
只有4頁(yè)!ICLR爆款論文「Patches are all you need」
點(diǎn)擊上方“機(jī)器學(xué)習(xí)與生成對(duì)抗網(wǎng)絡(luò)”,關(guān)注星標(biāo)
獲取有趣、好玩的前沿干貨!
轉(zhuǎn)自:新智元
金秋十月,又到了ICLR截稿的季節(jié)!
?
一篇「Patches are all you need」橫空出世。
?
堪稱ICLR 2022的爆款論文,從國(guó)外一路火到國(guó)內(nèi)。
?
509個(gè)贊,3269個(gè)轉(zhuǎn)發(fā)
?
知乎熱搜
?
這篇標(biāo)題里不僅有「劃掉」還有「表情」的論文,正文只有4頁(yè)!
?

https://openreview.net/pdf?id=TVHS5Y4dNvM
?
此外,作者還特地在文末寫(xiě)了個(gè)100多字的小論文表示:「期待更多內(nèi)容?并沒(méi)有。我們提出了一個(gè)非常簡(jiǎn)單的架構(gòu)和觀點(diǎn):patches在卷積架構(gòu)中很好用。四頁(yè)的篇幅已經(jīng)足夠了。」
?

?
這……莫非又是「xx is all you need」的噱頭論文?
你只需要PATCHES
這個(gè)特立獨(dú)行的論文在一開(kāi)篇的時(shí)候,作者就發(fā)出了靈魂拷問(wèn):「ViT的性能是由于更強(qiáng)大的Transformer架構(gòu),還是因?yàn)槭褂昧藀atch作為輸入表征?」
?
