點擊關(guān)注公眾號,Java干貨及時送達
作者:人月聊IT
來源:http://blog.sina.com.cn/s/blog_493a84550102z8t2.html
今天談下業(yè)務(wù)系統(tǒng)性能問題分析診斷和性能優(yōu)化方面的內(nèi)容。這篇文章重點還是談已經(jīng)上線的業(yè)務(wù)系統(tǒng)后續(xù)出現(xiàn)性能問題后的問題診斷和優(yōu)化重點。
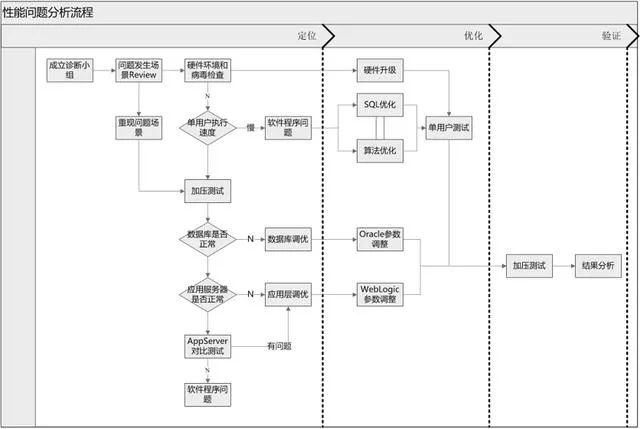
| 系統(tǒng)性能問題分析流程
我們首先來分析下如果一個業(yè)務(wù)系統(tǒng)上線前沒有性能問題,而在上線后出現(xiàn)了比較嚴重的性能問題,那么實際上潛在的場景主要來自于以下幾個方面。
- 業(yè)務(wù)出現(xiàn)大并發(fā)的訪問,導致出現(xiàn)性能瓶頸
- 上線后的系統(tǒng)數(shù)據(jù)庫數(shù)據(jù)日積月累,數(shù)據(jù)量增加后出現(xiàn)性能瓶頸
- 其它關(guān)鍵環(huán)境改變,比如我們常說的網(wǎng)絡(luò)帶寬影響
正是由于這個原因,當我們發(fā)現(xiàn)性能問題的時候,首先就需要判斷是單用戶非并發(fā)狀態(tài)下本身就有性能問題,還是說在并發(fā)狀態(tài)才存在性能問題。對于單用戶性能問題往往比較容易測試和驗證,對于并發(fā)性能問題我們可以在測試環(huán)境進行加壓測試和驗證,以判斷并發(fā)下的性能。如果是單用戶本身就存在性能問題,那么大部分問題都出在程序代碼和SQL需要進一步優(yōu)化上面。如果是并發(fā)性能問題,我們就需要進一步分析數(shù)據(jù)庫和中間件本身的狀態(tài),看是否需要對中間件進行性能調(diào)優(yōu)。在加壓測試過程中,我們還需要對CPU,內(nèi)存和JVM進行監(jiān)控,觀察是否存在類似內(nèi)存泄漏無法釋放等情況,即并發(fā)下性能問題本身也可能是代碼本身原因?qū)е滦阅墚惓!?/span>| 性能問題影響因素分析
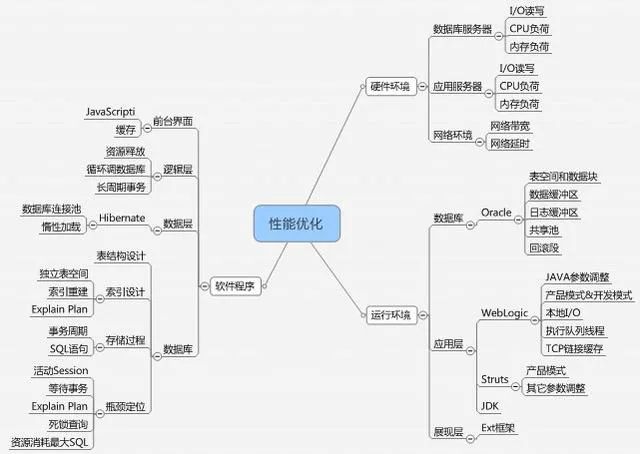
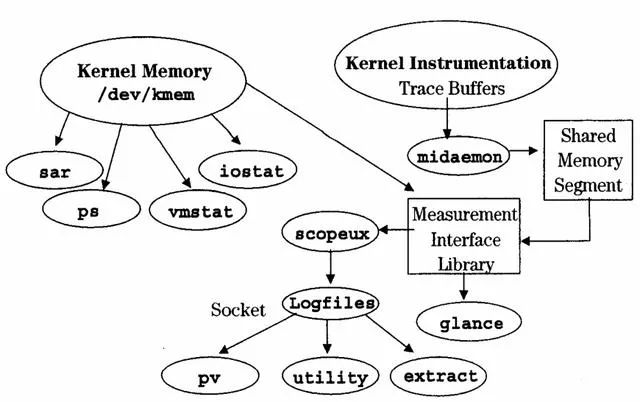
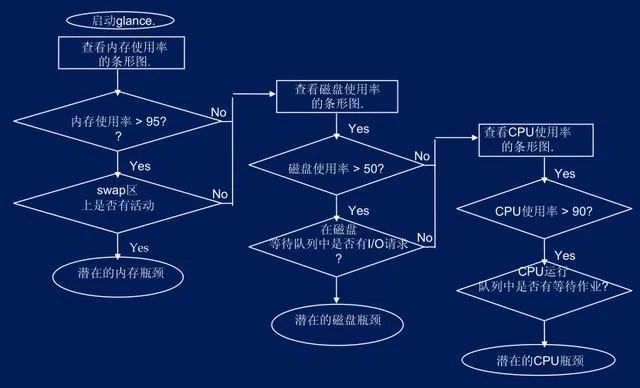
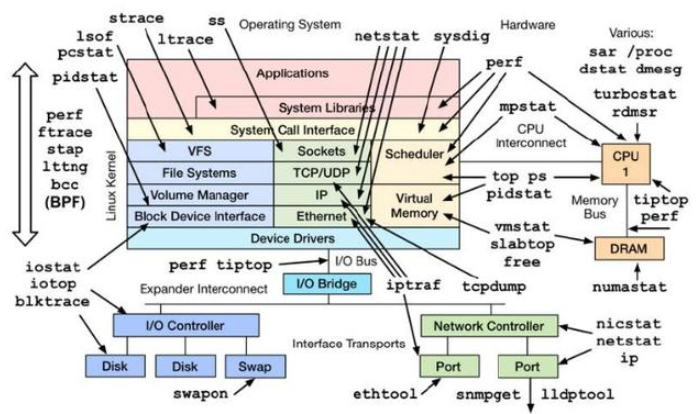
