
面試官:線程池大小 + 線程數(shù)量到底設置多少?

閱讀本文大概需要 7 分鐘。
CPU 密集型的程序 - 核心數(shù) + 1 I/O 密集型的程序 - 核心數(shù) * 2
線程數(shù)和CPU利用率的小測試
public class CPUUtilizationTest {
public static void main(String[] args) {
//死循環(huán),什么都不做
while (true){
}
}
}
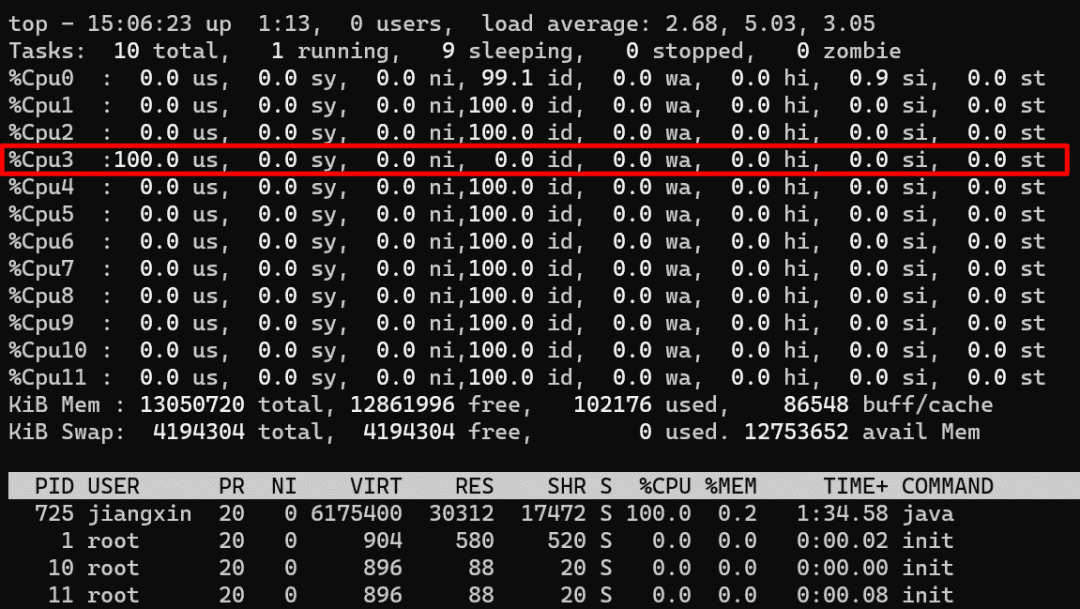
public class CPUUtilizationTest {
public static void main(String[] args) {
for (int j = 0; j < 6; j++) {
new Thread(new Runnable() {
@Override
public void run() {
while (true){
}
}
}).start();
}
}
}
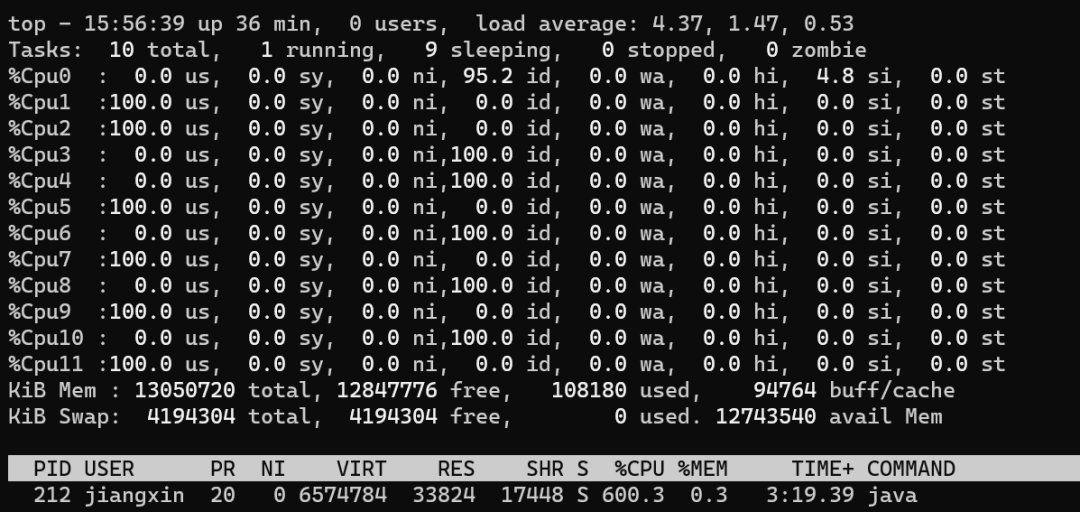
