
Redis、Kafka 和 Pulsar 消息隊(duì)列對比
點(diǎn)擊上方 藍(lán)字 關(guān)注我們!

每天 11 點(diǎn)更新文章,餓了點(diǎn)外賣,點(diǎn)擊 ??《無門檻外賣優(yōu)惠券,每天免費(fèi)領(lǐng)!》

來源:劉德恩
騰訊IEG研發(fā)工程師。
一、最基礎(chǔ)的隊(duì)列 二、Redis的隊(duì)列 三、Kafka 1. Kafka中的數(shù)據(jù)查找 2. Kafka高可用 3. 優(yōu)缺點(diǎn) 四、Pulsar 消費(fèi)模型 五、存算分離架構(gòu)
導(dǎo)讀
市面上有非常多的消息中間件,rabbitMQ、kafka、rocketMQ、pulsar、 redis等等,多得令人眼花繚亂。它們到底有什么異同,你應(yīng)該選哪個?本文嘗試通過技術(shù)演進(jìn)的方式,以redis、kafka和 pulsar為例,逐步深入,講講它們架構(gòu)和原理,幫助你更好地理解和學(xué)習(xí)消息隊(duì)列。
一、最基礎(chǔ)的隊(duì)列
最基礎(chǔ)的消息隊(duì)列其實(shí)就是一個雙端隊(duì)列,我們可以用雙向鏈表來實(shí)現(xiàn),如下圖所示:

push_front:添加元素到隊(duì)首; pop_tail:從隊(duì)尾取出元素。
有了這樣的數(shù)據(jù)結(jié)構(gòu)之后,我們就可以在內(nèi)存中構(gòu)建一個消息隊(duì)列,一些任務(wù)不停地往隊(duì)列里添加消息,同時另一些任務(wù)不斷地從隊(duì)尾有序地取出這些消息。添加消息的任務(wù)我們稱為producer,而取出并使用消息的任務(wù),我們稱之為consumer。
要實(shí)現(xiàn)這樣的內(nèi)存消息隊(duì)列并不難,甚至可以說很容易。但是如果要讓它能在應(yīng)對海量的并發(fā)讀寫時保持高效,還是需要下很多功夫的。
二、Redis的隊(duì)列
redis剛好提供了上述的數(shù)據(jù)結(jié)構(gòu)——list。redis list支持:
lpush:從隊(duì)列左邊插入數(shù)據(jù); rpop:從隊(duì)列右邊取出數(shù)據(jù)。
這正好對應(yīng)了我們隊(duì)列抽象的push_front和pop_tail,因此我們可以直接把redis的list當(dāng)成一個消息隊(duì)列來使用。而且redis本身對高并發(fā)做了很好的優(yōu)化,內(nèi)部數(shù)據(jù)結(jié)構(gòu)經(jīng)過了精心地設(shè)計和優(yōu)化。所以從某種意義上講,用redis的list大概率比你自己重新實(shí)現(xiàn)一個list強(qiáng)很多。
但另一方面,使用redis list作為消息隊(duì)列也有一些不足,比如:
消息持久化 :redis是內(nèi)存數(shù)據(jù)庫,雖然有aof和rdb兩種機(jī)制進(jìn)行持久化,但這只是輔助手段,這兩種手段都是不可靠的。當(dāng)redis服務(wù)器宕機(jī)時一定會丟失一部分?jǐn)?shù)據(jù),這對于很多業(yè)務(wù)都是沒法接受的。 熱key性能問題 :不論是用codis還是twemproxy這種集群方案,對某個隊(duì)列的讀寫請求最終都會落到同一臺redis實(shí)例上,并且無法通過擴(kuò)容來解決問題。如果對某個list的并發(fā)讀寫非常高,就產(chǎn)生了無法解決的熱key,嚴(yán)重可能導(dǎo)致系統(tǒng)崩潰。 沒有確認(rèn)機(jī)制 :每當(dāng)執(zhí)行rpop消費(fèi)一條數(shù)據(jù),那條消息就被從list中永久刪除了。如果消費(fèi)者消費(fèi)失敗,這條消息也沒法找回了。你可能說消費(fèi)者可以在失敗時把這條消息重新投遞到進(jìn)隊(duì)列,但這太理想了,極端一點(diǎn)萬一消費(fèi)者進(jìn)程直接崩了呢,比如被kill -9,panic,coredump… 不支持多訂閱者 :一條消息只能被一個消費(fèi)者消費(fèi),rpop之后就沒了。如果隊(duì)列中存儲的是應(yīng)用的日志,對于同一條消息,監(jiān)控系統(tǒng)需要消費(fèi)它來進(jìn)行可能的報警,BI系統(tǒng)需要消費(fèi)它來繪制報表,鏈路追蹤需要消費(fèi)它來繪制調(diào)用關(guān)系……這種場景redis list就沒辦法支持了。 不支持二次消費(fèi) :一條消息rpop之后就沒了。如果消費(fèi)者程序運(yùn)行到一半發(fā)現(xiàn)代碼有bug,修復(fù)之后想從頭再消費(fèi)一次就不行了。
對于上述的不足,目前看來第一條(持久化)是可以解決的。很多公司都有團(tuán)隊(duì)基于rocksdb leveldb進(jìn)行二次開發(fā),實(shí)現(xiàn)了支持redis協(xié)議的kv存儲。這些存儲已經(jīng)不是redis了,但是用起來和redis幾乎一樣。它們能夠保證數(shù)據(jù)的持久化,但對于上述的其他缺陷也無能為力了。
其實(shí)redis 5.0開始新增了一個stream數(shù)據(jù)類型,它是專門設(shè)計成為消息隊(duì)列的數(shù)據(jù)結(jié)構(gòu),借鑒了很多kafka的設(shè)計,但是依然還有很多問題…直接進(jìn)入到kafka的世界它不香嗎?
