
圖解 ElasticSearch 原理,寫得太好了!
除了搜索之外,結(jié)合 Kibana、Logstash、Beats,Elastic Stack 還被廣泛運(yùn)用在大數(shù)據(jù)近實(shí)時(shí)分析領(lǐng)域,包括日志分析、指標(biāo)監(jiān)控、信息安全等多個(gè)領(lǐng)域。
它可以幫助你探索海量結(jié)構(gòu)化、非結(jié)構(gòu)化數(shù)據(jù),按需創(chuàng)建可視化報(bào)表,對(duì)監(jiān)控?cái)?shù)據(jù)設(shè)置報(bào)警閾值,甚至通過使用機(jī)器學(xué)習(xí)技術(shù),自動(dòng)識(shí)別異常狀況。
為什么我的搜索 *foo-bar* 無法匹配 foo-bar ? 為什么增加更多的文件會(huì)壓縮索引(Index)? 為什么 ElasticSearch 占用很多內(nèi)存?
圖解 ElasticSearch
elasticsearch 版本: elasticsearch-2.2.0。
①云上的集群
如下圖:
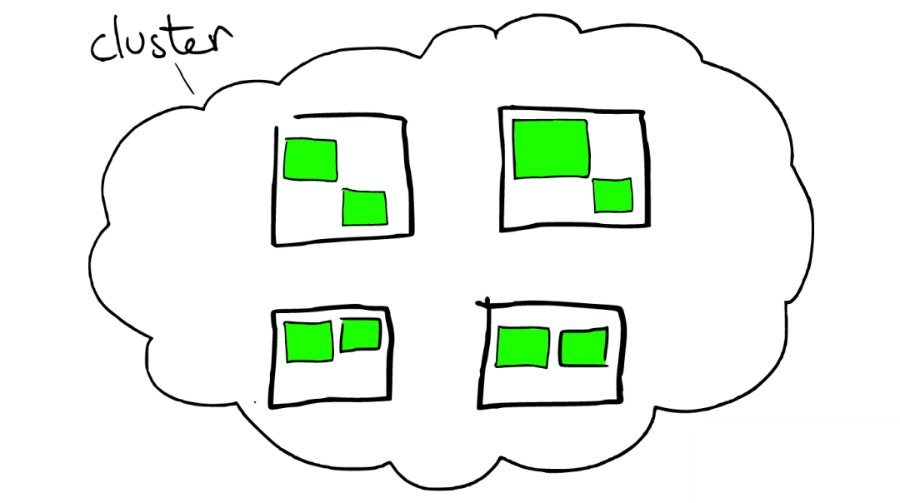
②集群里的盒子
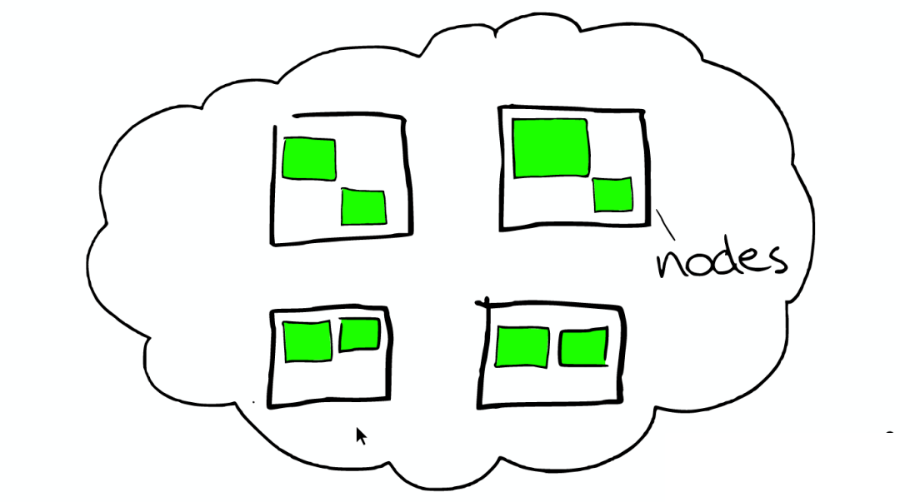
③節(jié)點(diǎn)之間
