
看完這篇AI算法和筆記,跟面試官扯皮沒問題了 | 基于深度學(xué)習(xí)和傳統(tǒng)算法的人體姿態(tài)估計(jì)
點(diǎn)擊藍(lán)色“AI專欄”關(guān)注我喲

關(guān)于人類活動(dòng)規(guī)律的研究,必定是計(jì)算機(jī)視覺領(lǐng)域首要關(guān)注的內(nèi)容。其中,人體姿態(tài)估計(jì)便是計(jì)算機(jī)視覺領(lǐng)域現(xiàn)有的熱點(diǎn)問題,其主要任務(wù)是讓機(jī)器自動(dòng)地檢測(cè)場(chǎng)景中的人“在哪里”和理解人在“干什么”。

除了工作人員很難長時(shí)間地保持高度警惕外,長期投入大量的人力來監(jiān)測(cè)小概率發(fā)生的事件也不是單位機(jī)構(gòu)提倡的做法。因此,實(shí)現(xiàn)視頻監(jiān)控的智能化成為一種互聯(lián)網(wǎng)時(shí)代的必然趨勢(shì)。但是,實(shí)現(xiàn)智能視頻監(jiān)控的前提條件是讓機(jī)器自動(dòng)地識(shí)別視頻圖像序列中的人體姿態(tài),從而進(jìn)一步分析視頻圖像中人類的行為活動(dòng)。
燒
人體行為分析理解成為了近幾年研究的熱點(diǎn)之一。在人體行為分析理解的發(fā)展過程中,研究人員攻克了很多技術(shù)上的難關(guān),并形成了一些經(jīng)典算法,但仍有很多尚未解決的問題。從研究的發(fā)展趨勢(shì)來看,人體行為分析的研究正由采用單一特征、單一傳感器向采用多特征、多傳感器的方向發(fā)展。而人體姿態(tài)估計(jì)作為人體行為識(shí)別的一個(gè)重要特征,是進(jìn)行人體行為分析的基礎(chǔ),是人體行為分析領(lǐng)域備受關(guān)注的研究方向之一。

燒
目前主流的人體姿態(tài)估計(jì)算法可以劃分為傳統(tǒng)方法和基于深度學(xué)習(xí)的方法。
基于傳統(tǒng)方法的人體姿態(tài)估計(jì)
其缺點(diǎn)是什么?
First,傳統(tǒng)方法雖然擁有較高的時(shí)間效率,但是由于其提取的特征主要是人工設(shè)定的HOG和SHIFT特征,無法充分利用圖像信息,導(dǎo)致算法受制于圖像中的不同外觀、視角、遮擋和固有的幾何模糊性。同時(shí),由于部件模型的結(jié)構(gòu)單一,當(dāng)人體姿態(tài)變化較大時(shí),部件模型不能精確地刻畫和表達(dá)這種形變,同一數(shù)據(jù)存在多個(gè)可行的解,即姿態(tài)估計(jì)的結(jié)果不唯一,導(dǎo)致傳統(tǒng)方法適用范圍受到很大限制。
Second,另一方面,傳統(tǒng)方法很多是基于深度圖等數(shù)字圖像提取姿態(tài)特征的算法,但是由于采集深度圖像需要使用專業(yè)的采集設(shè)備,成本較高,所以很難適用于所有的應(yīng)用場(chǎng)景,而且采集過程需要同步多個(gè)視角的深度攝像頭以減小遮擋問題帶來的影響,導(dǎo)致人體姿態(tài)數(shù)據(jù)的獲取過程復(fù)雜困難。因此這種傳統(tǒng)的基于手工提取特征,并利用部件模型建立特征之間聯(lián)系的方法大多數(shù)是昂貴和低效的。
基于深度學(xué)習(xí)的人體姿態(tài)估計(jì)算法
隨著大數(shù)據(jù)時(shí)代的到來,深度學(xué)習(xí)在計(jì)算機(jī)視覺領(lǐng)域得到了成功的應(yīng)用。因此,考慮如何將深度學(xué)習(xí)用于解決人體姿態(tài)估計(jì)問題,是人體姿態(tài)估計(jì)領(lǐng)域的學(xué)者們繼圖結(jié)構(gòu)模型后所要探索的另一個(gè)重點(diǎn)。早期利用深度學(xué)習(xí)估計(jì)人體姿態(tài)的方法,都是通過深度學(xué)習(xí)網(wǎng)絡(luò)直接回歸出輸入圖像中關(guān)節(jié)點(diǎn)的坐標(biāo)。
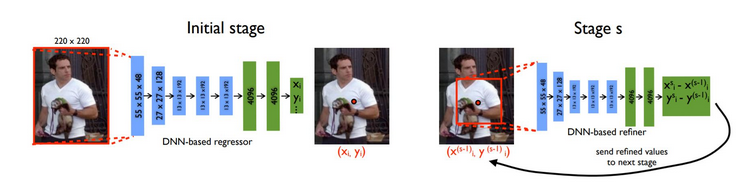
其好處是什么?
