
pandas中使用 Merge、Join 、Concat 合并數(shù)據(jù)效率對(duì)比
↓推薦關(guān)注↓
來源:Deephub Imba
在 Pandas 中有很多種方法可以進(jìn)行dataframe(數(shù)據(jù)框)的合并。
本文將研究這些不同的方法,以及如何將它們執(zhí)行速度的對(duì)比。
合并DF
import pandas as pd
# a dictionary to convert to a dataframe
data1 = {'identification': ['a', 'b', 'c', 'd'],
'Customer_Name':['King', 'West', 'Adams', 'Mercy'], 'Category':['furniture', 'Office Supplies', 'Technology', 'R_materials'],}
# our second dictionary to convert to a dataframe
data2 = {'identification': ['a', 'b', 'c', 'd'],
'Class':['First_Class', 'Second_Class', 'Same_day', 'Standard Class'],
'Age':[60, 30, 40, 50]}
# Convert the dictionary into DataFrame
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
identification Customer_Name Category
0 a King furniture
1 b West Office Supplies
2 c Adams Technology
3 d Mercy R_materials
identification Class Age
0 a First_Class 60
1 b Second_Class 30
2 c Same_day 40
3 d Standard Class 50
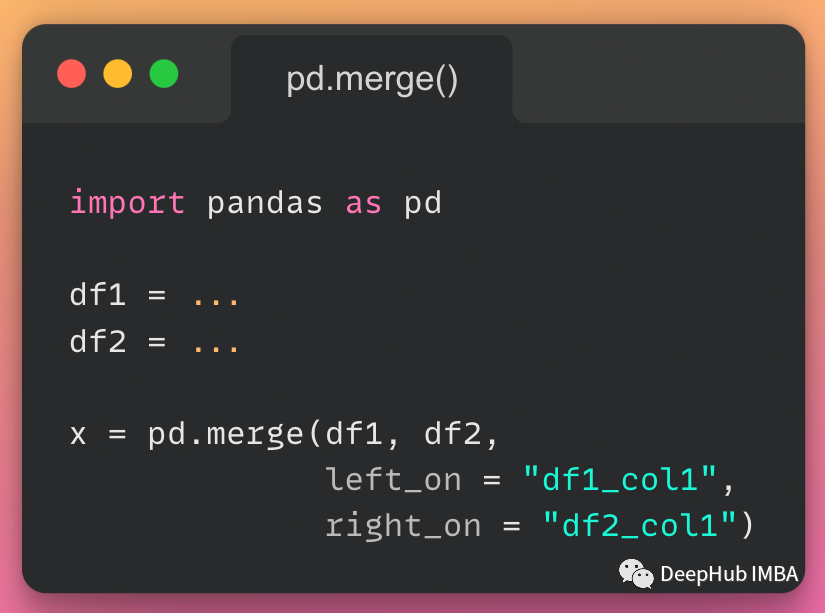
# using .merge() function
new_data = pd.merge(df1, df2, on='identification')
identification Customer_Name Category Class Age
0 a King furniture First_Class 60
1 b West Office Supplies Second_Class 30
2 c Adams Technology Same_day 40
3 d Mercy R_materials Standard Class 50
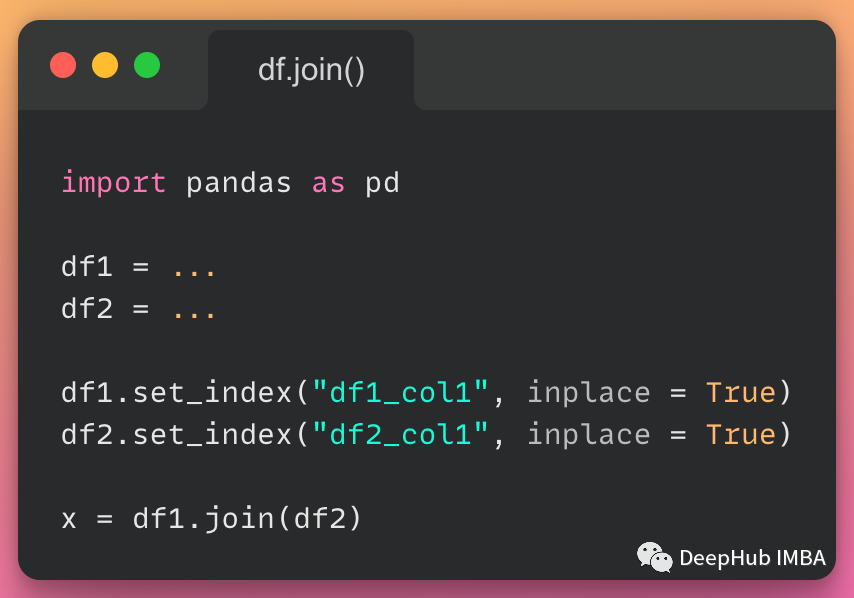
import pandas as pd
# a dictionary to convert to a dataframe
data1 = {
'Customer_Name':['King', 'West', 'Adams'],
'Category':['furniture', 'Office Supplies', 'Technology'],} 7
# our second dictionary to convert to a dataframe
data2 = {
'Class':['First_Class', 'Second_Class', 'Same_day', 'Standard Class'],
'Age':[60, 30, 40, 50]}
