
C++ 與正則表達(dá)式
正則表達(dá)式可以說(shuō)是軟件開(kāi)發(fā)中最常用的功能之一。本文將以C++語(yǔ)言為例,介紹其中的正則表達(dá)式相關(guān)知識(shí)。
前言當(dāng)你想要判斷許多字符串是否符合某個(gè)特定格式;當(dāng)你想在一大段文本中查找出所有的日期和時(shí)間;當(dāng)你想要修改大量日志中所有的時(shí)間格式,在這些情況下,正則表達(dá)式都能幫上忙。
簡(jiǎn)單來(lái)說(shuō),正則表達(dá)式描述了一系列規(guī)則,通過(guò)這些規(guī)則,可以在字符串中找到相關(guān)的內(nèi)容,規(guī)則使得搜索的能力更加強(qiáng)大。匹配的過(guò)程由正則表達(dá)式引擎完成。開(kāi)發(fā)者通常不需要關(guān)心正則表達(dá)式引擎的實(shí)現(xiàn)細(xì)節(jié),直接使用其提供的能力即可。
正則表達(dá)式非常的常用,但真正精通它的人卻不多。本文試圖給大家講解一些對(duì)于C++語(yǔ)言使用正則表達(dá)式的基礎(chǔ)知識(shí)。
代碼示例本文中所貼出的代碼示例可以到我的Github上獲取:paulQuei/cpp-regex[1]。
或者,你也可以直接通過(guò)下面這條命令獲取所有源碼:
git clone https://github.com/paulQuei/cpp-regex.git
C++中正則表達(dá)式的API基本上都位于頭文件中。
為了簡(jiǎn)化書(shū)寫(xiě),本文中給出的代碼都已經(jīng)默認(rèn)做了以下操作:
#include?<iostream>
#include?<regex>
using?namespace?std;
為了使大家有一個(gè)直觀的感受,文章的開(kāi)頭先通過(guò)一些入門(mén)示例給大家一個(gè)直觀的感受。在這個(gè)基礎(chǔ)之上,再詳細(xì)講解其中的細(xì)節(jié)。
使用正則表達(dá)式的大致流程如下:首先你有一段需要處理的文本。這可能是一個(gè)字符串對(duì)象,也可能是一個(gè)文本文件,或者是一大堆日志。接下來(lái)你會(huì)有特定的目標(biāo),例如:找出文本中所有的時(shí)間和日期。這個(gè)時(shí)候你就需要根據(jù)可能的格式寫(xiě)出具體的正則表達(dá)式,例如,日期的格式是:2020-01-01,那么你的正則表達(dá)式可能是這樣:\d{4}-\d{2}-\d{2}。(你現(xiàn)在不必糾結(jié)與這個(gè)正則表達(dá)式是什么意思,因?yàn)檫@是本文接下來(lái)要講解的內(nèi)容。)
有了正則表達(dá)式之后,你需要將你的文本和正則表達(dá)式交給正則表達(dá)式引擎 – 由C++語(yǔ)言(或者其他語(yǔ)言)提供。引擎會(huì)在文本中搜索到匹配的結(jié)果。這個(gè)結(jié)果的格式可能是包含了多個(gè)組,例如:你可能需要分離出年份和月份。有了引擎返回的結(jié)果之后,你就可以進(jìn)一步處理了。
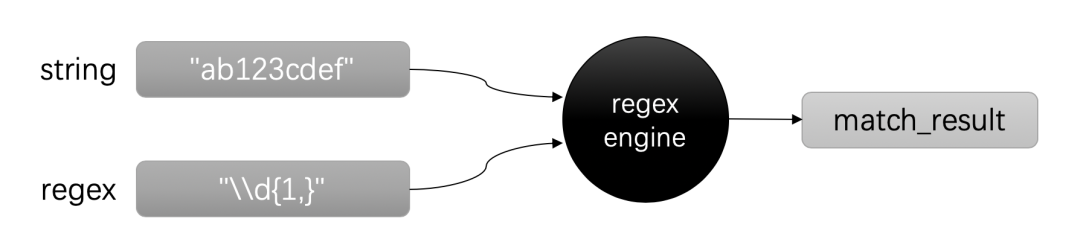 img
img使用正則表達(dá)式的流程大體都是一致的,下面是最常見(jiàn)的三種使用方式。
匹配
匹配是判斷給定的字符串是否符合某個(gè)正則表達(dá)式。例如:你想判斷當(dāng)前文本是否全部由數(shù)字構(gòu)成。
下面是一段代碼示例:
string?s1?=?"ab123cdef";?//?①
string?s2?=?"123456789";?//?②
regex?ex("\\d+");?//?③
cout?<<?s1?<<?"?is?all?digit:?"?<<?regex_match(s1,?ex)?<<?endl;?//?④
cout?<<?s2?<<?"?is?all?digit:?"?<<?regex_match(s2,?ex)?<<?endl;?//?⑤
在這段代碼中:
- 這是一個(gè)包含了數(shù)字和字母的字符串
- 這是一個(gè)只包含了數(shù)字的字符串
- 這是我們的正則表達(dá)式,它表示:有多個(gè)數(shù)字
- 通過(guò)
regex_match判斷第一個(gè)字符串是否匹配,這里將返回false - 通過(guò)
regex_match判斷第二個(gè)字符串是否匹配,這里將返回true
這段代碼輸出如下:
ab123cdef?is?all?digit:?0
123456789?is?all?digit:?1
請(qǐng)注意,正則表達(dá)式有它自身的語(yǔ)法。這與C++的語(yǔ)法是兩回事。C++編譯器只會(huì)檢查C++代碼的語(yǔ)法。因此,即便你的代碼通過(guò)了C++編譯器的語(yǔ)法檢查,但在運(yùn)行的時(shí)候,由于正則表達(dá)式的語(yǔ)義,還可能出現(xiàn)正則表達(dá)式的錯(cuò)誤。正則表達(dá)式的錯(cuò)看起來(lái)類(lèi)似這樣:
terminating with uncaught exception of type std::__1::regex_error: The expression contained an invalid escaped character, or a trailing escape.。
搜索
還有一些時(shí)候,我們要判斷的并非是文本的全體是否匹配。而是在一大段文本中搜索匹配的目標(biāo)。
下面是一段代碼示例,這段示例演示了在一個(gè)字符串中查找數(shù)字:
string?s?=?"ab123cdef";?//?①
regex?ex("\\d+");????//?②
smatch?match;?//?③
regex_search(s,?match,?ex);?//?④
cout?<<?s?<<?"?contains?digit:?"?<<?match[0]?<<?endl;?//?⑤
- 這是一個(gè)包含了數(shù)字和字母的字符串
- 和前面一樣的正則表達(dá)式
- 通過(guò)
std::smatch來(lái)保存匹配的結(jié)果。除了std::smatch,還有std::cmatch也很常用。前者是以std::string的形式返回結(jié)果,后者是以const char*的形式返回結(jié)果。 - 通過(guò)
regex_search函數(shù)搜索結(jié)果 - 打印出匹配的結(jié)果
這段代碼輸出如下:
ab123cdef?contains?digit:?123
替換
最后,使用正則表達(dá)式的還有一個(gè)常見(jiàn)功能是文本替換。很多的編輯器都有這樣的功能。
例如,下圖是我的Sublime編譯器,在搜索替換文本的時(shí)候,可以使用正則表達(dá)式,這時(shí)搜索的能力就更加強(qiáng)大了。“Find:”部分可以通過(guò)正則表達(dá)式來(lái)描述待替換的字符串,“Replace:”部分填寫(xiě)替換的字符串。