眾所周知,卷積網(wǎng)絡(luò)架構(gòu)常年來(lái)占據(jù)著CV的主流,不過(guò)最近ViT(Vision Transformer)架構(gòu)則在許多任務(wù)中的表現(xiàn)出優(yōu)于經(jīng)典卷積網(wǎng)絡(luò)的性能,尤其是在大型數(shù)據(jù)集上。
?
然而,Transformer中自注意力層的應(yīng)用,將導(dǎo)致計(jì)算成本將與每張圖像的像素?cái)?shù)成二次方擴(kuò)展。因此想要在CV任務(wù)中使用Transformer架構(gòu),則需要把圖像分成多個(gè)patch,再將它們線性嵌入 ,最后把Transformer直接應(yīng)用于patch集合。
?
在本文中作者提出了一個(gè)極其簡(jiǎn)單的模型:ConvMixer,其結(jié)構(gòu)與ViT和更基本的MLP-Mixer相似,直接以patch作為輸入,分離了空間和通道維度的混合,并在整個(gè)網(wǎng)絡(luò)中保持同等大小和分辨率。不同的是,ConvMixer只使用標(biāo)準(zhǔn)的卷積來(lái)實(shí)現(xiàn)混合步驟。
?
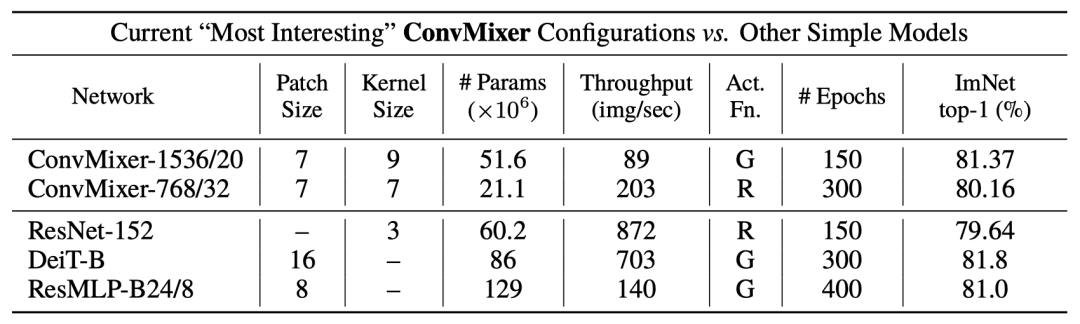
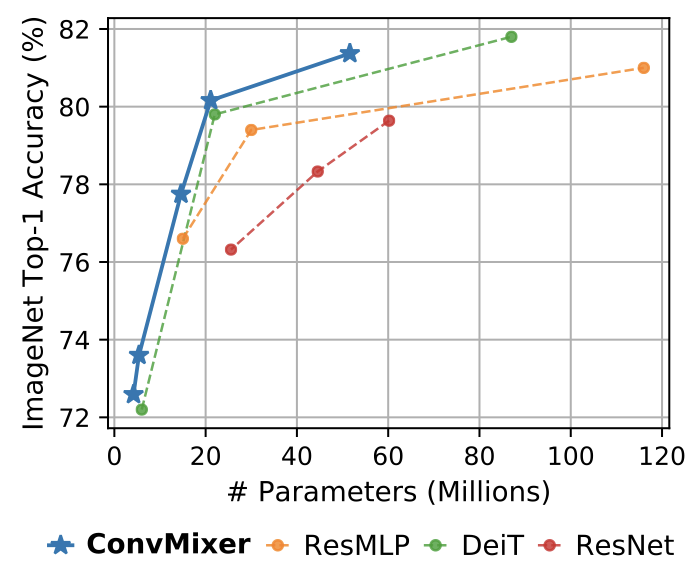
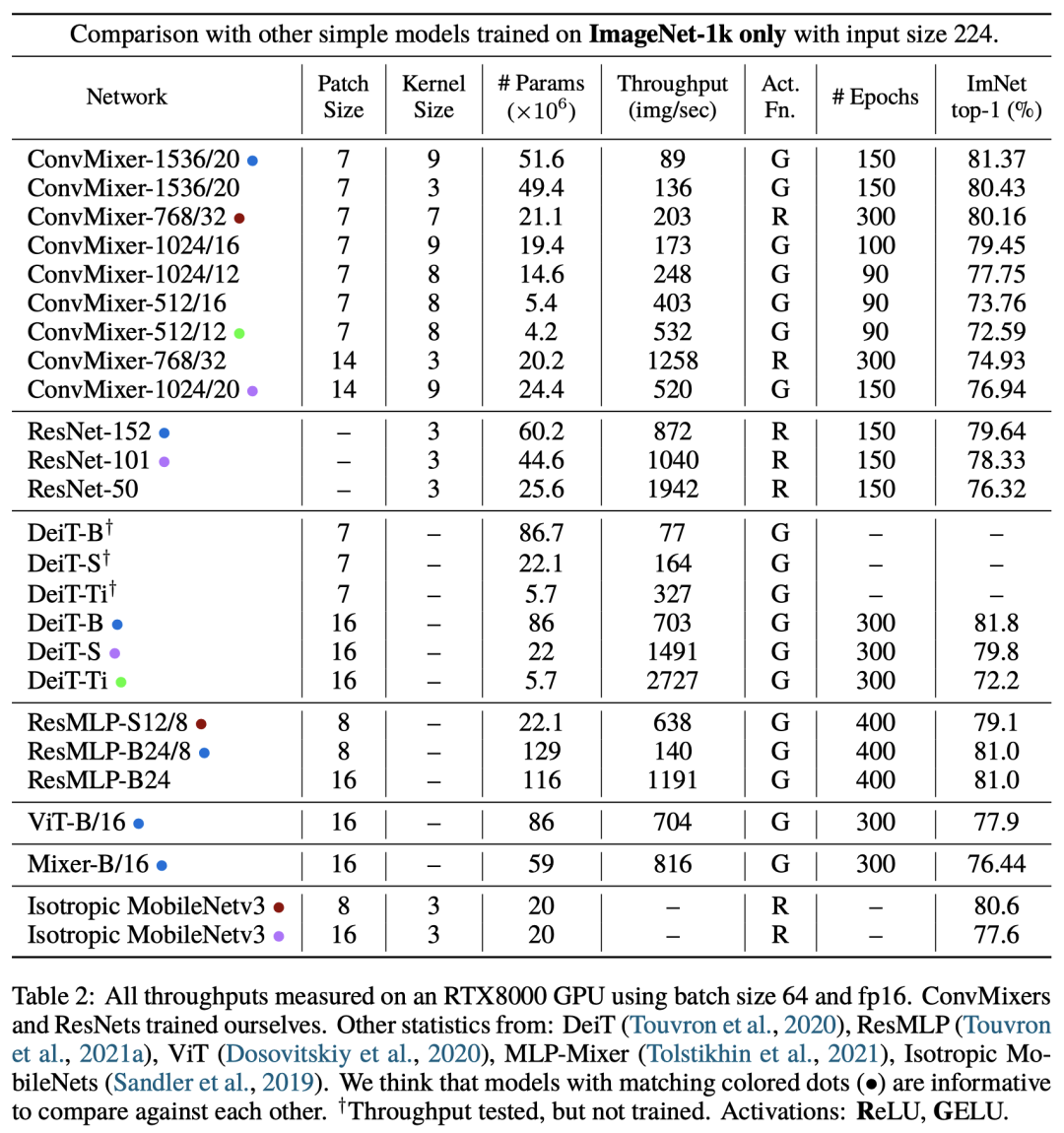
作者表示,通過(guò)結(jié)果可以證明ConvMixer在類似的參數(shù)量和數(shù)據(jù)集大小方面優(yōu)于ViT、MLP-Mixer和部分變種,此外還優(yōu)于經(jīng)典的視覺(jué)模型,如ResNet。
?
