說在前面
一些老師學習Python編程僅僅是為了教學,凡是教材上沒有或者考試不考的東西就不想去接觸,我認為這種態(tài)度并不可取。我學習編程的一大原因是為了提高工作效率,通過編寫一些小程序減少枯燥的手工勞動。pandas數(shù)據(jù)分析在教材中占比不高,估計考試中出現(xiàn)的概率也不會太大。但是pandas的功能實在太強大了,不用它來做點什么東西實在說不過去。
剛好學校教務處讓我做一個合并Excel文件的小工具,把老師們每個月的績效工資、加班津貼和各種獎勵津貼等進行匯總。以前這件事情都是用VLOOKUP函數(shù)來做,表格多了以后還是挺麻煩的。還有學生成績匯總,以前手工閱卷的時候都是由各科老師登記本人任教的班級成績,然后匯總給備課組長或者班主任,最后再匯總到教務處。中間要經(jīng)過多人的手,容易出錯,如果能夠讓各位老師把Excel文件放到指定文件夾,直接由教務處統(tǒng)一來匯總,相信效率一定會提高不少。(教務處老師抗議——你是不是想把我累死)沒有遇到pandas的時候,根本不想去做這件事情,現(xiàn)在有了pandas,似乎可以動點腦筋了。
編程過程比想象的要困難的多,幸虧有萬能的群——感謝“Python算法之旅”微信群和“Python技術交流教師群”的熱心朋友們——特別感謝龍思宇老師、董付國老師、虞穎健老師、裘成老師和毛巖志老師的熱心幫助和啟發(fā),讓我在一次次“山窮水盡疑無路”時,看到了“柳暗花明又一村”。也許這就是編程的快樂吧,不僅解決了問題、學會了方法,還見識了一些有趣的靈魂,體會到思維碰撞的快感。今天我想和大家分享的不僅是這個實用的小程序,更多的是解決問題的過程。在這個過程中我走了很多彎路,也學到了很多知識。熱心的老師們給了我很大的幫助和啟發(fā),我也希望今天的這篇文章能夠對大家有所啟發(fā),期待您開發(fā)出更有趣、有用的程序。
一、問題描述
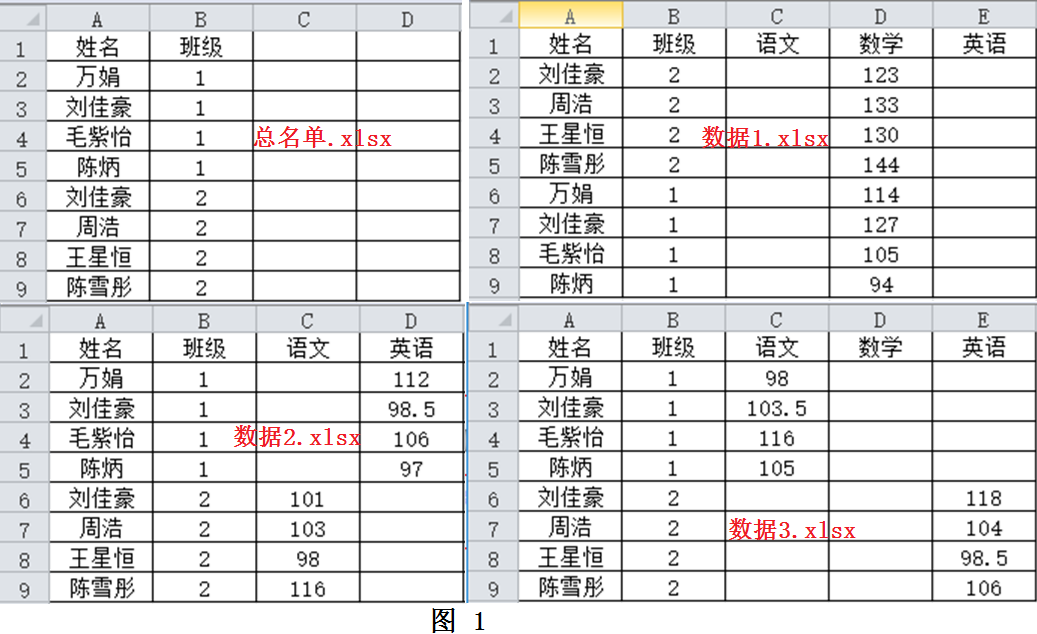
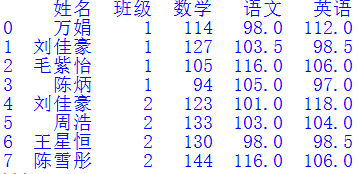
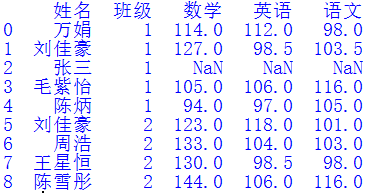
將多個Excel表格按照一定規(guī)則匹配、合成到一個文件中是常見的需求。當表格數(shù)量不多時,可以使用Excel軟件的VLOOKUP函數(shù)來做。但是當表格很多,且匹配數(shù)據(jù)復雜時,該方法就不太實用了,需要尋找更好的方法。圖1展示了4個Excel文件,第一份“總名單”記錄了所有學生的姓名和班級信息,另外3份數(shù)據(jù)文件分別表示不同老師記錄的學生成績。其中“數(shù)據(jù)1”記錄了2個班所有同學的數(shù)學成績,“數(shù)據(jù)2”記錄了1班的英語和2班的語文成績,“數(shù)據(jù)3”記錄了1班的語文和2班的英語成績。我們希望依次將圖1的3份數(shù)據(jù)文件與“總名單.xlsx”合并,獲得如圖2所示的“合并文件”。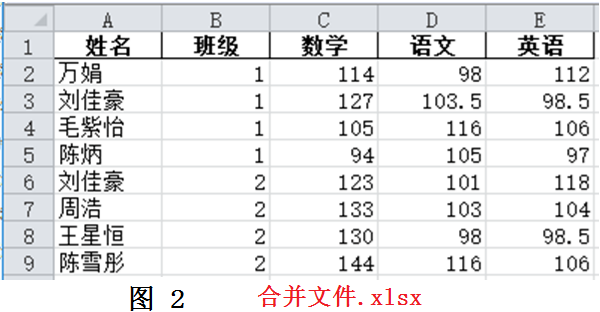