在一個(gè)或者多個(gè)節(jié)點(diǎn)直接,多個(gè)綠色小方塊組合在一起形成一個(gè) ElasticSearch 的索引。
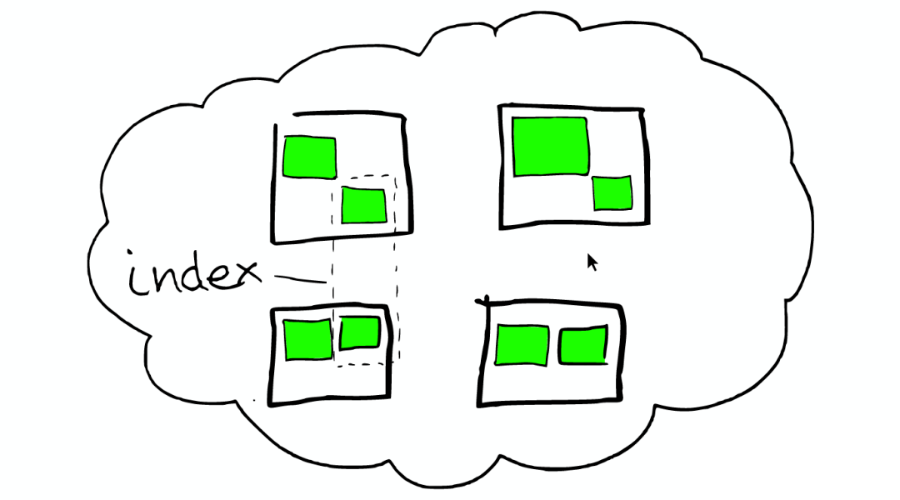
④索引里的小方塊
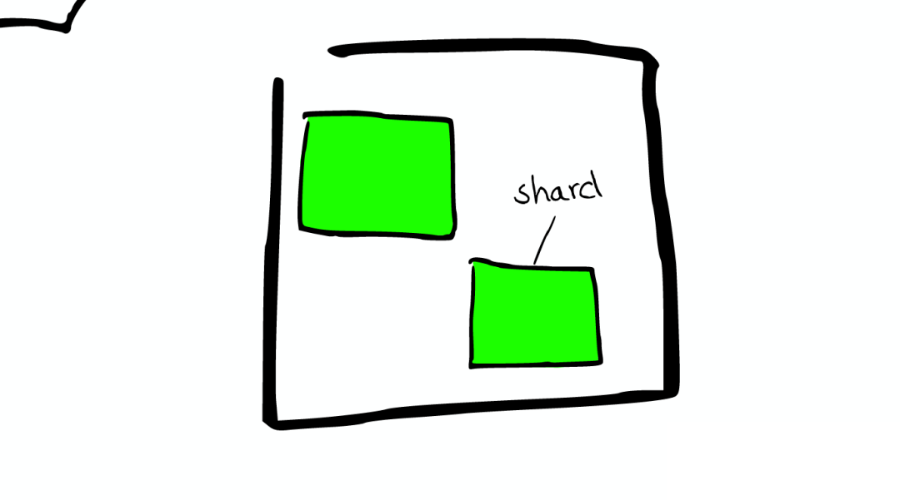
⑤Shard=Lucene Index
一個(gè) ElasticSearch 的 Shard 本質(zhì)上是一個(gè) Lucene Index。

Lucene 是一個(gè) Full Text 搜索庫(也有很多其他形式的搜索庫),ElasticSearch 是建立在 Lucene 之上的。
接下來的故事要說的大部分內(nèi)容實(shí)際上是 ElasticSearch 如何基于 Lucene 工作的。
圖解 Lucene
Mini 索引:Segment
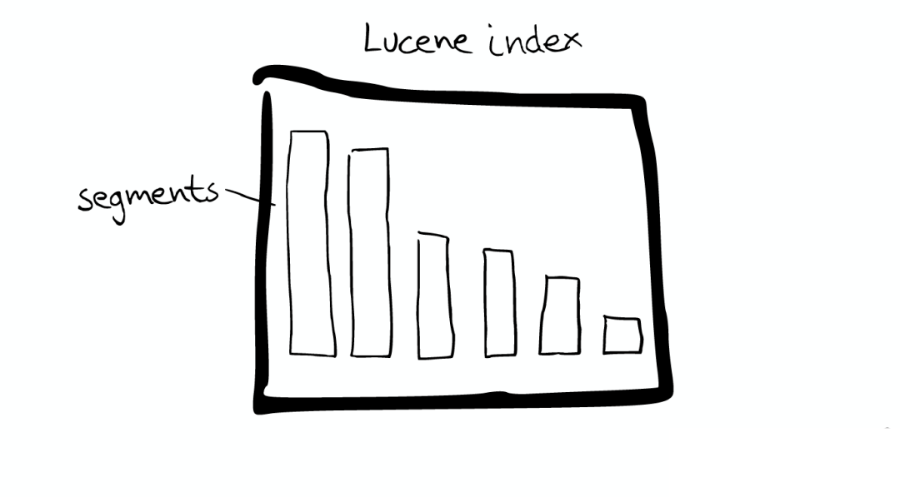
Segment 內(nèi)部

Inverted Index
Stored Fields
Document Values
Cache
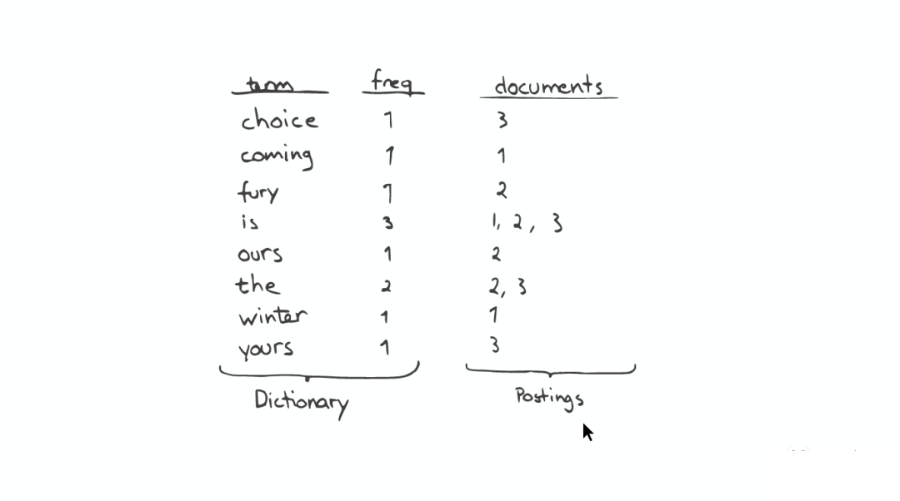
Inverted Index 主要包括兩部分:
一個(gè)有序的數(shù)據(jù)字典 Dictionary(包括單詞 Term 和它出現(xiàn)的頻率)。
