
kill 命令之后MySQL都做了哪些
關(guān)注?歡少的成之路??回復(fù)算法,MySQL,8888,6666 領(lǐng)取海量學(xué)習(xí)資料。有機(jī)會(huì)參與領(lǐng)書(shū)活動(dòng)!
大家好,我是Leo。目前在常州從事Java后端開(kāi)發(fā)的工作。上一篇我們介紹了線(xiàn)上數(shù)據(jù)庫(kù)誤刪數(shù)據(jù)后,到底是跑路還是該如何解決!這一篇我們介紹一下為什么我們?cè)谡{(diào)試SQL的時(shí)候會(huì)出現(xiàn)Kill不掉線(xiàn)程的情況。
思路
本篇文章的介紹思路以下圖的思維導(dǎo)圖為大綱。也有利于讀者更好的分辨可讀性!
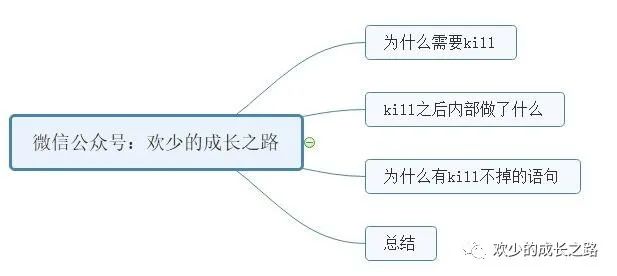
為什么需要kill
測(cè)試
從測(cè)試方面考慮的話(huà),就是我們?cè)趯?xiě)SQL語(yǔ)句的時(shí)候。開(kāi)始尋找不足點(diǎn),有些時(shí)候會(huì)偶然間執(zhí)行一個(gè)大事務(wù),這個(gè)時(shí)候我們?yōu)榱颂嵘释鶗?huì)直接干到這個(gè)查詢(xún)
生產(chǎn)
隨著數(shù)據(jù)量爆發(fā)式的增長(zhǎng),一些查詢(xún)功能越來(lái)越慢的。而我們?cè)谡{(diào)試一個(gè)功能的時(shí)候往往就是調(diào)試背后的SQL語(yǔ)句。還有一種情況就是,修改表結(jié)構(gòu)的時(shí)候,由于數(shù)據(jù)量過(guò)大,我們會(huì)放棄普遍方法,會(huì)尋找一個(gè)快速的方法。
鎖等待
比如發(fā)生死鎖的時(shí)候,或者兩個(gè)鎖在爭(zhēng)鎖的時(shí)候。往往會(huì)需要kill。結(jié)束掉一個(gè)事務(wù)給事務(wù)回滾放行另一個(gè)事務(wù)
kill內(nèi)部都做了啥
首先介紹兩種kill寫(xiě)法吧
kill query + 線(xiàn)程 id:表示終止這個(gè)線(xiàn)程中正在執(zhí)行的語(yǔ)句 kill connection + 線(xiàn)程 id:表示斷開(kāi)這個(gè)線(xiàn)程的連接,當(dāng)然如果這個(gè)線(xiàn)程有語(yǔ)句正在執(zhí)行,也是要先停止正在執(zhí)行的語(yǔ)句的。
言歸正傳
前幾篇文章我們介紹過(guò),對(duì)一個(gè)表進(jìn)行增刪改查的時(shí)候,會(huì)在表上加一個(gè)讀鎖。這個(gè)時(shí)候用戶(hù)雖然處于blocked狀態(tài),但是還拿著MDL讀鎖。如果線(xiàn)程直接被kill的話(huà),讀鎖就沒(méi)辦法釋放了。所以最理想的狀態(tài)應(yīng)該是,kill之后,讓他做一些收尾工作,全部結(jié)束之后再結(jié)束掉線(xiàn)程。
那么它到底做了啥
把 session B 的運(yùn)行狀態(tài)改成 THD::KILL_QUERY(將變量 killed 賦值為 THD::KILL_QUERY); 給 session B 的執(zhí)行線(xiàn)程發(fā)一個(gè)信號(hào)。
流程擴(kuò)展
我們繼續(xù)按照上述的流程作一個(gè)擴(kuò)展。為什么要發(fā)信號(hào)呢?