二、解題過程
pandas是基于numpy的數(shù)據(jù)分析模塊,提供了大量標準數(shù)據(jù)模型和高效操作大型數(shù)據(jù)集所需的工具,能夠快速便捷地進行數(shù)據(jù)分析和處理。我們今天就使用pandas模塊來編程解決合并Excel文件的問題。我們首先使用函數(shù)read_excel()讀取“總名單.xlsx”文件中的數(shù)據(jù),并存儲到DataFrame對象df中,代碼如下:importpandas as pd #導入pandas模塊file_name= "總名單.xlsx"df = pd.read_excel(file_name)
直接從Excel文件讀取的數(shù)據(jù)中可能會存在一些無效列,我們需要將其清除,以便后續(xù)合并DataFrame對象。例如df中讀入了兩個無效列,其值都是NaN,需要清除掉,只保留姓名和班級列。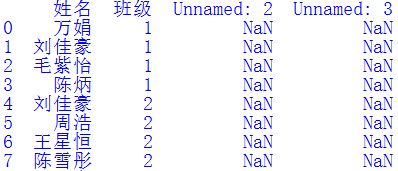
我們可以使用dropna()函數(shù)清除df中一整列都是缺失值的列。只需一行代碼即可完成該功能:
df =df.dropna(axis=1,how='all') #清除df中一整列都是缺失值的列#也可以寫作:df.dropna(axis=1,how='all',inplace=True)
其中inplace=True表示直接在df上修改,不返回新的DataFrame對象。清除無效數(shù)據(jù)后的df如下圖所示:

第三步:合并“數(shù)據(jù)1.xlsx”文件
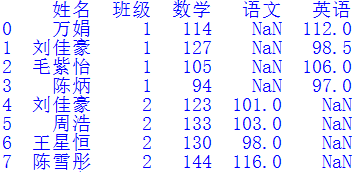
同樣的,我們將“數(shù)據(jù)1.xlsx”中的數(shù)據(jù)存儲到df2中,并清除無效數(shù)據(jù),得到df2如下圖所示:通常使用merge()函數(shù)來拼接左右兩個DataFrame對象。因為1班和2班都有一個叫劉佳豪的同學,所以在使用merge()函數(shù)合并df和df2時,不能只考慮“姓名”列,必須同時以“姓名”和“班級”列作為連接鍵,才能確定該學生所在的行。相關代碼如下:file_name = "數(shù)據(jù)1.xlsx" df2 = pd.read_excel(file_name)df2 = df2.dropna(axis=1, how='all')cols = ["姓名","班級"]df = pd.merge(df, df2, how='left', on=cols)
