
Rocketmq源碼分析17:RocketMq 知識點總結
架構總覽
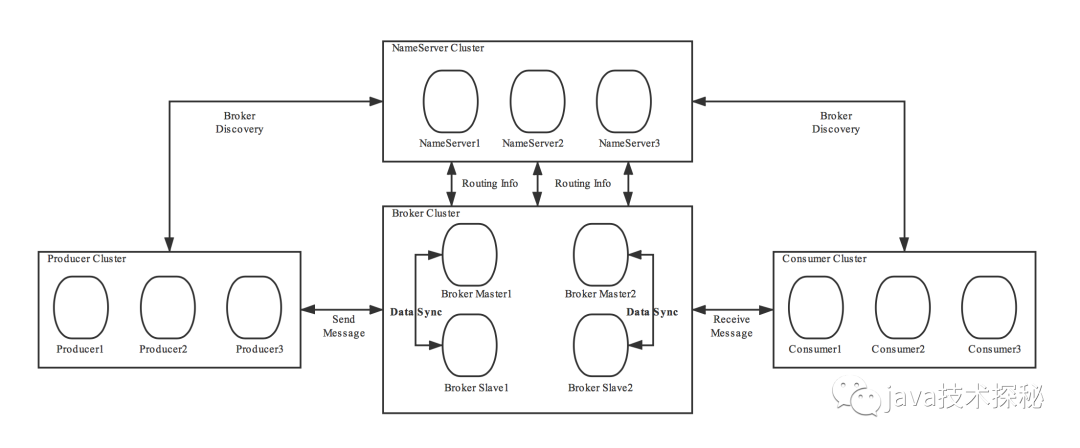
RocketMQ架構上主要分為四部分,如上圖所示:
Producer:消息發(fā)布的角色,支持分布式集群方式部署。Producer通過MQ的負載均衡模塊選擇相應的Broker集群隊列進行消息投遞,投遞的過程支持快速失敗并且低延遲。
Consumer:消息消費的角色,支持分布式集群方式部署。支持以push推,pull拉兩種模式對消息進行消費。同時也支持集群方式和廣播方式的消費,它提供實時消息訂閱機制,可以滿足大多數用戶的需求。
NameServer:NameServer是一個非常簡單的Topic路由注冊中心,其角色類似Dubbo中的zookeeper,支持Broker的動態(tài)注冊與發(fā)現。主要包括兩個功能:Broker管理,NameServer接受Broker集群的注冊信息并且保存下來作為路由信息的基本數據。然后提供心跳檢測機制,檢查Broker是否還存活;路由信息管理,每個NameServer將保存關于Broker集群的整個路由信息和用于客戶端查詢的隊列信息。然后Producer和Conumser通過NameServer就可以知道整個Broker集群的路由信息,從而進行消息的投遞和消費。NameServer通常也是集群的方式部署,各實例間相互不進行信息通訊。Broker是向每一臺NameServer注冊自己的路由信息,所以每一個NameServer實例上面都保存一份完整的路由信息。當某個NameServer因某種原因下線了,Broker仍然可以向其它NameServer同步其路由信息,Producer,Consumer仍然可以動態(tài)感知Broker的路由的信息。
BrokerServer:Broker主要負責消息的存儲、投遞和查詢以及服務高可用保證
topic、borker與queue三者關系
三者關系如下圖:
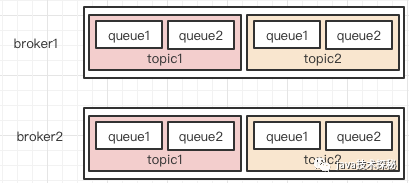
在圖中,共有2個broker,2個topic,每個topic都有4個隊列。在producer發(fā)送消息時,是發(fā)送到具體的隊列上,consumer獲取消息時,也是從隊列上獲取。
注:RocketMq 的 topic 可以在控制臺手動創(chuàng)建,也可以自動創(chuàng)建(需要開啟配置autoCreateTopicEnable=true),官方建議生產環(huán)境下關閉自動創(chuàng)建。
消息處理流程
RocketMq消息處理整個流程如下:

消息接收:消息接收是指接收 producer的消息,處理類是SendMessageProcessor,將消息寫入到commigLog文件后,接收流程處理完畢;消息分發(fā): broker處理消息分發(fā)的類是ReputMessageService,它會啟動一個線程,不斷地將commitLong分到到對應的consumerQueue,這一步操作會寫兩個文件:consumerQueue與indexFile,寫入后,消息分發(fā)流程處理 完畢;消息投遞:消息投遞是指將消息發(fā)往 consumer的流程,consumer會發(fā)起獲取消息的請求,broker收到請求后,調用PullMessageProcessor類處理,從consumerQueue文件獲取消息,返回給consumer后,投遞流程處理完畢。