與單詞 Term 對(duì)應(yīng)的 Postings(即存在這個(gè)單詞的文件)。

①查詢“the fury”

②自動(dòng)補(bǔ)全(AutoCompletion-Prefix)

③昂貴的查找
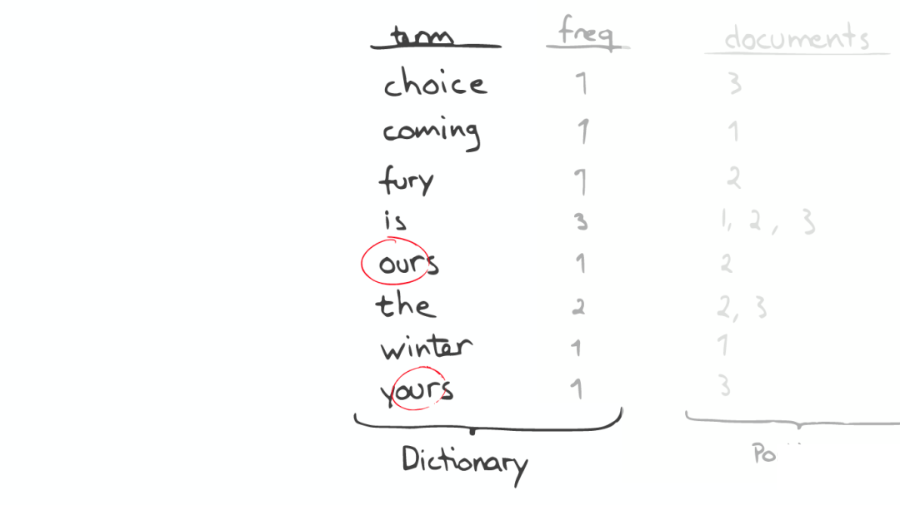
④問題的轉(zhuǎn)化

對(duì)于以上諸如此類的問題,我們可能會(huì)有幾種可行的解決方案:
* suffix→xiffus *,如果我們想以后綴作為搜索條件,可以為 Term 做反向處理。 (60.6384, 6.5017)→ u4u8gyykk,對(duì)于 GEO 位置信息,可以將它轉(zhuǎn)換為 GEO Hash。 123→{1-hundreds, 12-tens, 123},對(duì)于簡單的數(shù)字,可以為它生成多重形式的 Term。
⑤解決拼寫錯(cuò)誤
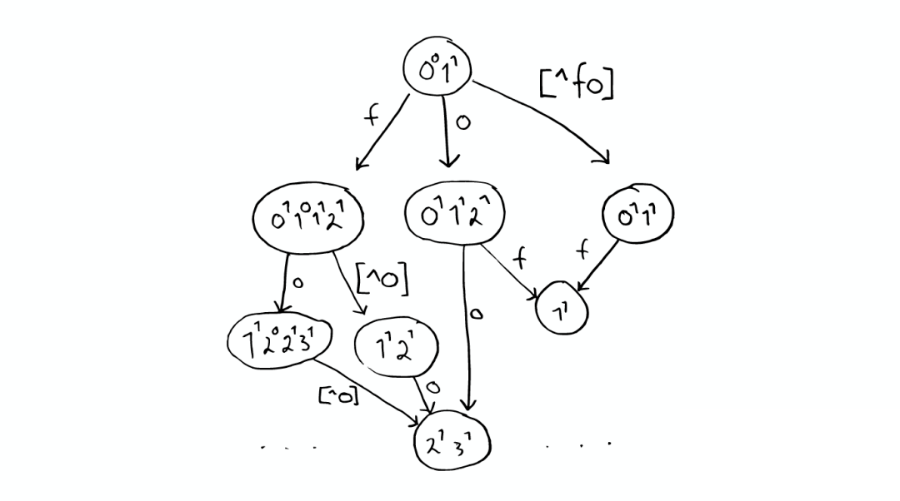
⑥Stored Field 字段查找
當(dāng)我們想要查找包含某個(gè)特定標(biāo)題內(nèi)容的文件時(shí),Inverted Index 就不能很好的解決這個(gè)問題,所以 Lucene 提供了另外一種數(shù)據(jù)結(jié)構(gòu) Stored Fields 來解決這個(gè)問題。