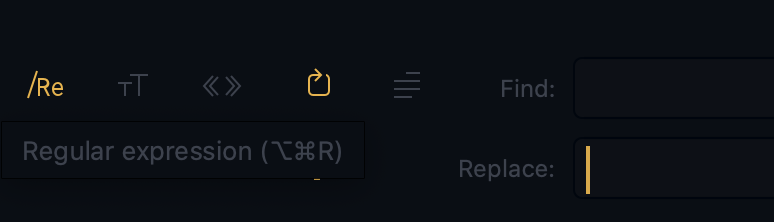 img
img下面是在C++中使用正則表達(dá)式完成字符串替換的代碼示例:
string?s?=?"ab123cdef";?//?①
regex?ex("\\d+");????//?②
string?r?=?regex_replace(s,?ex,?"xxx");?//?③
cout?<<?r?<<?endl;?//?④
- 仍然是前面這個(gè)字符串
- 仍然是同樣的正則表達(dá)式
- 通過(guò)
regex_replace完成替換 - 通過(guò)
cout輸出結(jié)果
最終輸出的字符串如下:
abxxxcdef
通過(guò)上面的三個(gè)示例我們看到,regex_match,regex_search和regex_replace三個(gè)函數(shù)是正則表達(dá)式的核心,它們會(huì)運(yùn)行正則表達(dá)式引擎完成匹配,查找和替換任務(wù)。
文法
C++中內(nèi)置了多種正則表達(dá)式文法,在創(chuàng)建正則表達(dá)式的時(shí)候可以通過(guò)參數(shù)來(lái)選擇。
它們?nèi)缦卤硭荆?/p>
| 文法 | 說(shuō)明 |
|---|---|
| ECMAScript | ECMAScript正則表達(dá)式語(yǔ)法[2],默認(rèn)選項(xiàng) |
| basic | 基礎(chǔ)POSIX正則表達(dá)式語(yǔ)法[3] |
| extended | 擴(kuò)展POSIX正則表達(dá)式語(yǔ)法[4] |
| awk | awk工具的正則表達(dá)式語(yǔ)法[5] |
| grep | grep工具的正則表達(dá)式語(yǔ)法[6] |
| egrep | grep工具的正則表達(dá)式語(yǔ)法[7] |
不同的文法在表達(dá)上有一些不同,如果你原先已經(jīng)很熟悉awk或者egrep文法的正則表達(dá)式,你可以直接使用它們。對(duì)于其他人來(lái)說(shuō),我們直接使用默認(rèn)的ECMAScript文法即可(Javascript的正則表達(dá)式也是使用ECMAScript文法)。
grep的全稱(chēng)是Global Regular Expression Print。這個(gè)名字是在提示我們,它本身與正則表達(dá)式的歷史有著特定的聯(lián)系。
C++ 中的 ECMAScript 正則表達(dá)式文法是?ECMA-262 文法[8],你可以點(diǎn)擊鏈接查看詳細(xì)內(nèi)容。
下文中,我們僅會(huì)講解該標(biāo)準(zhǔn)下的正則表達(dá)式。
Raw string literal
在代碼中寫(xiě)字符串有時(shí)候是比較麻煩的,因?yàn)楹芏嘧址枰ㄟ^(guò)反斜杠轉(zhuǎn)義。當(dāng)有多個(gè)反斜杠連在一起時(shí),就很容易寫(xiě)錯(cuò)或者理解錯(cuò)了。
當(dāng)通過(guò)字符串來(lái)寫(xiě)正則表達(dá)式時(shí),這個(gè)問(wèn)題就更嚴(yán)重了。因?yàn)檎齽t表達(dá)式本身也有一些字符需要轉(zhuǎn)義。例如,對(duì)于這樣一個(gè)字符串?"('(?:[^\\\\']|\\\\.)*'|\"(?:[^\\\\\"]|\\\\.)*\")|"?大部分人恐怕很難一眼看出其含義了。
在正則表達(dá)式很復(fù)雜的時(shí)候,推薦大家使用Raw string literal來(lái)表達(dá)。這種表達(dá)式是告訴編譯器:這里的內(nèi)容是純字符串,因此不再需要增加反斜杠來(lái)轉(zhuǎn)義特殊字符。
Raw string literal的格式如下:
R"delimiter(raw_characters)delimiter"
這其中:
- delimiter是可選的分隔符,通常不用寫(xiě)
- raw_characters是具體的字符串
也就是說(shuō),R"(content)"中的content是你需要的字符串本身。
下面是一個(gè)代碼示例:
string?s?=?R"("\w\\w\\\w)";cout?<<?s?<<?endl;
它將輸出:
"\w\\w\\\w
可以看到,這里的雙引號(hào)和反斜杠不會(huì)被解釋成轉(zhuǎn)義字符,而是當(dāng)成字符串內(nèi)容本身,因此會(huì)原樣輸出。這樣就減少了轉(zhuǎn)義字符的復(fù)雜度,于是更容易理解了。
特殊字符
正則表達(dá)式本身定義了一些特殊的字符,這些字符有著特殊的含義。它們?nèi)缦卤硭尽?/p>
| 字符 | 說(shuō)明 |
|---|---|
| . | 匹配任意字符 |
| [ | 字符類(lèi)的開(kāi)始 |
| ] | 字符類(lèi)的結(jié)束 |
| { | 量詞重復(fù)數(shù)開(kāi)始 |
| } | 量詞重復(fù)數(shù)結(jié)束 |
| ( | 分組開(kāi)始 |
| ) | 分組結(jié)束 |
| \ | 轉(zhuǎn)義字符 |
| \ | 轉(zhuǎn)義字符自身 |
| * | 量詞,0個(gè)或者多個(gè) |
| + | 量詞,1個(gè)或者多個(gè) |
| ? | 量詞,0個(gè)或者1個(gè) |
| | | 或 |
| ^ | 行開(kāi)始;否定 |
| $ | 行結(jié)束 |
| \n | 換行 |
| \t | Tab符 |
| \xhh | hh表示兩位十六進(jìn)展表示的Unicode字符 |
| \xhhhh | hhhh表示四位十六進(jìn)制表示的Unicode字符串 |
這些字符并不少,剛開(kāi)始接觸可能記不住,但隨著下文的講解,相信你會(huì)逐漸熟悉它們。
字符類(lèi)
字符類(lèi),顧名思義:是對(duì)字符的分類(lèi)。
例如:1234567890這些都屬于數(shù)字字符類(lèi)。除此之外,還有其他的分類(lèi),它們?nèi)缦卤硭荆?/p>
| 字符類(lèi) | 簡(jiǎn)寫(xiě) | 說(shuō)明 |
|---|---|---|
| [[:alnum:]] | 字母和數(shù)字 | |
| [_[:alnum:]] | \w | 字母,數(shù)字以及下劃線 |
| [^_[:alnum:]] | \W | 非字母,數(shù)字以及下劃線 |
| [[:digit:]] | \d | 數(shù)字 |
| [^[:digit:]] | \D | 非數(shù)字 |
| [[:space:]] | \s | 空白字符 |
| [^[:space:]] | \S | 非空白字符 |
| [[:lower:]] | 小寫(xiě)字母 | |
| [[:upper:]] | 大寫(xiě)字母 | |
