
C 語言基礎(chǔ),來嘍!
前言
C 語言是一門抽象的、面向過程的語言,C 語言廣泛應(yīng)用于底層開發(fā),C 語言在計(jì)算機(jī)體系中占據(jù)著不可替代的作用,可以說 C 語言是編程的基礎(chǔ),也就是說,不管你學(xué)習(xí)任何語言,都應(yīng)該把 C 語言放在首先要學(xué)的位置上。下面這張圖更好的說明 C 語言的重要性

可以看到,C 語言是一種底層語言,是一種系統(tǒng)層級的語言,操作系統(tǒng)就是使用 C 語言來編寫的,比如 Windows、Linux、UNIX 。如果說其他語言是光鮮亮麗的外表,那么 C 語言就是靈魂,永遠(yuǎn)那么樸實(shí)無華。
C 語言特性
那么,既然 C 語言這么重要,它有什么值得我們?nèi)W(xué)的地方呢?我們不應(yīng)該只因?yàn)樗匾W(xué),我們更在意的是學(xué)完我們能學(xué)會什么,能讓我們獲得什么。
C 語言的設(shè)計(jì)
C 語言是 1972 年,由貝爾實(shí)驗(yàn)室的丹尼斯·里奇(Dennis Ritch)和肯·湯普遜(Ken Thompson)在開發(fā) UNIX 操作系統(tǒng)時(shí)設(shè)計(jì)了C語言。C 語言是一門流行的語言,它把計(jì)算機(jī)科學(xué)理論和工程實(shí)踐理論完美的融合在一起,使用戶能夠完成模塊化的編程和設(shè)計(jì)。
計(jì)算機(jī)科學(xué)理論:簡稱 CS、是系統(tǒng)性研究信息與計(jì)算的理論基礎(chǔ)以及它們在計(jì)算機(jī)系統(tǒng)中如何實(shí)現(xiàn)與應(yīng)用的實(shí)用技術(shù)的學(xué)科。
C 語言具有高效性
C 語言是一門高效性語言,它被設(shè)計(jì)用來充分發(fā)揮計(jì)算機(jī)的優(yōu)勢,因此 C 語言程序運(yùn)行速度很快,C 語言能夠合理了使用內(nèi)存來獲得最大的運(yùn)行速度
C 語言具有可移植性
C 語言是一門具有可移植性的語言,這就意味著,對于在一臺計(jì)算機(jī)上編寫的 C 語言程序可以在另一臺計(jì)算機(jī)上輕松地運(yùn)行,從而極大的減少了程序移植的工作量。
C 語言特點(diǎn)
C 語言是一門簡潔的語言,因?yàn)?C 語言設(shè)計(jì)更加靠近底層,因此不需要眾多 Java 、C# 等高級語言才有的特性,程序的編寫要求不是很嚴(yán)格。 C 語言具有結(jié)構(gòu)化控制語句,C 語言是一門結(jié)構(gòu)化的語言,它提供的控制語句具有結(jié)構(gòu)化特征,如 for 循環(huán)、if? else 判斷語句和 switch 語句等。 C 語言具有豐富的數(shù)據(jù)類型,不僅包含有傳統(tǒng)的字符型、整型、浮點(diǎn)型、數(shù)組類型等數(shù)據(jù)類型,還具有其他編程語言所不具備的數(shù)據(jù)類型,比如指針。 C 語言能夠直接對內(nèi)存地址進(jìn)行讀寫,因此可以實(shí)現(xiàn)匯編語言的主要功能,并可直接操作硬件。 C 語言速度快,生成的目標(biāo)代碼執(zhí)行效率高。
下面讓我們通過一個(gè)簡單的示例來說明一下 C 語言
入門級 C 語言程序
下面我們來看一個(gè)很簡單的 C 語言程序,我覺得工具無所謂大家用著順手就行。
第一個(gè) C 語言程序
#include?
int?main(int?argc,?const?char?*?argv[])?{
????printf("Hello,?World!\n");
??
???printf("my?Name?is?cxuan?\n")
????
????printf("number?=?%d?\n",?number);
????
????return?0;
}
你可能不知道這段代碼是什么意思,不過別著急,我們先運(yùn)行一下看看結(jié)果。
這段程序輸出了 Hello,World! 和 My Name is cxuan,下面我們解釋一下各行代碼的含義。
首先,第一行的 #include , 這行代碼包含另一個(gè)文件,這一行告訴編譯器把 stdio.h 的內(nèi)容包含在當(dāng)前程序中。stdio.h 是 C 編譯器軟件包的標(biāo)準(zhǔn)部分,它能夠提供鍵盤輸入和顯示器輸出。
什么是 C 標(biāo)準(zhǔn)軟件包?C 是由 Dennis M 在1972年開發(fā)的通用,過程性,命令式計(jì)算機(jī)編程語言。C標(biāo)準(zhǔn)庫是一組 C 語言內(nèi)置函數(shù),常量和頭文件,例如
, , 等。此庫將用作 C 程序員的參考手冊。
我們后面會介紹 stdio.h ,現(xiàn)在你知道它是什么就好。
在 stdio.h 下面一行代碼就是 main 函數(shù)。
C 程序能夠包含一個(gè)或多個(gè)函數(shù),函數(shù)是 C 語言的根本,就和方法是 Java 的基本構(gòu)成一樣。main() 表示一個(gè)函數(shù)名,int 表示的是 main 函數(shù)返回一個(gè)整數(shù)。void 表明 main() 不帶任何參數(shù)。這些我們后面也會詳細(xì)說明,只需要記住 int 和 void 是標(biāo)準(zhǔn) ANSI C 定義 main() 的一部分(如果使用 ANSI C 之前的編譯器,請忽略 void)。
然后是 /*一個(gè)簡單的 C 語言程序*/ 表示的是注釋,注釋使用 /**/ 來表示,注釋的內(nèi)容在兩個(gè)符號之間。這些符號能夠提高程序的可讀性。
注意:注釋只是為了幫助程序員理解代碼的含義,編譯器會忽略注釋
下面就是 { ,這是左花括號,它表示的是函數(shù)體的開始,而最后的右花括號 } 表示函數(shù)體的結(jié)束。{ } 中間是書寫代碼的地方,也叫做代碼塊。
