
WebFlux和SpringMVC性能對比
從負(fù)載測試看異步非阻塞的優(yōu)勢
前面總是“安利”異步非阻塞的好處,下面我們就實(shí)實(shí)在在感受一下響應(yīng)式編程在高并發(fā)環(huán)境下的性能提升。異步非阻塞的優(yōu)勢體現(xiàn)在I/O操作方面,無論是文件I/O、網(wǎng)絡(luò)I/O,還是數(shù)據(jù)庫讀寫,都可能存在阻塞的情況。
我們的測試內(nèi)容有三:
首先分別創(chuàng)建基于WebMVC和WebFlux的Web服務(wù),來對比觀察異步非阻塞能帶來多大的性能提升,我們模擬一個(gè)簡單的帶有延遲的場景,然后啟動服務(wù)使用gatling進(jìn)行測試,并進(jìn)行分析;
由于現(xiàn)在微服務(wù)架構(gòu)應(yīng)用越來越廣泛,我們基于第一步的測試項(xiàng)目進(jìn)一步觀察調(diào)用存在延遲的服務(wù)的情況下的測試數(shù)據(jù),其實(shí)主要是針對客戶端的測試:阻塞的
RestTemplate和非阻塞的WebClient;針對MongoDB的同步和異步數(shù)據(jù)庫驅(qū)動進(jìn)行性能測試和分析。
說明:本節(jié)進(jìn)行的并非是嚴(yán)謹(jǐn)?shù)幕谛阅苷{(diào)優(yōu)的需求的,針對具體業(yè)務(wù)場景的負(fù)載測試。本節(jié)測試場景簡單而直接,各位朋友GET到我的點(diǎn)即可。
此外:由于本節(jié)主要是進(jìn)行橫向?qū)Ρ葴y試,因此不需要特定的硬件資源配置,不過還是建議在Linux環(huán)境下進(jìn)行測試,我最初是在Win10上跑的,當(dāng)用戶數(shù)上來之后出現(xiàn)了不少請求失敗的情況,下邊的測試數(shù)據(jù)是在一臺系統(tǒng)為Deepin Linux(Debian系)的筆記本上跑出來的。
那么我們就開始搭建測試環(huán)境吧~ (關(guān)于Spring WebFlux 不熟悉的話,請參考Spring WebFlux快速上手)。
1.4.1 帶有延遲的負(fù)載測試分析
1)搭建待測試項(xiàng)目
我們分別基于WebMVC和WebFlux創(chuàng)建兩個(gè)項(xiàng)目:mvc-with-latency和WebFlux-with-latency。
為了模擬阻塞,我們分別在兩個(gè)項(xiàng)目中各創(chuàng)建一個(gè)帶有延遲的/hello/{latency}的API。比如/hello/100的響應(yīng)會延遲100ms。