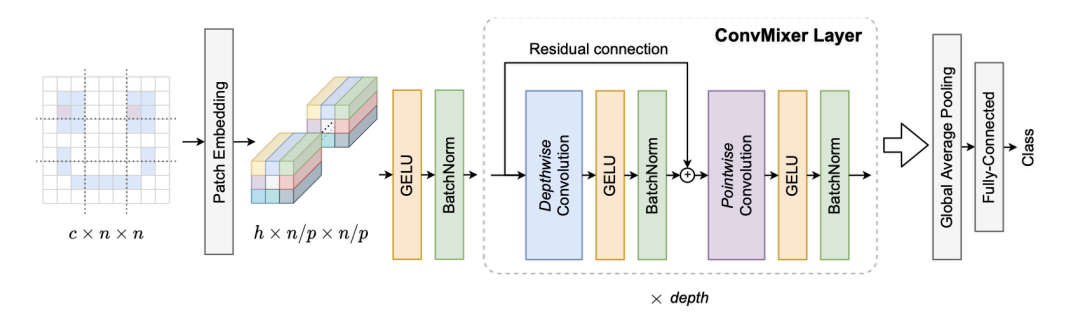
ConvMixer模型
?
ConvMixer由一個(gè)patch嵌入層和一個(gè)簡(jiǎn)單的完全卷積塊的重復(fù)應(yīng)用組成。
?
?
大小為p和維度為h的patch嵌入可以實(shí)現(xiàn)輸入通道為c、輸出通道為h、核大小為p和跨度為p的卷積。
?
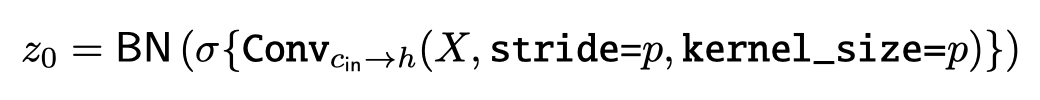
?
ConvMixer模塊包括depthwise卷積(組數(shù)等于通道數(shù)h的分組卷積)以及pointwise卷積(核大小為1×1)。每個(gè)卷積之后都有一個(gè)激活函數(shù)和激活后的BatchNorm:
?

??
在多次應(yīng)用ConvMixer模塊后,執(zhí)行全局池化可以得到一個(gè)大小為h的特征向量,并在之后將其傳遞給softmax分類器。
?
