
Java集合之LinkedHashMap

一、初識LinkedHashMap
上篇文章講了HashMap。HashMap是一種非常常見、非常有用的集合,但在多線程情況下使用不當會有線程安全問題。
大多數(shù)情況下,只要不涉及線程安全問題,Map基本都可以使用HashMap,不過HashMap有一個問題,就是迭代HashMap的順序并不是HashMap放置的順序,也就是無序。HashMap的這一缺點往往會帶來困擾,因為有些場景,我們期待一個有序的Map。
這個時候,LinkedHashMap就閃亮登場了,它雖然增加了時間和空間上的開銷,但是通過維護一個運行于所有條目的雙向鏈表,LinkedHashMap保證了元素迭代的順序。該迭代順序可以是插入順序或者是訪問順序。
二、四個關(guān)注點在LinkedHashMap上的答案
| 關(guān) ?注 ?點 | 結(jié) ? ? ?論 |
| LinkedHashMap是否允許空 | Key和Value都允許空 |
| LinkedHashMap是否允許重復(fù)數(shù)據(jù) | Key重復(fù)會覆蓋、Value允許重復(fù) |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否線程安全 | 非線程安全 |
三、LinkedHashMap基本結(jié)構(gòu)
關(guān)于LinkedHashMap,先提兩點:
1、LinkedHashMap可以認為是HashMap+LinkedList,即它既使用HashMap操作數(shù)據(jù)結(jié)構(gòu),又使用LinkedList維護插入元素的先后順序。
2、LinkedHashMap的基本實現(xiàn)思想就是----多態(tài)。可以說,理解多態(tài),再去理解LinkedHashMap原理會事半功倍;反之也是,對于LinkedHashMap原理的學習,也可以促進和加深對于多態(tài)的理解。
為什么可以這么說,首先看一下,LinkedHashMap的定義:?
public?class?LinkedHashMap<K,V>
????extends?HashMap<K,V>
????implements?Map<K,V>
{
????...
}看到,LinkedHashMap是HashMap的子類,自然LinkedHashMap也就繼承了HashMap中所有非private的方法。再看一下LinkedHashMap中本身的方法:
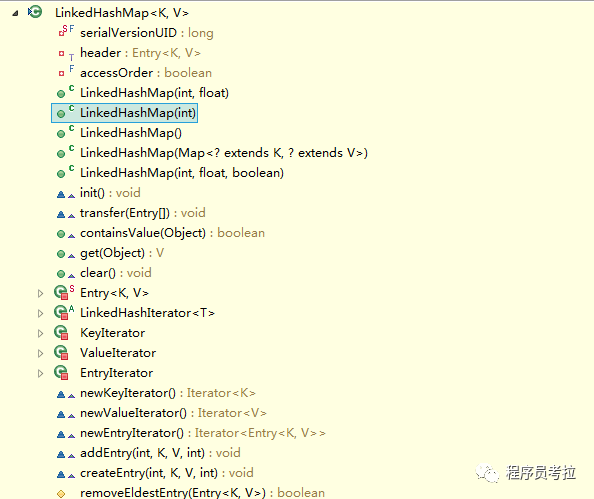
看到LinkedHashMap中并沒有什么操作數(shù)據(jù)結(jié)構(gòu)的方法,也就是說LinkedHashMap操作數(shù)據(jù)結(jié)構(gòu)(比如put一個數(shù)據(jù)),和HashMap操作數(shù)據(jù)的方法完全一樣,無非就是細節(jié)上有一些的不同罷了。
LinkedHashMap只定義了兩個屬性:
/**
?* The head of the doubly linked list.
?* 雙向鏈表的頭節(jié)點
?*/
private transient Entry header;
/**
?* The iteration ordering method for?this linked hash?map: true
?* for?access-order, false?for?insertion-order.