First,相較之下日常生活中的單目攝像頭更為常見,雖然其采集的彩色圖像容易受到光照等環(huán)境因素的影響,但是可以利用神經(jīng)網(wǎng)絡(luò)提取出比人工特征更為準(zhǔn)確和魯棒的卷積特征,以預(yù)測(cè)更為復(fù)雜的姿態(tài),所以基于深度學(xué)習(xí)的人體姿態(tài)估計(jì)方法得到了深入的研究。
Second,不同于傳統(tǒng)方法顯式地設(shè)計(jì)特征提取器和局部探測(cè)器,進(jìn)行深度學(xué)習(xí)時(shí)構(gòu)建CNN比較容易實(shí)現(xiàn),同時(shí)可以設(shè)計(jì)處理序列問題的CNN模型,例如循環(huán)神經(jīng)網(wǎng)絡(luò)RNN,通過分析連續(xù)多幀圖像獲得人體姿態(tài)的變化規(guī)律,進(jìn)而為人體姿態(tài)中各個(gè)關(guān)節(jié)點(diǎn)之間建立更為準(zhǔn)確的拓?fù)浣Y(jié)構(gòu)。
但是,如何在表征人體復(fù)雜結(jié)構(gòu)的理論數(shù)學(xué)模型和提升估計(jì)結(jié)果的精度上同時(shí)取得突破,是人體姿態(tài)估計(jì)領(lǐng)域一直以來探索的終極目標(biāo)。因此,人體姿態(tài)估計(jì)領(lǐng)域在未來的工作中具有較大的研究發(fā)展空間。