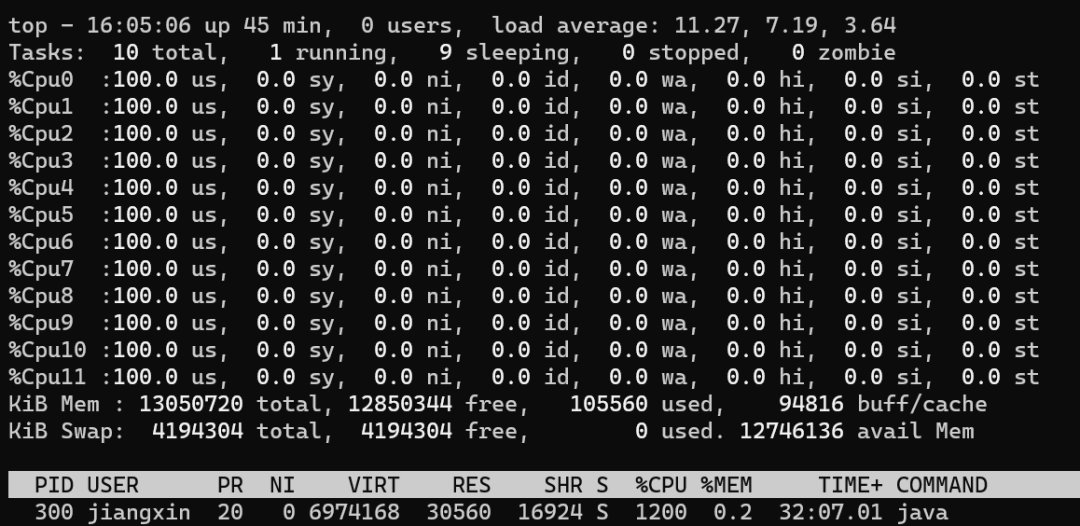
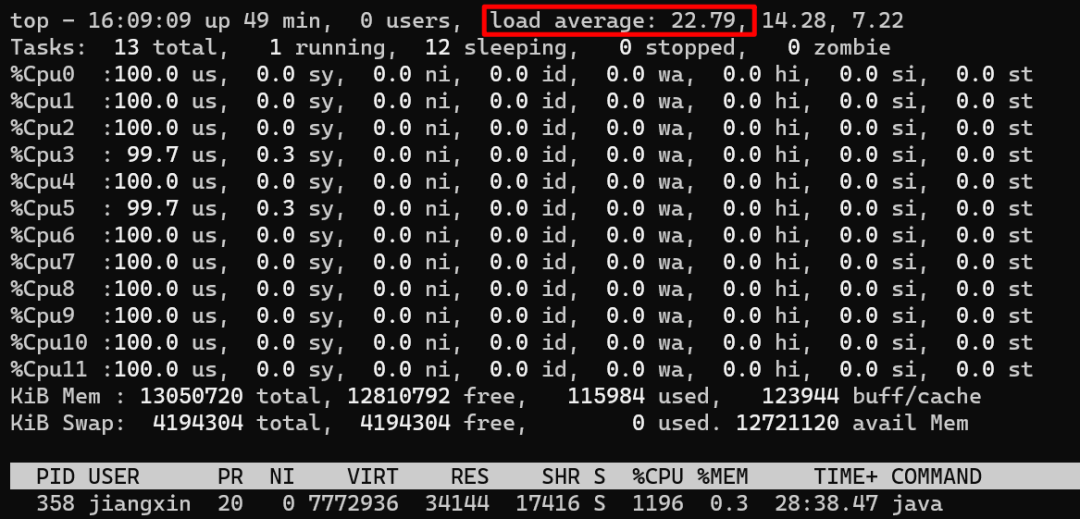
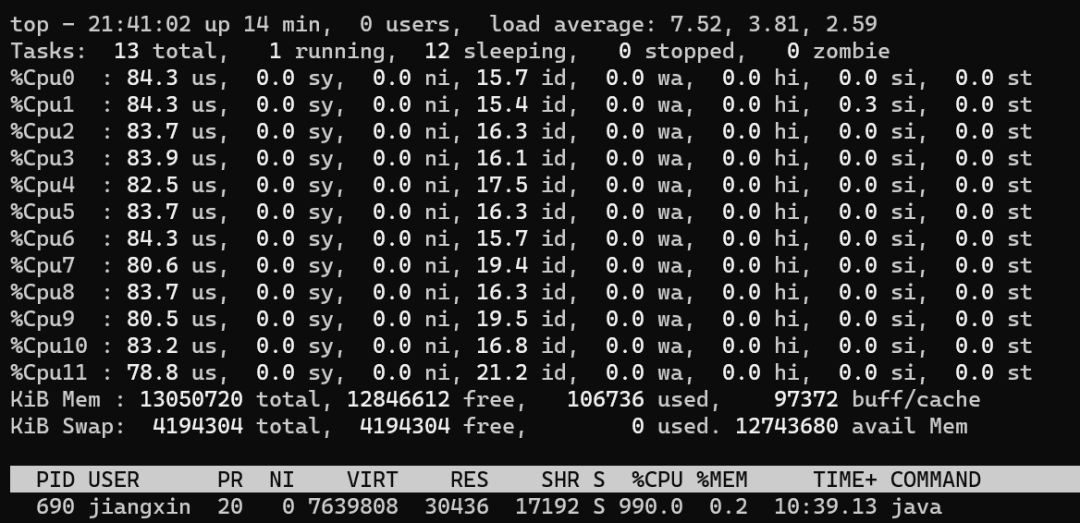
public class CPUUtilizationTest { public static void main(String[] args) throws InterruptedException { for (int n = 0; n < 1; n++) { new Thread(new Runnable() { public void run() { while (true){ //每次空循環(huán) 1億 次后,sleep 50ms,模擬 I/O等待、切換 for (int i = 0; i < 100_000_000l; i++) { } try { Thread.sleep(50); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } }}
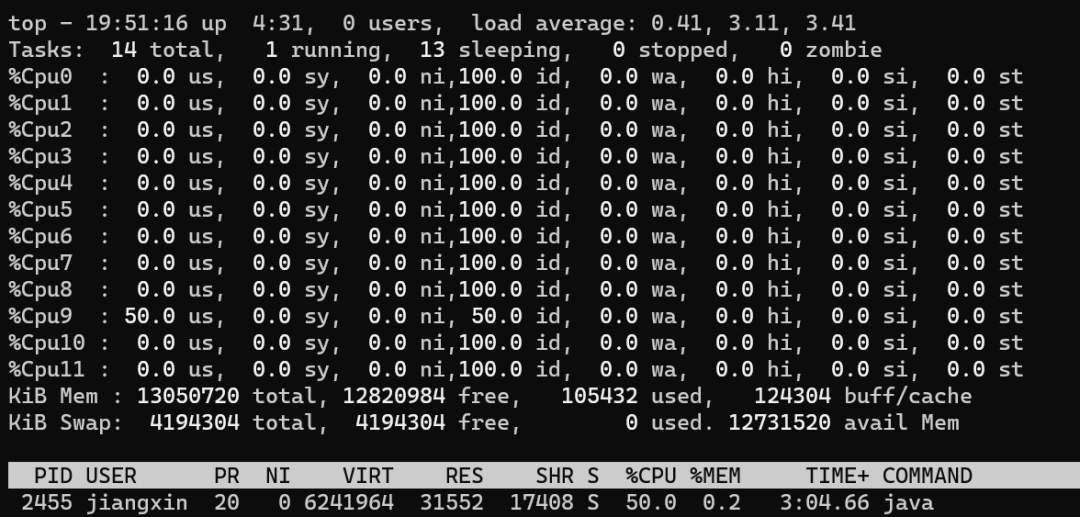