mvc-with-latency中創(chuàng)建HelloController.java:
@RestController
public class HelloController {
@GetMapping("/hello/{latency}")
public String hello(@PathVariable long latency) {
try {
TimeUnit.MILLISECONDS.sleep(latency); // 1
} catch (InterruptedException e) {
return "Error during thread sleep";
}
return "Welcome to reactive world ~";
}
}
利用sleep來模擬業(yè)務(wù)場景中發(fā)生阻塞的情況。
WebFlux-with-latency中創(chuàng)建HelloController.java:
@RestController
public class HelloController {
@GetMapping("/hello/{latency}")
public Mono
hello
(@PathVariable int latency)
{
return Mono.just("Welcome to reactive world ~")
.delayElement(Duration.ofMillis(latency)); // 1
}
}
使用
delayElement操作符來實(shí)現(xiàn)延遲。
然后各自在application.properties中配置端口號8091和8092:
server.port=8091
啟動應(yīng)用。
2)編寫負(fù)載測試腳本
本節(jié)我們采用gatling來進(jìn)行測試。創(chuàng)建測試項(xiàng)目gatling-scripts。
POM中添加gatling依賴和插件(目前gradle暫時(shí)還沒有這個(gè)插件,所以只能是maven項(xiàng)目):
<dependencies>
<dependency>
<groupId>io.gatling.highchartsgroupId>
<artifactId>gatling-charts-highchartsartifactId>
<version>2.3.0version>