?* true表示最近最少使用次序,false表示插入順序
?*/
private final boolean accessOrder; LinkedHashMap一共提供了五個構(gòu)造方法:
// 構(gòu)造方法1,構(gòu)造一個指定初始容量和負載因子的、按照插入順序的LinkedList
public?LinkedHashMap(int?initialCapacity, float?loadFactor)?{
????super(initialCapacity, loadFactor);
????accessOrder = false;
}
// 構(gòu)造方法2,構(gòu)造一個指定初始容量的LinkedHashMap,取得鍵值對的順序是插入順序
public?LinkedHashMap(int?initialCapacity)?{
????super(initialCapacity);
????accessOrder = false;
}
// 構(gòu)造方法3,用默認的初始化容量和負載因子創(chuàng)建一個LinkedHashMap,取得鍵值對的順序是插入順序
public?LinkedHashMap()?{
????super();
????accessOrder = false;
}
// 構(gòu)造方法4,通過傳入的map創(chuàng)建一個LinkedHashMap,容量為默認容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的較大者,裝載因子為默認值
public?LinkedHashMap(Map m)?{
????super(m);
????accessOrder = false;
}
// 構(gòu)造方法5,根據(jù)指定容量、裝載因子和鍵值對保持順序創(chuàng)建一個LinkedHashMap
public?LinkedHashMap(int?initialCapacity,
?????????????float?loadFactor,
?????????????????????????boolean?accessOrder)?{
????super(initialCapacity, loadFactor);
????this.accessOrder = accessOrder;
}從構(gòu)造方法中可以看出,默認都采用插入順序來維持取出鍵值對的次序。所有構(gòu)造方法都是通過調(diào)用父類的構(gòu)造方法來創(chuàng)建對象的。
LinkedHashMap和HashMap的區(qū)別在于它們的基本數(shù)據(jù)結(jié)構(gòu)上,看一下LinkedHashMap的基本數(shù)據(jù)結(jié)構(gòu),也就是Entry:
private?static?class?Entry<K,V> extends?HashMap.Entry<K,V> {
????// These fields comprise the doubly linked list used for iteration.
????Entry before, after;
????Entry(int?hash, K key, V value, HashMap.Entry next) {
????????super(hash, key, value, next);
????}
????...
} 列一下Entry里面有的一些屬性吧:
1、K key
2、V value
3、Entry
4、int hash
5、Entry
6、Entry
其中前面四個,也就是紅色部分是從HashMap.Entry中繼承過來的;后面兩個,也就是藍色部分是LinkedHashMap獨有的。不要搞錯了next和before、After,next是用于維護HashMap指定table位置上連接的Entry的順序的,before、After是用于維護Entry插入的先后順序的。