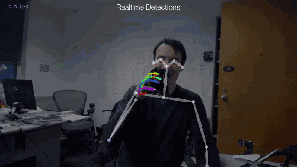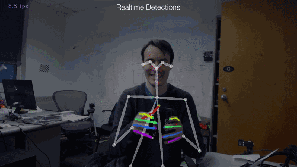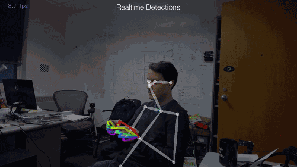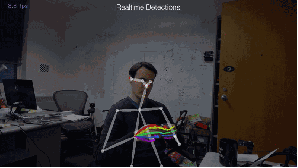
Fig.4: 2D估計(jì)
本文站長主要是想談?wù)?strong>基于深度學(xué)習(xí)的實(shí)時(shí)多人姿態(tài)估計(jì)。主要是拜讀了文獻(xiàn)7,所以本文站長想談?wù)勛约和ㄟ^很多文獻(xiàn)的全面閱讀后,自己的一些想法和理解,有理解不到位的地方請(qǐng)大家斧正,謝謝。
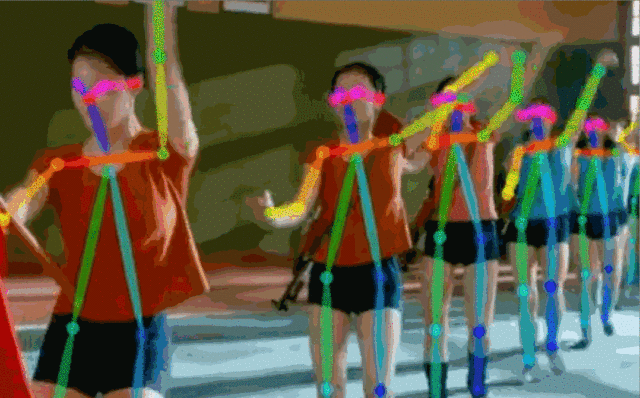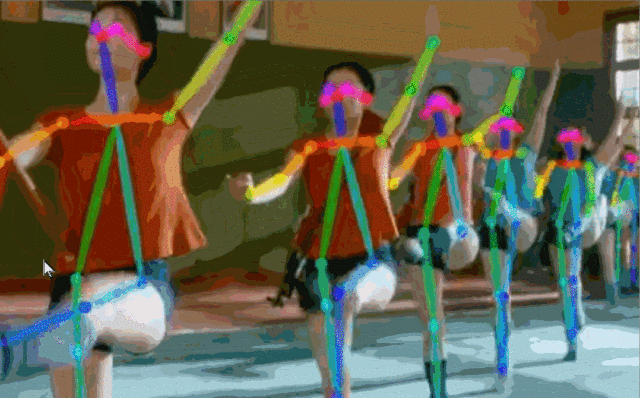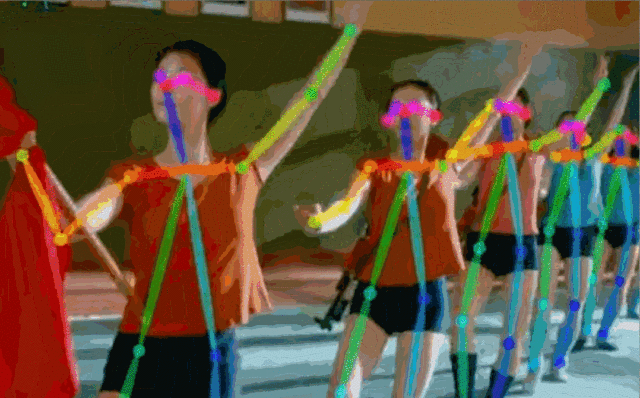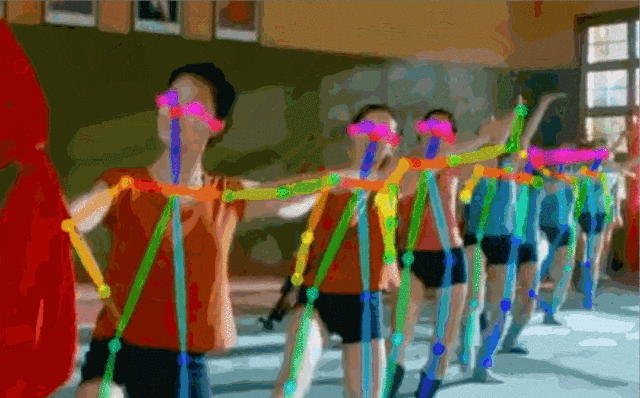