三、Kafka
從上面你可以看到,一個真正的消息中間件不僅僅是一個隊(duì)列那么簡單。尤其是當(dāng)它承載了公司大量業(yè)務(wù)的時候,它的功能完備性、吞吐量、穩(wěn)定性、擴(kuò)展性都有非常苛刻的要求。kafka應(yīng)運(yùn)而生,它是專門設(shè)計用來做消息中間件的系統(tǒng)。
前面說redis list的不足時,雖然有很多不足,但是如果你仔細(xì)思考,其實(shí)可以歸納為兩點(diǎn):
熱key的問題無法解決 ,即:無法通過加機(jī)器解決性能問題; 數(shù)據(jù)會被刪除 :rpop之后就沒了,因此無法滿足多個訂閱者,無法重新從頭再消費(fèi),無法做ack。
這兩點(diǎn)也是kafka要解決的核心問題。
熱key的本質(zhì)問題是數(shù)據(jù)都集中在一臺實(shí)例上,所以想辦法把它分散到多個機(jī)器上就好了。為此,kafka提出了partition 的概念。一個隊(duì)列(redis中的list),對應(yīng)到kafka里叫topic。kafka把一個topic拆成了多個partition,每個partition可以分散到不同的機(jī)器上,這樣就可以把單機(jī)的壓力分散到多臺機(jī)器上。因此topic在kafka中更多是一個邏輯上的概念,實(shí)際存儲單元都是partition。
其實(shí)redis的list也能實(shí)現(xiàn)這種效果,不過這需要在業(yè)務(wù)代碼中增加額外的邏輯。比如可以建立n個list,key1, key2, ..., keyn,客戶端每次往不同的key里push,消費(fèi)端也可以同時從key1到keyn這n個list中rpop消費(fèi)數(shù)據(jù),這就能達(dá)到kafka多partition的效果。所以你可以看到,partition就是一個非常樸素的概念,用來把請求分散到多臺機(jī)器。
redis list中另一個大問題是rpop會刪除數(shù)據(jù),所以kafka的解決辦法也很簡單,不刪就行了嘛。kafka用游標(biāo)(cursor)解決這個問題。
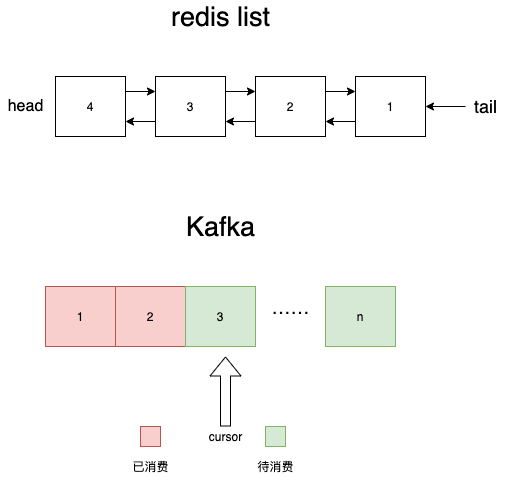
和redis list不同的是,首先kafka的topic(實(shí)際上是partion)是用的單向隊(duì)列來存儲數(shù)據(jù)的,新數(shù)據(jù)每次直接追加到隊(duì)尾。同時它維護(hù)了一個游標(biāo)cursor,從頭開始,每次指向即將被消費(fèi)的數(shù)據(jù)的下標(biāo)。每消費(fèi)一條,cursor+1 。通過這種方式,kafka也能和redis list一樣實(shí)現(xiàn)先入先出的語義,但是kafka每次只需要更新游標(biāo),并不會去刪數(shù)據(jù)。
這樣設(shè)計的好處太多了,尤其是性能方面,順序?qū)懸恢笔亲畲蠡么疟P帶寬的不二法門。但我們主要講講游標(biāo)這種設(shè)計帶來功能上的優(yōu)勢。
首先可以支持消息的ACK機(jī)制了。由于消息不會被刪除,因此可以等消費(fèi)者明確告知kafka這條消息消費(fèi)成功以后,再去更新游標(biāo)。這樣的話,只要kafka持久化存儲了游標(biāo)的位置,即使消費(fèi)失敗進(jìn)程崩潰,等它恢復(fù)時依然可以重新消費(fèi)
第二是可以支持分組消費(fèi):
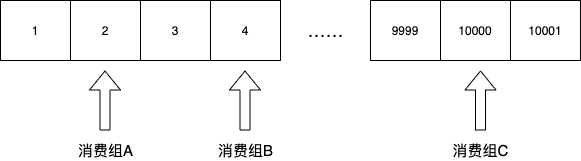
這里需要引入一個消費(fèi)組的概念,這個概念非常簡單,因?yàn)橄M(fèi)組本質(zhì)上就是一組游標(biāo)。對于同一個topic,不同的消費(fèi)組有各自的游標(biāo)。監(jiān)控組的游標(biāo)指向第二條,BI組的游標(biāo)指向第4條,trace組指向到了第10000條……各消費(fèi)者游標(biāo)彼此隔離,互不影響。
通過引入消費(fèi)組的概念,就可以非常容易地支持多業(yè)務(wù)方同時消費(fèi)一個topic,也就是說所謂的1-N的“廣播”,一條消息廣播給N個訂閱方。
最后,通過游標(biāo)也很容易實(shí)現(xiàn)重新消費(fèi)。因?yàn)橛螛?biāo)僅僅就是記錄當(dāng)前消費(fèi)到哪一條數(shù)據(jù)了,要重新消費(fèi)的話直接修改游標(biāo)的值就可以了。你可以把游標(biāo)重置為任何你想要指定的位置,比如重置到0重新開始消費(fèi),也可以直接重置到最后,相當(dāng)于忽略現(xiàn)有所有數(shù)據(jù)。
因此你可以看到,kafka這種數(shù)據(jù)結(jié)構(gòu)相比于redis的雙向鏈表有了一個質(zhì)的飛躍,不僅是性能上,同時也是功能上,全面的領(lǐng)先。
我們可以來看看kafka的一個簡單的架構(gòu)圖:
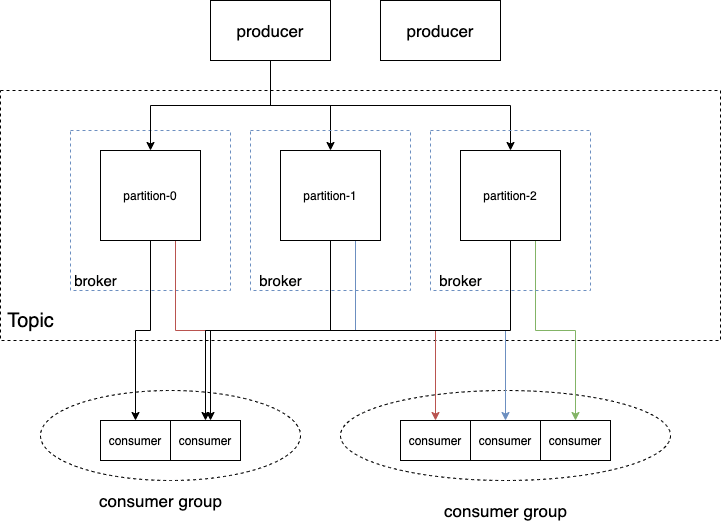
從這個圖里我們可以看出,topic是一個邏輯上的概念,不是一個實(shí)體。一個topic包含多個partition,partition分布在多臺機(jī)器上。這個機(jī)器,kafka中稱之為broker 。(kafka集群中的一個broker對應(yīng)redis集群中的一個實(shí)例)。對于一個topic,可以有多個不同的消費(fèi)組同時進(jìn)行消費(fèi)。一個消費(fèi)組內(nèi)部可以有多個消費(fèi)者實(shí)例同時進(jìn)行消費(fèi),這樣可以提高消費(fèi)速率。
但是這里需要非常注意的是,一個partition只能被消費(fèi)組中的一個消費(fèi)者實(shí)例來消費(fèi)。換句話說,消費(fèi)組中如果有多個消費(fèi)者,不能夠存在兩個消費(fèi)者同時消費(fèi)一個partition的場景。
為什么呢?其實(shí)kafka要在partition級別提供順序消費(fèi)的語義,如果多個consumer消費(fèi)一個partition,即使kafka本身是按順序分發(fā)數(shù)據(jù)的,但是由于網(wǎng)絡(luò)延遲等各種情況,consumer并不能保證按kafka的分發(fā)順序接收到數(shù)據(jù),這樣達(dá)到消費(fèi)者的消息順序就是無法保證的。因此一個partition只能被一個consumer消費(fèi)。kafka各consumer group的游標(biāo)可以表示成類似這樣的數(shù)據(jù)結(jié)構(gòu):
{
"topic-foo": {