還是用圖表示一下,列一下屬性而已:

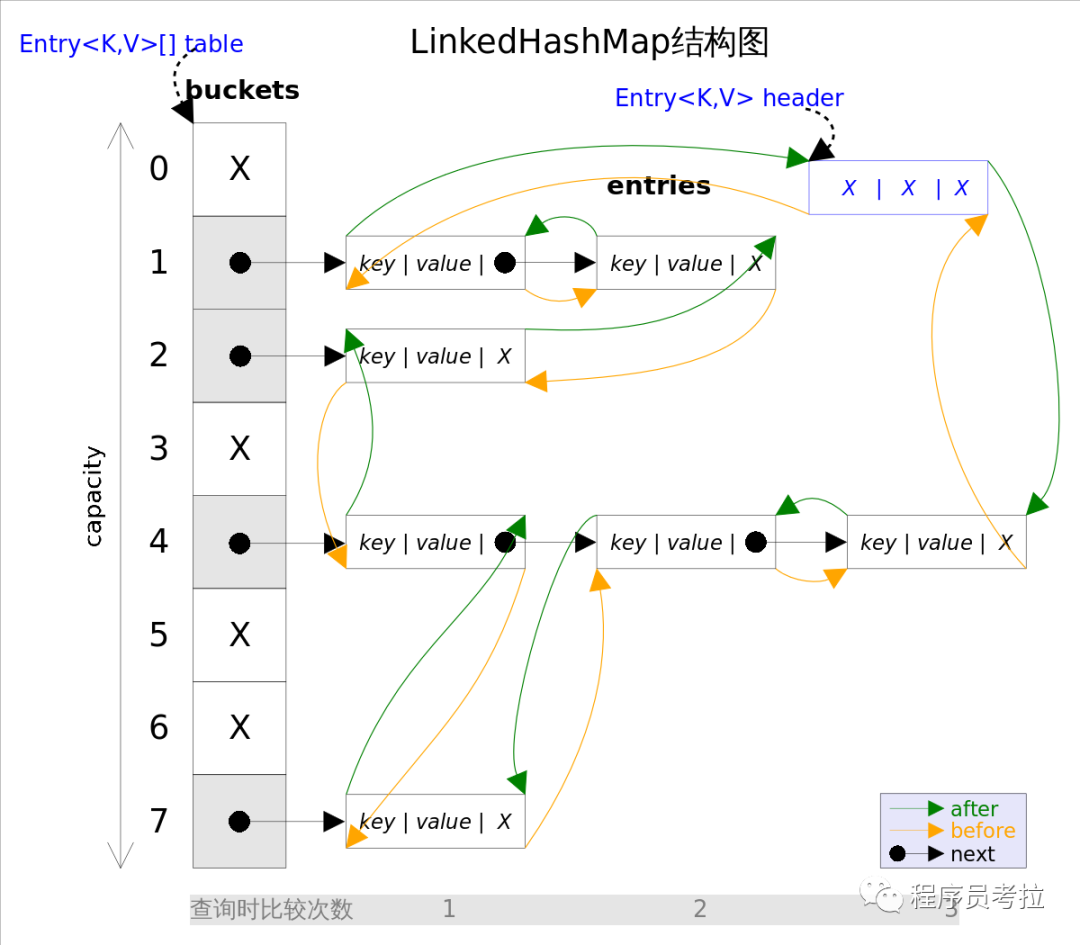
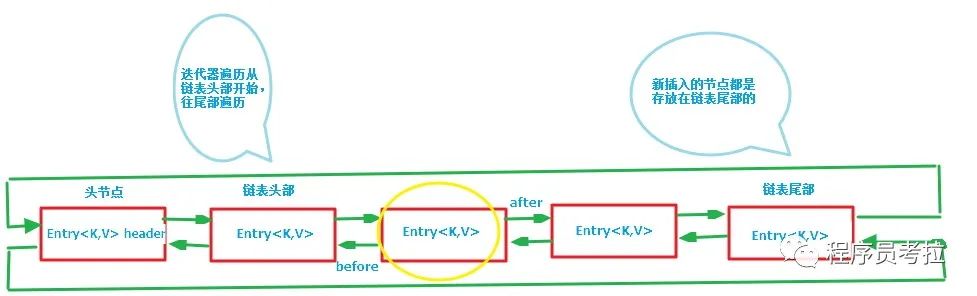
第一張圖為LinkedHashMap整體結(jié)構(gòu)圖,第二張圖專門把循環(huán)雙向鏈表抽取出來,直觀一點,注意該循環(huán)雙向鏈表的頭部存放的是最久訪問的節(jié)點或最先插入的節(jié)點,尾部為最近訪問的或最近插入的節(jié)點,迭代器遍歷方向是從鏈表的頭部開始到鏈表尾部結(jié)束,在鏈表尾部有一個空的header節(jié)點,該節(jié)點不存放key-value內(nèi)容,為LinkedHashMap類的成員屬性,循環(huán)雙向鏈表的入口。
四、初始化LinkedHashMap
假如有這么一段代碼:
public?static?void?main(String[] args)
{
????LinkedHashMap<String, String> linkedHashMap =
????????????new?LinkedHashMap<String, String>();
????linkedHashMap.put("111", "111");
????linkedHashMap.put("222", "222");
}首先是第3行~第4行,new一個LinkedHashMap出來,看一下做了什么:
通過源代碼可以看出,在LinkedHashMap的構(gòu)造方法中,實際調(diào)用了父類HashMap的相關(guān)構(gòu)造方法來構(gòu)造一個底層存放的table數(shù)組。
public?LinkedHashMap()?{
?????super();
?????accessOrder = false;
}public?HashMap()?{
????this.loadFactor = DEFAULT_LOAD_FACTOR;
????threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
????table = new?Entry[DEFAULT_INITIAL_CAPACITY];
????init();
?}我們已經(jīng)知道LinkedHashMap的Entry元素繼承HashMap的Entry,提供了雙向鏈表的功能。在上述HashMap的構(gòu)造器中,最后會調(diào)用init()方法,進行相關(guān)的初始化,這個方法在HashMap的實現(xiàn)中并無意義,只是提供給子類實現(xiàn)相關(guān)的初始化調(diào)用。
LinkedHashMap重寫了init()方法,在調(diào)用父類的構(gòu)造方法完成構(gòu)造后,進一步實現(xiàn)了對其元素Entry的初始化操作。
void?init() {
?????header = new?Entry(-1, null, null, null);
?????header.before = header.after = header;
} 這里出現(xiàn)了第一個多態(tài):init()方法。盡管init()方法定義在HashMap中,但是由于:
1、LinkedHashMap重寫了init方法
2、實例化出來的是LinkedHashMap
因此實際調(diào)用的init方法是LinkedHashMap重寫的init方法。假設(shè)header的地址是0x00000000,那么初始化完畢,實際上是這樣的:
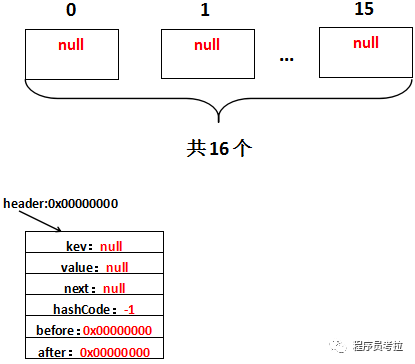
注意這個header,hash值為-1,其他都為null,也就是說這個header不放在數(shù)組中,就是用來指示開始元素和標志結(jié)束元素的。
header的目的是為了記錄第一個插入的元素是誰,在遍歷的時候能夠找到第一個元素。
