
分庫分表 與NewSQL數據庫
作者 | 蚊子squirrel
NewSQL數據庫先進在哪兒?
基于中間件(包括SDK和Proxy兩種形式)+傳統(tǒng)關系數據庫(分庫分表)模式是不是分布式架構?
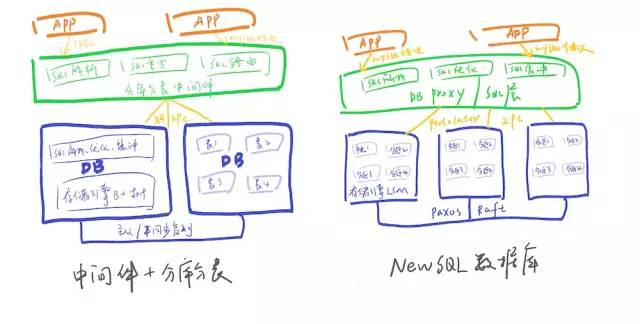
傳統(tǒng)數據庫面向磁盤設計,基于內存的存儲管理及并發(fā)控制,不如NewSQL數據庫那般高效利用。 中間件模式SQL解析、執(zhí)行計劃優(yōu)化等在中間件與數據庫中重復工作,效率相比較低; NewSQL數據庫的分布式事務相比于XA進行了優(yōu)化,性能更高; 新架構NewSQL數據庫存儲設計即為基于paxos(或Raft)協(xié)議的多副本,相比于傳統(tǒng)數據庫主從模式(半同步轉異步后也存在丟數問題),在實現(xiàn)了真正的高可用、高可靠(RTO<30s,RPO=0) NewSQL數據庫天生支持數據分片,數據的遷移、擴容都是自動化的,大大減輕了DBA的工作,同時對應用透明,無需在SQL指定分庫分表鍵。
首先要說的就是分布式事務:這是一把雙刃劍。
CAP限制
推薦一篇關于分布式系統(tǒng)有趣的文章,站在巨人的分布式肩膀上,其中提到:分布式系統(tǒng)中,您可以知道工作在哪里,或者您可以知道工作何時完成,但您無法同時了解兩者;兩階段協(xié)議本質上是反可用性協(xié)議。
完備性
兩階段提交協(xié)議是否嚴格支持ACID,各種異常場景是不是都可以覆蓋?
2PC在commit階段發(fā)送異常,其實跟最大努力一階段提交類似也會有部分可見問題,嚴格講一段時間內并不能保證A原子性和C一致性(待故障恢復后recovery機制可以保證最終的A和C)。
完備的分布式事務支持并不是一件簡單的事情,需要可以應對網絡以及各種硬件包括網卡、磁盤、CPU、內存、電源等各類異常,通過嚴格的測試。
之前跟某友商交流,他們甚至說目前已知的NewSQL在分布式事務支持上都是不完整的,他們都有案例跑不過,圈內人士這么篤定,也說明了分布式事務的支持完整程度其實是層次不齊的。
但分布式事務又是這些NewSQL數據庫的一個非常重要的底層機制,跨資源的DML、DDL等都依賴其實現(xiàn),如果這塊的性能、完備性打折扣,上層跨分片SQL執(zhí)行的正確性會受到很大影響。
性能
傳統(tǒng)關系數據庫也支持分布式事務XA,但為何很少有高并發(fā)場景下用呢?
因為XA的基礎兩階段提交協(xié)議存在網絡開銷大,阻塞時間長、死鎖等問題,這也導致了其實際上很少大規(guī)模用在基于傳統(tǒng)關系數據庫的OLTP系統(tǒng)中。
SI是樂觀鎖,在熱點數據場景,可能會大量的提交失敗。另外SI的隔離級別與RR并無完全相同,它不會有幻想讀,但會有寫傾斜。
解決分布式事務是否只能用兩階段提交協(xié)議? oceanbase1.0中通過updateserver避免分布式事務的思路很有啟發(fā)性 ,不過2.0版后也變成了2PC。
業(yè)界分布式事務也并非只有兩階段提交這一解,也有其它方案its-time-to-move-on-from-two-phase(如果打不開,國內有翻譯版https://www.jdon.com/51588)
HA與異地多活
主從模式并不是最優(yōu)的方式,就算是半同步復制,在極端情況下(半同步轉異步)也存在丟數問題
目前業(yè)界公認更好的方案是基于paxos分布式一致性協(xié)議或者其它類paxos如raft方式,Google Spanner、TiDB、cockcoachDB、OB都采用了這種方式,基于Paxos協(xié)議的多副本存儲,遵循過半寫原則,支持自動選主,解決了數據的高可靠,縮短了failover時間,提高了可用性,特別是減少了運維的工作量,這種方案技術上已經很成熟,也是NewSQL數據庫底層的標配。
分布式一致性算法本身并不難,但具體在工程實踐時,需要考慮很多異常并做很多優(yōu)化,實現(xiàn)一個生產級可靠成熟的一致性協(xié)議并不容易。例如實際使用時必須轉化實現(xiàn)為multi-paxos或multi-raft,需要通過batch、異步等方式減少網絡、磁盤IO等開銷。
Scale橫向擴展與分片機制