"groupA": {
"partition-0": 0,
"partition-1": 123,
"partition-2": 78
},
"groupB": {
"partition-0": 85,
"partition-1": 9991,
"partition-2": 772
},
}
}
了解了kafka的宏觀架構(gòu),你可能會有個疑惑,kafka的消費(fèi)如果只是移動游標(biāo)并不刪除數(shù)據(jù),那么隨著時間的推移數(shù)據(jù)肯定會把磁盤打滿,這個問題該如何解決呢?這就涉及到kafka的retention機(jī)制,也就是消息過期,類似于redis中的expire。
不同的是,redis是按key來過期的,如果你給redis list設(shè)置了1分鐘有效期,1分鐘之后redis直接把整個list刪除了。而kafka的過期是針對消息的,不會刪除整個topic(partition),只會刪除partition中過期的消息。不過好在kafka的partition是單向的隊(duì)列,因此隊(duì)列中消息的生產(chǎn)時間都是有序的。因此每次過期刪除消息時,從頭開始刪就行了。
看起來似乎很簡單,但仔細(xì)想一下還是有不少問題。舉例來說,假如topicA-partition-0的所有消息被寫入到一個文件中,比如就叫topicA-partition-0.log。我們再把問題簡化一下,假如生產(chǎn)者生產(chǎn)的消息在topicA-partition-0.log中一條消息占一行,很快這個文件就到200G了。現(xiàn)在告訴你,這個文件前x行失效了,你應(yīng)該怎么刪除呢?非常難辦,這和讓你刪除一個數(shù)組中的前n個元素一樣,需要把后續(xù)的元素向前移動,這涉及到大量的CPU copy操作。假如這個文件有10M,這個刪除操作的代價都非常大,更別說200G了。
因此,kafka在實(shí)際存儲partition時又進(jìn)行了一個拆分。topicA-partition-0的數(shù)據(jù)并不是寫到一個文件里,而是寫到多個segment文件里。假如設(shè)置的一個segment文件大小上限是100M,當(dāng)寫滿100M時就會創(chuàng)建新的segment文件,后續(xù)的消息就寫到新創(chuàng)建的segment文件,就像我們業(yè)務(wù)系統(tǒng)的日志文件切割一樣。這樣做的好處是,當(dāng)segment中所有消息都過期時,可以很容易地直接刪除整個文件。而由于segment中消息是有序的,看是否都過期就看最后一條是否過期就行了。
1. Kafka中的數(shù)據(jù)查找
topic的一個partition是一個邏輯上的數(shù)組,由多個segment組成,如下圖所示:
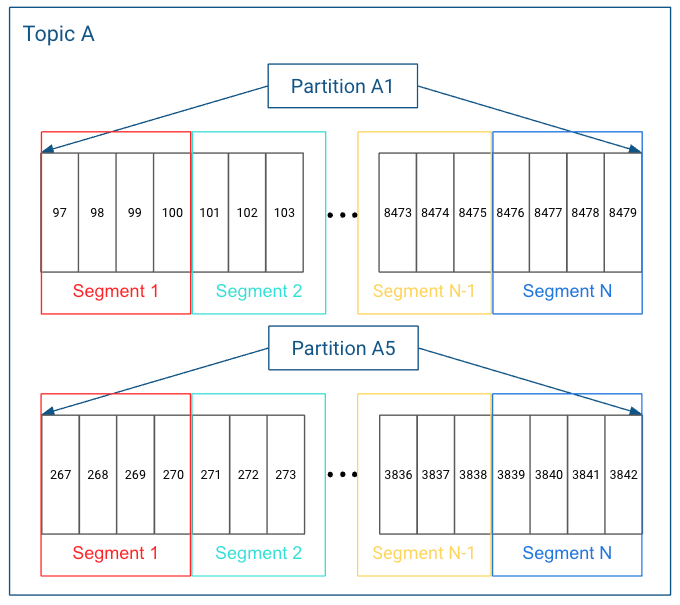
這時候就有一個問題,如果我把游標(biāo)重置到一個任意位置,比如第2897條消息,我怎么讀取數(shù)據(jù)呢?
根據(jù)上面的文件組織結(jié)構(gòu),你可以發(fā)現(xiàn)我們需要確定兩件事才能讀出對應(yīng)的數(shù)據(jù):
第2897條消息在哪個segment文件里; 第2897條消息在segment文件里的什么位置。
為了解決上面兩個問題,kafka有一個非常巧妙的設(shè)計。首先,segment文件的文件名是以該文件里第一條消息的offset來命名的。一開始的segment文件名是 0.log,然后一直寫直到寫了18234條消息后,發(fā)現(xiàn)達(dá)到了設(shè)置的文件大小上限100M,然后就創(chuàng)建一個新的segment文件,名字是18234.log……
- /kafka/topic/order_create/partition-0
- 0.log
- 18234.log #segment file
- 39712.log
- 54101.log
當(dāng)我們要找offset為x的消息在哪個segment時,只需要通過文件名做一次二分查找就行了。比如offset為2879的消息(第2880條消息),顯然就在0.log這個segment文件里。
定位到segment文件之后,另一個問題就是要找到該消息在文件中的位置,也就是偏移量。如果從頭開始一條條地找,這個耗時肯定是無法接受的!kafka的解決辦法就是索引文件。
就如mysql的索引一樣,kafka為每個segment文件創(chuàng)建了一個對應(yīng)的索引文件。索引文件很簡單,每條記錄就是一個kv組,key是消息的offset,value是該消息在segment文件中的偏移量:
| offset | position |
|---|---|
| 0 | 0 |
| 1 | 124 |
| 2 | 336 |
每個segment文件對應(yīng)一個索引文件:
- /kafka/topic/order_create/partition-0
- 0.log
- 0.index
- 18234.log #segment file
- 18234.index #index file
- 39712.log
- 39712.index
- 54101.log
- 54101.index
有了索引文件,我們就可以拿到某條消息具體的位置,從而直接進(jìn)行讀取。再捋一遍這個流程:
當(dāng)要查詢offset為x的消息 利用二分查找找到這條消息在y.log 讀取y.index文件找到消息x的y.log中的位置 讀取y.log的對應(yīng)位置,獲取數(shù)據(jù)
通過這種文件組織形式,我們可以在kafka中非常快速地讀取出任何一條消息。但這又引出了另一個問題,如果消息量特別大,每條消息都在index文件中加一條記錄,這將浪費(fèi)很多空間。
可以簡單地計算一下,假如index中一條記錄16個字節(jié)(offset 8 + position 8),一億條消息就是16*10^8字節(jié)=1.6G。對于一個稍微大一點(diǎn)的公司,kafka用來收集日志的話,一天的量遠(yuǎn)遠(yuǎn)不止1億條,可能是數(shù)十倍上百倍。這樣的話,index文件就會占用大量的存儲。因此,權(quán)衡之下kafka選擇了使用”稀疏索引 “。
所謂稀疏索引就是并非所有消息都會在index文件中記錄它的position,每間隔多少條消息記錄一條,比如每間隔10條消息記錄一條offset-position:
| offset | position |
|---|---|
| 0 | 0 |
| 10 | 1852 |
| 20 | 4518 |
| 30 | 6006 |
| 40 | 8756 |