| [[:alpha:]] | 任意字母 | |
| [[:blank:]] | 非換行符的空白字符 | |
| [[:cntrl:]] | 控制字符 | |
| [[:graph:]] | 圖形字符 | |
| [[:print:]] | 可打印字符 | |
| [[:punct:]] | 標(biāo)點(diǎn)字符 | |
| [[:xdigit:]] | 十六進(jìn)制的數(shù)字字符 |
這里我們可以看到:
- 字符類(lèi)通過(guò)
[]作為標(biāo)識(shí),因此這兩個(gè)字符是正則表達(dá)式的中的特殊字符。如果是想使用這兩個(gè)字符本身,需要對(duì)它們進(jìn)行轉(zhuǎn)義。 - 在
[]內(nèi)部,通過(guò)[:xxx:]來(lái)描述字符類(lèi)的名稱(chēng)。 []中可以通過(guò)^表示否定,即:字符類(lèi)的反面。- 字母,數(shù)字和空白字符由于這些字符類(lèi)非常常用,因此它們有簡(jiǎn)寫(xiě)的方法。簡(jiǎn)寫(xiě)使得正則表達(dá)式更加簡(jiǎn)潔,但表達(dá)的含義是一樣的。
接下來(lái)我們看一個(gè)代碼示例:
#include?<iostream>
#include?<regex>
using?namespace?std;
static?void?search_string(const?string&?str,
??????????????????????????const?regex&?reg_ex)?{?//?①
??for?(string::size_type?i?=?0;?i?<?str.size()?-?1;?i++)?{
????auto?substr?=?str.substr(i,?1);
????if?(regex_match(substr,?reg_ex))?{
??????cout?<<?substr;
????}
??}
}
static?void?search_by_regex(const?char*?regex_s,
????????????????????????????const?string&?s)?{?//?②
??regex?reg_ex(regex_s);
??cout.width(12);?//?③
??cout?<<?regex_s?<<?":?\"";?//?④
??search_string(s,?reg_ex);??//?⑤
??cout?<<?"\""?<<?endl;
}
int?main()?{
??string?s("_AaBbCcDdEeFfGg12345?\t\n!@#$%");?//?⑥
??search_by_regex("[[:alnum:]]",?s);??????????//?⑦
??search_by_regex("\\w",?s);??????????????????//?⑧
??search_by_regex(R"(\W)",?s);????????????????//?⑨
??search_by_regex("[[:digit:]]",?s);??????????//?⑩
??search_by_regex("[^[:digit:]]",?s);?????????//??
??search_by_regex("[[:space:]]",?s);??????????//??
??search_by_regex("\\S",?s);??????????????????//??
??search_by_regex("[[:lower:]]",?s);??????????//??
??search_by_regex("[[:upper:]]",?s);
??search_by_regex("[[:alpha:]]",?s);??????????//??
??search_by_regex("[[:blank:]]",?s);??????????//??
??search_by_regex("[[:graph:]]",?s);??????????//??
??search_by_regex("[[:print:]]",?s);??????????//??
??search_by_regex("[[:punct:]]",?s);??????????//??
??search_by_regex("[[:xdigit:]]",?s);?????????//??
??return?0;
}
這段代碼稍微有些長(zhǎng),但還是比較好理解的。
- 這里定義了一個(gè)函數(shù),它接受一個(gè)字符串和一個(gè)正則表達(dá)式作為輸入。該函數(shù)遍歷字符串,每次取出一個(gè)字符然后用正則表達(dá)式進(jìn)行匹配,如果匹配上,則輸出該字符。逐個(gè)遍歷字符串的方式并不是非常好,在后文中我們將看到更好的方法。
search_by_regex將調(diào)用search_string進(jìn)行字符的匹配。cout.width(12);?是為了控制輸出格式的縮進(jìn)。- 先打印出正則表達(dá)式,然后打印冒號(hào)和雙引號(hào)。將匹配的內(nèi)容放在雙引號(hào)中是為了更容易辨識(shí)。
- 調(diào)用
search_string進(jìn)行字符的匹配。 - 這是我們待匹配的字符串,它其中包含了各種類(lèi)型的字符。
[[:alnum:]]匹配字母和數(shù)字類(lèi)字符。\w是[_[:alnum:]]的簡(jiǎn)寫(xiě)方式,它與字符數(shù)字的區(qū)別在與:它還包含了_。當(dāng)通過(guò)字符串定義正則表達(dá)式時(shí),反斜杠需要轉(zhuǎn)義。R"(\W)"是一個(gè)Raw string literal,因此,這里的反斜杠不再需要轉(zhuǎn)義。[[:digit:]]匹配數(shù)字類(lèi)字符。[^[:digit:]]是非數(shù)字類(lèi)正則表達(dá)式,它與⑩正好相反。[[:space:]]匹配空白類(lèi)字符,該表達(dá)式將包含換行符。\S是非空白類(lèi)字符類(lèi)。[[:lower:]]小寫(xiě)字母,[[:upper:]]下一行是大寫(xiě)字母。[[:alpha:]]匹配所有字母字符。[[:blank:]]是空白字符類(lèi),它與[[:space:]]的區(qū)別是:它不包含換行符。[[:graph:]]是圖形類(lèi)字符。[[:print:]]是可打印字符。[[:punct:]]是標(biāo)點(diǎn)符號(hào)字符。[[:xdigit:]]是十六進(jìn)制的數(shù)字字符。
該程序的輸出如下:
??[[:alnum:]]:?"AaBbCcDdEeFfGg12345"
??????????\w:?"_AaBbCcDdEeFfGg12345"
??????????\W:?"??
!@#$"
?[[:digit:]]:?"12345"
[^[:digit:]]:?"_AaBbCcDdEeFfGg??
!@#$"
?[[:space:]]:?"??