<scope>testscope>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>io.gatlinggroupId>
<artifactId>gatling-maven-pluginartifactId>
<version>2.2.4version>
plugin>
plugins>
build>
在src/test下創(chuàng)建測試類,gatling使用scala語言編寫測試類:
import io.gatling.core.scenario.Simulation
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class LoadSimulation extends Simulation {
// 從系統(tǒng)變量讀取 baseUrl、path和模擬的用戶數(shù)
val baseUrl = System.getProperty("base.url")
val testPath = System.getProperty("test.path")
val sim_users = System.getProperty("sim.users").toInt
val httpConf = http.baseURL(baseUrl)
// 定義模擬的請求,重復(fù)30次
val helloRequest = repeat(30) {
// 自定義測試名稱
exec(http("hello-with-latency")
// 執(zhí)行g(shù)et請求
.get(testPath))
// 模擬用戶思考時(shí)間,隨機(jī)1~2秒鐘
.pause(1 second, 2 seconds)
}
// 定義模擬的場景
val scn = scenario("hello")
// 該場景執(zhí)行上邊定義的請求
.exec(helloRequest)
// 配置并發(fā)用戶的數(shù)量在30秒內(nèi)均勻提高至sim_users指定的數(shù)量
setUp(scn.inject(rampUsers(sim_users).over(30 seconds)).protocols(httpConf))
}
如上,這個(gè)測試的場景是:
指定的用戶量是在30秒時(shí)間內(nèi)勻速增加上來的;
每個(gè)用戶重復(fù)請求30次指定的URL,中間會隨機(jī)間隔1~2秒的思考時(shí)間。
其中URL和用戶量通過base.url、test.path、sim.users變量傳入,借助maven插件,通過如下命令啟動測試:
mvn gatling:test -Dgatling.simulationClass=test.load.sims.LoadSimulation -Dbase.url=http://localhost:8091/ -Dtest.path=hello/100 -Dsim.users=300
就表示用戶量為300的對http://localhost:8091/hello/100的測試。
3)觀察線程數(shù)量
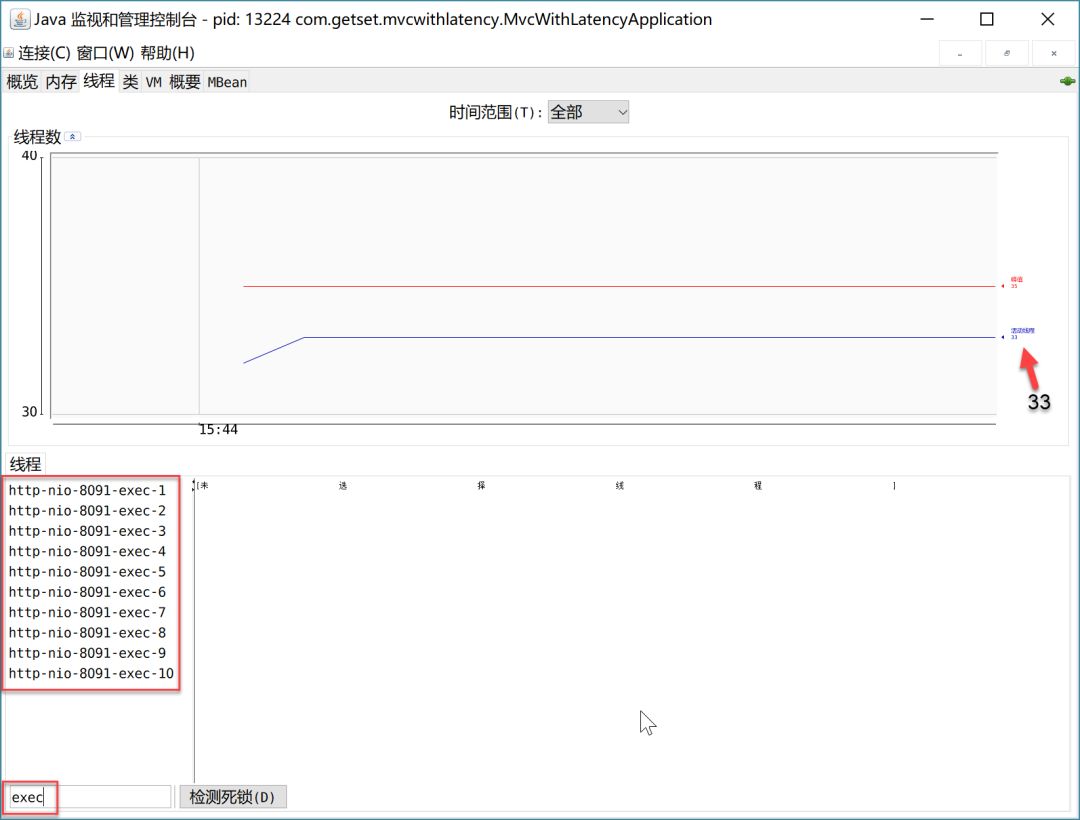
測試之前,我們打開jconsole觀察應(yīng)用(連接MVCWithLatencyApplication)的線程變化情況:
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
如圖(分辨率問題顯示不太好)是剛啟動無任何請求進(jìn)來的時(shí)候,默認(rèn)執(zhí)行線程有10個(gè),總的線程數(shù)31-33個(gè)。
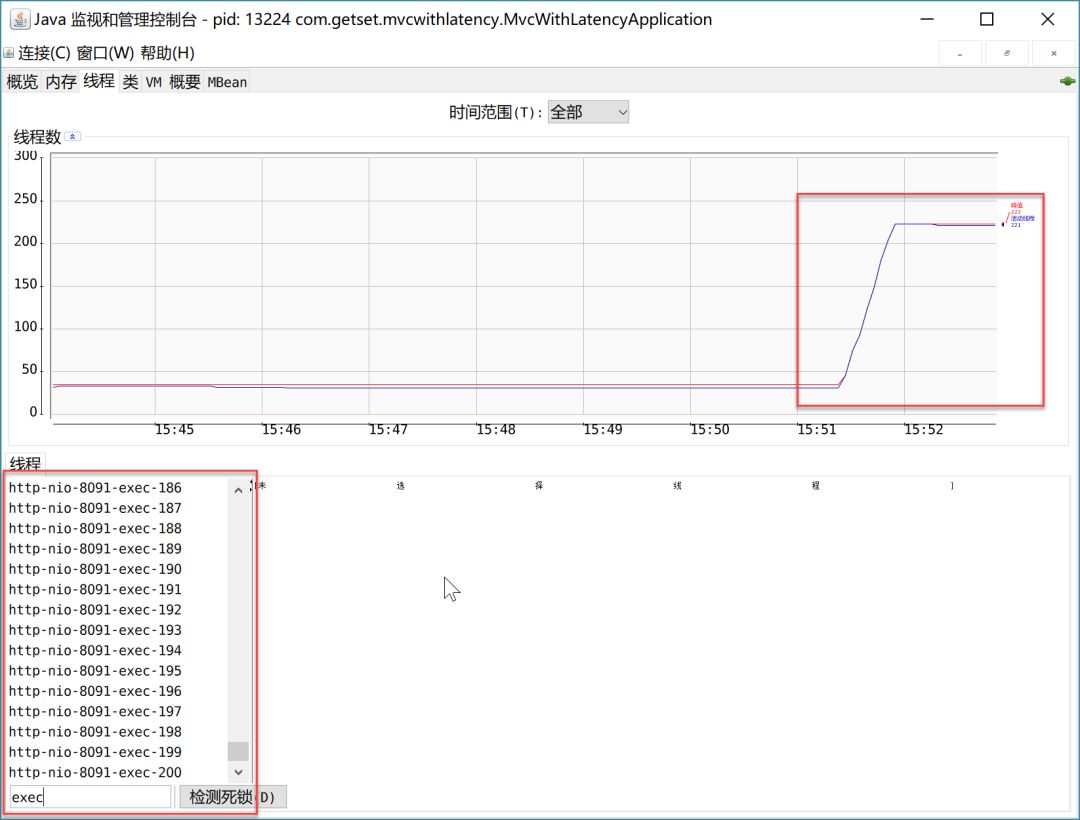
比如,當(dāng)進(jìn)行用戶數(shù)為2500個(gè)的測試時(shí),執(zhí)行線程增加到了200個(gè),總的線程數(shù)峰值為223個(gè),就是增加的這190個(gè)執(zhí)行線程。如下:
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
由于在負(fù)載過去之后,執(zhí)行線程數(shù)量會隨機(jī)減少回10個(gè),因此看最大線程編號估算線程個(gè)數(shù)的話并不靠譜,我們可以用“峰值線程數(shù)-23”得到測試過程中的執(zhí)行線程個(gè)數(shù)。
4)負(fù)載測試
首先我們測試mvc-with-latency:
-Dbase.url=http://localhost:8091/;
-Dtest.path=hello/100(延遲100ms);
-Dsim.users=1000/2000/3000/…/10000。
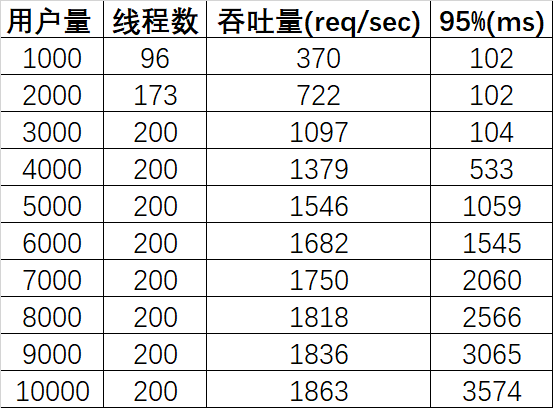
測試數(shù)據(jù)如下(Tomcat最大線程數(shù)200,延遲100ms):
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
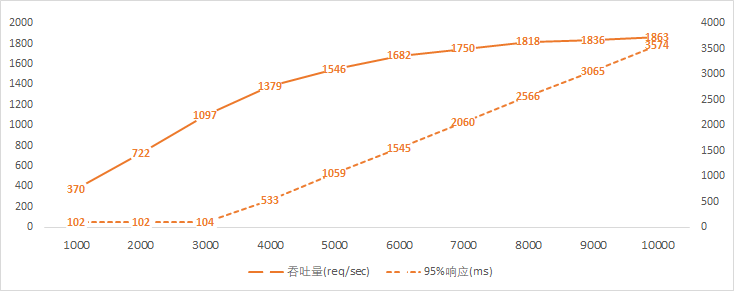
由以上數(shù)據(jù)可知:
用戶量在接近3000的時(shí)候,線程數(shù)達(dá)到默認(rèn)的最大值200;
線程數(shù)達(dá)到200前,95%的請求響應(yīng)時(shí)長是正常的(比100ms多一點(diǎn)點(diǎn)),之后呈直線上升的態(tài)勢;
線程數(shù)達(dá)到200后,吞吐量增幅逐漸放緩。
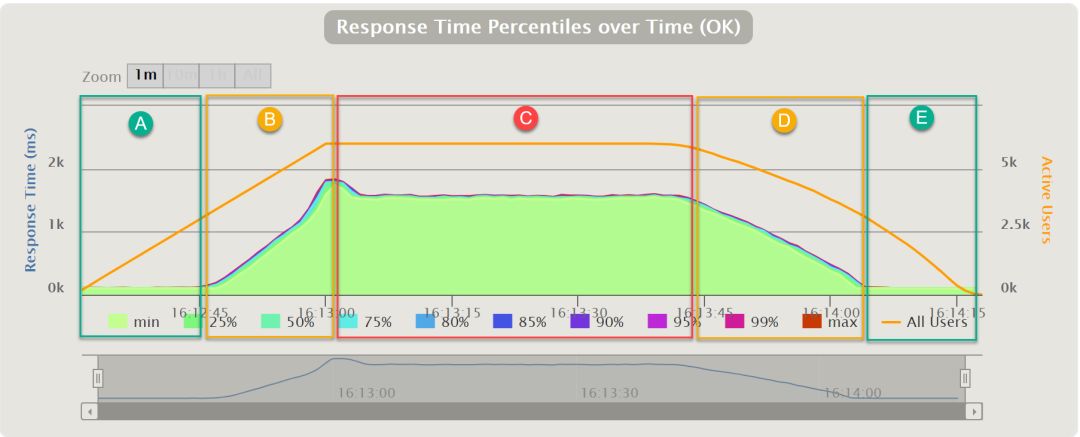
這里我們不難得出原因,那就是當(dāng)所有可用線程都在阻塞狀態(tài)的話,后續(xù)再進(jìn)入的請求只能排隊(duì),從而當(dāng)達(dá)到最大線程數(shù)之后,響應(yīng)時(shí)長開始上升。我們以6000用戶的報(bào)告為例:
 title
title
這幅圖是請求響應(yīng)時(shí)長隨時(shí)間變化的圖,可以看到大致可以分為五個(gè)段:
A. 有空閑線程可用,請求可以在100ms+時(shí)間返回;
B. 線程已滿,新來的請求開始排隊(duì),因?yàn)锳和B階段是用戶量均勻上升的階段,所以排隊(duì)的請求越來越多;
C. 每秒請求量穩(wěn)定下來,但是由于排隊(duì),維持一段時(shí)間的高響應(yīng)時(shí)長;
D. 部分用戶的請求完成,每秒請求量逐漸下降,排隊(duì)情況逐漸緩解;
E. 用戶量降至線程滿負(fù)荷且隊(duì)列消化后,請求在正常時(shí)間返回;
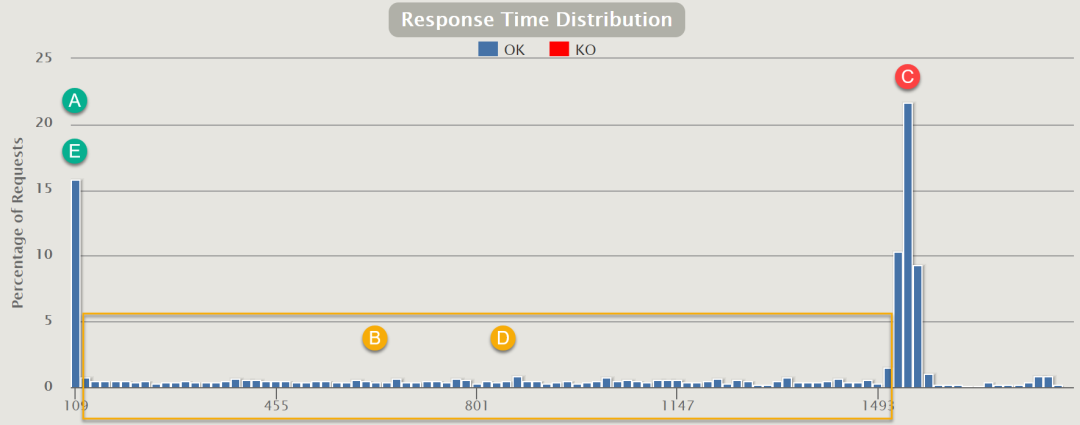
所有請求的響應(yīng)時(shí)長分布如下圖所示:
 title
title
A/E段與C段的時(shí)長只差就是平均的排隊(duì)等待時(shí)間。在持續(xù)的高并發(fā)情況下,大部分請求是處在C段的。而且等待時(shí)長隨請求量的提高而線性增長。
增加Servlet容器處理請求的線程數(shù)量可以緩解這一問題,就像上邊把最大線程數(shù)量從默認(rèn)的200增加的400。
最高200的線程數(shù)是Tomcat的默認(rèn)設(shè)置,我們將其設(shè)置為400再次測試。在application.properties中增加:
server.tomcat.max-threads=400
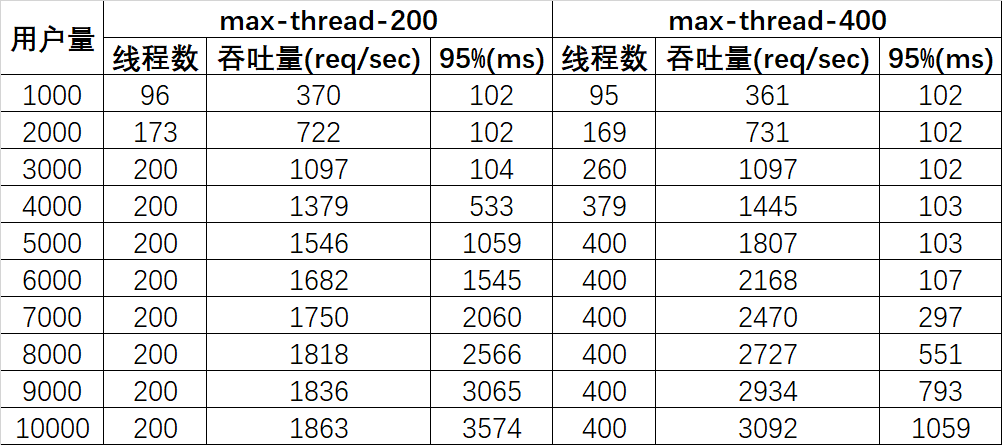
測試數(shù)據(jù)如下:
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
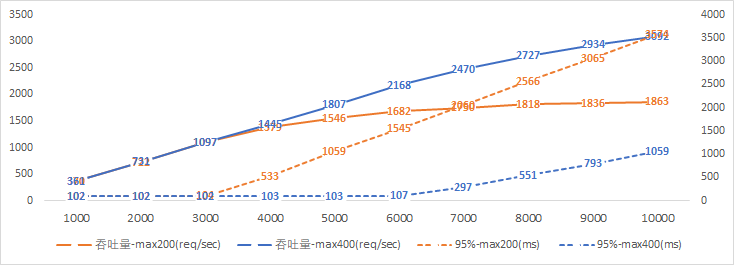
