
聊聊 APM 及介紹下我們的內(nèi)部實(shí)現(xiàn)
以下文章來源于武培軒,回復(fù)資源獲取資料
最近幾個(gè)月,我們?cè)诠鹃_發(fā)了 APM 系統(tǒng),借這個(gè)契機(jī),給大家分享一下。當(dāng)然,我不是來介紹項(xiàng)目的,而是借我們的項(xiàng)目給大家介紹 APM 系統(tǒng)相關(guān)內(nèi)容。
本文來說說什么是 APM 系統(tǒng),也就是大家平時(shí)說的監(jiān)控系統(tǒng),以及怎么實(shí)現(xiàn)一個(gè) APM 系統(tǒng)。因?yàn)橐恍┨厥獾脑颍以谖闹袝?huì)使用 Dog 作為我們的系統(tǒng)名稱進(jìn)行介紹。
我們?yōu)?Dog 規(guī)劃的目標(biāo)是接入公司的大部分應(yīng)用,預(yù)計(jì)每秒處理 500MB-1000MB 的數(shù)據(jù),單機(jī)每秒 100MB 左右,使用多臺(tái)普通的 AWS EC2。
因?yàn)楸疚牡暮芏嘧x者供職的公司不一定有比較全面的 APM 系統(tǒng),所以我盡量照顧更多讀者的閱讀感受,會(huì)在有些內(nèi)容上啰嗦一些,希望大家可以理解。我會(huì)在文中提到 prometheus、grafana、cat、pinpoint、skywalking、zipkin 等一系列工具,如果你沒有用過也不要緊,我會(huì)充分考慮到這一點(diǎn)。
本文預(yù)設(shè)的一些背景:Java 語言、web 服務(wù)、每個(gè)應(yīng)用有多個(gè)實(shí)例、以微服務(wù)方式部署。另外,從文章的可閱讀性上考慮,我假設(shè)每個(gè)應(yīng)用的不同實(shí)例分布在不同的 IP 上,可能你的應(yīng)用場(chǎng)景不一定是這樣的。
APM 簡介
APM 通常認(rèn)為是 Application Performance Management 的簡寫,它主要有三個(gè)方面的內(nèi)容,分別是 Logs(日志)、Traces(鏈路追蹤) 和 Metrics(報(bào)表統(tǒng)計(jì))。以后大家接觸任何一個(gè) APM 系統(tǒng)的時(shí)候,都可以從這三個(gè)方面去分析它到底是什么樣的一個(gè)系統(tǒng)。
有些場(chǎng)景中,APM 特指上面三個(gè)中的 Metrics,我們這里不去討論這個(gè)概念
這節(jié)我們先對(duì)這 3 個(gè)方面進(jìn)行介紹,同時(shí)介紹一下這 3 個(gè)領(lǐng)域里面一些常用的工具。
1、首先 Logs 最好理解,就是對(duì)各個(gè)應(yīng)用中打印的 log 進(jìn)行收集和提供查詢能力。
Logs 系統(tǒng)的重要性不言而喻,通常我們?cè)谂挪樘囟ǖ恼?qǐng)求的時(shí)候,是非常依賴于上下文的日志的。
以前我們都是通過 terminal 登錄到機(jī)器里面去查 log(我好幾年都是這樣過來的),但是由于集群化和微服務(wù)化的原因,繼續(xù)使用這種方式工作效率會(huì)比較低,因?yàn)槟憧赡苄枰卿浐脦着_(tái)機(jī)器搜索日志才能找到需要的信息,所以需要有一個(gè)地方中心化存儲(chǔ)日志,并且提供日志查詢。
Logs 的典型實(shí)現(xiàn)是 ELK (ElasticSearch、Logstash、Kibana),三個(gè)項(xiàng)目都是由 Elastic 開源,其中最核心的就是 ES 的儲(chǔ)存和查詢的性能得到了大家的認(rèn)可,經(jīng)受了非常多公司的業(yè)務(wù)考驗(yàn)。
Logstash 負(fù)責(zé)收集日志,然后解析并存儲(chǔ)到 ES。通常有兩種比較主流的日志采集方式,一種是通過一個(gè)客戶端程序 FileBeat,收集每個(gè)應(yīng)用打印到本地磁盤的日志,發(fā)送給 Logstash;另一種則是每個(gè)應(yīng)用不需要將日志存儲(chǔ)到磁盤,而是直接發(fā)送到 Kafka 集群中,由 Logstash 來消費(fèi)。
Kibana 是一個(gè)非常好用的工具,用于對(duì) ES 的數(shù)據(jù)進(jìn)行可視化,簡單來說,它就是 ES 的客戶端。

我們回過頭來分析 Logs 系統(tǒng),Logs 系統(tǒng)的數(shù)據(jù)來自于應(yīng)用中打印的日志,它的特點(diǎn)是數(shù)據(jù)量可能很大,取決于應(yīng)用開發(fā)者怎么打日志,Logs 系統(tǒng)需要存儲(chǔ)全量數(shù)據(jù),通常都要支持至少 1 周的儲(chǔ)存。
每條日志包含 ip、thread、class、timestamp、traceId、message 等信息,它涉及到的技術(shù)點(diǎn)非常容易理解,就是日志的存儲(chǔ)和查詢。
使用也非常簡單,排查問題時(shí),通常先通過關(guān)鍵字搜到一條日志,然后通過它的 traceId 來搜索整個(gè)鏈路的日志。
題外話,Elastic 其實(shí)除了 Logs 以外,也提供了 Metrics 和 Traces 的解決方案,不過目前國內(nèi)用戶主要是使用它的 Logs 功能。
2、我們?cè)賮砜纯?Traces 系統(tǒng),它用于記錄整個(gè)調(diào)用鏈路。
前面介紹的 Logs 系統(tǒng)使用的是開發(fā)者打印的日志,所以它是最貼近業(yè)務(wù)的。而 Traces 系統(tǒng)就離業(yè)務(wù)更遠(yuǎn)一些了,它關(guān)注的是一個(gè)請(qǐng)求進(jìn)來以后,經(jīng)過了哪些應(yīng)用、哪些方法,分別在各個(gè)節(jié)點(diǎn)耗費(fèi)了多少時(shí)間,在哪個(gè)地方拋出的異常等,用來快速定位問題。
