(shù)減少了40%,F(xiàn)LOPs減少了20%。在COCO val上,HRT-B比HRNet-W48增加0.9% AP,參數(shù)減少32%,F(xiàn)LOPs減少19%。在PASCAL-Context test和COCO-Stuff test中,HRT-B+OCR分別比HRNet-W48+OCR增加了+1.2%和+2.0% mIoU,參數(shù)減少了25%,F(xiàn)LOPs略多。
2相關(guān)工作
2.1 Vision Transformer
隨著Vision Transformer 和 Data-efficient image Transformer (DeiT)的成功,人們提出了各種技術(shù)來提高Vision Transformer的精度。在最近的改進(jìn)中,如多尺度特性層次結(jié)構(gòu)和合并卷積的有效性已經(jīng)得到驗(yàn)證。
例如,MViT、PVT和Swin按照典型卷積架構(gòu)(如ResNet-50)的空間配置將多尺度特征層次引入Transformer。與之不同的是HRT利用HRNet啟發(fā)的多分辨率并行設(shè)計(jì),融合了多尺度特征層次。
CvT、CeiT 和 LocalViT 通過在自注意力或FFN中插入深度卷積來增強(qiáng) Transformer 的局部特征的魯棒性。在HRT中插入卷積的目的是不同的,除了增強(qiáng)局部特征的魯棒性,它還確保了跨非重疊窗口的信息交換。
先前也有一些研究提出了類似的局部自注意力方案用于圖像分類。它們在卷積后構(gòu)造重疊的局部窗口,計(jì)算量大。本文提出應(yīng)用局部窗口自注意力方案將輸入特征映射劃分為非重疊窗口。然后在每個窗口內(nèi)獨(dú)立應(yīng)用自注意力,從而顯著提高效率。
