
ReentrantLock的這幾個(gè)問(wèn)題你知道嗎?
“寫(xiě)給自己看,說(shuō)給別人聽(tīng)。你好,這是think123的第63篇原創(chuàng)文章
公平鎖和非公平鎖的區(qū)別?
之前分析AQS的時(shí)候,了解到AQS依賴于內(nèi)部的兩個(gè)FIFO隊(duì)列來(lái)完成同步狀態(tài)的管理,當(dāng)線程獲取鎖失敗的時(shí)候,會(huì)將當(dāng)前線程以及等待狀態(tài)等信息構(gòu)造成Node對(duì)象并將其加入同步隊(duì)列中,同時(shí)會(huì)阻塞當(dāng)前線程。
當(dāng)釋放鎖的時(shí)候,會(huì)將首節(jié)點(diǎn)的next節(jié)點(diǎn)喚醒(head節(jié)點(diǎn)是虛擬節(jié)點(diǎn)),使其再次嘗試獲取鎖。
同樣的,如果線程因?yàn)槟硞€(gè)條件不滿足,而進(jìn)行等待,則會(huì)將線程阻塞,同時(shí)將線程加入到等待隊(duì)列中。
當(dāng)其他線程進(jìn)行喚醒的時(shí)候,則會(huì)將等待隊(duì)列中的線程出隊(duì)加入到同步隊(duì)列中使其再次獲得執(zhí)行權(quán)。
按照我們的分析,無(wú)論是同步隊(duì)列還是等待隊(duì)列都是FIFO,看起來(lái)就很公平呀?為什么ReentrankLock還分公平鎖和不公平鎖呢?
還是直接看源碼吧,看看它是怎么做的?
首先看看鎖的創(chuàng)建
//?默認(rèn)是不公平鎖?
public?ReentrantLock()?{
??sync?=?new?NonfairSync();
}
//?true表示公平鎖,false表示不公平鎖
public?ReentrantLock(boolean?fair)?{
??sync?=?fair???new?FairSync()?:?new?NonfairSync();
}
可以看到對(duì)應(yīng)不同的鎖,只是代表他們內(nèi)部的Sync變量不同而已。
其中NonfairSync和FairSync兩個(gè)類(lèi)是Sync的子類(lèi),Sync又繼承自AbstractQueuedSynchronizer
當(dāng)我們使用ReentrantLock加鎖的時(shí)候?qū)嶋H上調(diào)用的是sync.lock()方法,也就是說(shuō),我們需要看看他們加鎖的時(shí)候有什么不同之處?

可以看到在lock方法內(nèi)部,非公平鎖會(huì)先直接通過(guò)CAS修改state變量的值,如果修改成功則表示獲取到了鎖,而公平鎖則是直接調(diào)用AQS的acquire方法來(lái)獲取鎖。
也就是說(shuō)有可能當(dāng)其他線程釋放鎖的時(shí)候,非公平鎖能率先修改state的值成功,從而獲取到鎖。這樣就比其他等待的線程率先獲取到鎖了,這就是不公平。
之前也有提到過(guò),子類(lèi)會(huì)根據(jù)自己的需求以實(shí)現(xiàn)tryAcquire方法,同樣的非公平鎖和公平鎖的實(shí)現(xiàn)也實(shí)現(xiàn)了這個(gè)方法,我們可以來(lái)看看,兩個(gè)的實(shí)現(xiàn)有什么不同
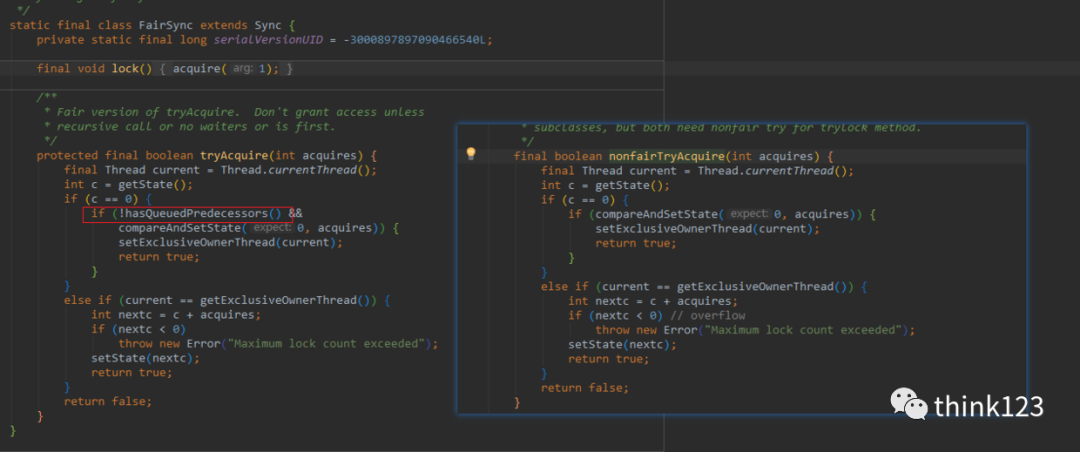
可以看到公平鎖比非公平鎖的實(shí)現(xiàn)多了一個(gè)判斷條件(!hasQueuedPredecessors()),我們來(lái)看看這個(gè)方法的實(shí)現(xiàn)
public?final?boolean?hasQueuedPredecessors()?{
??Node?t?=?tail;
??Node?h?=?head;
??Node?s;
??return?h?!=?t?&&
??????((s?=?h.next)?==?null?||?s.thread?!=?Thread.currentThread());
}
這個(gè)方法很簡(jiǎn)單,它的意思是如果當(dāng)前線程之前有排隊(duì)的線程,則返回true;如果當(dāng)前線程位于隊(duì)列的開(kāi)頭或隊(duì)列為空,則返回false。
也就是說(shuō)公平鎖在獲取鎖的時(shí)候會(huì)判斷隊(duì)列中是否已經(jīng)有排隊(duì)的線程,如果有則進(jìn)行阻塞,如果沒(méi)有則去通過(guò)CAS申請(qǐng)鎖。
這就實(shí)現(xiàn)了公平鎖,先來(lái)的先獲取到鎖,后來(lái)的后獲取到鎖。
所以我們可以總結(jié)下公平鎖和非公平鎖實(shí)現(xiàn)上的兩點(diǎn)區(qū)別:
非公平鎖在調(diào)用lock()方法后,首先會(huì)通過(guò)CAS搶占鎖,如果恰巧這個(gè)時(shí)候鎖沒(méi)有被占用,則獲取鎖成功 非公平鎖在CAS失敗后,和公平鎖一樣會(huì)調(diào)用tryAcquire()方法,在tryAcquire()方法中,如果發(fā)現(xiàn)鎖被釋放了(state=0),非公平鎖會(huì)直接CAS進(jìn)行搶占,而公平鎖會(huì)判斷同步隊(duì)列中是否有線程處于等待狀態(tài),如果有則不去搶占,而是排隊(duì)獲取。