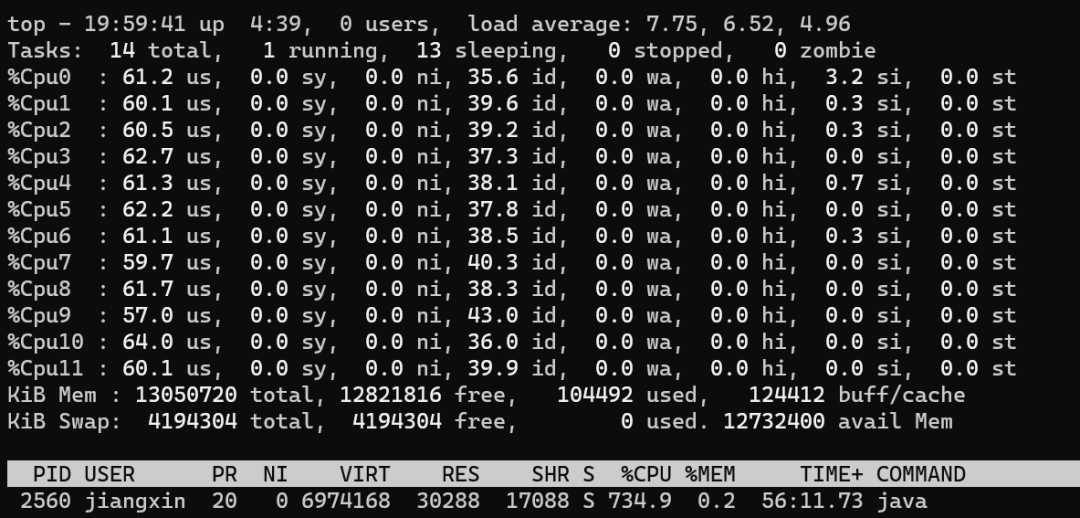
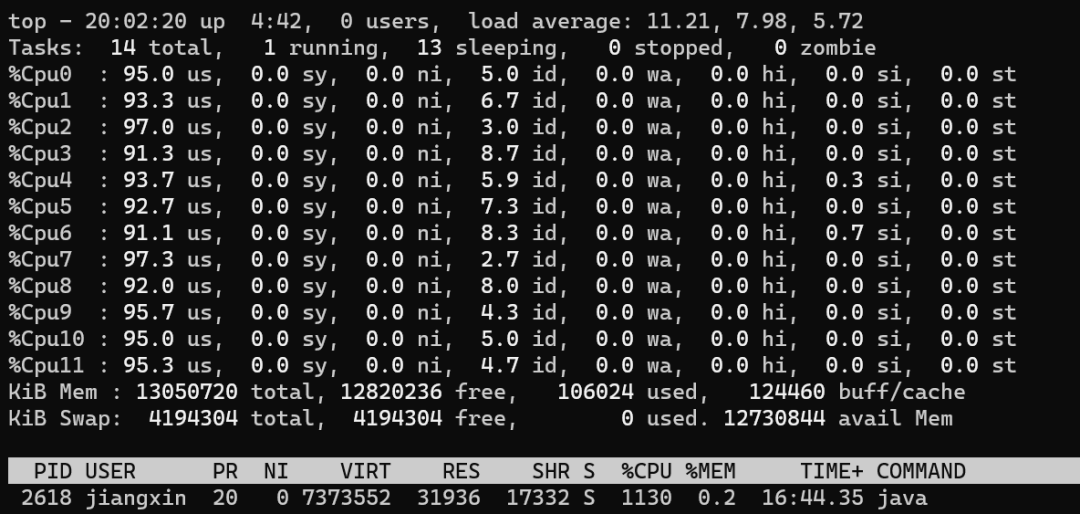
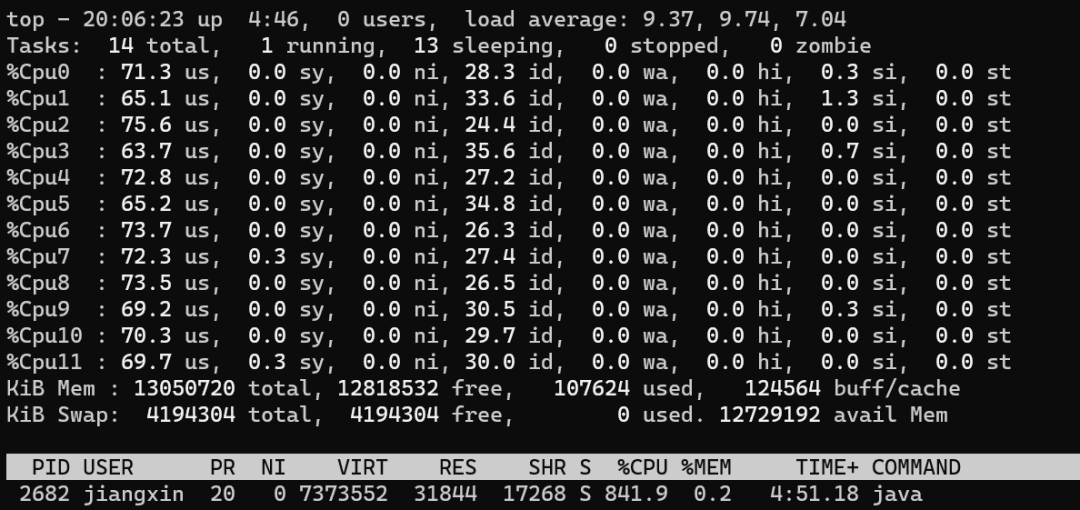
線程數(shù)和CPU利用率的小總結
一個極端的線程(不停執(zhí)行“計算”型操作時),就可以把單個核心的利用率跑滿,多核心CPU最多只能同時執(zhí)行等于核心數(shù)的“極端”線程數(shù) 如果每個線程都這么“極端”,且同時執(zhí)行的線程數(shù)超過核心數(shù),會導致不必要的切換,造成負載過高,只會讓執(zhí)行更慢 I/O 等暫停類操作時,CPU處于空閑狀態(tài),操作系統(tǒng)調度CPU執(zhí)行其他線程,可以提高CPU利用率,同時執(zhí)行更多的線程 I/O 事件的頻率頻率越高,或者等待/暫停時間越長,CPU的空閑時間也就更長,利用率越低,操作系統(tǒng)可以調度CPU執(zhí)行更多的線程
線程數(shù)規(guī)劃的公式