有研究表明,提高Vision Transformer 輸出的表示的空間分辨率對語義分割很重要。而HRT通過利用多分辨率并行Transformer 方案,為解決Vision Transformer的低分辨率問題提供了方法。
2.2 高分辨率CNN的密集預(yù)測
高分辨率卷積算法在姿態(tài)估計(jì)和語義分割方面都取得了很大的成功。在高分辨率卷積神經(jīng)網(wǎng)絡(luò)的開發(fā)中,開發(fā)了 3 種主要方法,包括:
應(yīng)用 dilated convolutions 去除一些 down-sample layers ; 用解碼器從低分辨率表示中恢復(fù)高分辨率表示; 在整個網(wǎng)絡(luò)中保持高分辨率表示。
本文的HRT屬于第3中方法,同時保留了vision transformer和HRNet的優(yōu)點(diǎn)。
3High-Resolution Transformer
3.1 多分辨率并聯(lián)Transformer
遵循HRNet的設(shè)計(jì),從高分辨率卷積作為第一階段,逐步添加高分辨率到低分辨率的流作為新的階段。多分辨率流是并行連接的。主體由一系列的階段組成。在每個階段,每個分辨率流的特征表示分別用多個Transformer Block 進(jìn)行更新,并通過卷積多尺度融合模塊進(jìn)行跨分辨率信息的重復(fù)交換。
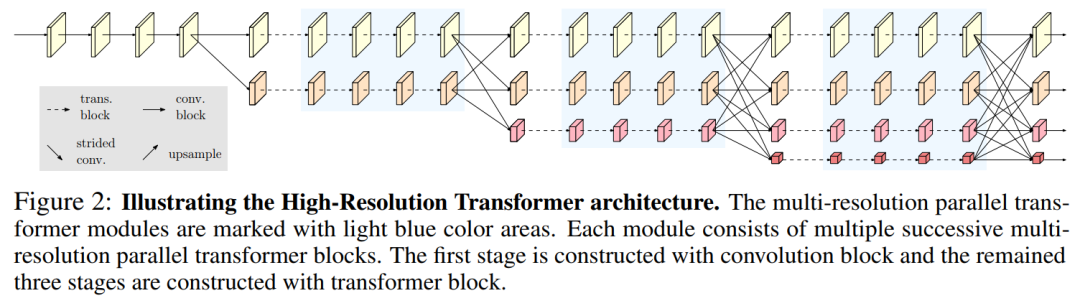
圖2說明了整個HRT體系結(jié)構(gòu)。卷積多尺度融合模塊的設(shè)計(jì)完全遵循HRNet。
3.2 Local-window Self-Attention
將Feature map 劃分為一組不重疊的小窗口:,其中每個窗口的大小為K × K。然后在每個窗口內(nèi)獨(dú)立執(zhí)行多頭自注意力(MHSA)。第p個窗口的多頭自注意力公式為:
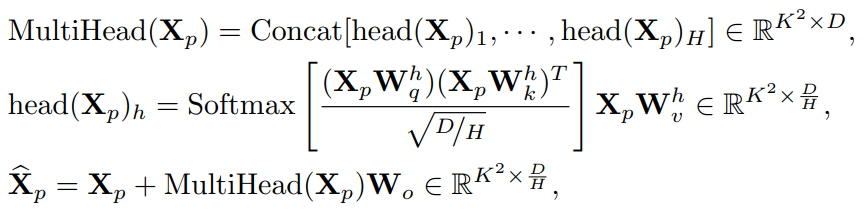