五、LinkedHashMap存儲元素
LinkedHashMap并未重寫父類HashMap的put方法,而是重寫了父類HashMap的put方法調(diào)用的子方法void recordAccess(HashMap m)? ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的雙向鏈接列表的實現(xiàn)。
繼續(xù)看LinkedHashMap存儲元素,也就是put("111","111")做了什么,首先當然是調(diào)用HashMap的put方法:
//這個方法應(yīng)該挺熟悉的,如果看了HashMap的解析的話
public?V put(K key, V value) {
????//key為null的情況
????if?(key == null)
????????return?putForNullKey(value);
????//通過key算hash,進而算出在數(shù)組中的位置,也就是在第幾個桶中
????int?hash = hash(key.hashCode());
????int?i = indexFor(hash, table.length);
????//查看桶中是否有相同的key值,如果有就直接用新值替換舊值,而不用再創(chuàng)建新的entry了
????for?(Entry e = table[i]; e != null; e = e.next) {
????????Object k;
????????if?(e.hash == hash && ((k = e.key) == key || key.equals(k))) {
????????????V oldValue = e.value;
????????????e.value?= value;
????????????e.recordAccess(this);
????????????return?oldValue;
????????}
????}
????modCount++;
????//上面度是熟悉的東西,最重要的地方來了,就是這個方法,LinkedHashMap執(zhí)行到這里,addEntry()方法不會執(zhí)行HashMap中的方法,
????//而是執(zhí)行自己類中的addEntry方法,
????addEntry(hash, key, value, i);
????return?null;
} 第23行又是一個多態(tài),因為LinkedHashMap重寫了addEntry方法,因此addEntry調(diào)用的是LinkedHashMap重寫了的方法:
void?addEntry(int?hash, K key, V value, int?bucketIndex) {
????//調(diào)用create方法,將新元素以雙向鏈表的的形式加入到映射中
????createEntry(hash, key, value, bucketIndex);
????// Remove eldest entry if instructed, else grow capacity if appropriate
????// 刪除最近最少使用元素的策略定義
????Entry eldest = header.after;
????if?(removeEldestEntry(eldest)) {
????????removeEntryForKey(eldest.key);
????} else?{
????????if?(size >= threshold)
????????????resize(2?* table.length);
????}
} 因為LinkedHashMap由于其本身維護了插入的先后順序,因此LinkedHashMap可以用來做緩存,第7行~第9行是用來支持FIFO算法的,這里暫時不用去關(guān)心它。看一下createEntry方法:?