具體分析可參考
三高保證
高并發(fā)
netty 高性能傳輸:
producer、broker、comsumer之間使用netty通信,高性能傳輸;業(yè)務處理時,使用的是自定義的工作線程池,最終處理操作在NettyServerHandler中丟給工作線程池。自旋鎖減少上下文切換:RocketMQ 的 CommitLog 為了避免并發(fā)寫入,使用一個
PutMessageLock。PutMessageLock有 2個實現版本:PutMessageReentrantLock和PutMessageSpinLock。PutMessageReentrantLock是基于 java 的同步等待喚醒機制;PutMessageSpinLock使用 Java 的 CAS 原語,通過自旋設值實現上鎖和解鎖。RocketMQ 默認使用PutMessageSpinLock以提高高并發(fā)寫入時候的上鎖解鎖效率,并減少線程上下文切換次數。順序寫文件:寫入
commitLog時,使用的是順序寫入,比隨機寫入的性能高很多,寫入commitLog時,并不是直接寫入磁盤的,而是先寫入PageCache,最后由操作系統(tǒng)異步將PageCache的數據刷到磁盤中MappedFile預熱和零拷貝機制:Linux 系統(tǒng)在寫數據時候不會直接把數據寫到磁盤上,而是寫到磁盤對應的PageCache中,并把該頁標記為臟頁。當臟頁累計到一定程度或者一定時間后再把數據 flush 到磁盤(當然在此期間如果系統(tǒng)掉電,會導致臟頁數據丟失)。多
broker多Queue模式:使用多broker多Queue的模式,提高消息的并行處理能力。
高可用
RocketMq 的高可用由 DLedger 提供,整個 broker 的高可用架構如下:
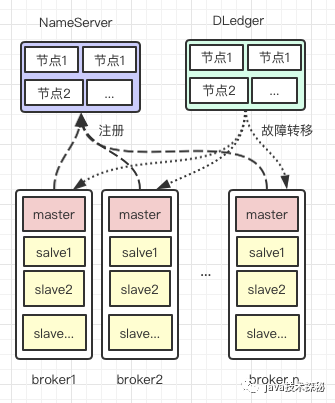
DLedger是一個多節(jié)點的集群,內部使用raft算法選舉leader節(jié)點,由該leader節(jié)點對broker中的節(jié)點進行故障轉移
多 NameServer避免NameServer的單點故障多個 broker集群,當一個broker集群出現故障時,其他broker集群也能正常工作每個 broker集群有一個master節(jié)點和多個slave節(jié)點,當master節(jié)點出現故障,DLedger在感知到故障后,會將其中一個slave節(jié)點切換為master節(jié)點,保證該集群繼續(xù)正常工作
高擴展
broker與producer/consumer沒有耦合關系,需要添加broker集群(1主多從)時,只需配置好nameServer的地址,然后添加即可,理論上broker可任意擴展。
當broker添加到集群后,新加入的 broker 集群會被注冊到nameServer上,producer/consumer就能發(fā)現該broker集群了。
消息可靠性
RocketMq 的消息可靠性分為如下幾個階段:
消息發(fā)送階段的可靠性 消息存儲階段可靠性 消息消費階段的可靠性
下面我們將介紹這3個階段的可靠性是如何做到的。
消息發(fā)送階段的可靠性