"
??????????\S:?"_AaBbCcDdEeFfGg12345!@#$"
?[[:lower:]]:?"abcdefg"
?[[:upper:]]:?"ABCDEFG"
?[[:alpha:]]:?"AaBbCcDdEeFfGg"
?[[:blank:]]:?"??"
?[[:graph:]]:?"_AaBbCcDdEeFfGg12345!@#$"
?[[:print:]]:?"_AaBbCcDdEeFfGg12345?!@#$"
?[[:punct:]]:?"_!@#$"
[[:xdigit:]]:?"AaBbCcDdEeFf12345"
請(qǐng)仔細(xì)看一下這個(gè)輸出,并確認(rèn)與你的認(rèn)知是否一致。這里的有些字符類(lèi)包含了換行符,因此在輸出的結(jié)果中也是換行的。
重復(fù)
上面的示例中,我們一次只匹配了一個(gè)字符。這樣做效率是很低的。
在很多時(shí)候,我們當(dāng)然是想一次性匹配出一個(gè)完整的字符串。例如:一個(gè)手機(jī)號(hào)碼。這種情況下,其實(shí)是多個(gè)數(shù)字字符的重復(fù)。
下面就是在正則表達(dá)式中描述重復(fù)的方式。它們通常跟在字符類(lèi)的后面,描述該字符出現(xiàn)多次。
| 字符 | 說(shuō)明 |
|---|---|
| {n} | 重復(fù)n次 |
| {n,} | 重復(fù)n或更多次 |
| {n,m} | 重復(fù)[n ~ m]次 |
| * | 重復(fù)0次或多次,等同于{0,} |
| + | 重復(fù)1次或多次,等同于{1,} |
| ? | 重復(fù)0次或1次,等同于{0,1} |
知道重復(fù)的方法之后,正則表達(dá)式的查找能力就更強(qiáng)大了。看一下下面這個(gè)代碼示例:
#include?<iostream>
#include?<regex>
using?namespace?std;
static?void?search_by_regex(const?char*?regex_s,
????????????????????????????const?string&?s)?{?//?①
??regex?reg_ex(regex_s);
??smatch?match_result;?//?②
??cout.width(14);?//?③
??if?(regex_search(s,?match_result,?reg_ex))?{?//?④
????cout?<<?regex_s?<<?":?\""?<<?match_result[0]?<<?"\""?<<?endl;?//?⑤
??}
}
int?main()?{
??string?s("_AaBbCcDdEeFfGg12345!@#$%?\t");?//?⑥
??search_by_regex("[[:alnum:]]{5}",?s);???????//?⑦
??search_by_regex("\\w{5,}",?s);??????????????//?⑧
??search_by_regex(R"(\W{3,5})",?s);???????????//?⑨
??search_by_regex("[[:digit:]]*",?s);?????????//?⑩
??search_by_regex(".+",?s);???????????????????//??
??search_by_regex("[[:lower:]]?",?s);?????????//??
??return?0;
}
在這段代碼中:
- 這里定義了一個(gè)函數(shù),它接受一個(gè)正則表達(dá)式和字符串。
match_result用來(lái)存儲(chǔ)查找的結(jié)果。- 設(shè)置輸出格式,為了讓輸出對(duì)齊。
- 通過(guò)
regex_search在字符串中查找匹配字符。 - 輸出匹配的結(jié)果。
- 待匹配的字符串。
[[:alnum:]]{5}是指:字符或者數(shù)字出現(xiàn)5次。\\w{5,}是指:字母,數(shù)字或者下劃線出現(xiàn)5次或更多次。R"(\W{3,5})"是指:非字母,數(shù)字或者下劃線出現(xiàn)3次到5次。[[:digit:]]*是指:數(shù)字出現(xiàn)任意多次。.+是指:任意字符出現(xiàn)至少1次。[[:lower:]]?是指:小寫(xiě)字母出現(xiàn)0次或者1次。
該程序輸出如下:
[[:alnum:]]{5}:?"AaBbC"
????????\w{5,}:?"_AaBbCcDdEeFfGg12345"
???????\W{3,5}:?"!@#$%"
??[[:digit:]]*:?""
????????????.+:?"_AaBbCcDdEeFfGg12345!@#$%??"
??[[:lower:]]?:?""
接下來(lái)我們會(huì)看到更多的示例。同時(shí),也會(huì)看到C++正則表達(dá)式API的更多功能。
為了便于下文示例的講解,我們以維基百科上對(duì)于正則表達(dá)式的介紹文本為基礎(chǔ)。
A regular expression, regex or regexp ((sometimes called a rational expression)) is a sequence of characters that define a search pattern. Usually such patterns are used by string searching algorithms for “find” or “find and replace” operations on strings, or for input validation. It is a technique developed in theoretical computer science and formal language theory.
The concept arose in the 1950s when the American mathematician Stephen Cole Kleene formalized the description of a regular language. The concept came into common use with Unix text-processing utilities. Different syntaxes for writing regular expressions have existed since the 1980s, one being the POSIX standard and another, widely used, being the Perl syntax.
Regular expressions are used in search engines, search and replace dialogs of word processors and text editors, in text processing utilities such as sed and AWK and in lexical analysis. Many programming languages provide regex capabilities either built-in or via libraries.