# Convert the dictionary into DataFrame
Ndata = pd.DataFrame(data1, index=pd.Index(['a', 'b', 'c'], name='identification'))
index = pd.MultiIndex.from_tuples([('a', 'x0'), ('b', 'x1'),
('c', 'x2'), ('c', 'x3')],
names=['identification', 'x']) 19
# Convert the dictionary into DataFrame
Ndata2 = pd.DataFrame(data2, index= index)
print(Ndata, "\n\n", Ndata2)
# joining singly indexed with
# multi indexed
result = Ndata.join(Ndata2, how='inner')
Customer_Name Category Class Age
identification x 3 a x0 King furniture First_Class 60
b x1 West Office Supplies Second_Class 30
c x2 Adams Technology Same_day 40
x3 Adams Technology Standard Class 50
連接DF
import pandas as pd
# a dictionary to convert to a dataframe
data1 = {'identification': ['a', 'b', 'c', 'd'],
'Customer_Name':['King', 'West', 'Adams', 'Mercy'],
'Category':['furniture', 'Office Supplies', 'Technology', 'R_materials'],}
# our second dictionary to convert to a dataframe
data2 = {'identification': ['a', 'b', 'c', 'd'],
'Class':['First_Class', 'Second_Class', 'Same_day', 'Standard Class'],
'Age':[60, 30, 40, 50]}
# Convert the dictionary into DataFrame
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
#perform concatenation here based on horizontal axis
new_data = pd.concat([df1, df2], axis=1)
print(new_data)
identification Customer_Name Category identification \
0 a King furniture a 3 1 b West Office Supplies b 4 2 c Adams Technology c 5 3 d Mercy R_materials d
Class Age
0 First_Class 60
1 Second_Class 30
2 Same_day 40
3 Standard Class 50
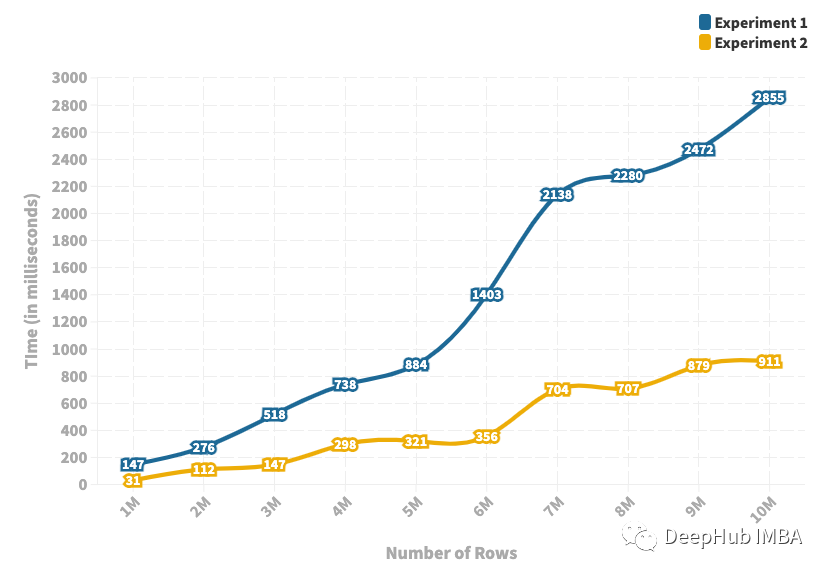
Merge和Join的效率對(duì)比
長(zhǎng)按或掃描下方二維碼,后臺(tái)回復(fù):加群,即可申請(qǐng)入群。一定要備注:來源+研究方向+學(xué)校/公司,否則不拉入群中,見諒!
(長(zhǎng)按三秒,進(jìn)入后臺(tái))
推薦閱讀