其中, , ,和()。H表示Head數(shù),D表示通道數(shù),N表示輸入分辨率,表示MHSA的輸出表示。作者還在模型中引入的相對位置嵌入方案,將相對位置信息融合到局部窗口的自注意力中。
MHSA在每個窗口中聚合信息,將它們合并以計(jì)算輸出:
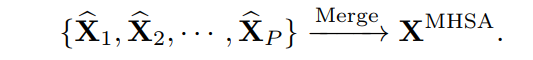
圖1的左邊部分說明了局部窗口自注意力如何更新2D輸入表示,其中多頭自注意在每個窗口中獨(dú)立操作。
3.3 FFN with depth-wise convolution
局部窗口自注意力對非重疊窗口分別執(zhí)行自注意力。窗戶之間沒有信息交換。為了解決這個問題,作者在Vision Transformer 中形成FFN的2個點(diǎn)MLP之間添加了一個3×3深度卷積:。圖1的右半部分展示了具有3×3深度卷積的FFN如何更新2D輸入表示的示例。
3.4 ? Representation head 設(shè)計(jì)
如圖2所示,HRT的輸出由4個不同分辨率的Feature map組成。
ImageNet分類:將4倍下采樣的特征圖送到bottleneck 中,輸出通道分別更改為128、256、512和1024。然后,應(yīng)用 ?strided convolutions ?來融合它們,輸出具有2048通道的最低分辨率的特征圖。最后,應(yīng)用一個全局平均池化操作,然后是最終分類器; 姿態(tài)估計(jì):只在最高分辨率的特征圖上應(yīng)用回歸Head; 語義分割:將語義分割頭應(yīng)用于級聯(lián)表示上,首先將所有低分辨率表示上采樣到最高分辨率,然后將它們級聯(lián)在一起。
3.5 Instantiation
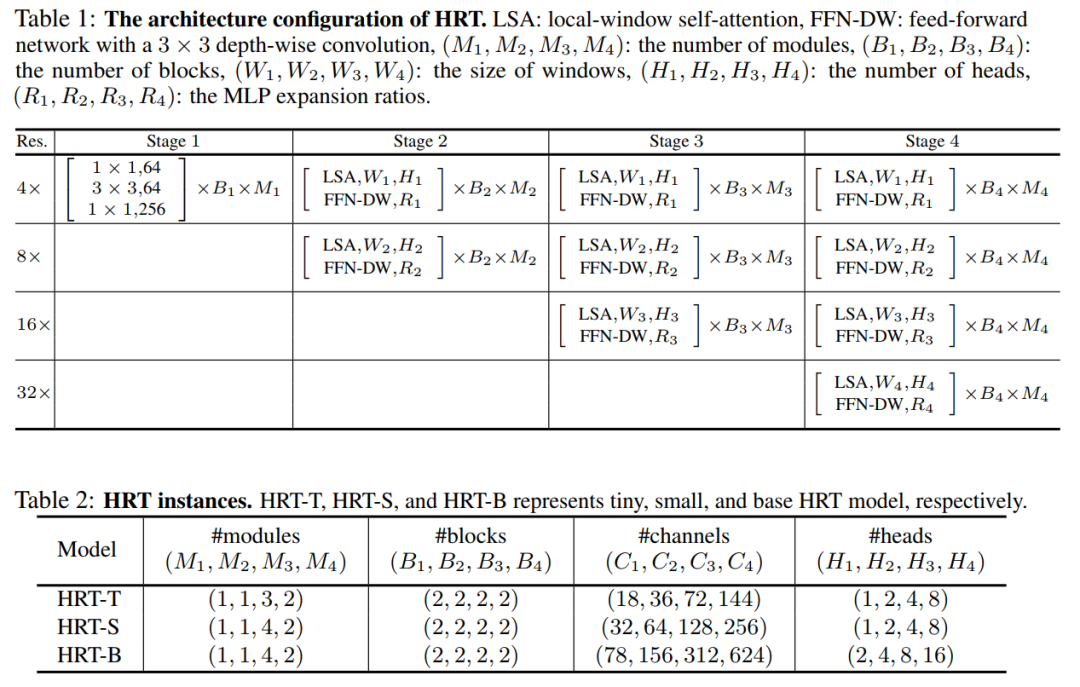
在表1中說明了HRT的總體架構(gòu)配置。
