
如何利用Scrapy爬蟲框架抓取網(wǎng)頁全部文章信息(下篇)
回復(fù)“書籍”即可獲贈(zèng)Python從入門到進(jìn)階共10本電子書
/前言/
???在上篇文章中,如何利用Scrapy爬蟲框架抓取網(wǎng)頁全部文章信息(中篇)、如何利用Scrapy爬蟲框架抓取網(wǎng)頁全部文章信息(上篇),我們已經(jīng)解析了列表頁中所有文章的URL并交給Scrapy進(jìn)行下載,這篇文章我們將提取下一頁的URL并交給Scrapy進(jìn)行下載,具體教程如下。
/具體實(shí)現(xiàn)/
??? 1、首先在網(wǎng)頁中先找到“下一頁”的相關(guān)鏈接,如下圖所示。與網(wǎng)頁進(jìn)行交互,找到“下一頁”的URL。
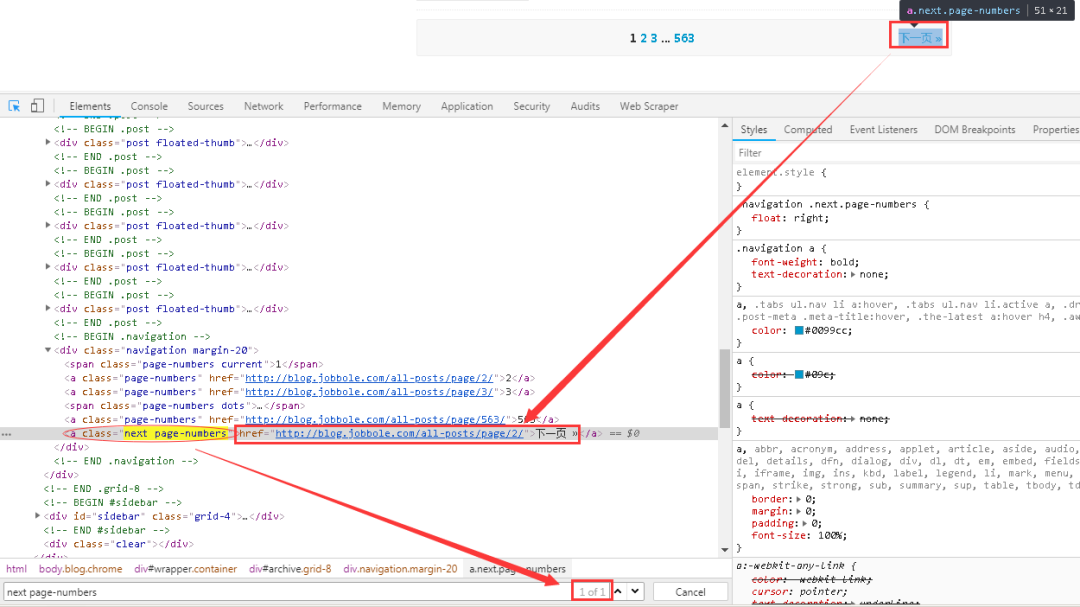
????可以看到下一頁的鏈接存在與a標(biāo)簽下的nextpage-numbers屬性下面的href標(biāo)簽中,而且該屬性是唯一的,可以很輕易的定位到該鏈接。
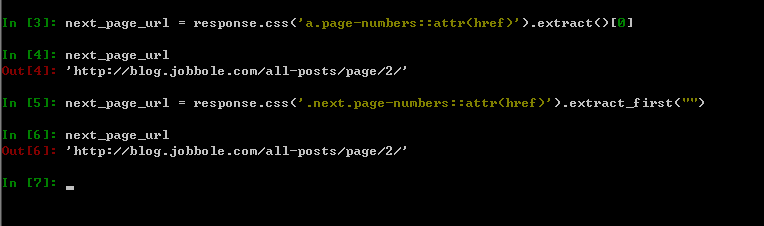
??? 2、可以在scrapyshell中進(jìn)行調(diào)試,爾后再將滿足條件的表達(dá)式寫入到代碼中去,如下圖所示。
?