我們將這段文字保存在名稱(chēng)為content.txt的文本文件中。下面幾個(gè)示例會(huì)在這個(gè)文本上操作。
迭代器
在上文中,為了從字符串中查找出所有匹配的字符,我們的做法是遍歷原始字符串的每一個(gè)子字符串來(lái)進(jìn)行查找,這樣做很明顯效率很低。更好的做法當(dāng)然是使用迭代器。
正則表達(dá)式迭代器一共有四種,分別對(duì)應(yīng)了是否是寬字符,是否是字符串類(lèi)型:
| 類(lèi)型 | 定義 |
|---|---|
| cregex_iterator | regex_iterator<const char*> |
| wcregex_iterator | regex_iterator<const wchar_t*> |
| sregex_iterator | regex_iteratorstd::string::const_iterator |
| wsregex_iterator | regex_iteratorstd::wstring::const_iterator |
在一大段文本中查找所有匹配的目標(biāo),這是一個(gè)非常常見(jiàn)的需求。而迭代器正好滿足這一需求,它會(huì)依次返回它從文本中找到的匹配內(nèi)容。
- 示例:統(tǒng)計(jì)出文本中一共出現(xiàn)了多個(gè)單詞。
- 思路:組成單詞的字母可以使用
[[:alpha:]]字符類(lèi)來(lái)表達(dá),一個(gè)單詞至少有一個(gè)字母,因此這個(gè)正則表達(dá)式可以寫(xiě)成:[[:alpha:]]+。然后借助迭代器便可以統(tǒng)計(jì)出總數(shù)量。
代碼示例如下:
#include?<fstream>
#include?<iostream>
#include?<regex>
using?namespace?std;
int?main()?{
??regex?word_regex("[[:alpha:]]+");?//?①
??ifstream?file("./content.txt");?//?②
??string?line;
??int?word_count?=?0;
??while(getline(file,?line))?{?//?③
????auto?iter_begin?=?sregex_iterator(line.begin(),
??????????????????????????????????????line.end(),
??????????????????????????????????????word_regex);??//?④
????auto?iter_end?=?sregex_iterator();?//?⑤
????for?(auto?iter?=?iter_begin;?iter?!=?iter_end;?iter++)?{?//?⑥
??????word_count++;??//?⑦
??????//?cout?<<?iter->str()?<<?endl;?//?⑧
????}
??}
??cout?<<?"It?contains?"?<<?word_count?<<?"?words"?<<?endl;?//?⑨
??return?0;
}
這段代碼的說(shuō)明如下:
- 匹配單詞的正則表達(dá)式
- 通過(guò)
ifstream讀取文本文件 - 依次讀取文本文件中的每一行
- 通過(guò)正則表達(dá)式迭代器從文本行的逐個(gè)匹配
- 迭代器的末尾
- 迭代器遍歷
- 每遇到一個(gè)匹配進(jìn)行一次計(jì)數(shù)
- 如果需要,可以輸出匹配的內(nèi)容
這段代碼輸出如下:
It?contains?153?words
接下來(lái)的幾個(gè)代碼示例的主體結(jié)構(gòu)和這里會(huì)很相似,我們總是先打開(kāi)文本文件,然后讀取每一行來(lái)進(jìn)行處理。
正則表達(dá)式選項(xiàng)
前面的示例中我們已經(jīng)看到,通過(guò)std::regex并傳遞字符串就可以構(gòu)造正則表達(dá)式對(duì)象。實(shí)際上,除了std::regex,還有寬字符版本的std::wregex。它們都源自std::basic_regex
| 類(lèi)型 | 定義 |
|---|---|
| regex | basic_regex |
| wregex | basic_regex<wchar_t> |
在創(chuàng)建正則表達(dá)式對(duì)象的時(shí)候,除了描述規(guī)則本身的字符串之外,還可以傳遞一個(gè)flag_type類(lèi)型的參數(shù),該參數(shù)的值定義在std::regex_constants::syntax_option_type中。它們中與“文法”[9]相關(guān)的已經(jīng)在上文介紹過(guò)了。
剩下的還有幾個(gè)說(shuō)明如下:
| 值 | 效果 |
|---|---|
| icase | 以不考慮大小寫(xiě)進(jìn)行字符匹配。 |
| nosubs | 進(jìn)行匹配時(shí),將所有被標(biāo)記的子表達(dá)式 (expr) 當(dāng)做非標(biāo)記的子表達(dá)式 (?:expr) 。不將匹配存儲(chǔ)于提供的 std::regex_match 結(jié)構(gòu)中,且?mark_count()?為零 |
| optimize | 指示正則表達(dá)式引擎進(jìn)行更快的匹配,帶有令構(gòu)造變慢的潛在開(kāi)銷(xiāo)。例如這可能表示將非確定 FSA 轉(zhuǎn)換為確定 FSA 。 |
| collate | 形如 “[a-b]” 的字符范圍將對(duì)本地環(huán)境敏感。 |
| multiline(C++17) | 若選擇 ECMAScript 引擎,則指定^匹配行首,$應(yīng)該匹配行尾。 |
這其中,第一個(gè)是我們最常用的。
- 示例:匹配文本中“regular expression”所有的單復(fù)數(shù),并且不區(qū)分大小寫(xiě)。
- 思路:?jiǎn)卧~的首字母有些會(huì)大寫(xiě),我們可以通過(guò)
[Rr]來(lái)匹配大寫(xiě)或者小寫(xiě)的R字母,但實(shí)際上,使用icase無(wú)疑會(huì)更方便。
代碼示例:
#include?<fstream>
#include?<iostream>
#include?<regex>
using?namespace?std;
int?main()?{
??regex?word_regex("regular?expressions?",?regex::icase);
??ifstream?file("./content.txt");
??string?line;
??while(getline(file,?line))?{
????auto?iter_begin?=?sregex_iterator(line.begin(),
??????????????????????????????????????line.end(),
??????????????????????????????????????word_regex);
????auto?iter_end?=?sregex_iterator();
????for?(auto?iter?=?iter_begin;?iter?!=?iter_end;?iter++)?{
??????cout?<<?iter->str()?<<?endl;
????}
??}
??return?0;
}
這段代碼與前面的結(jié)構(gòu)是一樣的,我們最需要關(guān)注的可能就是下面這一行:
regex?word_regex("regular?expressions?",?regex::icase);
通過(guò)std::regex::icase我們指定了這個(gè)正則表達(dá)式是不區(qū)分大小寫(xiě)的。
另外還有一個(gè)值得注意的就是正則表達(dá)式末尾的...s?,它意味著單詞可能是單數(shù)或者復(fù)數(shù),因此結(jié)尾的“s”可以出現(xiàn)0次或者1次。
這段代碼輸出如下:
regular?expression
regular?expressions
Regular?expressions
匹配結(jié)果與分組
std::match_results用來(lái)存儲(chǔ)匹配結(jié)果。與迭代器類(lèi)似,匹配結(jié)果也有四種類(lèi)型:
| 類(lèi)型 | 定義 |
|---|---|
| std::cmatch | std::match_results<const char*> |
| std::wcmatch | std::match_results<const wchar_t*> |