int number 表示的是將會使用一個(gè)名為 number 的變量,而且 number 是 int 整數(shù)類型。
number = 11 表示的是把值 11 賦值給 number 的變量。
printf(Hello,world!\n); 表示調(diào)用一個(gè)函數(shù),這個(gè)語句使用 printf() 函數(shù),在屏幕上顯示 Hello,world , printf() 函數(shù)是 C 標(biāo)準(zhǔn)庫函數(shù)中的一種,它能夠把程序運(yùn)行的結(jié)果輸出到顯示器上。而代碼 \n 表示的是 換行,也就是另起一行,把光標(biāo)移到下一行。
然后接下來的一行 printf() 和上面一行是一樣的,我們就不多說了。最后一行 printf() 有點(diǎn)意思,你會發(fā)現(xiàn)有一個(gè) %d 的語法,它的意思表示的是使用整形輸出字符串。
代碼塊的最后一行是 return 0,它可以看成是 main 函數(shù)的結(jié)束,最后一行是代碼塊 } ,它表示的是程序的結(jié)束。
好了,我們現(xiàn)在寫完了第一個(gè) C 語言程序,有沒有對 C 有了更深的認(rèn)識呢?肯定沒有。。。這才哪到哪,繼續(xù)學(xué)習(xí)吧。
現(xiàn)在,我們可以歸納為 C 語言程序的幾個(gè)組成要素,如下圖所示
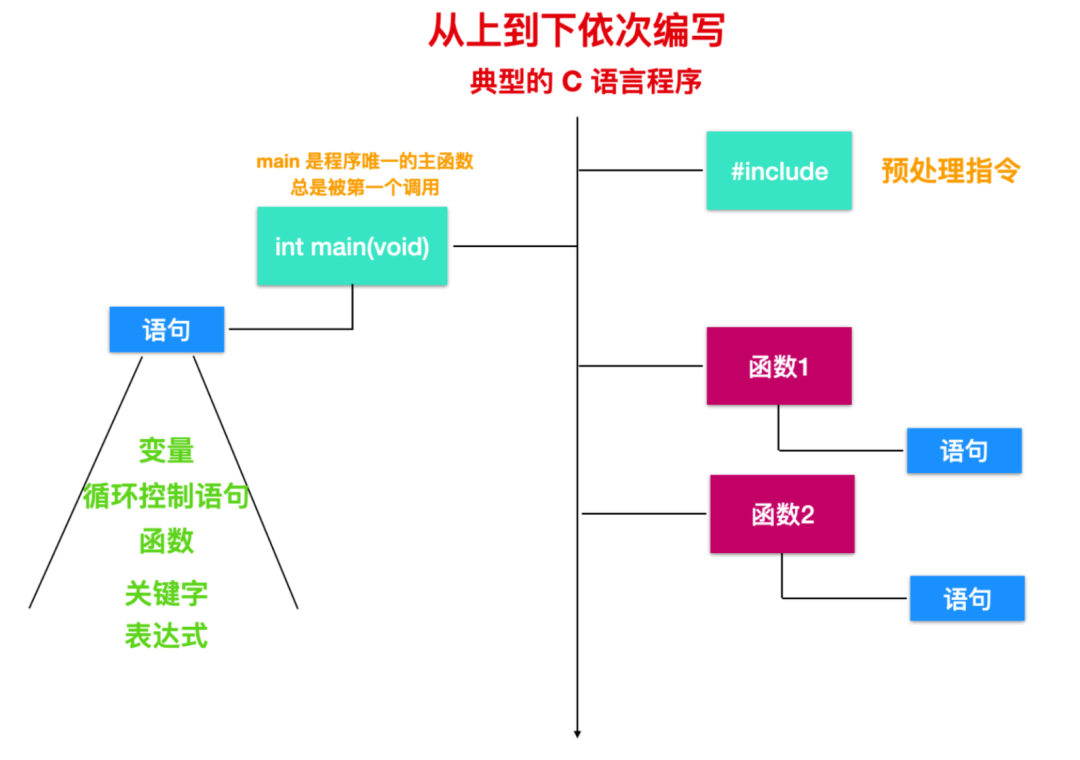
C 語言執(zhí)行流程
C 語言程序成為高級語言的原因是它能夠讀取并理解人們的思想。然而,為了能夠在系統(tǒng)中運(yùn)行 hello.c 程序,則各個(gè) C 語句必須由其他程序轉(zhuǎn)換為一系列低級機(jī)器語言指令。這些指令被打包作為可執(zhí)行對象程序,存儲在二進(jìn)制磁盤文件中。目標(biāo)程序也稱為可執(zhí)行目標(biāo)文件。
在 UNIX 系統(tǒng)中,從源文件到對象文件的轉(zhuǎn)換是由編譯器執(zhí)行完成的。
gcc?-o?hello?hello.c
gcc 編譯器驅(qū)動從源文件讀取 hello.c ,并把它翻譯成一個(gè)可執(zhí)行文件 hello。這個(gè)翻譯過程可用如下圖來表示
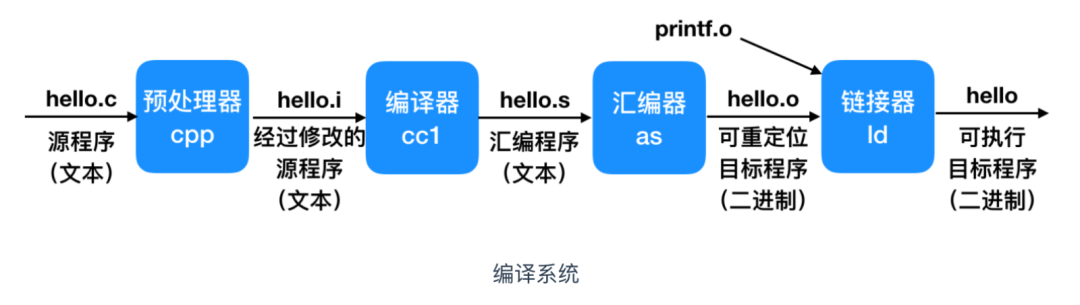
這就是一個(gè)完整的 hello world 程序執(zhí)行過程,會涉及幾個(gè)核心組件:預(yù)處理器、編譯器、匯編器、連接器,下面我們逐個(gè)擊破。
預(yù)處理階段(Preprocessing phase),預(yù)處理器會根據(jù)開始的#字符,修改源 C 程序。#include命令就會告訴預(yù)處理器去讀系統(tǒng)頭文件 stdio.h中的內(nèi)容,并把它插入到程序作為文本。然后就得到了另外一個(gè) C 程序hello.i,這個(gè)程序通常是以.i為結(jié)尾。然后是
編譯階段(Compilation phase),編譯器會把文本文件hello.i翻譯成文本hello.s,它包括一段匯編語言程序(assembly-language program)。編譯完成之后是
匯編階段(Assembly phase),這一步,匯編器 as會把 hello.s 翻譯成機(jī)器指令,把這些指令打包成可重定位的二進(jìn)制程序(relocatable object program)放在 hello.c 文件中。它包含的 17 個(gè)字節(jié)是函數(shù) main 的指令編碼,如果我們在文本編輯器中打開 hello.o 將會看到一堆亂碼。最后一個(gè)是
鏈接階段(Linking phase),我們的 hello 程序會調(diào)用printf函數(shù),它是 C 編譯器提供的 C 標(biāo)準(zhǔn)庫中的一部分。printf 函數(shù)位于一個(gè)叫做printf.o文件中,它是一個(gè)單獨(dú)的預(yù)編譯好的目標(biāo)文件,而這個(gè)文件必須要和我們的 hello.o 進(jìn)行鏈接,連接器(ld)會處理這個(gè)合并操作。結(jié)果是,hello 文件,它是一個(gè)可執(zhí)行的目標(biāo)文件(或稱為可執(zhí)行文件),已準(zhǔn)備好加載到內(nèi)存中并由系統(tǒng)執(zhí)行。
你需要理解編譯系統(tǒng)做了什么
對于上面這種簡單的 hello 程序來說,我們可以依賴編譯系統(tǒng)(compilation system)來提供一個(gè)正確和有效的機(jī)器代碼。然而,對于我們上面講的程序員來說,編譯器有幾大特征你需要知道
優(yōu)化程序性能(Optimizing program performance),現(xiàn)代編譯器是一種高效的用來生成良好代碼的工具。對于程序員來說,你無需為了編寫高質(zhì)量的代碼而去理解編譯器內(nèi)部做了什么工作。然而,為了編寫出高效的 C 語言程序,我們需要了解一些基本的機(jī)器碼以及編譯器將不同的 C 語句轉(zhuǎn)化為機(jī)器代碼的過程。理解鏈接時(shí)出現(xiàn)的錯(cuò)誤(Understanding link-time errors),在我們的經(jīng)驗(yàn)中,一些非常復(fù)雜的錯(cuò)誤大多是由鏈接階段引起的,特別是當(dāng)你想要構(gòu)建大型軟件項(xiàng)目時(shí)。避免安全漏洞(Avoiding security holes),近些年來,緩沖區(qū)溢出(buffer overflow vulnerabilities)是造成網(wǎng)絡(luò)和 Internet 服務(wù)的罪魁禍?zhǔn)祝晕覀冇斜匾ヒ?guī)避這種問題。