消息發(fā)送階段的可靠性由producer來處理,rocketmq主要支持三種消息發(fā)送方式
同步:消息發(fā)放后,線程會阻塞,直到返回結果 異步:在發(fā)送消息時,可以設置消息發(fā)送結果的監(jiān)聽,消息發(fā)送后,線程不會阻塞,消息發(fā)送完成后,發(fā)送結果會被監(jiān)聽到 單向:消息發(fā)送完成后,線程不會阻塞,不會有結果返回,也無法設置發(fā)送結果的監(jiān)聽,即發(fā)送就可以,不關心發(fā)送結果,不關心是否發(fā)送成功
在消息可靠性方面,
同步發(fā)送:消息發(fā)送失敗時,內部會「重試」(默認1次發(fā)送+2次失敗重試,共3次),另外,由于發(fā)送完成后可以得到發(fā)送結果,因此也「可對失敗的結果進行自主處理」異步發(fā)送:消息發(fā)送失敗時,同時有內部「重試」(默認1次發(fā)送+2次失敗重試,共3次),另外,發(fā)送消息時可以設置消息的監(jiān)聽規(guī)則,當發(fā)送失敗時,可以「在監(jiān)聽代碼中自主對失敗的消息進行處理」單向發(fā)送:該模式下,消息發(fā)送失敗時「無重試」(只是打出一條warn級別的日志),且「無發(fā)送結果返回、無結果監(jiān)聽」
消息存儲階段可靠性
消息存儲階段可靠性由broker來保證,
在單master架構的broker中,消息先寫入內存的PageCache中,然后再進行刷盤,刷盤方式有兩種:
SYNC_FLUSH(同步刷盤):消息寫入內存的 PageCache后,立刻通知刷盤線程刷盤,然后等待刷盤完成,刷盤線程執(zhí)行完成后喚醒等待的線程,返回消息寫成功的狀態(tài)。這種方式可以保證數據絕對安全,但是吞吐量不大。ASYNC_FLUSH(異步刷盤(默認)):消息寫入到內存的 PageCache中,就立刻給客戶端返回寫操作成功,當 PageCache中的消息積累到一定的量時,觸發(fā)一次寫操作,或者定時等策略將 PageCache中的消息寫入到磁盤中。這種方式吞吐量大,性能高,但是 PageCache 中的數據可能丟失,不能保證數據絕對的安全。
小結:同步刷盤,不丟失數據但影響性能;異步刷盤性能高,但如果在消息刷盤前發(fā)生斷電意外,消息就會丟失。
如果一主多從的broker架構中,master節(jié)點有兩種角色選擇:
SYNC_MASTER(同步主機):當接收到消息后,立即同步到slave節(jié)點,當slave節(jié)點同步成功后,才返回成功,可靠性高ASYNC_MASTER(異步主機):當接收到消息,并不立即同步給slave節(jié)點,同步操作由后臺線程進行,如果在發(fā)生主從切換時,同步操作還未進行,就有可能會丟失數據
小結:同步主機可靠性高,發(fā)生主從切換時不會丟失數據,但由于需要等待slave節(jié)點同步成功后才返回,因此性能略低;異步主機性能高,但如果在同步操作前發(fā)生了主從切換,原master上的數據可能并沒有同步給slave,因此會造成消息丟失
總結:如果要保證消息的可靠性,單master節(jié)點的刷新方式可選擇SYNC_FLUSH(同步刷盤)方式;一主多從的broker架構中,master節(jié)點的刷新方式可選擇ASYNC_FLUSH(異步刷盤)方式,master節(jié)點的角色使用SYNC_MASTER(同步主機),實際中就結合具體場景進行合理選擇。