Fig.5: 實(shí)時(shí)多人估計(jì)
自頂向下
自底向上
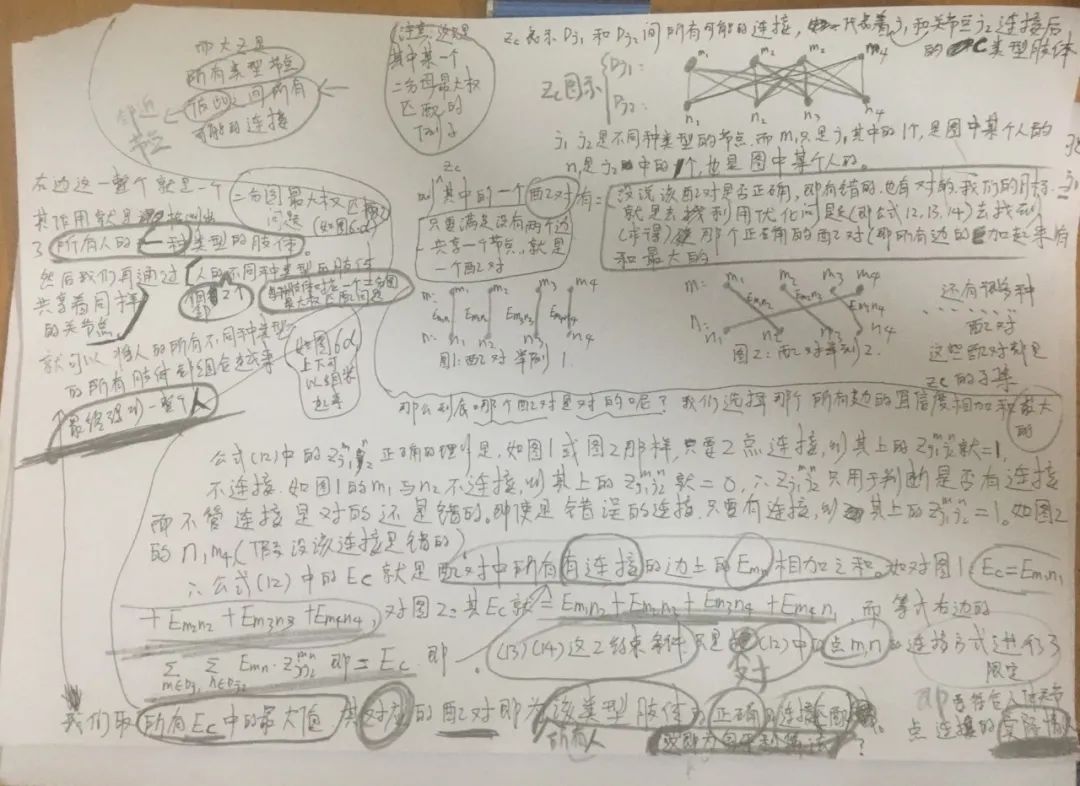
對(duì)于一張輸入圖像,深度神經(jīng)網(wǎng)絡(luò)同時(shí)預(yù)測(cè)出每個(gè)骨點(diǎn)的熱力圖S=(S1,S2,…,SJ)和骨點(diǎn)之間的親和區(qū)域L=(L1,L2,…,LC) 。熱力圖的峰值為骨點(diǎn)的位置,骨點(diǎn)相互連接構(gòu)成二分圖,親和區(qū)域?qū)D的連接進(jìn)行稀疏,最后對(duì)二分圖進(jìn)行最優(yōu)化實(shí)現(xiàn)多人姿態(tài)估計(jì)。
網(wǎng)絡(luò)結(jié)構(gòu)深度解讀
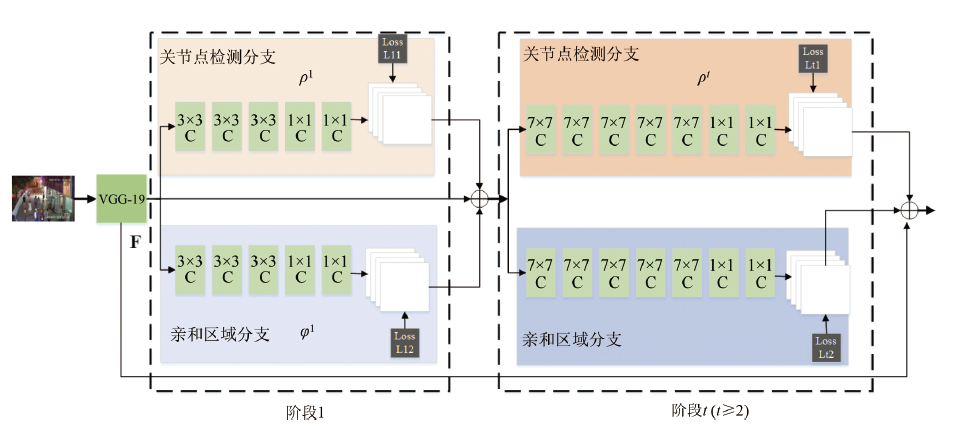
在第一階段,對(duì)于輸入特征采用3×3大小的卷積核連續(xù)進(jìn)行三次卷積,之后用1×1 大小的卷積核連續(xù)進(jìn)行三次卷積。
之后的階段將前一階段的預(yù)測(cè)結(jié)果和原圖像特征F進(jìn)行融合,作為當(dāng)前階段的輸入,經(jīng)過卷積操作分別預(yù)測(cè)出關(guān)節(jié)點(diǎn)熱力圖和關(guān)節(jié)點(diǎn)的親緣關(guān)系程度(站長自己的理解haha,簡(jiǎn)單點(diǎn)就是兩個(gè)關(guān)節(jié)點(diǎn)的朋友關(guān)系的親密程度唄):
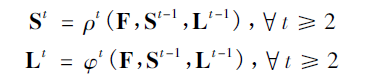
由于關(guān)節(jié)點(diǎn)熱力圖和關(guān)節(jié)點(diǎn)的親緣關(guān)系程度本質(zhì)有所不同,因此在訓(xùn)練的時(shí)候需要分別對(duì)關(guān)節(jié)點(diǎn)位置和親和區(qū)域進(jìn)行監(jiān)督,損失函數(shù)均采用L2損失。為了避免梯度消失現(xiàn)象發(fā)生,在每個(gè)階段的輸出都添加損失函數(shù),起到中繼監(jiān)督作用。
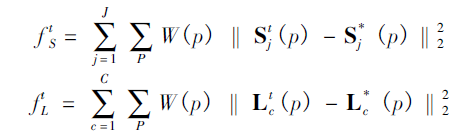
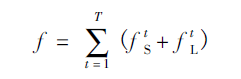
關(guān)于
關(guān)節(jié)點(diǎn)熱力圖

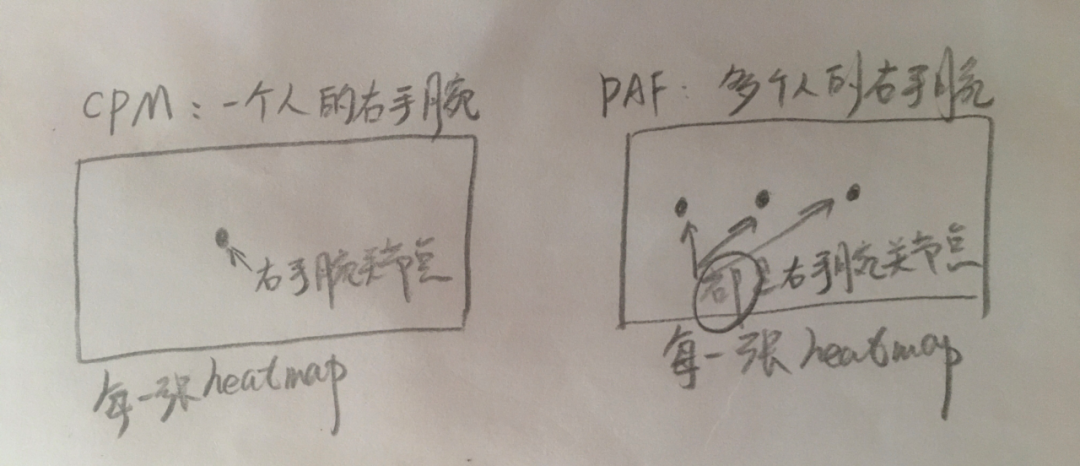
強(qiáng)調(diào)!Attention!