void?createEntry(int?hash, K key, V value, int?bucketIndex) {
????HashMap.Entry old = table[bucketIndex];
????Entry e = new?Entry(hash, key, value, old);
????table[bucketIndex] = e;
????//將該節(jié)點插入到鏈表尾部
????e.addBefore(header);
????size++;
} private?void?addBefore(Entry existingEntry) ?{
????after = existingEntry;
????before = existingEntry.before;
????before.after = this;
????after.before = this;
}createEntry(int hash,K key,V value,int bucketIndex)方法覆蓋了父類HashMap中的方法。這個方法不會拓展table數(shù)組的大小。該方法首先保留table中bucketIndex處的節(jié)點,然后調(diào)用Entry的構(gòu)造方法(將調(diào)用到父類HashMap.Entry的構(gòu)造方法)添加一個節(jié)點,即將當前節(jié)點的next引用指向table[bucketIndex] 的節(jié)點,之后調(diào)用的e.addBefore(header)是修改鏈表,將e節(jié)點添加到header節(jié)點之前。
第2行~第4行的代碼和HashMap沒有什么不同,新添加的元素放在table[i]上,差別在于LinkedHashMap還做了addBefore操作,這四行代碼的意思就是讓新的Entry和原鏈表生成一個雙向鏈表。假設(shè)字符串111放在位置table[1]上,生成的Entry地址為0x00000001,那么用圖表示是這樣的:
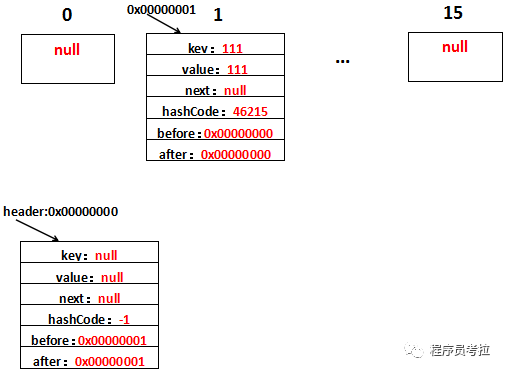
如果熟悉LinkedList的源碼應(yīng)該不難理解,還是解釋一下,注意下existingEntry表示的是header:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此時是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此時為0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此時為0x00000000即header,header的before=this,即header的before=0x00000001
這樣,header與新增的Entry的一個雙向鏈表就形成了。再看,新增了字符串222之后是什么樣的,假設(shè)新增的Entry的地址為0x00000002,生成到table[2]上,用圖表示是這樣的:

就不細解釋了,只要before、after清除地知道代表的是哪個Entry的就不會有什么問題。
注意,這里的插入有兩重含義:
1.從table的角度看,新的entry需要插入到對應(yīng)的bucket里,當有哈希沖突時,采用頭插法將新的entry插入到?jīng)_突鏈表的頭部。
2.從header的角度看,新的entry需要插入到雙向鏈表的尾部。
總得來看,再說明一遍,LinkedHashMap的實現(xiàn)就是HashMap+LinkedList的實現(xiàn)方式,以HashMap維護數(shù)據(jù)結(jié)構(gòu),以LinkList的方式維護數(shù)據(jù)插入順序。
六、LinkedHashMap讀取元素
LinkedHashMap重寫了父類HashMap的get方法,實際在調(diào)用父類getEntry()方法取得查找的元素后,再判斷當排序模式accessOrder為true時(即按訪問順序排序),先將當前節(jié)點從鏈表中移除,然后再將當前節(jié)點插入到鏈表尾部。由于的鏈表的增加、刪除操作是常量級的,故并不會帶來性能的損失。
/**
?* 通過key獲取value,與HashMap的區(qū)別是:當LinkedHashMap按訪問順序排序的時候,會將訪問的當前節(jié)點移到鏈表尾部(頭結(jié)點的前一個節(jié)點)
?*/
public?V get(Object key) {
????// 調(diào)用父類HashMap的getEntry()方法,取得要查找的元素。
????Entry e = (Entry)getEntry(key);
????if?(e == null)
????????return?null;
????// 記錄訪問順序。
????e.recordAccess(this);
????return?e.value;
} /**
?* 在HashMap的put和get方法中,會調(diào)用該方法,在HashMap中該方法為空
?* 在LinkedHashMap中,當按訪問順序排序時,該方法會將當前節(jié)點插入到鏈表尾部(頭結(jié)點的前一個節(jié)點),否則不做任何事
?*/
void?recordAccess(HashMap m ) {
????LinkedHashMap lm = (LinkedHashMap)m;