經(jīng)過多年的發(fā)展,Traces 系統(tǒng)雖然在服務(wù)端的設(shè)計(jì)很多樣,但是客戶端的設(shè)計(jì)慢慢地趨于統(tǒng)一,所以有了 OpenTracing 項(xiàng)目,我們可以簡單理解為它是一個(gè)規(guī)范,它定義了一套 API,把客戶端的模型固化下來。當(dāng)前比較主流的 Traces 系統(tǒng)中,Jaeger、SkyWalking 是使用這個(gè)規(guī)范的,而 Zipkin、Pinpoint 沒有使用該規(guī)范。限于篇幅,本文不對(duì) OpenTracing 展開介紹。
下面這張圖是我畫的一個(gè)請(qǐng)求的時(shí)序圖:
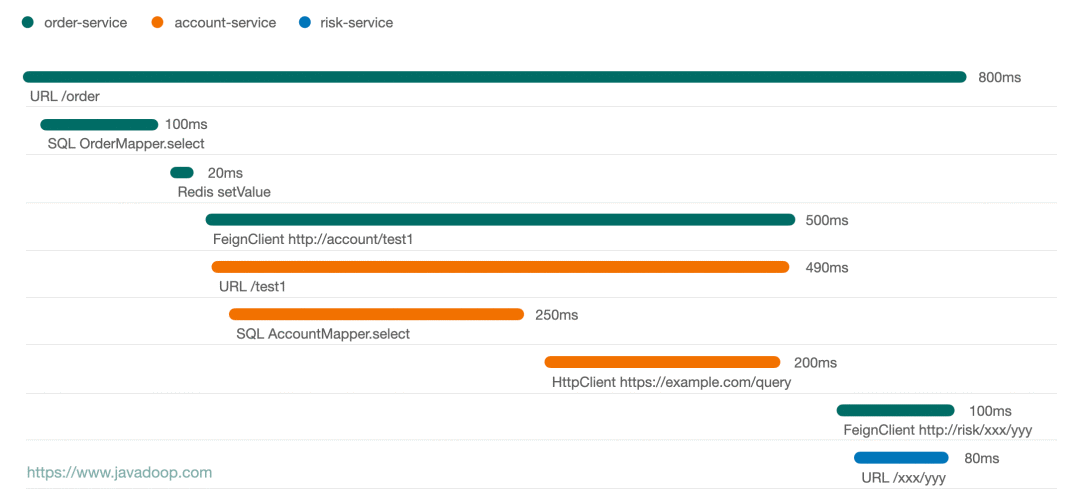
從上面這個(gè)圖中,可以非常方便地看出,這個(gè)請(qǐng)求經(jīng)過了 3 個(gè)應(yīng)用,通過線的長短可以非常容易看出各個(gè)節(jié)點(diǎn)的耗時(shí)情況。通常點(diǎn)擊某個(gè)節(jié)點(diǎn),我們可以有更多的信息展示,比如點(diǎn)擊 HttpClient 節(jié)點(diǎn)我們可能有 request 和 response 的數(shù)據(jù)。
下面這張圖是 Skywalking 的圖,它的 UI 也是蠻好的:

SkyWalking 在國內(nèi)應(yīng)該比較多公司使用,是一個(gè)比較優(yōu)秀的由國人發(fā)起的開源項(xiàng)目,已進(jìn)入 Apache 基金會(huì)。
另一個(gè)比較好的開源 Traces 系統(tǒng)是由韓國人開源的 Pinpoint,它的打點(diǎn)數(shù)據(jù)非常豐富,這里有官方提供的 Live Demo,大家可以去玩一玩。

最近比較火的是由 CNCF(Cloud Native Computing Foundation) 基金會(huì)管理的 Jeager:

當(dāng)然也有很多人使用的是 Zipkin,算是 Traces 系統(tǒng)中開源項(xiàng)目的老前輩了:

上面介紹的是目前比較主流的 Traces 系統(tǒng),在排查具體問題的時(shí)候它們非常有用,通過鏈路分析,很容易就可以看出來這個(gè)請(qǐng)求經(jīng)過了哪些節(jié)點(diǎn)、在每個(gè)節(jié)點(diǎn)的耗時(shí)、是否在某個(gè)節(jié)點(diǎn)執(zhí)行異常等。
雖然這里介紹的幾個(gè) Traces 系統(tǒng)的 UI 不一樣,大家可能有所偏好,但是具體說起來,表達(dá)的都是一個(gè)東西,那就是一顆調(diào)用樹,所以我們要來說說每個(gè)項(xiàng)目除了 UI 以外不一樣的地方。
首先肯定是數(shù)據(jù)的豐富度,你往上拉看 Pinpoint 的樹,你會(huì)發(fā)現(xiàn)它的埋點(diǎn)非常豐富,真的實(shí)現(xiàn)了一個(gè)請(qǐng)求經(jīng)過哪些方法一目了然。
但是這真的是一個(gè)好事嗎?值得大家去思考一下。兩個(gè)方面,一個(gè)是對(duì)客戶端的性能影響,另一個(gè)是服務(wù)端的壓力。
其次,Traces 系統(tǒng)因?yàn)橛邢到y(tǒng)間調(diào)用的數(shù)據(jù),所以很多 Traces 系統(tǒng)會(huì)使用這個(gè)數(shù)據(jù)做系統(tǒng)間的調(diào)用統(tǒng)計(jì),比如下面這個(gè)圖其實(shí)也蠻有用的:

另外,前面說的是某個(gè)請(qǐng)求的完整鏈路分析,那么就引出另一個(gè)問題,我們?cè)趺传@取這個(gè)“某個(gè)請(qǐng)求”,這也是每個(gè) Traces 系統(tǒng)的不同之處。
比如上圖,它是 Pinpoint 的圖,我們看到前面兩個(gè)節(jié)點(diǎn)的圓圈是不完美的,點(diǎn)擊前面這個(gè)圓圈,就可以看出來原因了:
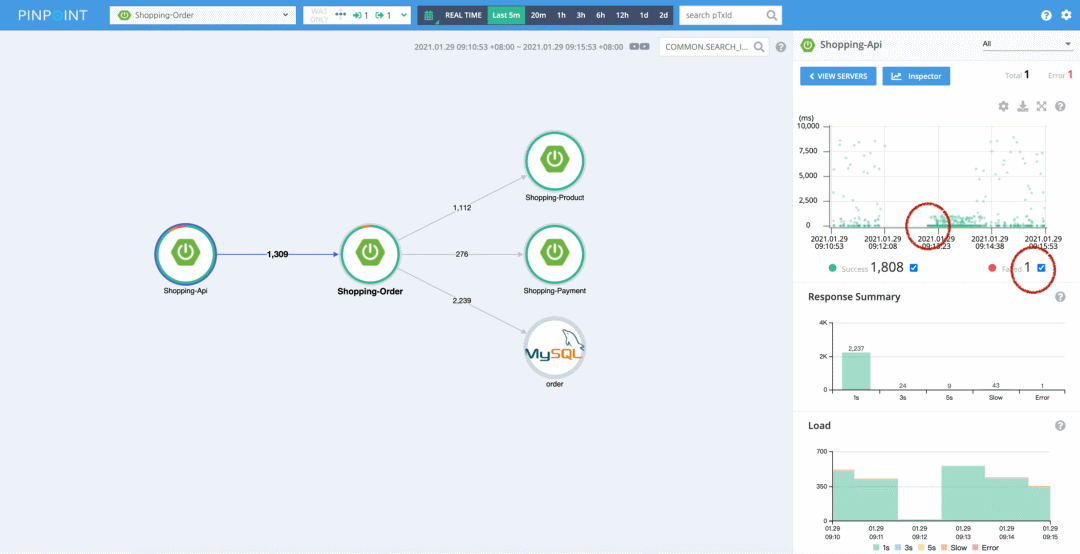
圖中右邊的兩個(gè)紅圈是我加的。我們可以看到在 Shopping-api 調(diào)用 Shopping-order 的請(qǐng)求中,有 1 個(gè)失敗的請(qǐng)求,我們用鼠標(biāo)在散點(diǎn)圖中把這個(gè)紅點(diǎn)框出來,就可以進(jìn)入到 trace 視圖,查看具體的調(diào)用鏈路了。限于篇幅,我這里就不去演示其他 Traces 系統(tǒng)的入口了。
還是看上面這個(gè)圖,我們看右下角的兩個(gè)統(tǒng)計(jì)圖,我們可以看出來在最近 5 分鐘內(nèi) Shopping-api 調(diào)用 Shopping-order 的所有請(qǐng)求的耗時(shí)情況,以及時(shí)間分布。在發(fā)生異常的情況,比如流量突發(fā),這些圖的作用就出來了。
對(duì)于 Traces 系統(tǒng)來說,最有用的就是這些東西了,當(dāng)然大家在使用過程中,可能也發(fā)現(xiàn)了 Traces 系統(tǒng)有很多的統(tǒng)計(jì)功能或者機(jī)器健康情況的監(jiān)控,這些是每個(gè) Traces 系統(tǒng)的差異化功能,我們就不去具體分析了。
3、最后,我們?cè)賮碛懻?Metrics,它側(cè)重于各種報(bào)表數(shù)據(jù)的收集和展示。
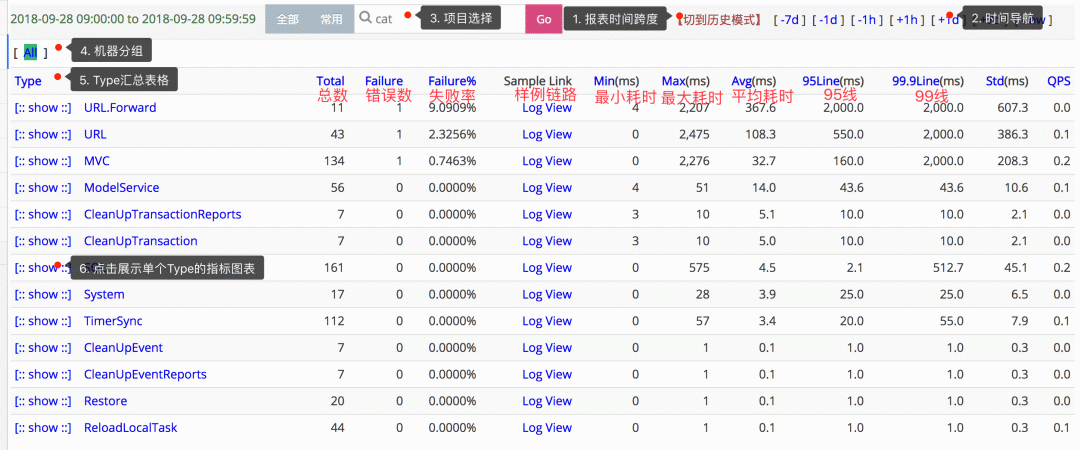
在 Metrics 方面做得比較好的開源系統(tǒng),是大眾點(diǎn)評(píng)開源的 Cat,下面這個(gè)圖是 Cat 中的 transaction 視圖,它展示了很多的我們經(jīng)常需要關(guān)心的統(tǒng)計(jì)數(shù)據(jù):
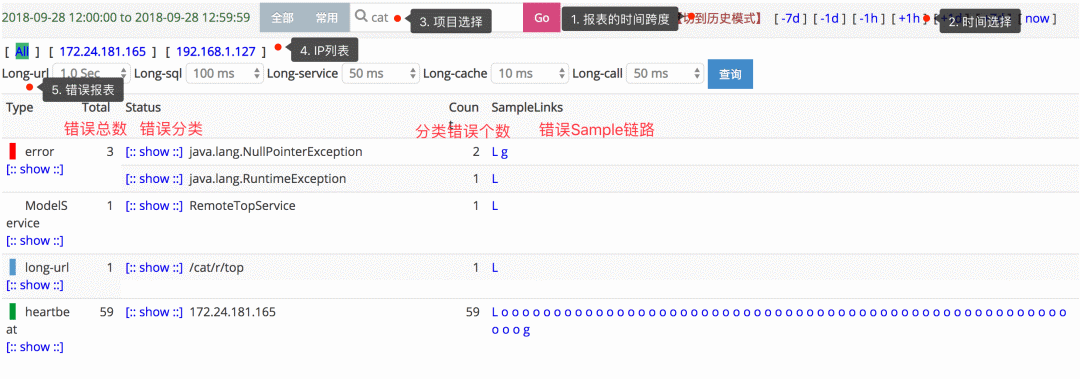
下圖是 Cat 的 problem 視圖,對(duì)我們開發(fā)者來說就太有用了,應(yīng)用開發(fā)者的目標(biāo)就是讓這個(gè)視圖中的數(shù)據(jù)越少越好。
本文之后的內(nèi)容主要都是圍繞著 Metrics 展開的,所以這里就不再展開更多的內(nèi)容了。