由于工作線程數(shù)擴(kuò)大一倍,因此請求排隊(duì)的情況緩解一半,具體可以對比一下數(shù)據(jù):
“最大線程數(shù)200用戶5000”的“95%響應(yīng)時(shí)長”恰好與“最大線程數(shù)400用戶10000”完全一致,我對天發(fā)誓,這絕對絕對是真實(shí)數(shù)據(jù),更加巧合的是,吞吐量也恰好是1:2的關(guān)系!有此巧合也是因?yàn)闇y試場景太簡單粗暴,哈哈;
“95%響應(yīng)時(shí)長”的曲線斜率也是兩倍的關(guān)系。
這也再次印證了我們上邊的分析。增加線程數(shù)確實(shí)可以一定程度下提高吞吐量,降低因阻塞造成的響應(yīng)延時(shí),但此時(shí)我們需要權(quán)衡一些因素:
增加線程是有成本的,JVM中默認(rèn)情況下在創(chuàng)建新線程時(shí)會分配大小為1M的線程棧,所以更多的線程異味著更多的內(nèi)存;
更多的線程會帶來更多的線程上下文切換成本。
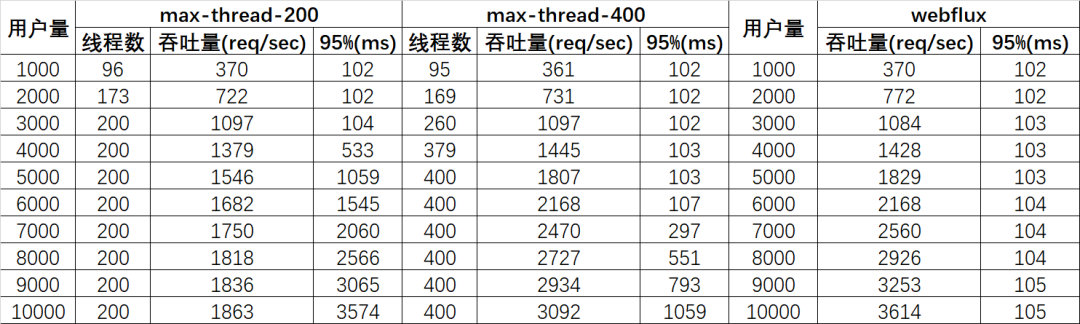
我們再來看一下對于WebFlux-with-latency的測試數(shù)據(jù):
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
這里沒有統(tǒng)計(jì)線程數(shù)量,因?yàn)閷τ谶\(yùn)行在異步IO的Netty之上的WebFlux應(yīng)用來說,其工作線程數(shù)量始終維持在一個(gè)固定的數(shù)量上,通常這個(gè)固定的數(shù)量等于CPU核數(shù)(通過jconsole可以看到有名為
reactor-http-nio-X和parallel-X的線程,我這是四核八線程的i7,所以X從1-8),因?yàn)楫惒椒亲枞麠l件下,程序邏輯是由事件驅(qū)動的,并不需要多線程并發(fā);隨著用戶數(shù)的增多,吞吐量基本呈線性增多的趨勢;
95%的響應(yīng)都在100ms+的可控范圍內(nèi)返回了,并未出現(xiàn)延時(shí)的情況。
可見,非阻塞的處理方式規(guī)避了線程排隊(duì)等待的情況,從而可以用少量而固定的線程處理應(yīng)對大量請求的處理。
除此之外,我又一步到位直接測試了一下20000用戶的情況:
對
mvc-with-latency的測試由于出現(xiàn)了許多的請求fail而以失敗告終;而
