
深入理解協(xié)程
C++ 在互聯(lián)網(wǎng)服務(wù)端開(kāi)發(fā)方向依然占據(jù)著相當(dāng)大的份額;百度,騰訊,甚至以java為主流開(kāi)發(fā)語(yǔ)言的阿里都在大規(guī)模使用C++做互聯(lián)網(wǎng)服務(wù)端開(kāi)發(fā),今天以C++為例子,分析一下要支持協(xié)程,需要考慮哪些問(wèn)題,如何權(quán)衡利弊,反過(guò)來(lái)也可以了解到協(xié)程適合哪些場(chǎng)景。
第1章 C++協(xié)程近況簡(jiǎn)介
第1節(jié).舊時(shí)代
每個(gè)流程都要定義一個(gè)上下文struct,并手動(dòng)保存與恢復(fù); 每次回調(diào)都會(huì)切斷棧上變量的生命周期,導(dǎo)致需要延續(xù)使用的變量必須申請(qǐng)到堆上或存入上下文結(jié)構(gòu)中; 由于C++是無(wú)GC的語(yǔ)言,碎片化的邏輯給內(nèi)存管理也帶來(lái)了更多挑戰(zhàn); 回調(diào)式的邏輯是“不知何時(shí)會(huì)被觸發(fā)”的,用戶狀態(tài)管理也會(huì)有更多挑戰(zhàn);
第2節(jié).新時(shí)代
第2章.協(xié)程庫(kù)的設(shè)計(jì)與實(shí)現(xiàn)
1.API級(jí)
2.玩具級(jí)
3.工業(yè)級(jí)
4.框架級(jí)
5.語(yǔ)言級(jí)
第1節(jié).協(xié)程上下文切換
1.使用操作系統(tǒng)提供的api:ucontext、fiber 這種方式是最安全可靠的,但是性能比較差。(切換性能大概在200萬(wàn)次/秒左右) 2.使用setjump、longjump: 代表作:libmill 3.自己寫(xiě)匯編碼實(shí)現(xiàn) 這種方式的性能可以很好,但是不同系統(tǒng)、甚至不同版本的linux都需要不同的匯編碼,兼容性奇差無(wú)比,代表作:libco 4.使用boost.coroutine 這種方式的性能很好,boost也幫忙處理了各種平臺(tái)架構(gòu)的兼容性問(wèn)題,缺陷是這東西隨著boost的升級(jí),并不是向后兼容的,不推薦使用 5.使用boost.context 性能、兼容性都是當(dāng)前最佳的,推薦使用。(切換性能大概在1.25億次/秒左右)
不愿意依賴boost庫(kù)的用戶直接編譯即可選擇第1種方案; 追求更佳性能的用戶編譯時(shí)使用cmake參數(shù)-DENABLE_BOOST_CONTEXT=ON即可選擇第5種方案
第2節(jié).協(xié)程棧
靜態(tài)棧(Static Stack)
分段棧(Segmented Stack)
拷貝棧(Copy Stack)
共享?xiàng)?Shared Stack)
1.協(xié)程切換慢:每次協(xié)程切換,都需要2次Copy協(xié)程棧內(nèi)存,這個(gè)內(nèi)存量基本上都在1KB以上,通常是幾十kb甚至幾百kb,這樣的2次Copy要花費(fèi)很長(zhǎng)的時(shí)間。 2.棧上引用失效導(dǎo)致隱蔽的bug:例如下面的代碼

虛擬內(nèi)存棧(Virtual Memory Stack)
第3節(jié).協(xié)程調(diào)度
棧式調(diào)度
星切調(diào)度(非對(duì)稱(chēng)協(xié)程調(diào)度)
環(huán)切調(diào)度(對(duì)稱(chēng)協(xié)程調(diào)度)
多線程調(diào)度、負(fù)載均衡與WorkSteal
第4節(jié).HOOK
基本守則:HOOK接口表現(xiàn)出來(lái)的行為與被HOOK的接口保持100%一致
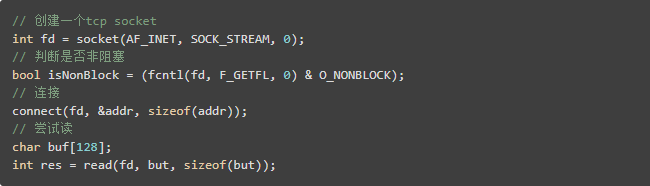
網(wǎng)絡(luò)io
DNS
gethostbyname2
gethostbyname_r
gethostbyname2_r
gethostbyaddr
gethostbyaddr_r
signal