ConvMixer的實(shí)例化取決于四個(gè)參數(shù):
「寬度」或隱藏維度h(即patch嵌入的維度) 「深度」或ConvMixer層的重復(fù)次數(shù)d 控制模型內(nèi)部分辨率的patch大小p 深度卷積層的核大小k
實(shí)驗(yàn)結(jié)果
算法實(shí)現(xiàn)

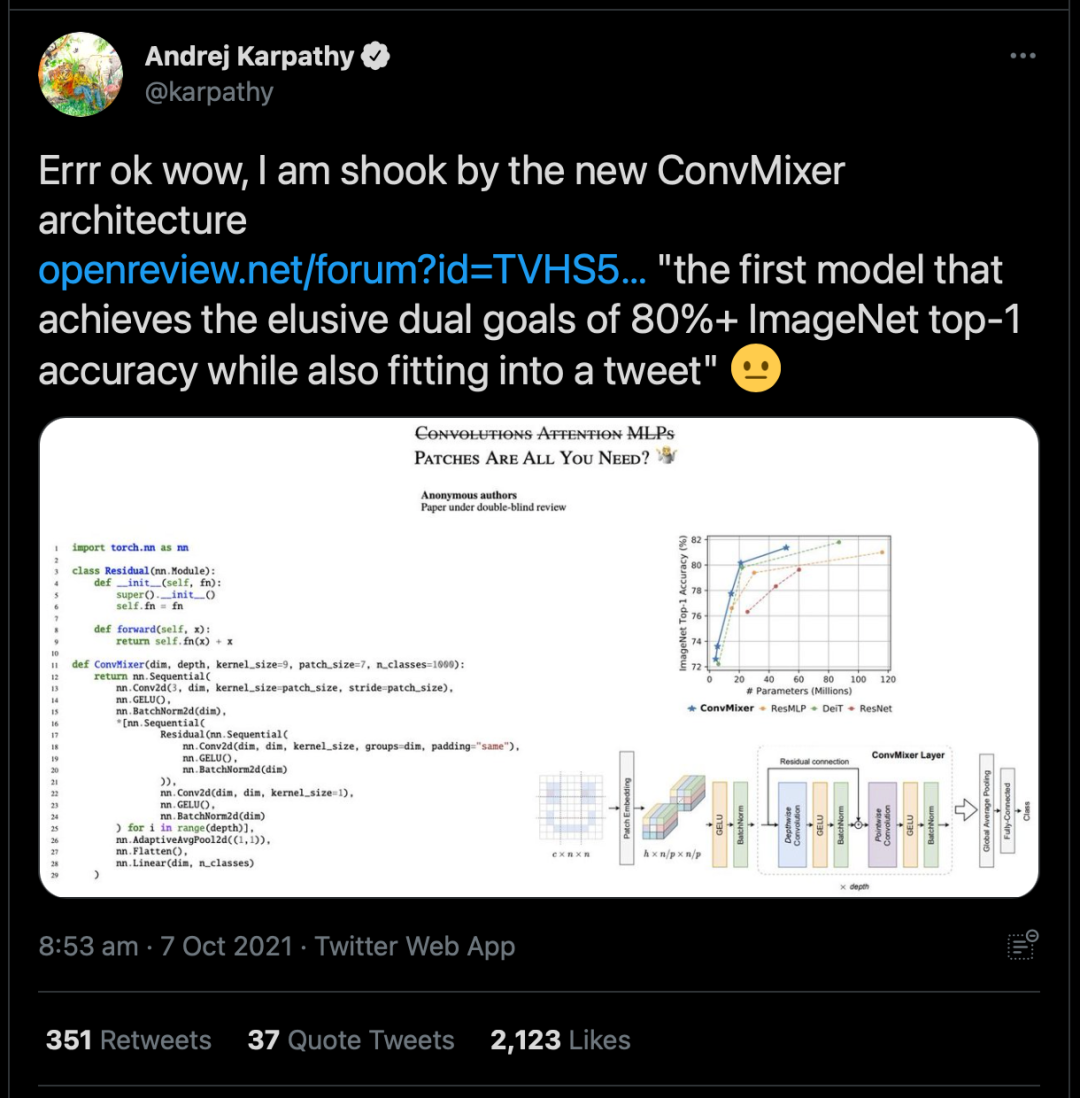
網(wǎng)友評(píng)論
?
網(wǎng)友評(píng)論







參考資料:
https://www.zhihu.com/question/492712118
https://openreview.net/pdf?id=TVHS5Y4dNvM
猜您喜歡:
等你著陸!【GAN生成對(duì)抗網(wǎng)絡(luò)】知識(shí)星球!
CVPR 2021 | GAN的說(shuō)話人驅(qū)動(dòng)、3D人臉論文匯總
CVPR 2021 | 圖像轉(zhuǎn)換 今如何?幾篇GAN論文
【CVPR 2021】通過(guò)GAN提升人臉識(shí)別的遺留難題
CVPR 2021生成對(duì)抗網(wǎng)絡(luò)GAN部分論文匯總
最新最全20篇!基于 StyleGAN 改進(jìn)或應(yīng)用相關(guān)論文
附下載 | 經(jīng)典《Think Python》中文版
附下載 | 《Pytorch模型訓(xùn)練實(shí)用教程》
附下載 | 最新2020李沐《動(dòng)手學(xué)深度學(xué)習(xí)》
附下載 |?《可解釋的機(jī)器學(xué)習(xí)》中文版
附下載 |《TensorFlow 2.0 深度學(xué)習(xí)算法實(shí)戰(zhàn)》