
BERT---容易被忽視的細(xì)節(jié)
來(lái)源:https://zhuanlan.zhihu.com/p/69351731
最近面試,被問(wèn)到一些模型的相關(guān)細(xì)節(jié),所以又重新讀了一些論文
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
論文地址:https://arxiv.org/pdf/1810.04805.pdf
細(xì)節(jié)一:Bert的雙向體現(xiàn)在什么地方?
Bert可以看作Transformer的encoder部分。Bert模型舍棄了GPT的attention mask。雙向主要體現(xiàn)在Bert的
預(yù)訓(xùn)練任務(wù)一:遮蔽語(yǔ)言模型(MLM),如:
小 明 喜 歡 [MASK] 度 學(xué) 習(xí) 。
這句話輸入到模型中,[MASK]通過(guò)attention均結(jié)合了左右上下文的信息,這體現(xiàn)了雙向。
attention是雙向的,但GPT通過(guò)attention mask達(dá)到單向,即:讓[MASK]看不到 度 學(xué) 習(xí)這三個(gè)字,只看到上文 小 明 喜 歡 。
細(xì)節(jié)二:Bert的是怎樣預(yù)訓(xùn)練的?
預(yù)訓(xùn)練任務(wù)一:遮蔽語(yǔ)言模型(MLM)
將一句被mask的句子輸入Bert模型,對(duì)模型輸出的矩陣中mask對(duì)應(yīng)位置的向量做分類,標(biāo)簽就是被mask的字在字典中對(duì)應(yīng)的下標(biāo)。這么講有點(diǎn)抽象,如圖:
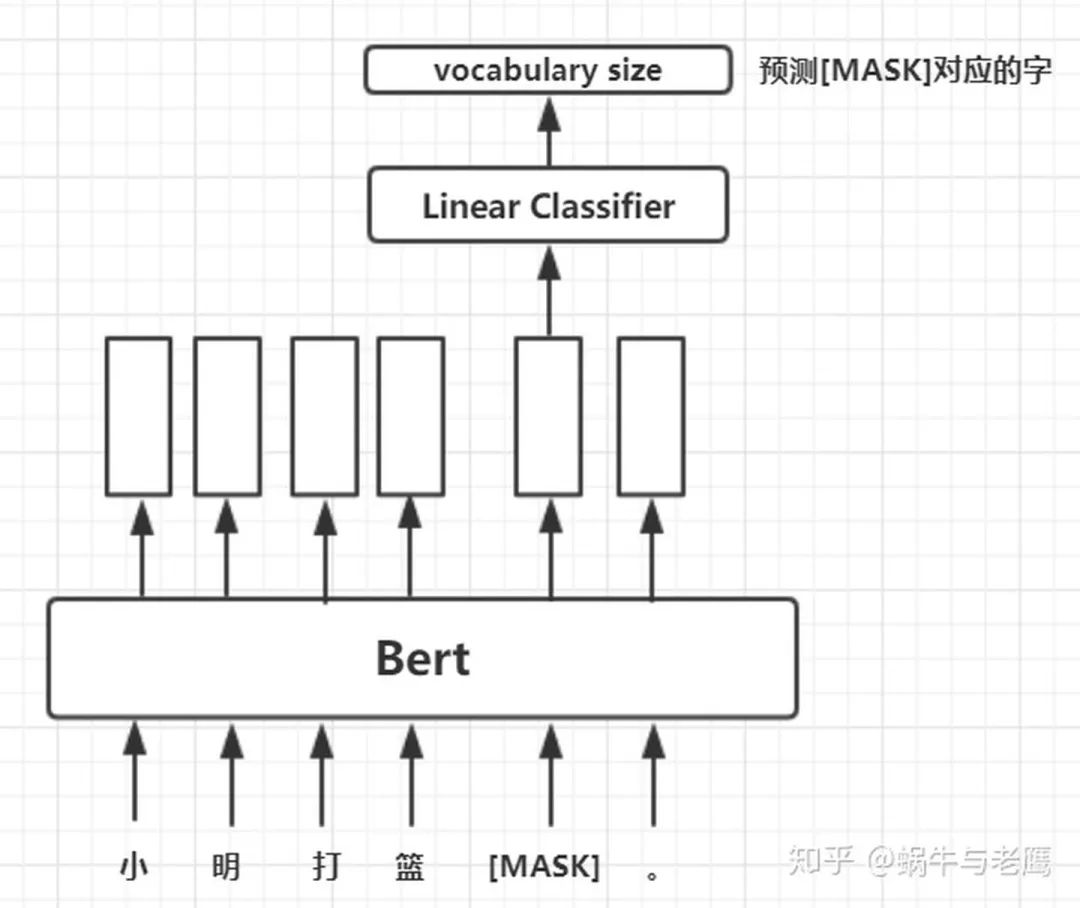
