
分布式緩存,就該這樣設(shè)計(jì)!
文章來(lái)源:https://sourl.cn/Sejspk
前 言
緩存的收益與成本
使用緩存我們得到以下收益:
加速讀寫(xiě)。因?yàn)榫彺嫱ǔJ侨珒?nèi)存的,比如Redis、Memcache。對(duì)內(nèi)存的直接讀寫(xiě)會(huì)比傳統(tǒng)的存儲(chǔ)層如MySQL,性能好很多。舉個(gè)例子:同等配置單機(jī)Redis QPS可輕松上萬(wàn),MySQL則只有幾千。加速讀寫(xiě)之后,響應(yīng)時(shí)間加快,相比之下系統(tǒng)的用戶體驗(yàn)?zāi)艿玫礁玫奶嵘?/span>
降低后端的負(fù)載。緩存一些復(fù)雜計(jì)算或者耗時(shí)得出的結(jié)果可以降低后端系統(tǒng)對(duì)CPU、IO、線程這些資源的需求,讓系統(tǒng)運(yùn)行在一個(gè)相對(duì)資源健康的環(huán)境。
但隨之以來(lái)也有一些成本:
數(shù)據(jù)不一致性:緩存層與存儲(chǔ)層的數(shù)據(jù)存在著一定時(shí)間窗口一致,時(shí)間窗口與緩存的過(guò)期時(shí)間更新策略有關(guān)。
代碼維護(hù)成本:加入緩存后,需要同時(shí)處理緩存層和存儲(chǔ)層的邏輯,增加了開(kāi)發(fā)者維護(hù)代碼的成本。
運(yùn)維成本:引入緩存層,比如Redis。為保證高可用,需要做主從,高并發(fā)需要做集群。
緩存的更新
緩存的數(shù)據(jù)一般都是有生命時(shí)間的,過(guò)了一段時(shí)間之后就會(huì)失效,再次訪問(wèn)時(shí)需要重新加載。緩存的失效是為了保證與數(shù)據(jù)源真實(shí)的數(shù)據(jù)保證一致性和緩存空間的有效利用性。下面將從使用場(chǎng)景、數(shù)據(jù)一致性、開(kāi)發(fā)運(yùn)維維護(hù)成本三個(gè)方面來(lái)介紹幾種緩存的更新策略。
1、LRU/LFU/FIFO
這三種算法都是屬于當(dāng)緩存不夠用時(shí)采用的更新算法。只是選出的淘汰元素的規(guī)則不一樣:LRU淘汰最久沒(méi)有被訪問(wèn)過(guò)的,LFU淘汰訪問(wèn)次數(shù)最少的,F(xiàn)IFO先進(jìn)先出。