| 50 | 10844 |
這樣的話,如果當(dāng)要查詢offset為x的消息,我們可能沒辦法查到它的精確位置,但是可以利用二分查找,快速地確定離他最近的那條消息的位置,然后往后多讀幾條數(shù)據(jù)就可以讀到我們想要的消息了。
比如,當(dāng)我們要查到offset為33的消息,按照上表,我們可以利用二分查找定位到offset為30的消息所在的位置,然后去對應(yīng)的log文件中從該位置開始向后讀取3條消息,第四條就是我們要找的33。這種方式其實(shí)就是在性能和存儲空間上的一個折中,很多系統(tǒng)設(shè)計時都會面臨類似的選擇,犧牲時間換空間還是犧牲空間換時間。
到這里,我們對kafka的整體架構(gòu)應(yīng)該有了一個比較清晰的認(rèn)識了。不過在上面的分析中,我故意隱去了kafka中另一個非常非常重要的點(diǎn),就是高可用方面的設(shè)計。因?yàn)檫@部分內(nèi)容比較晦澀,會引入很多分布式理論的復(fù)雜性,妨礙我們理解kafka的基本模型。在接下來的部分,將著重討論這個主題。
2. Kafka高可用
高可用(HA)對于企業(yè)的核心系統(tǒng)來說是至關(guān)重要的。因?yàn)殡S著業(yè)務(wù)的發(fā)展,集群規(guī)模會不斷增大,而大規(guī)模集群中總會出現(xiàn)故障,硬件、網(wǎng)絡(luò)都是不穩(wěn)定的。當(dāng)系統(tǒng)中某些節(jié)點(diǎn)各種原因無法正常使用時,整個系統(tǒng)可以容忍這個故障,繼續(xù)正常對外提供服務(wù),這就是所謂的高可用性。對于有狀態(tài)服務(wù)來說,容忍局部故障本質(zhì)上就是容忍丟數(shù)據(jù)(不一定是永久,但是至少一段時間內(nèi)讀不到數(shù)據(jù))。
系統(tǒng)要容忍丟數(shù)據(jù),最樸素也是唯一的辦法就是做備份,讓同一份數(shù)據(jù)復(fù)制到多臺機(jī)器,所謂的冗余 ,或者說多副本 。為此,kafka引入 leader-follower的概念。topic的每個partition都有一個leader,所有對這個partition的讀寫都在該partition leader所在的broker上進(jìn)行。partition的數(shù)據(jù)會被復(fù)制到其它broker上,這些broker上對應(yīng)的partition就是follower:
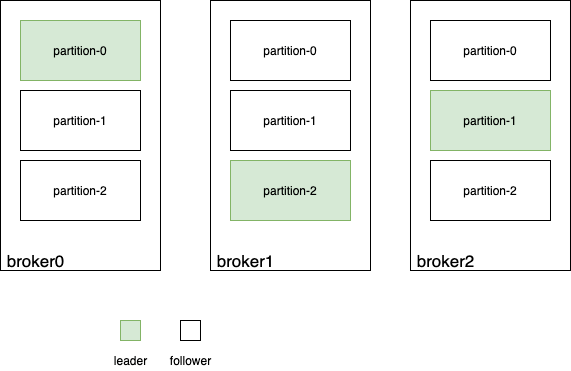
producer在生產(chǎn)消息時,會直接把消息發(fā)送到partition leader上,partition leader把消息寫入自己的log中,然后等待follower來拉取數(shù)據(jù)進(jìn)行同步。具體交互如下:
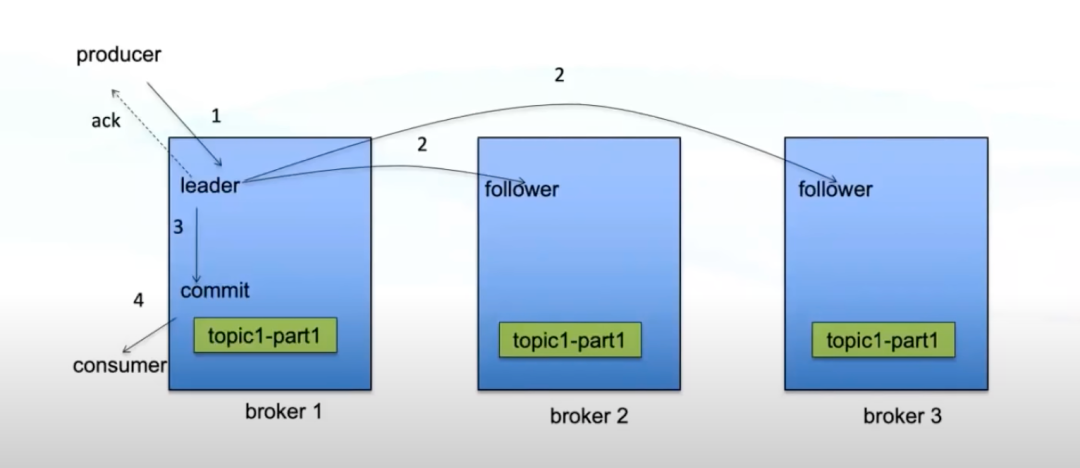
上圖中對producer進(jìn)行ack的時機(jī)非常關(guān)鍵,這直接關(guān)系到kafka集群的可用性和可靠性。
如果producer的數(shù)據(jù)到達(dá)leader并成功寫入leader的log就進(jìn)行ack
優(yōu)點(diǎn) :不用等數(shù)據(jù)同步完成,速度快,吞吐率高,可用性高;
缺點(diǎn) :如果follower數(shù)據(jù)同步未完成時leader掛了,就會造成數(shù)據(jù)丟失,可靠性低。
如果等follower都同步完數(shù)據(jù)時進(jìn)行ack
優(yōu)點(diǎn) :當(dāng)leader掛了之后follower中也有完備的數(shù)據(jù),可靠性高;
缺點(diǎn) :等所有follower同步完成很慢,性能差,容易造成生產(chǎn)方超時,可用性低。
而具體什么時候進(jìn)行ack,對于kafka來說是可以根據(jù)實(shí)際應(yīng)用場景配置的。
其實(shí)kafka真正的數(shù)據(jù)同步過程還是非常復(fù)雜的,本文主要是想講一講kafka的一些核心原理,數(shù)據(jù)同步里面涉及到的很多技術(shù)細(xì)節(jié),HW epoch等,就不在此一一展開了。最后展示一下kafka的一個全景圖:
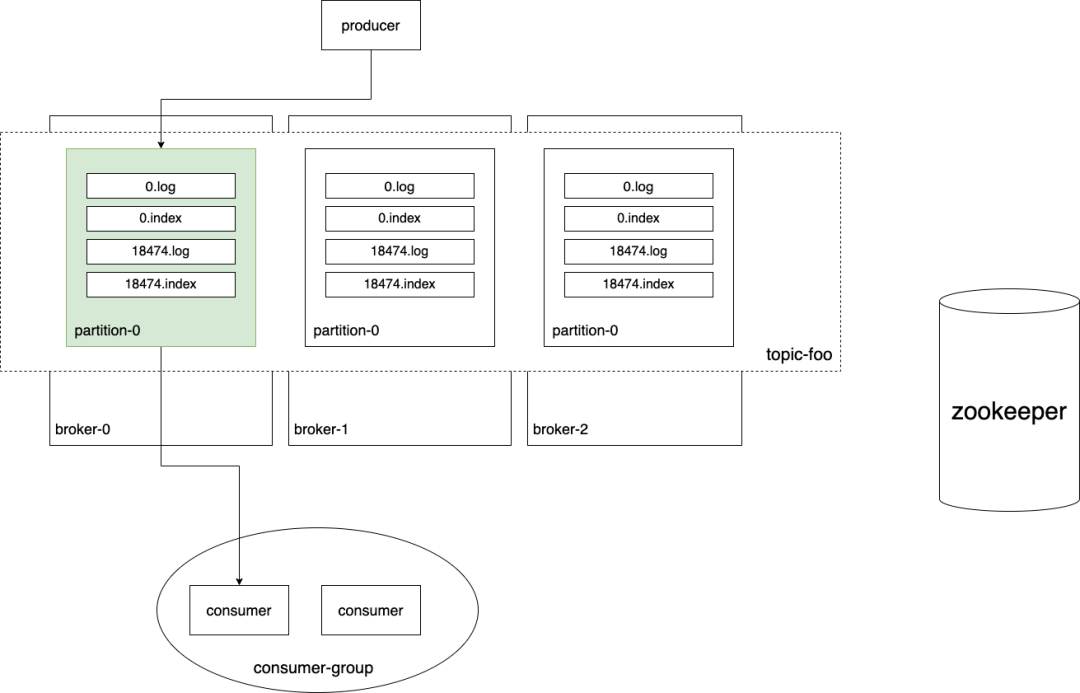
最后對kafka進(jìn)行一個簡要地總結(jié):kafka通過引入partition的概念,讓topic能夠分散到多臺broker上,提高吞吐率。但是引入多partition的代價就是無法保證topic維度的全局順序性,需要這種特性的場景只能使用單個partition。在內(nèi)部,每個partition以多個segment文件的方式進(jìn)行存儲,新來的消息append到最新的segment log文件中,并使用稀疏索引記錄消息在log文件中的位置,方便快速讀取消息。當(dāng)數(shù)據(jù)過期時,直接刪除過期的segment文件即可。為了實(shí)現(xiàn)高可用,每個partition都有多個副本,其中一個是leader,其它是follower,分布在不同的broker上。對partition的讀寫都在leader所在的broker上完成,follower只會定時地拉取leader的數(shù)據(jù)進(jìn)行同步。當(dāng)leader掛了,系統(tǒng)會選出和leader保持同步的follower作為新的leader,繼續(xù)對外提供服務(wù),大大提高可用性。在消費(fèi)端,kafka引入了消費(fèi)組的概念,每個消費(fèi)組都可以互相獨(dú)立地消費(fèi)topic,但一個partition只能被消費(fèi)組中的唯一一個消費(fèi)者消費(fèi)。消費(fèi)組通過記錄游標(biāo),可以實(shí)現(xiàn)ACK機(jī)制、重復(fù)消費(fèi)等多種特性。除了真正的消息記錄在segment中,其它幾乎所有meta信息都保存在全局的zookeeper中。
3. 優(yōu)缺點(diǎn)
(1)優(yōu)點(diǎn):kafka的優(yōu)點(diǎn)非常多
高性能:單機(jī)測試能達(dá)到 100w tps; 低延時:生產(chǎn)和消費(fèi)的延時都很低,e2e的延時在正常的cluster中也很低; 可用性高:replicate + isr + 選舉 機(jī)制保證; 工具鏈成熟:監(jiān)控 運(yùn)維 管理 方案齊全; 生態(tài)成熟:大數(shù)據(jù)場景必不可少 kafka stream.