系統(tǒng)硬件組成
為了理解 hello 程序在運(yùn)行時(shí)發(fā)生了什么,我們需要首先對系統(tǒng)的硬件有一個(gè)認(rèn)識。下面這是一張 Intel 系統(tǒng)產(chǎn)品的模型,我們來對其進(jìn)行解釋
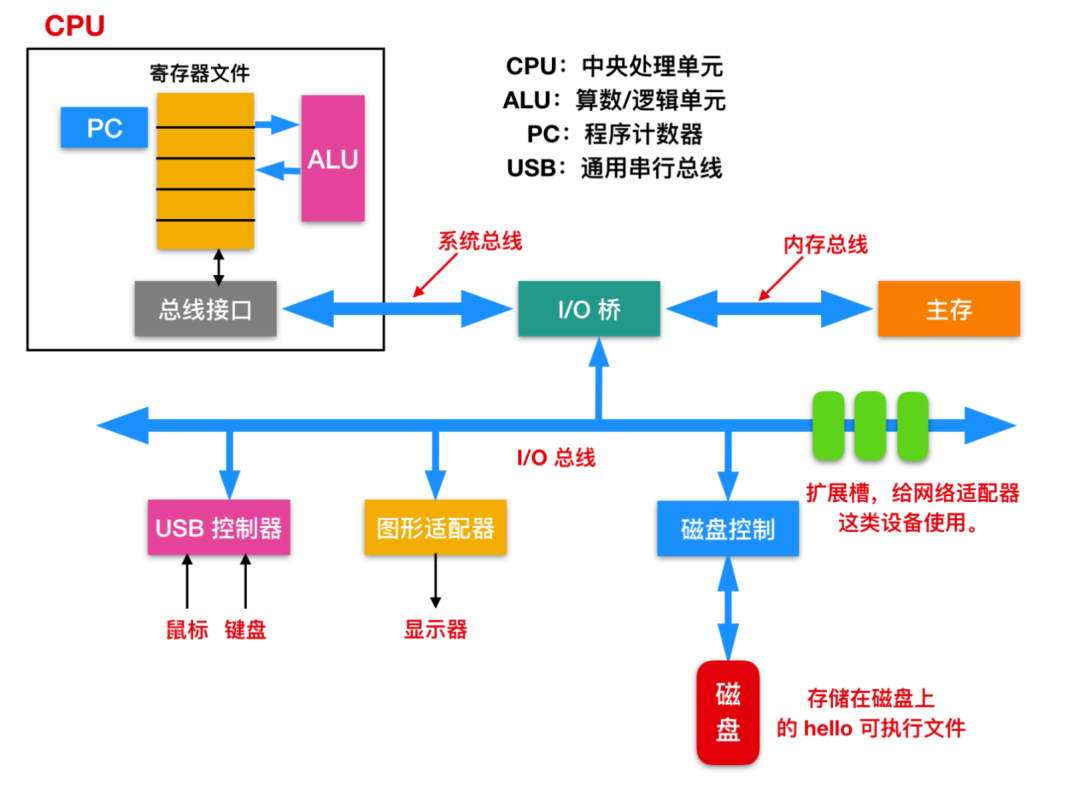
總線(Buses):在整個(gè)系統(tǒng)中運(yùn)行的是稱為總線的電氣管道的集合,這些總線在組件之間來回傳輸字節(jié)信息。通常總線被設(shè)計(jì)成傳送定長的字節(jié)塊,也就是字(word)。字中的字節(jié)數(shù)(字長)是一個(gè)基本的系統(tǒng)參數(shù),各個(gè)系統(tǒng)中都不盡相同。現(xiàn)在大部分的字都是 4 個(gè)字節(jié)(32 位)或者 8 個(gè)字節(jié)(64 位)。
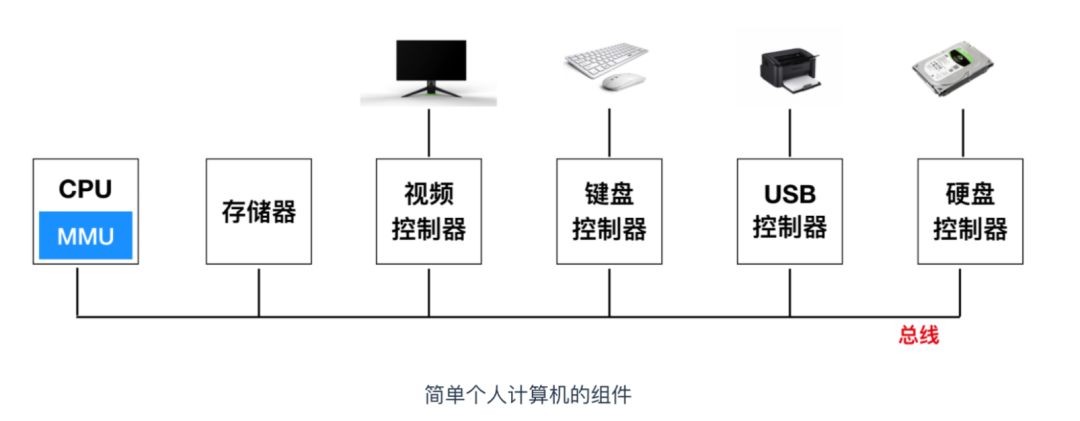
I/O 設(shè)備(I/O Devices):Input/Output 設(shè)備是系統(tǒng)和外部世界的連接。上圖中有四類 I/O 設(shè)備:用于用戶輸入的鍵盤和鼠標(biāo),用于用戶輸出的顯示器,一個(gè)磁盤驅(qū)動用來長時(shí)間的保存數(shù)據(jù)和程序。剛開始的時(shí)候,可執(zhí)行程序就保存在磁盤上。每個(gè)I/O 設(shè)備連接 I/O 總線都被稱為
控制器(controller)或者是適配器(Adapter)。控制器和適配器之間的主要區(qū)別在于封裝方式。控制器是 I/O 設(shè)備本身或者系統(tǒng)的主印制板電路(通常稱作主板)上的芯片組。而適配器則是一塊插在主板插槽上的卡。無論組織形式如何,它們的最終目的都是彼此交換信息。主存(Main Memory),主存是一個(gè)臨時(shí)存儲設(shè)備,而不是永久性存儲,磁盤是永久性存儲的設(shè)備。主存既保存程序,又保存處理器執(zhí)行流程所處理的數(shù)據(jù)。從物理組成上說,主存是由一系列DRAM(dynamic random access memory)動態(tài)隨機(jī)存儲構(gòu)成的集合。邏輯上說,內(nèi)存就是一個(gè)線性的字節(jié)數(shù)組,有它唯一的地址編號,從 0 開始。一般來說,組成程序的每條機(jī)器指令都由不同數(shù)量的字節(jié)構(gòu)成,C 程序變量相對應(yīng)的數(shù)據(jù)項(xiàng)的大小根據(jù)類型進(jìn)行變化。比如,在 Linux 的 x86-64 機(jī)器上,short 類型的數(shù)據(jù)需要 2 個(gè)字節(jié),int 和 float 需要 4 個(gè)字節(jié),而 long 和 double 需要 8 個(gè)字節(jié)。處理器(Processor),CPU(central processing unit)?或者簡單的處理器,是解釋(并執(zhí)行)存儲在主存儲器中的指令的引擎。處理器的核心大小為一個(gè)字的存儲設(shè)備(或寄存器),稱為程序計(jì)數(shù)器(PC)。在任何時(shí)刻,PC 都指向主存中的某條機(jī)器語言指令(即含有該條指令的地址)。從系統(tǒng)通電開始,直到系統(tǒng)斷電,處理器一直在不斷地執(zhí)行程序計(jì)數(shù)器指向的指令,再更新程序計(jì)數(shù)器,使其指向下一條指令。處理器根據(jù)其指令集體系結(jié)構(gòu)定義的指令模型進(jìn)行操作。在這個(gè)模型中,指令按照嚴(yán)格的順序執(zhí)行,執(zhí)行一條指令涉及執(zhí)行一系列的步驟。處理器從程序計(jì)數(shù)器指向的內(nèi)存中讀取指令,解釋指令中的位,執(zhí)行該指令指示的一些簡單操作,然后更新程序計(jì)數(shù)器以指向下一條指令。指令與指令之間可能連續(xù),可能不連續(xù)(比如 jmp 指令就不會順序讀取)
下面是 CPU 可能執(zhí)行簡單操作的幾個(gè)步驟
加載(Load):從主存中拷貝一個(gè)字節(jié)或者一個(gè)字到內(nèi)存中,覆蓋寄存器先前的內(nèi)容存儲(Store):將寄存器中的字節(jié)或字復(fù)制到主存儲器中的某個(gè)位置,從而覆蓋該位置的先前內(nèi)容操作(Operate):把兩個(gè)寄存器的內(nèi)容復(fù)制到ALU(Arithmetic logic unit)。把兩個(gè)字進(jìn)行算術(shù)運(yùn)算,并把結(jié)果存儲在寄存器中,重寫寄存器先前的內(nèi)容。
算術(shù)邏輯單元(ALU)是對數(shù)字二進(jìn)制數(shù)執(zhí)行算術(shù)和按位運(yùn)算的組合數(shù)字電子電路。
跳轉(zhuǎn)(jump):從指令中抽取一個(gè)字,把這個(gè)字復(fù)制到程序計(jì)數(shù)器(PC)中,覆蓋原來的值
剖析 hello 程序的執(zhí)行過程
前面我們簡單的介紹了一下計(jì)算機(jī)的硬件的組成和操作,現(xiàn)在我們正式介紹運(yùn)行示例程序時(shí)發(fā)生了什么,我們會從宏觀的角度進(jìn)行描述,不會涉及到所有的技術(shù)細(xì)節(jié)
剛開始時(shí),shell 程序執(zhí)行它的指令,等待用戶鍵入一個(gè)命令。當(dāng)我們在鍵盤上輸入了 ./hello 這幾個(gè)字符時(shí),shell 程序?qū)⒆址鹨蛔x入寄存器,再把它放到內(nèi)存中,如下圖所示
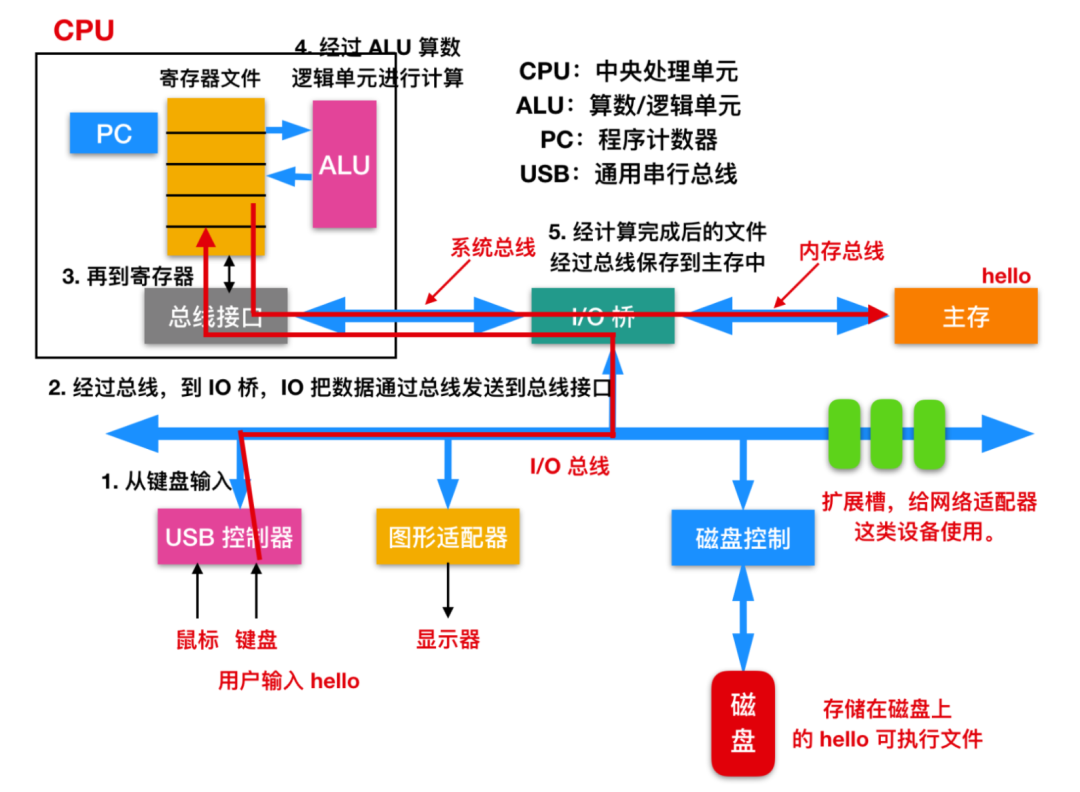