舉一個(gè)多用戶(hù)請(qǐng)求的例子。如果用戶(hù)A處于鎖等待狀態(tài),如果只是把用戶(hù)A的線(xiàn)程狀態(tài)設(shè)置為THD::KILL_QUERY?,線(xiàn)程A并不知道這個(gè)狀態(tài)變化,還是會(huì)繼續(xù)等待。發(fā)一個(gè)信號(hào)的目的,就是讓 用戶(hù)A 退出等待,來(lái)處理這個(gè)?THD::KILL_QUERY?狀態(tài)。
換言之。如果發(fā)現(xiàn)線(xiàn)程狀態(tài)是THD::KILL_QUERY?才開(kāi)始進(jìn)入語(yǔ)句終止邏輯。
kill不掉是啥鬼
首先我們介紹一個(gè)參數(shù),控制線(xiàn)程并發(fā)上限的這個(gè)參數(shù)innodb_thread_concurrency?舉例說(shuō)明一下
sessionA:select sleep(100) from t sessionB:select sleep(100) from t sessionC:select sleep(100) from t (blocked) sessionD:kill query C sessionE:kill C <=> kill connection C
通過(guò)上述5個(gè)用戶(hù)的執(zhí)行,我們先把他設(shè)置成set global innodb_thread_concurrency=2?可以看到
sesssion C 執(zhí)行的時(shí)候被堵住了;?因?yàn)椴l(fā)查詢(xún)線(xiàn)程上限了 但是 session D 執(zhí)行的 kill query C 命令卻沒(méi)什么效果, 直到 session E 執(zhí)行了 kill connection 命令,才斷開(kāi)了 session C 的連接,提示“Lost connection to MySQL server during query”, 但是這時(shí)候,如果在 session E 中執(zhí)行 show processlist,你就能看到下面這個(gè)圖。
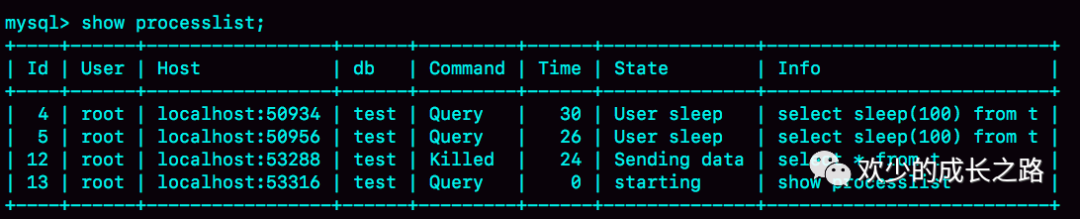
由圖得知,id=12 這個(gè)線(xiàn)程的 Commnad 列顯示的是 Killed。也就是說(shuō),客戶(hù)端雖然斷開(kāi)了連接,但實(shí)際上服務(wù)端上這條語(yǔ)句還在執(zhí)行過(guò)程中。
為什么在執(zhí)行 kill query 命令時(shí),不像 update 語(yǔ)句一樣退出呢?
在實(shí)現(xiàn)上,等行鎖時(shí),使用的是?pthread_cond_timedwait?函數(shù),這個(gè)等待狀態(tài)可以被喚醒。但是,在這個(gè)例子里,12 號(hào)線(xiàn)程的等待邏輯是這樣的:每 10 毫秒判斷一下是否可以進(jìn)入 InnoDB 執(zhí)行,如果不行,就調(diào)用 nanosleep 函數(shù)進(jìn)入 sleep 狀態(tài)。
也就是說(shuō),雖然 12 號(hào)線(xiàn)程的狀態(tài)已經(jīng)被設(shè)置成了 KILL_QUERY,但是在這個(gè)等待進(jìn)入 InnoDB 的循環(huán)過(guò)程中,并沒(méi)有去判斷線(xiàn)程的狀態(tài),因此根本不會(huì)進(jìn)入終止邏輯階段。
而當(dāng) session E 執(zhí)行 kill connection 命令時(shí)
把 12 號(hào)線(xiàn)程狀態(tài)設(shè)置為 KILL_CONNECTION; 關(guān)掉 12 號(hào)線(xiàn)程的網(wǎng)絡(luò)連接。因?yàn)橛羞@個(gè)操作,所以你會(huì)看到,這時(shí)候 session C 收到了斷開(kāi)連接的提示。
show processlist 隱藏邏輯?如果一個(gè)線(xiàn)程的狀態(tài)是KILL_CONNECTION,就把Command列顯示成Killed。
所以在show processlist列表中會(huì)把connection改成killed,也就是我們看到的狀態(tài)。
綜上所述 kill無(wú)效的幾種情況:
線(xiàn)程沒(méi)有執(zhí)行到判斷線(xiàn)程狀態(tài)的邏輯
跟這種情況相同的,還有由于 IO 壓力過(guò)大,讀寫(xiě) IO 的函數(shù)一直無(wú)法返回,導(dǎo)致不能及時(shí)判斷線(xiàn)程的狀態(tài)。
終止邏輯耗時(shí)較長(zhǎng)
從 show processlist 結(jié)果上看也是 Command=Killed,需要等到終止邏輯完成,語(yǔ)句才算真正完成。比如超大事務(wù)被kill需要做很多回收查找,大查詢(xún)回滾,DDL命令。