(2)不足
無法彈性擴(kuò)容:對partition的讀寫都在partition leader所在的broker,如果該broker壓力過大,也無法通過新增broker來解決問題; 擴(kuò)容成本高:集群中新增的broker只會處理新topic,如果要分擔(dān)老topic-partition的壓力,需要手動遷移partition,這時會占用大量集群帶寬; 消費(fèi)者新加入和退出會造成整個消費(fèi)組rebalance:導(dǎo)致數(shù)據(jù)重復(fù)消費(fèi),影響消費(fèi)速度,增加e2e延遲; partition過多會使得性能顯著下降:ZK壓力大,broker上partition過多讓磁盤順序?qū)憥缀跬嘶呻S機(jī)寫。
在了解了kafka的架構(gòu)之后,你可以仔細(xì)想一想,為什么kafka擴(kuò)容這么費(fèi)勁呢?其實(shí)這本質(zhì)上和redis集群擴(kuò)容是一樣的!當(dāng)redis集群出現(xiàn)熱key時,某個實(shí)例扛不住了,你通過加機(jī)器并不能解決什么問題,因?yàn)槟莻€熱key還是在之前的某個實(shí)例中,新擴(kuò)容的實(shí)例起不到分流的作用。kafka類似,它擴(kuò)容有兩種:新加機(jī)器(加broker)以及給topic增加partition。給topic新加partition這個操作,你可以聯(lián)想一下mysql的分表。比如用戶訂單表,由于量太大把它按用戶id拆分成1024個子表user_order_{0..1023},如果到后期發(fā)現(xiàn)還不夠用,要增加這個分表數(shù),就會比較麻煩。因?yàn)榉直砜倲?shù)增多,會讓user_id的hash值發(fā)生變化,從而導(dǎo)致老的數(shù)據(jù)無法查詢。所以只能停服做數(shù)據(jù)遷移,然后再重新上線。kafka給topic新增partition一樣的道理,比如在某些場景下msg包含key,那producer就要保證相同的key放到相同的partition。但是如果partition總量增加了,根據(jù)key去進(jìn)行hash,比如 hash(key) % parition_num,得到的結(jié)果就不同,就無法保證相同的key存到同一個partition。當(dāng)然也可以在producer上實(shí)現(xiàn)一個自定義的partitioner,保證不論怎么擴(kuò)partition相同的key都落到相同的partition上,但是這又會使得新增加的partition沒有任何數(shù)據(jù)。
其實(shí)你可以發(fā)現(xiàn)一個問題,kafka的核心復(fù)雜度幾乎都在存儲這一塊。數(shù)據(jù)如何分片,如何高效的存儲,如何高效地讀取,如何保證一致性,如何從錯誤中恢復(fù),如何擴(kuò)容再平衡……
上面這些不足總結(jié)起來就是一個詞:scalebility。通過直接加機(jī)器就能解決問題的系統(tǒng)才是大家的終極追求。Pulsar號稱云原生時代的分布式消息和流平臺,所以接下來我們看看pulsar是怎么樣的。
四、Pulsar
kafka的核心復(fù)雜度是它的存儲,高性能、高可用、低延遲、支持快速擴(kuò)容的分布式存儲不僅僅是kafka的需求,應(yīng)該是現(xiàn)代所有系統(tǒng)共同的追求。而apache項(xiàng)目底下剛好有一個專門就是為日志存儲打造的這樣的系統(tǒng),它叫bookeeper!