作者用(M1, M2, M3, M4)和(B1, B2, B3, B4)分別表示{state1, stage2, stage3, stage4}的模塊數(shù)和塊數(shù);用(C1, C2, C3, C4), (H1, H2, H3, H4)和(R1, R2, R3, R4)來表示不同分辨率下Transformer Block的通道數(shù),Head數(shù)和MLP膨脹比。
按照原始的HRNet保持第一階段不變,并使用Bottleneck作為基本的構(gòu)建塊。將Transformer Block應(yīng)用于其他階段,每個Transformer Block由一個局部窗口自注意力和一個具有3x3深度卷積的FFN組成。
為了簡單起見,在表1中沒有包含卷積多尺度融合模塊。在實(shí)現(xiàn)中默認(rèn)將4個分辨率流上的窗口大小設(shè)置為(7,7,7,7)。表2展示了3個不同的HRT實(shí)例的配置細(xì)節(jié),其中所有模型的MLP膨脹比(R1,R2,R3,R4)都被設(shè)置為(4,4,4,4)。
3.6 Analysis
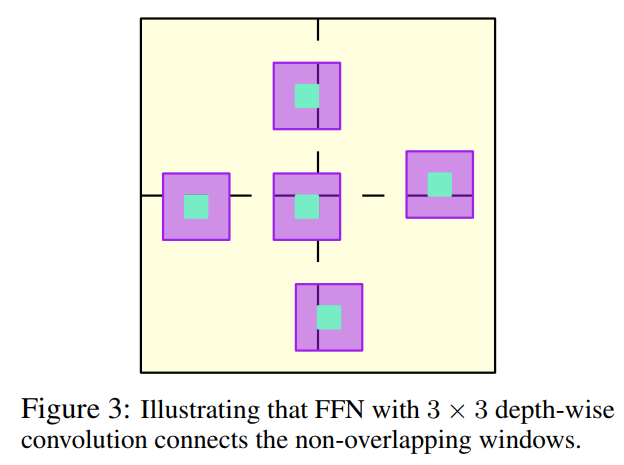
3×3深度卷積的好處有2個:
增強(qiáng)局部性; 支持跨窗口的交互。
在圖3中說明了具有深度卷積的FFN如何能夠?qū)⒔换U(kuò)展到非重疊的局部窗口之外,并對它們之間的關(guān)系建模。因此,結(jié)合局部窗口自注意力和3×3深度卷積的FFN,可以構(gòu)建出顯著提高內(nèi)存和計(jì)算效率的HRT Transformer Block。
4實(shí)驗(yàn)
4.1 姿態(tài)估計(jì)
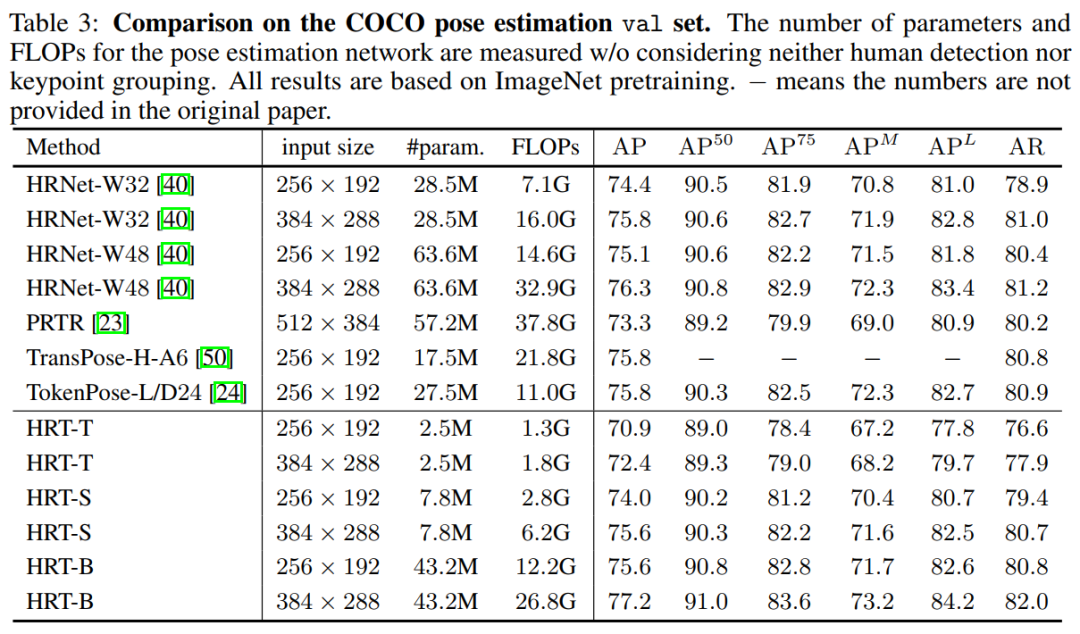