| std::smatch | std::match_resultsstd::string::const_iterator |
| std::wsmatch | std::match_resultsstd::wstring::const_iterator |
當(dāng)我們使用正則表達(dá)式時(shí),我們的目標(biāo)常常不單單是判斷或者查找完整匹配的內(nèi)容。而是需要捕獲匹配結(jié)果中的子串。例如:我們不僅要匹配出日期,還要捕獲日期中的年份,月份等信息。這個(gè)時(shí)候就要使用分組功能。
我們?cè)诮榻B正則表達(dá)式特殊字符的時(shí)候,提到過(guò)圓括號(hào)(和)。它們的作用就是分組。當(dāng)你在正則表達(dá)式中配對(duì)的使用圓括號(hào)時(shí),就會(huì)形成一個(gè)分組,一個(gè)正則表達(dá)式中可以包含多個(gè)分組。分組通過(guò)編號(hào)0, 1, 2, …來(lái)區(qū)分。編號(hào)0的分組是匹配的整體,其他編號(hào)根據(jù)括號(hào)的順序來(lái)確定。
這些分組最終可以在匹配完成之后,可以通過(guò)std::match_results的API來(lái)獲取。這些API如下表所示:
| API | 說(shuō)明 |
|---|---|
| empty | 檢查匹配是否成功 |
| size | 返回完成建立的結(jié)果狀態(tài)中的匹配數(shù) |
| max_size | 返回子匹配的最大可能數(shù)量 |
| length | 返回特定分組的長(zhǎng)度 |
| position | 分會(huì)特定分組首字符的位置 |
| str | 返回特定分組的字符序列 |
| operation[] | 返回指定的分組 |
| prefix | 返回目標(biāo)序列起始和完整匹配起始之間的分組 |
| suffix | 返回完整匹配結(jié)果和目標(biāo)序列結(jié)尾之間的分組 |
在C++中,分組叫做子匹配(sub_match)。std::sub_match[10]?這個(gè)類(lèi)型只有一個(gè)默認(rèn)構(gòu)造函數(shù),通常你不會(huì)主動(dòng)創(chuàng)建它,而是使用std::match_results的接口來(lái)獲取它的對(duì)象。
示例:查找出文本中所有的年代,并分離出世紀(jì)的部分和年份的部分。思路:年代的格式是四位數(shù)字加上“s”作為后綴。我們可以通過(guò)分組的形式分離出兩個(gè)部分。圖示如下:
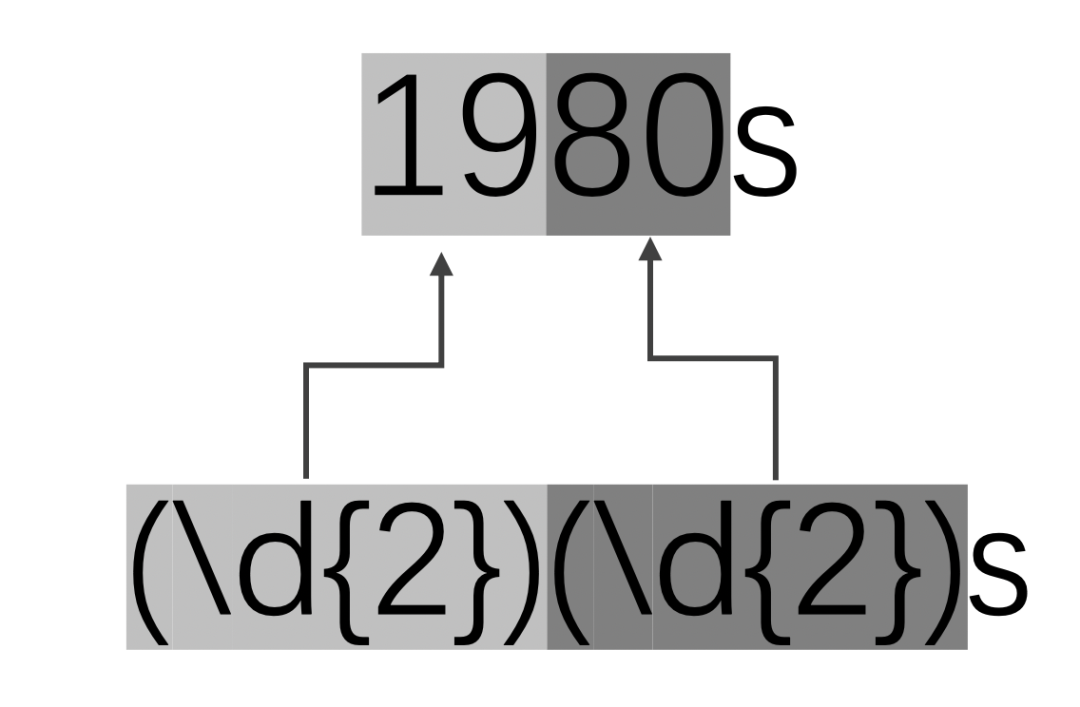 img
img代碼示例:
#include?<fstream>
#include?<iostream>
#include?<regex>
using?namespace?std;
int?main()?{
??regex?word_regex(R"((\d{2})(\d{2})s)");?//?①
??ifstream?file("./content.txt");
??string?line;
??while(getline(file,?line))?{
????auto?iter_begin?=?sregex_iterator(line.begin(),
??????????????????????????????????????line.end(),
??????????????????????????????????????word_regex);
????auto?iter_end?=?sregex_iterator();
????for?(auto?iter?=?iter_begin;?iter?!=?iter_end;?iter++)?{
??????cout?<<?"Match?content:?"?<<?iter->str(0)?<<?",?";?//?②
??????cout?<<?"group?Size:?"?<<?iter->size()?<<?endl;??//?③
??????cout?<<?"Century:?"?<<?iter->str(1)?<<?",?";?//?④
??????cout?<<?"length:?"?<<?iter->length(1)?<<?",?";
??????cout?<<?"position:?"?<<?iter->position(1)?<<?endl;
??????auto?year?=?(*iter)[2];?//?⑤
??????cout?<<?"Year:?"?<<?year.str()?<<?",?";
??????cout?<<?"length:?"?<<?year.length()?<<?",?";
??????cout?<<?"position:?"?<<?iter->position(2)?<<?endl;
??????cout?<<?endl;
????}
??}
??return?0;
}
這段代碼說(shuō)明如下:
- 這個(gè)正則表達(dá)式請(qǐng)注意其中的圓括號(hào)
- 先打印匹配的字符串整體
- 所有的分組數(shù)量,應(yīng)該是 2 + 1 = 3
- 打印出世紀(jì)的部分
- 獲取編號(hào)2的分組,其類(lèi)型是
sub_match
這段代碼輸出如下:
Match?content:?1950s,?group?Size:?3
Century:?19,?length:?2,?position:?25
Year:?50,?length:?2,?position:?27
Match?content:?1980s,?group?Size:?3
Century:?19,?length:?2,?position:?277
Year:?80,?length:?2,?position:?279
同一個(gè)符號(hào)的不同含義
前面的表格中[11],我們看到了正則表達(dá)式的特殊字符。但需要進(jìn)一步說(shuō)明的是,這些特殊字符在不同的環(huán)境可能有著不同的含義。
例如,特殊字符-只有在字符組[...]內(nèi)部才是元字符,否則它只能匹配普通的連字符符號(hào)。并且,即便在字符組內(nèi)部,如果連字符是在開(kāi)頭,它依然是一個(gè)普通字符而不是表示一個(gè)范圍。
相反的,問(wèn)號(hào)?和點(diǎn)號(hào).不在字符組內(nèi)部的時(shí)候才是特殊字符。因此[?.]中的這兩個(gè)符號(hào)僅僅代表這兩個(gè)字符自身。
還有,字符^出現(xiàn)在字符組中的時(shí)候表示的是否定,例如:[a-z]和[^a-z]表示的是正好相反的字符集。但是當(dāng)字符^不是用在字符組中的時(shí)候,它是一個(gè)錨點(diǎn)[12],具體內(nèi)容下文會(huì)說(shuō)到。
量詞的占有欲
還是以content.txt的內(nèi)容為基礎(chǔ),現(xiàn)在假設(shè)我們的目標(biāo)是:找出所有雙引號(hào)中的內(nèi)容。
根據(jù)之前的知識(shí),你可能很輕松就寫(xiě)出了下面這個(gè)正則表達(dá)式:
regex?content_regex("\"(.+)\"");
- 兩邊的雙引號(hào)通過(guò)反斜杠轉(zhuǎn)義
- 待捕獲的內(nèi)容通過(guò)圓括號(hào)形成分組
- 雙引號(hào)中可以是任意內(nèi)容,因此使用
.+
但是當(dāng)你運(yùn)行程序的時(shí)候卻發(fā)現(xiàn)它可能有點(diǎn)問(wèn)題。它捕獲的結(jié)果是:
"find"?or?"find?and?replace"
為什么?其實(shí)很簡(jiǎn)單,因?yàn)殡p引號(hào)本身也可以與.匹配。上面這個(gè)正則表達(dá)式的含義是:匹配一個(gè)兩端是雙引號(hào),中間是任意文字的內(nèi)容。
當(dāng)然,你馬上想到一個(gè)改進(jìn)方法那就是:將正則表達(dá)式圓括號(hào)中的.+改為[^"]+,它的含義是:一個(gè)或多個(gè)非雙引號(hào)字符。這么做是可以的。但其實(shí)我們還有更好的做法。
我們?cè)倩仡^看一下原先的正則表達(dá)式,不考慮分組和轉(zhuǎn)義,它可以寫(xiě)成:".+"。其實(shí)我們知道下面這三個(gè)字符串都是與其匹配的:
"find""find and replace""find" or "find and replace"
而將整個(gè)文本交給正則表達(dá)式的時(shí)候,它找出了最長(zhǎng)的那個(gè)串。可見(jiàn),原先的正則表達(dá)式太過(guò)“貪婪”(greedy)。是的,量詞在默認(rèn)情況都是貪婪的。即:它們會(huì)盡可能多的占有內(nèi)容。
那我們能不能控制量詞讓其盡可能少的占有內(nèi)容,只要滿足匹配要求就可以呢?