對于性能問題影響因素,簡單來說包括了硬件環(huán)境,軟件運行環(huán)境和軟件程序三個方面的主要內(nèi)容。下面分別再展開說明下。硬件環(huán)境就是我們常說的計算,存儲和網(wǎng)絡(luò)資源。對于服務(wù)器的計算能力,一般來說廠家都會提供TPMC參數(shù)作為一個參考數(shù)據(jù),但是我們實際看到相同TPMC能力下的X86服務(wù)器能力仍然低于小型機的能力。除了服務(wù)器的計算能力參數(shù),另外一個重點就是我們說的存儲設(shè)備,影響到存儲的重點又是IO讀寫性能問題。有時候我們監(jiān)控發(fā)現(xiàn)CPU和內(nèi)存居高不下,而真正的瓶頸通過分析反而發(fā)現(xiàn)是由于IO瓶頸導致,由于讀寫性能跟不上,導致大量數(shù)據(jù)無法快速持久化并釋放內(nèi)存資源。比如在Linux環(huán)境下,本身也提供了性能監(jiān)控工具方便進行性能分析。比如常用的iostat,ps,sar,top,vmstat等,這些工具可以對CPU,內(nèi)存,JVM,磁盤IO等進行性能監(jiān)控和分析,以發(fā)現(xiàn)真正的性能問題在哪里。
比如我們常說的內(nèi)存使用率持續(xù)告警,你就必須發(fā)現(xiàn)是高并發(fā)調(diào)用導致,還是JVM內(nèi)存泄漏導致,還是本身由于磁盤IO瓶頸導致。對于CPU,內(nèi)存,磁盤IO性能監(jiān)控和分析的一個思路可以參考:| 運行環(huán)境-數(shù)據(jù)庫和應(yīng)用中間件數(shù)據(jù)庫和應(yīng)用中間件性能調(diào)優(yōu)是另外一個經(jīng)常出現(xiàn)性能問題的地方。數(shù)據(jù)庫調(diào)優(yōu)
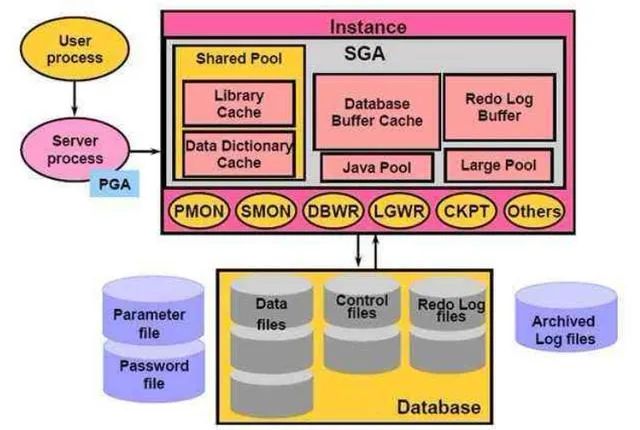
拿Oracle數(shù)據(jù)庫來說,影響數(shù)據(jù)庫性能的因素包括:系統(tǒng)、數(shù)據(jù)庫、網(wǎng)絡(luò)。數(shù)據(jù)庫的優(yōu)化包括:優(yōu)化數(shù)據(jù)庫磁盤I/O、優(yōu)化回滾段、優(yōu)化Rrdo日志、優(yōu)化系統(tǒng)全局區(qū)、優(yōu)化數(shù)據(jù)庫對象。要調(diào)整首先就需要對數(shù)據(jù)庫性能進行監(jiān)控。
我們可以在init.ora參數(shù)文件中設(shè)置TIMED_STATISTICS=TRUE 和在你的會話層設(shè)置ALTER SESSION SET STATISTICS=TRUE 。運行svrmgrl 用 connect internal 注冊,在你的應(yīng)用系統(tǒng)正常活動期間,運行utlbstat.sql 開始統(tǒng)計系統(tǒng)活動,達到一定的時間后,執(zhí)行utlestat.sql 停止統(tǒng)計。統(tǒng)計結(jié)果將產(chǎn)生在report.txt 文件中。