表3在COCO val上將HRT與具有代表性的卷積方法進(jìn)行了比較,如HRNet和最近的幾種變換方法,包括PRTR、TransPose-H-A6和TokenPose-L/D24。與384x288的HRNet-W48相比,HRT-B的增益為0.9%,參數(shù)減少了32%,F(xiàn)LOPs數(shù)減少了19%。因此,HRT-B已經(jīng)達(dá)到77.2%的w/o使用任何先進(jìn)的技術(shù),如利用UDP或DARK方案HRT-B可以實(shí)現(xiàn)更好的結(jié)果。
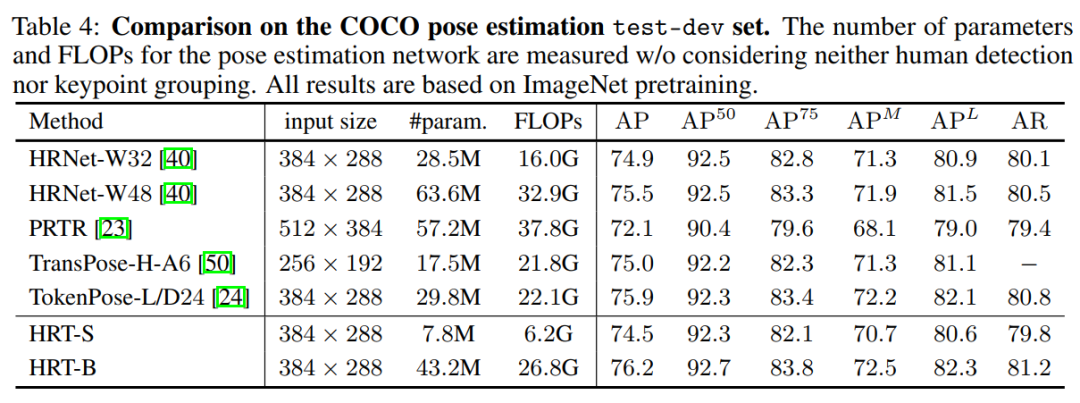
作者還在表4中根據(jù)COCO測試集上的比較。HRT-B的性能比HRNet-W48高0.7%左右,參數(shù)和FLOPs更少。圖4顯示了在COCO val集合上進(jìn)行人體姿態(tài)估計(jì)的一些示例結(jié)果。
4.2 語義分割
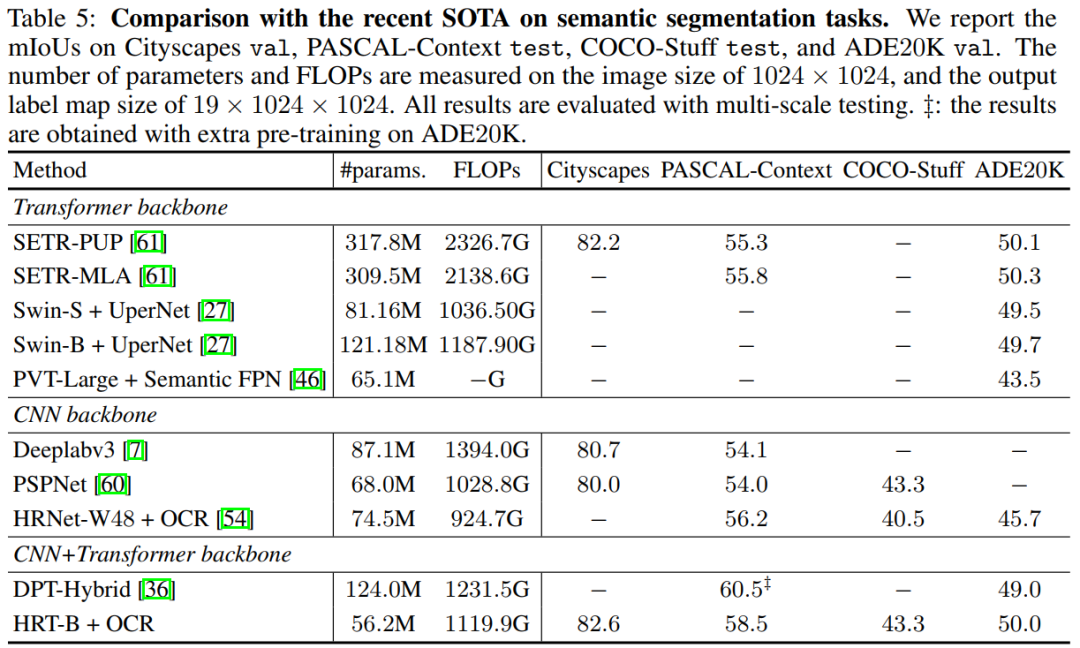

表5顯示了Cityscapes val的結(jié)果。作者選擇使用HRT+OCR作為語義分割架構(gòu)。作者將本文方法與幾種知名的基于Vision Transformer的方法和基于CNN的方法進(jìn)行了比較。
具體來說,SETR-PUP和SETRMLA使用ViT-Large作為Backbone。DPT-Hybrid使用 ?ViT-Hybrid由一個ResNet-50和12個Transformer層組成。ViT-Large和ViT-Hybrid都是用ImageNet-21k上預(yù)訓(xùn)練的權(quán)值進(jìn)行初始化的,在ImageNet上它們的Top1精度都達(dá)到了85:1%。
DeepLabv3和PSPNet是基于擴(kuò)展的ResNet-101,輸出stride為8。從表5的第4列可以看出,HRT+OCR整體上具有競爭力。例如,HRT-B+OCR與SETR-PUP在節(jié)省70%的參數(shù)和50%的FLOPs數(shù)的同時實(shí)現(xiàn)了相當(dāng)?shù)男阅堋?/p>
