
大模型時(shí)代:華為讓以太網(wǎng)進(jìn)化,打通數(shù)據(jù)運(yùn)力動(dòng)脈
隨著大模型時(shí)代的到來(lái),算力需求呈現(xiàn)出指數(shù)級(jí)增長(zhǎng)。據(jù)統(tǒng)計(jì),2012年到2019年AI訓(xùn)練算力平均每100天翻倍,而GPU單卡算力則需要2-3年增長(zhǎng)一倍。GPU卡集群成為應(yīng)對(duì)算力需求高速增長(zhǎng)的方案,隨著AI模型進(jìn)入萬(wàn)億參數(shù)模型時(shí)代,GPU卡的數(shù)量也提高到萬(wàn)卡規(guī)模,據(jù)了解,OpenAI使用25000張A100 GPU訓(xùn)練1.8萬(wàn)億參數(shù)的GPT4。
正是在AI計(jì)算集群支撐下,超萬(wàn)億參數(shù)大模型的高效訓(xùn)練成為可能,大模型加速進(jìn)入各行各業(yè)。在最近舉行的華為年度最重要的ICT盛會(huì)上,“大模型”成為最重要的關(guān)鍵詞,華為從算力、運(yùn)力、存力等多個(gè)維度全線出擊,使能百模千態(tài),賦能千行萬(wàn)業(yè),加速行業(yè)智能化。
其中,華為最令人關(guān)注的重磅創(chuàng)新之一,來(lái)自數(shù)據(jù)中心網(wǎng)絡(luò),華為對(duì)以太網(wǎng)進(jìn)行進(jìn)化,研發(fā)出超融合以太技術(shù),正是這項(xiàng)創(chuàng)新,讓數(shù)據(jù)中心網(wǎng)絡(luò)釋放出最大潛力,使得上萬(wàn)張AI板卡高效協(xié)同,成為萬(wàn)億參數(shù)大模型時(shí)代的堅(jiān)固基石。
為數(shù)據(jù)中心網(wǎng)絡(luò)裝上智慧調(diào)度大腦
想象一下,一個(gè)超大型機(jī)場(chǎng)如果沒(méi)有調(diào)度系統(tǒng),多條跑道同時(shí)起飛降落飛機(jī)的時(shí)候會(huì)發(fā)生什么?
這樣的景象其實(shí)也發(fā)生在數(shù)據(jù)中心。隨著AI進(jìn)入大模型時(shí)代,計(jì)算也進(jìn)入分布式訓(xùn)練的時(shí)代,即計(jì)算任務(wù)以數(shù)據(jù)并行、流水線并行、張量并行等分布式并行方式分配到多臺(tái)服務(wù)器上,以加快模型訓(xùn)練速度。這個(gè)時(shí)候,多臺(tái)服務(wù)器之間就需要同步參數(shù)、梯度、中間變量,在大模型訓(xùn)練時(shí),單次參數(shù)同步量高達(dá)100MB-幾GB的量級(jí)。如何協(xié)作數(shù)萬(wàn)張?zhí)幚砥鳎WC不隨著算力規(guī)模的增大而效率大幅降低,避免出現(xiàn)1+1<2的效果,是一大問(wèn)題。

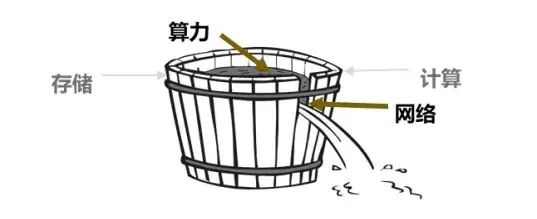
并行計(jì)算下,網(wǎng)絡(luò)負(fù)載均衡就是其中的關(guān)鍵。無(wú)論是數(shù)據(jù)并行,還是流水線并行,或是張量并行,多機(jī)之間都需要通過(guò)多次AllReduce集合通信操作來(lái)傳遞計(jì)算結(jié)果。AllReduce集合通信的特征是多打一,流數(shù)少、單流帶寬大,同一時(shí)間均是點(diǎn)到點(diǎn)通信,其完成需要所有點(diǎn)對(duì)點(diǎn)通信都成功完成。這時(shí)候就存在“木桶效應(yīng)”,木桶中盛的水由最短的木板所決定,而AllReduce的完成時(shí)間,也由其中最慢的點(diǎn)對(duì)點(diǎn)通信時(shí)間所決定。