消息消費階段的可靠性
消息消費階段的可靠性由comsumer來保證。在消費消息時,可返回兩種結果:
CONSUME_SUCCESS:消費成功RECONSUME_LATER:消費失敗,稍后再消費
Consumer消費消息失敗后,RocketMq會提供一種重試機制,令消息再消費一次。Consumer消費消息失敗通常可以認為有以下幾種情況:
由于消息本身的原因,例如反序列化失敗,消息數據本身無法處理(例如話費充值,當前消息的手機號被注銷,無法充值)等。這種錯誤通常需要跳過這條消息,再消費其它消息,而這條失敗的消息即使立刻重試消費,99%也不成功,所以最好提供一種定時重試機制,即過10秒后再重試。 由于依賴的下游應用服務不可用,例如db連接不可用,外系統(tǒng)網絡不可達等。遇到這種錯誤,即使跳過當前失敗的消息,消費其他消息同樣也會報錯。這種情況建議應用sleep 30s,再消費下一條消息,這樣可以減輕Broker重試消息的壓力。
RocketMQ會為每個消費組都設置一個Topic名稱為%RETRY%+consumerGroup的重試隊列(這里需要注意的是,這個Topic的重試隊列是針對消費組,而不是針對每個Topic設置的),用于暫時保存因為各種異常而導致Consumer端無法消費的消息。考慮到異常恢復起來需要一些時間,會為重試隊列設置多個重試級別,每個重試級別都有與之對應的重新投遞延時,重試次數越多投遞延時就越大。RocketMQ對于重試消息的處理是先保存至Topic名稱為SCHEDULE_TOPIC_XXXX的延遲隊列中,后臺定時任務按照對應的時間進行Delay后重新保存至%RETRY%+consumerGroup的重試隊列中。
負載均衡
producer 負載均衡
Producer端在發(fā)送消息的時候,會先根據Topic找到指定的TopicPublishInfo,在獲取了TopicPublishInfo路由信息后,RocketMQ的客戶端在默認方式下selectOneMessageQueue()方法會從TopicPublishInfo中的messageQueueList中選擇一個隊列(MessageQueue)進行發(fā)送消息。具體的容錯策略均在MQFaultStrategy這個類中定義。
這里有一個sendLatencyFaultEnable開關變量,如果開啟,在隨機遞增取模的基礎上,再過濾掉not available的Broker代理。所謂的"latencyFaultTolerance",是指對之前失敗的,按一定的時間做退避。例如,如果上次請求的latency超過550Lms,就退避3000Lms;超過1000L,就退避60000L;如果關閉,采用隨機遞增取模的方式選擇一個隊列(MessageQueue)來發(fā)送消息,latencyFaultTolerance機制是實現消息發(fā)送高可用的核心關鍵所在。
consumer 負載均衡