與CPM不同,CPM網(wǎng)絡(luò)只是針對(duì)單個(gè)人的Pose,所以它的網(wǎng)絡(luò)輸出的P張置信度圖中(假如一個(gè)人總共有P個(gè)關(guān)節(jié)點(diǎn)),每一張置信度上只有一個(gè)熱點(diǎn),這個(gè)熱點(diǎn)只是一個(gè)人的一個(gè)關(guān)節(jié)點(diǎn),比如右手腕關(guān)節(jié)這個(gè)關(guān)節(jié)點(diǎn)。
但如果圖片上有多個(gè)人,它的第一行網(wǎng)絡(luò)輸出的P張置信度圖中(假如單個(gè)人總共有P個(gè)關(guān)節(jié)點(diǎn)),每一張置信度上就有多個(gè)熱點(diǎn)了,比如右手腕關(guān)節(jié),假設(shè)有K個(gè)人,則要有K個(gè)右手腕關(guān)節(jié)點(diǎn),所以此時(shí)這張置信度上就要有K個(gè)熱點(diǎn)了。
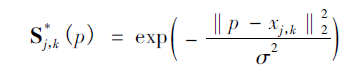
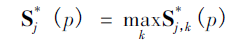
關(guān)節(jié)點(diǎn)親和區(qū)域

這是這個(gè)網(wǎng)絡(luò)實(shí)現(xiàn)關(guān)節(jié)點(diǎn)檢測(cè)的關(guān)鍵所在了,上面經(jīng)過網(wǎng)絡(luò)推理,得到骨點(diǎn)熱力圖以及骨點(diǎn)之間的親和區(qū)域,對(duì)熱力圖采取非極大值抑制得到一系列候選骨點(diǎn)。由于多人或者錯(cuò)誤檢測(cè),對(duì)于每一類型的骨點(diǎn)會(huì)存在多個(gè)候選骨點(diǎn)。這些候選骨點(diǎn)之間的連接構(gòu)成二分圖,每兩個(gè)骨點(diǎn)之間的連接置信度通過線積分計(jì)算得到。為二分圖找到最優(yōu)的稀疏性是NP-Hard 問題。
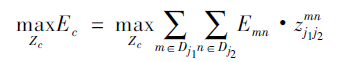
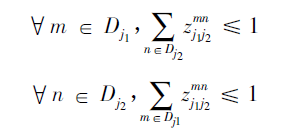
其中Ec為二分圖優(yōu)化之后肢體c的權(quán)重,我們要取其中總權(quán)重之和最大的;
Zc為所有骨點(diǎn)連接集合Z的子集;
約束條件表示一段肢體最多只存在一條連接邊。
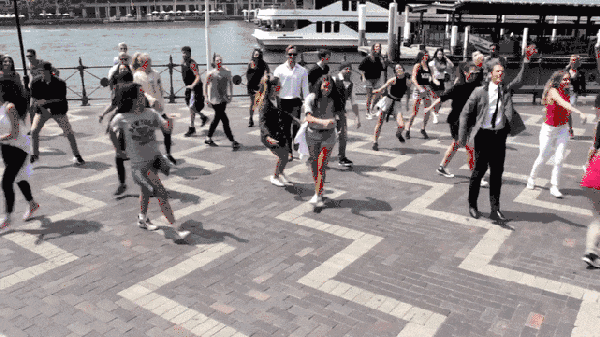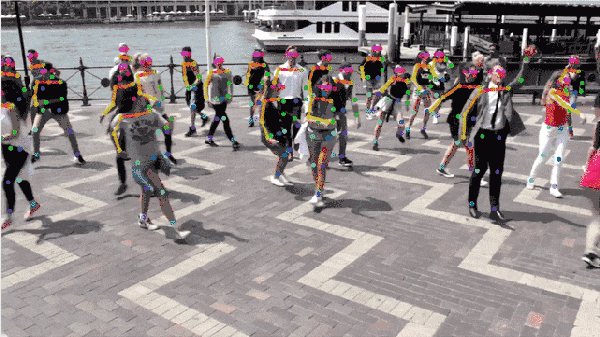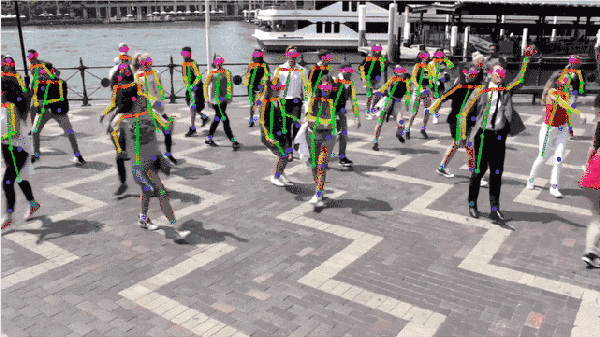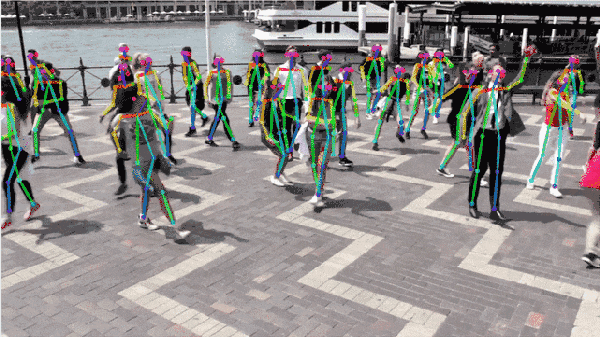
Fig.11: 算法效果
問題分解與簡(jiǎn)化
首先,如圖所示,剔除跨骨點(diǎn)之間的連接構(gòu)成稀疏二分圖,代替全連接二分圖; 然后根據(jù)肢體將稀疏后的二分圖拆解得到圖所示的多個(gè)簡(jiǎn)化二分圖。
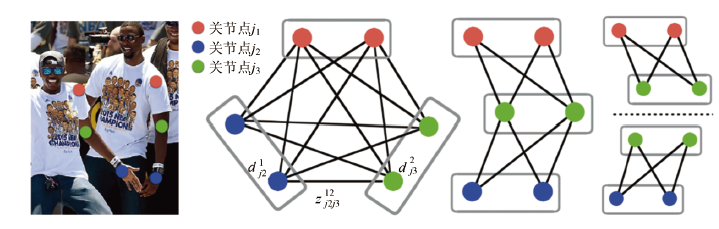
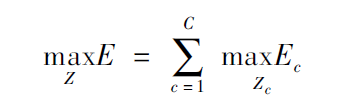
我對(duì)這個(gè)算法的整體思路做了個(gè)筆記,字太丑了orz,大家別見怪haha,道理講明白理解清楚就行了(要高清原圖的可以加站長微信領(lǐng)取哦)