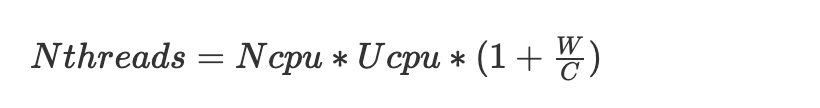


真實程序中的線程數(shù)
分析當前主機上,有沒有其他進程干擾
分析當前JVM進程上,有沒有其他運行中或可能運行的線程
設定目標
目標CPU利用率 - 我最高能容忍我的CPU飆到多少?
目標GC頻率/暫停時間 - 多線程執(zhí)行后,GC頻率會增高,最大能容忍到什么頻率,每次暫停時間多少?
執(zhí)行效率 - 比如批處理時,我單位時間內要開多少線程才能及時處理完畢
……
梳理鏈路關鍵點,是否有卡脖子的點,因為如果線程數(shù)過多,鏈路上某些節(jié)點資源有限可能會導致大量的線程在等待資源(比如三方接口限流,連接池數(shù)量有限,中間件壓力過大無法支撐等)
不斷的增加/減少線程數(shù)來測試,按最高的要求去測試,最終獲得一個“滿足要求”的線程數(shù)**
Tomcat中的maxThreads,在Blocking I/O和No-Blocking I/O下就不一樣 Dubbo 默認還是單連接呢,也有I/O線程(池)和業(yè)務線程(池)的區(qū)分,I/O線程一般不是瓶頸,所以不必太多,但業(yè)務線程很容易稱為瓶頸 Redis 6.0以后也是多線程了,不過它只是I/O 多線程,“業(yè)務”處理還是單線程
附錄
Java 獲取CPU核心數(shù)
Runtime.getRuntime().availableProcessors()//獲取邏輯核心數(shù),如6核心12線程,那么返回的是12
Linux 獲取CPU核心數(shù)
# 總核數(shù) = 物理CPU個數(shù) X 每顆物理CPU的核數(shù)
# 總邏輯CPU數(shù) = 物理CPU個數(shù) X 每顆物理CPU的核數(shù) X 超線程數(shù)
# 查看物理CPU個數(shù)
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每個物理CPU中core的個數(shù)(即核數(shù))
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看邏輯CPU的個數(shù)
cat /proc/cpuinfo| grep "processor"| wc -l
推薦閱讀:
微信掃描二維碼,關注我的公眾號
朕已閱 