另外,說到 APM 或系統(tǒng)監(jiān)控,就不得不提 Prometheus+Grafana 這對(duì)組合,它們對(duì)機(jī)器健康情況、URL 訪問統(tǒng)計(jì)、QPS、P90、P99 等等這些需求,支持得非常好,它們用來做監(jiān)控大屏是非常合適的,但是通常不能幫助我們排查問題,它看到的是系統(tǒng)壓力高了、系統(tǒng)不行了,但不能一下子看出來為啥高了、為啥不行了。
科普:Prometheus 是一個(gè)使用內(nèi)存進(jìn)行存儲(chǔ)和計(jì)算的服務(wù),每個(gè)機(jī)器/應(yīng)用通過 Prometheus 的接口上報(bào)數(shù)據(jù),它的特點(diǎn)是快,但是機(jī)器宕機(jī)或重啟會(huì)丟失所有數(shù)據(jù)。
Grafana 是一個(gè)好玩的東西,它通過各種插件來可視化各種系統(tǒng)數(shù)據(jù),比如查詢 Prometheus、ElasticSearch、ClickHouse、MySQL 等等,它的特點(diǎn)就是酷炫,用來做監(jiān)控大屏再好不過了。
Metrics 和 Traces
因?yàn)楸疚闹笠榻B的我們開發(fā)的 Dog 系統(tǒng)從分類來說,側(cè)重于 Metrics,同時(shí)我們也提供 tracing 功能,所以這里單獨(dú)寫一小節(jié),分析一下 Metrics 和 Traces 系統(tǒng)之間的聯(lián)系和區(qū)別。
使用上的區(qū)別很好理解,Metrics 做的是數(shù)據(jù)統(tǒng)計(jì),比如某個(gè) URL 或 DB 訪問被請(qǐng)求多少次,P90 是多少毫秒,錯(cuò)誤數(shù)是多少等這種問題。而 Traces 是用來分析某次請(qǐng)求,它經(jīng)過了哪些鏈路,比如進(jìn)入 A 應(yīng)用后,調(diào)用了哪些方法,之后可能又請(qǐng)求了 B 應(yīng)用,在 B 應(yīng)用里面又調(diào)用了哪些方法,或者整個(gè)鏈路在哪個(gè)地方出錯(cuò)等這些問題。
不過在前面介紹 Traces 的時(shí)候,我們也發(fā)現(xiàn)這類系統(tǒng)也會(huì)做很多的統(tǒng)計(jì)工作,它也覆蓋了很多的 Metrics 的內(nèi)容。
所以大家先要有個(gè)概念,Metrics 和 Traces 之間的聯(lián)系是非常緊密的,它們的數(shù)據(jù)結(jié)構(gòu)都是一顆調(diào)用樹,區(qū)別在于這顆樹的枝干和葉子多不多。在 Traces 系統(tǒng)中,一個(gè)請(qǐng)求所經(jīng)過的鏈路數(shù)據(jù)是非常全的,這樣對(duì)排查問題的時(shí)候非常有用,但是如果要對(duì) Traces 中的所有節(jié)點(diǎn)的數(shù)據(jù)做報(bào)表統(tǒng)計(jì),將會(huì)非常地耗費(fèi)資源,性價(jià)比太低。而 Metrics 系統(tǒng)就是面向數(shù)據(jù)統(tǒng)計(jì)而生的,所以樹上的每個(gè)節(jié)點(diǎn)我們都會(huì)進(jìn)行統(tǒng)計(jì),所以這棵樹不能太“茂盛”。
我們關(guān)心的其實(shí)是,哪些數(shù)據(jù)值得統(tǒng)計(jì)?首先是入口,其次是耗時(shí)比較大的地方,比如 db 訪問、http 請(qǐng)求、redis 請(qǐng)求、跨服務(wù)調(diào)用等。當(dāng)我們有了這些關(guān)鍵節(jié)點(diǎn)的統(tǒng)計(jì)數(shù)據(jù)以后,對(duì)于系統(tǒng)的健康監(jiān)控就非常容易了。
我這里不再具體去介紹他們的區(qū)別,大家看完本文介紹的 Metrics 系統(tǒng)實(shí)現(xiàn)以后,再回來思考這個(gè)問題會(huì)比較好。
Dog 在設(shè)計(jì)上,主要是做一個(gè) Metrics 系統(tǒng),統(tǒng)計(jì)關(guān)鍵節(jié)點(diǎn)的數(shù)據(jù),另外也提供 trace 的能力,不過因?yàn)槲覀兊臉洳皇呛堋泵ⅰ埃枣溌飞峡赡苁菙鄶嗬m(xù)續(xù)的,中間會(huì)有很多缺失的地帶,當(dāng)然應(yīng)用開發(fā)者也可以加入手動(dòng)埋點(diǎn)來彌補(bǔ)。
Dog 因?yàn)槭枪緝?nèi)部的監(jiān)控系統(tǒng),所以對(duì)于公司內(nèi)部大家會(huì)使用到的中間件相對(duì)是比較確定的,不需要像開源的 APM 一樣需要打很多點(diǎn),我們主要實(shí)現(xiàn)了以下節(jié)點(diǎn)的自動(dòng)打點(diǎn):
http 入口:通過實(shí)現(xiàn)一個(gè) Filter 來攔截所有的請(qǐng)求 MySQL: 通過 Mybatis Interceptor 的方式 Redis: 通過 javassist 增強(qiáng) RedisTemplate 的方式 跨應(yīng)用調(diào)用: 通過代理 feign client 的方式,dubbo、grpc 等方式可能需要通過攔截器 http 調(diào)用: 通過 javassist 為 HttpClient 和 OkHttp 增加 interceptor 的方式 Log 打點(diǎn): 通過 plugin 的方式,將 log 中打印的 error 上報(bào)上來
打點(diǎn)的技術(shù)細(xì)節(jié),就不在這里展開了,主要還是用了各個(gè)框架提供的一些接口,另外就是用到了 javassist 做字節(jié)碼增強(qiáng)。
這些打點(diǎn)數(shù)據(jù)就是我們需要做統(tǒng)計(jì)的,當(dāng)然因?yàn)榇螯c(diǎn)有限,我們的 tracing 功能相對(duì)于專業(yè)的 Traces 系統(tǒng)來說單薄了很多。
Dog 簡介
下面是 DOG 的架構(gòu)圖,客戶端將消息投遞給 Kafka,由 dog-server 來消費(fèi)消息,存儲(chǔ)用到了 Cassandra 和 ClickHouse,后面再介紹具體存哪些數(shù)據(jù)。