在RocketMQ中,Consumer端的兩種消費模式(Push/Pull)都是基于拉模式來獲取消息的,而在Push模式只是對pull模式的一種封裝,其本質實現為消息拉取線程在從服務器拉取到一批消息后,然后提交到消息消費線程池后,又“馬不停蹄”的繼續(xù)向服務器再次嘗試拉取消息。如果未拉取到消息,則延遲一下又繼續(xù)拉取。在兩種基于拉模式的消費方式(Push/Pull)中,均需要Consumer端在知道從Broker端的哪一個消息隊列—隊列中去獲取消息。因此,有必要在Consumer端來做負載均衡,即Broker端中多個MessageQueue分配給同一個ConsumerGroup中的哪些Consumer消費。
Consumer端的心跳包發(fā)送
在Consumer啟動后,它就會通過定時任務不斷地向RocketMQ集群中的所有Broker實例發(fā)送心跳包(其中包含了,消息消費分組名稱、訂閱關系集合、消息通信模式和客戶端id的值等信息)。Broker端在收到Consumer的心跳消息后,會將它維護在ConsumerManager的本地緩存變量—consumerTable,同時并將封裝后的客戶端網絡通道信息保存在本地緩存變量—channelInfoTable中,為之后做Consumer端的負載均衡提供可以依據的元數據信息。
Consumer端實現負載均衡的核心類—RebalanceImpl
在Consumer實例的啟動流程中的啟動MQClientInstance實例部分,會完成負載均衡服務線程—RebalanceService的啟動(每隔20s執(zhí)行一次)。通過查看源碼可以發(fā)現,RebalanceService線程的run()方法最終調用的是RebalanceImpl類的rebalanceByTopic()方法,該方法是實現Consumer端負載均衡的核心。這里,rebalanceByTopic()方法會根據消費者通信類型為“廣播模式”還是“集群模式”做不同的邏輯處理。這里主要來看下集群模式下的主要處理流程:
(1) 從rebalanceImpl實例的本地緩存變量—topicSubscribeInfoTable中,獲取該Topic主題下的消息消費隊列集合(mqSet);
(2) 根據topic和consumerGroup為參數調用mQClientFactory.findConsumerIdList()方法向Broker端發(fā)送獲取該消費組下消費者Id列表的RPC通信請求(Broker端基于前面Consumer端上報的心跳包數據而構建的consumerTable做出響應返回,業(yè)務請求碼:GET_CONSUMER_LIST_BY_GROUP);
(3) 先對Topic下的消息消費隊列、消費者Id排序,然后用消息隊列分配策略算法(默認為:消息隊列的平均分配算法),計算出待拉取的消息隊列。這里的平均分配算法,類似于分頁的算法,將所有MessageQueue排好序類似于記錄,將所有消費端Consumer排好序類似頁數,并求出每一頁需要包含的平均size和每個頁面記錄的范圍range,最后遍歷整個range而計算出當前Consumer端應該分配到的記錄(這里即為:MessageQueue)。
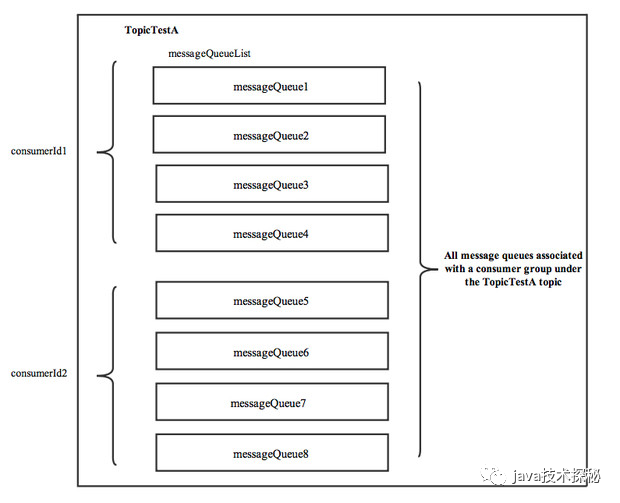
(4) 然后,調用updateProcessQueueTableInRebalance()方法,具體的做法是,先將分配到的消息隊列集合(mqSet)與processQueueTable做一個過濾比對。
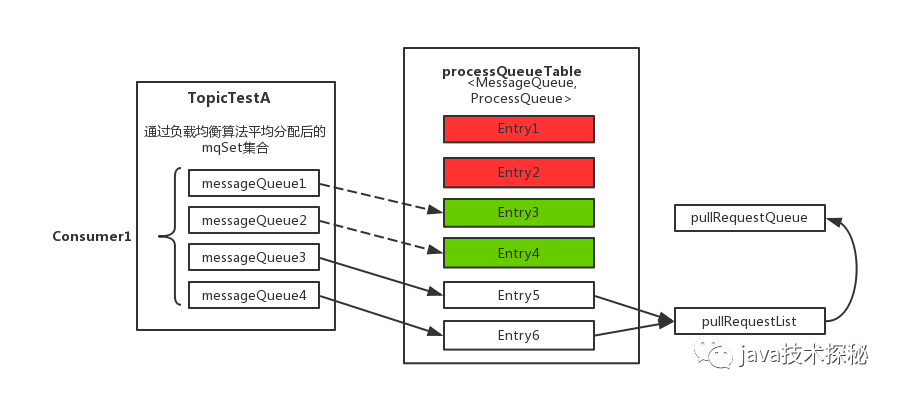