????上圖中兩種方式都可以提取到目標(biāo)信息。比較推薦的是第二種方式,其中.next.page-numbers代表的是同一個(gè)class下有兩個(gè)屬性,可以更快更準(zhǔn)確的定位到標(biāo)簽,需要注意的是兩個(gè)屬性直接直接用點(diǎn)號進(jìn)行連接,無任何的空格,初學(xué)者容易犯錯(cuò)。另外,extract_first("")這個(gè)函數(shù)在之前的文章中提及過,其默認(rèn)值為空,如果沒有匹配到目標(biāo)信息的話,則返回None。
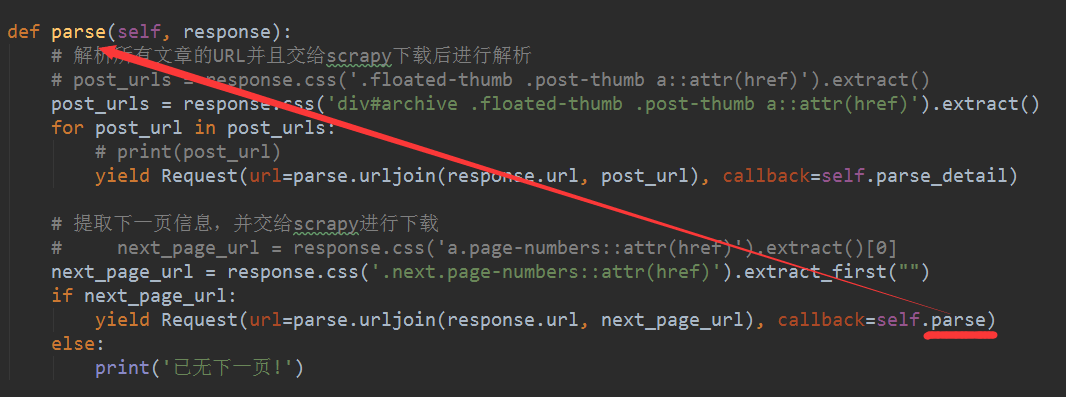
??? 3、取到了下一頁的鏈接之后,需要對其做個(gè)判斷,以防萬一,具體的代碼如下圖所示。
????
????至此,我們已經(jīng)提取了下一頁的URL,并交給Scrapy進(jìn)行下載。需要注意的是除了URL拼接部分之后,callback回調(diào)函數(shù)在這里是parse()函數(shù),表示回調(diào)下一頁的文章列表頁,而不是文章詳情頁面,這點(diǎn)需要特別注意。
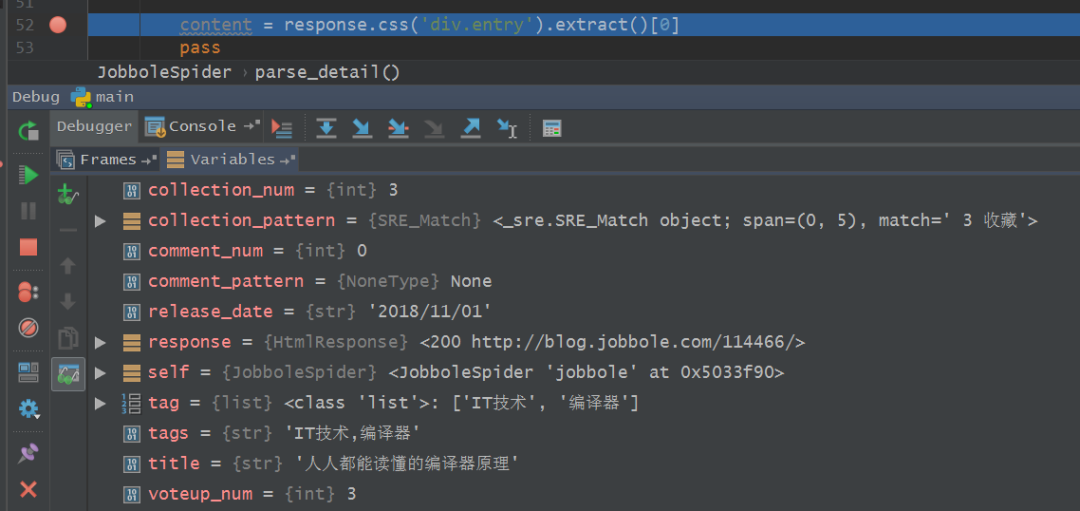
????4、接下來,我們就可以對整個(gè)爬蟲進(jìn)行調(diào)試了,在爬蟲主體文件中設(shè)置好斷點(diǎn),如下圖所示,之后在main.py文件中點(diǎn)擊運(yùn)行Debug,
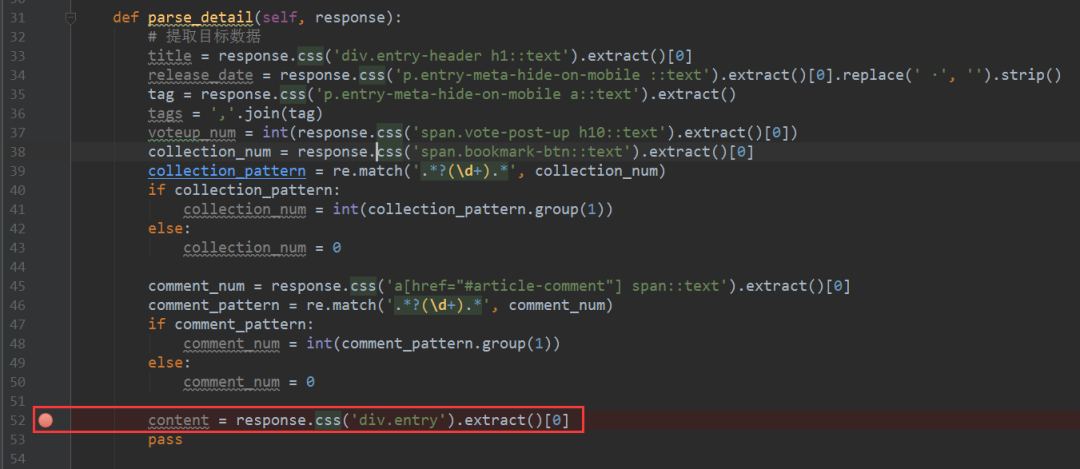
??? 5、稍等片刻,等待調(diào)試的結(jié)果出來,如下圖所示,結(jié)果鮮明。
??? 6、到這里,我們基本上已經(jīng)完成所有文章的提取,簡單的回顧一下整個(gè)爬取過程。