這就是兩者將細(xì)微的區(qū)別,如果這非公平鎖兩次CAS都失敗了,那么會(huì)和公平鎖一樣,乖乖的在同步隊(duì)列中排隊(duì)。
相對(duì)而言,非公平鎖的吞吐量更大,但是讓獲取鎖的時(shí)間變得不確定,可能會(huì)導(dǎo)致同步隊(duì)列中的線程長(zhǎng)期處于饑餓狀態(tài)。
ReentrantLock靠什么保證可見(jiàn)性?
synchronized 之所以能夠保證可見(jiàn)性,是因?yàn)橛幸粭lhappens-before原則,那Java SDK 里面 ReentrantLock 靠什么保證可見(jiàn)性呢?
它是利用了 volatile 相關(guān)的 Happens-Before 規(guī)則。AQS內(nèi)部有一個(gè) volatile 的成員變量 state,當(dāng)獲取鎖的時(shí)候,會(huì)讀寫(xiě)state 的值;解鎖的時(shí)候,也會(huì)讀寫(xiě) state 的值。
對(duì)一個(gè)volatile變量的寫(xiě)操作happens-before 于后面對(duì)這個(gè)變量的讀操作。這里的happens-before是時(shí)間上的先后順序
這樣說(shuō)起來(lái)挺抽象的,我們直接去看JVM中對(duì)volatile是否有特殊的處理,在src/hotspot/share/interpreter/bytecodeinterpreter.cpp中,我們找到getfield和getstatic字節(jié)碼執(zhí)行的位置
現(xiàn)在這個(gè)執(zhí)行器基本不再使用了,基本都會(huì)使用模板解釋器,但是模板解釋器的代碼基本都是匯編,而我們只是想要快速了解其原理,所以可以看這個(gè),對(duì)模板解釋器感興趣的可以去看templateTable_x86.cpp::getfield查看相關(guān)細(xì)節(jié)
...
CASE(_getfield):
CASE(_getstatic):
{
???...
???ConstantPoolCacheEntry*?cache;
???...
???if?(cache->is_volatile())?{
?????if?(support_IRIW_for_not_multiple_copy_atomic_cpu)?{
???????OrderAccess::fence();
?????}
?????...
???}
??...
}
可以看到在訪問(wèn)對(duì)象字段的時(shí)候,會(huì)判斷它是不是volatile的,如果是,且當(dāng)前CPU平臺(tái)支持多核atomic操作(現(xiàn)在大多數(shù)CPU都支持),就調(diào)用OrderAccess::fence()。
JDK中的Unsafe也提供了內(nèi)存屏障的方法,在JVM層面也是通過(guò)OrderAccess實(shí)現(xiàn)
接下來(lái)來(lái)看下Linux x86下的實(shí)現(xiàn)是怎樣的(src/hotspot/os_cpu/linux_x86/orderAccess_linux_x86.cpp)
inline?void?OrderAccess::fence()?{
//?always?use?locked?addl?since?mfence?is?sometimes?expensive
#ifdef?AMD64
??__asm__?volatile?("lock;?addl?$0,0(%%rsp)"?:?:?:?"cc",?"memory");
#else
??__asm__?volatile?("lock;?addl?$0,0(%%esp)"?:?:?:?"cc",?"memory");
#endif
??compiler_barrier();
}
指令中的"addl $0,0(%%esp)"(把ESP寄存器的值加0)是一個(gè)空操作,采用這個(gè)空操作而不是空操作指令nop是因?yàn)镮A32手冊(cè)規(guī)定lock前綴不允許配合nop指令使用,所以才采用加0這個(gè)空操作。
而lock有如下作用
lock鎖定的時(shí)候,如果操作某個(gè)數(shù)據(jù),那么其他CPU核不能同時(shí)操作 lock 鎖定的指令,不能上下文隨意排序執(zhí)行,必須按照程序上下順序執(zhí)行 在 lock 鎖定操作完畢之后,如果某個(gè)數(shù)據(jù)被修改了,那么需要立即告訴其他 CPU 這個(gè)值被修改了,是它們的緩存數(shù)據(jù)立即失效,需要重新到內(nèi)存獲取
關(guān)于lock的實(shí)現(xiàn)有兩種,一種是鎖總線,一種是鎖緩存。鎖緩存就涉及到CPU Cache,緩存行以及MESI了,所以這里就不展開(kāi)了,有興趣的童鞋咱們可以私下交流下。