預(yù)訓(xùn)練任務(wù)二:下一句預(yù)測(cè)(NSP)
訓(xùn)練一個(gè)下一句預(yù)測(cè)的二元分類任務(wù)。
具體 來(lái)說(shuō),在為每個(gè)訓(xùn)練前的例子選擇句子 A 和 B 時(shí),50% 的情況下 B 是真的在 A 后面的下一個(gè)句子, 50% 的情況下是來(lái)自語(yǔ)料庫(kù)的隨機(jī)句子。
然后將[cls]對(duì)應(yīng)的向量取出做二分類訓(xùn)練,如圖:
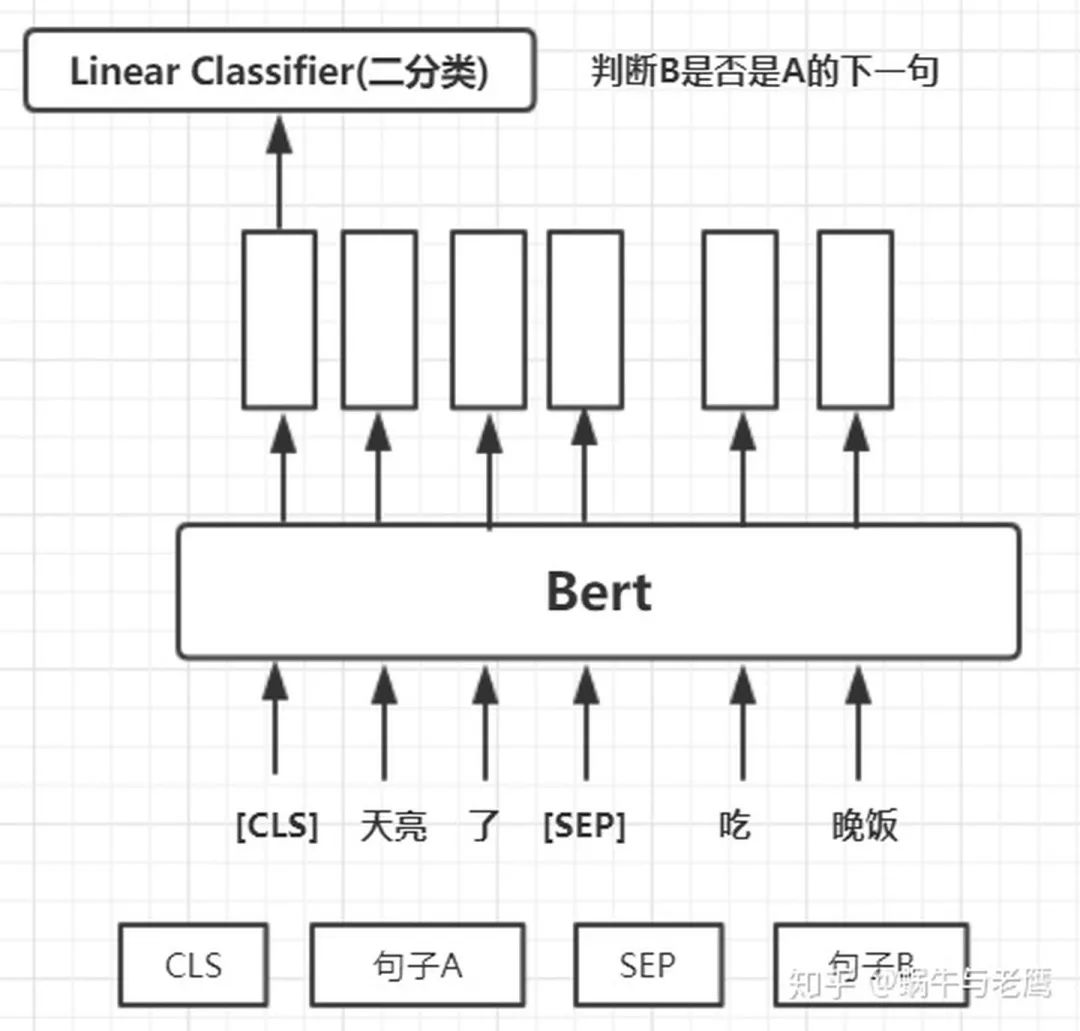
兩個(gè)任務(wù)共享Bert,使用不同的輸出層,做Muti-Task。
細(xì)節(jié)三:對(duì)于任務(wù)一,對(duì)于在數(shù)據(jù)中隨機(jī)選擇 15% 的標(biāo)記,其中80%被換位[mask],10%不變、10%隨機(jī)替換其他單詞,原因是什么?
兩個(gè)缺點(diǎn):
1、因?yàn)锽ert用于下游任務(wù)微調(diào)時(shí), [MASK] 標(biāo)記不會(huì)出現(xiàn),它只出現(xiàn)在預(yù)訓(xùn)練任務(wù)中。這就造成了預(yù)訓(xùn)練和微調(diào)之間的不匹配,微調(diào)不出現(xiàn)[MASK]這個(gè)標(biāo)記,模型好像就沒(méi)有了著力點(diǎn)、不知從哪入手。所以只將80%的替換為[mask],但這也只是緩解、不能解決。
2、相較于傳統(tǒng)語(yǔ)言模型,Bert的每批次訓(xùn)練數(shù)據(jù)中只有 15% 的標(biāo)記被預(yù)測(cè),這導(dǎo)致模型需要更多的訓(xùn)練步驟來(lái)收斂。
···? END? ···