數(shù)據(jù)庫性能優(yōu)化應(yīng)該是一個持續(xù)性的工作,一個方面是本身的性能和參數(shù)巡檢,另外一個方面就是DBA也會經(jīng)常提取最占用內(nèi)存的低效SQL語句給開發(fā)人員進一步分析,同時也會從數(shù)據(jù)庫本身的以下告警KPI指標中發(fā)現(xiàn)問題。比如我們可能會發(fā)現(xiàn)Oracle數(shù)據(jù)庫出現(xiàn)內(nèi)存使用率高的告警,而通過檢查會發(fā)現(xiàn)是產(chǎn)生了大量的Redo日志導致,那么我們就需要從程序上進一步分析為何會產(chǎn)生如此多的回滾。應(yīng)用中間件性能分析和調(diào)優(yōu)
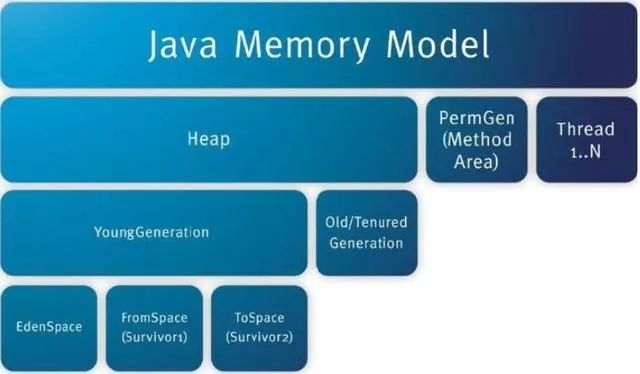
應(yīng)用中間件容器即我們常說的Weblogic, Tomcat等應(yīng)用中間件容器或Web容器。應(yīng)用中間件調(diào)優(yōu)一個方面是本身的配置參數(shù)優(yōu)化設(shè)置,一個方面就是JVM內(nèi)存啟動參數(shù)調(diào)優(yōu)。對于應(yīng)用中間件本身的參數(shù)設(shè)置,主要包括了JVM啟動參數(shù)設(shè)置,線程池設(shè)置,連接數(shù)的最小最大值設(shè)置等。如果是集群環(huán)境,還涉及到集群相關(guān)的配置調(diào)優(yōu)。對于JVM啟動參數(shù)調(diào)優(yōu),往往也是應(yīng)用中間件調(diào)優(yōu)的一個關(guān)鍵點,但是一般JVM參數(shù)調(diào)優(yōu)會結(jié)合應(yīng)用程序一起進行分析。比如我們常見的JVM堆內(nèi)存溢出,如果程序代碼沒有內(nèi)存泄漏問題的話,我就需要考慮調(diào)整JVM啟動時候堆內(nèi)存設(shè)置。在32位操作系統(tǒng)下只能夠設(shè)置到4G,但是在64位操作系統(tǒng)下已經(jīng)可以設(shè)置到8G甚至更大的值。
-Xmx??#設(shè)置最大堆空間
-Xms??#設(shè)置最小堆空間
-XX:MaxNewSize?#設(shè)置最大新生代空間
-XX:NewSize????#設(shè)置最小新生代空間
-XX:MaxPermSize??#設(shè)置最大永久代空間(注:新內(nèi)存模型已經(jīng)替換為Metaspace)