當(dāng)我們在鍵盤上敲擊回車鍵的時(shí)候,shell 程序就知道我們已經(jīng)結(jié)束了命令的輸入。然后 shell 執(zhí)行一系列指令來加載可執(zhí)行的 hello 文件,這些指令將目標(biāo)文件中的代碼和數(shù)據(jù)從磁盤復(fù)制到主存。
利用 DMA(Direct Memory Access) 技術(shù)可以直接將磁盤中的數(shù)據(jù)復(fù)制到內(nèi)存中,如下

一旦目標(biāo)文件中 hello 中的代碼和數(shù)據(jù)被加載到主存,處理器就開始執(zhí)行 hello 程序的 main 程序中的機(jī)器語言指令。這些指令將 hello,world\n 字符串中的字節(jié)從主存復(fù)制到寄存器文件,再從寄存器中復(fù)制到顯示設(shè)備,最終顯示在屏幕上。如下所示
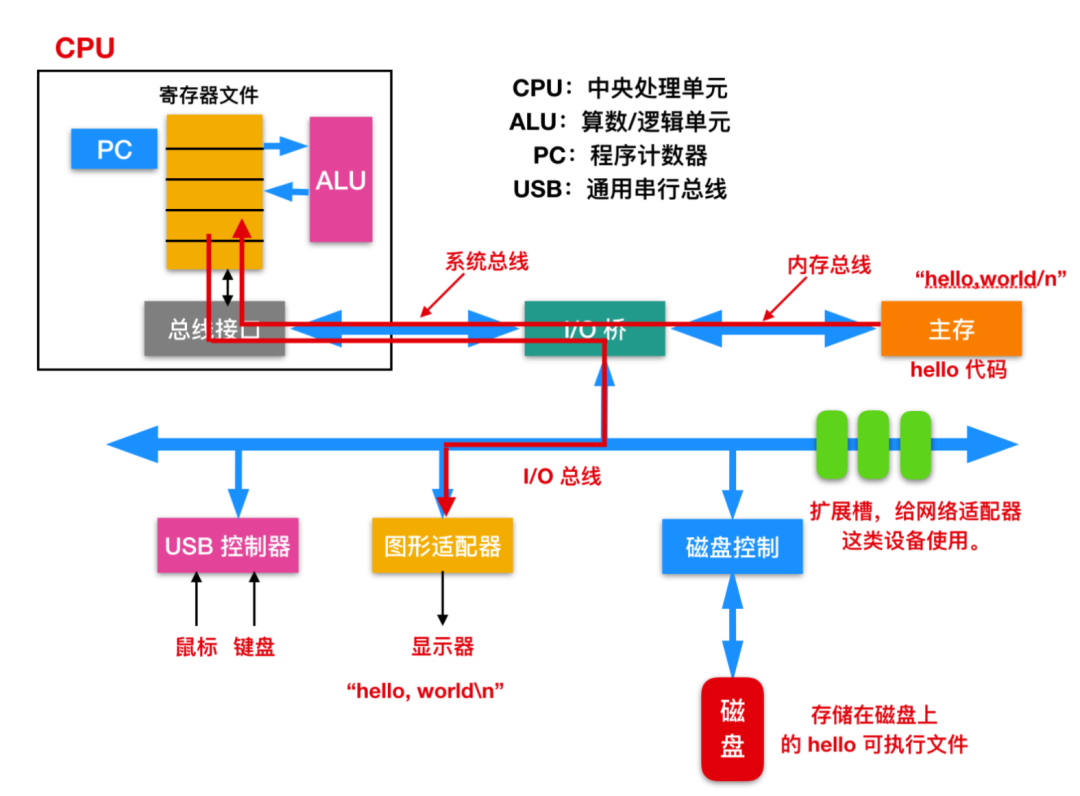
高速緩存是關(guān)鍵
上面我們介紹完了一個(gè) hello 程序的執(zhí)行過程,系統(tǒng)花費(fèi)了大量時(shí)間把信息從一個(gè)地方搬運(yùn)到另外一個(gè)地方。hello 程序的機(jī)器指令最初存儲在磁盤上。當(dāng)程序加載后,它們會拷貝到主存中。當(dāng) CPU 開始運(yùn)行時(shí),指令又從內(nèi)存復(fù)制到 CPU 中。同樣的,字符串?dāng)?shù)據(jù) hello,world \n 最初也是在磁盤上,它被復(fù)制到內(nèi)存中,然后再到顯示器設(shè)備輸出。從程序員的角度來看,這種復(fù)制大部分是開銷,這減慢了程序的工作效率。因此,對于系統(tǒng)設(shè)計(jì)來說,最主要的一個(gè)工作是讓程序運(yùn)行的越來越快。
由于物理定律,較大的存儲設(shè)備要比較小的存儲設(shè)備慢。而由于寄存器和內(nèi)存的處理效率在越來越大,所以針對這種差異,系統(tǒng)設(shè)計(jì)者采用了更小更快的存儲設(shè)備,稱為高速緩存存儲器(cache memory, 簡稱為 cache 高速緩存),作為暫時(shí)的集結(jié)區(qū)域,存放近期可能會需要的信息。如下圖所示
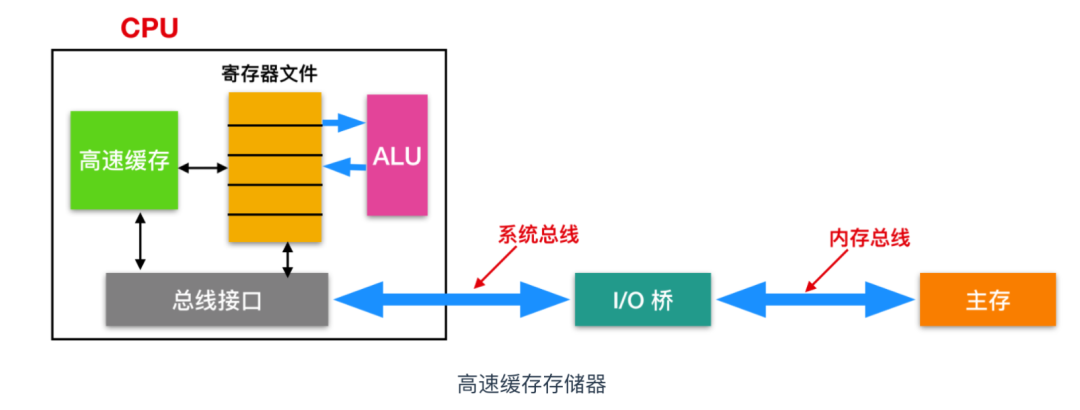
圖中我們標(biāo)出了高速緩存的位置,位于高速緩存中的 L1高速緩存容量可以達(dá)到數(shù)萬字節(jié),訪問速度幾乎和訪問寄存器文件一樣快。容量更大的 L2 高速緩存通過一條特殊的總線鏈接 CPU,雖然 L2 緩存比 L1 緩存慢 5 倍,但是仍比內(nèi)存要哦快 5 - 10 倍。L1 和 L2 是使用一種靜態(tài)隨機(jī)訪問存儲器(SRAM) 的硬件技術(shù)實(shí)現(xiàn)的。最新的、處理器更強(qiáng)大的系統(tǒng)甚至有三級緩存:L1、L2 和 L3。系統(tǒng)可以獲得一個(gè)很大的存儲器,同時(shí)訪問速度也更快,原因是利用了高速緩存的 局部性原理。
Again:入門程序細(xì)節(jié)
現(xiàn)在,我們來探討一下入門級程序的細(xì)節(jié),由淺入深的來了解一下 C 語言的特性。
#include
我們上面說到,#include 是程序編譯之前要處理的內(nèi)容,稱為編譯預(yù)處理命令。
預(yù)處理命令是在編譯之前進(jìn)行處理。預(yù)處理程序一般以 # 號開頭。
所有的 C 編譯器軟件包都提供 stdio.h 文件。該文件包含了給編譯器使用的輸入和輸出函數(shù),比如 println() 信息。該文件名的含義是標(biāo)準(zhǔn)輸入/輸出 頭文件。通常,在 C 程序頂部的信息集合被稱為 頭文件(header)。
C 的第一個(gè)標(biāo)準(zhǔn)是由 ANSI 發(fā)布的。雖然這份文檔后來被國際標(biāo)準(zhǔn)化組織(ISO)采納并且 ISO 發(fā)布的修訂版也被 ANSI 采納了,但名稱 ANSI C(而不是 ISO C) 仍被廣泛使用。一些軟件開發(fā)者使用ISO C,還有一些使用 Standard C。
C 標(biāo)準(zhǔn)庫
除了

提供了一個(gè)名為 assert 的關(guān)鍵字,它用于驗(yàn)證程序作出的假設(shè),并在假設(shè)為假輸出診斷消息。
C 標(biāo)準(zhǔn)庫的 ctype.h 頭文件提供了一些函數(shù),可以用于測試和映射字符。
這些字符接受 int 作為參數(shù),它的值必須是 EOF 或者是一個(gè)無符號字符
EOF是一個(gè)計(jì)算機(jī)術(shù)語,為 End Of File 的縮寫,在操作系統(tǒng)中表示資料源無更多的資料可讀取。資料源通常稱為檔案或串流。通常在文本的最后存在此字符表示資料結(jié)束。
C 標(biāo)準(zhǔn)庫的 errno.h 頭文件定義了整數(shù)變量 errno,它是通過系統(tǒng)調(diào)用設(shè)置的,這些庫函數(shù)表明了什么發(fā)生了錯(cuò)誤。
C 標(biāo)準(zhǔn)庫的 float.h 頭文件包含了一組與浮點(diǎn)值相關(guān)的依賴于平臺的常量。
limits.h 頭文件決定了各種變量類型的各種屬性。定義在該頭文件中的宏限制了各種變量類型(比如 char、int 和 long)的值。
locale.h 頭文件定義了特定地域的設(shè)置,比如日期格式和貨幣符號
math.h 頭文件定義了各種數(shù)學(xué)函數(shù)和一個(gè)宏。在這個(gè)庫中所有可用的功能都帶有一個(gè) double 類型的參數(shù),且都返回 double 類型的結(jié)果。
setjmp.h 頭文件定義了宏 setjmp()、函數(shù) longjmp() 和變量類型 jmp_buf,該變量類型會繞過正常的函數(shù)調(diào)用和返回規(guī)則。