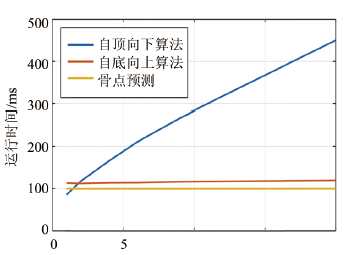
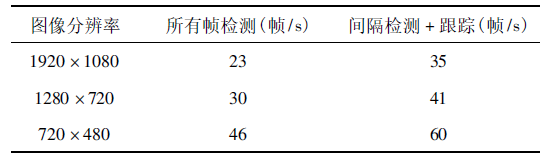
實(shí)驗(yàn)所使用的顯卡為NVIDIA TITAN XP,CPU為Intel i7-6900K。圖像大小為1920× 1080,通過下采樣方法額外獲得1280 × 720 和720 × 480 兩個(gè)低分辨率的視頻。
首先分析運(yùn)行效率與人數(shù)的關(guān)系,在相同視頻流和相同分辨情況下,計(jì)算自頂向下與自底向上運(yùn)行時(shí)間與人數(shù)關(guān)系,計(jì)算結(jié)果如圖14所示。由圖可知,自頂向下隨著人數(shù)的增加耗時(shí)幾乎呈線性增加,而自底向上的運(yùn)行耗時(shí)幾乎不隨人數(shù)增加而遞增。卷積神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)關(guān)節(jié)點(diǎn)的耗時(shí)也幾乎不隨人數(shù)增加而增加。因此我所使用的自底向上算法的運(yùn)行效率不受行人數(shù)量的影響,對(duì)人數(shù)不確定的情況依然可以實(shí)時(shí)進(jìn)行多人姿態(tài)估計(jì)。
站長測(cè)試(使用自己亂糟糟的圖片才有說服力哈)

能閱讀到這里,說明你也是個(gè)踏踏實(shí)實(shí)的做研究的人了。此時(shí),我們娛樂時(shí)間到了,讓我們來段測(cè)試視頻放松放松下哈:
六階段雙分支網(wǎng)絡(luò)結(jié)構(gòu)在關(guān)節(jié)點(diǎn)預(yù)測(cè)精度上略高于現(xiàn)有傳統(tǒng)的的人體姿態(tài)估計(jì)算法。本次站長采用的算法利用自底向上的思想,首先預(yù)測(cè)出所有骨點(diǎn)位置,并將骨點(diǎn)連接形成圖結(jié)構(gòu),通過圖優(yōu)化實(shí)現(xiàn)多人體姿態(tài)估計(jì)。算法運(yùn)行效率方面,由于網(wǎng)絡(luò)同時(shí)預(yù)測(cè)出關(guān)節(jié)點(diǎn)位置和關(guān)節(jié)點(diǎn)之間的空間關(guān)系,為多人姿態(tài)估計(jì)算法提供更加稀疏的二分圖,降低二分圖優(yōu)化復(fù)雜度而達(dá)到了實(shí)時(shí)的效果。
歡迎各位站友關(guān)注【AI專欄】加特別寵粉的站長微信交流交流算法哈。圖中3rdparty文件夾下主要包含caffe等第三方工具,build文件主要是cmake操作生成的。cmake文件主要包含一系列cmake操作的文件,examples下主要是一些demo案例程序,models主要是訓(xùn)練好的模型。
巨人的肩膀
[1] Qian C, Sun X, Wei Y, et al. Realtime and robust hand trackingfrom depth[C]//Proceedings of the IEEE conference on computer vision and patternrecognition. 2014: 1106-1113.