????//當LinkedHashMap按訪問排序時
????if?(lm.accessOrder) {
????????lm.modCount++;
????????//移除當前節(jié)點
????????remove();
????????//將當前節(jié)點插入到頭結(jié)點前面
????????addBefore(lm.header);
????}
} /**
?* 移除節(jié)點,并修改前后引用
?*/
private?void?remove()?{
????before.after = after;
????after.before = before;
}private?void?addBefore(Entry existingEntry) ?{
????after = existingEntry;
????before = existingEntry.before;
????before.after = this;
????after.before = this;
}七、利用LinkedHashMap實現(xiàn)LRU算法緩存
前面講了LinkedHashMap添加元素,刪除、修改元素就不說了,比較簡單,和HashMap+LinkedList的刪除、修改元素大同小異,下面講一個新的內(nèi)容。
LinkedHashMap可以用來作緩存,比方說LRUCache,看一下這個類的代碼,很簡單,就十幾行而已:
public?class?LRUCache?extends?LinkedHashMap
{
????public?LRUCache(int?maxSize)
????{
????????super(maxSize, 0.75F, true);
????????maxElements = maxSize;
????}
????protected?boolean?removeEldestEntry(java.util.Map.Entry eldest)
????{
????????return?size() > maxElements;
????}
????private?static?final?long?serialVersionUID = 1L;
????protected?int?maxElements;
}顧名思義,LRUCache就是基于LRU算法的Cache(緩存),這個類繼承自LinkedHashMap,而類中看到?jīng)]有什么特別的方法,這說明LRUCache實現(xiàn)緩存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以實現(xiàn)LRU算法的緩存基于兩點:
1、LinkedList首先它是一個Map,Map是基于K-V的,和緩存一致
2、LinkedList提供了一個boolean值可以讓用戶指定是否實現(xiàn)LRU
那么,首先我們了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是說,當緩存滿了,會優(yōu)先淘汰那些最近最不常訪問的數(shù)據(jù)。比方說數(shù)據(jù)a,1天前訪問了;數(shù)據(jù)b,2天前訪問了,緩存滿了,優(yōu)先會淘汰數(shù)據(jù)b。
我們看一下LinkedList帶boolean型參數(shù)的構(gòu)造方法:
public?LinkedHashMap(int?initialCapacity,
?????????float?loadFactor,
?????????????????????boolean?accessOrder)?{
????super(initialCapacity, loadFactor);
????this.accessOrder = accessOrder;
}就是這個accessOrder,它表示:
(1)false,所有的Entry按照插入的順序排列
(2)true,所有的Entry按照訪問的順序排列
第二點的意思就是,如果有1 2 3這3個Entry,那么訪問了1,就把1移到尾部去,即2 3 1。每次訪問都把訪問的那個數(shù)據(jù)移到雙向隊列的尾部去,那么每次要淘汰數(shù)據(jù)的時候,雙向隊列最頭的那個數(shù)據(jù)不就是最不常訪問的那個數(shù)據(jù)了嗎?換句話說,雙向鏈表最頭的那個數(shù)據(jù)就是要淘汰的數(shù)據(jù)。
"訪問",這個詞有兩層意思:
1、根據(jù)Key拿到Value,也就是get方法
2、修改Key對應(yīng)的Value,也就是put方法
首先看一下get方法,它在LinkedHashMap中被重寫:
public?V get(Object key) {
????Entry e = (Entry)getEntry(key);
????if?(e == null)
????????return?null;
????e.recordAccess(this);
????return?e.value;
} 然后是put方法,沿用父類HashMap的:
public?V put(K key, V value) {
????if?(key == null)
????????return?putForNullKey(value);
????int?hash = hash(key.hashCode());
????int?i = indexFor(hash, table.length);