paxos算法解決了高可用、高可靠問題,并沒有解決Scale橫向擴展的問題,所以分片是必須支持的。NewSQL數據庫都是天生內置分片機制的,而且會根據每個分片的數據負載(磁盤使用率、寫入速度等)自動識別熱點,然后進行分片的分裂、數據遷移、合并,這些過程應用是無感知的,這省去了DBA的很多運維工作量。以TiDB為例,它將數據切成region,如果region到64M時,數據自動進行遷移。
分庫分表模式也能做到在線擴容,基本思路是通過異步復制先追加數據,然后設置只讀完成路由切換,最后放開寫操作,當然這些需要中間件與數據庫端配合一起才能完成。
分布式SQL支持
常見的單分片SQL,這兩者都能很好支持。NewSQL數據庫由于定位與目標是一個通用的數據庫,所以支持的SQL會更完整,包括跨分片的join、聚合等復雜SQL。中間件模式多面向應用需求設計,不過大部分也支持帶拆分鍵SQL、庫表遍歷、單庫join、聚合、排序、分頁等。但對跨庫的join以及聚合支持就不夠了。
NewSQL數據庫往往選擇兼容MySQL或者PostgreSQL協(xié)議,所以SQL支持僅局限于這兩種,中間件例如驅動模式往往只需做簡單的SQL解析、計算路由、SQL重寫,所以可以支持更多種類的數據庫SQL。
這里也可以看出中間件+分庫分表模式的架構風格體現(xiàn)出的是一種妥協(xié)、平衡,它是一個面向應用型的設計;而NewSQL數據庫則要求更高、“大包大攬”,它是一個通用底層技術軟件,因此后者的復雜度、技術門檻也高很多。
存儲引擎
傳統(tǒng)關系數據庫的存儲引擎設計都是面向磁盤的,大多都基于B+樹。B+樹通過降低樹的高度減少隨機讀、進而減少磁盤尋道次數,提高讀的性能,但大量的隨機寫會導致樹的分裂,從而帶來隨機寫,導致寫性能下降。
NewSQL的底層存儲引擎則多采用LSM,相比B+樹LSM將對磁盤的隨機寫變成順序寫,大大提高了寫的性能。
不過LSM的的讀由于需要合并數據性能比B+樹差,一般來說LSM更適合應在寫大于讀的場景。當然這只是單純數據結構角度的對比,在數據庫實際實現(xiàn)時還會通過SSD、緩沖、bloom filter等方式優(yōu)化讀寫性能,所以讀性能基本不會下降太多。
NewSQL數據由于多副本、分布式事務等開銷,相比單機關系數據庫SQL的響應時間并不占優(yōu),但由于集群的彈性擴展,整體QPS提升還是很明顯的,這也是NewSQL數據庫廠商說分布式數據庫更看重的是吞吐,而不是單筆SQL響應時間的原因。
成熟度與生態(tài)
分布式數據庫是個新型通用底層軟件,準確的衡量與評價需要一個多維度的測試模型,需包括發(fā)展現(xiàn)狀、使用情況、社區(qū)生態(tài)、監(jiān)控運維、周邊配套工具、功能滿足度、DBA人才、SQL兼容性、性能測試、高可用測試、在線擴容、分布式事務、隔離級別、在線DDL等等
雖然NewSQL數據庫發(fā)展經過了一定時間檢驗,但多集中在互聯(lián)網以及傳統(tǒng)企業(yè)非核心交易系統(tǒng)中,目前還處于快速迭代、規(guī)模使用不斷優(yōu)化完善的階段。
對于互聯(lián)網公司,數據量的增長壓力以及追求新技術的基因會更傾向于嘗試NewSQL數據庫,不用再考慮庫表拆分、應用改造、擴容、事務一致性等問題怎么看都是非常吸引人的方案。
對于傳統(tǒng)企業(yè)例如銀行這種風險意識較高的行業(yè)來說,NewSQL數據庫則可能在未來一段時間內仍處于探索、審慎試點的階段。
總結
如果看完以上內容,您還不知道選哪種模式,那么結合以下幾個問題,先思考下NewSQL數據庫解決的點對于自身是不是真正的痛點:
強一致事務是否必須在數據庫層解決? 數據的增長速度是否不可預估的? 擴容的頻率是否已超出了自身運維能力? 相比響應時間更看重吞吐? 是否必須做到對應用完全透明? 是否有熟悉NewSQL數據庫的DBA團隊?
如果你還未做出抉擇,不妨再想想下面幾個問題:
最終一致性是否可以滿足實際場景? 數據未來幾年的總量是否可以預估? 擴容、DDL等操作是否有系統(tǒng)維護窗口? 對響應時間是否比吞吐更敏感? 是否需要兼容已有的關系數據庫系統(tǒng)? 是否已有傳統(tǒng)數據庫DBA人才的積累? 是否可容忍分庫分表對應用的侵入?
-?END?-
往期推薦
下方二維碼關注我

互聯(lián)網草根,堅持分享技術、創(chuàng)業(yè)、產品等心得和總結~

點擊“閱讀原文”,領取 2020 年最新免費技術資料大全
評論
圖片
表情