-XX:PermSize?????#設(shè)置最小永久代空間(注:新內(nèi)存模型已經(jīng)替換為Metaspace)
-Xss???#設(shè)置每個線程的堆棧大小
那么這些值究竟設(shè)置多大合適,具體來講: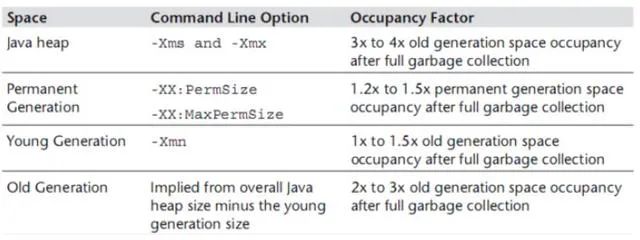 Java整個堆大小設(shè)置,Xmx 和 Xms設(shè)置為老年代存活對象的3-4倍,即FullGC之后的老年代內(nèi)存占用的3-4倍。永久代 PermSize和MaxPermSize設(shè)置為老年代存活對象的1.2-1.5倍。年輕代Xmn的設(shè)置為老年代存活對象的1-1.5倍。老年代的內(nèi)存大小設(shè)置為老年代存活對象的2-3倍。
Java整個堆大小設(shè)置,Xmx 和 Xms設(shè)置為老年代存活對象的3-4倍,即FullGC之后的老年代內(nèi)存占用的3-4倍。永久代 PermSize和MaxPermSize設(shè)置為老年代存活對象的1.2-1.5倍。年輕代Xmn的設(shè)置為老年代存活對象的1-1.5倍。老年代的內(nèi)存大小設(shè)置為老年代存活對象的2-3倍。注意在新的JVM內(nèi)存模型下已經(jīng)沒有PermSize而是變化為Metaspace,因此需要考慮Heap內(nèi)存和Metaspace大小的配比,同時還需要考慮相關(guān)的垃圾回收機制是采用哪種類型等。
對于JVM內(nèi)存溢出問題,我前面寫過一篇專門的分析文章可以參考。從表象到根源-一個軟件系統(tǒng)JVM內(nèi)存溢出問題分析解決全過程:
軟件程序性能問題分析
在這里首先要強調(diào)的一點就是,當我們發(fā)現(xiàn)性能問題后首先想到的就是擴展資源,但是大部分的性能問題本身并不是資源能力不夠?qū)е拢俏覀兂绦驅(qū)崿F(xiàn)上出現(xiàn)明顯缺陷。比如我們經(jīng)常看到的大量循環(huán)創(chuàng)建連接,資源使用了不釋放,SQL語句低效執(zhí)行等。為了解決這些性能問題,最好的方法仍然是在事前控制。其中包括了事前的代碼靜態(tài)檢查工具的使用,也包括了開發(fā)團隊對代碼進行的Code Review來發(fā)現(xiàn)性能問題。所有已知的問題都必須形成開發(fā)團隊的開發(fā)規(guī)范要求,避免重復再犯。| 業(yè)務(wù)系統(tǒng)性能問題擴展思考
對于業(yè)務(wù)系統(tǒng)的性能優(yōu)化,除了上面談到的標準分析流程和分析要素外,再談下其它一些性能問題引發(fā)的關(guān)鍵思考。上線前的性能測試是否有用?