一致性:要清理哪些數(shù)據(jù)是由具體的算法定的,開(kāi)發(fā)人員只能選擇其中的一種,一致性差。
開(kāi)發(fā)維護(hù)成本:算法不需要開(kāi)發(fā)人員維護(hù),只需要配置最大可使用內(nèi)存即可,然后選擇淘汰算法即可,故成本低。
使用場(chǎng)景:適合內(nèi)存空間有限,數(shù)據(jù)長(zhǎng)期不變動(dòng),基本不存在數(shù)據(jù)一不致性業(yè)務(wù)。比如一些一經(jīng)確定就不允許變更的信息。
2、超時(shí)剔除
給緩存數(shù)據(jù)手動(dòng)設(shè)置一個(gè)過(guò)期時(shí)間,比如Redis expire命令。當(dāng)超過(guò)時(shí)間后,再次訪問(wèn)時(shí)從數(shù)據(jù)源重新加載并設(shè)回緩存。
一致性:主要處決于緩存的生命時(shí)間窗口,這點(diǎn)由開(kāi)發(fā)人員控制。但仍不能保證實(shí)時(shí)一致性,估一致性一般。
開(kāi)發(fā)維護(hù)成本:成本不是很高,很多緩存系統(tǒng)都自帶過(guò)期時(shí)間API。比如Redis expire
使用場(chǎng)景:適合于能夠容忍一定時(shí)間內(nèi)數(shù)據(jù)不一致性的業(yè)務(wù),比如促銷(xiāo)活動(dòng)的描述文案。
3、主動(dòng)更新
如果數(shù)據(jù)源的數(shù)據(jù)有更新,則主動(dòng)更新緩存。
一致性:三者當(dāng)中一致性最高,只要能確定正確更新,一致性就能有保證。
開(kāi)發(fā)維護(hù)成本:這個(gè)相對(duì)來(lái)說(shuō)就高了,業(yè)務(wù)數(shù)據(jù)更新與緩存更新藕合了一起。需要處理業(yè)務(wù)數(shù)據(jù)更新成功,而緩存更新失敗的情景,為了解耦一般用來(lái)消息隊(duì)列的方式更新。不過(guò)為了提高容錯(cuò)性,一般會(huì)結(jié)合超時(shí)剔除方案,避免緩存更新失敗,緩存得不到更新的場(chǎng)景。
使用場(chǎng)景:對(duì)于數(shù)據(jù)的一致性要求很高,比如交易系統(tǒng),優(yōu)惠劵的總張數(shù)。