signal.h 頭文件定義了一個(gè)變量類型 sig_atomic_t、兩個(gè)函數(shù)調(diào)用和一些宏來處理程序執(zhí)行期間報(bào)告的不同信號。
stdarg.h 頭文件定義了一個(gè)變量類型 va_list 和三個(gè)宏,這三個(gè)宏可用于在參數(shù)個(gè)數(shù)未知(即參數(shù)個(gè)數(shù)可變)時(shí)獲取函數(shù)中的參數(shù)。
stddef .h 頭文件定義了各種變量類型和宏。這些定義中的大部分也出現(xiàn)在其它頭文件中。
stdlib .h 頭文件定義了四個(gè)變量類型、一些宏和各種通用工具函數(shù)。
string .h 頭文件定義了一個(gè)變量類型、一個(gè)宏和各種操作字符數(shù)組的函數(shù)。
time.h 頭文件定義了四個(gè)變量類型、兩個(gè)宏和各種操作日期和時(shí)間的函數(shù)。
main() 函數(shù)
main 函數(shù)聽起來像是調(diào)皮搗蛋的孩子故意給方法名起一個(gè) 主要的 方法,來告訴他人他才是這個(gè)世界的中心。但事實(shí)卻不是這樣,而 main() 方法確實(shí)是世界的中心。
C 語言程序一定從 main() 函數(shù)開始執(zhí)行,除了 main() 函數(shù)外,你可以隨意命名其他函數(shù)。通常,main 后面的 () 中表示一些傳入信息,我們上面的那個(gè)例子中沒有傳遞信息,因?yàn)閳A括號中的輸入是 void 。
除了上面那種寫法外,還有兩種 main 方法的表示方式,一種是 void main(){} ,一種是 int main(int argc, char* argv[]) {}
void main() 聲明了一個(gè)帶有不確定參數(shù)的構(gòu)造方法 int main(int argc, char* argv[]) {} 其中的 argc 是一個(gè)非負(fù)值,表示從運(yùn)行程序的環(huán)境傳遞到程序的參數(shù)數(shù)量。它是指向 argc + 1 指針數(shù)組的第一個(gè)元素的指針,其中最后一個(gè)為null,而前一個(gè)(如果有的話)指向表示從主機(jī)環(huán)境傳遞給程序的參數(shù)的字符串。如果argv [0]不是空指針(或者等效地,如果argc> 0),則指向表示程序名稱的字符串,如果在主機(jī)環(huán)境中無法使用程序名稱,則該字符串為空。
注釋
在程序中,使用 /**/ 的表示注釋,注釋對于程序來說沒有什么實(shí)際用處,但是對程序員來說卻非常有用,它能夠幫助我們理解程序,也能夠讓他人看懂你寫的程序,我們在開發(fā)工作中,都非常反感不寫注釋的人,由此可見注釋非常重要。
C 語言注釋的好處是,它可以放在任意地方,甚至代碼在同一行也沒關(guān)系。較長的注釋可以多行表示,我們使用 /**/ 表示多行注釋,而 // 只表示的是單行注釋。下面是幾種注釋的表示形式
//?這是一個(gè)單行注釋
/*?多行注釋用一行表示?*/
/*
??多行注釋用多行表示
????多行注釋用多行表示
??????多行注釋用多行表示
????????多行注釋用多行表示
*/
函數(shù)體
在頭文件、main 方法后面的就是函數(shù)體(注釋一般不算),函數(shù)體就是函數(shù)的執(zhí)行體,是你編寫大量代碼的地方。
變量聲明
在我們?nèi)腴T級的代碼中,我們聲明了一個(gè)名為 number 的變量,它的類型是 int,這行代碼叫做 聲明,聲明是 C 語言最重要的特性之一。這個(gè)聲明完成了兩件事情:定義了一個(gè)名為 number 的變量,定義 number 的具體類型。
int 是 C 語言的一個(gè) 關(guān)鍵字(keyword),表示一種基本的 C 語言數(shù)據(jù)類型。關(guān)鍵字是用于語言定義的。不能使用關(guān)鍵字作為變量進(jìn)行定義。
示例中的 number 是一個(gè) 標(biāo)識符(identifier),也就是一個(gè)變量、函數(shù)或者其他實(shí)體的名稱。
###變量賦值
在入門例子程序中,我們聲明了一個(gè) number 變量,并為其賦值為 11,賦值是 C 語言的基本操作之一。這行代碼的意思就是把值 1 賦給變量 number。在執(zhí)行 int number 時(shí),編譯器會在計(jì)算機(jī)內(nèi)存中為變量 number 預(yù)留空間,然后在執(zhí)行這行賦值表達(dá)式語句時(shí),把值存儲在之前預(yù)留的位置。可以給 number 賦不同的值,這就是 number 之所以被稱為 變量(variable) 的原因。

printf 函數(shù)
在入門例子程序中,有三行 printf(),這是 ?C 語言的標(biāo)準(zhǔn)函數(shù)。圓括號中的內(nèi)容是從 main 函數(shù)傳遞給 printf 函數(shù)的。參數(shù)分為兩種:實(shí)際參數(shù)(actual argument) 和 形式參數(shù)(formal parameters)。我們上面提到的 printf 函數(shù)括號中的內(nèi)容,都是實(shí)參。
return 語句
在入門例子程序中,return 語句是最后一條語句。int main(void) 中的 int 表明 main() 函數(shù)應(yīng)返回一個(gè)整數(shù)。有返回值的 C 函數(shù)要有 return 語句,沒有返回值的程序也建議大家保留 return 關(guān)鍵字,這是一種好的習(xí)慣或者說統(tǒng)一的編碼風(fēng)格。
分號