我們可以對(duì)大查詢(xún)回滾做一個(gè)擴(kuò)展介紹,前幾篇文章我們介紹過(guò)查詢(xún)數(shù)據(jù)的時(shí)候,當(dāng)數(shù)據(jù)量超過(guò)一個(gè)數(shù)量的時(shí)候我們會(huì)采用硬盤(pán)存儲(chǔ),如果小于這個(gè)數(shù)量的時(shí)候會(huì)采用內(nèi)存存儲(chǔ)。所以如果在磁盤(pán)中查詢(xún)的時(shí)候。進(jìn)行回滾!相應(yīng)的磁盤(pán)頁(yè)也會(huì)消耗一定的時(shí)間去關(guān)閉釋放。
客戶(hù)端與服務(wù)端的關(guān)閉問(wèn)題
Ctrl+C 關(guān)閉的什么
客戶(hù)端的操作只能操作到客戶(hù)端的線(xiàn)程,客戶(hù)端和服務(wù)端只能通過(guò)網(wǎng)絡(luò)交互,是不可能直接操作服務(wù)端線(xiàn)程的。而由于 MySQL 是停等協(xié)議,所以這個(gè)線(xiàn)程執(zhí)行的語(yǔ)句還沒(méi)有返回的時(shí)候,再往這個(gè)連接里面繼續(xù)發(fā)命令也是沒(méi)有用的。實(shí)際上,執(zhí)行 Ctrl+C 的時(shí)候,是 MySQL 客戶(hù)端另外啟動(dòng)一個(gè)連接,然后發(fā)送一個(gè) kill query 命令。
所以,你可別以為在客戶(hù)端執(zhí)行完 Ctrl+C 就萬(wàn)事大吉了。因?yàn)椋?kill 掉一個(gè)線(xiàn)程,還涉及到后端的很多操作。
數(shù)據(jù)表過(guò)多會(huì)影響性能嗎
我們?cè)诘谝黄恼戮徒榻B了每個(gè)客戶(hù)端和服務(wù)器建立連接時(shí),做了哪些事情。比如TCP握手,用戶(hù)校驗(yàn),獲取權(quán)限等
但實(shí)際上,當(dāng)使用默認(rèn)參數(shù)連接的時(shí)候,MySQL 客戶(hù)端會(huì)提供一個(gè)本地庫(kù)名和表名補(bǔ)全的功能。為了實(shí)現(xiàn)這個(gè)功能,客戶(hù)端在連接成功后,需要多做一些操作:
執(zhí)行 show databases; 切到 db1 庫(kù),執(zhí)行 show tables; 把這兩個(gè)命令的結(jié)果用于構(gòu)建一個(gè)本地的哈希表。
最耗時(shí)的也就是第三步的哈希表構(gòu)建了,也就是說(shuō),我們感知到的連接過(guò)程慢,其實(shí)并不是連接慢,也不是服務(wù)端慢,而是客戶(hù)端慢
-A,-quick?可以跳過(guò)這個(gè)階段。為什么這么說(shuō)呢,我們可以介紹一下 -quick參數(shù)涉及的MySQL配置。
MySQL 客戶(hù)端發(fā)送請(qǐng)求后,接收服務(wù)端返回結(jié)果的方式有兩種:
一種是本地緩存,也就是在本地開(kāi)一片內(nèi)存,先把結(jié)果存起來(lái)。如果你用 API 開(kāi)發(fā),對(duì)應(yīng)的就是 mysql_store_result 方法。 另一種是不緩存,讀一個(gè)處理一個(gè)。如果你用 API 開(kāi)發(fā),對(duì)應(yīng)的就是 mysql_use_result 方法。
MySQL 客戶(hù)端默認(rèn)采用第一種方式,而如果加上–quick 參數(shù),就會(huì)使用第二種不緩存的方式。
采用不緩存的方式時(shí),如果本地處理得慢,就會(huì)導(dǎo)致服務(wù)端發(fā)送結(jié)果被阻塞,因此會(huì)讓服務(wù)端變慢
擴(kuò)展
為什么取名為quick呢?
第一點(diǎn),就是前面提到的,跳過(guò)表名自動(dòng)補(bǔ)全功能。 第二點(diǎn),mysql_store_result 需要申請(qǐng)本地內(nèi)存來(lái)緩存查詢(xún)結(jié)果,如果查詢(xún)結(jié)果太大,會(huì)耗費(fèi)較多的本地內(nèi)存,可能會(huì)影響客戶(hù)端本地機(jī)器的性能; 第三點(diǎn),是不會(huì)把執(zhí)行命令記錄到本地的命令歷史文件。
綜上所述:quick是提升客戶(hù)端的性能,不是提升服務(wù)端的性能
聲明
這里聲明一下我最近的MySQL文章。支持原創(chuàng)!創(chuàng)作來(lái)源于林曉斌老師的MySQL45講!但是只是參考,在林曉斌老師的基礎(chǔ)上自己總結(jié)了一些知識(shí)點(diǎn)。有些地方是比較像的但是都是白話(huà)文,林曉斌老師已經(jīng)總結(jié)的很好了。具體的課程我還是不發(fā)了,需要的話(huà)自己找我拿卷。我怕發(fā)出去又怕被人黑。說(shuō)我賣(mài)課!
總結(jié)
今天大概介紹了MySQL內(nèi)部在kill線(xiàn)程的時(shí)候,都做了哪些操作以及強(qiáng)化了最開(kāi)始的文章深度。
這里的文章深度主要是在哈希表構(gòu)建的那一段。
下一篇文章 更新一篇字節(jié),網(wǎng)易,阿里,騰訊,美團(tuán),快手面試系列的MySQL文章