????for?(Entry e = table[i]; e != null; e = e.next) {
????????Object k;
????????if?(e.hash == hash && ((k = e.key) == key || key.equals(k))) {
????????????V oldValue = e.value;
????????????e.value?= value;
????????????e.recordAccess(this);
????????????return?oldValue;
????????}
????}
????modCount++;
????addEntry(hash, key, value, i);
????return?null;
} 修改數(shù)據(jù)也就是第6行~第14行的代碼。看到兩端代碼都有一個共同點:都調(diào)用了recordAccess方法,且這個方法是Entry中的方法,也就是說每次的recordAccess操作的都是某一個固定的Entry。
recordAccess,顧名思義,記錄訪問,也就是說你這次訪問了雙向鏈表,我就把你記錄下來,怎么記錄?把你訪問的Entry移到尾部去。這個方法在HashMap中是一個空方法,就是用來給子類記錄訪問用的,看一下LinkedHashMap中的實現(xiàn):
void?recordAccess(HashMap m ) {
????LinkedHashMap lm = (LinkedHashMap)m;
????if?(lm.accessOrder) {
????????lm.modCount++;
????????remove();
????????addBefore(lm.header);
????}
} private?void?remove()?{
????before.after = after;
????after.before = before;
}private?void?addBefore(Entry existingEntry) ?{
????after = existingEntry;
????before = existingEntry.before;
????before.after = this;
????after.before = this;
}看到每次recordAccess的時候做了兩件事情:
1、把待移動的Entry的前后Entry相連
2、把待移動的Entry移動到尾部
當然,這一切都是基于accessOrder=true的情況下。最后用一張圖表示一下整個recordAccess的過程吧:

void
recordAccess(HashMap
八、代碼演示LinkedHashMap按照訪問順序排序的效果
最后代碼演示一下LinkedList按照訪問順序排序的效果,驗證一下上一部分LinkedHashMap的LRU功能:
public?static?void?main(String[] args)
{
????LinkedHashMap<String, String> linkedHashMap =
????????????new?LinkedHashMap<String, String>(16, 0.75f, true);
????linkedHashMap.put("111", "111");
????linkedHashMap.put("222", "222");
????linkedHashMap.put("333", "333");
????linkedHashMap.put("444", "444");
????loopLinkedHashMap(linkedHashMap);
????linkedHashMap.get("111");
????loopLinkedHashMap(linkedHashMap);
????linkedHashMap.put("222", "2222");
????loopLinkedHashMap(linkedHashMap);
}
????
public?static?void?loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
????SetString, String>> set?= inkedHashMap.entrySet();
????IteratorString, String>> iterator = set.iterator();
????
????while?(iterator.hasNext())
????{
????????System.out.print(iterator.next() + "\t");
????}
????System.out.println();
} 注意這里的構(gòu)造方法要用三個參數(shù)那個且最后的要傳入true,這樣才表示按照訪問順序排序。看一下代碼運行結(jié)果:
111=111?222=222?333=333?444=444?
222=222?333=333?444=444?111=111?
333=333?444=444?111=111?222=2222代碼運行結(jié)果證明了兩點:
1、LinkedList是有序的
2、每次訪問一個元素(get或put),被訪問的元素都被提到最后面去了
原文鏈接:cnblogs.com/xiaoxi/p/6170590.html