答案是肯定的,而且做法很簡(jiǎn)單:在量詞的后面加上一個(gè)?。即,將圓括號(hào)中.+修改為.+?即可。量詞的默認(rèn)形式稱(chēng)之為“匹配優(yōu)先量詞”,現(xiàn)在這種寫(xiě)法稱(chēng)之為“忽略?xún)?yōu)先量詞”。
現(xiàn)在它找到的是下面兩個(gè)匹配:
"find"
"find?and?replace"
小結(jié)一下:
- 匹配優(yōu)先量詞:
*,+,?,{num, num} - 忽略?xún)?yōu)先量詞:?
*?,+?,??,{num, num}?
錨點(diǎn)
錨點(diǎn)是一類(lèi)特殊的標(biāo)記,它們不會(huì)匹配任何文本內(nèi)容,而是尋找特定的標(biāo)記。你可以簡(jiǎn)單理解為它是原先表達(dá)式的基礎(chǔ)上增加了新的匹配條件。如果條件不滿足,則無(wú)法完成匹配。
錨點(diǎn)主要分為三種:
- 行/字符串的起始位置:
^,行/字符串的結(jié)束位置:$ - 單詞邊界:
\b - 環(huán)視 ,見(jiàn)下文
例如:
- 正則表達(dá)式
^\d+在字符串"123abc"中能找到匹配,在字符串"abc123"卻找不到。 - 正則表達(dá)式
some\b在字符串"some birds"中能找到匹配,在字符串"sometimes wonderful"中卻找不到。
下面是代碼示例:
#include?<iostream>
#include?<regex>
using?namespace?std;
void?findIn(const?char*?content,?const?char*?reg_ex)?{
?cout?<<?"Search?'"?<<?reg_ex?<<?"'?in?'"?<<?content?<<?"':?";
?smatch?match;
?string?s(content);
?regex?reg(reg_ex);
?if(regex_search(s,?match,?reg))?{
??cout?<<?match[0]?<<?endl;
?}?else?{
??cout?<<?"NOTHING"?<<?endl;
?}
}
int?main()?{
??findIn("123abc",?"^\\d+");
??findIn("abc123",?"^\\d+");
??cout?<<?endl;
??findIn("some?birds",?"some\\b");
??findIn("sometimes?wonderful",?"some\\b");
??return?0;
}
它的輸出如下:
Search?'^\d+'?in?'123abc':?123
Search?'^\d+'?in?'abc123':?NOTHING
Search?'some\b'?in?'some?birds':?some
Search?'some\b'?in?'sometimes?wonderful':?NOTHING
環(huán)視
現(xiàn)在假設(shè)我們有下面兩個(gè)需求:
- 匹配出所有sometimes中的前四個(gè)字符“some”
- 匹配出所有的單詞some,但是要排除掉“some birds”中的“some”
對(duì)于第一個(gè)問(wèn)題,我們可以分兩步:先找出所有的單詞sometimes,然后取前四個(gè)字符。對(duì)于第二個(gè)問(wèn)題,我們可以先找出所有的單詞“some”,然后把后面是“birds”的丟掉。
以上的解法都是分兩步完成。但實(shí)際上,借助環(huán)視(lookaround)我們可以一步就完成任務(wù)。
環(huán)視是對(duì)匹配位置的附加條件,只有條件滿足時(shí)才能完成匹配。環(huán)視有:順序(向右),逆序(向左),肯定和否定一共四種:
| 類(lèi)型 | 正則表達(dá)式 | 匹配條件 |
|---|---|---|
| 肯定順序環(huán)視 | (?=...) | 子表達(dá)式能夠匹配右側(cè)文本 |
| 否定順序環(huán)視 | (?!...) | 子表達(dá)式不能匹配右側(cè)文本 |
| 肯定逆序環(huán)視 | (?<=...) | 子表達(dá)式能夠匹配左側(cè)文本 |
| 否定逆序環(huán)視 | (?<!...) | 子表達(dá)式不能匹配左側(cè)文本 |
C++中的環(huán)視只支持順序環(huán)視,不支持逆序環(huán)視。
環(huán)視說(shuō)起來(lái)有些拗口,但看具體的例子就容易理解了:
#include?<iostream>
#include?<regex>
using?namespace?std;
void?isMatch(const?char*?content,?const?char*?reg_ex)?{
?cout?<<?"Is?'"?<<?reg_ex?<<?"'?match?'"?<<?content?<<?"':?";
?smatch?match;
?string?s(content);
?regex?reg(reg_ex);
?if(regex_search(s,?match,?reg))?{
??cout?<<?"YES"?<<?endl;
?}?else?{
??cout?<<?"NO"?<<?endl;
?}
}
int?main()?{
??isMatch("sometimes",?"(?=sometimes)some");
??isMatch("something",?"(?=sometimes)some");
??cout?<<?endl;
??isMatch("some?eggs",?"(?!some?birds)some");
??isMatch("some?birds",?"(?!some?birds)some");
??return?0;
}
這段代碼并不復(fù)雜所以就不多做說(shuō)明,它的輸出結(jié)果如下:
Is?'sometimes'?match?'(?=sometimes)some':?YES
Is?'something'?match?'(?=sometimes)some':?NO