4.3 圖像分類
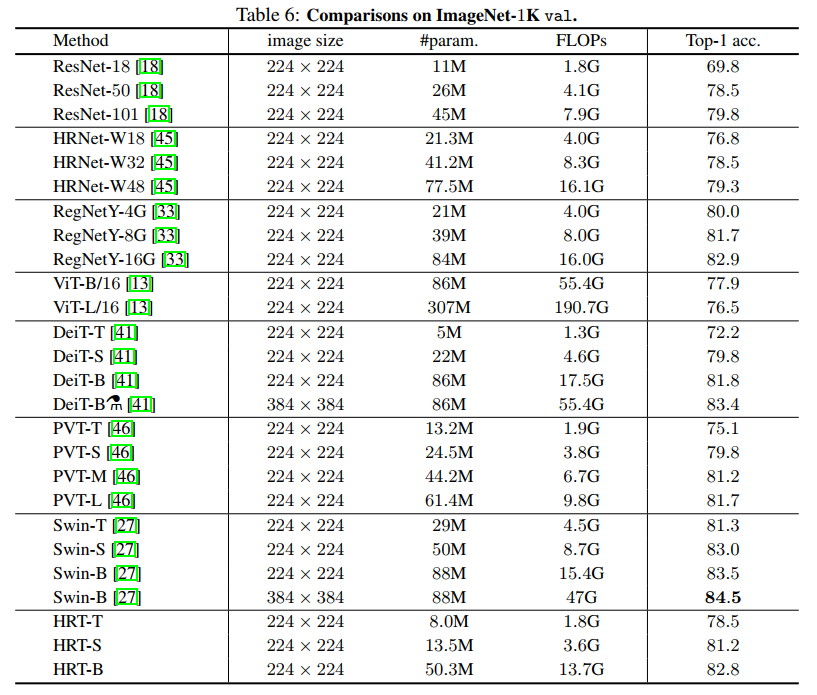
作者將HRT與表6中一些代表性的CNN方法和ViT Transformer方法進(jìn)行了比較,其中所有方法僅在 ?ImageNet-1K ?上訓(xùn)練。為了公平性, ?ViT-Large大數(shù)據(jù)集(如ImageNet-21K)的結(jié)果不包括在內(nèi)。從表6可以看出,HRT取得了具有競爭力的效果。例如,HRT-B比DeiT-B增加了1.0%,同時節(jié)省了近40%的參數(shù)和20%的FLOPs。
4.4 消融實(shí)驗(yàn)
1. FFN中3×3深度卷積的影響
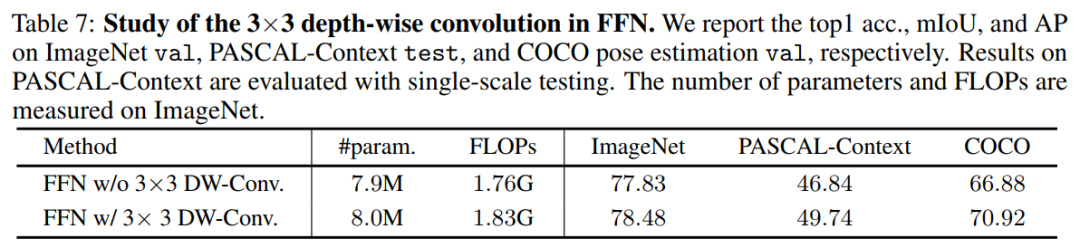
在表7中研究了基于HRT-T的FFN內(nèi)的3×3深度卷積的影響。作者觀察到,在FFN中應(yīng)用3×3深度卷積顯著提高了在多個任務(wù)上的性能,包括ImageNet分類、pascal上下文分割和COCO姿態(tài)估計(jì)。
例如,在ImageNet、PASCAL-Context和COCO上,HRT-T+FFN w/ 3×3深度卷積比HRT-T+FFN w/ 3× 3深度卷積分別高出0.65%、2.9%和4.04%。
2. FFN中移動窗口方案與3×3深度卷積的影響
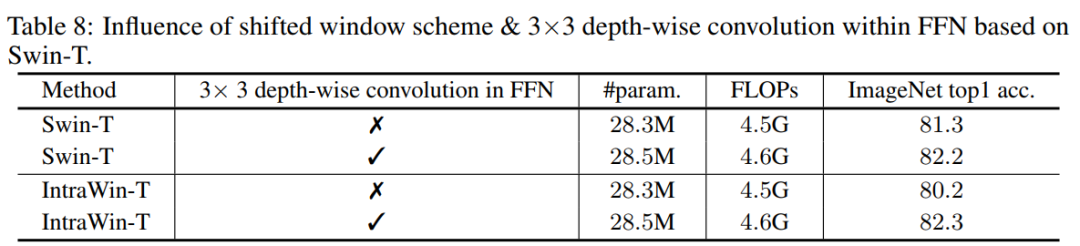
作者將本文方法與表8中Swin Transformer的移位窗口方案進(jìn)行了比較。為了進(jìn)行公平的比較,按照與Swin Transformer相同的架構(gòu)配置構(gòu)造了一個Intra-Window transformer架構(gòu),只是不應(yīng)用移位的窗口模式。
