
pandas100個騷操作:JSON自動解析為DataFrame

來源:Python數(shù)據(jù)科學(xué)
作者:東哥起飛
大家好,我是你們的東哥。
本篇是pandas100個騷操作的第2篇:JSON自動解析為DataFrame
全部內(nèi)容請點文章頭部的「pandas100個騷操作」系列查看。
調(diào)用API和文檔數(shù)據(jù)庫會返回嵌套的JSON對象,當我們使用Python嘗試將嵌套結(jié)構(gòu)中的鍵轉(zhuǎn)換為列時,數(shù)據(jù)加載到pandas中往往會得到如下結(jié)果:
df?=?pd.DataFrame.from_records(results?[“?issues”],columns?=?[“?key”,“?fields”])

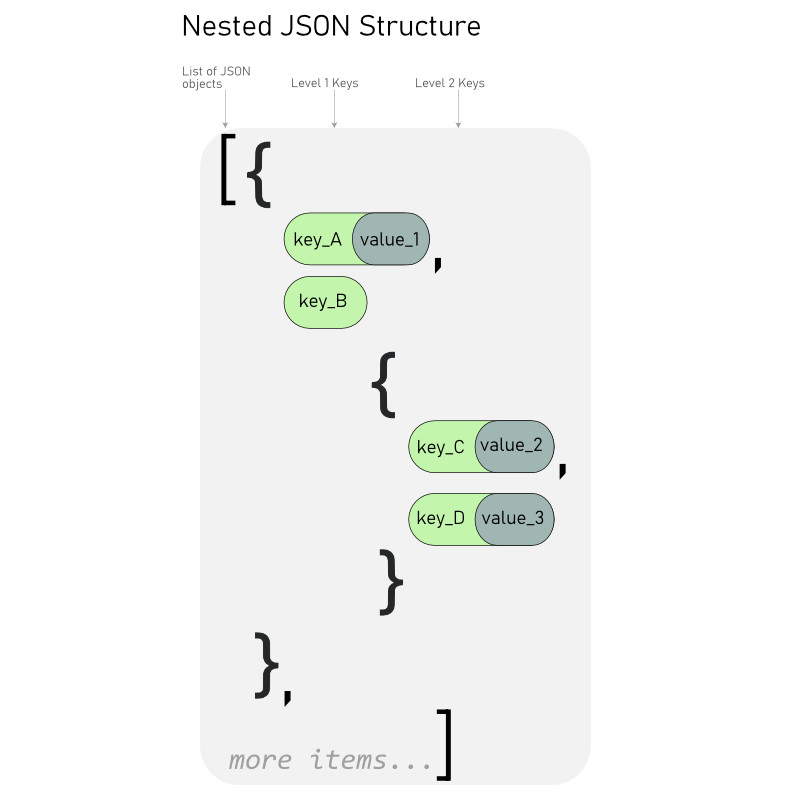
key:JSON密鑰,在第一級的位置。
summary:第二級的“字段”對象。
status name:第三級位置。
statusCategory name:位于第4個嵌套級別。
{
??"expand":?"schema,names",
??"issues":?[
????{
??????"fields":?{
????????"issuetype":?{
??????????"avatarId":?10300,
??????????"description":?"",
??????????"id":?"10005",
??????????"name":?"New?Feature",
??????????"subtask":?False
????????},
????????"status":?{
??????????"description":?"A?resolution?has?been?taken,?and?it?is?awaiting?verification?by?reporter.?From?here?issues?are?either?reopened,?or?are?closed.",
??????????"id":?"5",
??????????"name":?"Resolved",
??????????"statusCategory":?{
????????????"colorName":?"green",
????????????"id":?3,
????????????"key":?"done",
????????????"name":?"Done",
??????????}
????????},
????????"summary":?"Recovered?data?collection?Defraglar?$MFT?problem"
??????},
??????"id":?"11861",
??????"key":?"CAE-160",
????},
????{
??????"fields":?{?
...?more?issues],
??"maxResults":?5,
??"startAt":?0,
??"total":?160
}
一個不太好的解決方案
df?=?(
????df["fields"]
????.apply(pd.Series)
????.merge(df,?left_index=True,?right_index?=?True)
)

#?提取issue?type的name到一個新列叫"issue_type"
df_issue_type?=?(
????df["issuetype"]
????.apply(pd.Series)
????.rename(columns={"name":?"issue_type_name"})["issue_type_name"]
)
df?=?df.assign(issue_type_name?=?df_issue_type)

內(nèi)置的解決方案
確定我們要想的字段,使用 . 符號連接嵌套對象。 將想要處理的嵌套列表(這里是results["issues"])作為參數(shù)放進 .json_normalize 中。 過濾我們定義的FIELDS列表。
FIELDS?=?["key",?"fields.summary",?"fields.issuetype.name",?"fields.status.name",?"fields.status.statusCategory.name"]
df?=?pd.json_normalize(results["issues"])
df[FIELDS]

沒錯,就這么簡單。
其它操作
記錄路徑
#?使用路徑而不是直接用results["issues"]
pd.json_normalize(results,?record_path="issues")[FIELDS]
自定義分隔符
#?用?"-"?替換默認的?"."
FIELDS?=?["key",?"fields-summary",?"fields-issuetype-name",?"fields-status-name",?"fields-status-statusCategory-name"]
pd.json_normalize(results["issues"],?sep?=?"-")[FIELDS]
控制遞歸
#?只深入到嵌套第二級
pd.json_normalize(results,?record_path="issues",?max_level?=?2)

愛點贊的人,運氣都不會太差


評論
圖片
表情