Is?'some?eggs'?match?'(?!some?birds)some':?YES
Is?'some?birds'?match?'(?!some?birds)some':?NO
對(duì)于包含環(huán)視的正則表達(dá)式來(lái)說(shuō),環(huán)視之外的內(nèi)容是匹配的主體,環(huán)視本身只是一個(gè)附件條件。(?=sometimes)這個(gè)肯定順序環(huán)視要求從這個(gè)位置開(kāi)始,接下來(lái)的字符串必須是"sometimes"才能完成匹配。(?!some birds)這個(gè)否定順序環(huán)視要是接下來(lái)的字符串一定不能是"some birds"才能完成匹配。
為了進(jìn)一步幫助你理解,我們以圖示的方式將(?=sometimes)some匹配"something"的過(guò)程描述出來(lái)。
圖示中,虛線的上面是待匹配的文本,下面是正則表達(dá)式。對(duì)于環(huán)視,我們可以將其環(huán)視條件和主體分開(kāi)來(lái)看。我們以一個(gè)下標(biāo)三角箭頭表示當(dāng)前匹配的搜索位置。
剛開(kāi)始的時(shí)候,搜索的位置是第一個(gè)字符的前面:
 img
img接下來(lái),搜索位置往后走一個(gè)字符:
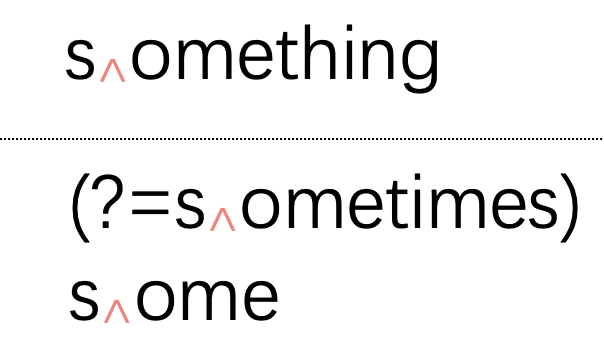 img
img這個(gè)過(guò)程可以一直進(jìn)行,直到匹配完"some":
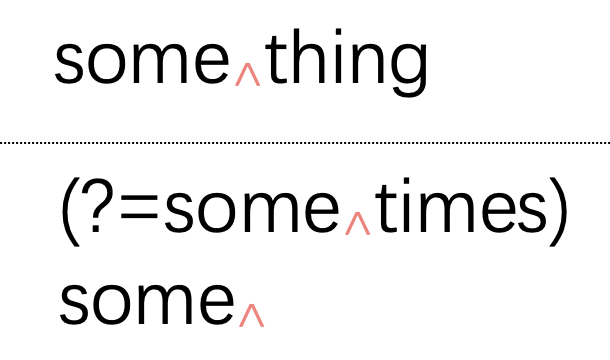 img
img雖然正則表達(dá)式的主體"some"完成了匹配,但是接下來(lái)環(huán)視的條件卻無(wú)法滿足,于是匹配失敗:
 img
img但是,如果要匹配內(nèi)容正好是"sometimes",則條件是滿足的,于是就完成了匹配。
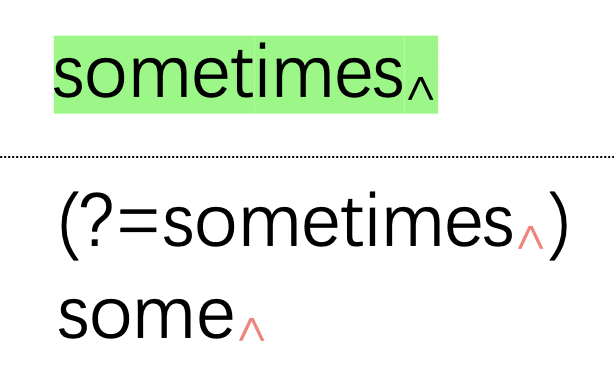 img結(jié)束語(yǔ)
img結(jié)束語(yǔ)因?yàn)槭侨腴T(mén)的文章,所以本文中所舉例的正則表達(dá)式都很簡(jiǎn)單。但實(shí)際應(yīng)用的時(shí)候,我們常常會(huì)寫(xiě)出非常復(fù)雜的正則表達(dá)式。你可以點(diǎn)擊這里瀏覽一些示例:Regular Expression Library[13]。
復(fù)雜的正則表達(dá)式常常很難理解,你可能需要借助工具來(lái)幫助分析,下面兩個(gè)工具也許能幫上忙:
- https://regex101.com[14]
- https://www.debuggex.com[15]
想要很好的掌握正則表達(dá)式,多使用多練習(xí)是最好的方法。想要深入學(xué)習(xí)正則表達(dá)式,Jeffrey E.F. Friedl的《精通正則表達(dá)式》[16]可能是最好的選擇。
參考資料
[1]paulQuei/cpp-regex:?https://github.com/paulQuei/cpp-regex
[2]ECMAScript正則表達(dá)式語(yǔ)法:?https://en.cppreference.com/w/cpp/regex/ecmascript
[3]基礎(chǔ)POSIX正則表達(dá)式語(yǔ)法:?http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_03
[4]擴(kuò)展POSIX正則表達(dá)式語(yǔ)法:?http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04
[5]awk工具的正則表達(dá)式語(yǔ)法:?http://pubs.opengroup.org/onlinepubs/9699919799/utilities/awk.html#tag_20_06_13_04
[6]grep工具的正則表達(dá)式語(yǔ)法:?https://www.gnu.org/software/findutils/manual/html_node/find_html/grep-regular-expression-syntax.html
[7]grep工具的正則表達(dá)式語(yǔ)法:?https://www.gnu.org/software/findutils/manual/html_node/find_html/posix_002degrep-regular-expression-syntax.html#posix_002degrep-regular-expression-syntax
[8]ECMA-262 文法:?http://ecma-international.org/ecma-262/5.1/#sec-15.10
[9]“文法”:?https://paul.pub/cpp-regex/#id-文法
[10]std::sub_match:?https://en.cppreference.com/w/cpp/regex/sub_match
[11]前面的表格中:?https://paul.pub/cpp-regex/#id-特殊字符
[12]a-z]和[^a-z]表示的是正好相反的字符集。但是當(dāng)字符^`不是用在字符組中的時(shí)候,它是一個(gè)[錨點(diǎn):?https://paul.pub/cpp-regex/#id-錨點(diǎn)
Regular Expression Library:?http://regexlib.com/DisplayPatterns.aspx
[14]https://regex101.com:?https://regex101.com/
[15]https://www.debuggex.com:?https://www.debuggex.com/
[16]《精通正則表達(dá)式》:?https://item.jd.com/11070361.html文章鏈接:https://paul.pub/cpp-regex/