本質(zhì)上,Stored Fields 是一個(gè)簡單的鍵值對(duì) key-value。默認(rèn)情況下,ElasticSearch 會(huì)存儲(chǔ)整個(gè)文件的 JSON source。

⑦Document Values 為了排序,聚合
即使這樣,我們發(fā)現(xiàn)以上結(jié)構(gòu)仍然無法解決諸如:排序、聚合、facet,因?yàn)槲覀兛赡軙?huì)要讀取大量不需要的信息。
所以,另一種數(shù)據(jù)結(jié)構(gòu)解決了此種問題:Document Values。這種結(jié)構(gòu)本質(zhì)上就是一個(gè)列式的存儲(chǔ),它高度優(yōu)化了具有相同類型的數(shù)據(jù)的存儲(chǔ)結(jié)構(gòu)。

Lucene 的一些特性使得這個(gè)過程非常重要:
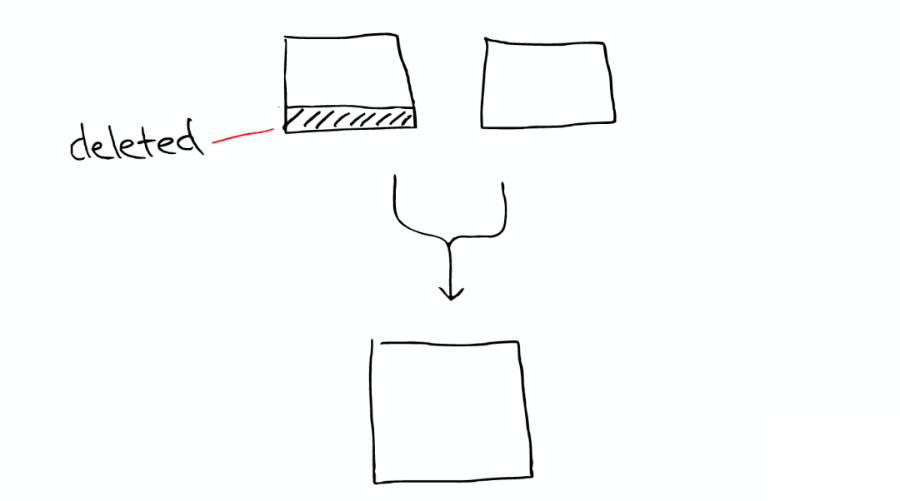
Segments 是不可變的(immutable):Delete?當(dāng)刪除發(fā)生時(shí),Lucene 做的只是將其標(biāo)志位置為刪除,但是文件還是會(huì)在它原來的地方,不會(huì)發(fā)生改變。
Update?所以對(duì)于更新來說,本質(zhì)上它做的工作是:先刪除,然后重新索引(Re-index)。