首先我們在parse()函數(shù)中獲取到文章的URL,爾后將其交給Scrapy去進(jìn)行下載,下載完成之后,Scrapy再去調(diào)用parse_detail()函數(shù)去提取網(wǎng)頁中的目標(biāo)信息,這個(gè)頁面提取完成之后,再進(jìn)行下一個(gè)頁面的信息提取,并將下一頁的URL交給Scrapy去進(jìn)行下載,再回調(diào)parse()函數(shù)以提取出下一頁中文章列表的URL,如此往復(fù)的進(jìn)行迭代,一直到最后一頁為止,整個(gè)爬蟲才會(huì)停止。
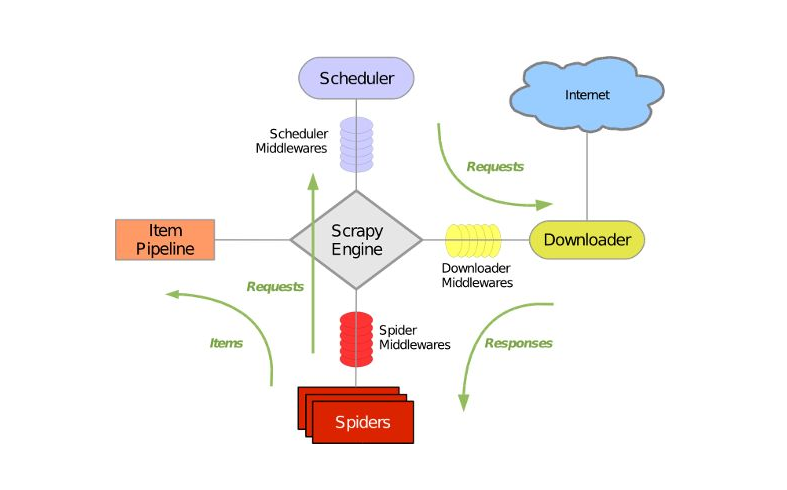
??? 7、利用Scrapy爬蟲框架,我們便可以獲取到整個(gè)網(wǎng)站的全部文章內(nèi)容,中間的具體下載實(shí)現(xiàn)完全不用經(jīng)過我們手動(dòng)去進(jìn)行,有木有感受到Scrapy爬蟲的強(qiáng)大咧?
????目前我們只是遍歷了整個(gè)網(wǎng)站,知道了目標(biāo)信息的提取方法,暫時(shí)還沒有將目標(biāo)數(shù)據(jù)保存到本地或者數(shù)據(jù)庫當(dāng)中去,后邊的文章我們繼續(xù)再約~~~
/小結(jié)/
????本文基于Scrapy爬蟲框架,利用CSS選擇器和Xpath選擇器解析列表頁中所有文章的URL,遍歷整個(gè)網(wǎng)站進(jìn)行數(shù)據(jù)采集,至此,我們已經(jīng)可以實(shí)現(xiàn)全網(wǎng)文章的數(shù)據(jù)采集了。
??? 想學(xué)習(xí)更多關(guān)于Python的知識(shí),可以參考學(xué)習(xí)網(wǎng)址:http://pdcfighting.com/,點(diǎn)擊閱讀原文,可以直達(dá)噢~
-------------------?End?-------------------
往期精彩文章推薦:

歡迎大家點(diǎn)贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請?jiān)诤笈_(tái)回復(fù)【入群】
萬水千山總是情,點(diǎn)個(gè)【在看】行不行
/今日留言主題/
隨便說一兩句吧~~