我們發(fā)現(xiàn)拼接結果和df2非常相似,但又略有區(qū)別。這是因為“數(shù)學”列是df2獨有的,而df中除了連接鍵以外沒有別的列,故拼接結果就是把多出的“數(shù)學”列加到了df中。然后調(diào)用merge()函數(shù)時為參數(shù)how賦值'left',即以df為基準對象,根據(jù)連接鍵,將df2的“數(shù)學”列拼接到df中,故各行排列的順序與原df相同。第四步:合并“數(shù)據(jù)2.xlsx”文件
這一步的做法和第三步基本一樣,除了Excel文件名不同,其他代碼都是一樣的。拼接結果如下圖所示:
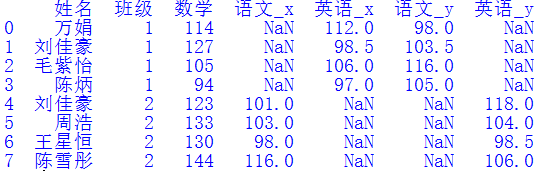
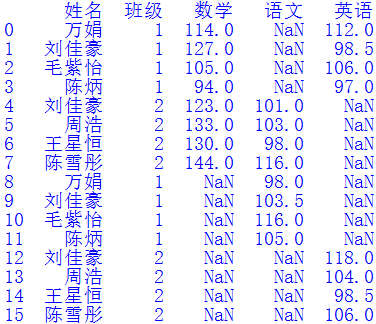
第五步:合并“數(shù)據(jù)3.xlsx”文件走到這一步時我遇到了困難。如果直接照搬前面的代碼:df = pd.merge(df, df2, how='left', on=cols),則得到如下結果:可以看出,結果并沒有合并“語文”和“英語”列,而是分成了“語文_x”、“英語_x”、“語文_y”和“英語_y”4列。我們把連接鍵改成cols =["姓名","班級","語文","英語"],并修改參數(shù)how='outer',則拼接結果如下圖所示:結果確實是合并了“語文”和“英語”列,但它只是把df2中的數(shù)據(jù)作為新行拼接到了df中,并沒有用有效數(shù)據(jù)去填充對應的NaN值。這不是我們想要的結果。那該怎么辦呢?多番思索無果后,我到“Python算法之旅”微信群尋找?guī)椭@蠋焸儫嵝牡卮饛土宋遥渲旋埶加罾蠋熃o出的答案順利解決了問題。他的答案非常簡單,只有一行代碼:
df.fillna(df2, inplace=True)
fillna()函數(shù)可以使用指定方法填充Dataframe對象的NaN值,在本例中df2中的語文和英語列恰好可以把原來df中的缺失值補上。問題完美解決。
但是——且慢,數(shù)據(jù)看上去太“完美”了——如果是有缺陷的數(shù)據(jù)呢?
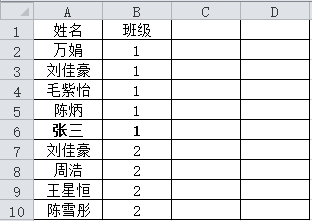
我在“總名單.xlsx”文件中間插入了一個學生,如下圖所示:
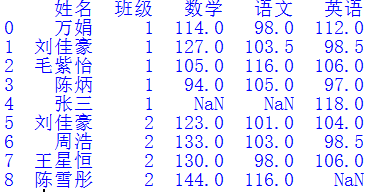
繼續(xù)運行原來的代碼,生成了如下結果:
果然出問題了!
在填充英語列的NaN值時,程序只知道從上向下依次填充,根本沒有考慮其姓名和班級是否對得上號,結果導致亂了套。看來fillna()函數(shù)還是不夠聰明。
有哪個函數(shù)能夠根據(jù)關鍵字匹配來填充缺失值呢?
思來想去好像只有merge()函數(shù)比較適合,但是不能一步到位,需要先生成一些不必要的行或列,再想辦法刪除那些多余的行或列;或者把df2中的各列拆分出來,逐列處理后,再拼接到df中。
總之我想了很多辦法,雖然最終能夠實現(xiàn)想要的功能,但是算法過于簡單粗暴,有違Python簡明優(yōu)雅的精神,實在不能令人滿意!