在 C 語言中,每一行的結(jié)尾都要用 ; 進(jìn)行結(jié)束,它表示一個(gè)語句的結(jié)束,如果忘記或者會略分號會被編譯器提示錯(cuò)誤。
關(guān)鍵字
下面是 C 語言中的關(guān)鍵字,C 語言的關(guān)鍵字一共有 32 個(gè),根據(jù)其作用不同進(jìn)行劃分
數(shù)據(jù)類型關(guān)鍵字
數(shù)據(jù)類型的關(guān)鍵字主要有 12 個(gè),分別是
char: 聲明字符型變量或函數(shù)double: 聲明雙精度變量或函數(shù)float: 聲明浮點(diǎn)型變量或函數(shù)int: 聲明整型變量或函數(shù)long: 聲明長整型變量或函數(shù)short: 聲明短整型變量或函數(shù)signed: 聲明有符號類型變量或函數(shù)_Bool: ?聲明布爾類型_Complex:聲明復(fù)數(shù)_Imaginary: 聲明虛數(shù)unsigned: 聲明無符號類型變量或函數(shù)void: 聲明函數(shù)無返回值或無參數(shù),聲明無類型指針
控制語句關(guān)鍵字
控制語句循環(huán)的關(guān)鍵字也有 12 個(gè),分別是
循環(huán)語句
for: for 循環(huán),使用的最多do:循環(huán)語句的前提條件循環(huán)體while:循環(huán)語句的循環(huán)條件break: 跳出當(dāng)前循環(huán)continue:結(jié)束當(dāng)前循環(huán),開始下一輪循環(huán)
條件語句
if:條件語句的判斷條件else: 條件語句的否定分支,與 if 連用goto: 無條件跳轉(zhuǎn)語句
開關(guān)語句
switch: 用于開關(guān)語句case:開關(guān)語句的另外一種分支default: 開關(guān)語句中的其他分支
返回語句
retur:子程序返回語句(可以帶參數(shù),也看不帶參數(shù))
存儲類型關(guān)鍵字
auto: 聲明自動變量 一般不使用extern: 聲明變量是在其他文件正聲明(也可以看做是引用變量)register: 聲明寄存器變量static: 聲明靜態(tài)變量
其他關(guān)鍵字
const: 聲明只讀變量sizeof: 計(jì)算數(shù)據(jù)類型長度typedef: 用以給數(shù)據(jù)類型取別名volatile: 說明變量在程序執(zhí)行中可被隱含地改變
C 中的數(shù)據(jù)
我們在了解完上面的入門例子程序后,下面我們就要全面認(rèn)識一下 C 語言程序了,首先我們先來認(rèn)識一下 C 語言最基本的變量與常量。
變量和常量
變量和常量是程序處理的兩種基本對象。
有些數(shù)據(jù)類型在程序使用之前就已經(jīng)被設(shè)定好了,在整個(gè)過程中沒有變化(這段話描述不準(zhǔn)確,但是為了通俗易懂,暫且這么描述),這種數(shù)據(jù)被稱為常量(constant)。另外一種數(shù)據(jù)類型在程序執(zhí)行期間可能會發(fā)生改變,這種數(shù)據(jù)類型被稱為 變量(variable)。例如 int number 就是一個(gè)變量,而3.1415 就是一個(gè)常量,因?yàn)?int number 一旦聲明出來,你可以對其任意賦值,而 3.1415 一旦聲明出來,就不會再改變。
變量名
有必要在聊數(shù)據(jù)類型之前先說一說變量名的概念。變量名是由字母和數(shù)字組成的序列,第一個(gè)字符必須是字母。在變量名的命名過程中,下劃線 _ 被看作字母,下劃線一般用于名稱較長的變量名,這樣能夠提高程序的可讀性。變量名通常不會以下劃線來開頭。在 C 中,大小寫是有區(qū)別的,也就是說,a 和 A 完全是兩個(gè)不同的變量。一般變量名使用小寫字母,符號常量(#define 定義的)全都使用大寫。選擇變量名的時(shí)候,盡量能夠從字面上描述出變量的用途,切忌起這種 abc 毫無意義的變量。
還需要注意一般局部變量都會使用較短的變量名,外部變量使用較長的名字。
數(shù)據(jù)類型
在了解數(shù)據(jù)類型之前,我們需要先了解一下這些概念 位、字節(jié)和字。
位、字節(jié)和字都是對計(jì)算機(jī)存儲單元的描述。在計(jì)算機(jī)世界中,最小的單元是
位(bit),一個(gè)位就表示一個(gè) 0 或 1,一般當(dāng)你的小伙伴問你的電腦是 xxx 位,常見的有 32 位或者 64 位,這里的位就指的是比特,比特就是 bit 的中文名稱,所以這里的 32 位或者 64 位指的就是 32 bit 或者 64 bit。字節(jié)是基本的存儲單元,基本存儲單元說的是在計(jì)算機(jī)中都是按照字節(jié)來存儲的,一個(gè)字節(jié)等于 8 位,即 1 byte = 8 bit。字是自然存儲單位,在現(xiàn)代計(jì)算機(jī)中,一個(gè)字等于 2 字節(jié)。
C 語言的數(shù)據(jù)類型有很多,下面我們就來依次介紹一下。
整型
C 語言中的整型用 int 來表示,可以是正整數(shù)、負(fù)整數(shù)或零。在不同位數(shù)的計(jì)算機(jī)中其取值范圍也不同。不過在 32 位和 64 位計(jì)算機(jī)中,int 的取值范圍是都是 2^32 ,也就是 -2147483648 ~ +2147483647,無符號類型的取值范圍是 0 ~ 4294967295。
整型以二進(jìn)制整數(shù)存儲,分為有符號數(shù)和無符號數(shù)兩種形態(tài),有符號數(shù)可以存儲正整數(shù)、負(fù)整數(shù)和零;無符號只能存儲正整數(shù)和零。
可以使用 printf 打印出來 int 類型的值,如下代碼所示。
#include??