正是因?yàn)檫@種木桶效應(yīng),智算數(shù)據(jù)中心網(wǎng)絡(luò)會(huì)遇到網(wǎng)絡(luò)負(fù)載不均衡問(wèn)題,如何進(jìn)行鏈路的負(fù)載均衡成為關(guān)鍵。在沒(méi)有實(shí)現(xiàn)全局負(fù)載均衡的網(wǎng)絡(luò)中,整體通信效率僅在30%-56%之間,這意味著有一半以上的網(wǎng)絡(luò)性能沒(méi)有被高效利用,同樣,這意味著整個(gè)AI集群的算力效率只有不到一半。因此,AI集群網(wǎng)絡(luò)的吞吐效率將直接影響整個(gè)智算中心集群的效率。
目前有很多網(wǎng)絡(luò)負(fù)載均衡技術(shù),但其缺點(diǎn)在于絕大多數(shù)技術(shù)只解決了本地等價(jià)路徑之間的均衡,是局部視角而非全局視角。甚至對(duì)于AI訓(xùn)練這種吞吐敏感性業(yè)務(wù),傳統(tǒng)的ECMP流量均衡機(jī)制也很難實(shí)現(xiàn)本地路徑的完美均衡。
正是在這樣的背景下,華為提出了網(wǎng)絡(luò)級(jí)負(fù)載均衡(Network Scale Load Balance,NSLB)的概念,顧名思義,其是基于算網(wǎng)協(xié)同實(shí)現(xiàn)多任務(wù)全局均衡路由,通過(guò)全局擁塞狀態(tài)的自適應(yīng)路由算法,實(shí)現(xiàn)AI訓(xùn)練流量滿吞吐和網(wǎng)絡(luò)帶寬的完全利用。
在華為全聯(lián)接大會(huì)2023上,華為發(fā)布的面向智算場(chǎng)景的業(yè)界首款高運(yùn)力AI智算交換機(jī)CloudEngine XH16800,就是在NSLB算法的加持下,實(shí)現(xiàn)網(wǎng)絡(luò)一鍵調(diào)優(yōu),可以根據(jù)整網(wǎng)交換機(jī)節(jié)點(diǎn)流擁塞狀態(tài)和全網(wǎng)拓?fù)錉顟B(tài)進(jìn)行全局算路,識(shí)別出最優(yōu)路徑,整網(wǎng)吞吐可以提升到高達(dá)98%。
這意味著智算數(shù)據(jù)中心的吞吐翻了一倍,當(dāng)然,這也意味著智算數(shù)據(jù)中心的集群效率提升了一倍。華為相當(dāng)于是為數(shù)據(jù)中心網(wǎng)絡(luò)裝上了一個(gè)智慧調(diào)度大腦,可以智能優(yōu)化網(wǎng)絡(luò)負(fù)載均衡,將網(wǎng)絡(luò)吞吐量做到極致。
大模型時(shí)代的“數(shù)據(jù)中心網(wǎng)絡(luò)樣板”
實(shí)際上,華為在數(shù)據(jù)中心網(wǎng)絡(luò)上的創(chuàng)新不止于此。華為全新升級(jí)的CloudFabric 3.0超融合數(shù)據(jù)中心網(wǎng)絡(luò),就以一系列底層技術(shù)創(chuàng)新,定義了大模型時(shí)代的“數(shù)據(jù)中心網(wǎng)絡(luò)樣板”。
目前業(yè)界主流的計(jì)算互聯(lián)協(xié)議有RoCE和IB兩種,其中據(jù)絕對(duì)領(lǐng)先份額的IB主要掌握在國(guó)外巨頭手中,技術(shù)和產(chǎn)品生態(tài)都比較封閉。而且,AI網(wǎng)絡(luò)里存在參數(shù)面、存儲(chǔ)面、業(yè)務(wù)面、管理面等多個(gè)平面,IB只用在參數(shù)面里面,其他網(wǎng)絡(luò)需要使用以太協(xié)議,這意味著需要兩套運(yùn)維系統(tǒng)。相比起來(lái),RoCE生態(tài)相對(duì)開(kāi)放,可以完全復(fù)用以太生態(tài),而且著力實(shí)現(xiàn)網(wǎng)絡(luò)的無(wú)損傳輸,被認(rèn)為是未來(lái)計(jì)算互聯(lián)的重要路徑。