飽受挫折的我再一次想到了萬能的群。眾位老師各抒己見,龍大神再次施展驚人絕技,3行代碼令我茅塞頓開:
a.set_index(["班級","姓名"], inplace=True)b.set_index(["班級","姓名"], inplace=True)a.combine_first(b)
原來我被merge()函數(shù)蒙蔽了雙眼,未能跳出思維定勢。雖然之前也想到了其孿生兄弟join()函數(shù),但簡單試用以后發(fā)現(xiàn)行不通就放棄了。set_index()函數(shù)我是知道的,因為它經(jīng)常和join()函數(shù)一起使用;但combine_first()函數(shù)我確實是第一次見到。學藝不精啊!寶刀在手,天下我有。有了set_index()和combine_first()函數(shù)的幫助,那一切都變得簡單了。接下來就是機械地搬磚過程:cols = ["姓名","班級"]df.set_index(cols, inplace=True)df2.set_index(cols, inplace=True)df = df.combine_first(df2)
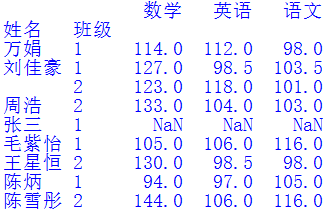
運行結果如下圖所示:
為了獲得我們想要的結果,還需要將上述結果按班級和姓名排序后,再把行索引還原回來,代碼如下:
df.sort_values(by=["班級","姓名"],?inplace=True)df.reset_index(inplace=True)
到這里,基本上就大功告成了。為了推廣到一般的情形,我們可以把"數(shù)據(jù)1.xlsx"等3個Excel文件放到“合并文件夾”目錄中,依次讀取文件,與"總名單.xlsx"合并后,再存儲到新文件"合并文件.xlsx"中。完整代碼如下:#!/usr/bin/python3# 文件名: pandas應用之合并Excel文件# 作者:巧若拙# 時間:2021-12-25
import os, sysimport pandas as pd
pd.set_option('display.unicode.ambiguous_as_wide', True)pd.set_option('display.unicode.east_asian_width', True) #中英文字符對齊
file_name = "總名單.xlsx"df = pd.read_excel(file_name)df = df.dropna(axis=1, how = 'all') #丟棄所有列中所有值均缺失的列basic_cols = list(df.columns) #獲取基本列df.set_index(basic_cols, inplace=True)
path = "合并文件夾/"for file in os.listdir(path): try: iffile.index(".xls") or file.index(".xlsx"): new_df =pd.read_excel(path+file) new_df =new_df.dropna(axis=1, how='all') new_df.set_index(basic_cols, inplace=True) df =df.combine_first(new_df) except ValueError: print(f"{file}不是需要的文件")
df.reset_index(inplace=True)print(df)writer_file_name = "合并文件.xlsx"writer = pd.ExcelWriter(writer_file_name)df.to_excel(writer, sheet_name='匯總表', index=False)writer.save()
三、總結反思
臺上三分鐘,臺下十年功。雖然最終呈現(xiàn)出來的代碼沒幾行,但其中的過程跌沓起伏,曾經(jīng)被使用和廢棄的代碼多達上百行,凝聚了眾多朋友的智慧和本人的心血,希望能對你有所幫助。本段程序利用pandas模塊提供的專業(yè)函數(shù)高效地完成了合并文件夾任務,幾乎每條語句都能完成一個特定功能,體現(xiàn)了pandas的強悍作風,也盡量表現(xiàn)了Python簡明優(yōu)雅的編程風格。pandas在金融、統(tǒng)計、社會科學、工程等領域都有著廣泛的應用,它提供的大量功能函數(shù)可以幫助我們快速方便地進行數(shù)據(jù)整理、分析和統(tǒng)計工作。但武器再好,不會用也是白搭。要想熟練使用這把“好劍”,就必須進一步深入學習,閱讀相關教程和文檔,提高自己的工作效率和編程水平。
除了本文提供的算法,還有很多方法也能實現(xiàn)合并Excel文件的功能。例如董付國老師就給我介紹了update()函數(shù),它和combine_first()函數(shù)有一些微妙的區(qū)別,相信加以巧妙利用以后,一定也能完成任務。還有,我在文章中只提供了最基本的源代碼,你可以結合tkinter,做出一個完整的作品,并打包成exe文件(就像我在視頻中做的那樣),提供給有需要的人。那么我就把這些作為課后作業(yè)交給你來完成吧,有什么好的想法和創(chuàng)意一定要記得和我交流哦!需要本文源代碼和課后練習答案的,可以加入“Python算法之旅”知識星球參與討論和下載文件,“Python算法之旅”知識星球匯集了數(shù)量眾多的同好,更多有趣的話題在這里討論,更多有用的資料在這里分享。
我們專注Python算法,感興趣就一起來!
相關優(yōu)秀文章:
閱讀代碼和寫更好的代碼
最有效的學習方式
課堂1:海龜繪圖之正四邊形及其拓展
課堂2:海龜繪圖之多彩螺旋線
課堂3:海龜繪圖之繪制虛線
課堂4:循環(huán)結構經(jīng)典案例
課堂5:解析算法經(jīng)典案例
課堂6:枚舉算法經(jīng)典案例
課堂7:算法程序實現(xiàn)的綜合應用
利用pandas模塊處理學生成績
利用pandas模塊處理百家姓數(shù)據(jù)