可以看到,在FFN中應(yīng)用3×3深度卷積可以改善Swin-T和IntrawinT。令人驚訝的是,當(dāng)在FFN內(nèi)配備3× 3深度卷積時,Intrawin-T的性能甚至超過了Swin Transformer。
3. 移位窗口方案vs . 3×3基于HRT-T的FFN深度卷積

在表9中,比較了FFN方案中的3×3深度卷積與基于HRT-T的移位窗口方案。結(jié)果表明,在FFN中應(yīng)用3×3深度卷積在所有不同任務(wù)中的性能顯著優(yōu)于移位窗口方案。
4. 與ViT、DeiT和Swin在姿態(tài)估計(jì)上的比較
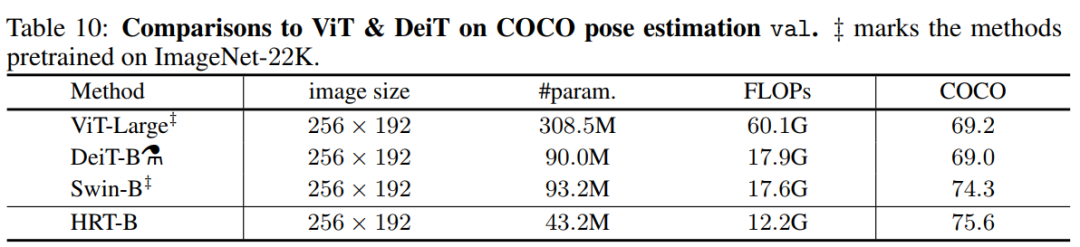
在表10中比較了著名的Transformer模型,包括ViT-Large, DeiT-B和Swin-B的COCO位姿估計(jì)結(jié)果。值得注意的是,ViT-Large和Swin-B都是事先在ImageNet21K上進(jìn)行預(yù)訓(xùn)練,然后在ImageNet1K上進(jìn)行微調(diào),分別達(dá)到85.1%和86.4%的top-1準(zhǔn)確率。DeiT-B在ImageNet1K上訓(xùn)練1000個Epoch,達(dá)到85.2%的top-1精度。對于三種方法,使用反卷積模塊按照SimpleBaseline對編碼器的輸出表示進(jìn)行上采樣。表10的第4列和第5列列出了參數(shù)和flop的數(shù)量。根據(jù)表10的結(jié)果,可以看到HRT-B在參數(shù)和FLOPs更少的情況下比這3種方法獲得了更好的性能。
5. 相比HRNet
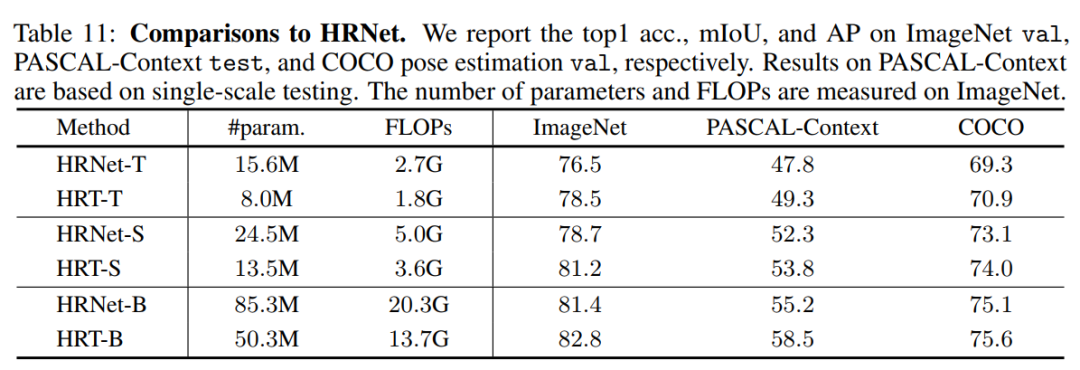
作者將HRT與具有幾乎相同架構(gòu)配置的卷積HRNet進(jìn)行比較,方法是將所有的Transformer塊替換為由2個3x3卷積組成的傳統(tǒng)基本塊。表11顯示了ImageNet、PASCAL-Context和COCO的對比結(jié)果。