[2] Joseph? Tan? D,?Cashman? T,? Taylor?J,? et? al.?Fits? like? a?glove:? Rapid? and?reliable? hand shape? personalization[A].? IEEE?Conference? on? Computer?Vision? and? Pattern Recognition[C], 2016: 5610-5619.
[3] Tang D, Jin Chang H, Tejani A, et al. Latent regression forest:Structured estimation of 3d articulated hand posture[A]. IEEE conference oncomputer vision and pattern recognition[A], 2014: 3786-3793.?
[4] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification withdeep convolutional neural networks[A]. Advances in neural informationprocessing systems[C], 2012: 1097-1105.
[5] Zhou E, Cao Z, Yin Q. Naive-Deep Face Recognition: Touching theLimit of LFW Benchmark or Not?[J]. Computer Science, 2015.
[6]?? Sharp? T,? Keskin?C,? Robertson? D,?et? al.? Accurate,?robust,? and? flexible?real-time? hand tracking[A].? Proceedings?of? the ?33rd?Annual? ACM? Conference on Human? Factors?in Computing Systems. ACM[C], 2015: 3633-3642.
[8] Oberweger? M? ,?Wohlhart? P? ,?Lepetit? V? .?Hands? Deep? in?Deep? Learning? for?Hand? Pose Estimation[J]. ComputerScience, 2015.
嘮叨嘮叨
CSDN博客:ID:qq_40636639,昵稱:AI專欄的站長知乎:AI驛站
站長個(gè)人微信
添加站長個(gè)人微信即送
500多本程序員必讀經(jīng)典書籍
→ 精選技術(shù)資料共享
→?微信看朋友圈私貨
→ 高手如云交流社群
?
推薦閱讀
5T技術(shù)資源大放送!包括但不限于:C/C++,Python,Java,PHP,人工智能,單片機(jī),樹莓派,等等。請(qǐng)關(guān)注并在公眾號(hào)內(nèi)回復(fù)「1024」,即可免費(fèi)獲取!!
關(guān)于交流群
目前站長已經(jīng)建立多個(gè)AI技術(shù)細(xì)分方向交流群,歡迎各位站友加入本公眾號(hào)讀者群一起和同行交流,目前有雙目立體視覺、三維重建、強(qiáng)化學(xué)習(xí)、分割、SLAM、識(shí)別、GAN、算法競(jìng)賽、醫(yī)學(xué)影像、副業(yè)賺錢交流、計(jì)算攝影、春招內(nèi)推群、秋招內(nèi)推群等微信群(以后站長會(huì)逐漸細(xì)分,所以一定要備注好方向!謝謝)。
請(qǐng)掃描下面站長微信拉你入群,請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)您的研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~
(請(qǐng)務(wù)必備注:”研究方向+學(xué)校/公司+昵稱“,比如:”人臉識(shí)別檢測(cè)+ 上海交大 + 靜靜“)
長按掃碼,申請(qǐng)入群
(添加人數(shù)較多,請(qǐng)耐心等待)
關(guān)于本公眾號(hào)
當(dāng)然是干貨資源教程滿滿吖
關(guān)注即可免費(fèi)領(lǐng)取資源,Goodbye,我們下次見!
關(guān)注領(lǐng)取500多本程序員必讀經(jīng)典書籍
? ???????? ? ? ? 最新 AI 干貨,我在看?