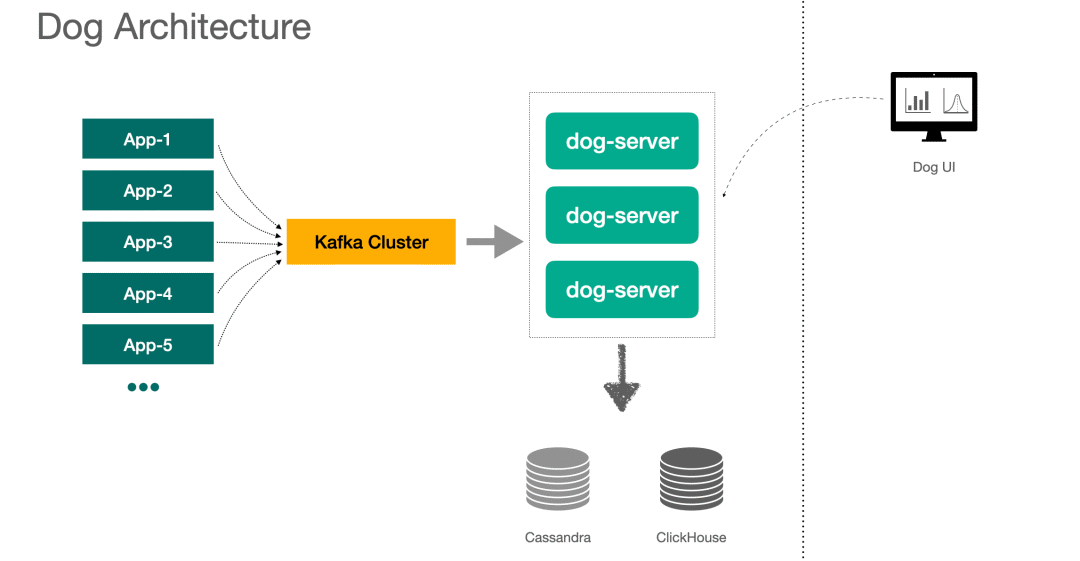
1、也有 APM 系統(tǒng)是不通過消息中間件的,比如 Cat 就是客戶端通過 Netty 連接到服務(wù)端來發(fā)送消息的。
2、Server 端使用了 Lambda 架構(gòu)模式,Dog UI 上查詢的數(shù)據(jù),由每一個(gè) Dog-server 的內(nèi)存數(shù)據(jù)和下游儲(chǔ)存的數(shù)據(jù)聚合而來。
下面,我們簡單介紹下 Dog UI 上一些比較重要的功能,我們之后再去分析怎么實(shí)現(xiàn)相應(yīng)的功能。
注意:下面的圖都是我自己畫的,不是真的頁面截圖,數(shù)值上可能不太準(zhǔn)確
下圖示例 transaction 報(bào)表:
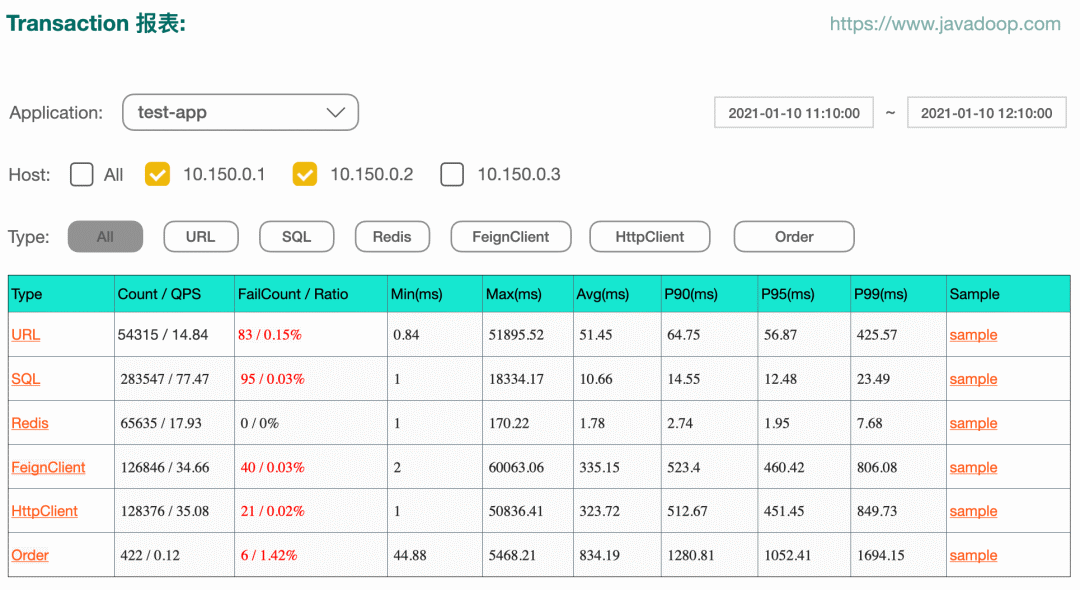
點(diǎn)擊上圖中 type 中的某一項(xiàng),我們有這個(gè) type 下面每個(gè) name 的報(bào)表。比如點(diǎn)擊 URL,我們可以得到每個(gè)接口的數(shù)據(jù)統(tǒng)計(jì):

當(dāng)然,上圖中點(diǎn)擊具體的 name,還有下一個(gè)層級(jí) status 的統(tǒng)計(jì)數(shù)據(jù),這里就不再貼圖了。Dog 總共設(shè)計(jì)了 type、name、status 三級(jí)屬性。上面兩個(gè)圖中的最后一列是 sample,它可以指引到 sample 視圖:

Sample 就是取樣的意思,當(dāng)我們看到有個(gè)接口失敗率很高,或者 P90 很高的時(shí)候,你知道出了問題,但因?yàn)樗挥薪y(tǒng)計(jì)數(shù)據(jù),所以你不知道到底哪里出了問題,這個(gè)時(shí)候,就需要有一些樣本數(shù)據(jù)了。我們每分鐘對(duì) type、name、status 的不同組合分別保存最多 5 個(gè)成功、5 個(gè)失敗、5 個(gè)慢處理的樣本數(shù)據(jù)。
點(diǎn)擊上面的 sample 表中的某個(gè) T、F、L 其實(shí)就會(huì)進(jìn)入到我們的 trace 視圖,展示出這個(gè)請(qǐng)求的整個(gè)鏈路:
通過上面這個(gè) trace 視圖,可以非常快速地知道是哪個(gè)環(huán)節(jié)出了問題。當(dāng)然,我們之前也說過,我們的 trace 依賴于我們的埋點(diǎn)豐富度,但是 Dog 是一個(gè) Metrics 為主的系統(tǒng),所以它的 Traces 能力是不夠的,不過大部分情況下,對(duì)于排查問題應(yīng)該是足夠用的。
對(duì)于應(yīng)用開發(fā)者來說,下面這個(gè) Problem 視圖應(yīng)該是非常有用的:
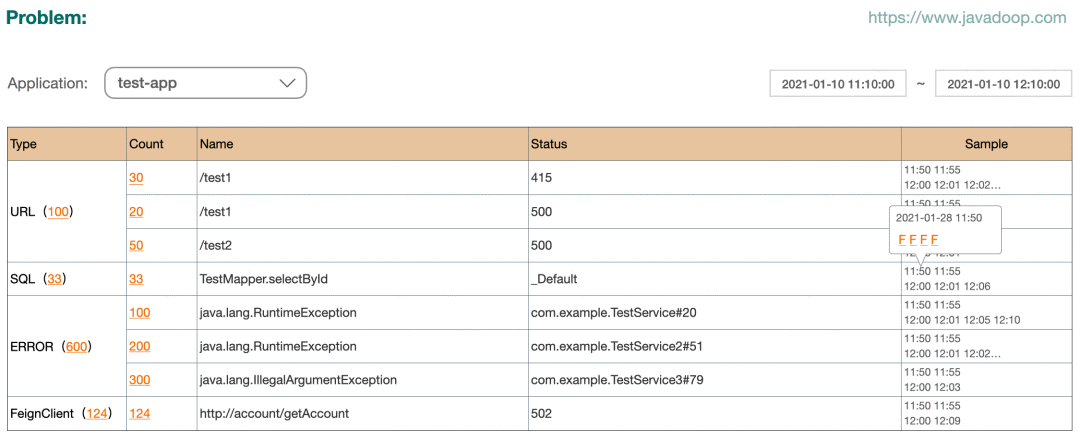
它展示了各種錯(cuò)誤的數(shù)據(jù)統(tǒng)計(jì),并且提供了 sample 讓開發(fā)者去排查問題。
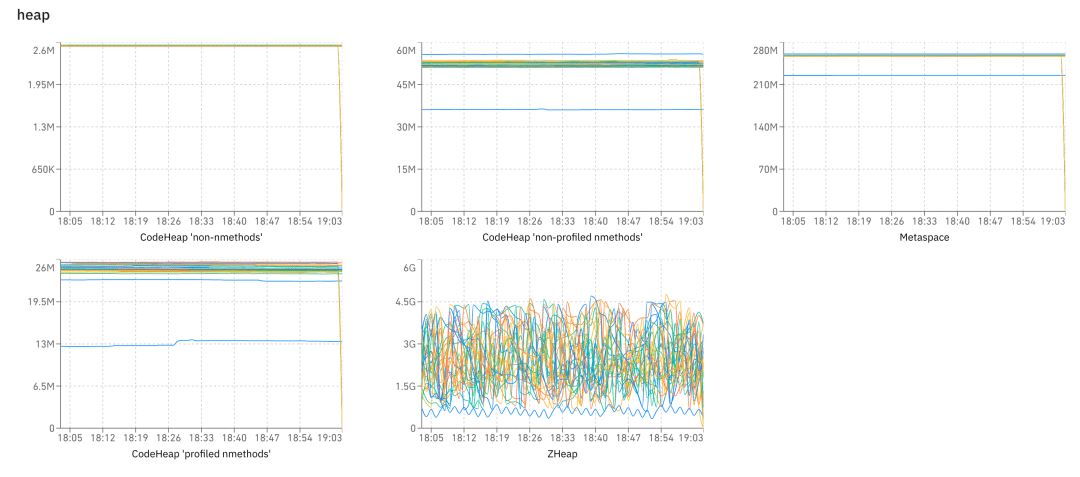
最后,我們?cè)俸唵谓榻B下 Heartbeat 視圖,它和前面的功能沒什么關(guān)系,就是大量的圖,我們有 gc、heap、os、thread 等各種數(shù)據(jù),讓我們可以觀察到系統(tǒng)的健康情況。
這節(jié)主要介紹了一個(gè) APM 系統(tǒng)通常包含哪些功能,其實(shí)也很簡單對(duì)不對(duì),接下來我們從開發(fā)者的角度,來聊聊具體的實(shí)現(xiàn)細(xì)節(jié)問題。
客戶端數(shù)據(jù)模型
大家都是開發(fā)者,我就直接一些了,下圖介紹了客戶端的數(shù)據(jù)模型:

對(duì)于一條 Message 來說,用于統(tǒng)計(jì)的字段是 type, name, status,所以我們能基于 type、type+name、type+name+status 三種維度的數(shù)據(jù)進(jìn)行統(tǒng)計(jì)。
Message 中其他的字段:timestamp 表示事件發(fā)生的時(shí)間;success 如果是 false,那么該事件會(huì)在 problem 報(bào)表中進(jìn)行統(tǒng)計(jì);data 不具有統(tǒng)計(jì)意義,它只在鏈路追蹤排查問題的時(shí)候有用;businessData 用來給業(yè)務(wù)系統(tǒng)上報(bào)業(yè)務(wù)數(shù)據(jù),需要手動(dòng)打點(diǎn),之后用來做業(yè)務(wù)數(shù)據(jù)分析。
Message 有兩個(gè)子類 Event 和 Transaction,區(qū)別在于 Transaction 帶有 duration 屬性,用來標(biāo)識(shí)該 transaction 耗時(shí)多久,可以用來做 max time, min time, avg time, p90, p95 等,而 event 指的是發(fā)生了某件事,只能用來統(tǒng)計(jì)發(fā)生了多少次,并沒有時(shí)間長短的概念。
Transaction 有個(gè)屬性 children,可以嵌套 Transaction 或者 Event,最后形成一顆樹狀結(jié)構(gòu),用來做 trace,我們稍后再介紹。
下面表格示例一下打點(diǎn)數(shù)據(jù),這樣比較直觀一些:
簡單介紹幾點(diǎn)內(nèi)容:
type 為 URL、SQL、Redis、FeignClient、HttpClient 等這些數(shù)據(jù),屬于自動(dòng)埋點(diǎn)的范疇。通常做 APM 系統(tǒng)的,都要完成一些自動(dòng)埋點(diǎn)的工作,這樣應(yīng)用開發(fā)者不需要做任何的埋點(diǎn)工作,就能看到很多有用的數(shù)據(jù)。像最后兩行的 type=Order 屬于手動(dòng)埋點(diǎn)的數(shù)據(jù)。 打點(diǎn)需要特別注意 type、name、status 的維度“爆炸”,它們的組合太多會(huì)非常消耗資源,它可能會(huì)直接拖垮我們的 Dog 系統(tǒng)。type 的維度可能不會(huì)太多,但是我們可能需要注意開發(fā)者可能會(huì)濫用 name 和 status,所以我們一定要做 normalize(如 url 可能是帶動(dòng)態(tài)參數(shù)的,需要格式化處理一下)。 表格中的最后兩條是開發(fā)者手動(dòng)埋點(diǎn)的數(shù)據(jù),通常用來統(tǒng)計(jì)特定的場(chǎng)景,比如我想知道某個(gè)方法被調(diào)用的情況,調(diào)用次數(shù)、耗時(shí)、是否拋異常、入?yún)ⅰ⒎祷刂档取R驗(yàn)樽詣?dòng)埋點(diǎn)是業(yè)務(wù)不想關(guān)的,冷冰冰的數(shù)據(jù),開發(fā)者可能想要埋一些自己想要統(tǒng)計(jì)的數(shù)據(jù)。 開發(fā)者在手動(dòng)埋點(diǎn)的時(shí)候,還可以上報(bào)更多的業(yè)務(wù)相關(guān)的數(shù)據(jù)上來,參考表格最后一列,這些數(shù)據(jù)可以做業(yè)務(wù)分析來用。比如我是做支付系統(tǒng)的,通常一筆支付訂單會(huì)涉及到非常多的步驟(國外的支付和大家平時(shí)使用的微信、支付寶稍微有點(diǎn)不一樣),通過上報(bào)每一個(gè)節(jié)點(diǎn)的數(shù)據(jù),最后我就可以在 Dog 上使用 bizId 來將整個(gè)鏈路串起來,在排查問題的時(shí)候是非常有用的(我們?cè)谧鲋Ц稑I(yè)務(wù)的時(shí)候,支付的成功率并沒有大家想象的那么高,很多節(jié)點(diǎn)可能出問題)。
客戶端設(shè)計(jì)
上一節(jié)我們介紹了單條 message 的數(shù)據(jù),這節(jié)我們覆蓋一下其他內(nèi)容。
首先,我們介紹客戶端的 API 使用:
public void test() {
Transaction transaction = Dog.newTransaction("URL", "/test/user");
try {
Dog.logEvent("User", "name-xxx", "status-yyy");
// do something
Transaction sql = Dog.newTransaction("SQL", "UserMapper.insert");
// try-catch-finally
transaction.setStatus("xxxx");
transaction.setSuccess(true/false);
} catch (Throwable throwable) {
transaction.setSuccess(false);
transaction.setData(Throwables.getStackTraceAsString(throwable));
throw throwable;
} finally {
transaction.finish();
}
}
上面的代碼示例了如何嵌套使用 Transaction 和 Event,當(dāng)最外層的 Transaction 在 finally 代碼塊調(diào)用 finish() 的時(shí)候,完成了一棵樹的創(chuàng)建,進(jìn)行消息投遞。
我們往 Kafka 中投遞的并不是一個(gè) Message 實(shí)例,因?yàn)橐淮握?qǐng)求會(huì)產(chǎn)生很多的 Message 實(shí)例,而是應(yīng)該組織成 一個(gè) Tree 實(shí)例以后進(jìn)行投遞。下圖描述 Tree 的各個(gè)屬性:
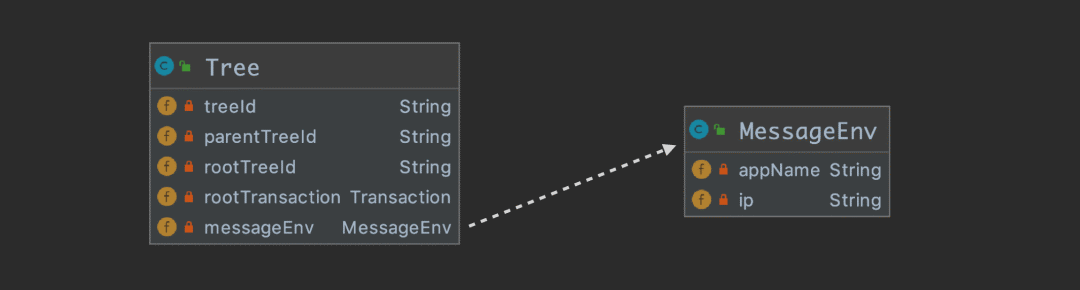
Tree 的屬性很好理解,它持有 root transaction 的引用,用來遍歷整顆樹。另外就是需要攜帶機(jī)器信息 messageEnv。
treeId 應(yīng)該有個(gè)算法能保證全局唯一,簡單介紹下 Dog 的實(shí)現(xiàn):{encode(ip)}-{自增id}。
下面簡單介紹幾個(gè) tree id 相關(guān)的內(nèi)容,假設(shè)一個(gè)請(qǐng)求從 A->B->C->D 經(jīng)過 4 個(gè)應(yīng)用,A 是入口應(yīng)用,那么會(huì)有:
1、總共會(huì)有 4 個(gè) Tree 對(duì)象實(shí)例從 4 個(gè)應(yīng)用投遞到 Kafka,跨應(yīng)用調(diào)用的時(shí)候需要傳遞 treeId, parentTreeId, rootTreeId 三個(gè)參數(shù);
2、A 應(yīng)用的 treeId 是所有節(jié)點(diǎn)的 rootTreeId;
3、B 應(yīng)用的 parentTreeId 是 A 的 treeId,同理 C 的 parentTreeId 是 B 應(yīng)用的 treeId;
4、在跨應(yīng)用調(diào)用的時(shí)候,比如從 A 調(diào)用 B 的時(shí)候,為了知道 A 的下一個(gè)節(jié)點(diǎn)是什么,所以在 A 中提前為 B 生成 treeId,B 收到請(qǐng)求后,如果發(fā)現(xiàn) A 已經(jīng)為它生成了 treeId,直接使用該 treeId。
大家應(yīng)該也很容易知道,通過這幾個(gè) tree id,我們是想要實(shí)現(xiàn) trace 的功能。
介紹完了 tree 的內(nèi)容,我們?cè)俸唵斡懻撓聭?yīng)用集成方案。
集成無外乎兩種技術(shù),一種是通過 javaagent 的方式,在啟動(dòng)腳本中,加上相應(yīng)的 agent,這種方式的優(yōu)點(diǎn)是開發(fā)人員無感知,運(yùn)維層面就可以做掉,當(dāng)然開發(fā)者如果想要手動(dòng)做一些埋點(diǎn),可能需要再提供一個(gè)簡單的 client jar 包給開發(fā)者,用來橋接到 agent 里。另一種就是提供一個(gè) jar 包,由開發(fā)者來引入這個(gè)依賴。