有時候大家可能覺得奇怪,為何我們系統(tǒng)上線前都做了性能測試,為何上線后還是會出現(xiàn)系統(tǒng)性能問題。那么我們可以考慮下實際上我們上線前性能測試可能存在的一些無法真實模擬生產(chǎn)環(huán)境的地方,具體為:- 硬件能否完全模擬真實環(huán)境?最好的性能測試往往是直接在搭建完成的生產(chǎn)環(huán)境進行。
- 數(shù)據(jù)量能否模擬實際場景?真實場景往往是多個業(yè)務(wù)表都已經(jīng)存在大數(shù)據(jù)量的積累而非空表。
- 并發(fā)能否模擬真實場景?一個是需要錄制復合業(yè)務(wù)場景,一個是需要多臺壓測機。
而實際上我們在做性能測試的時候以上幾個點都很難真正做到,因此要想完全模擬出生產(chǎn)真實環(huán)境是相當困難的,這也導致了很多性能問題是在真正上線后才發(fā)現(xiàn)。系統(tǒng)本身水平彈性擴展是否完全解決性能問題?
第二個點也是我們經(jīng)常談的比較多的點,就是我們的業(yè)務(wù)系統(tǒng)在進行架構(gòu)設(shè)計的時候,特別是面對非功能性需求,我們都會談到系統(tǒng)本身的數(shù)據(jù)庫,中間件都采用了集群技術(shù),能夠做到彈性水平擴展。那么這種彈性水平擴展能力是否又真正解決了性能問題?實際上我們看到對于數(shù)據(jù)庫往往很難真正做到無限的彈性水平擴展,即使對于Oracle RAC集群往往也是最多擴展到單點的2到3倍性能。對于應(yīng)用集群往往可以做到彈性水平擴展,當前技術(shù)也比較成熟。當中間件能夠做到完全彈性擴展的時候,實際上仍然可能存在性能問題,即隨著我們系統(tǒng)的運行和業(yè)務(wù)數(shù)據(jù)量的不斷積累增值。實際上你可以看到往往非并發(fā)狀態(tài)下的單用戶訪問本身就很慢,而不是說并發(fā)上來后慢。因此也是我們常說的要給點,即:- 單點訪問性能正常的時候可以擴展集群來應(yīng)對大并發(fā)狀態(tài)下的同時訪問
- 單點訪問本身性能就有問題的時候,要優(yōu)先優(yōu)化單節(jié)點訪問性能
業(yè)務(wù)系統(tǒng)性能診斷的分類
對于業(yè)務(wù)系統(tǒng)性能診斷,如果從靜態(tài)角度我們可以考慮從以下三個方面進行分類- 中間件層面(包括了數(shù)據(jù)庫,應(yīng)用服務(wù)器中間件)
- 軟件層面(包括了數(shù)據(jù)庫SQL和存儲過程,邏輯層,前端展現(xiàn)層等)
那么一個業(yè)務(wù)系統(tǒng)應(yīng)用功能出現(xiàn)問題了,我們當然也可以從動態(tài)層面來看實際一個應(yīng)用請求從調(diào)用開始究竟經(jīng)過了哪些代碼和硬件基礎(chǔ)設(shè)施,通過分段方法來定位和查詢問題。比如我們常見的就是一個查詢功能如果出現(xiàn)問題了,首先就是找到這個查詢功能對應(yīng)的SQL語句在后臺查詢是否很慢,如果這個SQL本身就慢,那么就要優(yōu)化優(yōu)化SQL語句。如果SQL本身快但是查詢慢,那就要看下是否是前端性能問題或者集群問題等。軟件代碼的問題往往是最不能忽視的一個性能問題點