可以觀察到,HRT在模型和計(jì)算復(fù)雜度更低的情況下,在各種配置下都顯著優(yōu)于HRNet。例如,HRT-T在3個任務(wù)中分別比HRNet-T高出2.0%、1.5%和1.6%,而只需要大約50%的參數(shù)和FLOPs。總之,HRT通過利用Transformer的好處獲得了更好的性能。
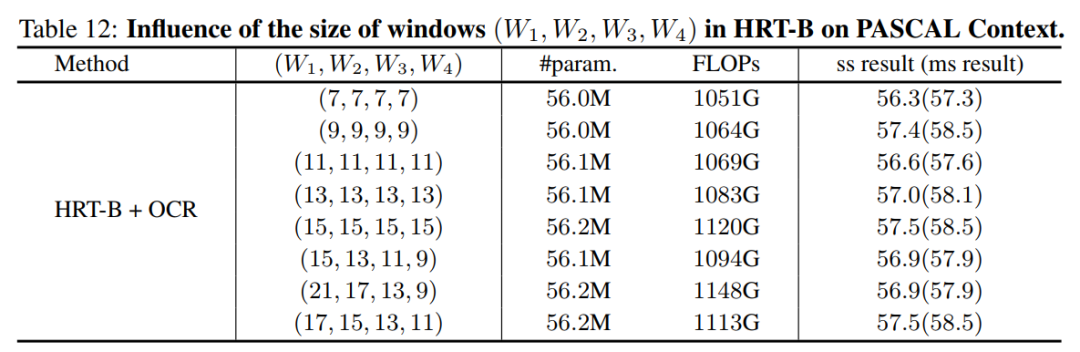
6. 窗口尺寸
作者還比較了在不同分辨率下不同窗口大小的語義分割任務(wù)的結(jié)果。使用,用stride表示不同分辨率的feature map關(guān)聯(lián)的窗口大小4,8,16,32。作者為更高分辨率的分支選擇更大的窗口大小,因此,有。根據(jù)這些結(jié)果,可以看到,應(yīng)用較大的窗口可以提高性能,而在不同分辨率下應(yīng)用不同的窗口大小沒有太大的區(qū)別。
5參考
[1].HRFormer: High-Resolution Transformer for Dense Prediction
6推薦閱讀

What?UFO!| UFO-ViT用X-Norm讓你的Transformer模型回歸線性復(fù)雜度

詳細(xì)解讀 | 如何改進(jìn)YOLOv3使其更好應(yīng)用到小目標(biāo)檢測(比YOLO V4高出4%)

Kaggle第一人 | 詳細(xì)解讀2021Google地標(biāo)識別第一名解決方案(建議全文背誦)
長按掃描下方二維碼添加小助手。
可以一起討論遇到的問題
聲明:轉(zhuǎn)載請說明出處
掃描下方二維碼關(guān)注【集智書童】公眾號,獲取更多實(shí)踐項(xiàng)目源碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!