所以總的來(lái)說(shuō)緩存更新的最佳實(shí)踐是:
低一致性業(yè)務(wù):可以選擇第一并結(jié)合第二種策略。
高一致性業(yè)務(wù):二、三策略結(jié)合。
穿透優(yōu)化
緩存穿透指查詢一個(gè)根本不存在的數(shù)據(jù),緩存層和存儲(chǔ)層都不命中。一般的處理邏輯是如果存儲(chǔ)層都不命中的話,緩存層就沒(méi)有對(duì)應(yīng)的數(shù)據(jù)。但在高并發(fā)場(chǎng)景中大量的緩存穿透,請(qǐng)求直接落到存儲(chǔ)層,稍微不慎后端系統(tǒng)就會(huì)被壓垮。所以對(duì)于緩存穿透我們有以下方案來(lái)優(yōu)化。
1、緩存空對(duì)象
第一種方案就是緩存一個(gè)空對(duì)象。對(duì)于存儲(chǔ)層都沒(méi)有命中請(qǐng)求,我們默認(rèn)返回一個(gè)業(yè)務(wù)上的對(duì)象。這樣就可以抵擋大量重復(fù)的沒(méi)有意義的請(qǐng)求,起到了保護(hù)后端的作用。不過(guò)這個(gè)方案還是不能應(yīng)對(duì)大量高并發(fā)且不相同的緩存穿透,如果有人之前摸清楚了你業(yè)務(wù)有效范圍,一瞬間發(fā)起大量不相同的請(qǐng)求,你第一次查詢還是會(huì)穿透到DB。另外這個(gè)方案的一種缺點(diǎn)就是:每一次不同的緩存穿透,緩存一個(gè)空對(duì)象。大量不同的穿透,緩存大量空對(duì)象。內(nèi)存被大量白白占用,使真正有效的數(shù)據(jù)不能被緩存起來(lái)。
所以對(duì)于這種方案需要做到:第一,做好業(yè)務(wù)過(guò)濾。比如我們確定業(yè)務(wù)ID的范圍是[a, b],只要不屬于[a,b]的,系統(tǒng)直接返回,直接不走查詢。第二,給緩存的空對(duì)象設(shè)置一個(gè)較短的過(guò)期時(shí)間,在內(nèi)存空間不足時(shí)可以被有效快速清除。
2、布隆過(guò)濾器
布隆過(guò)濾器是一種結(jié)合hash函數(shù)與bitmap的一種數(shù)據(jù)結(jié)構(gòu)。相關(guān)定義如下:
布隆過(guò)濾器(英語(yǔ):Bloom Filter)是1970年由布隆提出的。它實(shí)際上是一個(gè)很長(zhǎng)的二進(jìn)制向量和一系列隨機(jī)映射函數(shù)。布隆過(guò)濾器可以用于檢索一個(gè)元素是否在一個(gè)集合中。它的優(yōu)點(diǎn)是空間效率和查詢時(shí)間都遠(yuǎn)遠(yuǎn)超過(guò)一般的算法,缺點(diǎn)是有一定的誤識(shí)別率和刪除困難。
關(guān)于布隆過(guò)濾器的原理與實(shí)現(xiàn)網(wǎng)上有很多介紹,大家百度/GOOGLE一下便可。
布隆過(guò)濾器可以有效的判別元素是否集合中,比如上面的業(yè)務(wù)ID,并且即使是上億的數(shù)據(jù)布隆過(guò)濾器也能運(yùn)用得很好。所以對(duì)于一些歷史數(shù)據(jù)的查詢布隆過(guò)濾器是極佳的防穿透的選擇。對(duì)于實(shí)時(shí)數(shù)據(jù),則需要在業(yè)務(wù)數(shù)據(jù)時(shí)主動(dòng)更新布隆過(guò)濾器,這里會(huì)增加開(kāi)發(fā)維護(hù)更新的成本,與主動(dòng)更新緩存邏輯一樣需要處理各種異常結(jié)果。
綜上所述,其實(shí)我覺(jué)得布隆過(guò)濾器和緩存空對(duì)象是完全可以結(jié)合起來(lái)的。具體做法是布隆過(guò)濾器用本地緩存實(shí)現(xiàn),因?yàn)閮?nèi)存占用極低,不命中時(shí)再走redis/memcache這種遠(yuǎn)程緩存查詢。
無(wú)底洞優(yōu)化
1. 什么是緩存無(wú)底洞問(wèn)題:
Facebook的工作人員反應(yīng)2010年已達(dá)到3000個(gè)memcached節(jié)點(diǎn),儲(chǔ)存數(shù)千G的緩存。他們發(fā)現(xiàn)一個(gè)問(wèn)題–memcached的連接效率下降了,于是添加memcached節(jié)點(diǎn),添加完之后,并沒(méi)有好轉(zhuǎn)。稱為“無(wú)底洞”現(xiàn)象
2. 緩存無(wú)底洞產(chǎn)生的原因:
鍵值數(shù)據(jù)庫(kù)或者緩存系統(tǒng),由于通常采用hash函數(shù)將key映射到對(duì)應(yīng)的實(shí)例,造成key的分布與業(yè)務(wù)無(wú)關(guān),但是由于數(shù)據(jù)量、訪問(wèn)量的需求,需要使用分布式后(無(wú)論是客戶端一致性哈性、redis-cluster、codis),批量操作比如批量獲取多個(gè)key(例如redis的mget操作),通常需要從不同實(shí)例獲取key值,相比于單機(jī)批量操作只涉及到一次網(wǎng)絡(luò)操作,分布式批量操作會(huì)涉及到多次網(wǎng)絡(luò)io。
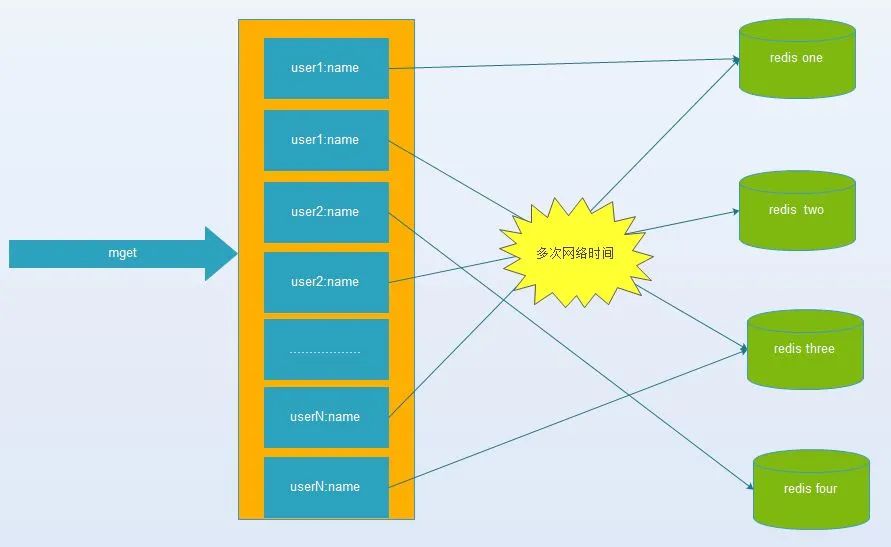
(1) 客戶端一次批量操作會(huì)涉及多次網(wǎng)絡(luò)操作,也就意味著批量操作會(huì)隨著實(shí)例的增多,耗時(shí)會(huì)不斷增大。
(2) 服務(wù)端網(wǎng)絡(luò)連接次數(shù)變多,對(duì)實(shí)例的性能也有一定影響。
所以無(wú)底洞似乎是一個(gè)無(wú)解的問(wèn)題。實(shí)際上我們只要了解無(wú)底洞產(chǎn)生原因在業(yè)務(wù)前期規(guī)劃好就可以減輕甚至避免無(wú)底洞的產(chǎn)生。
首先如果你的業(yè)務(wù)查詢沒(méi)有,像mget這種批量操作,恭喜你,無(wú)底洞將遠(yuǎn)離你。
將集群以項(xiàng)目組做隔離,這樣每組業(yè)務(wù)的redis/memcache集群就不會(huì)太大。
如果你公司的最大峰值流量遠(yuǎn)不及FB,可能也不需要擔(dān)心這個(gè)問(wèn)題。
那技術(shù)上有沒(méi)有一些優(yōu)先點(diǎn)?解決思路如下:
1. IO的優(yōu)化思路:
命令本身的效率:例如sql優(yōu)化,命令優(yōu)化。
網(wǎng)絡(luò)次數(shù):減少通信次數(shù)。
降低接入成本:長(zhǎng)連/連接池,NIO等。
IO訪問(wèn)合并:O(n)到O(1)過(guò)程:批量接口(mget)。
(1)、(3)、(4)通常是由緩存系統(tǒng)的設(shè)計(jì)開(kāi)發(fā)者來(lái)決定的,作為使用者我們可以從(2)減少通信次數(shù)上做優(yōu)化
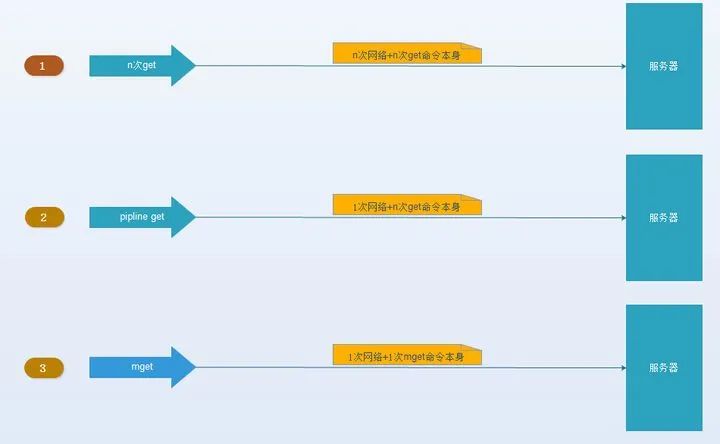
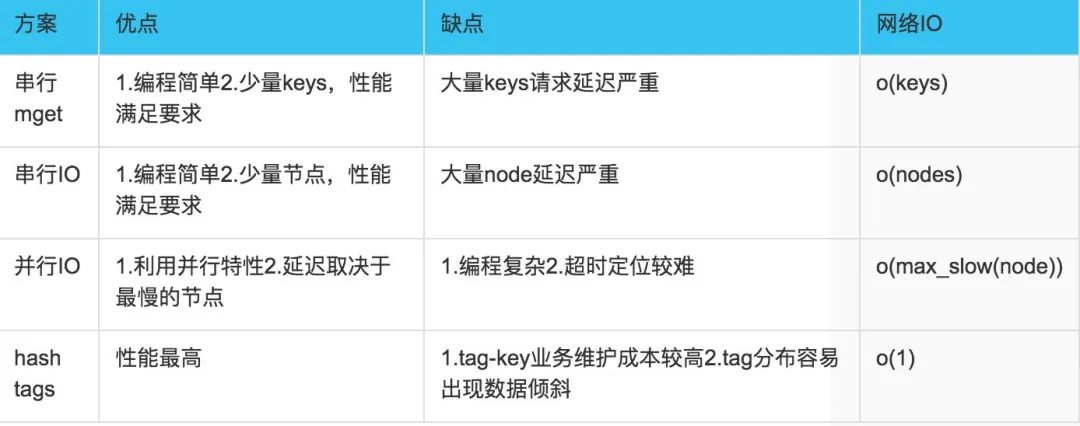
2. 以mget來(lái)說(shuō)有四種方案:
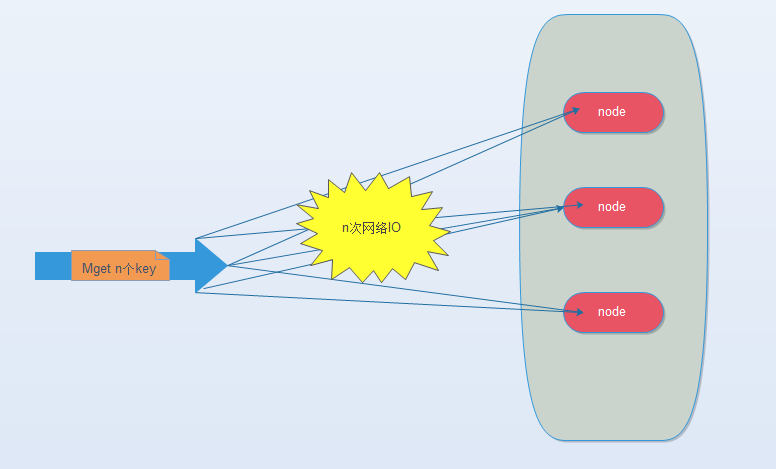
(1) 串行mget
將mget操作(n個(gè)key)拆分為逐次執(zhí)行N次get操作, 很明顯這種操作時(shí)間復(fù)雜度較高,它的操作時(shí)間=n次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間,網(wǎng)絡(luò)次數(shù)是n,很顯然這種方案不是最優(yōu)的,但是足夠簡(jiǎn)單。
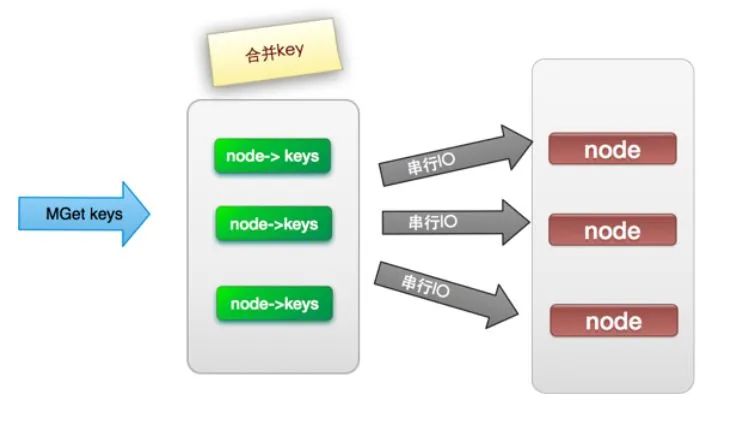
(2)?串行IO
將mget操作(n個(gè)key),利用已知的hash函數(shù)算出key對(duì)應(yīng)的節(jié)點(diǎn),這樣就可以得到一個(gè)這樣的關(guān)系:Map
它的操作時(shí)間=node次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間,網(wǎng)絡(luò)次數(shù)是node的個(gè)數(shù),很明顯這種方案比第一種要好很多,但是如果節(jié)點(diǎn)數(shù)足夠多,還是有一定的性能問(wèn)題。
(3)?并行IO
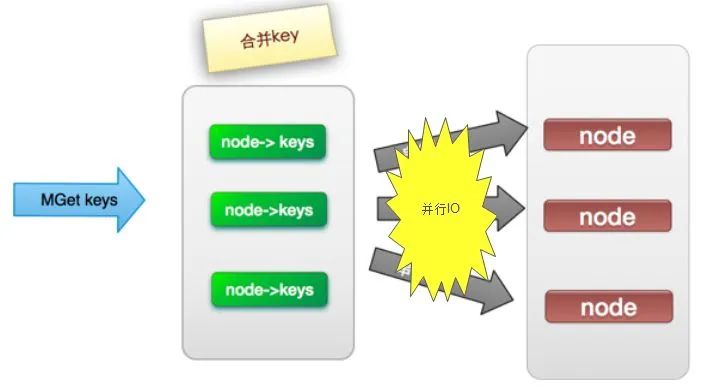
此方案是將方案(2)中的最后一步,改為多線程執(zhí)行,網(wǎng)絡(luò)次數(shù)雖然還是nodes.size(),但網(wǎng)絡(luò)時(shí)間變?yōu)閛(1),但是這種方案會(huì)增加編程的復(fù)雜度。
它的操作時(shí)間=1次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間
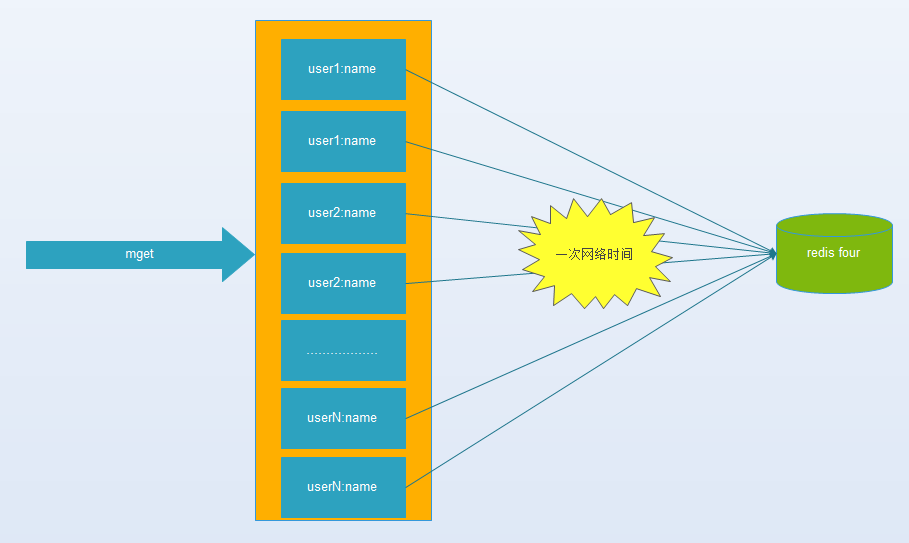
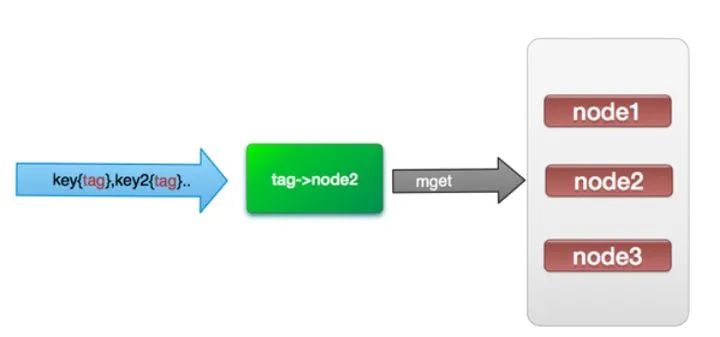
(4)?hash-tag實(shí)現(xiàn)
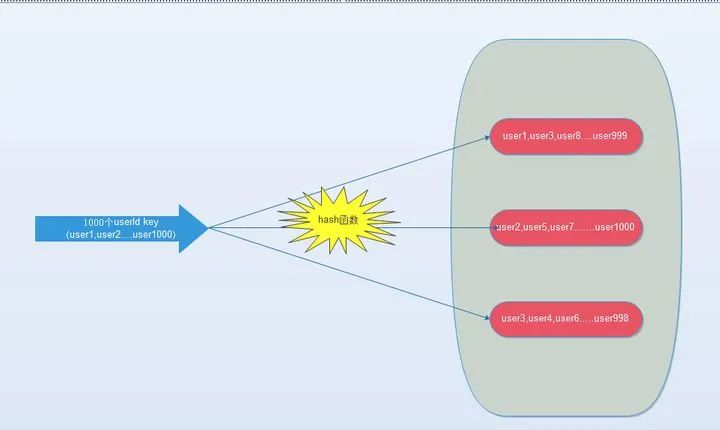
由于hash函數(shù)會(huì)造成key隨機(jī)分配到各個(gè)節(jié)點(diǎn),那么有沒(méi)有一種方法能夠強(qiáng)制一些key到指定節(jié)點(diǎn)到指定的節(jié)點(diǎn)呢?