華為基于RoCE,研發(fā)出超融合以太技術(shù),除了上面提到的NSLB技術(shù)帶來(lái)的網(wǎng)絡(luò)負(fù)載擁塞控制優(yōu)勢(shì),還有完善的流量控制、流量調(diào)度、應(yīng)用加速功能,而且獨(dú)家實(shí)現(xiàn)了以太網(wǎng)0丟包功能。從華為推出的CloudFabric3.0超融合數(shù)據(jù)中心網(wǎng)絡(luò)來(lái)看,其具有超強(qiáng)性能,獨(dú)家AI加速器(NSLB)網(wǎng)絡(luò)吞吐提升至98%,AI訓(xùn)練效率可提升20%;超穩(wěn)可靠,訓(xùn)前智能自檢,保障100%網(wǎng)絡(luò)健康;超快部署,多云多廠商實(shí)現(xiàn)天級(jí)設(shè)備管理,分鐘級(jí)業(yè)務(wù)編排,網(wǎng)絡(luò)與計(jì)算協(xié)同,端到端即插即用,開(kāi)局效率提升10倍;超智運(yùn)維,獨(dú)家網(wǎng)絡(luò)數(shù)字地圖使能計(jì)算網(wǎng)絡(luò)一體化運(yùn)維,通信異常一鍵診斷,實(shí)現(xiàn)訓(xùn)中排障效率提升90%。

如果我們將目標(biāo)著眼于數(shù)據(jù)中心,其中同樣存在木桶效應(yīng)。在構(gòu)成數(shù)據(jù)中心的關(guān)鍵要素——存儲(chǔ)、計(jì)算、網(wǎng)絡(luò)等木板中,網(wǎng)絡(luò)是最短的那塊木板。但是網(wǎng)絡(luò)又非常關(guān)鍵,其連接著用戶終端和數(shù)據(jù)中心內(nèi)部的計(jì)算、存儲(chǔ)等設(shè)備,保障數(shù)據(jù)通信鏈路上高效、安全的傳輸。華為超融合以太技術(shù),將數(shù)據(jù)中心網(wǎng)絡(luò)從傳統(tǒng)以太、無(wú)損以太向超融合以太升級(jí),從網(wǎng)絡(luò)架構(gòu)、帶寬、時(shí)延、可靠性、應(yīng)用加速、網(wǎng)絡(luò)技術(shù)演進(jìn)六大方面全面升級(jí),補(bǔ)齊了網(wǎng)絡(luò)這個(gè)短板。
更重要的是,這個(gè)解決方案不僅性能強(qiáng),而且成本低。通過(guò)將通用計(jì)算網(wǎng)絡(luò)、存儲(chǔ)網(wǎng)絡(luò)、高能能計(jì)算網(wǎng)絡(luò)和智能計(jì)算網(wǎng)絡(luò)統(tǒng)一承載在0丟包以太網(wǎng)技術(shù)棧上,相當(dāng)于實(shí)現(xiàn)了多張網(wǎng)到一張網(wǎng)的融合部署。此舉不僅降低了網(wǎng)絡(luò)的建設(shè)成本,而且在一系列智能化運(yùn)維技術(shù)的加持下,還能實(shí)現(xiàn)運(yùn)維成本的節(jié)省。最近,華為發(fā)布了L4數(shù)據(jù)中心自動(dòng)駕駛網(wǎng)絡(luò)方案及白皮書(shū),這意味著在L3.5數(shù)據(jù)中心自動(dòng)駕駛網(wǎng)絡(luò)的基礎(chǔ)上,數(shù)據(jù)中心網(wǎng)絡(luò)將朝著高度自動(dòng)化的更高度邁進(jìn)。
武漢超算中心就是很好的樣本,其采用華為超融合以太解決方案,打造出一張性能、兼容性、成本效益和靈活性兼具的高性能網(wǎng)絡(luò)。事實(shí)上,在項(xiàng)目部署前,武漢超算中心曾經(jīng)對(duì)96節(jié)點(diǎn)集群規(guī)模下,華為的方案和IB方案進(jìn)行過(guò)全面對(duì)比測(cè)試。測(cè)試表明,在MPI、Benchmark和HPC典型應(yīng)用測(cè)試中,華為智能無(wú)損高性能計(jì)算網(wǎng)絡(luò)性能與IB網(wǎng)絡(luò)整體基本持平,局部小幅領(lǐng)先,完全滿足業(yè)務(wù)的高性能需求。

在華為全聯(lián)接大會(huì)2023上,華為重磅發(fā)布面向AI智算場(chǎng)景的華為星河AI網(wǎng)絡(luò),可以預(yù)計(jì),在星河AI網(wǎng)絡(luò)的加持下,數(shù)據(jù)中心網(wǎng)絡(luò)將能實(shí)現(xiàn)AI時(shí)代的最強(qiáng)運(yùn)力,支撐起大模型時(shí)代的璀璨星河。