上圖中processQueueTable標注的紅色部分,表示與分配到的消息隊列集合mqSet互不包含。將這些隊列設置Dropped屬性為true,然后查看這些隊列是否可以移除出processQueueTable緩存變量,這里具體執(zhí)行removeUnnecessaryMessageQueue()方法,即每隔1s 查看是否可以獲取當前消費處理隊列的鎖,拿到的話返回true。如果等待1s后,仍然拿不到當前消費處理隊列的鎖則返回false。如果返回true,則從processQueueTable緩存變量中移除對應的Entry;
上圖中processQueueTable的綠色部分,表示與分配到的消息隊列集合mqSet的交集。判斷該ProcessQueue是否已經過期了,在Pull模式的不用管,如果是Push模式的,設置Dropped屬性為true,并且調用removeUnnecessaryMessageQueue()方法,像上面一樣嘗試移除Entry;
最后,為過濾后的消息隊列集合(mqSet)中的每個MessageQueue創(chuàng)建一個ProcessQueue對象并存入RebalanceImpl的processQueueTable隊列中(其中調用RebalanceImpl實例的computePullFromWhere(MessageQueue mq)方法獲取該MessageQueue對象的下一個進度消費值offset,隨后填充至接下來要創(chuàng)建的pullRequest對象屬性中),并創(chuàng)建拉取請求對象—pullRequest添加到拉取列表—pullRequestList中,最后執(zhí)行dispatchPullRequest()方法,將Pull消息的請求對象PullRequest依次放入PullMessageService服務線程的阻塞隊列pullRequestQueue中,待該服務線程取出后向Broker端發(fā)起Pull消息的請求。其中,可以重點對比下,RebalancePushImpl和RebalancePullImpl兩個實現類的dispatchPullRequest()方法不同,RebalancePullImpl類里面的該方法為空,這樣子也就回答了上一篇中最后的那道思考題了。
消息消費隊列在同一消費組不同消費者之間的負載均衡,其核心設計理念是在一個消息消費隊列在同一時間只允許被同一消費組內的一個消費者消費,一個消息消費者能同時消費多個消息隊列。
廣播模式與集群模式
廣播模式
廣播模式下,同一條消息會被同一consumerGroup下的每個consumer消費
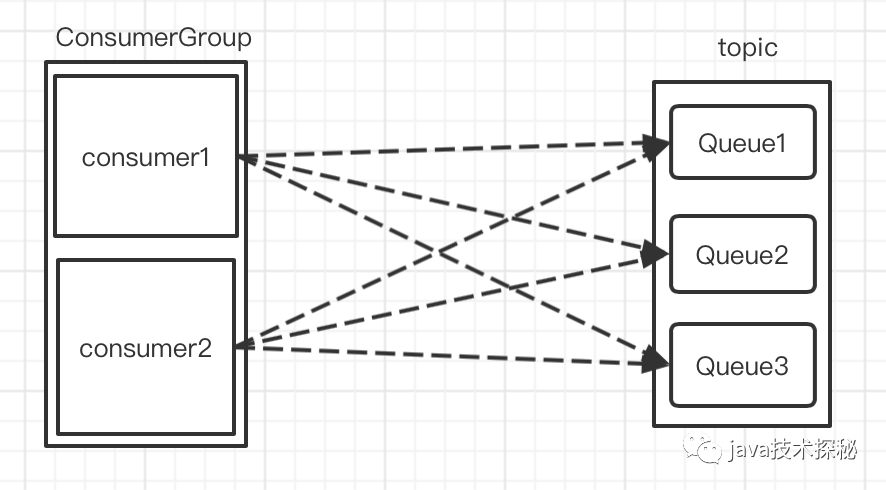
如圖,同一topic下有3個MessageQueue,且有一個consumerGroup,組內有兩個consumer,在廣播模式下,consumer1與consumer2都會消費MessageQueue1、MessageQueue2 與 MessageQueue3 的消息。
集群模式
集群模式下,同一條消息只會被同一consumerGroup下的一個consumer消費
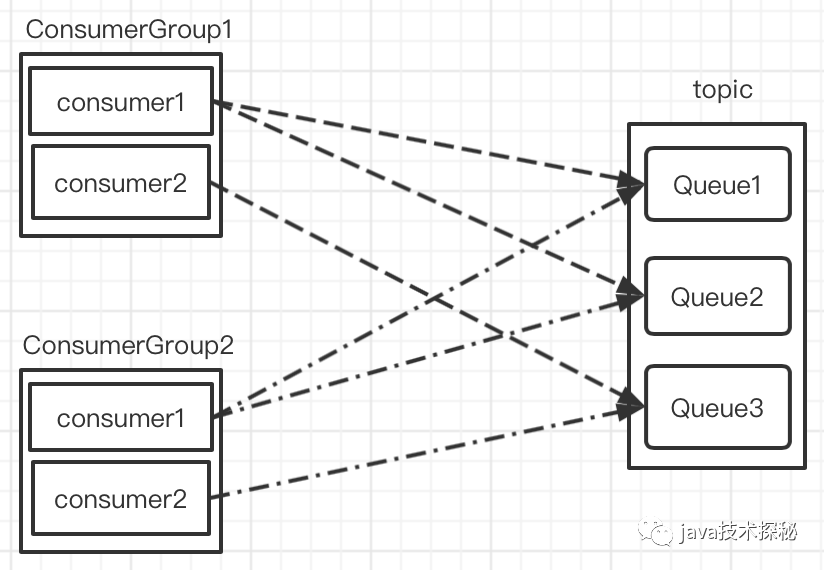