redis提供了這樣的功能,叫做hash-tag。什么意思呢?假如我們現(xiàn)在使用的是redis-cluster(10個(gè)redis節(jié)點(diǎn)組成),我們現(xiàn)在有1000個(gè)k-v,那么按照hash函數(shù)(crc16)規(guī)則,這1000個(gè)key會(huì)被打散到10個(gè)節(jié)點(diǎn)上,那么時(shí)間復(fù)雜度還是上述(1)~(3)
那么我們能不能像使用單機(jī)redis一樣,一次IO將所有的key取出來(lái)呢?hash-tag提供了這樣的功能,如果將上述的key改為如下,也就是用大括號(hào)括起來(lái)相同的內(nèi)容,那么這些key就會(huì)到指定的一個(gè)節(jié)點(diǎn)上。
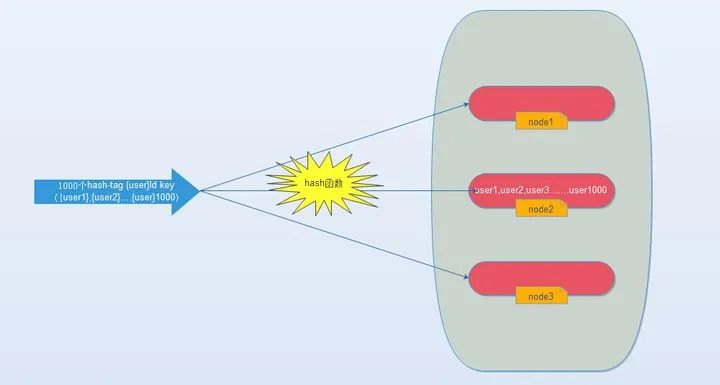
它的操作時(shí)間=1次網(wǎng)絡(luò)時(shí)間+n次命令時(shí)間
3. 四種批量操作解決方案對(duì)比
關(guān)于無(wú)底洞優(yōu)化這塊的內(nèi)容,詳細(xì)可參考并發(fā)編程網(wǎng)上面的一篇文章。
雪崩優(yōu)化
(1)保證緩存層服務(wù)的高可用性,比如一主多從,Redis Sentine機(jī)制。
(2)依賴隔離組件為后端限流并降級(jí),比如netflix的hystrix。關(guān)于限流、降級(jí)以及hystrix的技術(shù)設(shè)計(jì)可參考以下鏈接。
https://github.com/Netflix/Hystrix
(3)項(xiàng)目資源隔離。避免某個(gè)項(xiàng)目的bug,影響了整個(gè)系統(tǒng)架構(gòu),有問(wèn)題也局限在項(xiàng)目?jī)?nèi)部。
熱點(diǎn)key重建優(yōu)化
開(kāi)發(fā)人員使用"緩存+過(guò)期時(shí)間"的策略來(lái)加速讀寫(xiě),又保證數(shù)據(jù)的定期更新,這種模式基本能滿足絕大部分需求。但是如果有兩個(gè)問(wèn)題同時(shí)出現(xiàn),可能會(huì)對(duì)應(yīng)用造成致命的傷害。
當(dāng)前key是一個(gè)hot key,比如熱點(diǎn)娛樂(lè)新聞,并發(fā)量非常大。
重建緩存不能在短時(shí)間完成,可能是一個(gè)復(fù)雜計(jì)算,例如復(fù)雜的SQL, 多次IO,多個(gè)依賴等。
當(dāng)緩存失效的瞬間,將會(huì)有大量線程來(lái)重建緩存,造成后端負(fù)載加大,甚至讓?xiě)?yīng)該崩潰。要解決這個(gè)問(wèn)題有以下方案:
1、互斥鎖
具體做法是只允許一個(gè)線程重建緩存,其它線程等待重建緩存的線程執(zhí)行完,重新從緩存獲取數(shù)據(jù)即可。這種方案的話,有個(gè)風(fēng)險(xiǎn)就是重建的時(shí)間太長(zhǎng)或者并發(fā)量太大,將會(huì)大量的線程阻塞,同樣會(huì)加大系統(tǒng)負(fù)載。優(yōu)化方法:除了重建線程之外,其它線程拿舊值直接返回。比如Google 的 Guava Cache 的refreshAfterWrite采用的就是這種方案避免雪崩效應(yīng)。
2、永不過(guò)期
這種就是緩存更新操作是獨(dú)立的,可以通過(guò)跑定時(shí)任務(wù)來(lái)定期更新,或者變更數(shù)據(jù)時(shí)主動(dòng)更新。
3、后端限流
以上兩種方案都是建立在我們事先知道hot key的情況下,如果我們事先知道哪些是hot key的話,其實(shí)問(wèn)題都不是很大。問(wèn)題是我們不知道的情況!既然hot key的危害是因?yàn)橛写罅康闹亟ㄕ?qǐng)求落到了后端,如果后端自己做了限流呢,只有部分請(qǐng)求落到了后端, 其它的都打回去了。一個(gè)hot key 只要有一個(gè)重建請(qǐng)求處理成功了,后面的請(qǐng)求都是直接走緩存了,問(wèn)題就解決了。
所以高并發(fā)情況下,后端限流是必不可少。
結(jié)束語(yǔ)
以上就是我在工作中關(guān)于緩存設(shè)計(jì)、使用的一些心得。

為何數(shù)據(jù)庫(kù)連接池不采用IO多路復(fù)用?

僅僅過(guò)去 4 年,微軟最終放棄了它!

索引優(yōu)化的這把絕世好劍,你真的會(huì)用嗎?