有了專門的存儲組件,那么實(shí)現(xiàn)一個消息系統(tǒng)剩下的就是如何來使用這個存儲系統(tǒng)來實(shí)現(xiàn)feature了。pulsar就是這樣一個”計算-存儲 分離“的消息系統(tǒng):
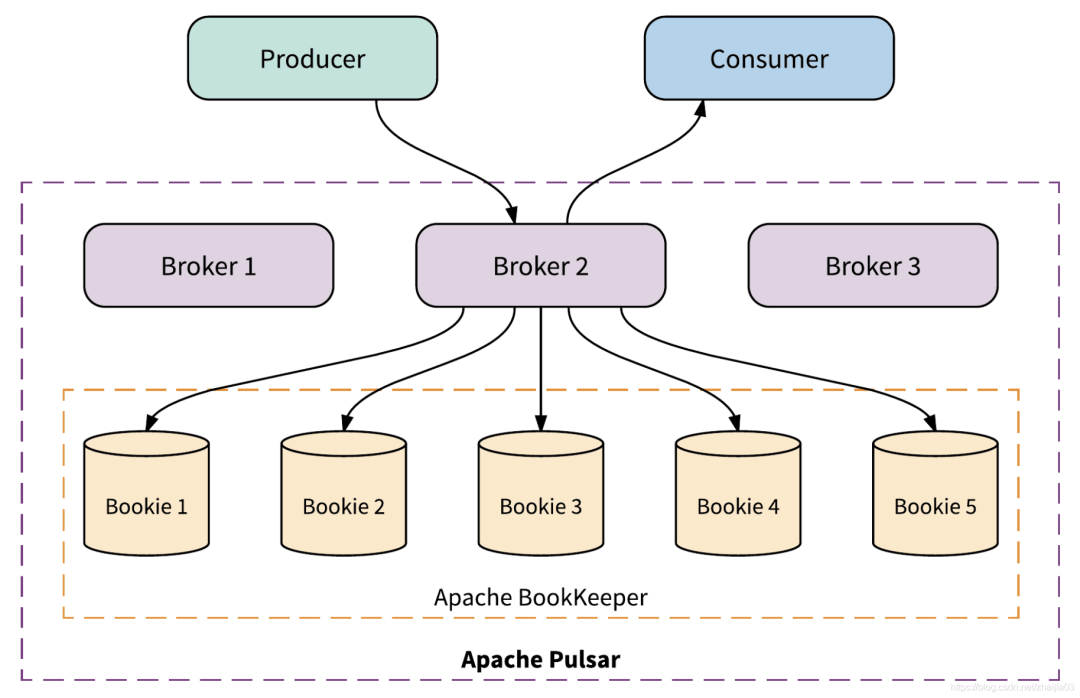
pulsar利用bookeeper作為存儲服務(wù),剩下的是計算層。這其實(shí)是目前非常流行的架構(gòu)也是一種趨勢,很多新型的存儲都是這種”存算分離“的架構(gòu)。比如tidb,底層存儲其實(shí)是tikv這種kv存儲。tidb是更上層的計算層,自己實(shí)現(xiàn)sql相關(guān)的功能。還有的例子就是很多"持久化"redis產(chǎn)品,大部分底層依賴于rocksdb做kv存儲,然后基于kv存儲關(guān)系實(shí)現(xiàn)redis的各種數(shù)據(jù)結(jié)構(gòu)。
在pulsar中,broker的含義和kafka中的broker是一致的,就是一個運(yùn)行的pulsar實(shí)例。但是和kafka不同的是,pulsar的broker是無狀態(tài)服務(wù),它只是一個”API接口層“,負(fù)責(zé)處理海量的用戶請求,當(dāng)用戶消息到來時負(fù)責(zé)調(diào)用bookeeper的接口寫數(shù)據(jù),當(dāng)用戶要查詢消息時從bookeeper中查數(shù)據(jù),當(dāng)然這個過程中broker本身也會做很多緩存之類的。同時broker也依賴于zookeeper來保存很多元數(shù)據(jù)的關(guān)系。
由于broker本身是無狀態(tài)的,因此這一層可以非常非常容易地進(jìn)行擴(kuò)容,尤其是在k8s環(huán)境下,點(diǎn)下鼠標(biāo)的事兒。至于消息的持久化,高可用,容錯,存儲的擴(kuò)容,這些都通通交給bookeeper來解決。
但就像能量守恒定律一樣,系統(tǒng)的復(fù)雜性也是守恒的。實(shí)現(xiàn)既高性能又可靠的存儲需要的技術(shù)復(fù)雜性,不會憑空消失,只會從一個地方轉(zhuǎn)移到另一個地方。就像你寫業(yè)務(wù)邏輯,產(chǎn)品經(jīng)理提出了20個不同的業(yè)務(wù)場景,就至少對應(yīng)20個if else,不論你用什么設(shè)計模式和架構(gòu),這些if else不會被消除,只會從從一個文件放到另一個文件,從一個對象放到另一個對象而已。所以那些復(fù)雜性一定會出現(xiàn)在bookeeper中,并且會比kafka的存儲實(shí)現(xiàn)更為復(fù)雜。
但是pulsar存算分離架構(gòu)的一個好處就是,當(dāng)我們在學(xué)習(xí)pulsar時可以有一個比較明確的界限,所謂的concern segregation。只要理解bookeeper對上層的broker提供的API語義,即使不了解bookeeper內(nèi)部的實(shí)現(xiàn),也能很好的理解pulsar的原理。
接下來你可以思考一個問題:既然pulsar的broker層是無狀態(tài)的服務(wù),那么我們是否可以隨意在某個broker進(jìn)行對某個topic的數(shù)據(jù)生產(chǎn)呢?
看起來似乎沒什么問題,但答案還是否定的——不可以。為什么呢?想一想,假如生產(chǎn)者可以在任意一臺broker上對topic進(jìn)行生產(chǎn),比如生產(chǎn)3條消息a b c,三條生產(chǎn)消息的請求分別發(fā)送到broker A B C,那最終怎么保證消息按照a b c的順序?qū)懭隻ookeeper呢?這是沒辦法保證,只有讓a b c三條消息都發(fā)送到同一臺broker,才能保證消息寫入的順序。
既然如此,那似乎又回到和kafka一樣的問題,如果某個topic寫入量特別特別大,一個broker扛不住怎么辦?所以pulsar和kafka一樣,也有partition的概念。一個topic可以分成多個partition,為了每個partition內(nèi)部消息的順序一致,對每個partition的生產(chǎn)必須對應(yīng)同一臺broker。
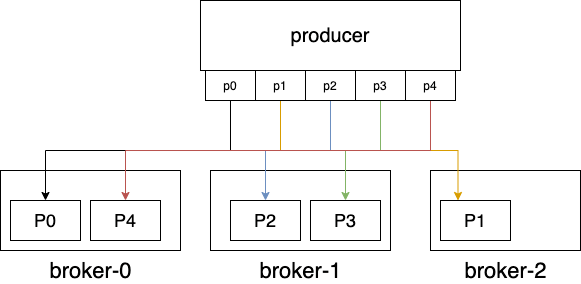
這里看起來似乎和kafka沒區(qū)別,也是每個partition對應(yīng)一個broker,但是其實(shí)差別很大。為了保證對partition的順序?qū)懭耄徽搆afka還是pulsar都要求寫入請求發(fā)送到partition對應(yīng)的broker上,由該broker來保證寫入的順序性。然而區(qū)別在于,kafka同時會把消息存儲到該broker上,而pulsar是存儲到bookeeper上。這樣的好處是,當(dāng)pulsar的某臺broker掛了,可以立刻把partition對應(yīng)的broker切換到另一個broker,只要保證全局只有一個broker對topic-partition-x有寫權(quán)限就行了,本質(zhì)上只是做一個所有權(quán)轉(zhuǎn)移而已,不會有任何數(shù)據(jù)的搬遷。