對于業(yè)務(wù)系統(tǒng)性能問題,我們經(jīng)常想到的就是要擴展數(shù)據(jù)庫的硬件性能,比如擴展CPU和內(nèi)存,擴展集群,但是實際上可以看到很多應(yīng)用的性能問題并不是硬件性能導致的,而是由于軟件代碼性能引起的。對于軟件代碼常見的性能問題我在以往的博客文章里面也談過到,比較典型的包括了。- 循環(huán)中初始化大的結(jié)構(gòu)對象,數(shù)據(jù)庫連接等
- 處理某一個業(yè)務(wù)場景或問題的時候,沒有選擇最優(yōu)的數(shù)據(jù)結(jié)構(gòu)或算法
以上都是常見的一些軟件代碼性能問題點,而這些往往需要通過我們進行Code Review或代碼評審的方式才能夠發(fā)現(xiàn)出來。因此如果要做全面的性能優(yōu)化,對于軟件代碼的性能問題排查是必須的。通過IT資源監(jiān)控或APM應(yīng)用工具來發(fā)現(xiàn)性能問題
對于性能問題的發(fā)現(xiàn)一般有兩條路徑,一個就是通過我們IT資源的監(jiān)控,APM的性能監(jiān)控和預警來提前發(fā)現(xiàn)性能問題,一個是通過業(yè)務(wù)用戶在使用過程中的反饋來發(fā)現(xiàn)性能問題。
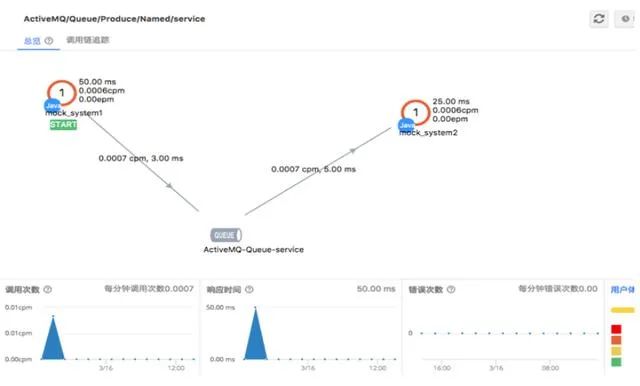
APM應(yīng)用性能管理主要指對企業(yè)的關(guān)鍵業(yè)務(wù)應(yīng)用進行監(jiān)測、優(yōu)化,提高企業(yè)應(yīng)用的可靠性和質(zhì)量,保證用戶得到良好的服務(wù),降低IT總擁有成本(TCO)。資源池-》應(yīng)用層-》業(yè)務(wù)層這個可以理解為APM的一個關(guān)鍵點,原有的網(wǎng)管類監(jiān)控軟件更多的是資源和操作系統(tǒng)層面,包括計算和存儲資源的使用和利用率情況,網(wǎng)絡(luò)本身的性能情況等。但是當要分析所有的資源層問題如何對應(yīng)到具體的應(yīng)用,對應(yīng)到具體的業(yè)務(wù)功能的時候很難。傳統(tǒng)模式下,當出現(xiàn)CPU或內(nèi)存滿負荷的時候,如果要查找到具體是哪個應(yīng)用,哪個進程或者具體哪個業(yè)務(wù)功能,哪個sql語句導致的往往并不是容易的事情。在實際的性能問題優(yōu)化中往往也需要做大量的日志分析和問題定位,最終才可能找到問題點。比如在我們最近的項目實施中,結(jié)合APM和服務(wù)鏈監(jiān)控,我們可以快速的發(fā)現(xiàn)究竟是哪個服務(wù)調(diào)用出現(xiàn)了性能問題,或者快速的定位出哪個SQL語句有驗證的性能問題。這個都可以幫助我們快速的進行性能問題分析和診斷。資源上承載的是應(yīng)用,應(yīng)用本身又包括了數(shù)據(jù)庫和應(yīng)用中間件容器,同時也包括了前端;在應(yīng)用之上則是對應(yīng)到具體的業(yè)務(wù)功能。因此APM一個核心就是要將資源-》應(yīng)用-》功能之間進行整合分析和銜接。而隨著DevOps和自動化運維的思路推進,我們更加希望是通過APM等工具主動監(jiān)控來發(fā)現(xiàn)性能問題,對于APM工具最大的好處就是可以進行服務(wù)全鏈路的性能分析,方便我們發(fā)現(xiàn)性能問題究竟發(fā)生在哪里。比如我們提交一個表單很慢,通過APM分析我們很容易發(fā)現(xiàn)究竟是調(diào)用哪個業(yè)務(wù)服務(wù)慢,或者是處理哪個SQL語句慢。這樣可以極大的提升我們性能問題分析診斷的效率。