隨處可見的壓縮:Lucene 非常擅長壓縮數(shù)據(jù),基本上所有教科書上的壓縮方式,都能在 Lucene 中找到。
緩存所有的所有:Lucene 也會(huì)將所有的信息做緩存,這大大提高了它的查詢效率。
當(dāng) ElasticSearch 索引一個(gè)文件的時(shí)候,會(huì)為文件建立相應(yīng)的緩存,并且會(huì)定期(每秒)刷新這些數(shù)據(jù),然后這些文件就可以被搜索到。
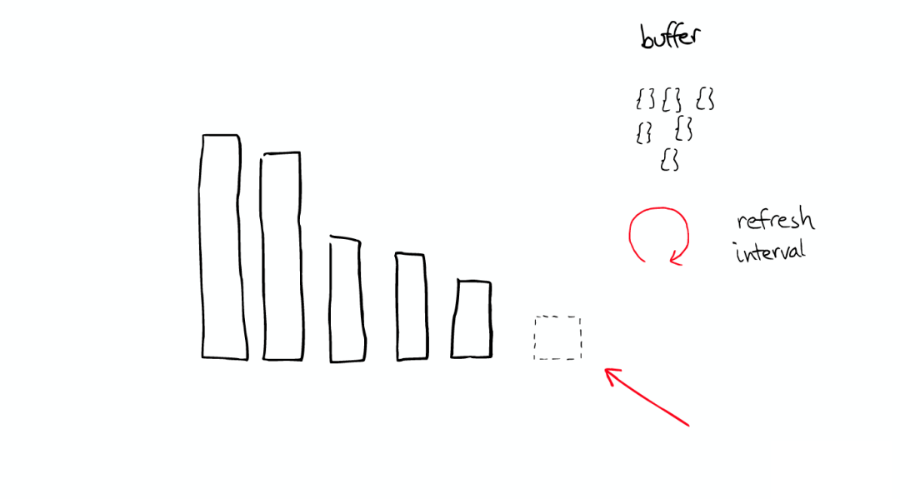
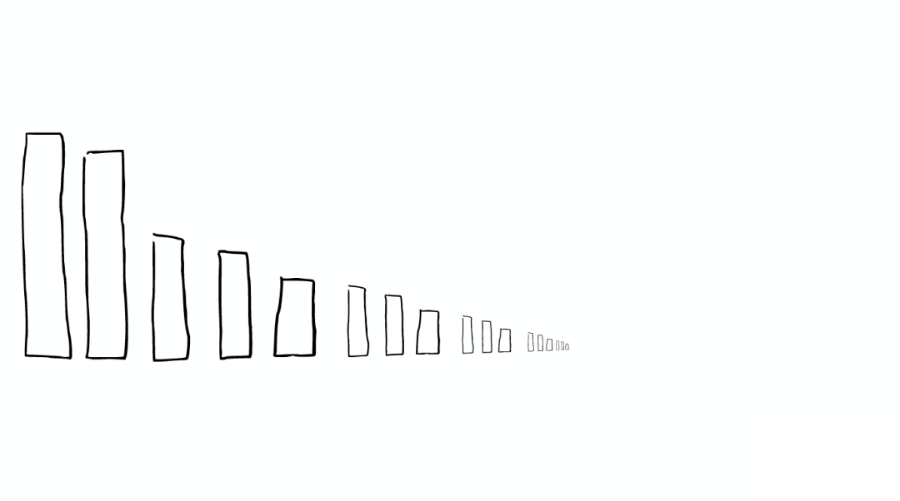
舉個(gè)栗子
有兩個(gè) Segment 將會(huì) Merge:

這兩個(gè) Segment 最終會(huì)被刪除,然后合并成一個(gè)新的 Segment,如下圖:
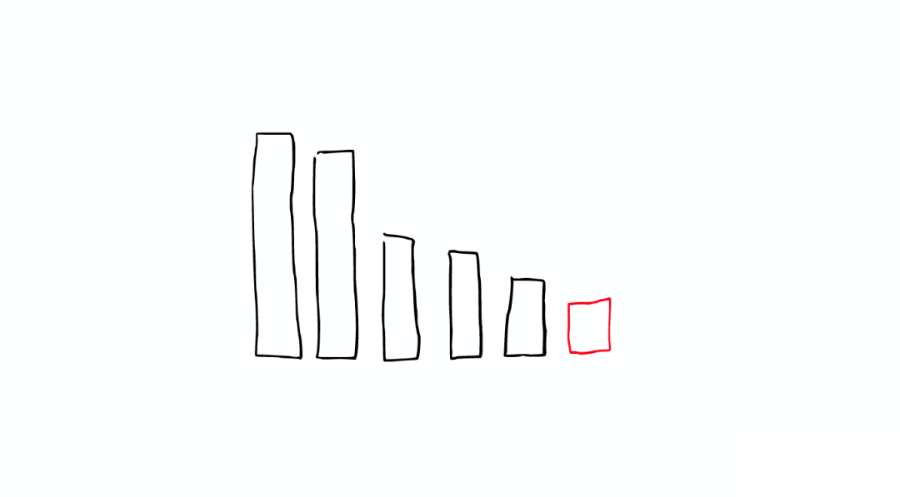
這時(shí)這個(gè)新的 Segment 在緩存中處于 Cold 狀態(tài),但是大多數(shù) Segment 仍然保持不變,處于 Warm 狀態(tài)。
以上場(chǎng)景經(jīng)常在 Lucene Index 內(nèi)部發(fā)生的,如下圖:
在 Shard 中搜索
ElasticSearch 從 Shard 中搜索的過程與 Lucene Segment 中搜索的過程類似。
對(duì)于日志文件的處理:當(dāng)我們想搜索特定日期產(chǎn)生的日志時(shí),通過根據(jù)時(shí)間戳對(duì)日志文件進(jìn)行分塊與索引,會(huì)極大提高搜索效率。
當(dāng)我們想要?jiǎng)h除舊的數(shù)據(jù)時(shí)也非常方便,只需刪除老的索引即可。
在上種情況下,每個(gè) Index 有兩個(gè) Shards。
如下圖:
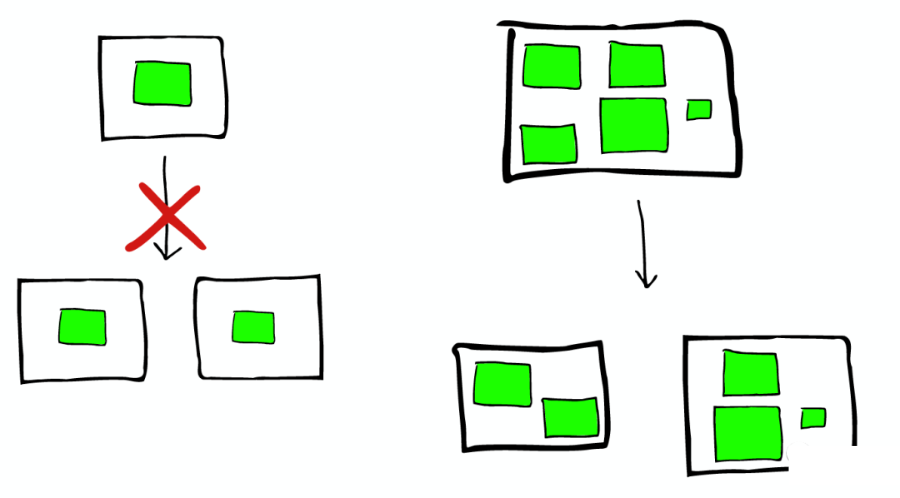
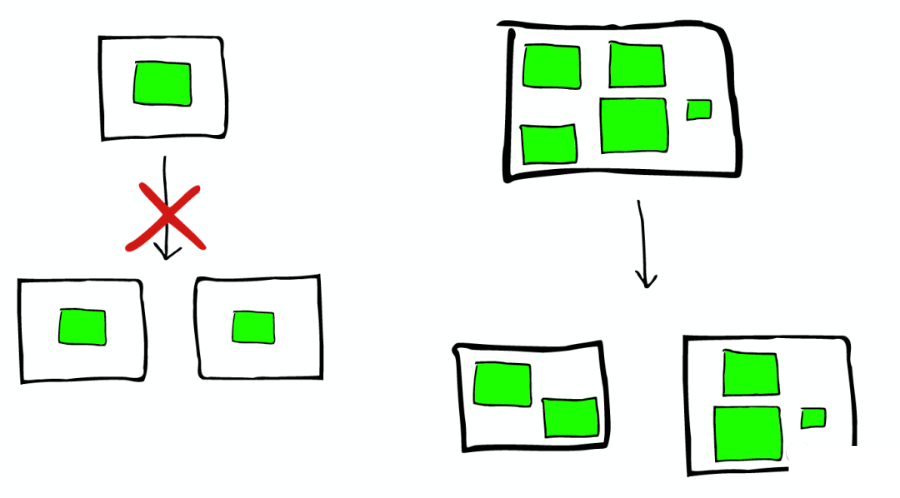
節(jié)點(diǎn)分配與 Shard 優(yōu)化:
為更重要的數(shù)據(jù)索引節(jié)點(diǎn),分配性能更好的機(jī)器。 確保每個(gè) Shard 都有副本信息 Replica。
路由 Routing:每個(gè)節(jié)點(diǎn),每個(gè)都存留一份路由表,所以當(dāng)請(qǐng)求到任何一個(gè)節(jié)點(diǎn)時(shí),ElasticSearch 都有能力將請(qǐng)求轉(zhuǎn)發(fā)到期望節(jié)點(diǎn)的 Shard 進(jìn)一步處理。