當(dāng)對partition的寫請求到達(dá)對應(yīng)broker時,broker就需要調(diào)用bookeeper提供的接口進(jìn)行消息存儲。和kafka一樣,pulsar在這里也有segment的概念,而且和kafka一樣的是,pulsar也是以segment為單位進(jìn)行存儲的(respect respect respect)。
為了說清楚這里,就不得不引入一個bookeeper的概念,叫l(wèi)edger,也就是賬本。可以把ledger類比為文件系統(tǒng)上的一個文件,比如在kafka中就是寫入到xxx.log這個文件里。pulsar以segment為單位,存入bookeeper中的ledger。
在bookeeper集群中每個節(jié)點(diǎn)叫bookie(為什么集群的實(shí)例在kafka叫broker在bookeeper又叫bookie……無所謂,名字而已,作者寫了那么多代碼,還不能讓人開心地命個名啊)。在實(shí)例化一個bookeeper的writer時,就需要提供3個參數(shù):
節(jié)點(diǎn)數(shù)n:bookeeper集群的bookie數(shù); 副本數(shù)m:某一個ledger會寫入到n個bookie中的m個里,也就是說所謂的m副本; 確認(rèn)寫入數(shù)t:每次向ledger寫入數(shù)據(jù)時(并發(fā)寫入到m個bookie),需要確保收到t個acks,才返回成功。
bookeeper會根據(jù)這三個參數(shù)來為我們做復(fù)雜的數(shù)據(jù)同步,所以我們不用擔(dān)心那些副本啊一致性啊的東西,直接調(diào)bookeeper的提供的append接口就行了,剩下的交給它來完成。
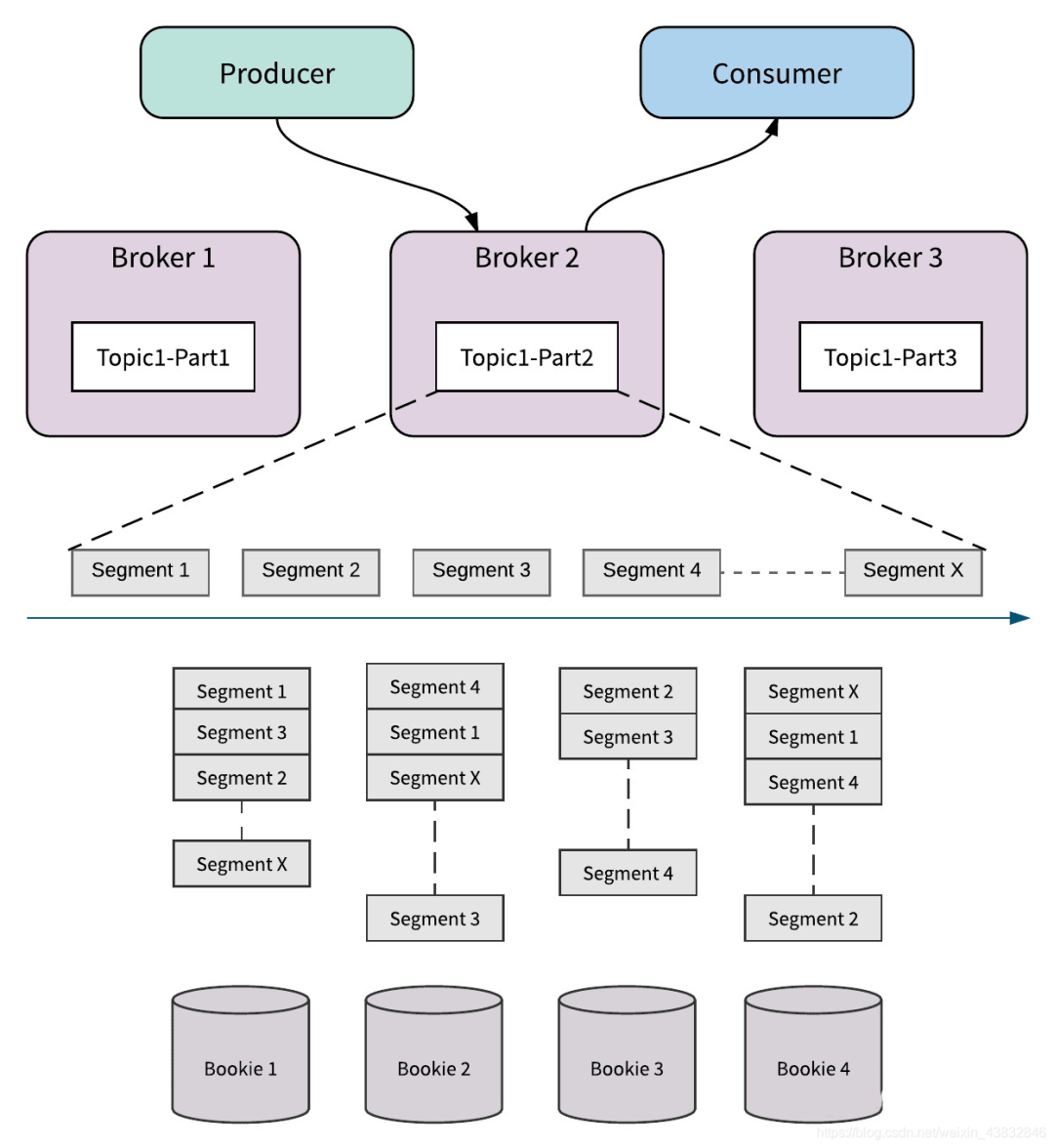
如上圖所示,parition被分為了多個segment,每個segment會寫入到4個bookie其中的3個中。比如segment1就寫入到了bookie1,2,4中,segment2寫入到bookie1,3,4中…
這其實(shí)就相當(dāng)于把kafka某個partition的segment均勻分布到了多臺存儲節(jié)點(diǎn)上。這樣的好處是什么呢?在kafka中某個partition是一直往同一個broker的文件系統(tǒng)中進(jìn)行寫入,當(dāng)磁盤不夠用了,就需要做非常麻煩的擴(kuò)容+遷移數(shù)據(jù)的操作。而對于pulsar,由于partition中不同segment可以保存在bookeeper不同的bookies上,當(dāng)大量寫入導(dǎo)致現(xiàn)有集群bookie磁盤不夠用時,我們可以快速地添加機(jī)器解決問題,讓新的segment尋找最合適的bookie(磁盤空間剩余最多或者負(fù)載最低等)進(jìn)行寫入,只要記住segment和bookies的關(guān)系就好了。
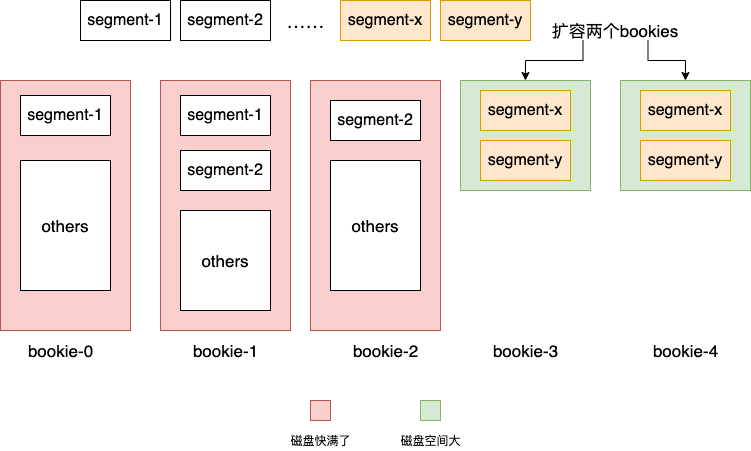
由于partition以segment為粒度均勻的分散到bookeeper上的節(jié)點(diǎn)上,這使得存儲的擴(kuò)容變得非常非常容易。這也是Pulsar一直宣稱的存算分離架構(gòu)的先進(jìn)性的體現(xiàn):
broker是無狀態(tài)的,隨便擴(kuò)容; partition以segment為單位分散到整個bookeeper集群,沒有單點(diǎn),也可以輕易地擴(kuò)容; 當(dāng)某個bookie發(fā)生故障,由于多副本的存在,可以另外t-1個副本中隨意選出一個來讀取數(shù)據(jù),不間斷地對外提供服務(wù),實(shí)現(xiàn)高可用。
其實(shí)在理解kafka的架構(gòu)之后再來看pulsar,你會發(fā)現(xiàn)pulsar的核心就在于bookeeper的使用以及一些metadata的存儲。但是換個角度,正是這個恰當(dāng)?shù)拇鎯陀嬎惴蛛x的架構(gòu),幫助我們分離了關(guān)注點(diǎn),從而能夠快速地去學(xué)習(xí)上手。
消費(fèi)模型
Pulsar相比于kafka另一個比較先進(jìn)的設(shè)計就是對消費(fèi)模型的抽象,叫做subscription。通過這層抽象,可以支持用戶各種各樣的消費(fèi)場景。還是和kafka進(jìn)行對比,kafka中只有一種消費(fèi)模式,即一個或多個partition對一個consumer。如果想要讓一個partition對多個consumer,就無法實(shí)現(xiàn)了。pulsar通過subscription,目前支持4種消費(fèi)方式:
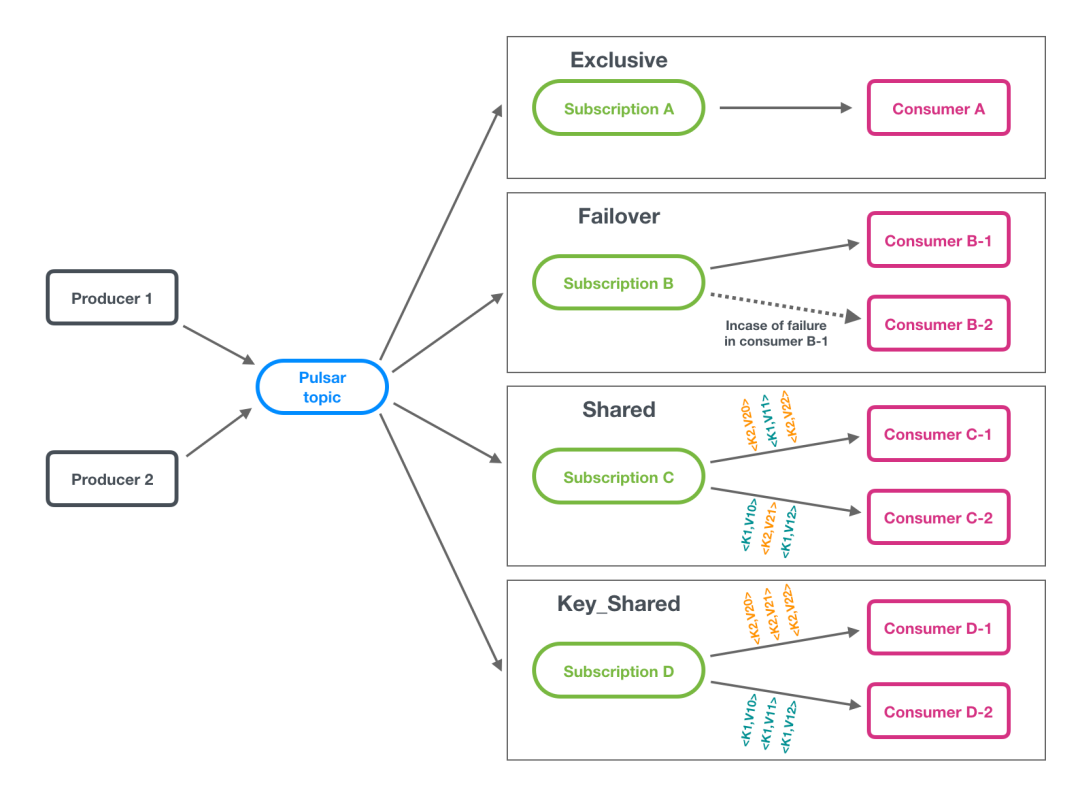
可以把pulsar的subscription看成kafka的consumer group,但subscription更進(jìn)一步,可以設(shè)置這個”consumer group“的消費(fèi)類型:
exclusive:消費(fèi)組里有且僅有一個consumer能夠進(jìn)行消費(fèi),其它的根本連不上pulsar; failover:消費(fèi)組里的每個消費(fèi)者都能連上每個partition所在的broker,但有且僅有一個consumer能消費(fèi)到數(shù)據(jù)。當(dāng)這個消費(fèi)者崩潰了,其它的消費(fèi)者會被選出一個來接班; shared:消費(fèi)組里所有消費(fèi)者都能消費(fèi)topic中的所有partition,消息以round-robin的方式來分發(fā); key-shared:消費(fèi)組里所有消費(fèi)者都能消費(fèi)到topic中所有partition,但是帶有相同key的消息會保證發(fā)送給同一個消費(fèi)者。
這些消費(fèi)模型可以滿足多種業(yè)務(wù)場景,用戶可以根據(jù)實(shí)際情況進(jìn)行選擇。通過這層抽象,pulsar既支持了queue消費(fèi)模型,也支持了stream消費(fèi)模型,還可以支持其它無數(shù)的消費(fèi)模型(只要有人提pr),這就是pulsar所說的統(tǒng)一了消費(fèi)模型。
其實(shí)在消費(fèi)模型抽象的底下,就是不同的cursor管理邏輯。怎么ack,游標(biāo)怎么移動,怎么快速查找下一條需要重試的msg……這都是一些技術(shù)細(xì)節(jié),但是通過這層抽象,可以把這些細(xì)節(jié)進(jìn)行隱藏,讓大家更關(guān)注于應(yīng)用。
五、存算分離架構(gòu)
其實(shí)技術(shù)的發(fā)展都是螺旋式的,很多時候你會發(fā)現(xiàn)最新的發(fā)展方向又回到了20年前的技術(shù)路線了。
在20年前,由于普通計算機(jī)硬件設(shè)備的局限性,對大量數(shù)據(jù)的存儲是通過NAS(Network Attached Storage)這樣的“云端”集中式存儲來完成。但這種方式的局限性也很多,不僅需要專用硬件設(shè)備,而且最大的問題就是難以擴(kuò)容來適應(yīng)海量數(shù)據(jù)的存儲。
數(shù)據(jù)庫方面也主要是以O(shè)racle小型機(jī)為主的方案。然而隨著互聯(lián)網(wǎng)的發(fā)展,數(shù)據(jù)量越來越大,Google后來又推出了以普通計算機(jī)為主的分布式存儲方案,任意一臺計算機(jī)都能作為一個存儲節(jié)點(diǎn),然后通過讓這些節(jié)點(diǎn)協(xié)同工作組成一個更大的存儲系統(tǒng),這就是HDFS。
然而移動互聯(lián)網(wǎng)使得數(shù)據(jù)量進(jìn)一步增大,并且4G 5G的普及讓用戶對延遲也非常敏感,既要可靠,又要快,又要可擴(kuò)容的存儲逐漸變成了一種企業(yè)的剛需。而且隨著時間的推移,互聯(lián)網(wǎng)應(yīng)用的流量集中度會越來越高,大企業(yè)的這種剛需訴求也越來越強(qiáng)烈。
因此,可靠的分布式存儲作為一種基礎(chǔ)設(shè)施也在不斷地完善。它們都有一個共同的目標(biāo),就是讓你像使用filesystem一樣使用它們,并且具有高性能高可靠自動錯誤恢復(fù)等多種功能。然而我們需要面對的一個問題就是CAP理論的限制,線性一致性(C),可用性(A),分區(qū)容錯性(P),三者只能同時滿足兩者。因此不可能存在完美的存儲系統(tǒng),總有那么一些“不足”。我們需要做的其實(shí)就是根據(jù)不同的業(yè)務(wù)場景,選用合適的存儲設(shè)施,來構(gòu)建上層的應(yīng)用。這就是pulsar的邏輯,也是tidb等newsql的邏輯,也是未來大型分布式系統(tǒng)的基本邏輯,所謂的“云原生”。
往期推薦
看完文章,餓了點(diǎn)外賣,點(diǎn)擊 ??《無門檻外賣優(yōu)惠券,每天免費(fèi)領(lǐng)!》
END
若覺得文章對你有幫助,隨手轉(zhuǎn)發(fā)分享,也是我們繼續(xù)更新的動力。
長按二維碼,掃掃關(guān)注哦
?「C語言中文網(wǎng)」官方公眾號,關(guān)注手機(jī)閱讀教程 ?

目前收集的資料包括: Java,Python,C/C++,Linux,PHP,go,C#,QT,git/svn,人工智能,大數(shù)據(jù),單片機(jī),算法,小程序,易語言,安卓,ios,PPT,軟件教程,前端,軟件測試,簡歷,畢業(yè)設(shè)計,公開課 等分類,資源在不斷更新中...