WebFlux-with-latency應(yīng)對20000用戶已然面不改色心不慌,吞吐量達(dá)到7228 req/sec(我擦,正好是10000用戶下的兩倍,太巧了今天怎么了,絕對是真實(shí)數(shù)據(jù)!),95%響應(yīng)時(shí)長僅117ms。
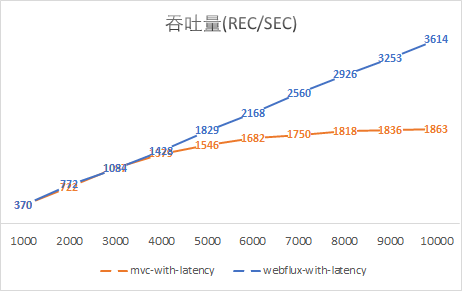
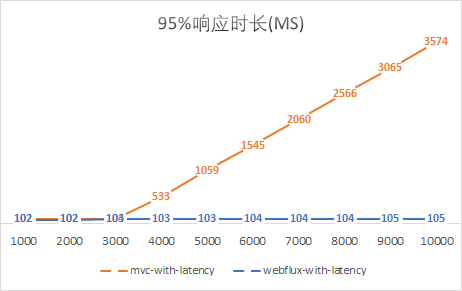
最后,再給出兩個(gè)吞吐量和響應(yīng)時(shí)長的圖,更加直觀地感受異步非阻塞的WebFlux是如何一騎絕塵的吧:
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
 (6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
(6)Spring WebFlux性能測試——響應(yīng)式Spring的道法術(shù)器
綜上來說,結(jié)論就是相對于Servlet多線程的處理方式來說,Spring WebFlux在應(yīng)對高并發(fā)的請求時(shí),借助于異步IO,能夠以少量而穩(wěn)定的線程處理更高吞吐量的請求,尤其是當(dāng)請求處理過程如果因?yàn)闃I(yè)務(wù)復(fù)雜或IO阻塞等導(dǎo)致處理時(shí)長較長時(shí),對比更加顯著。
本文模擬的延遲時(shí)間較長,達(dá)到了100ms,雖然有些夸張,但是不能否認(rèn)IO阻塞的嚴(yán)重性。如果CPU執(zhí)行一條指令的時(shí)間是1秒,那么內(nèi)存尋址就需要4分20秒,SSD尋址需要4.5天,磁盤尋址需要1個(gè)月。異步IO能夠?qū)PU從“漫長”的等待中解放出來,不再需要堆砌大量的線程來提高CPU利用率。這也是Spring WebFlux能夠以少量線程處理更高吞吐量的原因。
此時(shí),我們更加理解了Nodejs的驕傲,不過我們大Java語言也有了Vert.x和現(xiàn)在的Spring WebFlux。
兩年嘔心瀝血的文章:「面試題」「基礎(chǔ)」「進(jìn)階」這里全都有!
300多篇原創(chuàng)技術(shù)文章海量視頻資源精美腦圖面試題長按掃碼可關(guān)注獲取
在看和分享對我非常重要!![]()
創(chuàng)作不易,各位的支持和認(rèn)可,就是我創(chuàng)作的最大動力,我們下篇文章見! 求點(diǎn)贊 求關(guān)注? 求分享? 求留言?

點(diǎn)擊閱讀原文,關(guān)注我的GitHub