一個(gè)真實(shí)的請(qǐng)求
如下圖:

①Q(mào)uery
如下圖:

②Aggregation
如下圖:

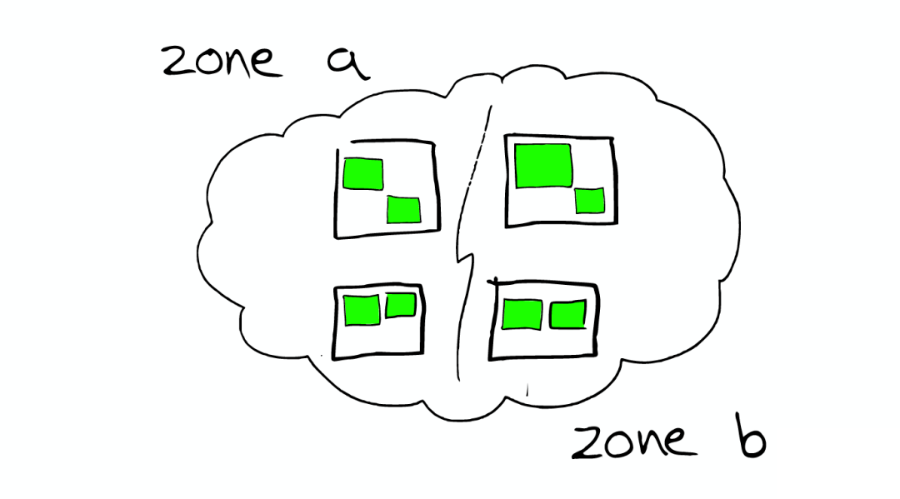
③請(qǐng)求分發(fā)
這個(gè)請(qǐng)求可能被分發(fā)到集群里的任意一個(gè)節(jié)點(diǎn),如下圖:
④上帝節(jié)點(diǎn)
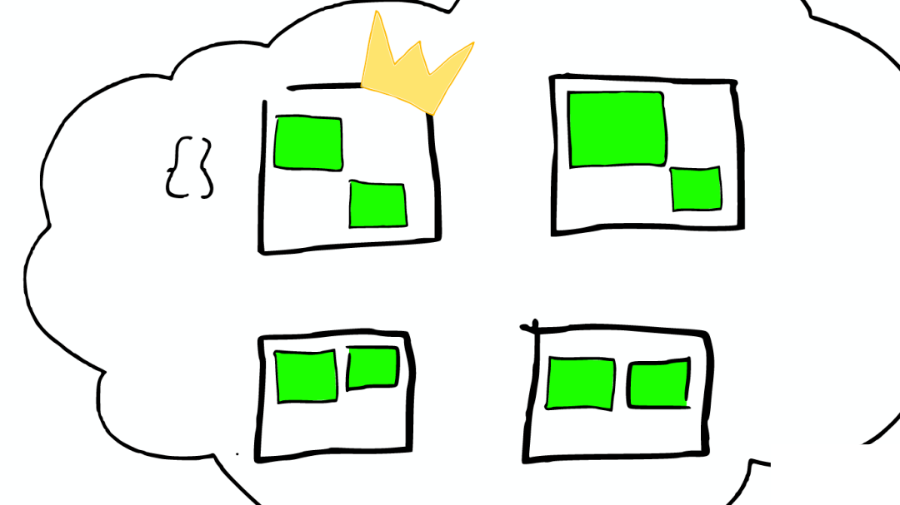
根據(jù)索引信息,判斷請(qǐng)求會(huì)被路由到哪個(gè)核心節(jié)點(diǎn)。
以及哪個(gè)副本是可用的。
等等。
⑤路由
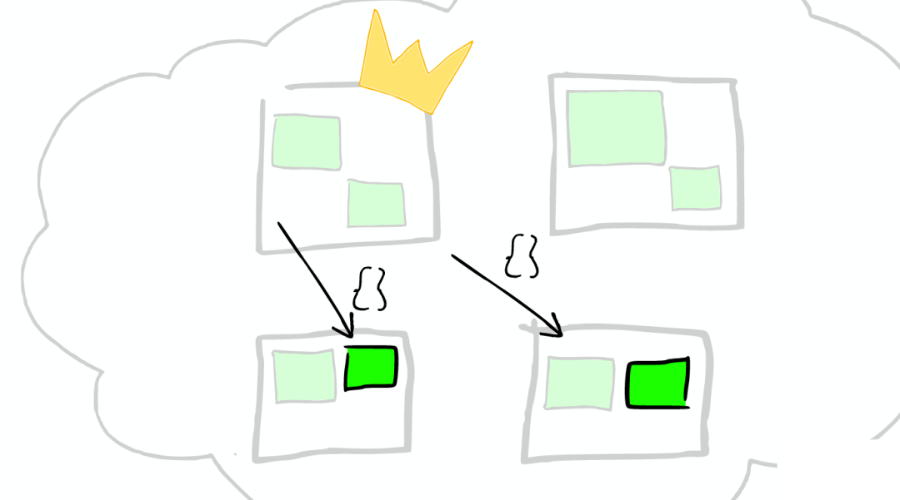
⑥在真實(shí)搜索之前
ElasticSearch 會(huì)將 Query 轉(zhuǎn)換成 Lucene Query,如下圖:
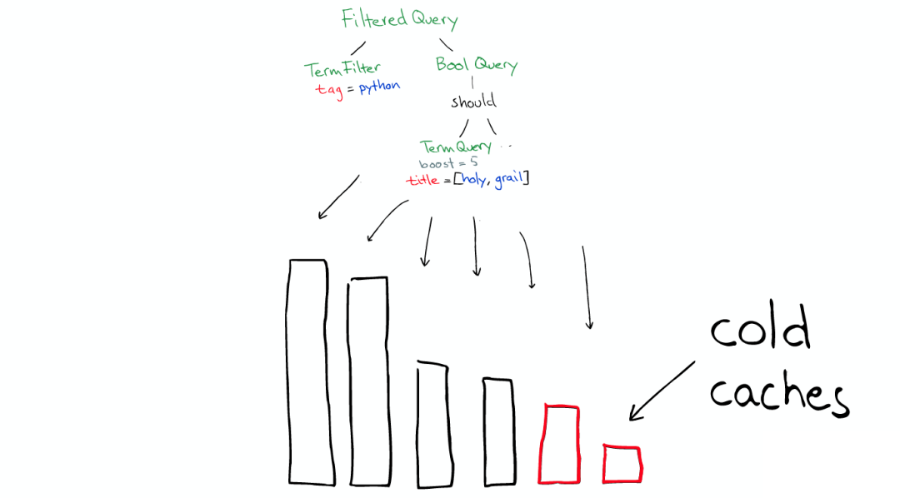
所以:
Filters 可以在任何時(shí)候使用。
Query 只有在需要 Score 的時(shí)候才使用。
⑦返回
搜索結(jié)束之后,結(jié)果會(huì)沿著下行的路徑向上逐層返回,如下圖:
作者:Richaaaard
來源:https://www.cnblogs.com/richaaaard/