如圖所示,同一topic下有3個MessageQueue,有兩個consumerGroup去消費這3個MessageQueue上的消息,consumerGroup1中的consumer1會消息MessageQueue1、MessageQueue2上的消息,consumerGroup1中的consumer2會消息MessageQueue3上的消息;consumerGroup2中的consumer1會消息MessageQueue1、MessageQueue2上的消息,consumerGroup2中的consumer2會消息MessageQueue3上的消息。
順序消息
消息有序指的是一類消息消費時,能按照發(fā)送的順序來消費。例如:一個訂單產生了三條消息分別是訂單創(chuàng)建、訂單付款、訂單完成。消費時要按照這個順序消費才能有意義,但是同時訂單之間是可以并行消費的。
RocketMQ可以嚴格的保證消息有序。
順序消息分為全局順序消息與分區(qū)順序消息,全局順序是指某個Topic下的所有消息都要保證順序;部分順序消息只要保證每一組消息被順序消費即可。
全局順序:對于指定的一個 Topic,所有消息按照嚴格的先入先出(FIFO)的順序進行發(fā)布和消費。適用場景:性能要求不高,所有的消息嚴格按照 FIFO 原則進行消息發(fā)布和消費的場景 分區(qū)順序:對于指定的一個 Topic,所有消息根據 sharding key 進行區(qū)塊分區(qū)。同一個分區(qū)內的消息按照嚴格的 FIFO 順序進行發(fā)布和消費。Sharding key 是順序消息中用來區(qū)分不同分區(qū)的關鍵字段,和普通消息的 Key 是完全不同的概念。適用場景:性能要求高,以 sharding key 作為分區(qū)字段,在同一個區(qū)塊中嚴格的按照 FIFO 原則進行消息發(fā)布和消費的場景。
事務消息
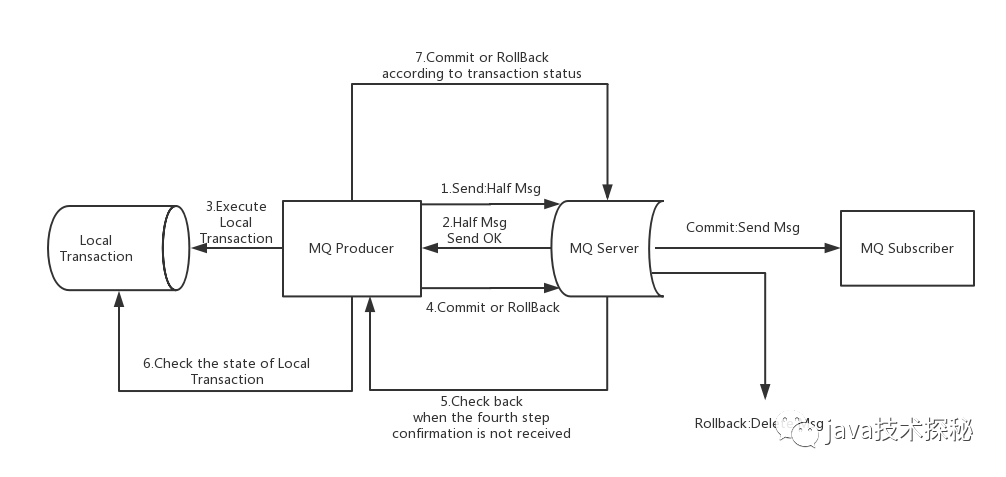
上圖說明了事務消息的大致方案,其中分為兩個流程:正常事務消息的發(fā)送及提交、事務消息的補償流程。
事務消息發(fā)送及提交:
發(fā)送消息(half消息)。 服務端響應消息寫入結果。 根據發(fā)送結果執(zhí)行本地事務(如果寫入失敗,此時half消息對業(yè)務不可見,本地邏輯不執(zhí)行)。 根據本地事務狀態(tài)執(zhí)行Commit或者Rollback(Commit操作生成消息索引,消息對消費者可見)
補償流程:
對沒有Commit/Rollback的事務消息(pending狀態(tài)的消息),從服務端發(fā)起一次“回查” Producer收到回查消息,檢查回查消息對應的本地事務的狀態(tài) 根據本地事務狀態(tài),重新Commit或者Rollback
其中,補償階段用于解決消息Commit或者Rollback發(fā)生超時或者失敗的情況。
延遲消息
rocketmq在實現延遲消息時,默認18個延遲級別,這些級別對應的延遲時間如下:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1s | 5s | 10s | 30s | 1m | 2m | 3m | 4m | 5m | 6m | 7m | 8m | 9m | 10m | 20m | 30m | 1h | 2h |
發(fā)消息時,設置delayLevel等級即可:msg.setDelayLevel(level)。level有以下三種情況:
level == 0,消息為非延遲消息 1<=level<=maxLevel,消息延遲特定時間,例如level==1,延遲1s level > maxLevel,則level== maxLevel,例如level==20,延遲2h
定時消息會暫存在名為SCHEDULE_TOPIC_XXXX的topic中,并根據delayTimeLevel存入特定的queue,queueId = delayTimeLevel – 1,即一個queue只存相同延遲的消息,保證具有相同發(fā)送延遲的消息能夠順序消費。broker會調度地消費SCHEDULE_TOPIC_XXXX,將消息寫入真實的topic。
消息過濾
RocketMQ分布式消息隊列的消息過濾方式有別于其它MQ中間件,是在Consumer端訂閱消息時再做消息過濾的。RocketMQ這么做是在于其Producer端寫入消息和Consumer端訂閱消息采用分離存儲的機制來實現的,Consumer端訂閱消息是需要通過ConsumeQueue這個消息消費的邏輯隊列拿到一個索引,然后再從CommitLog里面讀取真正的消息實體內容,所以說到底也是還繞不開其存儲結構。其ConsumeQueue的存儲結構如下,可以看到其中有8個字節(jié)存儲的Message Tag的哈希值,基于Tag的消息過濾正式基于這個字段值的。

主要支持如下2種的過濾方式
Tag過濾方式:Consumer端在訂閱消息時除了指定Topic還可以指定TAG,如果一個消息有多個TAG,可以用||分隔。其中,Consumer端會將這個訂閱請求構建成一個 SubscriptionData,發(fā)送一個Pull消息的請求給Broker端。Broker端從RocketMQ的文件存儲層—Store讀取數據之前,會用這些數據先構建一個MessageFilter,然后傳給Store。Store從 ConsumeQueue讀取到一條記錄后,會用它記錄的消息tag hash值去做過濾,由于在服務端只是根據hashcode進行判斷,無法精確對tag原始字符串進行過濾,故在消息消費端拉取到消息后,還需要對消息的原始tag字符串進行比對,如果不同,則丟棄該消息,不進行消息消費。
SQL92的過濾方式:這種方式的大致做法和上面的Tag過濾方式一樣,只是在Store層的具體過濾過程不太一樣,真正的 SQL expression 的構建和執(zhí)行由rocketmq-filter模塊負責的。每次過濾都去執(zhí)行SQL表達式會影響效率,所以RocketMQ使用了BloomFilter避免了每次都去執(zhí)行。SQL92的表達式上下文為消息的屬性。
參考:
https://github.com/apache/rocketmq/blob/master/docs/cn/design.md。 https://github.com/apache/rocketmq/blob/rocketmq-all-4.8.0-LEARN/docs/cn/design.md
限于作者個人水平,文中難免有錯誤之處,歡迎指正!原創(chuàng)不易,商業(yè)轉載請聯(lián)系作者獲得授權,非商業(yè)轉載請注明出處。
本文首發(fā)于微信公眾號 「Java技術探秘」,如果您喜歡本文,歡迎關注該公眾號,讓我們一起在技術的世界里探秘吧!