int?main(){
?int?a?=?-5;
?printf("%d\n",a);
?
?unsigned?int?b?=?6;
?printf("%d\n",b);
?
}
C 語言還提供 3 個(gè)附屬關(guān)鍵字修飾整數(shù)類型,即 short、long 和 unsigned。
short int 類型(或者簡寫為 short)占用的存儲空間 可能比 int 類型少,適合用于數(shù)值較小的場景。long int 或者 long 占用的存儲空間 可能比 int 類型多,適合用于數(shù)值較大的場景。long long int 或者 long long(C99 加入)占用的存儲空間比 long 多,適用于數(shù)值更大的場合,至少占用 64 位,與 int 類似,long long 也是有符號類型。 unsigned int 或 unsigned 只用于非負(fù)值的場景,這種類型的取值范圍有所不同,比如 16 位的 unsigned int 表示的范圍是 0 ~ 65535 ,而不是 -32768 ~ 32767。 在 C90 標(biāo)準(zhǔn)中,添加了 unsigned long int 或者 unsigned long 和 unsigned short int 或 unsigned short 類型,在 C99 中又添加了 unsigned long long int 或者 unsigned long long 。 在任何有符號類型前面加 signed ,可強(qiáng)調(diào)使用有符號類型的意圖。比如 short、short int、signed short、signed short int 都表示一種類型。
比如上面這些描述可以用下面這些代碼來聲明:
long?int?lia;
long?la;
long?long?lla;
short?int?sib;
short?sb;
unsigned?int?uic;
unsigned?uc;
unsigned?long?uld;
unsigned?short?usd;
這里需要注意一點(diǎn),unsigned 定義的變量,按照 printf 格式化輸出時(shí),是能夠顯示負(fù)值的,為什么呢?不是 unsigned 修飾的值不能是負(fù)值啊,那是因?yàn)?unsigned 修飾的變量,在計(jì)算時(shí)會有用,輸出沒什么影響,這也是 cxuan 剛開始學(xué)習(xí)的時(shí)候踩的坑。
我們學(xué)過 Java 的同學(xué)剛開始都對這些定義覺得莫名其妙,為什么一個(gè) C 語言要對數(shù)據(jù)類型有這么多定義?C 語言真麻煩,我不學(xué)了!
千萬不要有這種想法,如果有這種想法的同學(xué),你一定是被 JVM 保護(hù)的像個(gè)孩子!我必須從現(xiàn)在開始糾正你的這個(gè)想法,因?yàn)?Java 有 JVM 的保護(hù),很多特性都做了優(yōu)化,而 C 就像個(gè)沒有傘的孩子,它必須自己和這個(gè)世界打交道!
上面在說 short int 和 long int 的時(shí)候,都加了一個(gè)可能,怎么,難道 short int 和 long int 和 int 還不一樣嗎?
這里就是 C 語言數(shù)據(jù)類型一個(gè)獨(dú)特的風(fēng)格。
為什么說可能,這是由于 C 語言為了適配不同的機(jī)器來設(shè)定的語法規(guī)則,在早起的計(jì)算機(jī)上,int 類型和 short 類型都占 16 位,long 類型占 32 位,在后來的計(jì)算機(jī)中,都采用了 16 位存儲 short 類型,32 位存儲 int 類型和 long 類型,現(xiàn)在,計(jì)算機(jī)普遍使用 64 位 CPU,為了存儲 64 位整數(shù),才引入了 long long 類型。所以,一般現(xiàn)在個(gè)人計(jì)算機(jī)上常見的設(shè)置是 long long 占用 64 位,long 占用 32 位,short 占用 16 位,int 占用 16 位或者 32 位。
char 類型
char 類型一般用于存儲字符,表示方法如下
char?a?=?'x';
char?b?=?'y';
char 被稱為字符類型,只能用單引號 '' 來表示,而不能用雙引號 “” 來表示,這和字符串的表示形式相反。
char 雖然表示字符,但是 char 實(shí)際上存儲的是整數(shù)而不是字符,計(jì)算機(jī)一般使用 ASCII 來處理字符,標(biāo)準(zhǔn) ASCII 碼的范圍是 0 - 127 ,只需 7 位二進(jìn)制數(shù)表示即可。C 語言中規(guī)定 char 占用 1 字節(jié)。
其實(shí)整型和字符型是相通的,他們在內(nèi)存中的存儲本質(zhì)是相通的,編譯器發(fā)現(xiàn) char ,就會自動轉(zhuǎn)換為整數(shù)存儲,相反的,如果給 int 類型賦值英文字符,也會轉(zhuǎn)換成整數(shù)存儲,如下代碼
#include?
int?main(){
?char?a?=?'x';
?int?b;
?b?=?'y';
?
?printf("%d\n%d\n",a,b);
}
輸出
120
121
所以,int 和 char 只是存儲的范圍不同,整型可以是 2 字節(jié),4 字節(jié),8 字節(jié),而字符型只占 1 字節(jié)。
有些 C 編譯器把 char 實(shí)現(xiàn)為有符號類型,這意味著 char 可表示的范圍是 -128 ~ 127,而有些編譯器把 char 實(shí)現(xiàn)為無符號類型,這種情況下 char 可表示的范圍是 0 - 255。signed char 表示的是有符號類型,unsigned char 表示的是無符號類型。
_Bool 類型
_Bool 類型是 C99 新增的數(shù)據(jù)類型,用于表示布爾值。也就是邏輯值 true 和 false。在 C99 之前,都是用 int 中的 1 和 0 來表示。所以 _Bool 在某種程度上也是一種數(shù)據(jù)類型。表示 0 和 1 的話,用 1 bit(位)表示就夠了。
float、double 和 long double
整型對于大多數(shù)軟件開發(fā)項(xiàng)目而言就已經(jīng)夠用了。然而,在金融領(lǐng)域和數(shù)學(xué)領(lǐng)域還經(jīng)常使用浮點(diǎn)數(shù)。C 語言中的浮點(diǎn)數(shù)有 float、double 和 long double 類型。浮點(diǎn)數(shù)類型能夠表示包括小數(shù)在內(nèi)更大范圍的數(shù)。浮點(diǎn)數(shù)能表示小數(shù),而且表示范圍比較大。浮點(diǎn)數(shù)的表示類似于科學(xué)技術(shù)法。下面是一些科學(xué)記數(shù)法示例:
| 數(shù)字 | 科學(xué)記數(shù)法 | 指數(shù)記數(shù)法 |
|---|---|---|
| 1000000000 | 1 * 10^9 | 1.0e9 |
| 456000 | 4.56 * 10^5 | 4.56e5 |
| 372.85 | 3.7285 * 10 ^ 2 | 3.7285e2 |
| 0.0025 | 2.5 * 10 ^ -3 | 2.5e-3 |
C 規(guī)定 float 類型必須至少能表示 6 位有效數(shù)字,而且取值范圍至少是 10^-37 ~ 10^+37。通常情況下,系統(tǒng)存儲一個(gè)浮點(diǎn)數(shù)要占用 32 位。
C 提供的另一種浮點(diǎn)類型是 double(雙精度類型)。一般來說,double 占用的是 64 位而不是 32 位。
C 提供的第三種類型是 long double ,用于滿足比 double 類型更高的精度要求。不過,C 只保證了 long double 類型至少與 double 類型相同。
浮點(diǎn)數(shù)的聲明方式和整型類似,下面是一些浮點(diǎn)數(shù)的聲明方式。
#include?
int?main(){
?float?aboat?=?2100.0;
?double?abet?=?2.14e9;
?long?double?dip?=?5.32e-5;
?