兩種方案各有優(yōu)缺點(diǎn),Pinpoint 和 Skywalking 使用的是 javaagent 方案,Zipkin、Jaeger、Cat 使用的是第二種方案,Dog 也使用第二種手動(dòng)添加依賴的方案。
通常來說,做 Traces 的系統(tǒng)選擇使用 javaagent 方案比較省心,因?yàn)檫@類系統(tǒng) agent 做完了所有需要的埋點(diǎn),無需應(yīng)用開發(fā)者感知。
最后,我再簡單介紹一下 Heartbeat 的內(nèi)容,這部分內(nèi)容其實(shí)最簡單,但是能做出很多花花綠綠的圖表出來,可以實(shí)現(xiàn)面向老板編程。
前面我們介紹了 Message 有兩個(gè)子類 Event 和 Transaction,這里我們?cè)偌右粋€(gè)子類 Heartbeat,用來上報(bào)心跳數(shù)據(jù)。
我們主要收集了 thread、os、gc、heap、client 運(yùn)行情況(產(chǎn)生多少個(gè) tree,數(shù)據(jù)大小,發(fā)送失敗數(shù))等,同時(shí)也提供了 api 讓開發(fā)者自定義數(shù)據(jù)進(jìn)行上報(bào)。Dog client 會(huì)開啟一個(gè)后臺(tái)線程,每分鐘運(yùn)行一次 Heartbeat 收集程序,上報(bào)數(shù)據(jù)。
再介紹細(xì)一些。核心結(jié)構(gòu)是一個(gè) Map\<String, Double>,key 類似于 “os.systemLoadAverage”, “thread.count” 等,前綴 os,thread,gc 等其實(shí)是用來在頁面上的分類,后綴是顯示的折線圖的名稱。
關(guān)于客戶端,這里就介紹這么多了,其實(shí)實(shí)際編碼過程中,還有一些細(xì)節(jié)需要處理,比如如果一棵樹太大了要怎么處理,比如沒有 rootTransaction 的情況怎么處理(開發(fā)者只調(diào)用了 Dog.logEvent(...)),比如內(nèi)層嵌套的 transaction 沒有調(diào)用 finish 怎么處理等等。
Dog server 設(shè)計(jì)
下圖示例了 server 的整體設(shè)計(jì),值得注意的是,我們這里對(duì)線程的使用非常地克制,圖中只有 3 個(gè)工作線程。

首先是 Kafka Consumer 線程,它負(fù)責(zé)批量消費(fèi)消息,從 kafka 集群中消費(fèi)到的是一個(gè)個(gè) Tree 的實(shí)例,接下來考慮怎么處理它。
在這里,我們需要將樹狀結(jié)構(gòu)的 message 鋪平,我們把這一步叫做 deflate,并且做一些預(yù)處理,形成下面的結(jié)構(gòu):
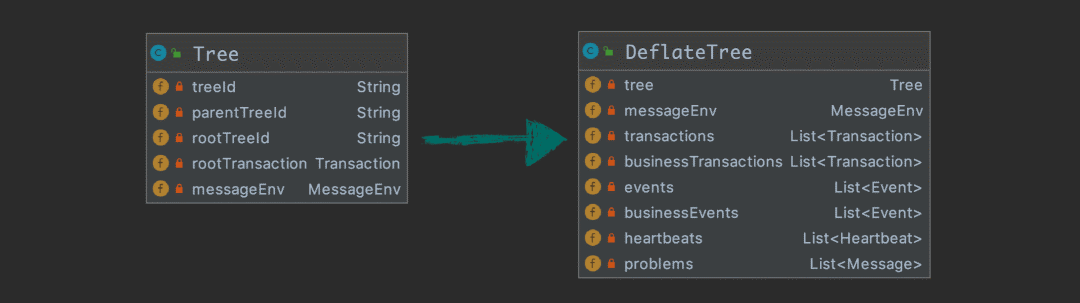
接下來,我們就將 DeflateTree 分別投遞到兩個(gè) Disruptor 實(shí)例中,我們把 Disruptor 設(shè)計(jì)成單線程生產(chǎn)和單線程消費(fèi),主要是性能上的考慮。消費(fèi)線程根據(jù) DeflateTree 的屬性使用綁定好的 Processor 進(jìn)行處理,比如 DeflateTree 中 List<Message> problmes 不為空,同時(shí)自己綁定了 ProblemProcessor,那么就需要調(diào)用 ProblemProcessor 來處理。
科普時(shí)間:Disruptor 是一個(gè)高性能的隊(duì)列,性能比 JDK 中的 BlockingQueue 要好
這里我們使用了 2 個(gè) Disruptor 實(shí)例,當(dāng)然也可以考慮使用更多的實(shí)例,這樣每個(gè)消費(fèi)線程綁定的 processor 就更少。我們這里把 Processor 綁定到了 Disruptor 實(shí)例上,其實(shí)原因也很簡單,為了性能考慮,我們想讓每個(gè) processor 只有單線程使用它,單線程操作可以減少線程切換帶來的開銷,可以充分利用到系統(tǒng)緩存,以及在設(shè)計(jì) processor 的時(shí)候,不用考慮并發(fā)讀寫的問題。
這里要考慮負(fù)載均衡的情況,有些 processor 是比較耗費(fèi) CPU 和內(nèi)存資源的,一定要合理分配,不能把壓力最大的幾個(gè)任務(wù)分到同一個(gè)線程中去了。
核心的處理邏輯都在各個(gè) processor 中,它們負(fù)責(zé)數(shù)據(jù)計(jì)算。接下來,我把各個(gè) processor 需要做的主要內(nèi)容介紹一下,畢竟能看到這里的開發(fā)者,應(yīng)該真的是對(duì) APM 的數(shù)據(jù)處理比較感興趣的。
Transaction processor
transaction processor 是系統(tǒng)壓力最大的地方,它負(fù)責(zé)報(bào)表統(tǒng)計(jì),雖然 Message 有 Transaction 和 Event 兩個(gè)主要的子類,但是在實(shí)際的一顆樹中,絕大部分的節(jié)點(diǎn)都是 transaction 類型的數(shù)據(jù)。
下圖是 transaction processor 內(nèi)部的一個(gè)主要的數(shù)據(jù)結(jié)構(gòu),最外層是一個(gè)時(shí)間,我們用分鐘時(shí)間來組織,我們最后在持久化的時(shí)候,也是按照分鐘來存的。第二層的 HostKey 代表哪個(gè)應(yīng)用以及哪個(gè) ip 來的數(shù)據(jù),第三層是 type、name、status 的組合。最內(nèi)層的 Statistics 是我們的數(shù)據(jù)統(tǒng)計(jì)模塊。