PS:歡迎在留言區(qū)留下你的觀點(diǎn),一起討論提高。如果今天的文章讓你有新的啟發(fā),歡迎轉(zhuǎn)發(fā)分享給更多人。 Java后端編程交流群已成立 公眾號(hào)運(yùn)營至今,離不開小伙伴們的支持。為了給小伙伴們提供一個(gè)互相交流的平臺(tái),特地開通了官方交流群。掃描下方二維碼備注 進(jìn)群 或者關(guān)注公眾號(hào) Java后端編程 后獲取進(jìn)群通道。 —————END————— 推薦閱讀:
SpringBoot+vue.js搭建圖書管理系統(tǒng) i++ 是線程安全的嗎? IDEA 卡成球了 !咋優(yōu)化 ? 最美的Vue+Element開源后臺(tái)管理系統(tǒng) 基于SpringBoot的迷你商城系統(tǒng),附源碼! IntelliJ IDEA 2020.2.4款 神級(jí)超級(jí)牛逼插件推薦
最近面試BAT,整理一份面試資料《Java面試BAT通關(guān)手冊(cè)》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫、數(shù)據(jù)結(jié)構(gòu)等等。 獲取方式:關(guān)注公眾號(hào)并回復(fù) java 領(lǐng)取,更多內(nèi)容陸續(xù)奉上。 明天見(??ω??)??