?printf("%f\n",?aboat);
?printf("%e\n",?abet);
?printf("%Lf\n",?dip);
?
}
printf() 函數(shù)使用 %f 轉(zhuǎn)換說明打印十進(jìn)制計(jì)數(shù)法的 float 和 double 類型浮點(diǎn)數(shù),用 %e 打印指數(shù)記數(shù)法的浮點(diǎn)數(shù)。打印 long double 類型要使用 %Lf 轉(zhuǎn)換說明。
關(guān)于浮點(diǎn)數(shù),還需要注意其上溢和下溢的問題。
上溢指的是是指由于數(shù)字過大,超過當(dāng)前類型所能表示的范圍,如下所示
float?toobig?=?3.4E38?*?100.0f;
printf("%e\n",toobig);
輸出的內(nèi)容是 inf,這表示 toobig 的結(jié)果超過了其定義的范圍,C 語言就會給 toobig 賦一個(gè)表示無窮大的特定值,而且 printf 顯示值為 inf 或者 infinity 。
下溢:是指由于數(shù)值太小,低于當(dāng)前類型所能表示的最小的值,計(jì)算機(jī)就只好把尾數(shù)位向右移,空出第一個(gè)二進(jìn)制位,但是與此同時(shí),卻損失了原來末尾有效位上面的數(shù)字,這種情況就叫做下溢。比如下面這段代碼
float?toosmall?=?0.1234e-38/10;
printf("%e\n",?toosmall);
復(fù)數(shù)和虛數(shù)類型
許多科學(xué)和工程計(jì)算都需要用到復(fù)數(shù)和虛數(shù),C99 標(biāo)準(zhǔn)支持復(fù)數(shù)類型和虛數(shù)類型,C 語言中有 3 種復(fù)數(shù)類型:float _Complex、double _Complex 和 long double ?_Complex。
C 語言提供的 3 種虛數(shù)類型:float _Imaginary、 double _Imaginary 和 long double _Imaginary。
如果包含 complex.h 頭文件的話,便可使用 complex 替換 _Complex,用 imaginary 替代 _Imaginary。
其他類型
除了上述我們介紹過的類型之外,C 語言中還有其他類型,比如數(shù)組、指針、結(jié)構(gòu)和聯(lián)合,雖然 C 語言沒有字符串類型,但是 C 語言卻能夠很好的處理字符串。
常量
在很多情況下我們需要常量,在整個(gè)程序的執(zhí)行過程中,其值不會發(fā)生改變,比如一天有 24 個(gè)小時(shí),最大緩沖區(qū)的大小,滑動窗口的最大值等。這些固定的值,即稱為常量,又可以叫做字面量。
常量也分為很多種,整型常量,浮點(diǎn)型常量,字符常量,字符串常量,下面我們分別來介紹
整數(shù)常量
整數(shù)常量可以表示為十進(jìn)制、八進(jìn)制或十六進(jìn)制。前綴指定基數(shù):0x 或 0X 表示十六進(jìn)制,0 表示八進(jìn)制,不帶前綴則默認(rèn)表示十進(jìn)制。整數(shù)常量也可以帶一個(gè)后綴,后綴是 U 和 L 的組合,U 表示無符號整數(shù)(unsigned),L 表示長整數(shù)(long)。
330?????????/*?合法的?*/
315u????????/*?合法的?*/
0xFeeL??????/*?合法的?*/
048?????????/*?非法的:8 進(jìn)制不能定義 8 */
浮點(diǎn)型常量
浮點(diǎn)型常量由整數(shù)部分、小數(shù)點(diǎn)、小數(shù)部分和指數(shù)部分組成。你可以使用小數(shù)形式或者指數(shù)形式來表示浮點(diǎn)常量。
當(dāng)使用小數(shù)形式表示時(shí),必須包含整數(shù)部分、小數(shù)部分,或同時(shí)包含兩者。當(dāng)使用指數(shù)形式表示時(shí), 必須包含小數(shù)點(diǎn)、指數(shù),或同時(shí)包含兩者。帶符號的指數(shù)是用 e 或 E 引入的。
3.14159???????/*?合法的?*/
314159E-5L????/*?合法的?*/
510E??????????/*?非法的:不完整的指數(shù)?*/
210f??????????/*?非法的:沒有小數(shù)或指數(shù)?*/
字符常量
C 語言中的字符常量使用單引號(即撇號)括起來的一個(gè)字符。如‘a(chǎn)’,‘x’,'D',‘?’,‘$’ 等都是字符常量。注意,‘a(chǎn)’ 和 ‘A’ 是不同的字符常量。
除了以上形式的字符常量外,C 還允許用一種特殊形式的字符常量,就是以一個(gè) “\” 開頭的字符序列。例如,前面已經(jīng)遇到過的,在 printf 函數(shù)中的‘\n’,它代表一個(gè)換行符。這是一種控制字符,在屏幕上是不能顯示的。
常用的以 “\” 開頭的特殊字符有

表中列出的字符稱為“轉(zhuǎn)義字符”,意思是將反斜杠(\)后面的字符轉(zhuǎn)換成另外的意義。如 ‘\n’ 中的 “n” 不代表字母 n 而作為“換行”符。
表中最后第 2 行是用ASCII碼(八進(jìn)制數(shù))表示一個(gè)字符,例如 ‘\101’ 代表 ASCII 碼(十進(jìn)制數(shù))為 65 的字符 “A”。‘\012’(十進(jìn)制 ASCII 碼為 10)代表換行。
需要注意的是 ‘\0’ 或 ‘\000’ 代表 ASCII 碼為 0 的控制字符,它用在字符串中。
字符串常量
字符串常量通常用 "" 進(jìn)行表示。字符串就是一系列字符的集合。一個(gè)字符串包含類似于字符常量的字符:普通的字符、轉(zhuǎn)義序列和通用的字符。
常量定義
C 語言中,有兩種定義常量的方式。
使用 #define預(yù)處理器進(jìn)行預(yù)處理使用 const關(guān)鍵字進(jìn)行處理
下面是使用 #define 預(yù)處理器進(jìn)行常量定義的代碼。
#include?
#define?LENGTH?5
#define?WIDTH?10
int?main(){
?
?int?area?=?LENGTH?*?WIDTH;
?
?printf("area?=?%d\n",?area);
?
}
同樣的,我們也可以使用 const 關(guān)鍵字來定義常量,如下代碼所示
#include?
int?main(){
?
?const?int?LENGTH?=?10;
?const?int?WIDTH?=?5;
?
?int?area;
?area?=?LENGTH?*?WIDTH;
?
?printf("area?=?%d\n",?area);
?
}
那么這兩種常量定義方式有什么不同呢?
編譯器處理方式不同
使用 #define 預(yù)處理器是在預(yù)處理階段進(jìn)行的,而 const 修飾的常量是在編譯階段進(jìn)行。
類型定義和檢查不同
使用 #define 不用聲明數(shù)據(jù)類型,而且不用類型檢查,僅僅是定義;而使用 const 需要聲明具體的數(shù)據(jù)類型,在編譯階段會進(jìn)行類型檢查。
完
?往期推薦?
??