另外我們也可以看到,這個(gè)結(jié)構(gòu)到底會(huì)消耗多少內(nèi)存,其實(shí)主要取決于我們的 type、name、status 的組合也就是 ReportKey 會(huì)不會(huì)很多,也就是我們前面在說客戶端打點(diǎn)的時(shí)候,要避免維度爆炸。
最外層結(jié)構(gòu)代表的是時(shí)間的分鐘表示,我們的報(bào)表是基于每分鐘來進(jìn)行統(tǒng)計(jì)的,之后持久化到 ClickHouse 中,但是我們的使用者在看數(shù)據(jù)的時(shí)候,可不是一分鐘一分鐘看的,所以需要做數(shù)據(jù)聚合,下面展示兩條數(shù)據(jù)是如何做聚合的,在很多數(shù)據(jù)的時(shí)候,都是按照同樣的方法進(jìn)行合并。

你仔細(xì)想想就會(huì)發(fā)現(xiàn),前面幾個(gè)數(shù)據(jù)的計(jì)算都沒毛病,但是 P90, P95 和 P99 的計(jì)算是不是有點(diǎn)欺騙人啊?其實(shí)這個(gè)問題是真的無解的,我們只能想一個(gè)合適的數(shù)據(jù)計(jì)算規(guī)則,然后我們?cè)傧胂脒@種計(jì)算規(guī)則,可能算出來的值也是差不多可用的就好了。
另外有一個(gè)細(xì)節(jié)問題,我們需要讓內(nèi)存中的數(shù)據(jù)提供最近 30 分鐘的統(tǒng)計(jì)信息,30 分鐘以上的才從 DB 讀取。然后做上面介紹的 merge 操作。
討論:我們是否可以丟棄一部分實(shí)時(shí)性,我們每分鐘持久化一次,我們讀取的數(shù)據(jù)都是從 DB 來的,這樣可行嗎?
不行,因?yàn)槲覀兊臄?shù)據(jù)是從 kafka 消費(fèi)來的,本身就有一定的滯后性,我們?nèi)绻陂_始一分鐘的時(shí)候就持久化上一分鐘的數(shù)據(jù),可能之后還會(huì)收到前面時(shí)間的消息,這種情況處理不了。
比如我們要統(tǒng)計(jì)最近一小時(shí)的情況,那么就會(huì)有 30 分鐘的數(shù)據(jù)從各個(gè)機(jī)器中獲得,有 30 分鐘的數(shù)據(jù)從 DB 獲得,然后做合并。
這里值得一提的是,在 transaction 報(bào)表中,count、failCount、min、max、avg 是比較好算的,但是 P90、P95、P99 其實(shí)不太好算,我們需要一個(gè)數(shù)組結(jié)構(gòu),來記錄這一分鐘內(nèi)所有的事件的時(shí)間,然后進(jìn)行計(jì)算,我們這里討巧使用了 Apache DataSketches,它非常好用,這里我就不展開了,感興趣的同學(xué)可以自己去看一下。
到這里,大家可以去想一想儲(chǔ)存到 ClickHouse 的數(shù)據(jù)量的問題。app_name、ip、type、name、status 的不同組合,每分鐘一條數(shù)據(jù)。
Sample Processor
sample processor 消費(fèi) deflate tree 中的 List<Transaction> transactions 和 List<Event> events 的數(shù)據(jù)。
我們也是按照分鐘來采樣,最終每分鐘,對(duì)每個(gè) type、name、status 的不同組合,采集最多 5 個(gè)成功、5 個(gè)失敗、5 個(gè)慢處理。
相對(duì)來說,這個(gè)還是非常簡單的,它的核心結(jié)構(gòu)如下圖:

結(jié)合 Sample 的功能來看比較容易理解:
Problem Processor
在做 deflate 的時(shí)候,所有 success=false 的 Message,都會(huì)被放入 List<Message> problmes 中,用來做錯(cuò)誤統(tǒng)計(jì)。
Problem 內(nèi)部的數(shù)據(jù)結(jié)構(gòu)如下圖:

大家看下這個(gè)圖,其實(shí)也就知道要做什么了,我就不啰嗦了。其中 samples 我們每分鐘保存 5 個(gè) treeId。
順便也再展示下 Problem 的視圖:
關(guān)于持久化,我們是存到了 ClickHouse 中,其中 sample 用逗號(hào)連接成一個(gè)字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
Heartbeat processor
Heartbeat 處理 List<Heartbeat> heartbeats 的數(shù)據(jù),題外話,正常情況下,一顆樹里面只有一個(gè) Heartbeat 實(shí)例。
前面我也簡單提到了一下,我們 Heartbeat 中用來展示圖表的核心數(shù)據(jù)結(jié)構(gòu)是一個(gè) Map<String, Double> 。
收集到的 key-value 數(shù)據(jù)如下所示:
{
"os.systemLoadAverage": 1.5,
"os.committedVirtualMemory": 1234562342,
"os.openFileDescriptorCount": 800,
"thread.count": 600,
"thread.httpThreadsCount": 250,
"gc.ZGC Count": 234,
"gc.ZGC Time(ms)": 123435,
"heap.ZHeap": 4051233219,
"heap.Metaspace": 280123212
}
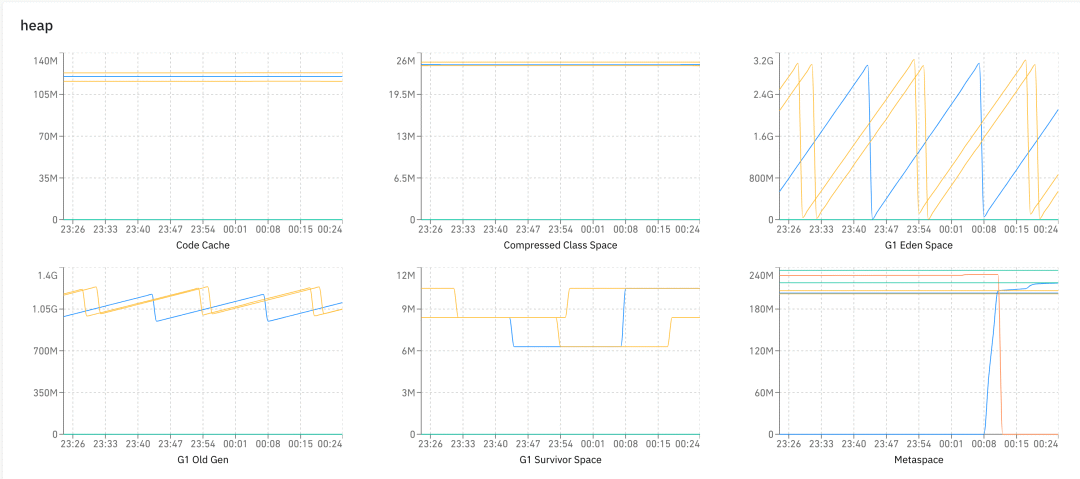
前綴是分類,后綴是圖的名稱。客戶端每分鐘收集一次數(shù)據(jù)進(jìn)行上報(bào),然后就可以做很多的圖了,比如下圖展示了在 heap 分類下的各種圖:
Heartbeat processor 要做的事情很簡單,就是數(shù)據(jù)存儲(chǔ),Dog UI 上的數(shù)據(jù)是直接從 ClickHouse 中讀取的。
heartbeat_data 的列如下:
event_date, event_time, timestamp, app_name, ip, name, value
MessageTree Processor
前面我們多次提到了 Sample 的功能,這些采樣的數(shù)據(jù)幫助我們恢復(fù)現(xiàn)場(chǎng),這樣我們可以通過 trace 視圖來跟蹤調(diào)用鏈。
要做上面的這個(gè) trace 視圖,我們需要上下游的所有的 tree 的數(shù)據(jù),比如上圖是 3 個(gè) tree 實(shí)例的數(shù)據(jù)。
之前我們?cè)诳蛻舳私榻B的時(shí)候說過,這幾個(gè) tree 通過 parent treeId 和 root treeId 來組織。
要做這個(gè)視圖,給我們提出的挑戰(zhàn)就是,我們需要保存全量的數(shù)據(jù)。
大家可以想一想這個(gè)問題,為啥要保存全量數(shù)據(jù),我們直接保存被 sample 到的數(shù)據(jù)不就好了嗎?
這里我們用到了 Cassandra 的能力,Cassandra 在這種 kv 的場(chǎng)景中,有非常不錯(cuò)的性能,而且它的運(yùn)維成本很低。
我們以 treeId 作為主鍵,另外再加 data 一個(gè)列即可,它是整個(gè) tree 的實(shí)例數(shù)據(jù),數(shù)據(jù)類型是 blob,我們會(huì)先做一次 gzip 壓縮,然后再扔給 Cassandra。
Business Processor
我們?cè)诮榻B客戶端的時(shí)候說過,每個(gè) Message 都可以攜帶 Business Data,不過只有應(yīng)用開發(fā)者自己手動(dòng)埋點(diǎn)的時(shí)候才會(huì)有,當(dāng)我們發(fā)現(xiàn)有業(yè)務(wù)數(shù)據(jù)的時(shí)候,我們會(huì)做另一個(gè)事情,就是把這個(gè)數(shù)據(jù)存儲(chǔ)到 ClickHouse 中,用來做業(yè)務(wù)分析。
我們其實(shí)不知道應(yīng)用開發(fā)者到底會(huì)把它用在什么場(chǎng)景中,因?yàn)槊總€(gè)人負(fù)責(zé)的項(xiàng)目都不一樣,所以我們只能做一個(gè)通用的數(shù)據(jù)模型。
回過頭來看這個(gè)圖,BusinessData 中我們定義了比較通用的 userId 和 bizId,我們認(rèn)為它們可能是每個(gè)業(yè)務(wù)場(chǎng)景會(huì)用到的東西。userId 就不用說了,bizId 大家可以做來記錄訂單 id,支付單 id 等。
然后我們提供了 3 個(gè) String 類型的列 ext1、ext2、ext3 和兩個(gè)數(shù)值類型的列 extVal1 和 extVal2,它們可以用來表達(dá)你的業(yè)務(wù)相關(guān)的參數(shù)。
我們的處理當(dāng)然也非常簡單,將這些數(shù)據(jù)存到 ClickHouse 中就可以了,表中主要有這些列:
event_data, event_time, user, biz_id, timestamp, type, name, status, app_name、ip、success、ext1、ext2、ext3、ext_val1、ext_val2
這些數(shù)據(jù)對(duì)我們 Dog 系統(tǒng)來說肯定不認(rèn)識(shí),因?yàn)槲覀円膊恢滥惚磉_(dá)的是什么業(yè)務(wù),type、name、status 是開發(fā)者自己定義的,ext1, ext2, ext3 分別代表什么意思,我們都不知道,我們只負(fù)責(zé)存儲(chǔ)和查詢。
這些業(yè)務(wù)數(shù)據(jù)非常有用,基于這些數(shù)據(jù),我們可以做很多的數(shù)據(jù)報(bào)表出來。因?yàn)楸疚氖怯懻?APM 的,所以該部分內(nèi)容就不再贅述了。
其他
ClickHouse 需要批量寫入,不然肯定是撐不住的,一般一個(gè) batch 至少 10000 行數(shù)據(jù)。
我們?cè)?Kafka 這層控制了,一個(gè) app_name + ip 的數(shù)據(jù),只會(huì)被同一個(gè) dog-server 消費(fèi),當(dāng)然也不是說被多個(gè) dog-server 消費(fèi)會(huì)有問題,但是這樣寫入 ClickHouse 的數(shù)據(jù)就會(huì)更多。
還有個(gè)關(guān)鍵的點(diǎn),前面我們說了每個(gè) processor 是由單線程進(jìn)行訪問的,但是有一個(gè)問題,那就是來自 Dog UI 上的請(qǐng)求可怎么辦?這里我想了個(gè)辦法,那就是將請(qǐng)求放到一個(gè) Queue 中,由 Kafka Consumer 那個(gè)線程來消費(fèi),它會(huì)將任務(wù)扔到兩個(gè) Disruptor 中。比如這個(gè)請(qǐng)求是 transaction 報(bào)表請(qǐng)求,其中一個(gè) Disruptor 的消費(fèi)者會(huì)發(fā)現(xiàn)這個(gè)是自己要干的,就會(huì)去執(zhí)行這個(gè)任務(wù)。
小結(jié)
如果你了解 Cat 的話,可以看到 Dog 在很多地方和 Cat 有相似之處,或者直接說”抄“也行,之前我們也考慮過直接使用 Cat 或者在 Cat 的基礎(chǔ)上做二次開發(fā)。但是我看完 Cat 的源碼后,就放棄了這個(gè)想法,仔細(xì)想想,只是借鑒 Cat 的數(shù)據(jù)模型,然后我們自己寫一套 APM 其實(shí)不是很難,所以有了我們這個(gè)項(xiàng)目。
行文需要,很多地方我都避重就輕,因?yàn)檫@不是什么源碼分析的文章,沒必要處處談細(xì)節(jié),主要是給讀者一個(gè)全貌,讀者能通過我的描述大致想到需要處理哪些事情,需要寫哪些代碼,那就當(dāng)我表述清楚了。
 覺得不錯(cuò),請(qǐng)點(diǎn)個(gè)在看呀
覺得不錯(cuò),請(qǐng)點(diǎn)個(gè)在看呀