其他會(huì)導(dǎo)致阻塞的syscall
第5節(jié).完整生態(tài)
Channel





協(xié)程鎖、協(xié)程讀寫(xiě)鎖



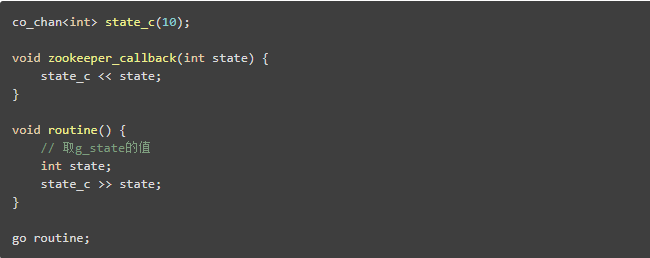
定時(shí)器
CLS(Coroutine Local Storage)(協(xié)程本地存儲(chǔ))
線程池



1.可以設(shè)置co_sched.GetOptions().debug打印一些log,具體flag見(jiàn)config.h 2.可以設(shè)置一個(gè)協(xié)程事件監(jiān)聽(tīng)器,詳見(jiàn)tutorial文件夾下的sample12_listener.cpp教程代碼 3.編譯時(shí)添加cmake參數(shù):-DENABLE_DEBUGGER=ON 開(kāi)啟debug信息收集后,可以使用co::CoDebugger類(lèi)獲取一些調(diào)試信息,詳見(jiàn)debugger.h的注釋 4.后續(xù)還會(huì)提供更多調(diào)試手段
協(xié)程之外(運(yùn)行在線程上的代碼)
跨平臺(tái)
libgo支持三大主流系統(tǒng):linux、windows、mac-os
上層封裝
未來(lái)的發(fā)展方向
1.目前是使用go、go_stack、go_dispatch三個(gè)不同的宏來(lái)設(shè)置協(xié)程的屬性,這種方式不夠靈活,后續(xù)要改成:go stack(1024 * 1024) dispatch(::co::egod_robin) func; 這樣的語(yǔ)法形式,可以更靈活的定制協(xié)程屬性。 2.基于(1)的新語(yǔ)法,實(shí)現(xiàn)“協(xié)程親緣性”功能,將協(xié)程綁定到指定線程上,并防止被steal。 3.優(yōu)化協(xié)程切換速度: A)使用環(huán)切調(diào)度替代現(xiàn)在的星切調(diào)度(CoYeild時(shí)選擇下一個(gè)切換目標(biāo)),必要時(shí)才切換回線程處理epoll、定時(shí)器、sleep等邏輯,同時(shí)協(xié)調(diào)好多線程調(diào)度 B)調(diào)度器的Run函數(shù)里面做了很多協(xié)程切換之外的事情,盡量降低這部分在非必要時(shí)的cpu消耗,比如:有任務(wù)加入定時(shí)器是設(shè)置一個(gè)tls標(biāo)記為true,只有標(biāo)記為true時(shí)才去處理定時(shí)器相關(guān)邏輯。 C)調(diào)度器中的runnable隊(duì)列使用了自旋鎖,沒(méi)有競(jìng)爭(zhēng)時(shí)對(duì)原子變量的操作也是比較昂貴的,runnable隊(duì)列可以優(yōu)化成多寫(xiě)一讀,僅在寫(xiě)入端加鎖的隊(duì)列。 4.協(xié)程對(duì)象Task內(nèi)存布局調(diào)優(yōu),tls池化,每個(gè)池使用多寫(xiě)一讀鏈表隊(duì)列,申請(qǐng)時(shí)僅在當(dāng)前線程的池中申請(qǐng),可以免鎖,釋放時(shí)均衡每個(gè)線程的池水水位,可以塞入其他線程的池中。 5.libgo之外,會(huì)進(jìn)一步尋找和當(dāng)前已經(jīng)比較成熟的非協(xié)程的開(kāi)發(fā)框架的結(jié)合方案,讓還未能用上協(xié)程的用戶低成本的用上協(xié)程。
https://github.com/yyzybb537/libgo
作者:Li_Mr https://my.oschina.net/yyzybb/blog/1817226
評(píng)論
圖片
表情